
لوحة المتصدرين




المحتوى الأكثر حصولًا على سمعة جيدة
المحتوى الأعلى تقييمًا في 08/21/21 في كل الموقع
-
في لغة SQL ، يوجد طريقة لإختيار عناصر محددة باستخدام IN أو NOT IN وأريد تطبيق نفس الطريقة على dataframe في pandas. لدي الكود التالي: df = pd.DataFrame({'country': ['US', 'UK', 'Germany', 'China']}) countries_to_keep = ['UK', 'China'] #طريقتي df[df['country'] not in countries_to_keep] أريد إيجاد طريقة لأختبار تواجد عناصر داخل countries_to_keep حيث تكون الاجابة ب true او false, كيف يمكن فعل ذلك؟2 نقاط
-
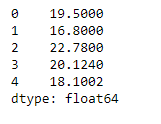
لدي بعض العناصر على شكل dataframe كالتالي: import pandas as pd sr = pd.Series([19.5, 16.8, 22.78, 20.124, 18.1002]) print(sr) أريد أن أقوم بإقتصاص جزء معين من هذه البيانات، فمثلا أريد إقتطاع البيانات التي ترميزها index أصغر من 1 وأكبر من 3. كيف يمكنني فعل ذلك؟
 2 نقاط
2 نقاط -
أحاول بناء صفحة للبحث في موقع مبني بـ جانغو Django، وفي صفحة البحث هذه، أبحث في نموذجين models مختلفة (posts و pages). وللحصول على ترقيم صفحات في صفحة نتائج البحث، أود استخدام object_list لعرض النتائج. ولكن للقيام بذلك ، يتعين عليّ دمج نتائج البحث للنموذجين معًا results = [] # قائمة نتائج البحث النهائية pages = Page.objects.filter(Q(title__icontains=term) | Q(body__icontains=term)) for x in pages: results.append(x) posts = Post.objects.filter(Q(title__icontains=term) | Q(body__icontains=term)) for x in posts: results.append(x) return object_list( request, queryset=results, template_object_name='result', paginate_by=15, extra_context={'term': term}, template_name="search/results.html") لكن الكود السابق لا يعمل.و أحصل على خطأ عندما أحاول استخدام تلك القائمة في ملفات العرض. كيف يمكنني دمج كل من pages و posts معًا؟2 نقاط
-
في نموذج QuerySets في جانغو Django، أرى أن هناك __gt و __lt لمقارنة القيم، لكن هل هناك __ne أو! = (not equals)؟ أريد تصفية النتائج باستخدام شرط لا يساوي. على سبيل المثال: Model: bool x; int y; أريد أن أقوم بـ : results = Model.objects.exclude(x=True, y!=10) لكن هذه الطريقة لم تفلح، لذلك أستخدم الكود التالي: results = Model.objects.exclude(x=True, y__lt=10).exclude(x=True, y__gt=10) لكن أعتقد أن الكود السابق ليس عملي ويسبب بطيء أثناء التنفيذ، لذلك هل توجد طريقة لعمل شرط "لا يساوي" في جانغو Django؟2 نقاط
-
السلام عليكم، في عملية الupdate للstate اقصد التعديل على محتوى معيّن.. عند الضغط على " التعديل" يجب ان يتحوّل الكلام الى input بداخله القيمة الموجودة في المحتوى.. "toggle" الذي يحدث أنني عندي اكثر من محتوى يتحول لذلك، أريد التخصيص انني فقط في هذا المحتوى اريد التعديل و شكراً لكم1 نقطة
-
عندي <li> أعرض بداخلها قيمة الاعجابات التي أقرأها من الdatabase و اضعها في state و لكن عند الضغظ على "اعجاب" يزيد اللايك في قاعدة البينات و يجب تحديث الصفحة من اجل اظهار الرقم الجديد هل هُناك حل لأُري المستخدم ان عدد الاعجاب يزيد فور ضغطه على " إعجاب" ؟1 نقطة
-
السلام عليكم هل المكتبة تقوم بمقارنة التوكن القادم من المستخدم بالذي تم ارساله له ؟ ام يجب علي حفظ التوكن المنشئ في كل مره ومقارنته بنفسي ؟ علماً اني استخدمها في spa وكيف يمكن تغيير خيارات الكوكيز في المكتبة بحيث اعدل key او httponly وغيرها.1 نقطة
-
لدي بيانات على شكل dataframe ، وأود أن أقوم بعمل دالة بحيث يتم تطبيقها على تلك البيانات كلها. على سبيل المثال عمل دالة لتحديد اذا كانت القيمة مرتفعة أو متوسطة أو منخفضة بناء على قيمة العنصر العددية، كيف يمكن عمل هذا؟1 نقطة
-
لدي نموذجان models في جانغو Django، لكل منهما مفتاح foreign key للآخر. يؤدي حذف نسخ من النماذج إلى إرجاع خطأ بسبب قيد مفتاح foreign key: cursor.execute("DELETE FROM items WHERE id = %s", id_) transaction.commit_unless_managed() # يظهر خطأ هنا بسبب foreign key هل من الممكن تعطيل القيود مؤقتًا وحذفها على أي حال؟ أم يجب أن أقوم بتنفيذ جمل SQL مباشرة على قاعدة البيانات؟1 نقطة
-
قراءة من ملف وعمل لوب كل مرة تقرأ 8 بايت وإخراج الناتج مثل هذا 111111101010010101011100111010100101010101001100101010101010011 نقطة
-
######################### إنشاء ملف ثنائي ############ # إنشاء ملف ثنائي # w تشير إلى وضع الكتابة # b تشير إلى ملف ثنائي f=open("binfile.bin","wb") # تعريف مصفوفة num=[5, 10, 15, 20, 25] # تحويلها لصيغة ثنائية arr=bytearray(num) # كتابتها في ملف f.write(arr) f.close() ######################### قراءته ############## import pathlib s="" for byte in pathlib.Path("binfile.bin").read_bytes(): # decimal ستقرأ البايت وتحوله ل s+="{0:b}".format(byte) # s نحوله لثنائي مرة أخرى ونضيف ماقرأناه ل print(s) # 101101011111010011001 حيث أن pathlib تسمح لنا بالمرور على الملف بايت بايت.1 نقطة
-
استخدم تنسرفلو لتدريب نموذج لكن لم أفهم بدقة ماذا تعني ال epoch، من المعروف أن ال iteration هو عملية forward و backward على البيانات (مرور على البيانات ثم تحديث قيم الأوزان في الشبكة)، لكن ماهو ال epoch ؟ ولماذا لانستخدم مصطلح ال iteration؟ Epoch 1/5 105/938 [==>...........................] - ETA: 51s - loss: 0.6753 - acc: 0.79481 نقطة
-
في التوثيق الخاص بالدالة softmax في تنسرفلو يتم تعريف الدالة بالشكل التالي : tf.nn.softmax( logits, axis=None, name=None ) # أيضاً هناك دالة أخرى معرفة بالشكل التالي tf.nn.softmax_cross_entropy_with_logits(logits, labels, name=None) ما المقصود بال logits وما الفرق بين الدالتين السابقتين؟1 نقطة
-
حاولت اجيب عدد الأعضاء المتصلين بالموقع عن طريق الكود التالي و لم استطيع "SELECT COUNT(*) FROM users u WHERE u.last_login_date <= 18000" ممكن حد يساعدني1 نقطة
-
لدي بيانات على هيئة dataframe ، وأود أن أقوم بتبديل قيم بعض العناصر فيها بقيم أخرى، فقط عناصر محددة وليست كل البيانات، كيف يمكنني فعل هذا؟1 نقطة
-
يتم استخدام الدالة replace ولها الشكل التالي: Syntax: DataFrame.replace( old value, new value) مثال: import pandas as pd # إنشاء قاموس dic1 = {'c1': ['55', '44', '33', '22'], 'c2': ['1', '2', '3', '4']} dic2 = {'c1': [ 'e','f', 'g', 'h'], 'c2': ['argentena', 'barca', 'MachineLearning', 'ali']} # تحويلها لداتا فريم df1 = pd.DataFrame(dic1, columns=['c1', 'c2']) df2 = pd.DataFrame(dic2, columns=['c1', 'c2']) # عرض البيانات display(df1) display(df2) """ c1 c2 0 55 1 1 44 2 2 33 3 3 22 4 """ """ c1 c2 0 e argentena 1 f barca 2 g MachineLearning 3 h ali """ # استبدال القيمة 3 في العمود الثاني من الفريم الأول بالقيمةالثانية من العمود الثاني في الفريم الثاني # تحديد القيمة القديمة المراد استبدالها old = df1['c2'][2] # حيث حددنا العمود الثاني والفهرس الذي يقابل القيمة 3 # تحديد القيمة الجديدة new = df2['c2'][1] # تنفيذ عملية الاستبدال df1 = df1.replace(old,new) # عرض النتيجة display(df1) """ c1 c2 0 55 1 1 44 2 2 33 barca 3 22 4 """ # كما يمكنك استبدالها بقيمة أنت تريدها مثلا old = df1['c1'][0] df1 = df1.replace(old,'hsoub') display(df1) """ c1 c2 0 hsoub 1 1 44 2 2 33 barca 3 22 4 """ # كما ويمكننا استبدال عمود بآخر df1['c1'] = df1.replace(df1['c1'],df1['c2']) display(df1) """ c1 c2 0 hsoub 1 1 44 2 2 33 barca 3 22 4 """ كما يمكنك تمرير الوسيط inplace=True في حال أردت أن يتم التعديل على المصفوفة الأصلية بدون إنشاء نسخة.1 نقطة
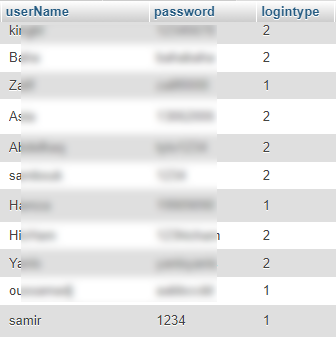
-
من فضلكم مساعدة ليش المتصفح ماعم يدخل لداش بورد الخاصة بالزبون وعم يرجع لنفس الصفحة الرئيسية <?php session_start(); error_reporting(0); include('../connect.php'); if (!isset($_SESSION["userName"])) { ?> <script type="text/javascript"> window.location = "../index.php"; </script> <?php } else { $userName = $_SESSION["userName"]; $sql = "select * from users where userName ='$userName' "; $result = $conn->query($sql); while ($row = $result->fetch_assoc()) { $logintype = $row['logintype']; if ($logintype !='1') { ?> <script type="text/javascript"> window.location = "../index.php"; </script> <?php } } } ?> مع انو الشرط صحيح يعني ليش يرجع الصفحة الرئيسية if ($logintype !='1') لان في قاعدة البيانات بالفعل المتغير logintype= 1 يعني صحيح يسجل جلسة لاكن عم يرجع لنفس الصفحة توجد صورة مرفقة تدل على ان الشرط صحيح في قاعدة البيانات رقم 1 كود صفحة الدخول <?php session_start(); error_reporting(0); include('connect.php'); include "inc/header.php" ;?> <title>شحن اللعبة | دخول </title> <!--header--> <div class="projects-2 section " style="background: #fff;"> <div class="container"> <div class="row "> <div class="col-md-12"> <h1 style="color: #064a6e">تسجيل الدخول <span> </span></h1> </div> </div> <div class="row"> <div class="container"> <?php error_reporting(0); include('connect.php'); ?> <div class="row"> <div class="col-md-12"> <div class="featured-boxes"> <div class="row"> <div class="col-sm-6"> <div class="featured-box featured-box-primary align-left mt-xlg clear" id="login-form" style=""> <div class="box-content bg_Lightgrey"> <h4 class="heading-primary text-uppercase mb-md">لديك حساب حالي ؟</h4> <form action="" id="frmSignIn" method="post"> <div class="alert alert-danger" id="error" style="display: none"> <strong>خطأ!</strong> بيانات الدخول غير صحيحة </div> <div class="alert alert-danger" id="erroractive" style="display: none"> <strong>خطأ!</strong> هذا الحساب بانتظار التفعيل من قبل الادارة ، سيتم التفعيل فى اقرب وقت شكرا </div> <div class="alert alert-danger" id="errorstop" style="display: none"> <strong>خطأ!</strong> هذا الحساب موقوف </div> <div class="alert alert-success" id="success" style="display: none"> <strong>تهانينا!</strong> نجاح العملية يرجى الانتظار جارى التوجيه... </div> <div class="form-group"> <div class="col-md-12"> <label for="LoginEmail">اسم المستخدم<span class="required">*</span></label> <input type="text" name="userName" value="<?php if (isset($_COOKIE["member_login"])) { echo $_COOKIE["member_login"]; } ?>" class="form-control input-md" required="required" placeholder="أدخل اسم المستخدم"> </div> </div> <div class="form-group"> <div class="col-md-12"> <label for="Password">كلمة المرور <span class="required">*</span></label> <input type="password" value="<?php if (isset($_COOKIE["member_login"])) { echo $_COOKIE["member_login"]; } ?>" name="password" class="form-control input-md" required="required" placeholder="أدخل كلمة المرور"> </div> </div> <div class="form-group"> <div class="col-md-12"> <span><input type="checkbox" <?php if (isset($_COOKIE["member_login"])) { ?> checked <?php } ?> name="remember">تذكرنى </span><br> <a href="forgetpass.php">نسيت كلمة السر؟</a> </div> </div> <div class="row mt-lg"> <div class="col-md-12"> <input type="submit" name="login" value="تسجيل الدخول" class="btn btn-primary pull-left mb-xl"> </div> </div> </form> </div> </div> </div> </div> </div> </div> </div> </div> </div> <?php include "inc/footer.php"; ?> <?php error_reporting(0); if (isset($_POST["login"])) { $userName = htmlspecialchars($_POST['userName']); $password = htmlspecialchars($_POST['password']); $countc = 0; $resc = mysqli_query($conn, "select * from users where BINARY userName='$userName' && BINARY password= '$password' && active = '0' LIMIT 1"); $countc = mysqli_num_rows($resc); if ($countc > 0) { ?> <script type="text/javascript"> document.getElementById("erroractive").style.display = "block"; </script> <?php } else { $counts = 0; $ress = mysqli_query($conn, "select * from users where BINARY userName='$userName' && BINARY password= '$password' && active = '2' LIMIT 1"); $counts = mysqli_num_rows($ress); if ($counts > 0) { ?> <script type="text/javascript"> document.getElementById("errorstop").style.display = "block"; </script> <?php } else { $count = 0; $res = mysqli_query($conn, "select * from users where BINARY userName='$userName' && BINARY password= '$password' && active = '1' LIMIT 1"); $count = mysqli_num_rows($res); if ($count == 0) { ?> <script type="text/javascript"> document.getElementById("error").style.display = "block"; </script> <?php } else { $sql = "select * from users where BINARY userName='$userName' && BINARY password= '$password' && active = '1' "; $result = $conn->query($sql); while ($row = $result->fetch_assoc()) { $logintype = $row['logintype']; if ($logintype == 1) { ?> <script type="text/javascript"> document.getElementById("success").style.display = "block"; </script> <?php $_SESSION["userName"] = $userName; ?> <script type="text/javascript"> window.location = "Supermarket"; </script> <?php } elseif ($logintype == 2) { ?> <script type="text/javascript"> document.getElementById("success").style.display = "block"; </script> <?php $_SESSION["userName"] = $userName; ?> <script type="text/javascript"> window.location = "client"; </script> <?php } } } } } } ?> ارجو المساعدة من فضلكم ليش الخلل ومن يجرب https://gsmrida.com/login.php اسم المستخدم: samir كلمة السر: 1234 من المفروض يوجه لداش بورد
 1 نقطة
1 نقطة -
هل توجد مكتبة أخرى؟1 نقطة
-
حاول الوصول للقائمة المرادة من خلال عمل var targetSelect = $(#id); ثم: $(targetSelect).html(data); **** يمكنك إسناد خاصة من اختيارك في HTML مثلا: <div id="navLinks"> <ul> <li class="itemLinks" data-pos="0"></li> <li class="itemLinks" data-pos="1"></li> <li class="itemLinks" data-pos="2"></li> <li class="itemLinks" data-pos="3"></li> </ul> </div> لاحظ data-pos هي تمثل ترتيب العناصر، يمكن الوصول لها من جيكوري: var postion = clickedLink.attr("data-pos"); => var $links = $(".itemLinks"); $links.click(function(e){ var clickedLink = e.target; clickedLink = $(clickedLink); var postion = clickedLink.attr("data-pos"); }1 نقطة
-
إن الشيفرة السابقة يتم تنفيذها لكل القوائم لأن لهم صنف مشترك كما أعتقد، فأي تغيير فيهم يسبب نفس التعديل $(document).on('change', '.color', function() { ^^^^^^^^ $(document).on('change', '#select-1', function() { ^^^^^^^ حاول تبديل كل منهم بشفرة خاصة .. بوضع معرف خاص لكل قائمة مثلا id ويتم جلبة من خلال وضع # أما اسمه كما أن $(".size").html(data); ^^^^^^^^^^ هذا يقوم بعمل التحديث بنفس العنصر دوما لأن له الصنف size ارتبط تعديل قائمة مع تعديل أخرى عن طريق id لكل منهما إن أردت.. أعتقد أن الشيفرة الأولى يمكن أن تكون عامة، اجلب العنصر الهدف أيضا بطريقة ديناميكية..1 نقطة
-
يمكننا استخدام الدالة Series.str.replace() او الدالة replace وذلك لتبديل قيم عناصر محددة بقيم أخرى، والفرق بينها وبين .replace() فقط انها مفيدة في حالة اردت استبدال معلومات على الشكل string. المثال التالي يوضح كيفية استخدام replace : # استدعاء المكتبة import pandas as pd # قراءة البيانات data = pd.read_csv("data.csv") # تبديل عناصر في عمود بعناصر أخرى data["Age"]= data["Age"].replace(25.0,20.0) #طباعة البيانات الجديدة print(data) هنا نقوم باختيار العمود Age وإستبدال بعض القيم العددية فيه من 25 الي 20. أما اذا اردت استخدام الدالة str.replace فيمكنك استخدامها كالتالي: # استدعاء المكتبة import pandas as pd # قراءة البيانات data = pd.read_csv("data.csv") # استبدال قيم من عمود معين بقيم أخرى data["country"]= data["country"].str.replace("Egypt", "KSA", case = False) #طباعة البيانات المعدلة print(data) هنا نقوم باستبدال الكلمة "Egypt" بالكلمة "KSA" من العمود country، لاحظ أن case = False تعني أنه لا يهتم سواء كانت الكلمات بحروف كبيرة capital او حروف صغيرة small1 نقطة
-
ببساة يمكنك استخدام التابع sum فكما نعلم أن هذا التابع يقوم بحساب مجموع قيم مصفوفة ما، لكن إذا طبقته على مصفوفة بوليانية سيقوم بعد عدد مرات ظهور القيمة True : a=np.array([True,True,True,False,False]) sum(a) # 3 # أما في حالة كانت المصفوفة متعددة الأبعاد a=np.array([[True,True,True,False,False],[True,True,True,False,False]]) sum(a.ravel()) # 6 # أي يجب تسطيح المصفوفة إذا كانت بأكثر من بعد أو ببساطة متناهية: a=np.array([[True,True,True,False,False],[True,True,True,False,False]]) a[a].size حيث أن ناتج a[a] هو: array([ True, True, True, True, True, True]) أي فقط القيم التي تعطي True من a. أو من خلال التابع np.count_nonzero(array) : np.count_nonzero(a) # 6 أو من خلال التابع sum في نمباي: a.sum() أو من خلال استخدام التابع bicount من نمباي: arr=np.array([False, True, True, True, False, True, False, True, True]) #false وعدد ال true سيقوم بحساب عدد ال bin_arr = np.bincount(arr) bin_arr # array([3, 6]) #True لاستخلاص عدد ال bin_arr[1] # 6 للمقارنة: a=np.array([[True,True,True,False,False]*100]) %timeit a[a].size %timeit sum(a.ravel()) %timeit np.count_nonzero(a) %timeit a.sum() %timeit np.bincount(a.ravel()) """ The slowest run took 23.84 times longer than the fastest. This could mean that an intermediate result is being cached. 1000000 loops, best of 5: 1.82 µs per loop 1000 loops, best of 5: 1.14 ms per loop The slowest run took 19.70 times longer than the fastest. This could mean that an intermediate result is being cached. 1000000 loops, best of 5: 975 ns per loop The slowest run took 27.08 times longer than the fastest. This could mean that an intermediate result is being cached. 100000 loops, best of 5: 2.98 µs per loop The slowest run took 67.31 times longer than the fastest. This could mean that an intermediate result is being cached. 100000 loops, best of 5: 2.62 µs per loop """1 نقطة
-
يمكنك القيام بحساب طويلة متجه بعدة طرق. أولها من خلال التابع numpy.linalg.norm بالشكل التالي: import numpy as np x = np.array([1,2,3,4]) np.linalg.norm(x) # 5.477225575051661 حيث أن التابع np.linalg.norm(x) يقوم بحساب الطويلة للشعاع. أو يمكنك تحقيق ذلك بشكل يدوي من خلال استخدم التابع dot و sqrt كالتالي حيث أن عملية إيجاد الطويلة لمتجه هو تربيع القيم ثم حساب الجذر التربيعي وبالتالي نستخدم عملية الضرب x.dot(x) لتقوم بعملية ضرب عناصر الشعاع x ببعضها ثم حساب جذر المجموع الناتج: m = np.sqrt(x.dot(x)) # 5.477225575051661 # بحيث: # x.dot(x)=30 # 1*1+2*2+3*3+4*4=30 # 30^1/2=5.477 أو يمكنك الاعتماد على مكتبة einsum لتنفيذ الجداء : np.sqrt(np.einsum('...i,...i', x, x)) # 5.477225575051661 أو: from numpy.core.umath_tests import inner1d np.sqrt(inner1d(x,x)) أو من خلال مكتبة vg استخدم التابع : import vg vg.magnitude(x) #5.477225575051661 لكن عليك أولاً أن تقوم بتحميلها: pip install vg للمقارنة: %timeit vg.magnitude(x) %timeit np.sqrt(inner1d(x,x)) %timeit np.sqrt(np.einsum('...i,...i', x, x)) %timeit np.sqrt(x.dot(x)) %timeit np.linalg.norm(x) """ The slowest run took 142.37 times longer than the fastest. This could mean that an intermediate result is being cached. 100000 loops, best of 5: 8.71 µs per loop The slowest run took 8.71 times longer than the fastest. This could mean that an intermediate result is being cached. 100000 loops, best of 5: 5.11 µs per loop The slowest run took 6.30 times longer than the fastest. This could mean that an intermediate result is being cached. 100000 loops, best of 5: 8.37 µs per loop The slowest run took 10.48 times longer than the fastest. This could mean that an intermediate result is being cached. 100000 loops, best of 5: 4.6 µs per loop The slowest run took 17.93 times longer than the fastest. This could mean that an intermediate result is being cached. 100000 loops, best of 5: 8.51 µs per loop """1 نقطة
-
يمكنك استخدام الدالة numpy.flip عن طريق تمرير الدالة argsort لها حيث سترد لك ال indexes للقيم مرتبة بترتيب تنازلي بعد أن يتم فرزها تصاعدياً باستخدام argsort حيث تقوم هذه الدالة بعكس ترتيب العناصر : import numpy as np a = np.array([2, 9, 7, 10, 5, 3]) n=3 ids = np.flip(np.argsort(a)) print(ids[0:n]) #[3 1 2] نفس الفكرة باستخدام np.flipud: import numpy as np a = np.array([2, 9, 7, 10, 5, 3]) n=3 ids = np.flipud(np.argsort(a)) print(ids[0:n]) #[3 1 2] أو يمكنك القيام بعكسها بإحدى الأشكال التالية: # نضرب المصفوفة بسالب وبالتالي يصبح الأصغر أكبر وبالتالي نحصل على الفهرس المطلوب np.argsort(-1*a)[:3] #- كما ويمكن استخدام المعامل # أي بشكل مشابه للطريقة السابقة (-a).argsort()[:3] # أو بالطريقة التقليدية عن طريق أخذ آخر 3 عناصر a.argsort()[::-1][:3] وكمقارنة: %timeit np.flipud(np.argsort(a))[0:3] %timeit np.flip(np.argsort(a))[0:3] %timeit np.argsort(-1*a)[:3] %timeit (-a).argsort()[:3] %timeit a.argsort()[::-1][:3] 5.14 µs ± 211 ns per loop (mean ± std. dev. of 7 runs, 100000 loops each) 5.29 µs ± 337 ns per loop (mean ± std. dev. of 7 runs, 100000 loops each) 4.57 µs ± 127 ns per loop (mean ± std. dev. of 7 runs, 100000 loops each) 1.97 µs ± 288 ns per loop (mean ± std. dev. of 7 runs, 100000 loops each) 1.86 µs ± 251 ns per loop (mean ± std. dev. of 7 runs, 1000000 loops each) # الطريقة الأخيرة أفضل1 نقطة
-
يمكنك القيام بذلك بشكل يدوي: import numpy as np A = np.random.randint(low=0,high=255, size=(2, 4)).astype(float) A """ array([[166., 246., 37., 195.], [ 63., 33., 189., 200.]]) """ th=127 A[A > th] = 255.0 A """ array([[255., 255., 37., 255.], [ 63., 33., 255., 255.]]) """ كما ويمكنك استخدام التابع np.putmask حيث نمرر له المصفوفة والعتبة والقيمة المراد الاستبدال بها: A = np.random.randint(low=0,high=255, size=(2, 4)).astype(float) """ array([[ 62., 23., 218., 205.], [197., 254., 149., 32.]]) """ # تحديد العتبة T=127 np.putmask(A, A>=T, 255.0) """ array([[ 62., 23., 255., 255.], [255., 255., 255., 32.]]) """ أو من خلال np.place حيث نمرر له المصفوفة، ثم العتبة كما في المثال، ثم القيمة المراد التحويل لها : A=np.array([[ 62., 23., 218., 205.], [197., 254., 149., 32.]]) np.place(A, A >=127, 255) """ array([[ 62., 23., 255., 255.], [255., 255., 255., 32.]]) """ أو من خلال np.where: A=np.array([[ 62., 23., 218., 205.], [197., 254., 149., 32.]]) np.where(A > 127, 255,A) """ array([[ 62., 23., 255., 255.], [255., 255., 255., 32.]]) """ كمقارنة: %timeit np.place(A, A >=127, 255) %timeit np.putmask(A, A>127, 255) %timeit np.where(A > 127, 255,A) 3.44 µs ± 197 ns per loop (mean ± std. dev. of 7 runs, 100000 loops each) 3.03 µs ± 162 ns per loop (mean ± std. dev. of 7 runs, 100000 loops each) 4.84 µs ± 1.15 µs per loop (mean ± std. dev. of 7 runs, 100000 loops each) # قريبتان من بعضهما لكن الأولى أفضل1 نقطة
-
يمكنك استخدام numpy.ndarray.size. فعن طريق الوصول إلى عدد العناصر في numpy.ndarray باستخدام numpy.ndarray.size. يمكنك تحديد فيما إذا كانت المصفوفة فارغة أم لا حيث، إذا كان عدد العناصر في المصفوفة يساوي 0 ، فإن المصفوفة فارغة: import numpy as np empty_array = np.array([]) is_empty = empty_array.size == 0 is_empty # True ################################ empty_array = np.array([1,2]) is_empty = empty_array.size == 0 is_empty # False حسناً قد تظهر لنا مشكلة عندما يتم تعريف المصفوفة الفارغة بالشكل np.array(None) حيث أن ناتج تطبيق size سيكون 1، لذا لحل المشكلة: import numpy as np empty_array = np.array(None) is_empty = False if empty_array.size and empty_array.ndim else True is_empty # True ########################## import numpy as np empty_array = np.array([]) is_empty = False if empty_array.size and empty_array.ndim else True is_empty # True ######################### import numpy as np empty_array = np.array([1]) is_empty = False if empty_array.size and empty_array.ndim else True is_empty # False ويمكنك كتابة التابع التالي الذي يشمل كل ماسبق: def elements(array): return False if array.ndim and array.size else True elements(np.array([1])) #False elements(np.array([])) # True elements(np.array(None)) # True كما ويمكنك استخدام الدالة np.any، لكن القيد على هذه الوظيفة هو أنها لا تعمل إذا كانت المصفوفة تحتوي على القيمة 0 فيها. import numpy as np arr = np.array([]) flag = not np.any(arr) if flag: print('empty') else: print('not empty') # empty ############################# arr = np.array(None) flag = not np.any(arr) if flag: print('empty') else: print('not empty') # empty ############################ arr = np.array([1]) flag = not np.any(arr) if flag: print('empty') else: print('not empty') # not empty أو من خلال تحويلها لقائمة: import numpy as np arr = np.array([1]) if len(arr.tolist()) == 0: print("Empty") else: print("Not") قمنا أولاً بتحويل المصفوفة إلى قائمة باستخدام طريقة tolist (). ثم تحققنا من حجم القائمة باستخدام طريقة len () للتحقق مما إذا كانت المصفوفة فارغة.، لكن في حال تم تعريف المصفوفة من خلال None فسيظهر خطأ لذا لحل المشكلة قمت بتعريف التابع التالي: def test(a): try: if len(a.tolist()) == 0: return "Empty" else: return "Not" except: return "Empty" test(np.array([1])) # 'Not' test(np.array([])) # 'Empty' test(np.array(None)) # 'Empty' وأخيراً من خلال التبع shape: import numpy as np a = np.array([]) if a.shape[0] == 0: print("Empty") وذلك من خلال التحقق مما إذا كان عدد العناصر في المحور 0 ، أي الصف ، صفراً أم لا.1 نقطة
-
يمكننا استخدام الدالة empty لإنشاء مصفوفة ثم القيام بتعبئتها بالقيمة المطلوبة من خلال التابع fill كما يلي: def fill(n): arr = np.empty(n) return arr.fill(np.nan) fill(5) # array([nan, nan, nan, nan, nan]) def fill(n): arr = np.empty(n) arr.fill(np.nan) return arr print(fill((3,2))) """ [[nan nan] [nan nan] [nan nan]] """ أو يمكنك أن تقوم يتعبئتها بشكل يدوي: def c(n): a = np.empty(n) a[:] = np.nan return a print(c((3,2))) """ [[nan nan] [nan nan] [nan nan]] """ وكطريقة سهلة يمكنك استخدام التابع full بحيث نمرر له أبعاد المصفوفة والقيمة المراد تعبئتها: def full(n): return numpy.full(n, np.nan) print(c((3,2))) """ [[nan nan] [nan nan] [nan nan]] """ أو من خلال التابع التالي حيث سنعتمد على مفهوم القوائم ثم تحويلها لمصفوفة نمباي: def list(n,row,col): return np.array(n * [np.nan]).reshape(-1,col) print(list(12,3,4)) """ [[nan nan nan nan] [nan nan nan nan] [nan nan nan nan]] """ لكن هنا نمرر عدد عناصر المصفوفة المطلوبة وعدد أسطر وأعمدة المصفوفة المطلوبة. ويمكنك أيضاً تنفيذ ماتريده بالشكل التالي: np.nan * np.zeros(shape=(3,2)) """ array([[nan, nan], [nan, nan], [nan, nan]]) """ كما ويمكنك من خلال الدالةtile حيث نمرر لها القيمة ثم الأبعاد كما في المثال التالي : np.tile(np.nan, (2, 3)) """ array([[nan, nan, nan], [nan, nan, nan]]) """ وبشكل عام فإن أسرع طريقة هي استخدام الدالة fill.1 نقطة
-
أولاً يجب أن نفهم المشكلة. ال unit vector أو متجه الوحدة هو متجه طويلته (magnitude) تساوي ال 1. وبالتالي فإن الشعاع التالي لايمثل متجه وحدة: import numpy as np # تعريف الشعاع التالي v = np.array([1,3]) # حساب الطويلة np.linalg.norm(v) #3.1622776601683795 # إذاً ليس متجه وحدة حيث أن التابع np.linalg.norm(x) يقوم بحساب الطويلة للشعاع. الآن إذا أردنا أن نقوم بتحويل هذا الشعاع إلى متجه وحدة فيجب أن نقوم بعملية normalizing. رياضياً فإنه لتحويل أي شعاع إلى شعاع وحدة يجب أن نقوم بقسمة جميع عناصره على طويلته، أي لتحويل الشعاع السابق يجب أن نقوم بقسمة قيمه على 3.16227766. import numpy as np v = np.array([1,3]) magnitude =np.linalg.norm(v) # نقسم كل عنصر على الطويلة v=v/magnitude # نختبر إذا أصبح متجه وحدة np.linalg.norm(v) # 1.0 # نجحنا حسناً إذا أردت أن لاتستخدم np.linalg.norm(v) يمكنك استخدام الصيغة التالية، فكما نعلم أن الطويلة هي الجذر التربيعي لمجموع مربعات قيم الشعاع: import numpy as np v = np.array([1,3,5,6,33]) magnitude =np.sqrt(np.sum(v**2)) # نقسم كل عنصر على الطويلة v=v/magnitude # نختبر إذا أصبح متجه وحدة np.linalg.norm(v) # 1.0 # نجحنا كما ويمكنك استخدام مكتبة Sklearn حيث تحتوي على طرق فعالة متاحة للمعالجة المسبقة للبيانات وأدوات التعلم الآلي الأخرى. عادةً ما يستخدم التابع normalize في هذه المكتبة مع المصفوفات ثنائية الأبعاد وتوفر خيار تسوية L1 و L2. سنستخدم في الكود التالي هذه التابع مع مصفوفة 1D حيث سنقوم باستخدام الدالة ravel لتسطيح المصفوفة : import numpy as np from sklearn.preprocessing import normalize v = np.array([1,3,5,6,33]) v = normalize(v[:,np.newaxis], axis=0).ravel() # نختبر إذا أصبح متجه وحدة np.linalg.norm(v) # 1.0 # نجحنا ,وأخيراً يمكنك استخدام الدالة الجاهزة لتحويل الشعاع إلى شعاع وحدة بشكل مباشر من خلال المكتبة transformations: # لتحميلها : pip install transformations import numpy as np import transformations as trafo v = np.array([1,3,5,6,33]) unit_v = trafo.unit_vector(data, axis=1) # نختبر إذا أصبح متجه وحدة np.linalg.norm(unit_v) # 1.01 نقطة
-
الطريقة الوحيدة في نمباي من خلال التابع percentile : import numpy as np arr = np.array([1,2,3,4,5]) # نريد القيمة الأكبر من نصف عناصر المصفوفة per = np.percentile(arr, 50) # 3.0 # القيمة الأكبر من 90 بالمئة من عناصر المصفوفة np.percentile(arr, 90) # 4.6 np.percentile(arr, 100) # 5.0 np.percentile(arr, 0) # 1.0 حيث نمرر له المصفوفة والنسبة المئوية التي نريده أن يرد لنا القيمة الموافقة لها. وإذا أردت أن يتم تقريب قيم الخرج لأقرب قيمة. أي مثلاً بدلاً من 4.6 تريد 4 أو 5 فيمكنك القيام بذلك كالتالي: import numpy as np arr = np.array([1,2,3,4,6]) np.percentile(arr, 90, interpolation='lower') # 4 # التقريب للأعلى np.percentile(arr, 90, interpolation='higher') # 6 مثال آخر: a = np.array([[10, 7, 4], [3, 2, 1]]) """ array([[10, 7, 4], [ 3, 2, 1]]) """ np.percentile(a, 50) # 3.5 np.percentile(a, 50, axis=0) # array([6.5, 4.5, 2.5]) np.percentile(a, 50, axis=1) # array([7., 2.]) np.percentile(a, 50, axis=0, out=out) """ array([6.5, 4.5, 2.5]) """ np.percentile(a, 50, axis=1, keepdims=True) """ array([[7.], [2.]]) """ حيث أن الوسيط axis يمثل المحور أو المحاور التي سيتم حساب النسب المئوية على طولها. الافتراضي هو حساب النسب المئوية على طول نسخة مسطحة من المصفوفة. أما الوسيط out فيمثل مصفوفة إخراج بديلة لوضع النتيجة فيها. يجب أن يكون له نفس الشكل وطول المخزن المؤقت للإخراج المتوقع ، ولكن سيتم إرسال نوع (الإخراج) إذا لزم الأمر. ويمكنك من خلال التابع التالي القيام بذلك حيث سنستعين بالمكتبة الرياضية في بايثون: import numpy as np arr = np.array([1,2,3,4,5]) import math def per(data, perc: int): return sorted(data)[int(math.ceil((len(data) * perc) / 100)) - 1] per(arr,50) # 3 per(arr,90) # 5 # لاحظ أنه لم يعطي 4.6 per(arr,92) # 5 لكن هنا كما تلاحظ قام بعملية تقريب بحيث تكون القيمة ضمن المصفوفة أي لن يحتسب مجالات القيم. ويمكنك أيضاً القيام بذلك من خلال التابع التالي: import numpy as np arr = np.array([1,2,3,4,5]) def per(N, P): n = int(round(P * len(N) + 0.5)) return N[n-1] per(arr,0.5) # 3 per(arr,0.9) # 51 نقطة
-
الطريقة الأولى هي استخدام ()numpy.nan و ()numpy.logical_not. فلتكن لدينا المصفوفة التالية: a = numpy.array([2, 8, numpy.nan, 3, 1, numpy.nan]) ولو طبقنا عليها numpy.isnan سوف يعيد لنا نفس المصفوفة لكن بقيم بوليانية بحيث يضع true مكان القيم التي ليست nan و false مكان القيم nan: print(numpy.isnan(a)) # [False False True False False True] الآن لو استخدمنا على الناتج السابق التابع logical_not فسوف يعكس النتائج، أي بدل true سيضع false والعكس: print(numpy.logical_not(numpy.isnan(a))) # [ True True False True True False] الآن يمكننا الاستفادة من الفكرة التالية: e=(np.array([1, 0, 3,4])) e[[True, True, True,False]] # array([1, 0, 3]) لذا يكون الحل كالتالي: import numpy # إنشاؤ المصفوفة a = numpy.array([2, 8, numpy.nan, 3, 1, numpy.nan]) #numpy.logical_not و numpy.isnan(): باستخدام #nan سنقوم بحذف قيم print(numpy.isnan(a)) # [False False True False False True] print(numpy.logical_not(numpy.isnan(a))) # [ True True False True True False] b = a[numpy.logical_not(numpy.isnan(a))] print(b) # [2. 8. 3. 1.] مثال آخر على مصفوفة ثنائية: import numpy # إنشاؤ المصفوفة a = numpy.array([[6, 2, numpy.nan], [2, 6, 1], [numpy.nan, 1, numpy.nan]]) #numpy.logical_not و numpy.isnan(): باستخدام #nan سنقوم بحذف قيم print(numpy.isnan(a)) """ [[False False True] [False False False] [ True False True]] """ print(numpy.logical_not(numpy.isnan(a))) """ [[ True True False] [ True True True] [False True False]] """ b = a[numpy.logical_not(numpy.isnan(a))] print(b) # [6. 2. 2. 6. 1. 1.] أو يمكنك استخدام المعامل ~ بدلاً من logical كالتالي: import numpy a = numpy.array([[12, 5, numpy.nan, 7], [2, 61, 1, numpy.nan], [numpy.nan, 1, numpy.nan, 5]]) a = a[~(numpy.isnan(c))] a #array([12., 5., 7., 2., 61., 1., 1., 5.]) أو من خلال التابع isfinite في نمباي (بنفس المبدأ) : import numpy a = numpy.array([[12, 5, numpy.nan, 7], [2, 61, 1, numpy.nan], [numpy.nan, 1, numpy.nan, 5]]) a[np.isfinite(a)] # array([12., 5., 7., 2., 61., 1., 1., 5.])1 نقطة
-
del تستخدم مع القوائم وليس مصفوفات نمباي على ما اعتقد، لذالك يظهر الخطأ. هناك عدة طرق للحذف من نمباي، فيمكنك استخدام التابع setdiff1d من نمباي، حيث نمرر له المصفوفة الأصلية والقيم التي نريد حذفها موضوعة ضمن مصفوفة: import numpy as np arr = np.array([1, 2, 3, 4, 5, 6, 7, 8, 9]) # مصفوفة بالقيم التي نريد حذفها b = np.array([1,2,4]) arr = np.setdiff1d(arr,b) arr # array([3, 5, 6, 7, 8, 9]) أو من خلال التابع delete لكن هنا نمرر له ال index المراد حذفها وليس القيم: import numpy as np arr = np.array([1, 2, 3, 4, 5, 6, 7, 8, 9]) b = np.delete(arr, [2,3,6]) #index هنا نمرر له ال b #array([1, 2, 5, 6, 8, 9]) # لحذف عنصر واحد من خلال الفهرس array = [10, 20, 30, 40, 50, 60, 70, 80, 90, 100] index = 2 array = np.delete(array, index) array # array([ 10, 20, 40, 50, 60, 70, 80, 90, 100]) أيضاً هنا يتم الحذف من خلال تحديد الفهرس عن طريق استخدام itertools.compress وهي الطريقة الأسرع: import numpy as np arr = np.array([1, 2, 3, 4, 5, 6, 7, 8, 9]) import itertools index=[2,3,6] arr = np.array(list(itertools.compress(arr, [i not in index for i in range(len(arr))]))) arr # array([1, 2, 5, 6, 8, 9]) حسناً الطرق السابقة كانت من أجل مصفوفات نمباي، لكن هناك طرق أخرى خاصة بالقوائم، فمثلاً يمكنك تحويل المصفوفة إلى قائمة ثم حذف العنصر من القائمة بإحدى الطرق التالية، ثم إعادة تحويلها لمصفوفة. استخدام Remove لحذف عنصر محدد: array = [10, 20, 30, 40, 50, 60, 70, 80, 90, 100] array.remove(40) #[10, 20, 30, 50, 60, 70, 80, 90, 100] أو pop لحذف عنصر من خلال تمرير ال index: array = [10, 20, 30, 40, 50, 60, 70, 80, 90, 100] index = 2 array.pop(index) array # [10, 20, 40, 50, 60, 70, 80, 90, 100] أو من خلال del وأيضاً من خلال ال index: array = [10, 20, 30, 40, 50, 60, 70, 80, 90, 100] index = 2 del array[index] array # [10, 20, 40, 50, 60, 70, 80, 90, 100]1 نقطة









