لوحة المتصدرين




المحتوى الأكثر حصولًا على سمعة جيدة
المحتوى الأعلى تقييمًا في 06/26/21 في كل الموقع
-
عندي خيارين اذا اختر الاول ينقلني الزر على صفحة واذا اخترت الثاني ابغا نفس الزر ينقلني على صفحة اخرى كيف ممكن اعمله بالجافا سكربت2 نقاط
-
لما اكتب الكود بهذه الطريقة abort_if(Gate::denies('user_create'), Response::HTTP_FORBIDDEN, '403 Forbidden'); هل هو نفس فكرة Gate::define('create-post', function (User $user, Category $category, $pinned) { if (! $user->canPublishToGroup($category->group)) { return false; } elseif ($pinned && ! $user->canPinPosts()) { return false; } return true; });1 نقطة
-
هل يلزم متابعة الدورة من بدايتها بالترتيب من (دورة علوم الحاسوب) ام استطيع التنقل بغير ترتيب؟1 نقطة
-
لو سمحتوا كنت عايز اعرف الفرق ما بين master و origin في الgithub بالتفصيل وسهوله في الشرح بعد اذنكم لأ،ي نا دورت كتير ومش فاهمها بردو1 نقطة
-
أحاول الحصول على المجلّدات الموجودة ضمن مجلّد معين في node.js ، وحاولت استخدام path للحصول على مسار المجلّد: path.dirname(__filename) لكن حصلت فقط على مسار المجلّد الحالي، كيف يمكنني الوصول وطباعة اسماء جميع المجلّدات الموجودة ضمن هذا المجلّد؟1 نقطة
-
لدي مشكلة في npm بحيث عندما أحاول تحميل أي مكتبة كبيئة تطوير بتنفيذ الأمر: npm install something --dev يتم تجاهل --dev ولا يتم تحميلها ضمن devDependencies. وحتى الأمر npm install أيضاً لا يقوم بتحميل أي مكاتب dev. كيف يمكنني حل هذه المشكلة؟1 نقطة
-
لقد قمت بتحميل نسخة node.js من خلال nvm ولكنها أقدم من النسخة التي أرغب باستخدامها حالياً. هل من الممكن تحديث نسخة node.js بشكل آلي أو من خلال nvm دون تحميلها بشكل يدوي؟1 نقطة
-
طباعة العناصر المتكرر في stack و عدد مرات تكرارها.1 نقطة
-
لحساب تكرار العناصر، يتوجب بناء بنية معطيات تمكننا من عد العناصر، مثل مصفوفة أو Map: يمكن حساب التكرار للعناصر قبل إضافتها للمكدس. #include<bits/stdc++.h> using namespace std; // حساب التكرارات map<int, int> freqMap; // تعريف المكدس stack<int> stack; // حساب التكرارات void push(int x) { // تكرار of x freqMap[x] = freqMap[x] + 1; stack.push(x); } int main() { // إضافة العناصر للمكدس push(4); push(6); push(7); push(6); push(4); push(8); } لطباعة عناصر Map تمر عليهم بحلقة for.. for (auto& t : freqMap) std::cout << t.first << " " << t.second << "\n"; يمكن الإعتماد على الشيفرة السابقة وإضافتها لشيفرة المكدس لديكِ. الطريقة السابقة هي أفضل طريقة لأنه في حال أردنا حساب نفس المنطق بعد إضافة العناصر سيتوجب علينا إفراغ المكدس و إعادة إضافة العناصر له، لأنه كما نعلم أننا نستطيع الوصول للعنصر القمي فقط في المكدس top1 نقطة
-
هذه الطريقة نادرة الاستخدام عموماً. وهي أحد طرق تقسيم الداتا مثل StratifiedKFold ولكن يختلف عنه بأنه يقوم بأخذ نسبه متساوية من كل صنف في كل مجموعة.. في StratifiedKFold لو كان لدينا أربع عينات وكل منها يحمل 0و0و1و1 فمن الممكن أن يأخذ 0و0 والمجموعه الثانيه 1و1 وهذا تساوي أما Repeated Stratified KFold سوف يأخذ 0و1 في الأولى و1و0 في الثانية لكي تكون النسبة متساوية لكل صنف في كل مجموعة. يتم استخدامه عبر الموديل sklearn.model_selection. #استدعاء المكتبات from sklearn.model_selection import RepeatedStratifiedKFold قمنا باستدعاء المكتبة numpy لتشكيل الداتا واستدعاء الوظيفه RepeatedStratifiedKFold من الوحدة model_selection في مكتبة sklearn #تشكيل الداتا الدخل والخرج X = np.array([[1, 2], [3, 4], [5, 6], [7, 8]]) y = np.array([1, 0, 1, 0]) حيث X مصفوفة أبعادها 4 أسطر وعمودين وy عمود واحد بأربع أسطر #RepeatedStratifiedKFold rskf = RepeatedStratifiedKFold(n_splits=5,n_repeats=10, random_state=None) الوسيط الأول n_splits عدد صحيح لتحديد عدد الأجزاء folds وهي افتراضية في sklearn من 3 إلى 5. الوسيط الثاني n_repeats وهو نقطة الاختلاف عن StratifiedKFold هو عدد صحيح يمثل عدد KFolds. الوسيط الثالث random_state للتحكم بآلية التقسيم. نفس الأمر في StratifiedKFold مرور حلقة حيث يتم استخدام اثنين من الاندكسات في الحلقة للمرور على التدريب والاختبار وتحوي rskf.split(X, y) هذه الاندكسات . نقوم بطباعة الاندكس للتدريب والاختبار في كل محاولة وبعدها تخزين التدريب والاختبار ومن ثم طباعة كل منها: for train_index, test_index in rskf.split(X, y): print("TRAIN:", train_index, "TEST:", test_index) X_train, X_test = X[train_index], X[test_index] y_train, y_test = y[train_index], y[test_index] print('X_train:\n '+str(X_train),end='\n\n') print('X_test:\n '+str(X_train),end='\n\n') print('y_train:\n '+str(X_train),end='\n\n') print('y_test:\n '+str(X_train),end='\n\n')1 نقطة
-
ماتزال هذه النسخة تجريبة حتى الآن "experimental" لذا لاستخدامه ، تحتاج إلى استيراد enable_iterative_imputer بشكل صريح لكي يتم استخدام الميزات التجريبية كالتالي: from sklearn.experimental import enable_iterative_imputer from sklearn.impute import IterativeImputer1 نقطة
-
هي أحد طرق تقسيم الداتا هي متل KFold ولكن يختلف عنه بأنه يقوم بأخذ مجموعات متساوية من حيث عدد الفئات في كل مجموعة في حال كانت البيانات بغرض التنصيف يتم استخدامه عبر الموديل sklearn.model_selection. #استدعاء المكتبات from sklearn.model_selection import StratifiedKFold قمنا باستدعاء المكتبة numpy لتشكيل الداتا. واستدعاء الوظيفه StratifiedKFold من الوحدة model_selection في مكتبة sklearn. #تشكيل الداتا الدخل والخرج X = np.array([[1, 2], [3, 4], [5, 6], [7, 8]]) y = np.array([1, 0, 1, 0]) حيث X مصفوفة أبعادها 4 أسطر وعمودين وy عمود واحد بأربع أسطر. #StratifiedKFold Skf = StratifiedKFold(n_splits=5, *, shuffle=False, random_state=None) الوسيط الأول n_splits عدد صحيح لتحديد عدد الأجزاء folds وهي افتراضية في sklearn من 3 إلى 5. الوسيط الثاني shuffle تأخذ قيمه بوليانية عند وضعها True تقوم بعمل خلط عشوائي للبيانات وfalse عكس ذلك. الوسيط الثالث random_state للتحكم بآلية التقسيم. نفس الأمر في Kfolds مرور حلقة حيث يتم استخدام اثنين من الاندكسات في الحلقة للمرور على التدريب والاختبار وتحوي skf.split(X) هذه الاندكسات . نقوم بطباعة الاندكس للتدريب والاختبار في كل محاوله وبعدها تخزين التدريب والاختبار. ومن ثم طباعة كل منها. #استدعاء المكتبات from sklearn.model_selection import StratifiedKFold #تشكيل الداتا الدخل والخرج X = np.array([[1, 2], [3, 4], [5, 6], [7, 8]]) y = np.array([1, 0, 1, 0]) #StratifiedKFold skf = StratifiedKFold(n_splits=2, shuffle=False, random_state=None) for train_index, test_index in skf.split(X, y): print("TRAIN:", train_index, "TEST:", test_index) X_train, X_test = X[train_index], X[test_index] y_train, y_test = y[train_index], y[test_index] print('X_train:\n '+str(X_train),end='\n\n') print('X_test:\n '+str(X_train),end='\n\n') print('y_train:\n '+str(X_train),end='\n\n') print('y_test:\n '+str(X_train),end='\n\n')1 نقطة
-
المشكلة في قيم معامل التنعيم C حيث أن القيم المسموح بها هي القيم الموجبة تماماً أي الأكبر تماماً من الصفر، وأنت تحاول تجريب القيمة C=0 وهذا سينتج عنه خطأ. لحل المشكلة يمكنك إعطاء C قيمة متناهية في الصغر بحيث تكون مهملة (أي وكأنها صفر) : from sklearn.svm import SVR from sklearn.datasets import load_boston from sklearn.model_selection import train_test_split from sklearn.model_selection import GridSearchCV import pandas as pd BostonData = load_boston() X = BostonData.data y = BostonData.target X_train, X_test, y_train, y_test = train_test_split(X, y, test_size=0.2, random_state=0, shuffle =True) SelectedModel = SVR() Selected = {'kernel':('linear', 'rbf'),'C': [0.000001, 0.7, 8]} GridSearchModel = GridSearchCV(SelectedModel,Selected, cv = 2,return_train_score=True) GridSearchModel.fit(X_train, y_train)1 نقطة
-
السلام عليكم.. مرحبا, عندنا مشروع كامل بـ Laravel مع MySQL, والان نريد اضافة حقول و جداول جديدة في المشروع بعد عدة اشهر في Production, و المشكلة الان يوجد الاف ريكورد في Database. اعرف اذا بدنا نزيد حقل مثلا في جدول users نكتب: php artisan make:migration add_phone_to_users --table=users ثم php artisan migrate هنا السؤال: نحن كالمبرمج في Development mode عشرات مرات نكتب: php artisan migrate:fresh --seed لغرض Testing و Debugging, لكن بعد ما يوجد ريكوردات حقيقة و اضفنا حقول و جداول جديدة كيف نعمل fresh او refresh ؟ بدون فقد ريكوردات حقيقية ؟ شكرا..1 نقطة
-
أظن أن من الخطأ إستعمال نفس قواعد البيانات للتحقق Testing و حل المشاكل Debugging , بهاته الطريقة ستكون البيانات الحقيقية عرضة للفقدان كليا . الطريق الأقصر : و هي الإستعانة بالكثير من الحلول البديلة من مثل : تحضير نسخ إحتياطية Backups لقواعد البيانات قبل تجربة التطبيق أو قبل تحديث التهجير لقواعد البيانات , ثم إعادة التهجير بعد التحقق . تحضير نسخة إحتياطية تجريبية للتطبيق , يمكن إستعمال حزم من مثل laravel-backup من مجموعة spatie لعمل ذلك و التجربة عليه . لكن الأفضل ,و الطريق الأطول, يكون بفصل عملية التحقق Testing بشكل كامل عن نفس إتصال قواعد البيانات الذي يستخدمه تطبيقك . و لارافيل تجعل ذلك سهلا مع phpunit . فعلى سبيل المثال : إن كان تطبيقك يستخدم Mysql فعمليات التحقق يجب أن تستخدم ذاكرة مؤقتة و إتصال sqlite . و إن لم يتم كتابة الاختبارات Tests بشكل إما مواز أو مسبق للأكواد فسيجب لتحقيق هذا كتابة الإختبارات اللازمة لكل أجزاء التطبيق حتى يتم تحقيق هذا الأخير و إختبار التطبيق نفسه , لا نسخة إحتياطية منه ,في بيئة التطوير أو الإنتاج و بدون أي فقد لأية بيانات .1 نقطة
-
هو أداة تستخدم لتنظيف البيانات أو معالجة البيانات قبل عملية التدريب، يستخدم في عملية تحديد وجود قيم مفقودة في البيانات حيث يرد مصفوفة بوليانية كل عمود فيها يمثل عمود في البيانات وتحوي فقط الأعمدة التي تحوي قيم مفقودة أي في حال وجود عمود لا يحوي قيم مفقودة لا يقوم بإعطاء عمود له في المصفوفة أما عند وجود قيمة مفقودة في عمود ما يتم إضافة عمود إلى المصفوفة تكون كل قيمه True و مكان القيمة المفقودة false. يتم استخدامه عبر الموديول: sklearn.impute #استدعاء المكتبات: from sklearn.impute import MissingIndicator في البداية قمنا باستدعاء المكتبة التي يوجد فيها MissingIndicator. #الشكل العام MissingIndicator: MI=MissingIndicator(missing_values=nan, features='missing-only', sparse='auto') الوسيط الأول missing_values القيمة المفقودة أي القيمة التي سوف يتم البحث عنها في البيانات و في كثير من الأمثلة تكون القيمة المفقودة Nan أو 0. الوسيط الثاني features في حال كان هذا الوسيط يساوي missing-only بتالي سوف يتم طباعة المصفوفة البوليانة كما ذكرنا سابقا في تعريف MissingIndicator أما في حال all فسوف يتم طباعتها بالكامل مع كافة الأعمدة التي تحوي قيم مفقودة ولا تحوي قيم مفقودة. الوسيط الثالث sparse يتحكم في طباعة المصفوفة إذا كان auto تكون المصفوفة مثل مصفوفة الدخل واذا كان false سوف تكون المصفوفة كاملة أيضا إذا كان true فسوف تكون المصفوفة بدون الميزات التي لا تحوي قيم مفقودة لذلك يتم وضعه auto لترك MissingIndicator يقرر المناسب. طريقة استخدامه: MI=MissingIndicator(missing_values=nan, features='missing-only', sparse='auto') MI.fit_transform(X) حيث الدالة fit_transform يوجد ضمنها جميع العمليات الداخلية لعملية حساب القيم و تطبيقها على البيانات. لنأخذ مثال يوضح MissingIndicator. #استدعاء المكتبات import numpy as np from sklearn.impute import MissingIndicator #تعين داتا دخل مزيفة X = np.array([[np.nan, 2, 3], [0, 1, np.nan], [8, 3, 0]]) #طباعة القيم الناتجه لمعرفة مكان القيم المفقوده MI=MissingIndicator(missing_values=np.nan, features='missing-only',sparse=False) MI.fit_transform(X) #النتيجة array([[ True, False], [False, True], [False, False]])1 نقطة
-
هي أداة نستخدمها لتطبيق العديد من المعاملات العليا hyperparameters على نموذجنا، لتجريبها و اختيار الأفضل منها. يتم استخدامها عبر الموديول: model_selection.GridSearchCV خطوات تنفيذها: 1. استيراد المكتبة. from sklearn.model_selection import GridSearchCV 2. استيراد الموديل المطلوب فحصه وإنشاؤه. 3. عمل قاموس بحيث يكون فيه المفتاح هو اسم الـ parameter و القيمة هي القيم المطلوب تجريبها له. 4. تنفيذ GridSearchCV حيث نمرر له الموديل المطلوب تنفيذه و القاموس الذي يحوي مانريد نتجريبه. 5. ثم إظهار النتائج عبر عدد من الـ attributes التي سنوردها في المثال (ستكون كل الأمور واضحة جداً) . حيث يجرب GridSearchCV جميع مجموعات القيم التي تم تمريرها في القاموس ويقيم النموذج لكل مجموعة باستخدام طريقة Cross-Validation. ومن ثم، بعد استخدام هذه الوظيفة ، نحصل على الدقة / الخسارة لكل مجموعة من المعلمات العليا ويمكننا اختيار الأفضل أداءً. الصيغة: sklearn.model_selection.GridSearchCV(estimator, param_grid, scoring=None, n_jobs=None, cv=None, verbose=0, return_train_score=False) 1.estimator: النموذج الذي تريد التحقق من المعلمات العليا الخاصة به. 2.params_grid: كائن القاموس الذي يحتوي على المعلمات العليا التي تريد تجربتها. 3-scoring: مقياس التقييم الذي تريد استخدامه. 4.cv: عدد عمليات التحقق المتبادل التي يجب أن تجربها لكل مجموعة مختارة من المعلمات العليا. 5. overbose: يمكنك ضبطه على 1 للحصول على نسخة مطبوعة مفصلة أثناء ملائمة البيانات لـ GridSearchCV . 6.n_jobs: عدد العمليات التي ترغب في تشغيلها بالتوازي لهذه المهمة إذا كانت -1 ستستخدم جميع المعالجات المتاحة. الوسيط الأخير إذا كان False، فلن تتضمن السمة cv_results_ ال score للتدريب. مثال: from sklearn.svm import SVR from sklearn.datasets import load_boston from sklearn.model_selection import train_test_split from sklearn.model_selection import GridSearchCV import pandas as pd # تحميل البيانات BostonData = load_boston() X = BostonData.data y = BostonData.target # تقسيم البيانات X_train, X_test, y_train, y_test = train_test_split(X, y, test_size=0.2, random_state=0, shuffle =True) #تطبيق GridSearchCV SelectedModel = SVR() ''' :نحدد الآن في القاموس التالي مايلي 1. المفاتيح التي تمثل المعاملات العليا المطلوب إجراء التجريب عليها 2.القيم المراد اختبارها من أجل كل مفتاح لاحظ أننا حددنا للكيرنل قيمتين ليتم تجريبهم وهم linear و rbf :وحددنا للإبسلون القيم التالية 0.1 0.2 0.3 ''' Selected = {'kernel':('linear', 'rbf'), 'epsilon':[0.1,0.2,0.3]} GridSearchModel = GridSearchCV(SelectedModel,Selected, cv = 2,return_train_score=True) # للبدأ بالتدريب GridSearchModel.fit(X_train, y_train) sorted(GridSearchModel.cv_results_.keys()) GridSearchResults = pd.DataFrame(GridSearchModel.cv_results_)[['mean_test_score', 'std_test_score', 'params' , 'rank_test_score' , 'mean_fit_time']] # عرض النتائج print('All Results :', GridSearchResults ) # عرض أفضل نتيجة print('Best Score is :', GridSearchModel.best_score_) # عرض أفضل المعاملات العليا print('Best Parameters :', GridSearchModel.best_params_) #Estimator عرض أفضل print('Best Estimator :', GridSearchModel.best_estimator_) # الخرج ''' All Results : mean_test_score std_test_score params \ 0 0.744228 0.009539 {'epsilon': 0.1, 'kernel': 'linear'} 1 0.234970 0.049682 {'epsilon': 0.1, 'kernel': 'rbf'} 2 0.743469 0.009218 {'epsilon': 0.2, 'kernel': 'linear'} 3 0.232345 0.049925 {'epsilon': 0.2, 'kernel': 'rbf'} 4 0.744154 0.009648 {'epsilon': 0.3, 'kernel': 'linear'} 5 0.231108 0.053474 {'epsilon': 0.3, 'kernel': 'rbf'} rank_test_score mean_fit_time 0 1 0.956472 1 4 0.001997 2 3 1.818950 3 5 0.002998 4 2 1.063380 5 6 0.002010 Best Score is : 0.7442279764447716 Best Parameters : {'epsilon': 0.1, 'kernel': 'linear'} Best Estimator : SVR(C=1.0, cache_size=200, coef0=0.0, degree=3, epsilon=0.1, gamma='scale', kernel='linear', max_iter=-1, shrinking=True, tol=0.001, verbose=False) ''' مثال آخر: # استيراد المكتبات import sklearn from sklearn.svm import SVC from sklearn.model_selection import GridSearchCV from sklearn.model_selection import train_test_split from sklearn.datasets import load_breast_cancer from sklearn.metrics import classification_report, confusion_matrix from sklearn.datasets import load_breast_cancer # تحميل بياناتك dataset = load_breast_cancer() X=dataset.data Y=dataset.target # تقسيمها X_train, X_test, y_train, y_test = train_test_split(X,Y,test_size = 0.2, random_state = 1) # تحديد مانريد اختباره param_grid = {'C': [0.1, 0.7, 8], 'gamma': [1, 0.1, 0.01, 0.0001], 'gamma':['scale', 'auto'], 'kernel': ['linear','rbf']} #GridSearchCV إنشاء ال grid = GridSearchCV(SVC(), param_grid, refit = True,cv=2) # بدأ التدريب والتجريب grid.fit(X_train, y_train) # عرض أفضل المعاملات print(grid.best_params_) # توقع القيم grid_predictions = grid.predict(X_test) #classification_report عرض ال print(classification_report(y_test, grid_predictions)) ''' {'C': 0.1, 'gamma': 'scale', 'kernel': 'linear'} precision recall f1-score support 0 1.00 0.86 0.92 42 1 0.92 1.00 0.96 72 accuracy 0.95 114 macro avg 0.96 0.93 0.94 114 weighted avg 0.95 0.95 0.95 114 '''1 نقطة
-
origin هي إختصار لرابط المُستودع البعيد و يتم تخزينه عند تنفيذ الأمر: git remote add origin https://... كما يُمكن تعديل الرابط إنطلاقاً من الأمر التالي: git remote set-url origin new.git.url/here يٌعتبر master فرع من الفروع في المستودع. لمعرفة الفروع الموجودة في المستودع: git branch #local branches git branch -r #remote branches git branch -a #all branches لإنشاء فرع و تغيير المُؤشر نحوه: git checkout -b <branch-name> # Create a new branch and check it out كما بالإمكان إنشاء فرع دون تغيير المُؤشر أي البقاء في الفرع الحالي: git branch new_branch و لتغيير المؤشر لفرع ما نستخدم: git checkout <branch-name> لدفع التغييرات على الملفات من فرع محلي إلى فرع في المستودع نستخدم: git push <remote-name> <branch-name> حيث يكون <remote-name> هو origin و <branch-name> إسم الفرع المحلي. حيث أن صيغة الأمر هي بالشكل التالي: git push <remote-name> <local-branch-name>:<remote-branch-name> إذا لم تُحدد إسم الفرع البعيد فسيتم إعتبار إسم الفرع البعيد هو نفس الفرع المحلي وإن لم يكن موجود سيتم إنشاؤه.1 نقطة
-
بالطبع يفضل الإلتزام بالترتيب حيث توجد بعض الدروس التي تعتمد على الدروس السابقة فمثلاً عند دراسة المسار " قواعد البيانات " يجب عليك على الأقل دراسة المسار " أساسيات البرمجة " لذلك معظم الدروس مرتبطة ببعضها وبرما تكون هناك دروس غير مرتبطة بما قبلها ولكن حتى لا تفوت عليك بعض المعلومات يجب عليك الإلتزام بالترتيب إلا في حالة أنك على علم بأحد المسارات وقد درسته دراسة وافية وأيضاً لا يفضل ذلك1 نقطة
-
تكون الأرباح معلقة بينك وبين العميل لفترة حتى يضمن الموقع انه لن يشتكي احد من خداع او ما شابه ولكن لماذا فترة 14 يوم تحديدا لماذا لا تكون اسبوع واحد لا أدري1 نقطة
-
ما هي الطريقة الأكثر فاعلية لتعيين دالة map على مصفوفة numpy؟ الطريقة التي كنت أقوم بها في مشروعي الحالي هي كما يلي: import numpy as np arr = np.array([0, 1, 2, 3, 4, 5]) arr_squarer = lambda t: t ** 2 squares = np.array([arr_squarer (i) for i in arr_squarer]) لكن أعتقد أن هذه الطريقة غير عملية على الإطلاق، هل توجد طريقة أفضل للقيام بذلك من خلال مكتبة numpy فقط1 نقطة
-
يتم استخدامه عبر الموديول: sklearn.impute #استدعاء المكتبات: from sklearn.impute import KNNImputer في البداية قمنا باستدعاء المكتبة التي يوجد فيها KNNImputer. #الشكل العام KNNImputer: imputerKNN=KNNImputer(missing_values=nan, n_neighbors=5, weights='uniform',metric='nan_euclidean', copy=True) الوسيط الأول missing_values القيمة المفقودة أي القيمه التي سنضع مكانها ما ينوب عنها وفي كثير من الأمثلة تكون القيمه المفقودة Nan أو 0. الوسيط الثاني n_neighbors عدد الجيران الذي سيتم حساب القيمة المتوسطة لهم من أجل عينة تحوي قيمة مفقودة. الوسيط الثالث weights هذا الوسيط يحدد الأساس الذي سيسير عليه KNNImputer حيث يأخذ قيمتين هي ‘uniform’ حيث تعني أن الجار القريب أو البعيد لهم نفس التأثير أي لا يفرق أحدهما في عملية حساب القيمة المتوسطة أما ‘distance’ هنا يتم اعتماد المسافة كعامل تقييم أي الاقرب مسافة إلى المثال الذي يتم التنبؤ بقيمته بتالي سوف يكون تأثير الجار ذو المسافة الأقل أكبر من الجار ذو المسافة الأبعد الوسيط الرابع metric مقياس المسافة للبحث عن الجيران. الوسيط الخامس copy عند وضع هذا الوسيط True يتم أخذ نسخه من البيانات false عكس ذلك أي يتم التطبيق على البيانات الاصلية. مثال: #استدعاء المكتبات import numpy as np from sklearn.impute import KNNImputer #تعين داتا دخل مزيفة X = [[3, 4, np.nan], [3, 4, 3], [np.nan, 1, 2], [8, 8, 7]] #طباعة القيم بعد عملية التنظيف imputerKNN= KNNImputer(n_neighbors=2) imputerKNN.fit_transform(X) #النتيجة array([[3. , 4. , 2.5], [3. , 4. , 3. ], [3. , 1. , 2. ], [8. , 8. , 7. ]]) حيث الدالة fit_transform يوجد ضمنها جميع العمليات الداخلية لعملية حساب القيم و تطبيقها على البيانات.1 نقطة
-
QDA(Quadratic Discriminant Analysis) هو طريقة تستخدم في تقليل الأبعاد وخاصة في مسائل التصنيف التابعة بالتعليم بإشراف فلو كان لدينا عملية تصنيف ما لأكثر من صنف هو نفس LDA الفرق الوحيد أن LDA عملية الفصل لديه خطية أما QDA مربعة، ويمكن استخدامه كموديل للتنصيف. يتم استخدامه عبر الموديول: sklearn.discriminant_analysis استدعاء المكتبات: from sklearn.discriminant_analysis import QuadraticDiscriminantAnalysis في البداية قمنا باستدعاء المكتبة التي يوجد فيها هذا الموديل. الشكل العام للموديل: QDA=QuadraticDiscriminantAnalysis(priors=None, reg_param=0.0, tol=0.0001) الوسيط الأول priors قيم الاحتمالات للصفوف أي تساوي عدد الصفوف يمكن تمريرها كمصفوفة تحوي الاحتمال لكل صف. الوسيط الثاني reg_param يمثل معامل التنعيم. الوسيط الثالث tol مقدار التسامح في التقارب من القيم الدنيا. طبعا قمت بشرح الشكل العام للموديل ولكن عن طريقة استخدامه سهل جدا فقط بعد أن تقوم بتقسيم الداتا إلى X_train, y_train,X_test, y_test تسطيع كتابة الأتي لعملية التدريب. #الشكل العام للموديل QDA=QuadraticDiscriminantAnalysis( priors=None, reg_param=0.0,tol=0.0001) QDA.fit(X_train, y_train) حيث الدالة fit يوجد ضمنها جميع العمليات الداخلية لعملية التدريب. يوجد دالة أخرى تستخدم لغرض التنبؤ كالاتي: #حساب القيم المتوقعة y_pred =َQDA.predict(X_test) نستطيع حساب دقة الموديل أو كفاءته على التدريب والاختبار عن طريق التابع score ويكون وفق الشكل: # حساب الكفاءه على الاختبار والتدريب print('QDA Train Score is : ' , QDA.score(X_train, y_train)) print('QDA Test Score is : ' , QDA.score(X_test, y_test)) لنأخذ مثال يوضح المصنف: قمنا باستدعاء المكتبات وبناء عينة مزيفه وكان التصنيف ثنائي أما 1 أو 0. ثم قمنا بتجريب الموديل على عينة معطاة. # استدعاء المكتبات import numpy as np from sklearn.discriminant_analysis import QuadraticDiscriminantAnalysis #تعين داتا دخل مزيفة X = np.array([[1, 1], [3, 1], [-3, -2], [-1, -1], [-3, -1], [3, 2]]) y = np.array([1, 0, 0, 1, 1, 1]) #بناء الموديل QDA = QuadraticDiscriminantAnalysis() QDA.fit(X,y) #طباعة تصنيف العينه print(QDA.predict([[-1, -0.4]])) #النتيجة #[1]1 نقطة
-
في الواقع هناك العديد من الطرق لتسريع تحميل الصورة و الأيقونات أهمها: تغيير حجم الصور قبل استخدامها ضغط الصور لتوفير حجم أكبر استخدم CDN لتضمين صورك ومحتوياتك الأخرى تفعيل التخزين المؤقت في المتصفح الخاصبك إذا طبقت كل هذا ومازال تحميل الصور و الأيقونات فأنصحك تغببر الإستضافة وإختيار إستضافة أسرع إذا كان لديك مضيف ويب بأوقات استجابة بطيئة ، فهذه النصائح لن تفيدك في شيء, أي أن سرعة موقعك ستتأثر دائمًا بأداء مضيفك. لذلك ، إذا كنت قد نفذت كل شيء أعلاه وما زلت تشعر بخيبة أمل بسبب أوقات تحميل الموقع مع الصور والأيقونات، فقد يكون الوقت قد حان للتغلب على المشكلة والتحول إلى مزود استضافة متميز. أو إذا كنت تبحث عن خيارات أرخص لكنها لا تزال فعالة ، فأنا من أشد المعجبين بـ SiteGround.1 نقطة
-
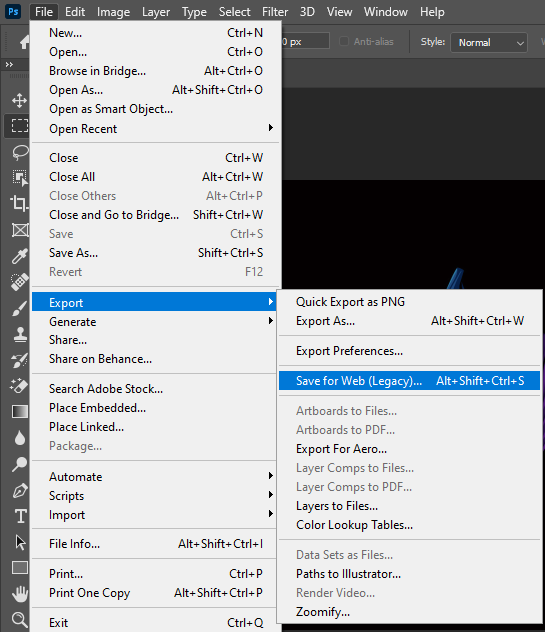
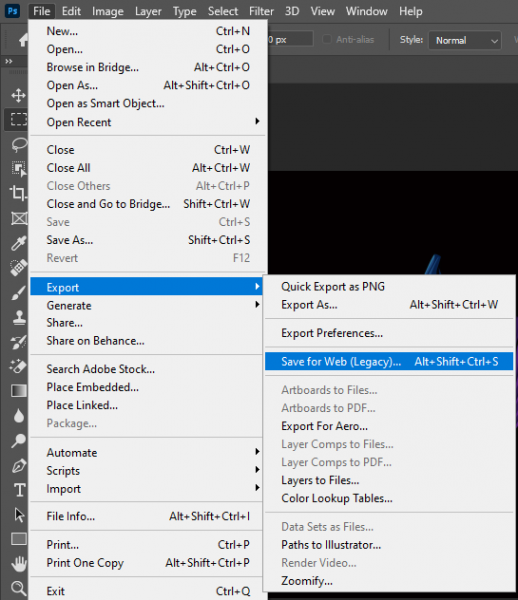
مشكلة عدم تحميل الصور بشكل سريع هو سبب حجم الصورة الكبير والذي يأخذ وقت طويل في تحميل الصورة, ولكن ما الحل؟ الحل لهذه المشكلة هو استخدام صور لها حجم قليل ومناسبة للعرض في الموقع بحيث يتم تحميل الموقع بطريقة سريعة ولا يأخذ وقت لتحميلها, من هذه الطرق استخدام الفوتوشوب لحفظ الصورة لاستخدام الويب, سوف تجدا هذا الخيار عند استخدامك للفوتوشوب ويمكنك الوصول اليه كما في الصورة التالية أما بالنسبة لتحميل الأيقونات المتأخر فهو يحدث بسبب اما انك تستخدم رابط cdn الذي من الممكن يؤخر عملية تحميل الأيقونات , أو انك تستخدم ملف حجمه كبير بعض الشيء ولذلك تجد بعض التأخير في تحميل الأيقونة, وأيضا لا ننسى ان السبب قد يكون السيرفر الذي رفعت عليه ملفاتك فربما يكون بطيء
 1 نقطة
1 نقطة -
LDA(Linear Discriminant Analysis) هي طريقة تستخدم في تقليل الأبعاد وخاصة في مسائل التصنيف التابعة بالتعليم بإشراف فلو كان لدينا عملية تصنيف ما لأكثر من صنف وكان تمثيل الداتا بالمستوى ثنائي الابعاد فالخط المستقيم يمكن أن يكون غير كافي في عملية الفصل لذلك يتم استخدام LDA ليقوم بتحويل المستوي ثنائي الابعاد إلى أحادي الأبعاد. ويمكن استخدامه كموديل للتنصيف. يتم استخداه عبر الموديول: sklearn.discriminant_analysis استدعاء المكتبات: from sklearn.discriminant_analysis import LinearDiscriminantAnalysis في البداية قمنا باستدعاء المكتبة التي يوجد فيها هذا الموديل. # الصيغة المبسطة للموديل: LDA=LinearDiscriminantAnalysis(solver='svd', shrinkage=None, priors=None, n_components=None, tol=0.0001) الوسيط الأول solver يمثل طريقة الحل ويأخذ ثلاث قيم {‘svd’, ‘lsqr’, ‘eigen’} الوسيط الثاني shrinkage معامل تنعيم يستخدم لتحسين تقدير المصفوفات في حال كان عدد عينات التدريب صغير وعدد الميزات كبير الوسيط الثالث priors قيم الاحتمالات للصفوف أي تساوي عدد الصفوف يمكن تمريرها كمصفوفة تحوي الاحتمال لكل صف الوسيط الرابع n_components هو عدد حقيقي أو صحيح يشير إلى عدد المكونات التي سيتم الإبقاء عليها المقصود بالمكونات أٌقل عدد أمثلة وعدد الفيتشرز وإذا أخذ None يتم الاحتفاظ بجميع المكونات الوسيط الخامس tol مقدار التسامح في التقارب من القيم الدنيا طبعا قمت بشرح الشكل العام للموديل ولكن عن طريقة استخدامه سهل جداً فقط بعد أن تقوم بتقسيم الداتا إلى X_train, y_train,X_test, y_test تسطيع كتابة الأتي لعملية التدريب # الشكل العام للموديل: LDA=LinearDiscriminantAnalysis(solver='svd', shrinkage=None, priors=None, n_components=None, tol=0.0001 ) LDA.fit(X_train, y_train) حيث الدالة fit يوجد ضمنها جميع العمليات الداخلية لعملية التدريب. يوجد دالة أخرى تستخدم لغرض التنبؤ كالاتي.. #حساب القيم المتوقعة: y_pred =LDA.predict(X_test) نستطيع حساب دقة الموديل أو كفاءته على التدريب والاختبار عن طريق التابع score ويكون وفق الشكل: حساب الكفاءة على الاختبار والتدريب: print('LDA Train Score is : ' , LDA.score(X_train, y_train)) print('LDA Test Score is : ' , LDA.score(X_test, y_test)) لنأخذ مثال يوضح المصنف.. قمنا باستدعاء المكتبات وبناء عينة مزيفة وكان التصنيف ثنائي أما 1 أو 0. ثم قمنا بتجريب الموديل على عينة معطاة. استدعاء المكتبات import numpy as np from sklearn.discriminant_analysis import LinearDiscriminantAnalysis #تعين داتا دخل مزيفة X = np.array([[1, 1], [3, 1], [-3, -2], [-1, -1], [-3, -1], [3, 2]]) y = np.array([0, 0, 1, 1, 0, 1]) #بناء الموديل LDA = LinearDiscriminantAnalysis() LDA.fit(X,y) #طباعة تصنيف العينه print(LDA.predict([[-1, -0.4]])) #النتيجة #[0]1 نقطة
-
بس الكود في الصورة شغال ولا يوجد أي مشكلة احتمال تكون المشكلة في إعدادات الانتينا1 نقطة
-
الخطأ الذي ظهر لك هو نتيجة غير مباشرة لاستخدامك نموذج توقع ك base_estimator في نموذج BaggingClassifier، حيث أن المهمة التي تعمل عليها هي مهمة تصنيف والنموذج BaggingClassifier هو نموذج تصنيف وتحاول استخدام نموذج SVR وهو نموذج توقع ك base_estimator وهذا خاطئ، يجب استخدام نموذج تصنيف حصراً ك base_estimator. لإصلاح الأمر استخدم نموذج تصنيف مثل SVC أو قم بضبط ال base_estimator على None.1 نقطة
-
تحياتي هل يعني هذا انه في حال لم يقبل صاحب المشروع استلام العمل ان الطلب يكون مفتوح وقيد التنفيذ الي ما شاء الله ام هناك قيد زمني مثل خمسات يتم استلام الطلب تلقائيا علما ان هناك اصحاب مشاريع لا يدخلون الي الموقع بعد طلب المشروع؟1 نقطة
-
 هل فكّرت من قبل كيف لك أن تبدع في العمل الحر؟ إن العمل الحر ليس بالوظيفة التقليديّة، فإن حدث وسلكت طريق العمل الحرّ، ستكتشف بأن المستقلين هم على قدر عال من الإبداعيّة والإنتاجيّة وبشكل أكبر منه من هؤلئك الذين يعملون في المكاتب والشركات، حيث يملك المستقل حرية مطلقة على عكس القيود المفروضة في الوظائف الاعتيادية. أنت كمستقل يمكنك أن تعمل من أي مكان، وفي أي وقت: في مكتبك المنزلي، أو في المقهى الذي تحبه، أو حتى في غرفة نومك، لا يهم أيًا كان المكان فقط اختر ما يُناسبك، فهذه الحريّة والاستقلالية هي هِبَة لا تقدّر بثمن، ولكنّها ليست مجانية وعليك دفع الثمن، فأنت كمستقل ومطوّر مواقع، عليك التعامل مع مختلف العقليات، أيضًا الالتزام بمواعيد محدّدة، والأهم التعامل مع العدو اللدود للمستقل وهو التسّويف. ما الذي ستفعله لتصبح ذلك المستقل الحذق والذي يعرف من أن أين تؤكل الكتف وليكون لك نصيب الأسد في هذا الدرب؟ هذا هو لب وجوهر المقال، إليك أبرز الأفكار: مواقع العمل الحر والاختيار فيما بينهالا يُمكن لك أن تعمل بمجال العمل الحر من دون الاعتماد على نظامٍ/موقع يسمح لك بالحصول على المزيد من العملاء/الزبائن، فمواقع البحث عن الوظائف أصبحت كثيرة والاختيار بينها قد لا يكون بالأمر السهل، حيث يوجد العديد من منصات العمل الحر، لذا اختر بعناية، يوجد هنا في الأكاديمية مقالة مفصّلة تتحدّث عن أبرز مواقع العمل الحر اطلع عليها ربما تجد ضالتك في اختيار الأنسب. السير على روتين معينفي رياضة كرة السلّة، أفضل منفّذي الرمية الحرّة free-throw هم الذين يتبعون روتين محدّد في الرمي، حيث يسمح هذا الروتين للرامي بالتركيز وتجهيز الحالة الذهنية للتفكير في أنه يُسدّد رمية حرّة وليس أي رمية. حقوق الصورة Kate Parker يُمكن تطبيق نفس الأمر في عالم العمل الحر، حيث سيساعد السير على روتين يومي خاص بمهامك على زيادة الإنتاجيّة، عند طريق تحضير الحالة الذهنية وحثها على العمل، وبالإضافة إلى ذلك، ستكون قادرًا على إدارة وقتك بالشكل الأمثل والملائم، وعليه ضع أهداف ورتّبها تبعًا إلى الضرورة والأهمية، ووازن بين المهام وحكّم عقلك وخبرتك فيما يجب الانتهاء منه أوّلًا. اهتم بالأولوياتحدّد المشاريع التي يجب الانتهاء منها أولًا وما هي المشاريع الأكثر أهمية والتي يجب أن تعطيها القدر الكافي من الوقت، ولا تركّز على مشروع واحد فقط، بل حاول العمل على المهام التي تريد أن تنجزها أولًا. هل سمعت من قبل بمبدأ ‹‹بَرِتو›› Pareto Principle أو قاعدة 80-20؟ ربما عليك استخدام هذه الأسلوب الذي يَنصح به الكثير في الإدارة والتنظيم والذي قد يَصب في مصلحتك ومصلحة عملائك. تَفترض هذه القاعدة أو النظرية على أن 80% من النتائج ينتج من 20% من المُسببات، بمعنى أن 80% من أسباب تأخّر مشاريعك يأتي من 20% من العمل على مشاريع لا تستطيع الانتهاء منها، أو بمعنى آخر، يُستخدم 80% من الوقت في إنجاز ما قدره 20% من المشروع، وعلى الجهة الأخرى، يكفي استغلال 20% من الوقت لإنجاز 80% من المشروع. وعليه وفي المرة المقبلة التي تقبل فيها مشروع، فكّر في صعوبة إنجاز المشروع وما هو الوقت المقدّر لإنهائه، ومن ثم احسب كم ستكسب لقاء هذا التعب والجهد، وعندها ستحدّد النتيجة أولوية المشروع. حقوق الصورة Amy ملاحظات هامّة: ابدأ بالمشروع الأسهل، وبذلك ستنتهي منه بدل أن تقضي وقتًا كبيرًا على مشروع صعب يستهلك معظم الوقت. قم بإنهاء المشاريع ذات الموعد النهائي الأقرب. ركّز على المشاريع التي تحبّذ العمل عليها. اختر بين العمل ليلا أو نهاراهل أنت شخص يُفضّل العمل في وضح النهار أم في عُتمة الليل؟ فبعض الأشخاص يجد في الصباح الحماس والنشاط، بينما يجد البعض الآخر في عُتمة الليل عزلة فكرية من نوع خاص تدفع بهم نحو الإنتاجيّة، لا أنصح بوقت دون الآخر، ولكن من المهم الاختيار والتزام بغض النظر عما قد تختاره، يُمكنني القول إن الأمر بالمجمل هو من المحاسن، لأن معظم الوظائف الاعتياديّة لا تقدّم هذا النوع من المرونة من الأساس كل ما هنالك عليك التعامل مع التشتت الحاصل عند العمل في وضح النهار، لذا عليك المقاومة والعمل بجد لمقاومة هذا التشتت. حقوق الصورة Sam Javanrouh لذا اختر ولا تضيّع وقتك من دون تنظيم وتحديد ساعات الإنتاجيّة المثاليّة الخاصّة بك، وبذلك أنت تستثمر الوقت أفضل استثمار وتنجز أكثر وبمجهود أقل. حدد فترة زمنية لكل مشروعلا تهدر الوقت يُمنة ويُسرى، جدّوِلْ مهامك ومشاريعك، وخصّص لكل مشروع وقتًا محدّدًا وكافيًا من أجلك لتنهي ما يجب إنهاؤه، وبذلك ستعرف كم من الوقت ستحتاج لإنهاء المشاريع وبالقدر الكافي من الرعاية والاهتمام اللازمين، وإن حدث وفشلت في مجاراة الموعد النهائي وكنت تظن أن تمديد الفترة الزمنيّة سيؤثّر على باقي المشاريع، قم بتأجيله إلى حين الانتهاء من باقي المشاريع، وبذلك لن تقع في مطب "ضاع كل الوقت من دون إنجاز أي شيء". حقوق الصورة Sean MacEntee تجنب المشتتاتابتعد عن الملهيات عند ممارسة عملك اليومي، وبالأخص تلك الرغبة الملحة في معرفة من أرسل لك رسالة على تطبيقات التواصل الاجتماعي، من ‹‹فيس بوك›› و ‹‹واتساب›› WhatsApp، أو ألعاب العالم الافتراضي MMORPG، فهذه الأمور تبعدك عما يفترض بك التركيز عليه، وبالتالي عليك تحديد ما هي هذه المُتشتتات وتجنّبها بكل ما أوتيت من قوّة، وقد لا يكون الأمر سهلة في البداية، ولكن تذكّر أن جميع الأمور تبدو صعبةً من الوهلة الأولى وكل ما تحتاجه هو الإرادة فقط. استثمر أفكاركهل أصابك الإحباط من قبل وتَوقّفت مخيلتك عن ابتداع أي شيء فنّي تحتاجه لاستكمال المشروع؟ لا أخفيك هذه الحالة ليست باليسيرة، فأنت تواجه سد منيع وجدار مُصمت لا يتحرّك، ولكن ما الحلّ؟ كيف لك أن تنهي مشروعك (سواء كان تصميم أو كتابة إبداعية أو حتى ترجمة) باختصار شديد عليك: بتخزين الأفكار وتسطيرها outlining. تسطير الأفكار ما هو إلا وسيلة عمليّة لصون أفكارك الإبداعيّة للمشاريع اللاحقة، وتطبيق هذه الفكرة بسيطٌ للغاية: أولًا: عليك حمل أدواتك الكتابيّة حيثما ذهبت وحللت، استخدم قلم وورقة أو استخدم أحد التطبيقات في تدوين الملاحظات. ثانيًا: وعندما تجد نفسك محبطًا، استرح قليلًا، اشرب كأسًا من الشاي أو القهوة، أو تابع قناتك المفضّلة على يوتيوب، وإن خطر على بالك أي فكرة−والذي سيكون لا نقاش في ذلك− دونّه مباشرةً، أو ارسمه إن اقتضى الأمر، فبهذه الطريقة أنت تستثمر في "بنك أفكارك" إن جاز التعبير، وستسحب من هذا البنك عند الحاجة، وعلى مبدأ خبّي قرشك الأبيض ليومك الأسود. حقوق الصورة Marcio Eugenio صمم صفحة أعمال خاصة بك Portfolioلا يملك المستقلون شهادات مرجعية تُثبت قدراتهم في معظم الأحيان، ولا حتى اسمًا تجاريًا لتقديمه للعملاء، ولذلك قد يُشكّك بعض أصحاب المشاريع في خبرة بعض المستقلين، ولذلك على المستقل الحرص دائمًا على إنشاء صفحة أعمال، لتحتوي هذه الصّفحة على أعمال المستقل، ولكن مع الانتباه إلى تقديم أبرز الأعمال وليس كل الأعمال، وبهذه الطريقة وعندما يأتي أي زبون محتمل ليطلب قائمة بالأعمال السابقة، ستكون جاهزة ومُرتّبة وكل ما على المستقل هو إرسال العنوان URL إلى العميل، عندها سيدرك العميل جودة وخبرة المستقل. حقوق الصورة petermailloux.com خذ قسطا من الراحةإن الترويح عن النفس بين الحين والآخر أمرٌ ضروري لا شك في ذلك، فكما هو الأمر مع مواقع الإنترنت وحاجتها إلى مسح التخبئة cache بين الحين والآخر، وكما تحتاج أجهزة الحاسب إلى إعادة إنعاش refresh، أنت أيضًا كمُستقل تحتاج إلى راحة أيضًا، الأمر الذي سيجعلك أكثر إنتاجيّة تجاه المشروع، ناهيك عن الراحة الذهنية والنفسية. حقوق الصورة Steve Beckett زبدة الكلامتوجد صعوبات وتحديات في العمل الحرّ ولا يُمكن لأحد إنكار ذلك، ولكنك ستقطف ثمار جهدك المبذول في فك وحل هذه المشاكل، خاصة عندما تستخدم روتين معيّن، وتتجنّب المشتتات، ستجد نفسك تستمتع بالعمل كمستقل، وستجني أرباحًا تساوي أرباح الذي يعملون في المكاتب وبدوام كامل، هذا في البداية فقط، حيث أنك ستتفوّق عليهم بالأرباح بعد أن تصبح مُستقل ذكي ويعرف كيف يقتنص الفرص. ترجمة وبتصرّف للمقال How to Ace Your Freelancing Career لصاحبه Rudolph Musngi. حقوق الصورة البارزة: Designed by Freepik.1 نقطة
هل فكّرت من قبل كيف لك أن تبدع في العمل الحر؟ إن العمل الحر ليس بالوظيفة التقليديّة، فإن حدث وسلكت طريق العمل الحرّ، ستكتشف بأن المستقلين هم على قدر عال من الإبداعيّة والإنتاجيّة وبشكل أكبر منه من هؤلئك الذين يعملون في المكاتب والشركات، حيث يملك المستقل حرية مطلقة على عكس القيود المفروضة في الوظائف الاعتيادية. أنت كمستقل يمكنك أن تعمل من أي مكان، وفي أي وقت: في مكتبك المنزلي، أو في المقهى الذي تحبه، أو حتى في غرفة نومك، لا يهم أيًا كان المكان فقط اختر ما يُناسبك، فهذه الحريّة والاستقلالية هي هِبَة لا تقدّر بثمن، ولكنّها ليست مجانية وعليك دفع الثمن، فأنت كمستقل ومطوّر مواقع، عليك التعامل مع مختلف العقليات، أيضًا الالتزام بمواعيد محدّدة، والأهم التعامل مع العدو اللدود للمستقل وهو التسّويف. ما الذي ستفعله لتصبح ذلك المستقل الحذق والذي يعرف من أن أين تؤكل الكتف وليكون لك نصيب الأسد في هذا الدرب؟ هذا هو لب وجوهر المقال، إليك أبرز الأفكار: مواقع العمل الحر والاختيار فيما بينهالا يُمكن لك أن تعمل بمجال العمل الحر من دون الاعتماد على نظامٍ/موقع يسمح لك بالحصول على المزيد من العملاء/الزبائن، فمواقع البحث عن الوظائف أصبحت كثيرة والاختيار بينها قد لا يكون بالأمر السهل، حيث يوجد العديد من منصات العمل الحر، لذا اختر بعناية، يوجد هنا في الأكاديمية مقالة مفصّلة تتحدّث عن أبرز مواقع العمل الحر اطلع عليها ربما تجد ضالتك في اختيار الأنسب. السير على روتين معينفي رياضة كرة السلّة، أفضل منفّذي الرمية الحرّة free-throw هم الذين يتبعون روتين محدّد في الرمي، حيث يسمح هذا الروتين للرامي بالتركيز وتجهيز الحالة الذهنية للتفكير في أنه يُسدّد رمية حرّة وليس أي رمية. حقوق الصورة Kate Parker يُمكن تطبيق نفس الأمر في عالم العمل الحر، حيث سيساعد السير على روتين يومي خاص بمهامك على زيادة الإنتاجيّة، عند طريق تحضير الحالة الذهنية وحثها على العمل، وبالإضافة إلى ذلك، ستكون قادرًا على إدارة وقتك بالشكل الأمثل والملائم، وعليه ضع أهداف ورتّبها تبعًا إلى الضرورة والأهمية، ووازن بين المهام وحكّم عقلك وخبرتك فيما يجب الانتهاء منه أوّلًا. اهتم بالأولوياتحدّد المشاريع التي يجب الانتهاء منها أولًا وما هي المشاريع الأكثر أهمية والتي يجب أن تعطيها القدر الكافي من الوقت، ولا تركّز على مشروع واحد فقط، بل حاول العمل على المهام التي تريد أن تنجزها أولًا. هل سمعت من قبل بمبدأ ‹‹بَرِتو›› Pareto Principle أو قاعدة 80-20؟ ربما عليك استخدام هذه الأسلوب الذي يَنصح به الكثير في الإدارة والتنظيم والذي قد يَصب في مصلحتك ومصلحة عملائك. تَفترض هذه القاعدة أو النظرية على أن 80% من النتائج ينتج من 20% من المُسببات، بمعنى أن 80% من أسباب تأخّر مشاريعك يأتي من 20% من العمل على مشاريع لا تستطيع الانتهاء منها، أو بمعنى آخر، يُستخدم 80% من الوقت في إنجاز ما قدره 20% من المشروع، وعلى الجهة الأخرى، يكفي استغلال 20% من الوقت لإنجاز 80% من المشروع. وعليه وفي المرة المقبلة التي تقبل فيها مشروع، فكّر في صعوبة إنجاز المشروع وما هو الوقت المقدّر لإنهائه، ومن ثم احسب كم ستكسب لقاء هذا التعب والجهد، وعندها ستحدّد النتيجة أولوية المشروع. حقوق الصورة Amy ملاحظات هامّة: ابدأ بالمشروع الأسهل، وبذلك ستنتهي منه بدل أن تقضي وقتًا كبيرًا على مشروع صعب يستهلك معظم الوقت. قم بإنهاء المشاريع ذات الموعد النهائي الأقرب. ركّز على المشاريع التي تحبّذ العمل عليها. اختر بين العمل ليلا أو نهاراهل أنت شخص يُفضّل العمل في وضح النهار أم في عُتمة الليل؟ فبعض الأشخاص يجد في الصباح الحماس والنشاط، بينما يجد البعض الآخر في عُتمة الليل عزلة فكرية من نوع خاص تدفع بهم نحو الإنتاجيّة، لا أنصح بوقت دون الآخر، ولكن من المهم الاختيار والتزام بغض النظر عما قد تختاره، يُمكنني القول إن الأمر بالمجمل هو من المحاسن، لأن معظم الوظائف الاعتياديّة لا تقدّم هذا النوع من المرونة من الأساس كل ما هنالك عليك التعامل مع التشتت الحاصل عند العمل في وضح النهار، لذا عليك المقاومة والعمل بجد لمقاومة هذا التشتت. حقوق الصورة Sam Javanrouh لذا اختر ولا تضيّع وقتك من دون تنظيم وتحديد ساعات الإنتاجيّة المثاليّة الخاصّة بك، وبذلك أنت تستثمر الوقت أفضل استثمار وتنجز أكثر وبمجهود أقل. حدد فترة زمنية لكل مشروعلا تهدر الوقت يُمنة ويُسرى، جدّوِلْ مهامك ومشاريعك، وخصّص لكل مشروع وقتًا محدّدًا وكافيًا من أجلك لتنهي ما يجب إنهاؤه، وبذلك ستعرف كم من الوقت ستحتاج لإنهاء المشاريع وبالقدر الكافي من الرعاية والاهتمام اللازمين، وإن حدث وفشلت في مجاراة الموعد النهائي وكنت تظن أن تمديد الفترة الزمنيّة سيؤثّر على باقي المشاريع، قم بتأجيله إلى حين الانتهاء من باقي المشاريع، وبذلك لن تقع في مطب "ضاع كل الوقت من دون إنجاز أي شيء". حقوق الصورة Sean MacEntee تجنب المشتتاتابتعد عن الملهيات عند ممارسة عملك اليومي، وبالأخص تلك الرغبة الملحة في معرفة من أرسل لك رسالة على تطبيقات التواصل الاجتماعي، من ‹‹فيس بوك›› و ‹‹واتساب›› WhatsApp، أو ألعاب العالم الافتراضي MMORPG، فهذه الأمور تبعدك عما يفترض بك التركيز عليه، وبالتالي عليك تحديد ما هي هذه المُتشتتات وتجنّبها بكل ما أوتيت من قوّة، وقد لا يكون الأمر سهلة في البداية، ولكن تذكّر أن جميع الأمور تبدو صعبةً من الوهلة الأولى وكل ما تحتاجه هو الإرادة فقط. استثمر أفكاركهل أصابك الإحباط من قبل وتَوقّفت مخيلتك عن ابتداع أي شيء فنّي تحتاجه لاستكمال المشروع؟ لا أخفيك هذه الحالة ليست باليسيرة، فأنت تواجه سد منيع وجدار مُصمت لا يتحرّك، ولكن ما الحلّ؟ كيف لك أن تنهي مشروعك (سواء كان تصميم أو كتابة إبداعية أو حتى ترجمة) باختصار شديد عليك: بتخزين الأفكار وتسطيرها outlining. تسطير الأفكار ما هو إلا وسيلة عمليّة لصون أفكارك الإبداعيّة للمشاريع اللاحقة، وتطبيق هذه الفكرة بسيطٌ للغاية: أولًا: عليك حمل أدواتك الكتابيّة حيثما ذهبت وحللت، استخدم قلم وورقة أو استخدم أحد التطبيقات في تدوين الملاحظات. ثانيًا: وعندما تجد نفسك محبطًا، استرح قليلًا، اشرب كأسًا من الشاي أو القهوة، أو تابع قناتك المفضّلة على يوتيوب، وإن خطر على بالك أي فكرة−والذي سيكون لا نقاش في ذلك− دونّه مباشرةً، أو ارسمه إن اقتضى الأمر، فبهذه الطريقة أنت تستثمر في "بنك أفكارك" إن جاز التعبير، وستسحب من هذا البنك عند الحاجة، وعلى مبدأ خبّي قرشك الأبيض ليومك الأسود. حقوق الصورة Marcio Eugenio صمم صفحة أعمال خاصة بك Portfolioلا يملك المستقلون شهادات مرجعية تُثبت قدراتهم في معظم الأحيان، ولا حتى اسمًا تجاريًا لتقديمه للعملاء، ولذلك قد يُشكّك بعض أصحاب المشاريع في خبرة بعض المستقلين، ولذلك على المستقل الحرص دائمًا على إنشاء صفحة أعمال، لتحتوي هذه الصّفحة على أعمال المستقل، ولكن مع الانتباه إلى تقديم أبرز الأعمال وليس كل الأعمال، وبهذه الطريقة وعندما يأتي أي زبون محتمل ليطلب قائمة بالأعمال السابقة، ستكون جاهزة ومُرتّبة وكل ما على المستقل هو إرسال العنوان URL إلى العميل، عندها سيدرك العميل جودة وخبرة المستقل. حقوق الصورة petermailloux.com خذ قسطا من الراحةإن الترويح عن النفس بين الحين والآخر أمرٌ ضروري لا شك في ذلك، فكما هو الأمر مع مواقع الإنترنت وحاجتها إلى مسح التخبئة cache بين الحين والآخر، وكما تحتاج أجهزة الحاسب إلى إعادة إنعاش refresh، أنت أيضًا كمُستقل تحتاج إلى راحة أيضًا، الأمر الذي سيجعلك أكثر إنتاجيّة تجاه المشروع، ناهيك عن الراحة الذهنية والنفسية. حقوق الصورة Steve Beckett زبدة الكلامتوجد صعوبات وتحديات في العمل الحرّ ولا يُمكن لأحد إنكار ذلك، ولكنك ستقطف ثمار جهدك المبذول في فك وحل هذه المشاكل، خاصة عندما تستخدم روتين معيّن، وتتجنّب المشتتات، ستجد نفسك تستمتع بالعمل كمستقل، وستجني أرباحًا تساوي أرباح الذي يعملون في المكاتب وبدوام كامل، هذا في البداية فقط، حيث أنك ستتفوّق عليهم بالأرباح بعد أن تصبح مُستقل ذكي ويعرف كيف يقتنص الفرص. ترجمة وبتصرّف للمقال How to Ace Your Freelancing Career لصاحبه Rudolph Musngi. حقوق الصورة البارزة: Designed by Freepik.1 نقطة