هشام رزق الله
-
المساهمات
1442 -
تاريخ الانضمام
-
تاريخ آخر زيارة
-
عدد الأيام التي تصدر بها
31
نوع المحتوى
ريادة الأعمال
البرمجة
التصميم
DevOps
التسويق والمبيعات
العمل الحر
البرامج والتطبيقات
آخر التحديثات
قصص نجاح
أسئلة وأجوبة
كتب
دورات
كل منشورات العضو هشام رزق الله
-
أسهل طريقة لفعل ذلك هي عن طريق استخدام وحدة fileinput، فعلى سبيل المثال هذه الشيفرة البرمجية لإضافة رقم كل سطر في الملف: import fileinput for line in fileinput.input("test.txt", inplace=True): print "%d: %s" % (fileinput.filelineno(), line),شرح ما الذي ستفعله هذه الشيفرة البرمجية: إنشاء نسخة احتياطية من الملف الأصلي.إعادة توجيه المخرجات القياسية إلى الملف الأصلي داخل الحلقة.تبديل أي تعليمات للطباعة باستخدام print إلى كتابة ما بداخل التعليمة إلى الملف الأصلي.المصدر
-
تمر عملية إقلاع النظام بالمراحل التالية: عند تشغيل الحاسوب فإن BIOS سيعمل تلقائيا.سيبحث BIOS عن MBR حسب ترتيب الإقلاع الذي وضعه المستخدم.بعد ذلك سيُحمل BIOS قاطع الإقلاع الذي يبلغ حجمه 521 بايت إلى موقع الذاكرة “0x7c00” من مكان معين في وسيلة نقل المعلومات (media) ومن ثم سيُنفذها.وفي هذه 512 بايت سيتم تحميل نظام التشغيل أو برنامج للإقلاع أكثر تعقيدا.مثال على نظام تشغيل بسيط باستخدام NASM: %if 0; * Title: A Simple Bootloader in NASM * Author: Osanda Malith Jayathissa (@OsandaMalith) * Website: http://OsandaMalith.wordpress.com %endif; BITS 16 jmp short _start ; Jump past disk description section nop ; Disk description table, to make it a valid floppy OEMLabel db "OsandaOS" ; Disk label BytesPerSector dw 512 ; Bytes per sector SectorsPerCluster db 1 ; Sectors per cluster ReservedForBoot dw 1 ; Reserved sectors for boot record NumberOfFats db 2 ; Number of copies of the FAT RootDirEntries dw 224 LogicalSectors dw 2880 ; Number of logical sectors MediumByte db 0F0h ; Medium descriptor byte SectorsPerFat dw 9 ; Sectors per FAT SectorsPerTrack dw 18 ; Sectors per track (36/cylinder) Sides dw 2 ; Number of sides/heads HiddenSectors dd 0 ; Number of hidden sectors LargeSectors dd 0 ; Number of LBA sectors DriveNo dw 0 ; Drive No: 0 Signature db 41 ; Drive signature: 41 for floppy VolumeID dd 12345678h ; Volume ID: any number VolumeLabel db "My First OS"; Volume Label: any 11 chars FileSystem db "FAT12 " ; File system type: don't change! _start: mov ax, 07C0h ; move 0x7c00 into ax mov ds, ax ; set data segment to where we're loaded mov si, string ; Put string position into SI call print_string ; Call our string-printing routine jmp $ ; infinite loop! string db "Welcome to @OsandaMalith's First OS :)", 0 print_string: mov ah, 0Eh ; int 10h 'print char' function .loop: lodsb ; load string byte to al cmp al, 0 ; cmp al with 0 je .done ; if char is zero, ret int 10h ; else, print jmp .loop .done: ret times 510-($-$$) db 0 ; Pad remainder of boot sector with 0s dw 0xAA55 ; The standard PC boot signatureالمصدر
-
يعتبر هذا النوع من الأخطاء الأكثر شيوعا عند المبرمجين المبتدئين بلغة بايثون ويعود السبب إلى عدم دراسة جزء العوامل الحسابية جيدا عند تعلم اللغة. فسبب الخطأ في السطر السابق هو أن بايثون يُطبّق تسلسل عامل المقارنة أي أنه سيُقسم النص إلى جزأين ومن ثم سيربطهم عن طريق العامل and. سيصبح السطر السابق الذي كتبته كالتالي: (1 in [1, 0]) and ([1, 0] == True) والذي يعطي خطأ (false).
-
نعم، هنالك فرق بين هاتين الدالتين في الإصدارين الثاني والثالث للبايثون. في الإصدار الثاني: كانت raw_input() تقوم بأخذ بالضبط ما كتبه المستخدم وتضعه في سلسلة نصية، أما input() فهي تقوم بنفس وظيفة raw_input() لكن تقوم بعمل eval() عليه. الفرق الرئيسي بينهما أن input() تتوقع أن يتم إدخال سطر برمجي صحيح نحويا أما raw_input() فلا. في الإصدار الثالث: تم تغيير اسم raw_input() إلى input() وبالتالي حُذفت input() القديمة، وإذا أردت استخدام input() القديمة فيمكنك أن تكتب eval(input()).
-
على الرغم من أن كلا الدالتين تُستخدمان للبحث داخل السلسلة النصية إلا أنه هنالك فرق بسيط بينهما، فدالة re.match تستخدم للبحث في بداية السلسلة النصية، وهذه الدالة لا تفعل أي شيئ للأسطر الجديدة ولذلك فهي ليست مشابهة لـ ^ عند استخدام التعابير النمطية. أما بالنسبة لـ re.search فهي تُستخدم للبحث في كامل السلسلة النصيّة وإرجاع موقع الكلمة/ الكلمات التي تبحث عنها. لتوضيح الفرق بشكلٍ أفضل، أنصحك بإلقاء نظرة على هذه الأسطر: a = "123abc" t = re.match("[a-z]+",a) t = re.search("[a-z]+",a) بالنسبة إلى re.match فإنها ستقوم بإرجاع سلسلة فارغة وأما re.search فإنها ستقوم بإرجاع abc. المصدر
-
هنالك عدة حلول لهذه المشكلة وبما أنك ذكرت أنك تريد استخدام دالة معينة فسأقوم بشرح ثلاثة دوال تساعدك على ملئ السلاسل النصية بالفراغات أو غيرها. أول هذه الدوال هي str.ljust() التي ستزيح بمقدار ما تمرره لها من عدد -الفراغات إلى اليمين-، حيث سيتم احتساب الأحرف عند الإزاحة، أي لو كانت السلسلة النصية تتكون من حرفين وقمت بتمرير 8 لدالة str.ljust() فإنه سيتم كتابة 6 فراغات وليس 8). وتوجد أيضا دالة str.rjust() التي ستقوم بنفس وظيفة الدالة السابقة ولكن الفراغات تُضاف إلى يسار السلسلة النصية -إزاحة إلى اليمين -. وفي النهاية توجد دالة string.zfill() التي تقوم بنفس وظيفة الدالة السابقة لكن بدل الفراغات سيتم وضع أصفار. المصدر
-
إذا أردت على سبيل المثال التأكد من نوع متغير o فما إذا كان من نوع سلسلة نصية أو لا فيمكنك استخدام دالة isinstance مع تمرير اسم المتغير ونوع basestring كما في المثال التالي: isinstance(o, basestring) إن كل من str و unicode هي أصناف فرعية من basestring. أما لو أردت التأكد من أن o هي من نوع سلسلة نصية Str وليس unicode فيجب عليك تمرير str بدلا من basestring كما في هذا المثال: isinstance(o, str) ملاحظات: تمت إزالة basestring من بايثون 3، وأصبحت str هي نوع السلسلة النصية الوحيد. المصدر
-
نعم هنالك عدة حلول لهذه المشكلة فيمكنك على سبيل المثال استخدام تابع File.expand_path الذي ستُمرر له اسم الملف ومن ثم ستمرر هذا التابع لدالة open حتى تتمكن من فتح الملف الذي ترغب به: open(File.expand_path('~/some_file')) و هنالك حل آخر وأعتبره أفضل من سابقه لأنه يستخدم متغيرات البيئة وسيكون أوضح من استخدام expand_path كما في المثال التالي: open(ENV['HOME']+'/some_file') حل ثالث لكنني غير متأكد من عمله على الإصدارات القديمة لروبي (ما قبل الإصدار 1.9.3) والذي أستخدم فيه متغير مدمج Dir.home كما في المثال التالي: open("#{Dir.home}/some_file") المصدر
-
أبسط جواب لسؤالك هو أنه يجب عليك استخدام علامة الاقتباس المزدوجة "” عندما تريد إقحام متغيرات داخل السلاسل النصية عن طريق كتابتها بين {}# كما في المثال التالي: a = 2 puts "#{a}" وإذا لم تحتج إلى ذلك فأنصحك أن تستخدم علامة اقتباس المفردة. بالنسبة للفرق بين السرعة فتقريبا لكلاهما نفس سرعة التنفيذ إلا لو قمت بإقحام متغيرات داخل السلسلة النصية حيث ستصبح أبطأ من السلسلة النصية التي بدونها. إذا كنت تريد تعلم ROR (روبي أون ريلز) فأنصحك باختيار كتاب يتحدث عن أساسيات لغة روبي و ROR حتى يتوضح لك متى تستخدم علامات الاقتباس وغيرها من الأشياء التي يجب إتقانها حتى تصبح محترف في لغة روبي.
-
يمكنك التأكد من صياغة شيفرة برمجية مكتوبة بلغة بايثون بتجميعها عن طريق تمرير -m py_compile قبل اسم السكربت كما في المثال التالي: python -m py_compile script.py أو يمكنك استخدام برامج للتحقق من صحة صياغة سكربت بايثون الخاص بك، من أبرز هذه البرامج PyChecker و Pyflakes و Pylint. ويمكنك أيضا إنشاء سكربت بسيط يتحقق من الشيفرة البرمجية التي قمت بكتابتها عن طريق تجميعها وإظهار الأخطاء إن وجدت، مثال على السكربت: import sys filename = sys.argv[1] source = open(filename, 'r').read() + '\n' compile(source, filename, 'exec') احفظه باسم checker.py ومن ثم استخدمه لفحص شيفرتك البرمجية كالتالي: python checker.py yourpyfile.py
-
هنالك عدة طرق لفعل ذلك في لغة بايثون، فيمكنك مثلا استخدام الدالة المدمجة split() والتي ستخزن كل كلمة ضمن عنصر قائمة، ولن تحتاج إلى كتابة أي شيفرة برمجية ولا أي حلقة تكرار: words = text.split() يمكنك أيضا تعيين محدد معين مثل ",” لتقسيم السلسلة النصية إلى أجزاء حسب هذه المعين كما في المثال التالي: words = text.split(",") وإذا أردت استخدام دالة أخرى فيمكن استخدام word_tokenize من مكتبة nltk حيث ستُمرر السلسلة النصية التي ترغب بتقسيمها كما في split(): >>> import nltk >>> s = "The fox's foot grazed the sleeping dog, waking it." >>> words = nltk.word_tokenize(s) >>> words ['The', 'fox', "'s", 'foot', 'grazed', 'the', 'sleeping', 'dog', ',', 'waking', 'it', '.'] المصدر
-
يمكنك استخدام دالة timedelta حتى تتمكن من إضافة عدد الثواني التي ترغب بها إلى وقت موجود في متغير datetime، حيث سنقوم بتمرير عدد الأيام أولًا ثم عدد الثواني كما يظهر هذا في المثال التالي: import datetime a = datetime.datetime(100,1,1,11,34,59) b = a + datetime.timedelta(0,3) # days, seconds, then other fields. print a.time() print b.time() وسيكون ناتج السطور السابقة كالتالي: 11:34:59 11:35:02 أو يمكنك تمرير عدد الثواني مباشرة: b = a + datetime.timedelta(seconds=3) وإذا كنت ترغب بكتابة دالة لإضافة عدد الثواني بدل من استخدام دالة timedelta مباشرة، فيمكنك كتابة: import datetime def addSecs(tm, secs): fulldate = datetime.datetime(100, 1, 1, tm.hour, tm.minute, tm.second) fulldate = fulldate + datetime.timedelta(seconds=secs) return fulldate.time() a = datetime.datetime.now().time() b = addSecs(a, 300) print a print bالمصدر
-
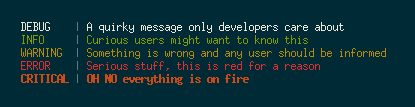
لديك خيارين لتلوين ناتج سجلات بايثون، فإما أن تقوم باستخدام مكتبة للتلوين أو أن تقوم بكتابة شيفرات التلوين بنفسك. يمكنك على سبيل المثال استخدام مكتبة colorlog التي يمكن تثبيتها عن طريق PyPI، وهذا مثال على استخدام هذه المكتبة لتلوين ناتج السجلات التنقيح: import logging LOG_LEVEL = logging.DEBUG LOGFORMAT = " %(log_color)s%(levelname)-8s%(reset)s | %(log_color)s%(message)s%(reset)s" from colorlog import ColoredFormatter logging.root.setLevel(LOG_LEVEL) formatter = ColoredFormatter(LOGFORMAT) stream = logging.StreamHandler() stream.setLevel(LOG_LEVEL) stream.setFormatter(formatter) log = logging.getLogger('pythonConfig') log.setLevel(LOG_LEVEL) log.addHandler(stream) log.debug("A quirky message only developers care about") log.info("Curious users might want to know this") log.warn("Something is wrong and any user should be informed") log.error("Serious stuff, this is red for a reason") log.critical("OH NO everything is on fire")سيكون الناتج كالتالي: وهنالك مكتبات أخرى لتلوين الناتج مثل مكتبة coloredlogs ...إلخ أما لو أردت استخدام شيفرات برمجية لتلوين ناتج عمليات التنقيح في بايثون فيمكنك كتابة شيفرة برمجية كهذه: BLACK, RED, GREEN, YELLOW, BLUE, MAGENTA, CYAN, WHITE = range(8) #The background is set with 40 plus the number of the color, and the foreground with 30 #These are the sequences need to get colored ouput RESET_SEQ = "\033[0m" COLOR_SEQ = "\033[1;%dm" BOLD_SEQ = "\033[1m" def formatter_message(message, use_color = True): if use_color: message = message.replace("$RESET", RESET_SEQ).replace("$BOLD", BOLD_SEQ) else: message = message.replace("$RESET", "").replace("$BOLD", "") return message COLORS = { 'WARNING': YELLOW, 'INFO': WHITE, 'DEBUG': BLUE, 'CRITICAL': YELLOW, 'ERROR': RED } class ColoredFormatter(logging.Formatter): def __init__(self, msg, use_color = True): logging.Formatter.__init__(self, msg) self.use_color = use_color def format(self, record): levelname = record.levelname if self.use_color and levelname in COLORS: levelname_color = COLOR_SEQ % (30 + COLORS[levelname]) + levelname + RESET_SEQ record.levelname = levelname_color return logging.Formatter.format(self, record)ولاستخدامها يجب عليك إنشاء صنف خاص بك للسجلات: # Custom logger class with multiple destinations class ColoredLogger(logging.Logger): FORMAT = "[$BOLD%(name)-20s$RESET][%(levelname)-18s] %(message)s ($BOLD%(filename)s$RESET:%(lineno)d)" COLOR_FORMAT = formatter_message(FORMAT, True) def __init__(self, name): logging.Logger.__init__(self, name, logging.DEBUG) color_formatter = ColoredFormatter(self.COLOR_FORMAT) console = logging.StreamHandler() console.setFormatter(color_formatter) self.addHandler(console) return logging.setLoggerClass(ColoredLogger)المصدر
-
يمكنك فعل ذلك بعدة طرق وبسهولة في بايثون، فلو كان نوع القيم الافتراضية غير قابلة للتغيير (immutable) فيمكنك كتابة سطر برمجي مثل هذا للقيام بذلك [0]*10 أما لو كنت -على سبيل المثال- بحاجة إلى قائمة تتكون من 10 قواميس فلا يجب عليك استخدام [{}]*10 لأن ناتج هذا الأمر سيعطيك قائمة بها 10 قواميس متماثلة وليس 10 قواميس منفردة، ففي هذه الحالة يُنصح مثلا باستخدام حلقة التكرار for كما في المثال التالي: [{} for i in range(10)]أو يمكنك استخدام أي طريقة أخرى لإنشاء 10 قواميس منفصلة ومن ثم وضعها في القائمة.
-
كالعادة في روبي، توجد أكثر من طريقة لفعل وظيفة معينة، فللحصول على اسم شهر محدد، يمكنك استخدام Date::MONTHNAMES من وحدة date والذي ستعطي لك الاسم كامل للشهر باللغة الإنجليزية كما في المثال التالي: require 'date' Date::MONTHNAMES[Date.today.month] كما يمكنك استخدام I18n والذي يتميز بتعدد طرق عرض الشهر، فمثلا يمكنك الحصول على اسم الشهر بالكامل مثل "December" أو يمكنك الحصول على مختصر اسم الشهر مثل "Dec" كما يلي: I18n.t("date.month_names") # [nil, "January", "February", "March", "April", "May", "June", "July", "August", "September", "October", "November", "December"] I18n.t("date.abbr_month_names") # [nil, "Jan", "Feb", "Mar", "Apr", "May", "Jun", "Jul", "Aug", "Sep", "Oct", "Nov", "Dec"] I18n.t("date.month_names")[Date.today.month] # "December" I18n.t("date.abbr_month_names")[Date.today.month] # "Dec" يمكنك أيضا استخدام strftime كما في هذا المثال: Date.today.strftime("%B") # -> November المصدر
-
هنالك طريقتين سهلتين لدمج عناصر المصفوفة مع بعضها لتصبح سلسلة نصية، أولها استخدام تابع join للمصفوفة والذي سوف نُمرر له ما سيوضع للفصل بين عناصر المصفوفة في السلسلة النصية ولنستخدم في هذا المثال مسافة فارغة " ” مثلًا: @arr.join(" ") أما لو كانت المصفوفة تحتوي أعدادًا بدلًا من السلاسل النصية فيجب عليك في هذه الحالة تحويلها إلى سلاسل نصية أولًا عن طريق تابع to_s، إلا لو أردت أن يكون الناتج عدد صحيح ففي هذه الحالة يجب عليك أن تستخدم تابع to_i. طريقة أخرى للدمج: @arr * " "
-
هنالك طرق مختلفة لدمج عناصر قائمة من القوائم عن طريق بايثون، وأسهل هذه الطرق وأسرعها هي استخدام دالة chain من مكتبة itertools مع استعمال دالة list() للناتج (لتحويل الناتج إلى قائمة لأن دالة chain تحوّله إلى سلسلة نصية) كما في المثال التالي: import itertools a = [["a","b"], ["c"]] print list(itertools.chain(*a))أما لو أردت استخدام حلقة التكرار for وكان عٌمق السلسلة النصية مستوى واحد فقط فيمكنك في هذه الحال استخدام شيفرة برمجية مثل هذه لدمج القوائم: >>> x = [["a","b"], ["c"]] >>> [inner ... for outer in x ... for inner in outer] ['a', 'b', 'c'] أو يمكنك فعل ذلك بسطر واحد كالتالي: >>> [j for i in x for j in i] ['a', 'b', 'c'] المصدر
-
نعم ناتج السطرين يختلفان، فسطر i += 1 يقوم بشيء مشابه لهذا: try: i = i.__iadd__(1) except AttributeError: i = i.__add__(1) أما بالنسبة إلى i = i + 1 فإنها ستقوم بشيء مثل هذا: i = i.__add__(1) المشكلة تكمن في أنواع المتغيرات القابلة للتغيير مثل القوائم، حيث سيتحورون إلى __iadd__ (ومن ثم سيُرجعون self عند استدعاءهم إلا لو قمت بتغيير ذلك عن طريق إحدى الخدع)، بينما المتغيرات غير القابلة للتغيير مثل int فإن الطريقة السابقة لن تعمل معها. مثال للتوضيح: >>> l1 = [] >>> l2 = l1 >>> l1 += [3] >>> l2 [3] بسبب أن l2 لديها نفس كائن l1، وقد حورنا l1 فإنك سنحوّر l2 أيضا. مثال آخر: >>> l1 = [] >>> l2 = l1 >>> l1 = l1 + [3] >>> l2 [] في هذا المثال، لم نقم بتحوير l1 بل أنشئنا قائمة جديد، ومن ثم باستخدام l1 + [3] أضفنا [3] إلى l1 تاركا l2 تشير إلى القائمة الأصلية.
-
هنالك عدة أسباب تجعل استخدام وحدة os أفضل من تطبيق أوامر النظام بشكل مباشرة وأهمها أن استخدام دوال وحدة os أسرع من استخدام os.system() أو subprocess.call() ويرجع السبب إلى أن هذين الأخيرين يقومان بإنشاء عمليتين (processes) غير ضروريتين. السبب الآخر أن بعض الأوامر ليس لديها أية فائدة لو استعملناها في عمليات منفصلة مثلا لو قمت بتنفيذ أمر os.spawn("cd dir/") فإنه سيُغير المجلد الحالي للعملية الصغيرة التي أنشأها ولم يتم تغيير أي شيء في عملية بايثون. أما السبب الثالث هو أن دوال مكتبة os يدعم جميع الأنظمة على عكس الأوامر التي تعمل في نوع واحد من الأنظمة.
-
يمكنك فعل ذلك بسطر واحد وبطرق متعددة في روبي، فإذا كانت جميع المفاتيح هي سلاسل نصية ولديها خط سفلي (underscore) في بدايتها فيمكنك حذف هذه البادئة عن طريق استخدام هذا السطر الذي سيقوم بالتكرار وحذف بادئة (أول رمز) لجميع المفاتيح كما في المثال التالي: h.keys.each { |k| h[k[1, k.length - 1]] = h[k]; h.delete(k) } هذه العبارة "k[1, k.length – 1]” معناها جلب جميع أجزاء k باستثناء الحرف الأول، وإذا أردت الحصول على hash جديد بدل استبدال المفاتيح في hash السابق فيمكنك استخدام السطر التالي: new_h = Hash[h.map { |k, v| [k[1, k.length - 1], v] }]
-
أسهل طريقة للحصول على اسم المضيف (Hostname) هي عن طريق استخدام الدالة gethostname من مكتبة socket حيث نعيّن النتيجة إلى متغير آخر كما في هذا المثال: require 'socket' hostname = Socket.gethostname أما بالنسبة للحصول على عناوين IP، فإذا كنت تستخدم روبي 1.9 فيمكنك استخدام مكتبة socket أيضًا للحصول على قائمة من العناوين المحلية، فالدالة ip_address_list تُرجع مصفوفة من كائنات AddrInfo والتي يمكنك اختيار ما تريده منها من العناوين بناءا على ما الذي تريد أن تفعله وعلى عدد الواجهات (interfaces) التي تملكها. مثال بسيط سوف نختار فيه أول عنوان non-loopback IPV4 وستكون النتيجة عبارة عن سلسلة نصية: require 'socket' ip_address = Socket.ip_address_list.find { |ai| ai.ipv4? && !ai.ipv4_loopback? }.ip_address المصدر
-
حل هذه المشكلة بسيط، فالمشكلة حدثت بسبب خطأ في تكوين القائمة، فعندما تكتب [x]*3 فسوف تحصل على قائمة [x, x, x] والتي هي قائمة بها 3 مراجع لـ x وفي هذه الحالة عندما تُغير قيمة x سوف تتغير قيم المراجع الثلاثة. ولحل هذه المشكلة، يجب عليك أن تتأكد من إنشاء قائمة جديدة في كل موقع من مواقع القائمة الأصلية، ويمكنك فعل ذلك عن طريق استخدام حلقة التكرار for كما في المثال التالي: [[1]*4 for n in range(3)]
-
استخدمت عدة مكتبات http في البايثون سابقا، ولكن أعجبتني مكتبة Requests لما تقدمه من سهولة وسرعة لذلك أصبح المكتبة http المفضلة عندي. على الرغم من أن المكتبات مفيدة للغاية سواء استخدمتَ مكتبة Requests أو غيرها، لكن في الغالب ستكتب أسطر أطول حجمًا وأقل عددًا. مثال على طلبات PUT باستخدام مكتبة requests: payload = {'username': 'bob', 'email': 'bob@bob.com'} >>> r = requests.put("http://somedomain.org/endpoint", data=payload) يمكنك التحقق من رمز حالة الإجابة عن طريق السطر التالي: r.status_code أو يمكنك التحقق من الإجابة عن طريق: r.content ستجد الكثير من الطرق المختصرة في مكتبة requests والتي سوف تجعل التعامل مع http أسهل. المصدر
-
هنالك العديد من الحلول لهذه المشكلة ولكنها جميعها تشترك في أنه يجب عليك تقسيم الملف إلى أجزاء وقراءة كل جزء على حدة، ومن أفضل الطرق تقسيم الملف إلى أجزاء بحجم 128 بابت ومن ثم بناء رمز MD5 عن طريق ترميزهم تباعا ودمجهم باستخدام update()، مثال على قراءة أجزاء من الملف: f = open(fileName) while not endOfFile: f.read(128) أو لقراءة الملف بشكل أسرع يمكنك استخدام هذه الدالة والتي تقرأ الملف بشكل أجزاء ومن ثم تقوم بترميزه: def md5_for_file(f, block_size=2**20): md5 = hashlib.md5() while True: data = f.read(block_size) if not data: break md5.update(data) return md5.digest()
-
الفرق الوحيد بين عاملي or و|| هي الأولوية، فالعامل || لديه أولوية أكبر من عامل or، انتبه لهذه النقاط: إن and و or و not لديهم أولوية أقل من && و || و!لكن and وor لديهم نفس الأولية بينما && لديه أولوية أكبر من ||بشكل عام، من الأفضل تجنب استخدام and وor و not واستبدالهم بـ && و || و! لأنها قد تتسبب ببعض المشاكل كما في التعبير الشرطي الذي يُستخدم فيه العامل (? : )ورمز التعيين (=). المصدر