Bahaa Hamed
-
المساهمات
3 -
تاريخ الانضمام
-
تاريخ آخر زيارة
إنجازات Bahaa Hamed
عضو مبتدئ (1/3)
1
السمعة بالموقع
-
للفائدة : لقد حللت المشكلة عن طريق استيراد الملف داخل برنامج الاكسل من علامة التبويب بيانات ومن ثم اختيار "من النص / CSV " بعدها تحميل
-
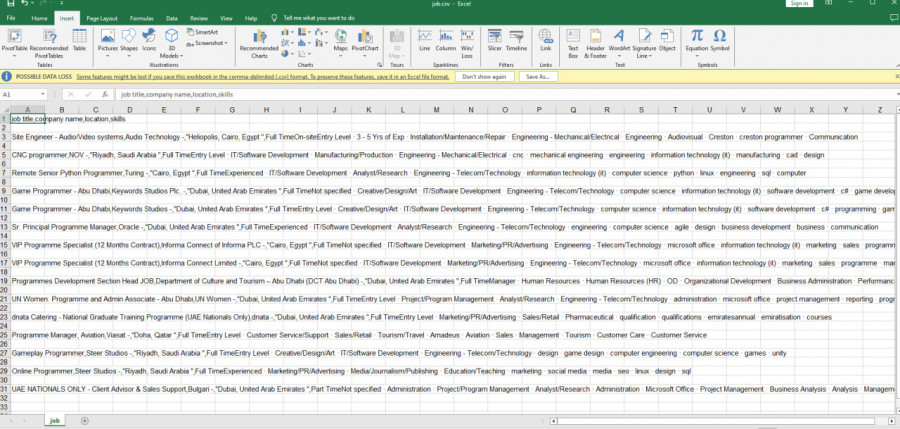
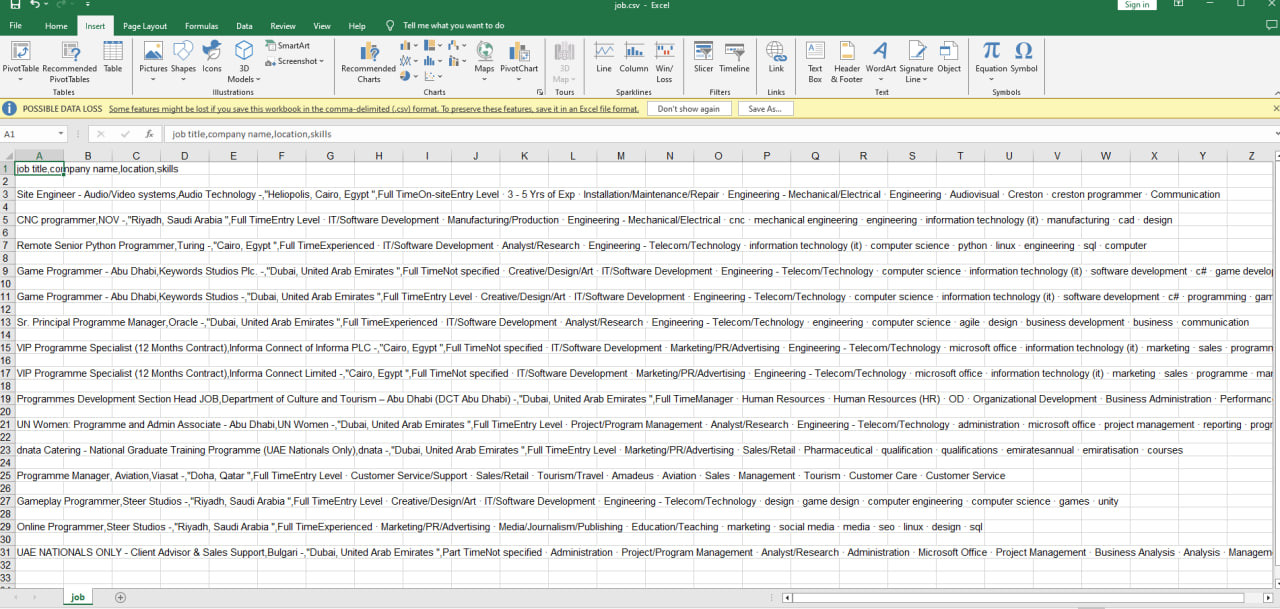
السلام عليكم المشكلة هي انه البيانات تظهر بعامود واحد فقط ولا تتوزع على باقي الاعمدة ( تم ارفاق صورة ) مع العلم بالخطوة السابعة استخدمت طريقة zip longest وعملت unpacking لا اعلم اين المشكلة بالضبط اتمنى المساعدة وشكرا import requests from bs4 import BeautifulSoup import csv from itertools import zip_longest job_title = [] company_name = [] location_name = [] skills = [] #2 use requests to fetch the url result = requests.get ("https://wuzzuf.net/search/jobs/?q=programmer&a=hpb") #3 save page content/markup src = result.content #4 create soup object to parse content soup = BeautifulSoup (src, "lxml") #5 find the elements containing info we need #-- job titles, job skills, company names, location names job_titles = soup.find_all("h2",{"class":"css-m604qf"}) company_names = soup.find_all("a",{"class":"css-17s97q8"}) locations_names = soup.find_all("span",{"class":"css-5wys0k"}) job_skills = soup.find_all("div",{"class":"css-y4udm8"}) #6 loop over returned lists to extract needed info other lists for i in range(len(job_titles)): job_title.append(job_titles[i].text) company_name.append(company_names[i].text) location_name.append(locations_names[i].text) skills.append(job_skills[i].text) #7 create csv file and fill it with values file_list = [job_title, company_name, location_name, skills] exported = zip_longest(*file_list) with open("job.csv", "w" ) as myfile: wr = csv.writer(myfile) wr.writerow(["job title", "company name", "location", "skills"]) wr.writerows(exported)