Ali Haidar Ahmad
-
المساهمات
1068 -
تاريخ الانضمام
-
تاريخ آخر زيارة
-
عدد الأيام التي تصدر بها
43
نوع المحتوى
ريادة الأعمال
البرمجة
التصميم
DevOps
التسويق والمبيعات
العمل الحر
البرامج والتطبيقات
آخر التحديثات
قصص نجاح
أسئلة وأجوبة
كتب
دورات
كل منشورات العضو Ali Haidar Ahmad
-
 import java.util.Vector; //vector استيراد الصف public class ourvector { public static void main(String[] args) { Vector vec = new Vector(); // تعريف غرض /* له عدة بواني vector الصف Vector() الباني الافتراضي، في هذه الحالة كلما امتلأ الشعاع يتم زيادة حجمه بمقدار واحد Vector(int size) باني بوسيط واحد يعبر عن حجم الشعاع وأيضاً يقوم بنفس العمل عندما يمتلئ Vector(int size,int inc) (الخانات التي ستحجو في الذاكرة)باني بوسيطين بحيث الباني الثاني يعبر عن عدد العناصر التي ستضاف كلما امتلأ */ vec.add(12); // لإضافة عنصر إلى الشعاع vec.add(82); vec.add(9);// يمكنك أيضاًإنشاء شعاع وتمريره لهذه الدالة وبالتالي سيضيف كل قيم الشعاع الممرر إلى الشعاع الأساسي System.out.println(vec.size()); // لطباعة عدد عناصر الشعاع for(int i=0; i<vec.size(); j++) { // لطباعة عناصر الشعاع System.out.println("vec[" +j+ "]= " +vec.get(j)); } vec.remove(1); // لحذف عنصر محدد حيث نقوم بتمرير موقعه vec.clear(); // لحذف عناصر الشعاع } } // استعرضت لك التوابع الأساسية، وهناك الكثير الكثير من التوابع الأخرى
import java.util.Vector; //vector استيراد الصف public class ourvector { public static void main(String[] args) { Vector vec = new Vector(); // تعريف غرض /* له عدة بواني vector الصف Vector() الباني الافتراضي، في هذه الحالة كلما امتلأ الشعاع يتم زيادة حجمه بمقدار واحد Vector(int size) باني بوسيط واحد يعبر عن حجم الشعاع وأيضاً يقوم بنفس العمل عندما يمتلئ Vector(int size,int inc) (الخانات التي ستحجو في الذاكرة)باني بوسيطين بحيث الباني الثاني يعبر عن عدد العناصر التي ستضاف كلما امتلأ */ vec.add(12); // لإضافة عنصر إلى الشعاع vec.add(82); vec.add(9);// يمكنك أيضاًإنشاء شعاع وتمريره لهذه الدالة وبالتالي سيضيف كل قيم الشعاع الممرر إلى الشعاع الأساسي System.out.println(vec.size()); // لطباعة عدد عناصر الشعاع for(int i=0; i<vec.size(); j++) { // لطباعة عناصر الشعاع System.out.println("vec[" +j+ "]= " +vec.get(j)); } vec.remove(1); // لحذف عنصر محدد حيث نقوم بتمرير موقعه vec.clear(); // لحذف عناصر الشعاع } } // استعرضت لك التوابع الأساسية، وهناك الكثير الكثير من التوابع الأخرى- 2 اجابة
-
- 3
-

-
الرجاء إعادة صياغة الطلب a بطريقة واضحة
-
import pandas as pd dic = {'column1':[17, 3, 4], 'column2':[66, 77, 66], 'column3':[66, 77, 5]} df = pd.DataFrame(dic) # لإعادة تسمية الأعمدة df1=df.rename(columns={"c1": "A", "c2": "B"}) print(df1,end='\n\n') # لإعادة تسمية الأسطر df2=df.rename(index={0: "x", 1: "y", 2: "z"}) print(df2)
- 1 جواب
-
- 3
-
-
import pandas as pd # لنفرض لدينا البيانات التالية dic = {'c1':[17, 3, 4], 'c2':[66, 77, 66], 'c3':[66, 77, 5]} # DataFrame نحولها ل df = pd.DataFrame(dic) print(df,end='\n\n') # عرض البيانات ################################ للاستعلام ######################################## # select * from table where column_name = some_value < تكافئ > table[table.column_name == some_value] # :مثال values=df[df.c2 == 66] # c2 أي سنختار الأسطر التي تتضمن القيمة 66 في العمود print(values,end='\n\n') # عرض نتيجة الاستعلام values=df.query('c2 == 66') # طريقة أخرى print(values,end='\n\n') # :أما في حالة كان لديك عدة شروط نستخدم # table.query('column_name1 == value1 | column_name2 == value2') # :أو # table[(table.column_name1 == some_value1) | (table.column_name2 == some_value2)] values=df[(df.c3 == 77) | (df.c1 == 3)] print(values) # وكان بإمكانك تجربة الشكل الثاني أيضاً
- 1 جواب
-
- 2
-
-
(object)append تضيف كائن في نهاية ال list كما هو: li = ['adam', 'messi',44] li.append([5,5]) # الخرج : ['adam', 'messi', 44, [5, 5]] (iterable)extend تقوم بإضافة عناصر إلى ال list من iterable (أي list أخرى أو tuble أو set أو dict): li2 = ['adam', 'messi',44] li2.extend([5,5]) # الخرج : ['adam', 'messi', 44, 5, 5] # لاحظ كيف اختلفت عملية الإضافة (index,value)insert: تستخدم لإضافة عنصر جديد في مكان محدد في الـlist الذي قام باستدعائها. li3 = ['adam', 'messi',44] li3.insert(0,[5,5]) # الخرج : [[5, 5], 'adam', 'messi', 44]
- 3 اجابة
-
- 3
-
-
يمكن تحقيقه باستخدام المصفوفات (سافترض أن لديك معرفة نظرية بسيطة حوله): المكدس عبارة عن نموذج خاص لتخزین البیانات واستخراجها بآلیة الداخل أولاً الخارج أخراً أو الداخل أخيراً يخرج أولاً LIFO (LAST INPUT FIRST OUTPUT) نستخدم مع المكدس مؤشر واحد فقط نسميه top. عند إدخال أول قیمة فإننا نزید من قيمته فيصبح صفراً وكل ما أدخلنا قیمة جديدة فإن المؤشر یزید بمقدار واحد إلى أن یمتلئ المكدس. عندما یكون المكدس فارغاُ يكون top=-1 وعند القيام بعملیة إخراج لقيمة من المكدس فإننا ننقص المؤشر بمقدار واحد إلى أن تصل قیمة المؤشر إلى -1. import java.io.*; class javaapplication1 { static final int CAPACITY=5; // يمكنك تعديلها static int[] Stack=new int[CAPACITY]; static int top=-1; // ویسمى ذیل المكدس وھو متغیر عام تستطیع الدوال الوصول إليهTop تعریف static boolean isEmpty(){ // اختبار المكدس فيما إذا كان فارغاً return (top < 0); } static boolean isFull(){ // اختبار المكدس فيما إذا كان ممتلئ return (top+1== CAPACITY); } /* حجم المصفوفة -1 = top نعلم أن المكدس ممتلئ عندما یكون مؤشر الذیل أي top وإلا سنزید من المؤشر بواحد وسنضع القیمة بداخل المصفوفة بداخل الموقع الذي تكون قیمته أي اقل من الصفر top=-1 نعلم أن المكدس يصبح فارغاً عندما تكون قیمة المؤشر وسنطرح قیمة المؤشر top وإلا سنخرج القیمة من داخل المصفوفة التي تحمل عنوان قیمة بواحد. */ static void push(int element){ // دالة لإدخال البیانات إلى المكدس if (isFull()) // إذا كان ممتلئ لايمكن الإضافة عليه System.out.println("Stack is full."); else // نضيف العنصر الجديد إلى المكدس فيما عدا ذلك Stack[top++] = element; } static int pop(){ // دالة أخراج البیانات من المكدس if (isEmpty()){ System.out.println("Stack is empty."); System.exit( 0 ); } return Stack[top--]; } // اختبار التوابع public static void main(String args[])throws IOException{ String num; BufferedReader br = new BufferedReader(new InputStreamReader (System.in)); System.out.println( "Enter first integer" ); while(!isFull()){ num=br.readLine(); push(Integer.parseInt(num)); } while(!isEmpty())System.out.println(pop()+" "); } } // أدخلي القيم التي تريدينها وستلاحظين أن الخرج سيحقق مفهوم المكدس طبعاً يمكنك تعديل الكود السابق وتغليفه مثلاً ضمن class تسميه Stack ويمكنك أن تضيف له العديد من الدوال الأخرى. ويمكنك أيضاً استخدام الكلاس stack الذي تقدمه جافا وهو كلاس يرث الصف vector وبالتالي يرث كل الدوال الموجودة فيها. import java.util.Stack; // stack استيراد الصف public class Main { public static void main(String[] args) { // تعريف غرض من الصف Stack ourstack = new Stack(); // s هنا قمنا بإضافة 4 عناصر في الكائن ourstack.push("Ali"); ourstack.push("Ahmad") // إخراج البيانات من المكدس while( !s.empty() ) { System.out.println(ourstack.pop()); } } } ويوجد العديد من الدوال الأخرى ضمن الكلاس Stack في جافا.
- 3 اجابة
-
- 2
-
-
# iterrows باستخدام الدالة for i, row in df.iterrows(): for j, column in row.iteritems(): print(column) # أو بالشكل التالي for index, row in df.iterrows(): print(row['column1'], row['column2']) # iloc أو باستخدام التابع for i in range(0, len(data)): print df.iloc[i]['column1'], df.iloc[i]['ccolumn2'] حيث أن الدالة iterrows هو مولد ينتج كلاً من الفهرس والسطر (كسلسلة).
- 1 جواب
-
- 3
-
-
إن الـصف الابن يرث كل شيء موجود في الـصف الأب إلا الخصائص التي تم تعريفها كوسطاء بداخل الدالة __init__ و السبب في هذا أن الدالة __init__ تولد الخصائص لل object و تربطها بالكلاس لحظة إنشاء ال object. أي إذا لم تنشئ كائن من الكلاس لن يتم إستدعاء هذه الدالة أصلاً أي يمكنك القول أن المتحولات المعرفة ضمنها لن تكون موجودة، لذا لايمكن وراثتها بشكل مباشر. وحل هذه المشكلة يكون كما في المثال التالي، حيث نقوم باستدعاء الدالة __init__ للصف الأب داخل دالة __init__ للصف الابن: class myname: def __init__(self,name="Esraa"): self.name=name # نقوم بوراثته class emp(myname): def __init__(self): myname.__init__(self) # نقوم باستدعاء باني الصف الاب داخل باني الصف الاب p = emp() # أخذ غرض من الصف الابن print(p.name) # Esraa
- 1 جواب
-
- 3
-
-
ملف CSV (Comma Separated Values قيم مفصولة بفاصلة) هو عبارة عن نوع خاص من الملفات التي يمكنك إنشاؤها أو تحريرها في Excel. بدلاً من تخزين المعلومات في أعمدة، تُخزّن ملفات CSV المعلومات مفصولة بفواصل. لقراءة ملف من هذا النوع نستخدم التابع csv.reader(): تعيد هذه الدالة كائن قراءة Object Reader مهمته هي المرور على جميع الأسطر في ملف csv. # مثال import csv path1='E:\file.csv' # كتابة المسار الذي يوجد به الملف file=open(path1,'r') # فتح الملف الموجود في المسار الممر reader=csv.reader(file) # csv الموجود في الصف reader قراءة الملف باستخدام التابع # reader موجودة في الغرض csv الآن أصبحت كل الأسطر في ملف # لعرض الملف يمكننا القيام بمايلي for row in reader: print(row)
- 2 اجابة
-
- 2
-
-
سأقوم بإنشاء صف ابن Child Class وأقوم بوراثته من صف أب Super Class ثم سأستدعي جميع الدول: طبعاً لاتختلف عملية الاستدعاء أو كتابة البرنامج في باي تشارم عن بقية البرامج مثل سبايدر وجوبيتر فكلها IDE للبايثون. #----------------------------------------# # تعريف الصف الأب class info: def gender(self,gen): if gen=='male': return "Male" else: return "Female" def isteenager(self,age): if age<=21: return True else: return False #----------------------------------------# # تعريف الصف الابن الذي يمثل طالب class Student(info): def __init__(self,name,age,degree1,degree2,degree3): self.degree1=degree1 self.degree2=degree2 self.degree3=degree3 self.name=name self.age=age def calc_Gpa(self): return (self.degree1+self.degree2+self.degree3)/3 # حساب معدل الطالب في المواد الثلاثة def get_info(self): print("Name : "+str(self.name)+'\n'+"Age :"+str(self.age)) #----------------------------------------# Leen = Student('Leen',20,100,90,85) # إنشاء غرض من الصف الابن #----------------------------------------# # استدعاء الطرق الموجودة في الصف الابن print(Leen.calc_Gpa()) print(Leen.get_info()) #----------------------------------------# # استدعاء الطرق الموجودة في الصف الأب من خلال الصف الابن، وهذا ممكن لأننا قمنا بوراثته print(Leen.isteenager(Leen.age)) print(Leen.gender("female")) #----------------------------------------# # (أي هنا لن نستخدم الصف الابن) استدعاء الطرق الموجودة في الصف الأب عن طريق إنشاء كائن من الصف الأب p=info() # إنشاء غرض من الصف الأب print(p.isteenager(20)) print(p.gender("male"))
- 1 جواب
-
- 1
-
-
هناك طرق كثيرة ويمكنك استخدام المكتبة Sikit-Learn لتنفيذها مباشرة: 1.Standardization: وهي العملية الأكثر شهرة , وفيها يتم طرح القيمة ناقص ال mean مقسومة علي الانحراف المعياري std. # StandardScaler استيراد الصف from sklearn.preprocessing import StandardScaler # القيام بعملية التقييس StandardSca = StandardScaler(copy=True) #StandardScaler تعريف غرض من الصف # copy=True لكي لايعدل على البيانات الأساسية أي سينشئ نسخة عن البيانات ويطبق عليها التقييس data = StandardSca.fit_transform(data) # StandardScaler استدعاء التابع الذي ينفذ عملية التقييس من الصف 2.MinMaxScaler: يتم فيه طرح القيمة من المتوسط وتقسم على المدى (الفرق بين أكبر وأصغر قيمة) وتكون القيم الجديدة بين 0 و 1. #MinMaxScaler استيراد الصف from sklearn.preprocessing import MinMaxScaler MinMaxSc = MinMaxScaler(copy=True, feature_range=(0, 1)) # يمكننا تغيير المجال data = MinMaxSc.fit_transform(data) 3.Binarizer: تقوم بتحويل القيم إلى 0 أو ، بناءان على قيمة العتبة threshold الممرة from sklearn.preprocessing import Binarizer Binarize = Binarizer(threshold = value) data = Binarize.fit_transform(data) 4.Normalizer: مخصصة لتناول كل صف علي حدة في المصفوفات ثنائية الأبعاد. from sklearn.preprocessing import Normalizer Normalize = Normalizer(copy=True, norm='l2') # max يمكنك تغيير النورم الى 11 أو data = Normalize.fit_transform(data) 5.FunctionTransformer: للقيام بالتقييس باستحدام دالة نعرفها بأنفسنا. from sklearn.preprocessing import FunctionTransformer ''' FunctionTransformer(func=None, inverse_func=None, validate= None, accept_sparse=False,pass_y='deprecated', check_inverse=True, kw_args=None,inv_kw_args=None) ''' scaler = FunctionTransformer(func = lambda x: x**2,validate = True) data = scaler.fit_transform(data)
- 3 اجابة
-
- 2
-
-
تعيد الدالة super() كائنا وسيطا يفوض استدعاءات التوابع إلى صنف أب أو صنف شقيق للصنف الذي استدعيت منه الدالة. هذا مفيد للوصول إلى التوابع الموروثة التي أعيدت كتابتها في صنف معيّن. ترتيب البحث يكون هو نفسه التّرتيب المستخدم من طرف الدالة getattr() لكن النوع type المعطى يتجاهل. المعاملات: type: النوع الذي ستقوم الدّالة super() بتفويض استدعاءات التّوابع إلى صنف أب أو صنف شقيق له. تعرض الخاصية __mro__ الخاصة بالصّنف type ترتيب البحث عن التوابع (method resolution search order) الذي يستعمل من طرف كلّ من الدّالة getattr() والدّالة super() . وتكون الخاصيّة ديناميكيّةً يُمكن لها أن تتغيّر كلّمَا حُدّثت شجرة الوراثة (inheritance hierarchy). object-or-type:إن لم تُمرّر قيمة للمُعامل، فالكائن super المُعاد لا يكون مربوطًا (unbound). إن كانت قيمة المُعامل كائنًا، فيجب على الاستدعاء isinstance(obj, type) أن يُعيد القيمة True. إن كانت قيمة المُعامل نوعًا (type)، فيجب على الاستدعاء issubclass(type2, type) أن يُعيد القيمة True (وهذا مُفيد لتوابع الأصناف). القيمة المعادة: كائن وسيط يُفوّض استدعاءات التّوابع إلى صنف أبٍ أو صنف شقيق للصّنف الذي استُدعيَت منه الدّالة. أمثلة: هناك حالتان تستعمل فيهما الدّالة super() عادة: تستعمل للوصول إلى الصّنف الأب في شجرة أصناف ذات وراثة وحيدة (class hierarchy with single inheritance) دون الحاجة إلى تسمية الصنف مباشرة، ما يسمح للشيفرة بأن تكون قابلة للتّطوير والصيانة بشكل أفضل، وحالة الاستخدام هذه تشابه طريقة استخدام super() في لغات البرمجة الأخرى. المثال التّالي يُوضّح حالة الاستخدام هذه: class A: def add(self, x, y): # دالّة تُعيد مجموع عددين return x+y class B(A): # وراثة من الصّنف الأب def add_print(self, x, y): # دالّة تُضيف العددين وتطبع العمليّة result = super().add(x, y) # استدعاء تابع يتواجد في الصّنف الأب دون تسميّة الصّنف الأب صراحةً print(f'{x}+{y}={result}') # طباعة العمليّة الحسابيّة adder = B() # إنشاء كائن من الصّنف الوارث adder.add_print(1, 2) # استدعاء دالّة الإضافة والطّباعة #1+2=3 adder.add_print(1, 5) #1+5=6 الحالة الثانيّة التي تستخدم فيها هي عند الرغبة في استعمال وراثة متعددة متعاونة (cooperative multiple inheritance) في بيئة تنفيذ ديناميكية (أي أن الصنف يمكن له أن يرث من أكثر من صنف واحد). هذه الميزة موجودة فقط في لغة بايثون ولا توجد في لغات البرمجة المجمعة (statically compiled languages) أو في لغات البرمجة التي لا تدعم سوى الوراثة الأحادية (أي أن الصنف لا يُمكن أن يرث إلا من صنف واحد فقط). ما يمكن من تطبيق "تخطيطات الماسة (diamond diagrams)" عندما تحتوي أصناف آباء عدة على نفس التابع. يجب على هذا التابع أن يمتلك نفس توقيع الاستدعاء (calling signature) في جميع الحالات (لأنّ ترتيب الاستدعاءات يحدد في وقت التّنفيذ runtime، ولأن الترتيب يتغير حسب تغيّر شجرة الأصناف، ولأن الترتيب يمكن له أن يشمل أصنافا شقيقة غير معلومة قبل بدء وقت التنفيذ). class C(B): def method(self, arg): super().method(arg) # هذا الاستدعاء مُكافئ للاستدعاء أدناه # super(C, self).method(arg) ملاحظات: الدالة super() مطبقَة كجزء من عملية الرّبط للبحث عن الخاصيات بوضوح (explicit) باستخدام النّقطة . مثل super().__getitem__(name). وتقوم بذلك عبر تطبيق تابع __getattribute__() خاص بها للبحث عن الأصناف بترتيب يمكن توقّعه يَدعم الوراثة المتعددة المتعاونة. وبالتّالي، فالدالة super() غير معرفَة للبحث الضمني (implicit) باستخدام الجمل أو العوامل مثل super()[name]. استخدام super() ليس محصورا داخل التّوابع فقط، المعاملان اللذان تقبلهما الدالة يحددان المراجع المناسبة التي ستنشأ. استدعاء الدالة دون عوامل يعمل داخل الأصناف فقط، لأن المجمع يملأ الفراغات المطلوبة للحصول على الصنف المناسب، إضافة للوصول إلى النسخة الحالية للتوابع العادية. # تم تعديله
- 2 اجابة
-
- 1
-
-
تشير الأقواس المتعرجة {} إلى وجود Block أي نطاق محلي أو كتلة من التعليمات المترابطة. فعندما نعرف حلقة تقوم بعمل تكرار لتعليمات معينة، نقوم بوضع هذه التعليمات ضمن Block أي ضمن {} ,والغاية من ذلك هو تحديد التعليمات التي ستتكرر، أي لكي يفهم الكومبايلر أين تبدأ التعليمات التي تريدها أن تتكرر وأين تنتهي. for (int i = 0; i < 5; i++) { // هنا أنت تخبر الكومبايلر أن التعليمات التي تريد أن تكررها تبدأ من هنا System.out.println(i); // خمس مرات System.out.println(i) أي سيتم تنفيذ التعليمة } // وتنتهي هنا // for التعليمات التالية ليست ضمن القوسين المتعرجين لحلقة // أي طالما ليسوا ضمن القوسين فهما منفصلين عن الحلقة int x=5; System.out.println(x); أو عندما نعرف تابع فيجب أن نضع التعليمات التي يقوم بها هذا التابع ضمن Block أيضاُ، لكي يفهم الكومبايلر أين يبدأ التابع الخاص بك وأين ينتهي. public void bar(int num1, int num2) { // أي هنا تبدأ التعليمات التي ينفذها التابع // تعليمة 1 // تعليمة 2 // تعليمة 3 } // وهنا تنتهي أما بالنسبة للأقواس من الشكل () فهذه الأقواس نستخدمها لكي نضع ضمنها الوسطاء التي يحتاجها تابع للقيام بمهمة ما، أو مثلاً المعلومات التي تحتاجها الحلقة لتقوم بعملية التكرار. public sum bar(int num1, int num2) // () هنا وضعنا المعلومات التي يحتاجها التابع لكي يقوم بعمله ضمن { // تعليمة 1 // تعليمة 2 // تعليمة 3 } for (int i = 0; i < 5; i++) // وضعنا ضمن القوسين () المعلومات التي تحتاجها الحلقة { System.out.println(i); } الأقواس المربعة [] تستخدم لتعريف المصفوفات int [] numbers; // أي قمنا بتعريف مصفوفة
- 5 اجابة
-
- 2
-
-
list1 = ["Hello", "take"] list2 = ["Dear", "Sir"] list3=list1+list2 فقط استخدم المعامل +
- 2 اجابة
-
- 1
-
-
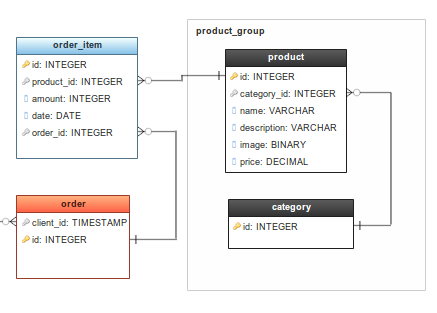
DB Diagram: تعرض مخططات قاعدة البيانات بنية قاعدة البيانات بشكل بياني. وذلك باستخدام رسوم تخطيطية لقاعدة البيانات. حيث يمكنك من خلالها تمثيل ال Objects في جداول وتمثيل العلاقات بينها بالرسم. مثال:
-
في One_Hot، يتم إعطاء كل كلمة w في مجموعة المفردات رقم تعريف فريد Wid يتراوح بين 1 و | V |، بحيث |V| هو عدد الكلمات المختلفة في مجموعة البيانات (عدد الكلمات المختلفة الكلي)، و V هي كل الكلمات المختلفة في مجموعة البيانات. ثم يتم تمثيل كل كلمة بواسطة متجه قيمه من 0 و 1 وأبعاده تساوي |V| أي بعدد المفردات المختلفة، ومملوء ب صفر باستثناء الفهرس الذي يقابل رقم الكلمة index = wid، حيث نضع فيه 1. ليكن لدينا المثال التالي : D1 Dog bites man D2 Man bites dog D3 Dog eats meat D4 Man eats food نقوم أولاً بإعطاء رقم فريد لكل كلمة: dog = 1, bites = 2, man = 3, meat = 4 , food = 5, eats = 6 نلاحظ أن V|=6| لنأخذ أول نص من بياناتنا ونرمزه باستخدام One_Hot: -يتم تمثيل dog ك [1,0,0,0,0,0] -يتم تمثيل bites ك [0,1,0,0,0,0] -يتم تمثيل man ك [0,0,1,0,0,0] وبالتالي يتم تمثيل D1 ك : [[0,0,1,0,0,0],[0,1,0,0,0,0],[1,0,0,0,0,0]] أو [1,1,1,0,0,0] وهكذا بالنسبة للبقية. سأعطي الآن مثال حقيقي وأرمزه باستخدام keras: ##################################################### By Ali #########################################333 # قمنا بتعريف عدة نصوص Text1='The Argentine national team will play tomorrow' Text2='The Brazil national team will travel to Hill' Text3='I Love' Text4='Champeons Leage' Text5='One hot Encoding is a type of vector representation ' data=[Text1,Text2,Text3,Text4,Text5] #list جمعنا هذه النصوص في print("The data :"data) ''' Tokenizer نقوم باستيراد الكلاس لها Tokenaization هذا الكلاس نعطيه البيانات ويقوم بعمل أي من خلاله سأقوم بإسناد رقم فريد لكل كلمة في النص وسأقوم أيضاً من خلاله بتمثيل النصوص على شكل أرقام ''' from keras.preprocessing.text import Tokenizer t= Tokenizer() t.fit_on_texts(data) # هنا سوف يأخذ كل البيانات ويربط كل كلمة بعدد صحيح فريد #هنا سيعرض لي القاموس الذي تم إنشاؤه لبياناتنا وهو قاموس يحتوي على كل كلمة مع العدد الصحيح الذي تم ربطها به print("The word index",t.word_index) # الآن نقوم بتحويل النصوص التي لدينا إلى نصوص مرمزة بأرقام على أساس قيم القاموس sequences = t.texts_to_sequences(data) print("The sequences generated from text are : ",sequences) # one hot encodingهناالتابع الذي سيحقق لي عملية ال import numpy as np def One_hot_encoded(sequences, dimension=24+1): # لأن عدد الكلمات المميزةهو 24 results = np.zeros((len(sequences), dimension)) for i, sequence in enumerate(sequences): results[i, sequence] = 1 return results # الآن نستدعي التابع One_Hot_data = One_hot_encoded(sequences) print("One Hot Encoding:\n"+str(One_Hot_data)) # END الخرج : The word index {'the': 1, 'national': 2, 'team': 3, 'will': 4, 'argentine': 5, 'play': 6, 'tomorrow': 7, 'brazil': 8, 'travel': 9, 'to': 10, 'hill': 11, 'i': 12, 'love': 13, 'champeons': 14, 'leage': 15, 'one': 16, 'hot': 17, 'encoding': 18, 'is': 19, 'a': 20, 'type': 21, 'of': 22, 'vector': 23, 'representation': 24} The sequences generated from text are : [[1, 5, 2, 3, 4, 6, 7], [1, 8, 2, 3, 4, 9, 10, 11], [12, 13], [14, 15], [16, 17, 18, 19, 20, 21, 22, 23, 24]] One Hot Encoding: [[0. 1. 1. 1. 1. 1. 1. 1. 0. 0. 0. 0. 0. 0. 0. 0. 0. 0. 0. 0. 0. 0. 0. 0. 0.] [0. 1. 1. 1. 1. 0. 0. 0. 1. 1. 1. 1. 0. 0. 0. 0. 0. 0. 0. 0. 0. 0. 0. 0. 0.] [0. 0. 0. 0. 0. 0. 0. 0. 0. 0. 0. 0. 1. 1. 0. 0. 0. 0. 0. 0. 0. 0. 0. 0. 0.] [0. 0. 0. 0. 0. 0. 0. 0. 0. 0. 0. 0. 0. 0. 1. 1. 0. 0. 0. 0. 0. 0. 0. 0. 0.] [0. 0. 0. 0. 0. 0. 0. 0. 0. 0. 0. 0. 0. 0. 0. 0. 1. 1. 1. 1. 1. 1. 1. 1. 1.]] -
- 1 جواب
-
- 1
-
-
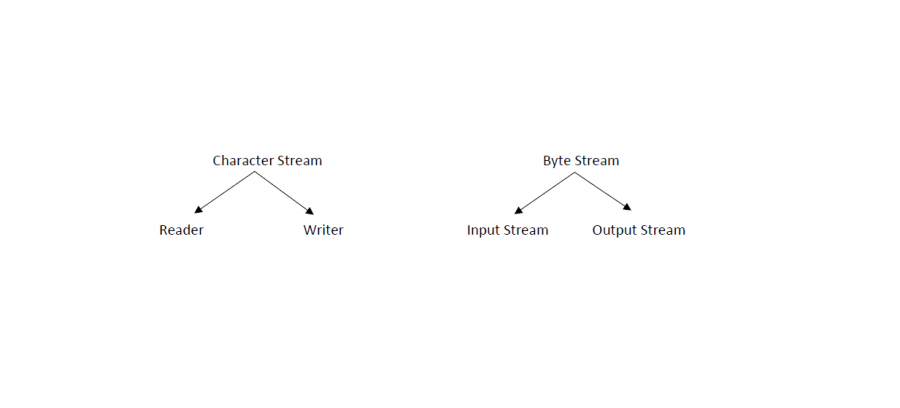
ان مصدر البيانات متعدد اما ان يكون الكيبورد (وهو القياسي ) أو يكون ملف و ممكن ان يكون socket أي قراءة البيانات من الشبكة وفي جميع الحالات يتم التعامل مع هذه المصادر من خلال ما يسمى مجرى البيانات Stream، أما الكتابة ممكن أن تكون على الشاشة وممكن أن تكون كتابة الى ملف او الى جهاز اخر عبر ال Socket، وكذلك هذه العمليات تتم بنفس الطريقة من خلال ال Stream. إذاً الغاية من استخدام المجاري Stream هي توحيد عمليات الادخال والإخراج بغض النظر عن الهدف. وال Stream هو تدفق البيانات من مصدر الى الهدف . وأنواع المجاري هي اما Byte Streams او Character Streams. حيث نوع البيانات التي سأنقلها من المصدر الى الهدف هي التي تحدد نوع المجرى الذي سأتعامل معه، مثلا عندما نقرا من ملف نصي فيجب أن نأخذ مجرى محرفي ( كل محرف من 16 بت ) اما عندما تكون البيانات ثنائية مثلا أغنية او فيديو أو... عندها نتعامل مع مجرى Byte Streams حيث كل بايت من 8 بتات. بعد معرفة نوع المجرى يجب تحديد المجرى هل هو مجرى دخل أم خرج ؟ أي هل برنامج سوف يقرا بيانات ام سوف يكتب بيانات ؟ اذا كان البرنامج يريد أن يقرا بيانات ثنائية فهو يتعامل مع Input Stream اما اذا كان البرنامج يريد أن يقرا بيانات محرفية فهو يتعامل مع Reader. اذا كان البرنامج يريد أن يكتب بيانات ثنائية فهو يتعامل مع Output Stream اما اذا كان البرنامج يريد أن يكتب بيانات محرفية فهو يتعامل مع Writer.
- 2 اجابة
-
- 3
-
-
في حال كانت القيم التي تتعامل معها أعداد صحيحة Integer، استخدم الصف BigInteger لحل مشكلتك فهو صف مخصص للتعامل مع الأرقام الضخمة كالتالي: import java.math.BigInteger; BigInteger Bigint = new BigInteger("88888999999999999999999999"); # أدخل الرقم كسلسلة نصية في حال كانت بياناتك أعداد عشرية، استخدم الصف BigDemical بنفس الطريقة السابقة: import java.math.BigDemical; BigDemical Bigdem = new BigDemical("88888999999999999999999.2123"); # أدخل الرقم كسلسلة نصية للقيام بعمليات الجمع والضرب والقسمة..إلخ.. في هذه الحالة نستخدم توابع جاهزة معرفة من أجل هذه الكلاسات مثال: /* BigInteger x = new BigInteger("1"); BigInteger y = new BigInteger("5"); الجمع يتم كالتالي BigInteger z=x.add(y); الطرح BigInteger w=x.subtract(y); الضرب BigInteger k=x.multiply(y); القسمة BigInteger k=x.divide(y); */ # مثال لتابع يحسب العاملي لعدد ما import java.math.BigInteger; public class BigNumbers { static BigInteger factorial(int m) { BigInteger x = new BigInteger("1"); for (int i = 2; i <= m; i++) x = x.multiply(BigInteger.valueOf(i)); # BigInteger.valueOf(i) هذه التعليمة لتحويل نمط المتغير return x; } public static void main(String args[]) { System.out.println(factorial(50)); } }
- 2 اجابة
-
- 1
-
-
قم بإعادة تثبيت النظام .. إذا لم ينجح الأمر فغالباً المشكلة في الأسلاك الداخلية لجهازك
-
جهازك لايفي بالمتطلبات اللازمة لتشغيل البرنامج ... البرنامج يحتاج ذاكرة وصول عشوائي 4GB ونظام Windows10 ومتطلبات أخرى يمكنك مراجعتها بالبحث عن ذلك.
- 1 جواب
-
- 1
-
-
يجب أن يتم تحويل نوع العمود ل datatime لكي تستطيع القيام بعملية الترتيب التحويل يتم كالتالي: import pandas as pd df['Birthday']=pd.to_datatime(df['Birthday'])
- 3 اجابة
-
- 1
-
-
مانوع العمود ؟
-
يجب تقسيم الملف ثم حفظه في أكثر من sheet ضمن ملف اكسيل واحد، لأن حجم الملف كبير وبالنسبة لملفات اكسل فإن اعلى حد للتخزين هو 1048576، الكود التالي يحل كل مشكلتك: # قسم الملف لأكثر من قسم 4 أقسام مثلاً nr=r.shape[0]//4 r1=r.iloc[:nr][:] r2=r.iloc[nr:2*nr][:] r3=r.iloc[nr*2:3*nr][:] r4=r.iloc[3*nr:][:] # تخزين الأقسام writer.book.use_zip64() n=input("enter new file name\n") writer = pd.ExcelWriter('{}.xlsx'.format(n), engine='xlsxwriter',options={'strings_to_urls': False}) r1.to_excel(writer, 'Sheet1') r2.to_excel(writer, 'Sheet2') r3.to_excel(writer, 'Sheet3') r4.to_excel(writer, 'Sheet4') writer.save()
- 2 اجابة
-
- 1
-
-
لجعل الكلاس يرث من كلاس آخر, نضع بعد إسم الكلاس قوسين و بداخلهما إسم الكلاس الذي نريده أن يرث منه. في حال كان الكلاس يرث من أكثر من كلاس, يجب وضع فاصلة بين كل كلاسَين نضعهما بين القوسين. تريدين صف ابن يسمى Student سنجعله يرث الصف Person كالتالي: # تعريف الصف الأب class Person: def __init__(self,ID,name,age): self.ID=ID self.name=name self.age=age # تعريف الصف الابن الذي يمثل طالب class Student(Person): def __init__(self,ID,name,age,degree1,degree2,degree3): self.degree1=degree1 self.degree2=degree2 self.degree3=degree3 Person.__init__(self,ID, name, age) # نقوم باستدعاء باني الصف الاب داخل باني الصف الابن def calc_Gpa(self): return (self.degree1+self.degree2+self.degree3)/3 # حساب معدل الطالب في المواد الثلاثة def get_info(self): print("ID :"+str(self.ID)+'\n'+"Name : "+str(self.name)+'\n'+"Age :"+str(self.age)) # اختبار ماقمنا به Leen = Student(55,'Leen',20,100,90,85) print(Leen.calc_Gpa()) print(Leen.get_info())
- 3 اجابة
-
- 3
-
-
هناك أسئلة مشابهة لهذا السؤال على الموقع وتمت الإجابة عليها.. يمكنك الرجوع لها
- 1 جواب
-
- 2
-