كل الأنشطة
- الساعة الماضية
-
 Amr Ramadan3 اشترك بالأكاديمية
Amr Ramadan3 اشترك بالأكاديمية -
 My Oem اشترك بالأكاديمية
My Oem اشترك بالأكاديمية - اليوم
-
فهمت شكراا لحضرتكم
- 3 اجابة
-
- 2
-

-

-
الهدف النهائي من بناء نموذج في البرمجة أو في الذكاء الاصطناعي هو استخدام البيانات اللي عندنا عشان نساعد في اتخاذ قرارات أفضل وأسرع في الحياة اليومية أو في الأعمال. النموذج ده بيكون زي عقل إلكتروني بيفهم البيانات ويتعلم منها عشان يديك توقعات أو توصيات مفيدة. في الطب: النموذج يقدر يساعد الدكاترة في تشخيص الأمراض بسرعة وبدقة. في الأعمال: يقدر يتنبأ بمبيعات المنتجات عشان الشركات تعرف تخطط للمستقبل. في السيارات الذاتية القيادة: النموذج بيساعد العربية تفهم الطريق وتتجنب الحوادث. في التطبيقات اليومية: ممكن يساعدك تختار الأفلام أو الأغاني اللي ممكن تعجبك. يمكننا التكلم عن الفوائد بشكل مبسط في المثال الذي ذكرته(نموذج يتنبأ إذا كان الشخص مصابًا بمرض السكر أم لا): 1. الاكتشاف المبكر: النموذج يمكنه المساعدة في اكتشاف حالات السكر مبكرا، مما يمنح المريض فرصة لبدء العلاج بسرعة وتجنب المضاعفات. 2. توفير الوقت والجهد: بدلاً من أن يحتاج الطبيب إلى فحص جميع الأعراض وإجراء جميع الفحوصات بنفسه، يمكن للنموذج أن يساعده في الحصول على فكرة سريعة عما إذا كان المريض يحتاج إلى فحص أدق أم لا. 3. تحسين الرعاية الصحية: عندما يكون لدينا نماذج دقيقة، نستطيع توفير رعاية صحية أفضل للناس وتقليل عدد الحالات التي لا يتم اكتشافها أو تشخيصها بشكل خاطئ. 4. توفير الأموال: النموذج يمكنه توفير الأموال لأن الفحوصات المبكرة والعلاج المبكر يمكن أن يمنع مشاكل أكبر وأغلى في المستقبل. 5. البحث العلمي: هذه النماذج تساعد في الأبحاث العلمية لفهم الأمراض وأسبابها بشكل أفضل، مما يمكن أن يفتح لنا الباب لعلاجات جديدة. يعني الهدف الأساسي هو تحسين حياتنا وجعلها أسهل وأكثر فعالية من خلال استغلال قوة البيانات والتكنولوجيا. ببساطة، النموذج ليس مجرد أداة للتنبؤ، بل هو أيضا وسيلة لتحسين حياتنا وصحتنا بشكل عام.
- 3 اجابة
-
- 1
-
-
وعليكم السلام، الهدف في كل المشاريع (ومنها مشاريع الذكاء الاصطناعي وتعلم الآلة) يجب أن يتم وضعه قبل بداية المشروع وليس عند الانتهاء منه! هذا أمر لا يتعلق بالبرمجة ولا التقنيات، إنما هو مبدأ عام في الحياة. في فترة التعلم يجب أن تقوم بمشاريع حتى وإن كنت لن تستفيد منها بشكل مباشرة، فالهدف في البداية هو فقط التدريب. ولذلك ترى أغلب المشاريع الموجهة للمبتدئين في البرمجة عبارة عن Todo app أو Blog أو شيء من هذا القبيل. على الرغم من أنه لدينا الملايير من هذه المشاريع، إلّا أنه يستمر العمل بها من أجل التعليم. لكن عندما تنتهي من الدراسة الأساسية وتريد الدخول إلى العمل الحقيقي، فهنا يجب أن تقوم بإنشاء شيء مختلف له فائدة حقيقية. لذلك، ينطبق نفس المبدأ على مشاريع تعلم الآلة. عليك تحديد الهدف الذي تريد الوصول إليه، بعد ذلك العمل على إنشاء نماذج تساعدك في تحقيقه. فمثلا، إن كان المطلوب إنشاء موقع للتنبؤ بالروابط التي تبدو احتيالية (هذا مشروع عُرض علي وقمت به)، فهنا سوف تعمل على إنشاء نماذج تعمل على النص وتحاول تدريبها انطلاقا من مجموعة بيانات تحوي هذه الروابط، ثم دمج هذا النموذج في الموقع المطلوب إنشاؤه لكي يستخدمه الأشخاص الآخرون. كما ترى، الهدف كان واضحا منذ البداية، ثم قمنا بالعمل استنادا إلى المطلوب.
- 3 اجابة
-
- 1
-
-
السلام عليكم انا عاوز افهم هو اي الهدف النهايه من بناء نموذج يعني مثل انا عملت نموذج يتنبا اذكان الشخص ده عندو السكر والا الا اي الاستفدا من حاجه زي كده ؟
- 3 اجابة
-
- 2
-
-
 يحيى زكريا2 اشترك بالأكاديمية
يحيى زكريا2 اشترك بالأكاديمية -
 يوسف المحسن اشترك بالأكاديمية
يوسف المحسن اشترك بالأكاديمية -
 تسنيم خالد اشترك بالأكاديمية
تسنيم خالد اشترك بالأكاديمية -
 رغد الجهني2 اشترك بالأكاديمية
رغد الجهني2 اشترك بالأكاديمية -
 ريم عادل اشترك بالأكاديمية
ريم عادل اشترك بالأكاديمية -
 Abu Hassan Alrazhi اشترك بالأكاديمية
Abu Hassan Alrazhi اشترك بالأكاديمية -
 Ashraf Mostafa2 اشترك بالأكاديمية
Ashraf Mostafa2 اشترك بالأكاديمية -
 Ahmed Abdelhady4 اشترك بالأكاديمية
Ahmed Abdelhady4 اشترك بالأكاديمية - البارحة
-
تسلم ايدك الطريقة الاولى اللى انت ذكرتها بوضع ال params كانت بردو ترجعلى data فاضية اما الطريقة الثانية بمسح ال params وكتابة ال api كامل بالشكل دة : https://alsouq.anevex.com/app/shop-api/advertisements?home_page_position=Header&show_in=home await axios.get("https://alsouq.anevex.com/app/shop-api/advertisements?home_page_position=Header&show_in=home") كانت افضل لان ال data بالفعل رجعلتى بالقيم المطلوبة
-
 قم بفتح الطرفية (التيرمنال) من قائمة التطبيقات أو بالضغط على Ctrl + Alt + T. ثم استخدم الأمر add-apt-repository لإضافة المستودع الجديد: sudo add-apt-repository repository/name عليك تبديل repository/name بعنوان المستودع الذي تريد إضافته. بعد إضافة المستودع، تحتاج إلى تحديث قائمة الحزم: sudo apt update ويوجد طريقة الثانية من خلال واجهة المستخدم، افتح "إدارة التحديثات" (Update Manager) وتستطيع العثور عليها في قائمة التطبيقات. افتح الإعدادات Settings في نافذة "إدارة التحديثات"، ثم انتقل إلى علامة التبويب "المستودعات الأخرى" (Other Software). ثم اضغط على زر "إضافة" Add وأدخل عنوان المستودع الذي تريد إضافته، وبعد إضافة المستودع، ستحتاج إلى تحديث قائمة الحزم. يمكنك القيام بذلك من خلال الضغط على زر "تحديث" (Refresh) أو باستخدام الطرفية: sudo apt update
قم بفتح الطرفية (التيرمنال) من قائمة التطبيقات أو بالضغط على Ctrl + Alt + T. ثم استخدم الأمر add-apt-repository لإضافة المستودع الجديد: sudo add-apt-repository repository/name عليك تبديل repository/name بعنوان المستودع الذي تريد إضافته. بعد إضافة المستودع، تحتاج إلى تحديث قائمة الحزم: sudo apt update ويوجد طريقة الثانية من خلال واجهة المستخدم، افتح "إدارة التحديثات" (Update Manager) وتستطيع العثور عليها في قائمة التطبيقات. افتح الإعدادات Settings في نافذة "إدارة التحديثات"، ثم انتقل إلى علامة التبويب "المستودعات الأخرى" (Other Software). ثم اضغط على زر "إضافة" Add وأدخل عنوان المستودع الذي تريد إضافته، وبعد إضافة المستودع، ستحتاج إلى تحديث قائمة الحزم. يمكنك القيام بذلك من خلال الضغط على زر "تحديث" (Refresh) أو باستخدام الطرفية: sudo apt update -
 في الكود الثاني، قمت بتطبيق التحجيم القياسي (StandardScaler)فقط على بيانات التدريب (x_traing) ولكن لم تقم بتطبيق نفس التحجيم على بيانات الاختبار (x_test). هذا يؤدي إلى عدم توافق في توزيع البيانات بين التدريب والاختبار، مما يسبب زيادة كبيرة في الخطأ. يجب عليك أيضًا تطبيق التحجيم على بيانات الاختبار باستخدام نفس التحجيم الذي استخدمته لبيانات التدريب: import pandas as pd from sklearn.linear_model import LinearRegression from sklearn.preprocessing import StandardScaler from sklearn.model_selection import train_test_split from sklearn.metrics import mean_squared_error data = pd.read_csv("heart_disease.csv") feutures = data.drop(['target'], axis=1, inplace=False) outpnt = data['target'] x_traing, x_test, y_traing, y_test = train_test_split(feutures, outpnt, test_size=0.25, random_state=44, shuffle=True) scaler = StandardScaler() x_scaler_traing = scaler.fit_transform(x_traing) x_scaler_test = scaler.transform(x_test) # تطبيق نفس التحجيم على بيانات الاختبار linearregression = LinearRegression(fit_intercept=True, copy_X=True, n_jobs=-1) fit = linearregression.fit(x_scaler_traing, y_traing) y_prodict = fit.predict(x_scaler_test) msevalue = mean_squared_error(y_test, y_prodict, multioutput="uniform_average") print(f"MSEvalue: {msevalue}") وتأكد من أن البيانات في ملف heart_disease.csv لا تحتوي على قيم شاذة أو غير منطقية يمكن أن تؤثر على النتائج بعد التحجيم. بتطبيق التعديلات السابقة، يجب أن تحصل على نتائج أكثر منطقية لقيمة MSE.
في الكود الثاني، قمت بتطبيق التحجيم القياسي (StandardScaler)فقط على بيانات التدريب (x_traing) ولكن لم تقم بتطبيق نفس التحجيم على بيانات الاختبار (x_test). هذا يؤدي إلى عدم توافق في توزيع البيانات بين التدريب والاختبار، مما يسبب زيادة كبيرة في الخطأ. يجب عليك أيضًا تطبيق التحجيم على بيانات الاختبار باستخدام نفس التحجيم الذي استخدمته لبيانات التدريب: import pandas as pd from sklearn.linear_model import LinearRegression from sklearn.preprocessing import StandardScaler from sklearn.model_selection import train_test_split from sklearn.metrics import mean_squared_error data = pd.read_csv("heart_disease.csv") feutures = data.drop(['target'], axis=1, inplace=False) outpnt = data['target'] x_traing, x_test, y_traing, y_test = train_test_split(feutures, outpnt, test_size=0.25, random_state=44, shuffle=True) scaler = StandardScaler() x_scaler_traing = scaler.fit_transform(x_traing) x_scaler_test = scaler.transform(x_test) # تطبيق نفس التحجيم على بيانات الاختبار linearregression = LinearRegression(fit_intercept=True, copy_X=True, n_jobs=-1) fit = linearregression.fit(x_scaler_traing, y_traing) y_prodict = fit.predict(x_scaler_test) msevalue = mean_squared_error(y_test, y_prodict, multioutput="uniform_average") print(f"MSEvalue: {msevalue}") وتأكد من أن البيانات في ملف heart_disease.csv لا تحتوي على قيم شاذة أو غير منطقية يمكن أن تؤثر على النتائج بعد التحجيم. بتطبيق التعديلات السابقة، يجب أن تحصل على نتائج أكثر منطقية لقيمة MSE.- 6 اجابة
-
- 1
-
-
 انا اول ما عملت كده يا أ.مصطفي فا حسابات الMSE فا كان ده النتجيه 87.53644204505163 مع العلم قبل ما اعمل كده فا كانت النتجيه 0.12410403813221675 فا اي السبيب ؟ وده الكود قبل import pandas as pd from sklearn.linear_model import LinearRegression from sklearn.model_selection import train_test_split from sklearn.metrics import mean_squared_error data = pd.read_csv("heart_disease.csv") feutures = data.drop(['target'] , axis=1 , inplace=False) outpnt = data['target'] x_traing , x_test , y_traing , y_test = train_test_split(feutures , outpnt , test_size=0.25, random_state=44 , shuffle=True) linearregression = LinearRegression(fit_intercept=True , copy_X=True , n_jobs=-1) fit = linearregression.fit(x_traing , y_traing) y_prodict = fit.predict(x_test) msevalue = mean_squared_error(y_test , y_prodict , multioutput="uniform_average") print(f"MSEvalue: {msevalue}") وده الكود بعد import pandas as pd from sklearn.linear_model import LinearRegression from sklearn.preprocessing import StandardScaler from sklearn.model_selection import train_test_split from sklearn.metrics import mean_squared_error data = pd.read_csv("heart_disease.csv") feutures = data.drop(['target'] , axis=1 , inplace=False) outpnt = data['target'] x_traing , x_test , y_traing , y_test = train_test_split(feutures , outpnt , test_size=0.25, random_state=44 , shuffle=True) scaler = StandardScaler() x_scaler_traing = scaler.fit_transform(x_traing) linearregression = LinearRegression(fit_intercept=True , copy_X=True , n_jobs=-1) fit = linearregression.fit(x_scaler_traing , y_traing) y_prodict = fit.predict(x_test) msevalue = mean_squared_error(y_test , y_prodict , multioutput="uniform_average") print(f"MSEvalue: {msevalue}")
انا اول ما عملت كده يا أ.مصطفي فا حسابات الMSE فا كان ده النتجيه 87.53644204505163 مع العلم قبل ما اعمل كده فا كانت النتجيه 0.12410403813221675 فا اي السبيب ؟ وده الكود قبل import pandas as pd from sklearn.linear_model import LinearRegression from sklearn.model_selection import train_test_split from sklearn.metrics import mean_squared_error data = pd.read_csv("heart_disease.csv") feutures = data.drop(['target'] , axis=1 , inplace=False) outpnt = data['target'] x_traing , x_test , y_traing , y_test = train_test_split(feutures , outpnt , test_size=0.25, random_state=44 , shuffle=True) linearregression = LinearRegression(fit_intercept=True , copy_X=True , n_jobs=-1) fit = linearregression.fit(x_traing , y_traing) y_prodict = fit.predict(x_test) msevalue = mean_squared_error(y_test , y_prodict , multioutput="uniform_average") print(f"MSEvalue: {msevalue}") وده الكود بعد import pandas as pd from sklearn.linear_model import LinearRegression from sklearn.preprocessing import StandardScaler from sklearn.model_selection import train_test_split from sklearn.metrics import mean_squared_error data = pd.read_csv("heart_disease.csv") feutures = data.drop(['target'] , axis=1 , inplace=False) outpnt = data['target'] x_traing , x_test , y_traing , y_test = train_test_split(feutures , outpnt , test_size=0.25, random_state=44 , shuffle=True) scaler = StandardScaler() x_scaler_traing = scaler.fit_transform(x_traing) linearregression = LinearRegression(fit_intercept=True , copy_X=True , n_jobs=-1) fit = linearregression.fit(x_scaler_traing , y_traing) y_prodict = fit.predict(x_test) msevalue = mean_squared_error(y_test , y_prodict , multioutput="uniform_average") print(f"MSEvalue: {msevalue}")- 6 اجابة
-
- 1
-
-
اطفه المستودع القديم والجديد في لينكس منت عندي اخطاى في النطم في لبترمنل هذي التقريارير النطم
- 1 جواب
-
- 1
-
-
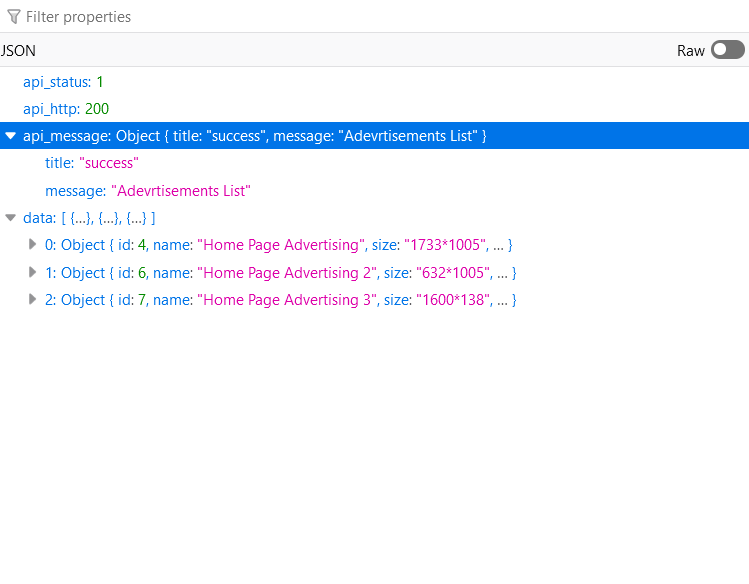
مرحباً محمد , يمكنك نتفيذ هذا الكود سيعمل كما في الصورة المرفقة , أيضاً قمت بتوضيح خطوة خطوة من خلال التعليقات : const url = 'https://alsouq.anevex.com/app/shop-api/advertisements'; const params = { home_page_position: 'Header', show_in: 'home' }; // Send the GET request axios.get(url, { params }) .then(response => { // Handle the response console.log('Data:', response.data); }) .catch(error => { // Handle any errors console.error('Error fetching data:', error); }); ايضاً لاحظ عند ارسال سيكون عنوان url بالشكل التالي لان نوع method الخاصة ب api هي GET : https://alsouq.anevex.com/app/shop-api/advertisements?home_page_position=Header&show_in=home
- 8 اجابة
-
- 1
-
-
طيب اي الاحسن MSE ام RMSE ؟
-
 يستخدم كل من ووردبريس بدون رأس Headless WordPress وواجهات برمجة التطبيقات REST API ضمن بيئة تطوير ووردبريس بشكل كبير مؤخرًا، ويحتاج المطورون لامتلاك مجموعة من الأدوات القياسية التي يرغبون في استخدامها عند العمل على هذه النوع من المشاريع. سسنشرح في مقال اليوم طريقة التعامل مع مفهوم ووردبريس مقطوع الرأس (بلا رأس) باستخدام مجموعة من الأدوات وعلى الرغم أننا لا نؤكد أن مجموعة الأدوات التي سنستخدمها ينبغي أن تكون قياسية إلا أننا نرى أن هذه الادوات ستكون مناسبة للاستخدام عند بناء تطبيقاتنا باستخدام REST API، وهذه الأدوات هي : MailHog: وهي أداة اختبار SMTP تعتمد على الويب وواجهة برمجة التطبيقات. Insomnia: هو عميل REST قوي متعدد الأنظمة يستخدم لاختبار واجهات برمجة التطبيقات. JWT Auth: هي أداة شائعة الاستخدام لتأمين واجهات برمجة التطبيقات. تطبيقات ووردبرس بدون رأس Headless WordPress باستخدام REST API لنتعرف في الفقرات التالية على أهم المتطلبات والخطوات التي تحتاجها لتطور تطبيقات ووردبريس بدون رأس مع توضيح حالات الاستخدام المفيدة لهذا النوع من التطبيقات. المتطلبات قبل النظر في استخدام هذه الأدوات في بناء مشروع فعلي يجب عليك تجهيز الحاسوب الذي سيستخدم هذه الأدوات. وعلى الرغم من أنك لن تقوم بذلك في مشاريع التطوير الفعلية لكن تجهيز بيئة تطوير محلية يفيدك في مرحلة التعلم واختبار التطبيق وإليك قائمة بأهم الأدوات التي ستحتاجها: خادم ويب يدعم لارافيل مثل Valet نظام إدارة قواعد البيانات مثل MariaDB لغة البرمجة PHP (أي إصدار أعلى من 7.4.33 حسب نوع الخادم الذي تشغل المشروع عليه) ولمزيد من المعلومات حول إعداد بيئة تطوير محلية يمكنك الاطلاع على مقال تثبيت وضبط تطبيق لارافيل مع خادم Nginx على حزمة LEMP من أوبنتو ومقال دليل إعداد خادم ويب محلي خطوة بخطوة سنستخدم أيضاً الأدوات التالية بالنسبة لبيئة التطوير الخاصة بنا: Visual Studio Code Insiders: لتحرير الأكواد. PHPDoc Comment: لتوثيق الأكواد. PHP Sniffer & Beautifier مع PSR12: لتحليل وتنسيق كود PHP والتأكد من مطابقته للمعايير والقواعد البرمجية. PHP Debug: لمراقبة تطبيقات PHP وتتبع أخطائها. Ray: أداة تسهل تصحيح الأخطاء البرمجية. عملياً إذا كنت على معرفة بكل الأدوات والتقنيات السابقة وكان لديك الإعدادات الخاصة بك أو كنت معتاد على بناء التطبيقات أو الحلول باستخدام ووردبرس فقد يكون كل ما سبق لا يعنيك. وإلا يجب عليك أن تأخذ بعض الوقت لتتعرف على كل ما ورد أعلاه. دراسة حالة بسيطة: بفرض طلب منك تطوير تطبيق ووردبرس بدون رأس Headless WordPress يوفر نقاط نهاية مخصصة endpoints ويمكن لتطبيق iOS الاتصال بها لتسجيل الدخول والقيام بالاستيثاق أو التأكد من صحة البيانات وإرسال واستقبال البيانات. سيقدم تطبيق ووردبريس الوظائف التالية بالتحديد: إنشاء حساب جديد للمستخدم. الحصول على معلومات المستخدم. طلب مفتاح التشفير المساعد token. التحقق من المفتاح المساعد token. ضبط بيانات المستخدم. إن هذه البنود ليست كاملة ولكنها كافية لتوضيح طريقة استخدام الأدوات المختلفة في بناء تطبيقات مماثلة.كما أن الوظائف المذكورة في التطبيق يمكنها أن توفر عبر نقاط الوصول endpoints التالية: /acme/v1/getUser /acme/v1/createUser /jwt-auth/v1/token /jwt-auth/v1/token/validate /acme/v1/setData ملاحظة: إن acme هنا عبارة عن قيمة مؤقتة placeholder تعبر عن اسم التطبيق. أما jwt-auth فهو اسم المكتبة الخاصة بعملية المصادقة (اسم المستخدم وكلمة المرور) التي نقوم باستخدامها وهذا ما سيتم مناقشته لاحقاً في هذه المقالة توثيق واجهة برمجة التطبيقات API: يعد توثيق واجهة برمجة التطبيقات API شرطاً أساسياً من شروط نجاحها، وبما أننا نعمل على إنجاز تطبيق بدون رأس Headless فمن المهم جداً تنفيذ واجهة جميلة موثقة جيدًا للتطبيق، وسننفذ واجهة تطبيقنا باستخدام REST API ليتفاعل معها المستخدمون. لكن واجهة برمجة التطبيق API لا ينبغي أن تكون كصندوق أسود نتفاعل معها دون الاهتمام بتوثيقها وتوضيح تفاصيلها الداخلية إذ يحتاج المطور لمعرفة رأي المستخدمين في التطبيق الذي أنشأه فربما يكتشف المستخدمون بعض الثغرات التي تجاهلها المطور عند بناء التطبيق. وهناك أسباب أخرى تدعونا إلى توثيق واجهة برمجة التطبيقات APIs حتى لو لم يكن التطبيق متداول على نطاق واسع. وهذه الأسباب هي: الاتصال الجيد بين نقاط الوصول والوسطاء والخرج المتوقع. سهولة تواصل المطورين الجدد مع الواجهة. سهولة العودة لتصحيح الأخطاء في حال ظهورها في التطبيق المقدم للعميل. وجود عدة إصدارات من واجهة برمجة التطبيق API يمنح للمطورين المرونة باختيار الإصدار المناسب لتطبيقاتهم ومعرفة المميزات الموجودة في كل إصدار. لذا من المفيد أن تأخذ هذه الأسباب بعين الاعتبار عندما تقوم بإنشاء وتنفيذ أي تطبيق في المستقبل. الأداة MailHog إذا قمت سابقاً بتثبيت برنامج ووردبريس فمن المؤكد أنك رأيت كمية رسائل البريد الإلكتروني المرسلة لك وذلك إما عبر واجهة التطبيق أو عبر واجهة سطر الأوامر Command Line Interface فعندما تعمل في بيئة التطوير الخاصة بك سيكون هناك اختلاف بسيط في التعامل وإدارة رسائل البريد الإلكتروني (سواء في طريقة استلامها أو تخصيصها) وهنا يمكنك استخدام تقنية MailHog وهي عبارة عن تطبيق ويب مفيد جداً عندما تصل إلى مراحل متقدمة في تطوير واختبار مشروعك حيث تقوم هذه التقنية بدور خادم SMTP وهمي وتقوم بشكل أساسي بدور خادم بريد إلكتروني وهمي لمساعدتك في اختبار وظائف البريد الإلكتروني وتصحيح الأخطاء. تقوم الأداة MailHog بشكل أساسي باعتراض وفحص رسائل البريد الإلكتروني الصادرة من تطبيقك بدلاً من إرسالها بشكل مباشر إلى المستلمين الحقيقيين ثم تقدم هذه الرسائل عبر واجهة التطبيق، وهذا يسهل قراءة وتحليل ومراجعة الرسائل الصادرة من ووردبريس. إذ تسمح لك هذه الأداة بإلقاء نظرة كاملة على رسائل البريد الإلكتروني وهذا يتضمن: الموضوع (عنوان الرسالة) المرسل المستقبل (مستلم الرسالة) الرسالة (نص الرسالة) كما تسهل هذه الأداة وظائف البريد الإلكتروني من خلال التأكد من تنسيق رسائل البريد الإلكتروني وتسليمها بشكل صحيح. وعلى الرغم من أن هذه الأداة تعد مفيدة نوعاً ما عند العمل ضمن برنامج ووردبريس إلا أنه يجب الأخذ بعين الاعتبار معرفة كيفية استجابة التطبيق عندما نستخدم بيئة ووردبريس بدون رأس Headless WordPress فكل الأوامر تشغل من خلال نقاط الوصول الخاصة بواجهة برمجة التطبيق API الأداة Insomnia الأداة Insomnia هي تطبيق عميل API مفتوح المصدر متوافق مع مختلف الأنظمة، لكن إذا كنت معتادًا على التعامل مع تطبيقات REST API مثل تطبيق Postman أو تطبيق Paw (المسمى حالياً RapidAPI) فإنك لن تكون مهتماً بالعمل على هذه التقنية بالرغم من أنها أبسط نوعاً ما من التطبيقات المذكورة أعلاه بالنسبة للمطورين الذين لا يعملون على البرامج المذكورة أعلاه فإن هدفهم الأول هو تبسيط عملية التفاعل مع واجهة برمجة التطبيق REST API واختبارها. تنشئ الأداة Insomnia طلبات بروتوكول HTTP وتحللها وترسلها إلى نقاط وصول واجهة برمجة التطبيق API باستخدام الأوامر GET و POST و PUT و DELETE القياسية وتجعل التعامل معها أكثر سهولة. كما أنها تسهل التعامل مع ملفات JSON, XML وبيانات النماذج أو الاستمارات forms. وإن كان هذا الأمر غير مهم عند إنشاء التطبيقات لأنه يمكنك التحكم بنوع ملفات الخرج التي سيتم استرجاعها ولكنه أساسي عندما تتعامل API آخر لأن تحتاج لتغيير تنسيق البيانات قبل إرسالها أو استقبالها. ومن أهم ميزات هذه الأداة هي قدرتها على تنظيم الطلبات requests في مجلدات ومساحات عمل workspaces وهذا يسمح للمطورين بتنظيم وإدارة مشاريع اختبار واجهة برمجة التطبيق API الخاصة بهم ويسهل عملية التنقل والتبديل بين نقاط الوصول المختلفة. بالإضافة إلى ذلك فإن الطريقة التي يسمح لنا التطبيق بها في هذه الأداة بتوثيق وتنظيم كل نقطة وصول تجعل عملية مشاركة التطبيق مع المطورين الآخرين أسهل وبالتالي يمكنهم اختبار التطبيق على تطبيق واجهة برمجية API آخر على سبيل المثال بمجرد إنشاء REST API لموقع مبني بواسطة ووردبريس يمكنك مشاركته بواسطة الأداة Insomnia مع مطوري تطبيقات iOS ليتمكنوا من معرفة ما يلي: بنية نقطة الوصول الوسطاء المتوقعة الخرج الذي سيعيده التطبيق توثيق كل نقطة وصول في حال حدوث خطأ غير متوقع أخيراً فإن هذا النوع من الأدوات يسهل بناء وتطوير التطبيقات عند العمل مع مطورين يعملون على تطبيقات أخرى الأداة JWT-Auth قبل البدء في معرفة أهمية الأداة JWT-Auth فإنه من المفيد جداً معرفة ما هي JWT ومدى فائدتها في تطوير واجهة برمجة التطبيقات REST API بشكل عام يمكن تعريف JWT على أنه طريقة آمنة لنقل المعلومات بين المطورين بصيغة JSON وبعبارة أبسط هي عبارة عن آلية مصادقة معتمدة على المفتاح المساعد token وتستخدم بشكل كبير في تطبيقات الويب ملاحظة: على الرغم من صحة ما سبق فإنك إن لم تكن على دراية بآلية عمل مصادقة REST API لن تستطيع بناء المصادقة التي تحتاج إليها. عند إجراء مقارنة بين طريقة تفاعلنا مع الووردبريس من خلال المتصفح، وطريقة تفاعلنا مع الوورد بريس من خلال JWT فإنه يجب الانتباه إلى النقاط التالية: أولا نقوم بإرسال بيانات الاستيثاق (اسم المستخدم وكلمة السر) إلى المتصفح ومن ثم يطابق التطبيق تلك البيانات ويرسلها إلى المتصفح وبعد ذلك نكون قادرين على العمل والتنقل ضمن الوورد بريس (إدارة المستخدمين - كتابة وتحرير المنشورات وما إلى ذلك وأحياناً يكون عبارة عن مراجعة للمنشورات فقط) وهذه الأمور تتم فقط من خلال مدير نظام ووردبريس. أما عندما تتم المصادقة عبر واجهة برمجة التطبيقات REST APIs فيجب أن يكون هناك طريقة أخرى للمصادقة يستطيع التطبيق من خلالها معرفة بيانات استيثاق المستخدم وهنا يأتي دور المفتاح المساعد token حيث ستقوم آلية المصادقة المعتمدة على JWT بإنشاء مفتاح مساعد token ثم تقوم بتضمين هذا المفتاح المساعد token مع كل طلب وفي انتهاء صلاحية المفتاح المساعد token ستقوم واجهة برمجة التطبيق API بإعلامك من أجل أن تقوم بتحديث المفتاح المساعد token من الواضح بأنك بحاجة إلى عمل كثير عند تطبيق JWT في ووردبريس ولكن عند استخدام إضافة JWT-Auth فإن ستصبح الأمور أسهل بكثير. وكما توضح الصورة أعلاه المأخوذة من توثيق الإضافة فإن استيثاق ووردبريس باستخدام JSON Web Token يسمح بإجراء مصادقة واجهة REST API باستخدام المفتاح المساعد token وهي عملية بسيطة وغير معقدة وسهلة الاستخدام وهذه الإضافة مناسبة جداًَ لعمل مصادقة JWT ضمن ووردبريس. وللتعامل معها عليك القيام بما يلي: ضع مفتاح سري في الملف wp-config.php حدد فيما إذا كنت تريد من الإضافة أن تدعم خاصية CROS (وهو موضوع مهم إذا كنت تريد تمكين الاتصال الآمن بين تطبيقات الويب) بعد الانتهاء من تثبيت الإضافة يمكنك ان تقوم بعمل طلب request إلى wp-json/jwt-auth/v1/token/ متضمنا اسم المستخدم وكلمة السر للحساب بتنسيق JSON كما في المثال التالي: { "username": "John@appleseed.com", "password": "kn6oLrcW0\/D1M" } وبعدها سوف تستقبل الرد التالي: { "success": true, "statusCode": 200, "code": "jwt_auth_valid_credential", "message": "Credential is valid", "data": { "token": "eyJ0eXAiOiJKV1QiLCJhbGciOiJIUzI1NiJ9.eyJpc3MiOiJodHRwczovL3NjYXJpZi50ZXN0IiwiaWF0IjoxNjg0MzU1MzA5LCJuYmYiOjE2ODQzNTUzMDksImV4cCI6MTY4NDk2MDEwOSwiZGF0YSI6eyJ1c2VyIjp7ImlkIjoyNTksImRldmljZSI6IiIsInBhc3MiOiJiMWM3OTBhMmJhYzExNzNlYzI4ZTQxZGUxMDYyYzIwZiJ9fX0.q3-DRC_DQvezy1w-XV0CYNQYyKC3X8iSs7GKy86zjbg", "id": 259, "email": "John@appleseed.com", "nicename": "johnappleseed-com", "firstName": "John", "lastName": "Appleseed", "displayName": "John@appleseed.com" } وبعد ذلك ستقوم بتضمين المفتاح المساعد token مع كل طلب جديد، وإما أن يسمح لك الووردبريس مع إضافة JWT Auth بإرسال هذا الطلب request أو أن يمنعك من ذلك. هذا هو باختصار جوهر عمل الأداة JWT ضمن التطبيقات دون الرأس headless ولكن هذا ليس كل شيء إذ توفر هذه الأداة الكثير من المميزات الأخرى التي لن نتطرق لها حاليًا الخاتمة تعرفنا في مقال اليوم على أهم الأدوات التي سنحتاجها لبناء تطبيقات ووردبريس بدون رأس Headless WordPress باستخدام واجهة برمجة التطبيق REST API والتي يمكنك من خلالها الاستفادة من مرونة الووردبريس كنظام إدارة محتوى. نتمنى لكم الاستفادة الجيدة من هذا المقال وفي حال كان لديكم أي تساؤل حول ما ورد فيه فيمكن تركه في قسم التعليقات أسفل المقال أو كتابته في قسم الأسئلة والأجوبة في أكاديمية حسوب. ترجمة وبتصرف للمقال How To Build Headless WordPress Applications with a REST API لكاتبه Tom McFarlin اقرأ أيضًا مُقدّمة إلى برمجة إضافات Wordpress مدخل إلى برمجة قوالب ووردبريس أفضل طريقة للتّعديل على ووردبريس وإضافة نص برمجي إليه استقبال وحفظ خيارات الإضافة في ووردبريس من خلال التعامل مع Setting API وOptions API
يستخدم كل من ووردبريس بدون رأس Headless WordPress وواجهات برمجة التطبيقات REST API ضمن بيئة تطوير ووردبريس بشكل كبير مؤخرًا، ويحتاج المطورون لامتلاك مجموعة من الأدوات القياسية التي يرغبون في استخدامها عند العمل على هذه النوع من المشاريع. سسنشرح في مقال اليوم طريقة التعامل مع مفهوم ووردبريس مقطوع الرأس (بلا رأس) باستخدام مجموعة من الأدوات وعلى الرغم أننا لا نؤكد أن مجموعة الأدوات التي سنستخدمها ينبغي أن تكون قياسية إلا أننا نرى أن هذه الادوات ستكون مناسبة للاستخدام عند بناء تطبيقاتنا باستخدام REST API، وهذه الأدوات هي : MailHog: وهي أداة اختبار SMTP تعتمد على الويب وواجهة برمجة التطبيقات. Insomnia: هو عميل REST قوي متعدد الأنظمة يستخدم لاختبار واجهات برمجة التطبيقات. JWT Auth: هي أداة شائعة الاستخدام لتأمين واجهات برمجة التطبيقات. تطبيقات ووردبرس بدون رأس Headless WordPress باستخدام REST API لنتعرف في الفقرات التالية على أهم المتطلبات والخطوات التي تحتاجها لتطور تطبيقات ووردبريس بدون رأس مع توضيح حالات الاستخدام المفيدة لهذا النوع من التطبيقات. المتطلبات قبل النظر في استخدام هذه الأدوات في بناء مشروع فعلي يجب عليك تجهيز الحاسوب الذي سيستخدم هذه الأدوات. وعلى الرغم من أنك لن تقوم بذلك في مشاريع التطوير الفعلية لكن تجهيز بيئة تطوير محلية يفيدك في مرحلة التعلم واختبار التطبيق وإليك قائمة بأهم الأدوات التي ستحتاجها: خادم ويب يدعم لارافيل مثل Valet نظام إدارة قواعد البيانات مثل MariaDB لغة البرمجة PHP (أي إصدار أعلى من 7.4.33 حسب نوع الخادم الذي تشغل المشروع عليه) ولمزيد من المعلومات حول إعداد بيئة تطوير محلية يمكنك الاطلاع على مقال تثبيت وضبط تطبيق لارافيل مع خادم Nginx على حزمة LEMP من أوبنتو ومقال دليل إعداد خادم ويب محلي خطوة بخطوة سنستخدم أيضاً الأدوات التالية بالنسبة لبيئة التطوير الخاصة بنا: Visual Studio Code Insiders: لتحرير الأكواد. PHPDoc Comment: لتوثيق الأكواد. PHP Sniffer & Beautifier مع PSR12: لتحليل وتنسيق كود PHP والتأكد من مطابقته للمعايير والقواعد البرمجية. PHP Debug: لمراقبة تطبيقات PHP وتتبع أخطائها. Ray: أداة تسهل تصحيح الأخطاء البرمجية. عملياً إذا كنت على معرفة بكل الأدوات والتقنيات السابقة وكان لديك الإعدادات الخاصة بك أو كنت معتاد على بناء التطبيقات أو الحلول باستخدام ووردبرس فقد يكون كل ما سبق لا يعنيك. وإلا يجب عليك أن تأخذ بعض الوقت لتتعرف على كل ما ورد أعلاه. دراسة حالة بسيطة: بفرض طلب منك تطوير تطبيق ووردبرس بدون رأس Headless WordPress يوفر نقاط نهاية مخصصة endpoints ويمكن لتطبيق iOS الاتصال بها لتسجيل الدخول والقيام بالاستيثاق أو التأكد من صحة البيانات وإرسال واستقبال البيانات. سيقدم تطبيق ووردبريس الوظائف التالية بالتحديد: إنشاء حساب جديد للمستخدم. الحصول على معلومات المستخدم. طلب مفتاح التشفير المساعد token. التحقق من المفتاح المساعد token. ضبط بيانات المستخدم. إن هذه البنود ليست كاملة ولكنها كافية لتوضيح طريقة استخدام الأدوات المختلفة في بناء تطبيقات مماثلة.كما أن الوظائف المذكورة في التطبيق يمكنها أن توفر عبر نقاط الوصول endpoints التالية: /acme/v1/getUser /acme/v1/createUser /jwt-auth/v1/token /jwt-auth/v1/token/validate /acme/v1/setData ملاحظة: إن acme هنا عبارة عن قيمة مؤقتة placeholder تعبر عن اسم التطبيق. أما jwt-auth فهو اسم المكتبة الخاصة بعملية المصادقة (اسم المستخدم وكلمة المرور) التي نقوم باستخدامها وهذا ما سيتم مناقشته لاحقاً في هذه المقالة توثيق واجهة برمجة التطبيقات API: يعد توثيق واجهة برمجة التطبيقات API شرطاً أساسياً من شروط نجاحها، وبما أننا نعمل على إنجاز تطبيق بدون رأس Headless فمن المهم جداً تنفيذ واجهة جميلة موثقة جيدًا للتطبيق، وسننفذ واجهة تطبيقنا باستخدام REST API ليتفاعل معها المستخدمون. لكن واجهة برمجة التطبيق API لا ينبغي أن تكون كصندوق أسود نتفاعل معها دون الاهتمام بتوثيقها وتوضيح تفاصيلها الداخلية إذ يحتاج المطور لمعرفة رأي المستخدمين في التطبيق الذي أنشأه فربما يكتشف المستخدمون بعض الثغرات التي تجاهلها المطور عند بناء التطبيق. وهناك أسباب أخرى تدعونا إلى توثيق واجهة برمجة التطبيقات APIs حتى لو لم يكن التطبيق متداول على نطاق واسع. وهذه الأسباب هي: الاتصال الجيد بين نقاط الوصول والوسطاء والخرج المتوقع. سهولة تواصل المطورين الجدد مع الواجهة. سهولة العودة لتصحيح الأخطاء في حال ظهورها في التطبيق المقدم للعميل. وجود عدة إصدارات من واجهة برمجة التطبيق API يمنح للمطورين المرونة باختيار الإصدار المناسب لتطبيقاتهم ومعرفة المميزات الموجودة في كل إصدار. لذا من المفيد أن تأخذ هذه الأسباب بعين الاعتبار عندما تقوم بإنشاء وتنفيذ أي تطبيق في المستقبل. الأداة MailHog إذا قمت سابقاً بتثبيت برنامج ووردبريس فمن المؤكد أنك رأيت كمية رسائل البريد الإلكتروني المرسلة لك وذلك إما عبر واجهة التطبيق أو عبر واجهة سطر الأوامر Command Line Interface فعندما تعمل في بيئة التطوير الخاصة بك سيكون هناك اختلاف بسيط في التعامل وإدارة رسائل البريد الإلكتروني (سواء في طريقة استلامها أو تخصيصها) وهنا يمكنك استخدام تقنية MailHog وهي عبارة عن تطبيق ويب مفيد جداً عندما تصل إلى مراحل متقدمة في تطوير واختبار مشروعك حيث تقوم هذه التقنية بدور خادم SMTP وهمي وتقوم بشكل أساسي بدور خادم بريد إلكتروني وهمي لمساعدتك في اختبار وظائف البريد الإلكتروني وتصحيح الأخطاء. تقوم الأداة MailHog بشكل أساسي باعتراض وفحص رسائل البريد الإلكتروني الصادرة من تطبيقك بدلاً من إرسالها بشكل مباشر إلى المستلمين الحقيقيين ثم تقدم هذه الرسائل عبر واجهة التطبيق، وهذا يسهل قراءة وتحليل ومراجعة الرسائل الصادرة من ووردبريس. إذ تسمح لك هذه الأداة بإلقاء نظرة كاملة على رسائل البريد الإلكتروني وهذا يتضمن: الموضوع (عنوان الرسالة) المرسل المستقبل (مستلم الرسالة) الرسالة (نص الرسالة) كما تسهل هذه الأداة وظائف البريد الإلكتروني من خلال التأكد من تنسيق رسائل البريد الإلكتروني وتسليمها بشكل صحيح. وعلى الرغم من أن هذه الأداة تعد مفيدة نوعاً ما عند العمل ضمن برنامج ووردبريس إلا أنه يجب الأخذ بعين الاعتبار معرفة كيفية استجابة التطبيق عندما نستخدم بيئة ووردبريس بدون رأس Headless WordPress فكل الأوامر تشغل من خلال نقاط الوصول الخاصة بواجهة برمجة التطبيق API الأداة Insomnia الأداة Insomnia هي تطبيق عميل API مفتوح المصدر متوافق مع مختلف الأنظمة، لكن إذا كنت معتادًا على التعامل مع تطبيقات REST API مثل تطبيق Postman أو تطبيق Paw (المسمى حالياً RapidAPI) فإنك لن تكون مهتماً بالعمل على هذه التقنية بالرغم من أنها أبسط نوعاً ما من التطبيقات المذكورة أعلاه بالنسبة للمطورين الذين لا يعملون على البرامج المذكورة أعلاه فإن هدفهم الأول هو تبسيط عملية التفاعل مع واجهة برمجة التطبيق REST API واختبارها. تنشئ الأداة Insomnia طلبات بروتوكول HTTP وتحللها وترسلها إلى نقاط وصول واجهة برمجة التطبيق API باستخدام الأوامر GET و POST و PUT و DELETE القياسية وتجعل التعامل معها أكثر سهولة. كما أنها تسهل التعامل مع ملفات JSON, XML وبيانات النماذج أو الاستمارات forms. وإن كان هذا الأمر غير مهم عند إنشاء التطبيقات لأنه يمكنك التحكم بنوع ملفات الخرج التي سيتم استرجاعها ولكنه أساسي عندما تتعامل API آخر لأن تحتاج لتغيير تنسيق البيانات قبل إرسالها أو استقبالها. ومن أهم ميزات هذه الأداة هي قدرتها على تنظيم الطلبات requests في مجلدات ومساحات عمل workspaces وهذا يسمح للمطورين بتنظيم وإدارة مشاريع اختبار واجهة برمجة التطبيق API الخاصة بهم ويسهل عملية التنقل والتبديل بين نقاط الوصول المختلفة. بالإضافة إلى ذلك فإن الطريقة التي يسمح لنا التطبيق بها في هذه الأداة بتوثيق وتنظيم كل نقطة وصول تجعل عملية مشاركة التطبيق مع المطورين الآخرين أسهل وبالتالي يمكنهم اختبار التطبيق على تطبيق واجهة برمجية API آخر على سبيل المثال بمجرد إنشاء REST API لموقع مبني بواسطة ووردبريس يمكنك مشاركته بواسطة الأداة Insomnia مع مطوري تطبيقات iOS ليتمكنوا من معرفة ما يلي: بنية نقطة الوصول الوسطاء المتوقعة الخرج الذي سيعيده التطبيق توثيق كل نقطة وصول في حال حدوث خطأ غير متوقع أخيراً فإن هذا النوع من الأدوات يسهل بناء وتطوير التطبيقات عند العمل مع مطورين يعملون على تطبيقات أخرى الأداة JWT-Auth قبل البدء في معرفة أهمية الأداة JWT-Auth فإنه من المفيد جداً معرفة ما هي JWT ومدى فائدتها في تطوير واجهة برمجة التطبيقات REST API بشكل عام يمكن تعريف JWT على أنه طريقة آمنة لنقل المعلومات بين المطورين بصيغة JSON وبعبارة أبسط هي عبارة عن آلية مصادقة معتمدة على المفتاح المساعد token وتستخدم بشكل كبير في تطبيقات الويب ملاحظة: على الرغم من صحة ما سبق فإنك إن لم تكن على دراية بآلية عمل مصادقة REST API لن تستطيع بناء المصادقة التي تحتاج إليها. عند إجراء مقارنة بين طريقة تفاعلنا مع الووردبريس من خلال المتصفح، وطريقة تفاعلنا مع الوورد بريس من خلال JWT فإنه يجب الانتباه إلى النقاط التالية: أولا نقوم بإرسال بيانات الاستيثاق (اسم المستخدم وكلمة السر) إلى المتصفح ومن ثم يطابق التطبيق تلك البيانات ويرسلها إلى المتصفح وبعد ذلك نكون قادرين على العمل والتنقل ضمن الوورد بريس (إدارة المستخدمين - كتابة وتحرير المنشورات وما إلى ذلك وأحياناً يكون عبارة عن مراجعة للمنشورات فقط) وهذه الأمور تتم فقط من خلال مدير نظام ووردبريس. أما عندما تتم المصادقة عبر واجهة برمجة التطبيقات REST APIs فيجب أن يكون هناك طريقة أخرى للمصادقة يستطيع التطبيق من خلالها معرفة بيانات استيثاق المستخدم وهنا يأتي دور المفتاح المساعد token حيث ستقوم آلية المصادقة المعتمدة على JWT بإنشاء مفتاح مساعد token ثم تقوم بتضمين هذا المفتاح المساعد token مع كل طلب وفي انتهاء صلاحية المفتاح المساعد token ستقوم واجهة برمجة التطبيق API بإعلامك من أجل أن تقوم بتحديث المفتاح المساعد token من الواضح بأنك بحاجة إلى عمل كثير عند تطبيق JWT في ووردبريس ولكن عند استخدام إضافة JWT-Auth فإن ستصبح الأمور أسهل بكثير. وكما توضح الصورة أعلاه المأخوذة من توثيق الإضافة فإن استيثاق ووردبريس باستخدام JSON Web Token يسمح بإجراء مصادقة واجهة REST API باستخدام المفتاح المساعد token وهي عملية بسيطة وغير معقدة وسهلة الاستخدام وهذه الإضافة مناسبة جداًَ لعمل مصادقة JWT ضمن ووردبريس. وللتعامل معها عليك القيام بما يلي: ضع مفتاح سري في الملف wp-config.php حدد فيما إذا كنت تريد من الإضافة أن تدعم خاصية CROS (وهو موضوع مهم إذا كنت تريد تمكين الاتصال الآمن بين تطبيقات الويب) بعد الانتهاء من تثبيت الإضافة يمكنك ان تقوم بعمل طلب request إلى wp-json/jwt-auth/v1/token/ متضمنا اسم المستخدم وكلمة السر للحساب بتنسيق JSON كما في المثال التالي: { "username": "John@appleseed.com", "password": "kn6oLrcW0\/D1M" } وبعدها سوف تستقبل الرد التالي: { "success": true, "statusCode": 200, "code": "jwt_auth_valid_credential", "message": "Credential is valid", "data": { "token": "eyJ0eXAiOiJKV1QiLCJhbGciOiJIUzI1NiJ9.eyJpc3MiOiJodHRwczovL3NjYXJpZi50ZXN0IiwiaWF0IjoxNjg0MzU1MzA5LCJuYmYiOjE2ODQzNTUzMDksImV4cCI6MTY4NDk2MDEwOSwiZGF0YSI6eyJ1c2VyIjp7ImlkIjoyNTksImRldmljZSI6IiIsInBhc3MiOiJiMWM3OTBhMmJhYzExNzNlYzI4ZTQxZGUxMDYyYzIwZiJ9fX0.q3-DRC_DQvezy1w-XV0CYNQYyKC3X8iSs7GKy86zjbg", "id": 259, "email": "John@appleseed.com", "nicename": "johnappleseed-com", "firstName": "John", "lastName": "Appleseed", "displayName": "John@appleseed.com" } وبعد ذلك ستقوم بتضمين المفتاح المساعد token مع كل طلب جديد، وإما أن يسمح لك الووردبريس مع إضافة JWT Auth بإرسال هذا الطلب request أو أن يمنعك من ذلك. هذا هو باختصار جوهر عمل الأداة JWT ضمن التطبيقات دون الرأس headless ولكن هذا ليس كل شيء إذ توفر هذه الأداة الكثير من المميزات الأخرى التي لن نتطرق لها حاليًا الخاتمة تعرفنا في مقال اليوم على أهم الأدوات التي سنحتاجها لبناء تطبيقات ووردبريس بدون رأس Headless WordPress باستخدام واجهة برمجة التطبيق REST API والتي يمكنك من خلالها الاستفادة من مرونة الووردبريس كنظام إدارة محتوى. نتمنى لكم الاستفادة الجيدة من هذا المقال وفي حال كان لديكم أي تساؤل حول ما ورد فيه فيمكن تركه في قسم التعليقات أسفل المقال أو كتابته في قسم الأسئلة والأجوبة في أكاديمية حسوب. ترجمة وبتصرف للمقال How To Build Headless WordPress Applications with a REST API لكاتبه Tom McFarlin اقرأ أيضًا مُقدّمة إلى برمجة إضافات Wordpress مدخل إلى برمجة قوالب ووردبريس أفضل طريقة للتّعديل على ووردبريس وإضافة نص برمجي إليه استقبال وحفظ خيارات الإضافة في ووردبريس من خلال التعامل مع Setting API وOptions API -
 وعليكم السلام Understanding the mathematical equations associated with models can be helpful for comprehending how each model works and customizing its usage effectively. However, it’s not necessary to memorize all the equations in detail. In fact, you can rely on programming libraries and available tools to execute these equations instead of memorizing them manually. For example, in the case of Linear Regression, the main equation is: [ y = \beta_0 + \beta_1 x ] Where: (y) represents the target value (dependent variable). (x) represents the independent variable. (\beta_0) and (\beta_1) are the regression coefficients. As for the RandomForestClassifier model, it relies on an ensemble of decision trees and doesn’t have a specific mathematical equation in the same way.
وعليكم السلام Understanding the mathematical equations associated with models can be helpful for comprehending how each model works and customizing its usage effectively. However, it’s not necessary to memorize all the equations in detail. In fact, you can rely on programming libraries and available tools to execute these equations instead of memorizing them manually. For example, in the case of Linear Regression, the main equation is: [ y = \beta_0 + \beta_1 x ] Where: (y) represents the target value (dependent variable). (x) represents the independent variable. (\beta_0) and (\beta_1) are the regression coefficients. As for the RandomForestClassifier model, it relies on an ensemble of decision trees and doesn’t have a specific mathematical equation in the same way.- 6 اجابة
-
- 1
-
-
تمام بس سوال كمان كل نموذج ليا معادلات رياضيه فا هل موطلب مني معرفت المعادالات لكل نموذج استخدمو ؟ ان عرف LinearReagression
- 6 اجابة
-
- 1
-
-
اختيار النموذج المناسب يعتمد على العديد من العوامل بما في ذلك طبيعة البيانات، الهدف من النموذج، والأداء المطلوب. بالتالي القول بأن نموذجًا معينًا مثل RandomForestClassifier هو دائمًا أفضل من LinearRegression غير دقيق، لأن كل منهما يخدم أغراضًا مختلفة ويعمل بشكل أفضل في ظروف معينة. لديك LinearRegression نموذج بسيط وسهل الفهم يستخدم للعلاقات الخطية بين المتغيرات المستقلة والمتغير التابع، ومناسب في حال العلاقة بين متغيراتك خطية وتحتاج إلى تفسير بسيط للنموذج. بينما RandomForestClassifier نموذج أكثر تعقيدًا يستخدم للأغراض التصنيفية، ويعمل بشكل جيد عندما تكون البيانات معقدة وتحتوي على العديد من الميزات التي قد تتفاعل مع بعضها بطرق غير خطية، ويتميز بأنه يستخدم مجموعة من الأشجار decision trees ويجمع نتائجها للحصول على تصنيف أكثر دقة. واستخدم التحقق المتبادل لتقييم أداء النموذج على مجموعة من البيانات غير المرئية للنموذج، وقد تحتاج إلى ضبط الباراميترات للنماذج المعقدة لتحسين أدائها.
- 6 اجابة
-
- 2
-
-
وعليكم السلام The Linear Regression model and the RandomForestClassifier model differ in their use cases and the contexts where they are most beneficial.: 1Linear Regression: The Linear Regression model is used when we assume a linear relationship between the dependent variable (target) and the independent variables (predictors). It is suitable for continuous numerical data and can be used to predict target values using a straight line. Example: It can be used to predict house prices based on house size. 2Random Forest Classifier: The RandomForestClassifier model is used for classification, not continuous value prediction. It relies on an ensemble of decision trees and combines their predictions for classification. It is suitable for categorical data (such as classifying into specific categories). 3General Considerations: The choice of model depends on the nature of the data and the goal of the analysis. If you want to predict continuous values, Linear Regression is the appropriate choice. If you want to perform classification, RandomForestClassifier is the suitable choice.
- 6 اجابة
-
- 1
-
-
السلام عليكم هل الLinearRegression مش افضل حاجه دلوقتي وهل فيه نموذك افضل من نموذج ؟ يعني مثل الRandomForestClassifier افضل من الLinearRegression والا الا علي حساب البيانات اي
- 6 اجابة
-
- 2
-
-
بالضبط، ففي مكتبة scikit-learn، باراميتر normalize لم يعد موجودًا في الإصدار 0.24.0 وما بعده من النموذج LinearRegression. في الإصدارات الأحدث من المكتبة، عليك استخدام StandardScaler أو Normalizer من مكتبة sklearn.preprocessing لتطبيع البيانات قبل تمريرها إلى النموذج. للتوضيح: from sklearn.linear_model import LinearRegression from sklearn.preprocessing import StandardScaler import numpy as np X = np.array([[1, 2], [3, 4], [5, 6], [7, 8]]) y = np.array([1, 2, 3, 4]) scaler = StandardScaler() X_scaled = scaler.fit_transform(X) model = LinearRegression() model.fit(X_scaled, y) predictions = model.predict(X_scaled) print(predictions) لاحظ تطبيع البيانات باستخدام StandardScaler قبل استخدامها في تدريب النموذج LinearRegression، وذلك يحقق نفس النتيجة التي كان يحققها استخدام الباراميتر normalize=True في الإصدارات الأقدم.
- 6 اجابة
-
- 2
-
-
وعليكم السلام! In the scikit-learn library, the normalize parameter is not available in the LinearRegression model. The LinearRegression model is used to fit a linear model with coefficients w = (w1, ..., wp) to minimize the sum of squared residuals between observed targets in the dataset and the predicted targets from the linear approximation If you need to apply normalization to your data before using the LinearRegression model, you can use the normalize function from scikit-learn to normalize the data. This function helps standardize the data and avoids issues related to varying scales.
- 6 اجابة
-
- 1
-
-
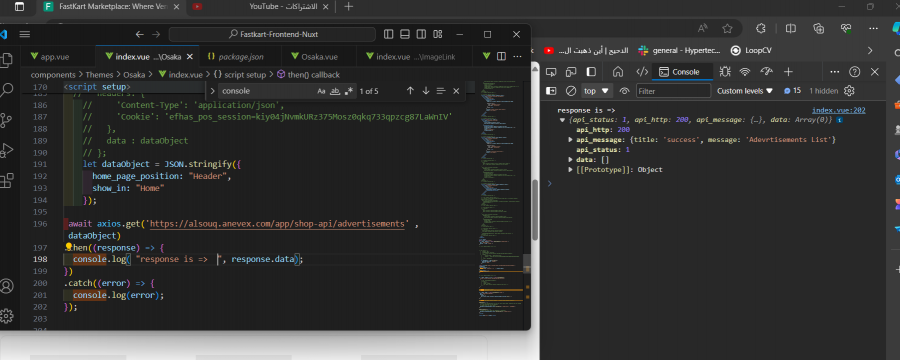
مازالت الداتا ترجعلى فاضية حتى بعد تجربة الكود المتوفر من البرنامج على الرغم من ان ال postman بيرجع داتا موجودة فعلا بعد التجربة مازالت ترجع الداتا فاضية على الرغم من ان ال postman يرجع داتا حقيقية جربت الطريقة لكن ما زالت الداتا ترجع فاضية
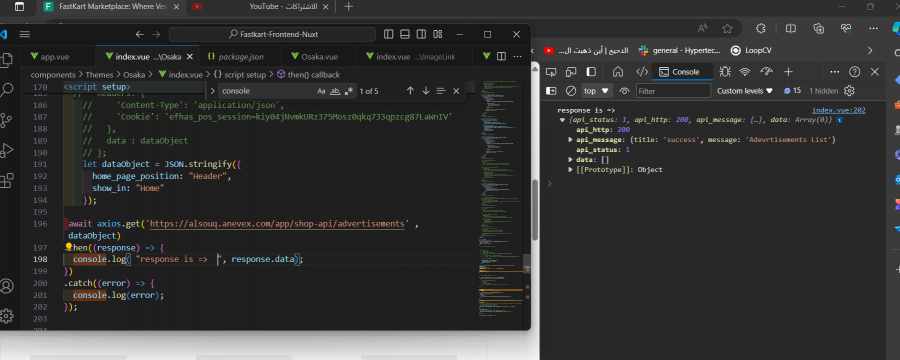
- 8 اجابة
-
- 1
-
-
السلام عليكم في مكتبه sklearn هو الparameters (normalize) مش موجود في الmodel LinearRegression ؟
- 6 اجابة
-
- 2
-