Ali Haidar Ahmad
-
المساهمات
1068 -
تاريخ الانضمام
-
تاريخ آخر زيارة
-
عدد الأيام التي تصدر بها
43
نوع المحتوى
ريادة الأعمال
البرمجة
التصميم
DevOps
التسويق والمبيعات
العمل الحر
البرامج والتطبيقات
آخر التحديثات
قصص نجاح
أسئلة وأجوبة
كتب
دورات
كل منشورات العضو Ali Haidar Ahmad
-
لحذف موديول من Node.js: npm uninstall <module_name> هذا الأمر سيقوم بحذف الموديول من المجلد node_modules ولكن لن يتم حذفه من package.json. لذا إذا أردنا حذفه من هناك أيضاً: npm uninstall <module_name> --save في بعض الحالات قد تضطر إلى كتابة المسار كامل أي: npm uninstall /full/path/to/node_modules/module-name في بعض الحالات قد لاتعمل معك الحلول السابقة، لذا يمكنك استخدام ال : # بفرض قمت بتنزيل الحزمة بالشكل التالي npm install @ngtools/webpack@latest # لحذفها npm uninstall @ngtools/webpack@latest # وإذا لم ينجح npm uninstall @ngtools/webpack
-
يمكنك استخدام المكتبة fs للقيام بعمليات القراءة والكتابة: const fs = require('fs'); // القراءة let rawdata = fs.readFileSync('file.json'); let punishments= JSON.parse(rawdata); console.log(punishments); //json للتشييك على محتويات ملف ال punishments الآن يمكنك استخدام المتغير أيضاً يمكنك تغيير محتويات الملف (الموجودة حالياً في المتغيرpunishments): // الكتابة let data = JSON.stringify(punishments); fs.writeFileSync('file.json', data); الكود الكامل: const fs = require('fs'); // read let rawdata = fs.readFileSync('file.json'); let punishments= JSON.parse(rawdata); console.log(punishments); // write let data = JSON.stringify(punishments); fs.writeFileSync('file.json', data);
-
قم بفتح ال PowerShell ك administrator ثم نفذ الأمر التالي: npm i -g npm أو من خلال الأمر التالي لتحديث إلى أحدث إصدار: npm install npm@latest -g ويمكنك التحقق من ذلك من خلال npm -v
-
 تماماً كما أوضح سامح. وفي Flask أو أي مكان تستخدم فيه psycopg2 تحتاج فقط إلى التعليمات التالية وسينجح الأمر غالباً: curs = conn.cursor() curs.execute("ROLLBACK") conn.commit()
تماماً كما أوضح سامح. وفي Flask أو أي مكان تستخدم فيه psycopg2 تحتاج فقط إلى التعليمات التالية وسينجح الأمر غالباً: curs = conn.cursor() curs.execute("ROLLBACK") conn.commit()- 2 اجابة
-
- 1
-

-
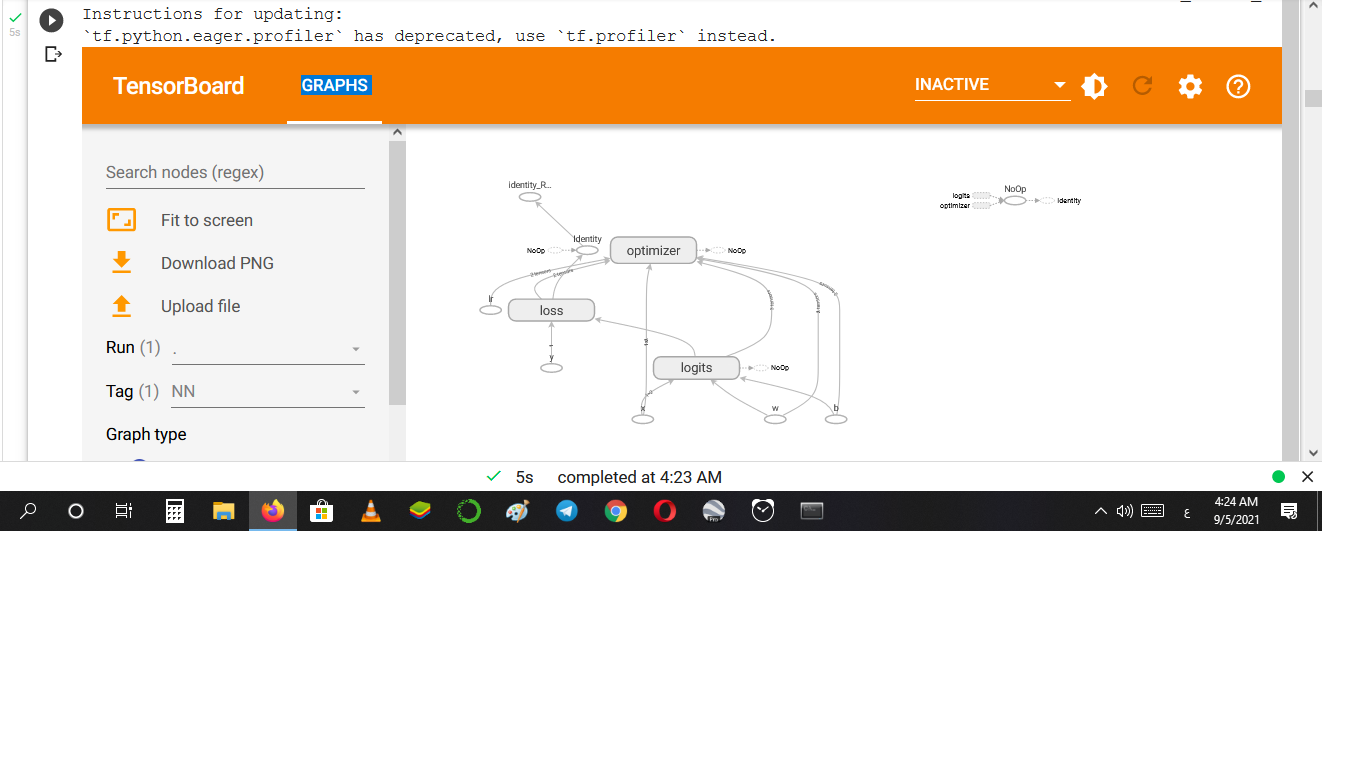
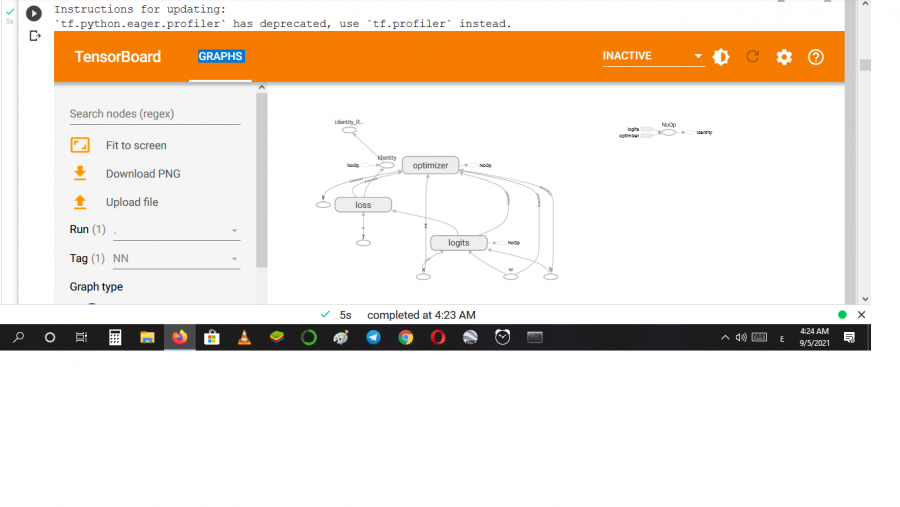
إذا كنت تريد إجراء تحليل خاص فهنا يجب أن تذهب إلى الدالة tf.train.summary_iterator وذلك لمرور (looping) على كل المخازن المؤقتة للبروتوكول tf.Event و tf.Summary في السجل: for summary in tf.train.summary_iterator("/path/to/log/file"): # نفذ تحليلاتك هنا في تنسرفلو 2 استوردها بالشكل التالي فقد تغير موقعها: from tensorflow.python.summary.summary_iterator import summary_iterator يمكنك استخدام TensorBoard فهي أداة رائعة توفرها تنسرفلو لعرض البيانات والسجلات (summary logs). لكن
-
بداية أود أن ألفت الانتباه إلى الكتاب "Clean Code: A Handbook of agile software craftsmanship" فهو المصدر لأغلب ماسنتناوله الآن: الكود الرديء يعني حرفياً خسارة آلاف الزوار والمغامرة بحركة البيع والشراء والإيرادات وحتى في مسيرة تطور الموقع الإلكتروني والشركة ككل. لهذا لا تقبل الشركات الكبيرة التعامل مع المبتدئين، لأنها تعرف أن التأخير الزمني في فتح صفحة الويب، ليس لثوان معدودة بل لأجزاء من الثانية، تعني خسارة زبون، وخسارة زبون واحد تعني خسارة آلاف الزبائن المحتملين وفق التسلسل الهرمي، وهذا يعني خسارة نسبية في الأرباح السنوية تصل إلى آلاف الدولارات، لذا عليك كتابة أكواد برمجية مفهومة للجميع دون الحاجة إلى تقديم التوضيحات والشروحات لأحد الزملاء إلّا فيما ندر. وليس هذا فحسب حيث تفكر الشركات لأبعد من هذا بكثير، فمن الممكن أن تترك أنت مهمة ما في منتصفها ويتولاها آخر بشكل مفاجئ، ومن الممكن أن تتولى أنت مهمة شخص آخر في العمل، أو أن تترك العمل في تلك الشركة بلا عودة، وهنا نفهم من هذا السيناريو أن الأكواد المبهمة والغامضة مرفوضةٌ تماماً في بيئة العمل حتى يتسنّى لباقي المطوّرين العمل على تطوير المشروع ومتابعة العمل بسلاسة دون الحاجة لساعات من البحث والعمل على فك الشيفرة. لا يقتصر الأمر على الإيضاح فحسب، وإنما على طريقة الكتابة، واستخدام أحدث الأساليب في لغة البرمجة التي تعمل عليها، أو على الأقل الاتفاق بين رفقاء العمل على التعليمات البرمجية التي توافق مجال العمل، لا يمكنك على سبيل المثال كتابة كود برمجي بـ 10 أسطر ويمكنك كتابته بـ 5 أو بـ 8 حتى وذلك باستخدام تعليمات أحدث أو أفضل. يمكننا سرد بعض الخصائص العامة للأكواد النظيفة وتلخيصها بالنقاط التالية: 1.عدد متغيرات أقل ما يمكن ولا يختلف اثنان على ضرورة تخفيض عدد المتغيرات والدوال والـ classes… إلخ، للوصول إلى كود أسهل وذي أفكار أبسط. 2. عدم التكرار وهذا شيء معروف عند الجميع، علينا أن نلغي كل الأسطر المتفرقة التي تؤدي نفس المهمة، ونحاول جمعها في سطر واحد أو في دالة واحدة نستدعيها عند اللزوم. 3. اجتياز كافة الاختبارات: هناك بيئات عمل معروفة أو ما تسمى Test-driven development TDD لاختبار الأكواد البرمجية، وهي عبارة عن أكواد برمجية عادية تقوم بفحص الكود البرمجي والهدف منها هو وضع معايير عامة للمشروع. 4. وضوح الهدف والبساطة: يجب أن تكون مهمة كل دالة واضحة، وألا تتشعب فيها المهام لأداء كثير من الأفكار فإن كانت دالة ما لها وظيفة عداد على سبيل المثال، فلا يجب تضمين مهام أخرى فيها حتى لو كانت الأمور تسير بدون أخطاء وهذا ينطبق على الكود ككل. 5.المحافظة على السياق: إذا كتبت دالة ما باستخدام طريقة ما، وكان عليك كتابة دالة مشابهة ولكن لغرض آخر، فاستخدم نفس الطريقة التي استخدمتها في الدالة الأولى. إن كنت ترغب بكتابة كود نظيف Clean Code التزم الخطوات التالية: 1. اجعل الأسماء ذات معنى: يجب أن تكون أسماء المتغيرات والدوال وكل شيء في الكود البرمجي يشير إلى عمله، فالمتغير الذي يعبر عن سيارة يجب أن يكون اسمه car وليس x، وإن كنت تريد إنشاء دالة تقوم بالعد فسمها count وليس c مثلاً. 2. لا تستخدم الاختصارات: وكما قلنا عن وجوب استخدام الأسماء المعبرة، فبالتأكيد يجب عدم استخدام الاختصارات، يجب أن يكون الكود مقروء للجميع، فمتغير اسمه name لا يجب أن يُختصر إلى nm، ومتغير اسمه lastName لا يجب أن يُختصر إلى ln. 3.اختر الأسماء البسيطة: هذا الأمر بديهي، إلا أنك قد تشعر بالحيرة بعض الأحيان عند تسمية بعض الدوال، وستتخلص من هذه الحيرة إذا اتبعت قاعدة المَهمّة الواحدة للدالة . لا تستخدم مهاراتك اللغوية في كتابة الأسماء، فدالة وظيفتها الحذف يمكن تسميتها بكل بساطة delete وليس kill. 4. طريقة التسمية: اختر صيغة الفعل لتسمية الدوال أي بدلاً من taxCalculator قم بتسميتها calculateTax، أما فيما يتعلّق بتسمية classes فعلى العكس أي استخدم معها صيغة الوصف أو الاسم بدلاً من الفعل. 5.كما لا تنس القواعد المعروفة باستخدام أسلوب camelCase في التسمية المركبة والتي تبدأ فيها أول كلمة بحرف صغير والكلمة الثانية بحرف كبير وذلك لسهولة القراءة. كما يجب أن تبدأ التسمية بحرف صغير للدوال والمتغيرات بشكل عام، أما classes فيجب أن تبدأ بحرف كبير. 5.التعليقات: ومع أني أحب كتابة التعليقات، إلا أن قواعد الكود النظيف تقول أنه يجب أن يشرح نفسه بنفسه وهو لا يحتاج إلى التعليقات مطلقاً! بل وعلى العكس لو كان الكود مفهوماً فما احتاج إلى تعليقات بالأصل! طبعاً باستثناء التعليقات حول حقوق التأليف والاستخدام أو التعريف بالبرنامج ككل.6.الدوال: حاول أن تتصف الدوال بالصفات التالية: ذات حجم صغير. حاول أن لا يكون طول الدالة أكثر من 10 أو 15 أو 20 سطراً هذه أمثلة عليك جعلها أقصر ما يمكن. ذات اسم معبر عن مهمتها. 7. عدد الـ arguments أقل ما يمكن. ثلاثة على الأكثر، وإلا عليك التفكير بكتابتها على شكل class. لها مهمة واحدة محدد. حاول أن يكون للدالة مهمة واحدة حتى يستطيع الأصدقاء فهم ما يحصل. 8. اجعل الأسطر قصيرة قدر الإمكان ولا تجعل القارئ مضطراً لتمرير النافذة أفقياً ليقرأ سطراً طويلاً. .9. في الحقيقة الموضوع يطول ويطول وتبقى الخطوات السابقة جزءاً من كم لا بأس به من القواعد العامة لكتابة الكود النظيف، ربما ستتعلمها بشكل عملي من المجتمع الخاص بلغة البرمجة التي تعمل بها ولكن كبداية يمكنك الاستعانة بكتاب Clean Code: A Handbook of agile software craftsmanship الذي يعتبر أحد أبرز الكتب في هذا المجال.
-
يتم استخدام كل من var و let للإعلان عن المتغير في جافا سكريبت ولكن الاختلاف بينهما هو أن var عبارة عن دالة ذات نطاق مفتوح و let يتم تحديد نطاقها. يمكن القول أن المتغير الذي تم التصريح به باستخدام var يتم تعريفه في جميع أنحاء البرنامج مقارنةً بـ let. مثال سيوضح الفرق بشكل أفضل: مثال عن let: Input: console.log(x); let x=5; console.log(x); Output: Error مثال عن var: Input: console.log(x); var x=5; console.log(x); Output: undefined 5 المتغيرات let لها مناطق ميتة مؤقتة بينما المتغيرات var ليست كذلك. لفهم المنطقة الميتة الزمنية ، دعنا نفحص دورات حياة كل من متغيري var و let ، والتي لها خطوتان: الإنشاء والتنفيذ. أولاً var: في مرحلة الإنشاء ، يقوم محرك JavaScript بتعيين مساحات تخزين لمتغيرات مختلفة ويقوم على الفور بتهيئتها إلى غير محددة. وفي مرحلة التنفيذ ، يخصص محرك JavaScript للمتغيرات var القيم المحددة بواسطة التخصيصات إذا كانت موجودة. خلاف ذلك ، تظل المتغيرات var غير محددة. أما let ففي مرحلة الإنشاء ، يقوم محرك JavaScript بتعيين مساحات تخزين لمتغيرات let ولكن لا يقوم بتهيئة المتغيرات. ستؤدي الإشارة إلى المتغيرات غير المهيأة إلى حدوث خطأ في ReferenceError. المتغيرات let لها نفس مرحلة التنفيذ مثل المتغيرات var. تبدأ المنطقة الميتة الزمنية The temporal dead zoneمن الكتلة حتى تتم معالجة إعلان المتغير Let . بمعنى آخر ، إنه يكون ذلك الموقع حيث لا يمكنك الوصول إلى متغيرات let قبل تحديدها.
-
حسب التوثيق "في TensorFlow ، يكون للتنسر shape ستاتيكي (مستدل) وشكل ديناميكي (حقيقي). يمكن معرفة ال shape الستاتيكي باستخدام الدالة tf.Tensor.get_shape: يُستدل على هذا ال shape من العمليات التي تم استخدامها لإنشاء هذا التنسر، وقد يكون مكتملًا جزئياً. إذا لم يتم تحديد ال shape الستاتيكي بالكامل، فيمكن تحديد الشكل الديناميكي لـ Tensor t من خلال tf.shape (t)." حسناً ربما لم تفهم شيئ. تابع معي.. في بعض الأحيان ، يعتمد شكل التنسر على قيمة يتم حسابها في زمن التنفيذ. لنأخذ المثال التالي ، يحيث x هو متجه tf.placeholder بأربعة عناصر: x = tf.placeholder(tf.int32, shape=[4]) x.get_shape() # (4,) خرج x.get_shape يمثل ال shape الستاتيكي لـ x ، وتعني (4 ،) أنه متجه بطول 4. الآن دعنا نطبق العملية التالية على x: y, _ = tf.unique(x) y.get_shape() # (?,) (؟ ،) تعني أن y متجه بطول غير معروف. لماذا هو مجهول؟ تُرجع tf.unique (x) القيم الفريدة من x ، وقيم x غير معروفة لأنها tf.placeholder ، لذلك لا تحتوي على قيمة حتى تقوم بإدخالها. الآن في حالة قمت بإدخال قيمتين مختلفتين: sess = tf.Session() sess.run(y, feed_dict={x: [0, 1, 2, 3]}).shape # (4,) sess.run(y, feed_dict={x: [0, 0, 0, 0]}).shape # (1,) إذاً الموتر يمكن أن يكون له شكل ستاتيكي وديناميكي مختلفين. دائماً ما يكون الشكل الديناميكي محدداً تماماً (ليس لها أبعاد وهذا مايشار له ب "؟") لكن الشكل الستاتيكي يمكن أن يكون أقل تحديداً. وهذا ما يسمح لـ TensorFlow بدعم عمليات مثل tf.unique و tf.dynamic_partition، والتي يمكن أن تحتوي على مخرجات متغيرة الحجم ، وتستخدم في التطبيقات المتقدمة. الآن اعتقد أن كل شيء واضح والأبعاد التي تبحث عنها أنت هي الأبعاد الستاتيكية لذا استخدم الدالة get_shape
- 1 جواب
-
- 1
-
-
إليك ماتحتاجه، أضفت طريقتين للقيام بالمهمة من دون استخدام توابع باندا (توابع باندا دوماً أقل كفاءة من ناحية الأداء): df = pd.DataFrame({'col':list('abccbac')}) df """ col 0 a 1 b 2 c 3 c 4 b 5 a 6 c """ #pivot_table ألطريقة الأولى هي استخدام الدالة df.pivot_table(index = ['col'], aggfunc ='size') """ col a 2 b 2 c 3 dtype: int64 """ #Counter يمكنك أيضاً استخدام from collections import Counter Counter(list(df['col'])) # Counter({'a': 2, 'b': 2, 'c': 3}) #لمعرفة عدد مرات تكرار عنصر معين operator يمكنك أيضاً استخدام import operator operator.countOf(list(df['col']), "a") # 2
- 2 اجابة
-
- 1
-
-
كما أشار أحمد. وفي حالة كان لدينا مستويين للفهرس أي حالة MultiIndex: import pandas as pd import numpy as np index = pd.MultiIndex.from_product([['TX', 'FL', 'CA'], ['North', 'South']], names=['State', 'Direction']) df = pd.DataFrame(index=index, data=np.random.randint(0, 10, (6,4)), columns=list('abcd')) """ a b c d State Direction TX North 5 7 1 0 South 1 5 7 4 FL North 2 8 1 7 South 5 9 4 0 CA North 0 8 9 0 South 5 7 9 4 """ df.reset_index() """ State Direction a b c d 0 TX North 6 6 2 5 1 TX South 9 1 0 4 2 FL North 2 6 1 4 3 FL South 6 7 6 3 4 CA North 3 3 5 8 5 CA South 7 3 8 1 """ """ #level استخدم المعامل للتحكم في مستويات الفهرس التي يتم تحويلها إلى أعمدة. إذا لم تكن هناك أسماء مستويات ، يمكنك الرجوع إلى كل مستوى من خلال موقعه الصحيح ، والذي يبدأ عند 0 من الخارج. يمكنك استخدام قيمة عددية هنا أو قائمة بجميع الفهارس التي ترغب في إعادة تعيينها. """ df.reset_index(level='State') # نفسها df.reset_index(level=0) """ State a b c d Direction North TX 1 4 2 0 South TX 1 2 8 2 North FL 8 1 9 1 South FL 1 9 6 1 North CA 9 5 5 2 South CA 3 4 6 0 """ """ في بعض الحالات عندما تريد الاحتفاظ بالفهرس وتحويله إلى عمود ، يمكنك القيام بما يلي """ # من أجل مستوى واحد df.assign(State=df.index.get_level_values('State')) """ a b c d State State Direction TX North 2 0 3 6 TX South 2 1 0 0 TX FL North 1 7 4 4 FL South 1 2 7 9 FL CA North 0 0 9 8 CA South 8 8 8 7 CA """ # من أجل كل المستويات df.assign(**df.index.to_frame()) """ a b c d State Direction State Direction TX North 8 7 6 9 TX North South 6 3 1 3 TX South FL North 1 9 2 8 FL North South 4 4 1 7 FL South CA North 8 4 0 7 CA North South 9 8 5 0 CA South """ وفي الحالة العادية يمكنك استخدام الدالة insert أيضاً: import pandas as pd df = pd.DataFrame({'Roll Number': ['20CSE29', '20CSE49'], 'Name': ['Amelia', 'Sam'], 'Subject': ['Physics', 'Physics']}) df """ Roll Number Name Subject 0 20CSE29 Amelia Physics 1 20CSE49 Sam Physics """ #insert استخدام الدالة df.insert( 0, column="new",value = df.index.values) df """ new Roll Number Name Subject 0 0 20CSE29 Amelia Physics 1 1 20CSE49 Sam Physics """
-
للتحقق من المستخدمين المصادق عليهم ضمن القالب الخاص بك، فقم بما يلي: {% if user.is_authenticated %} <p>user</p> {% else %} <!-- شيئ ما تريد فعله مع مستخدم غير مصدق عليه --> {% endif %} # أو #else بدون {% if user.is_authenticated %} <p>{{ user }}</p> {% endif %} #decorator في وظائف التحكم الخاصة بك أضف from django.contrib.auth.decorators import login_required @login_required def privateFunction(request):
- 2 اجابة
-
- 1
-
-
قد تكون المشكلة إما بالصف الأول من البيانات كما أشار أحمد، أو بالمحددات delimiters. لذا لحل المشكلة قم باستخدام الوسيط sep و/أو الوسيط header مع الدالة read_csv. بالنسبة ل sep فالتوثيق يقول"إذا كان sep = None [ أي غير محدد] ، فسيحاول باندا تحديده تلقائياً." أي عدم تحديده لن يسبب مشكلة (ومع ذلك في الممارسة العملية تنتج أخطاء مع البعض لذا يفضل تحديده إذا حدث خطأ). أما بالنسبة لل header تقول المستندات في باندا ""إذا كان الملف لا يحتوي على صف header، فيجب عليك تمرير header = None" بشكل صريح. ,في هذه الحالة، يقوم باندا تلقائياً بإنشاء فهارس لكل حقل {0،1،2، ...}." مثلاً: df = pd.read_csv(path, sep='delimiter', header=None) # sep :delimiter تقوم من خلالها بتعريف المحدد # header=None: لإخبار باندا بأن بياناتك لا تحتوي على صف لعناوين الرؤوس / الأعمدة كما يمكنك استخدام الحلول التي أشار لها أحمد بالنسبة لل header
- 3 اجابة
-
- 1
-
-
إضافة لإجابة سامح الرئعة يمكنك إنشاء دالة للقيام بهذه المهمة: def chk(model, **kwargs): try: return model.objects.get(**kwargs) except model.DoesNotExist: return None # واستخدمها بالشكل التالي get = chk(Content,role="writer") #في حالة عدم التطابق None القيمة get ستعيد #Content وإلا ستعيد ال # MultipleObjectsReturned سيعيد الاستثناء #role="writer" إذا تم إرجاع أكثر من إدخال واحد ل # لذا يجب التقاط هذا الاستثناء لكي لايتسبب بمشاكل def chk(model, **kwargs): try: return model.objects.get(**kwargs) except model.MultipleObjectsReturned as e: print(e) except model.DoesNotExist: return None كذلك هناك الدالة get_object_or_None من الموديول annoying.functions : from annoying.functions import get_object_or_None as get #.... go = get(Content, role="writer")
- 2 اجابة
-
- 1
-
-
الغراف يبقى عبارة عن كود ليس له أي مساحة في الذاكرة أو أي موارد أي مجرد تعليمات إلى أن يتم بناؤه من خلال ال Session. لذا توقعك في مكانه فلايمكننا استخدام if منطقياً هنا (وليس قواعدياً)، لأن الشرط سيتم تقييمه عند بناء الغراف بينما أنت تريد أن يعتمد الشرط على القيمة التي يتم تغذيتها للعنصر النائب placeholder في زمن التشغيل runtime. لذا فاستخدامك ل if هنا سيؤدي دوماً لاختيار الفرع الأول ل if لأن الشرط الخاص بك سيتم تقييمه على tensor أي 0<tensor أي دوماً True. لذا توفر لنا تنسرفلو الدالة tf.cond للقيام بهذا الأمر بالشكل الصحيح كمايلي. حيث يقوم بتقييم أحد فرعين، اعتماداً على الحالة المنطقية. لتوضيح كيفية استخدامه، سأعيد كتابة الكود: data = tensorflow.placeholder(shape=[None, ins_size**2*3]) wights = tensorflow.Variable(tensorflow.zeros([ins_size**2*3,label_option])) bias = tensorflow.Variable(tensorflow.zeros([label_option])) yourcond=tensorflow.placeholder(shape=[1, 1]) #lambda نمرر لها الشرط والفرعين من خلال pred = tensorflow.cond(yourcond > 0, lambda: tensorflow.matmul(data, wights) + bias, tensorflow.matmul(data, wights) - bias)
- 1 جواب
-
- 1
-
-
حسناً إضافة للطرق السابقة إليك طرق إضافية (أنصح بشدة باستخدام vectorize التي ذكرتها @Reem Elmahdiإذا كنت مهتماً بالسرعة): import pandas as pd # إنشاء داتا لنعمل عليها df =pd.DataFrame( {'Name':['Jai', 'Princi', 'Gaurav', 'Anuj'], 'Age':[27, 24, 22, 32], 'Address':['Delhi', 'Kanpur', 'Allahabad', 'Kannauj'], 'Qualification':['Msc', 'MA', 'MCA', 'Phd']}) df """ Name Age Address Qualification 0 Jai 27 Delhi Msc 1 Princi 24 Kanpur MA 2 Gaurav 22 Allahabad MCA 3 Anuj 32 Kannauj Phd """ # str.find أول طريقة لنستخدم التابع # a مثلاً نريد البحث عن الأماكن التي توجد بها المحرف # يعيد هذا التابع الفهرس الأول الذي تواجدت فيه بداية السلسلة الجزئية التي تبحث عنها sub ='a' df["Indexes"]= df["Name"].str.find(sub) df """ Name Age Address Qualification Indexes 0 Jai 27 Delhi Msc 1 1 Princi 24 Kanpur MA -1 2 Gaurav 22 Allahabad MCA 1 3 Anuj 32 Kannauj Phd -1 """ # findall الطريقة الثانية هي استخدام #re وذلك من خلال مكتبة # هذه الطريقة تمكنك من البحث يطريقة فعالة وسهلة حيث أنك فقط تحدد لها ماتريد البحث عنه import re #ci أو ai هنا نحدد أننا نريد جميع الكلمات التي تحوي df['Name'].str.findall('ci|ai', flags=re.IGNORECASE) # هنا قمت بتجاهل حالة الأحرف ويمكنك أن لاتتجاهلها حسبما تريد # إليك التابع التالي الذي قمت بتعريفه لك بحيث يسهل عليك عملية البحث عن أي سلسلة جزئية وهو حل فعال جداً من ناحية الأداء #regex وذلك لأنني اعتمدت فيهاستخدام مكتبة التعابير المنتظمة def stringSearchColumn_DataFrame(df, colName, regex): newdf = pd.DataFrame() for idx, record in df[colName].iteritems(): if re.search(regex, record): newdf = pd.concat([df[df[colName] == record], newdf], ignore_index=True) return newdf stringSearchColumn_DataFrame(df,"Name","ai") """ Name Age Address Qualification Indexes 0 Jai 27 Delhi Msc 1 """ stringSearchColumn_DataFrame(df,"Name","ai|ci") """ Name Age Address Qualification 0 Princi 24 Kanpur MA 1 Jai 27 Delhi Msc """ # هذا مريح أكثر أليس كذلك؟؟
- 4 اجابة
-
- 1
-
-
يمكنك حل المشكلة بالشكل التالي: push(`${asPath.split('?')[0]}?comp=${id}`); // أو إذا كنت تريد دالة قابلة لإعادة الاستخدام function delQuery(asPath) { return asPath.split('?')[0] } .. .. const {push, asPath} = useRouter() push(`${delQuery(asPath)}?comp=${id}`); كما يمكنك استخدام history.replaceState لكن قد : if (typeof window !== "undefined") { window.history.replaceState(null, '', '/about') }
-
يجب عليك إنشاء ارتباط رمزي (ملف اختصار) "symlink" أو كما يسمى أيضاً "link soft" ضمن ال bin بشكل يدوي: sudo ln -s `which nodejs` /usr/bin/node #غير قياسية shells وإذاكنت تستخدم #node.js للمسار الذي تجد به Hardcoding قم ب sudo ln -s /usr/bin/nodejs /usr/bin/node # Hardcoding: أي استخدام اسم صريح بدلاً من اسم رمزي لشيء من المحتمل أن يتغير في وقت لاحق لحل المشكلة قم بتنقيذ الأوامر التالية: sudo apt-get --purge remove node sudo apt-get --purge remove nodejs sudo apt-get install nodejs أو: sudo update-alternatives --install /usr/bin/node node /usr/bin/nodejs 10 عبر npm أو nvm ، يُطلق على Node.js اسم node ولكن إذا قمت بالتثبيت عبر apt-get ، فأنت بحاجة إلى استخدام اسم الحزمة nodejs لأنه من خلال apt-get ، يكون اسم الحزمة مأخوذاً بواسطة تطبيق مختلف تماماً ويسمى أيضاً node.
-
نعم بالتأكيد يمكنك ترقيته طالما أن المعالج ب 64 بت. فقط عليك أن تقوم بتحديث النظام إلى نسخة تتعامل مع ال 64 بت. أما إذا كان 32 بت فبالطبع لايمكنك. لكن جهازك يدعم ال 64 بت إذاً يمكنك أن تقوم بتنزيل نظام يعمل على 64 بت عند أي مركز صيانة للأجهزة.
- 5 اجابة
-
- 1
-
-
يمكننا القيام بذلك من خلال التعليمة التالية: %tensorboard --logdir logs/train لكن يجب أولاً أن نقوم بتحميل الإضافة: %load_ext tensorboard.notebook أو في حال ظهر لديك الخطأ التالي: RuntimeError: Use '%load_ext tensorboard' instead of '%load_ext tensorboard.notebook'. قم باستخدام: %load_ext tensorboard.notebook مثال: %load_ext tensorboard.notebook import tensorflow as tf import numpy as np logdir = 'logs/' writer = tf.summary.create_file_writer(logdir) tf.summary.trace_on(graph=True, profiler=True) @tf.function def forward_and_backward(x, y, w, b, lr=tf.constant(0.01)): with tf.name_scope('logits'): logits = tf.matmul(x, w) + b with tf.name_scope('loss'): loss_fn = tf.nn.sparse_softmax_cross_entropy_with_logits( labels=y, logits=logits) reduced = tf.reduce_sum(loss_fn) with tf.name_scope('optimizer'): grads = tf.gradients(reduced, [w, b]) _ = [x.assign(x - g*lr) for g, x in zip(grads, [w, b])] return reduced # الدخل x = tf.convert_to_tensor(np.ones([1, 2]), dtype=tf.float32) y = tf.convert_to_tensor(np.array([1])) # params w = tf.Variable(tf.random.normal([2, 2]), dtype=tf.float32) b = tf.Variable(tf.zeros([1, 2]), dtype=tf.float32) loss_val = forward_and_backward(x, y, w, b) with writer.as_default(): tf.summary.trace_export( name='NN', step=0, profiler_outdir=logdir) %tensorboard --logdir logs/ الخرج:
- 1 جواب
-
- 1
-
-
لفرق بين هاتين الفئتين هو: فئة container هي ذات العرض الثابت. هذا لا يعني أنه لا يستجيب. إنه متجاوب. ومع ذلك ، تم إصلاحه بناءً على حجم الشاشة. تشمل أحجام الشاشة: Xs للأجهزة الصغيرة جداً (تستخدم لأقل من 768 مثل الهواتف الذكية والجوال وما إلى ذلك). Sm للشاشات الصغيرة (من 768 بكسل وما فوق على سبيل المثال الأجهزة اللوحية). Md للشاشة المتوسطة (> = 992 بكسل. أجهزة الكمبيوتر المكتبية / أجهزة الكمبيوتر المحمولة). Lg للشاشات الكبيرة (> = 1200. بكسل مثل أجهزة الكمبيوتر المكتبية الكبيرة). إذا كنت تستخدم فئة ال container والتحقق من صفحة الويب في المتصفح ، فسيتم ضبطها وفقاً للشاشة وحجم المتصفح. على سبيل المثال، إذا كان عرض متصفحك الحالي يزيد عن 1200، فسيتم ضبطه على 1170 بكسل. إذا قمت بتغيير حجم المتصفح إلى حجم صغير ، فسيظل كما هو حتى يصل إلى 992 بكسل. وفي هذه المرحلة سيتم ضبط فئة ال container على 970 بكسل. (من الناحية التقنية يمكننا القول إنه "عرض ثابت" لأن قيم البكسل محددة). من ناحية أخرى ، ستأخذ فئة ال container-fluid العرض (width) الكامل لإطار العرض (حجم نافذة المتصفح). وإذا كنت تستخدم container-fluid وقمت بتغيير حجم نافذة المتصفح، فقد تلاحظ أن المحتوى الموجود بداخله سيتم ضبطه مع كل بكسل لأخذ العرض المتاح بالكامل (أي دوماً سيكون 100% من حجمه). وبالتالي يكون العرض width مرتبط بعرض منفذ العرض (عرض نافذة المتصفح)، وبالتالي تكون الشاشة ديناميكية. وبالتالي نستنتج أنها مفيدة أكثر في حالة أردت تغيير شكل صفحتك مع كل اختلاف بسيط في حجم منفذ العرض الخاص بها. بينما نستخدم الcontainer عندما تريد تغيير شكل صفحتك إلى 5 أنواع فقط من الأحجام ، والتي تُعرف أيضاً باسم "نقاط التوقف".
- 3 اجابة
-
- 1
-
-
يمكنك أيضاً استخدام npm كالتالي: var daemon = require('daemon'); daemon.daemonize({ stdout: './log.log' , stderr: './log.error.log' } , './node.pid' , function (err, pid) { if (err) { console.log('Error starting daemon: \n', err); return process.exit(-1); } console.log('Daemonized successfully with pid: ' + pid); // تطبيقك هنا });
-
engineStrict تم إهمالها على ما اعتقد لذا يمكنك القيام بالتالي: # معرفة النسخة import semver from 'semver'; import { engines } from './package'; const version = engines.node; if (!semver.satisfies(process.version, version)) { console.log(`Required node version ${version} not satisfied with current version ${process.version}.`); process.exit(1); } # package.json: { "name": "my package", "engines": { "node": ">=50.9" // intentionally so big version number }, "scripts": { "requirements-check": "babel-node check-version.js", "postinstall": "npm run requirements-check" } } #.nvmrc ثم إنشاء ملف
-
إضافة إلى الطرق التي ذكرها سامح، يمكنك القيام بذلك كالتالي: import os, django os.environ.setdefault("DJANGO_SETTINGS_MODULE", "app.settings") django.setup() # الآن يمكن أن تضع الكود هنا... وهذه الطريقة تجنبك حدوث بعض الاستثناءات مثل django.core.AppRegistryNoReady أو: import sys, os sys.path.append('/path/to/your/django/app') os.environ['DJANGO_SETTINGS_MODULE'] = 'settings' from django.conf import settings # أضف ماتريده بعدها
- 2 اجابة
-
- 1
-
-
كما أشار أحمد يمكنك استخدام Apply لكن أنصح دوماً بالاعتماد على طرق أخرى لأن هذه الطرق بطيئة، لذا يمكن أن نقوم بالأمر من خلال الدالة vectorize التي ستعطيك فرق كبير للغاية بالسرعة كالتالي: import pandas as pd # تعرف داتا فريم لنختبر عليه df = pd.DataFrame({'ID':['1', '2', '3'], 'col1': [0, 1, 2], 'col2':[3, 4, 5]}) df """ ID col1 col2 0 1 0 3 1 2 1 4 2 3 2 5 """ # نعرف تابع لنختبر عليه def f(x,y): return x+y import numpy as np # نقوم بتطبيق التابع على عمودي البيانات df.loc[:,'result'] = np.vectorize(f) (df['col1'], df['col2']) df """ ID col1 col2 result 0 1 0 3 3 1 2 1 4 5 2 3 2 5 7 """ كذلك كان بإمكانك استخدام الدالة apply: df['col_3'] = df.apply(lambda x: f(x.col1, x.col2), axis=1) df """ ID col1 col2 col_3 0 1 0 3 3 1 2 1 4 5 2 3 2 5 7 """ وكتحسين لسرعة التنفيذ باستخدام apply يمكنك استخدام الأداة swifter: import swifter df['col_3'] = df.swifter.apply(lambda x: f(x.col1, x.col2), axis=1) للمقارنة: # توليد داتافريم بحجم كبير df1 = df.sample(100000, replace=True).reset_index(drop=True) # تطبيق نفس العملية واستخلاص زمن التنفيذ %timeit df1.apply(lambda x: f(x.col1, x.col2), axis=1) # 1 loop, best of 5: 1.84 s per loop %timeit df1.swifter.apply(lambda x: f(x.col1, x.col2), axis=1) # 100 loops, best of 5: 2.24 ms per loop %timeit np.vectorize(f) (df['col1'], df['col2']) # 10000 loops, best of 5: 62.7 µs per loop لاحظ أن apply استغرقت ثانيتين تقريباً وع التحسين swifter استغرقت 2 ونصف ميلي ثانية، لكن باستخدام vectorize استغرقت 62 ميكرو ثانية وهو فرق هائل. وهنا نتحدث عن عمليات بسيطة جداً هناك عمليات قد يتطلب تنفيذها وقت يتجاوز النصف ساعة والساعة حتى تنتهي لو استخدمنا Apply. لذا إذا كنت تفكر بالتعامل مع بيانات ضخمة ابتعد عنها.
- 3 اجابة
-
- 1
-
-
كما أشار وائل تماماً. وبالنسبة لهذا "و اذا كان الجهاز 32-bit هل هناك طريقه ليصبح 64-bit " فلا لايمكن لأننا نتحدث هنا عن معمارية المعالج.