Ali Ibrahim12
-
المساهمات
37 -
تاريخ الانضمام
-
تاريخ آخر زيارة
نوع المحتوى
ريادة الأعمال
البرمجة
التصميم
DevOps
التسويق والمبيعات
العمل الحر
البرامج والتطبيقات
آخر التحديثات
قصص نجاح
أسئلة وأجوبة
كتب
دورات
كل منشورات العضو Ali Ibrahim12
-
في نماذج التعلم الالي مفهوم ال"target" يعبر عن الخرج المستهدف أو النتيجة المرغوبة التي يتم استهدافها في مجموعة البيانات. حيث تكون موجودة في مسائل التعلم بالاشراف (supervised learning) من مسائل تصنيف او تنبؤ على غرار مسائل الغير خاضعة للاشراف (unsupervised learning) مثل خوارميات التجميع وغيرها. حيث يمكن ان تصادفك بغير اسم لكن تعبر عن نفس المعنى ومن الاسماء الشائعة الاخرى للtarget هي: Label (التصنيف) Class (الفئة) Outcome (النتيجة) Ground truth (الحقيقة الأساسية) Y (نتيجة او الدالة ) ففي مثالك الtarget هي حالة السكري في الدم حيث تعبر 0 للحالة الطبيعية اي انه بمعنى اخر غير مصاب بالسكر وال1 انه مرتفع السكري وهو مؤشر لاصابته بالسكري فيمكن ان تحل البيانات التي تملكها ان يمكن تصنيف الاشخاص المصابين بالسكري من غير المصابين وذلك تبعا للعوامل مثل العمر والجنس والخ...) هدف استخدام الـ target في التعلم الآلي هو تدريب النموذج للتنبؤ بالفئة المناسبة للمثال الجديد. عند تدريب النموذج، يتم مقارنة النتيجة المتوقعة المستنتجة من النموذج بالقيمة الهدف (target) الحقيقية. بناءً على هذه المقارنة، يتم تحديث وضبط معلمات النموذج ليتعلم التنبؤ الدقيق بالفئات وهذا تعريف التعلم بالاشراف.
- 10 اجابة
-
- 1
-

-
يمكن أن تكون المشكلة في إعدادات البريد الإلكتروني الخاصة بـ Django على الاستضافة. هناك احتمالان رئيسيان للمشكلة: 1. إعدادات البريد الإلكتروني في Django: - تأكد من تكوين إعدادات البريد الإلكتروني بشكل صحيح في ملف `settings.py` الخاص بمشروع Django الخاص بك. تحتاج إلى تحديد معلومات الاعتماد الصحيحة لخادم البريد الصادر (SMTP) الذي تستخدمه لإرسال البريد الإلكتروني. -تكون من الشكل : EMAIL_BACKEND = 'django.core.mail.backends.smtp.EmailBackend' EMAIL_HOST = 'your-smtp-host' EMAIL_PORT = 587 EMAIL_HOST_USER = 'your-email@example.com' EMAIL_HOST_PASSWORD = 'your-email-password' EMAIL_USE_TLS = True DEFAULT_FROM_EMAIL = EMAIL_HOST_USER 2. قيود الاستضافة: - بعض خدمات الاستضافة تفرض قيودًا على إرسال البريد الإلكتروني، مثل حجم رسائل البريد أو قيود بروتوكول SMTP. يجب التحقق من قواعد الاستضافة الخاصة بك للتأكد من عدم وجود أي قيود تمنع إرسال رسائل البريد الإلكتروني من الاستضافة. ويكن مراجعة الجواب التالي لاعداد البريد الالكتروني والتاكد من انك قمت بالاعداد الصحيح
- 8 اجابة
-
- 1
-
-
قم بإنشاء نسخة احتياطية من بياناتك (تصديرها) قبل القيام بالتغييرات وذلك في حال استخدام MySql بطريقة بسيطة بالذهاب الى phpmyadmin واختبار قاعدة البيانات المطلوبة وثم القيام بصدير ينتج ملف ذو لاحقة sql توجد فيه نسخة احطياتية لبياناتك ويوجد طرق اخرى لكن هذه اسهل واحدة . وعندما تريد استردادها قم بimport الى قاعدة بيانات فارغة واختيار الملف الذي قمت بتصديره مسبقا. يمكن اضافة الحقل الجديد دون مشاكل عبر طريقتين نعطي مثال اضافة phone_number الى نموذج ال User وداخل تابع up قم باضافة الحق الجديد عن طريق : اضافة الحقل في ملف الترحيل لكن يجب وضع له قيمة افتراضية مما يعطي كل البيانات القديمة هذه القيمة الافتراضية: قم باجراء التعليمة التي تقوم بانشاء ملفmigration جديد يوجد في المسار database/migrations php artisan make:migration add_phone_number_users_table ثم وضع قيمة افتراضية داخل الجدول الاتي ولتكن 55555 public function up() { Schema::table('users', function (Blueprint $table) { $table->integer('phone_number')->default(55555); }); } ينتج اضافة حقل جديد لكل البيانات القديمة مع قيمة 55555 لكل المستخدمين . او بوضع الحقل اسمح بان يكون null عبر public function up() { Schema::table('users', function (Blueprint $table) { $table->integer('phone_number')->nullable(); }); } ينتج اضافة حقل جديد لكل البيانات القديمة تأخذ قيمة null لكل المستخدمين . بعدها تنفيذ امر تهجير البيانات php artisan migrate وهذا تكون اضفت حقل جديد دون التاثير على البيانات
-
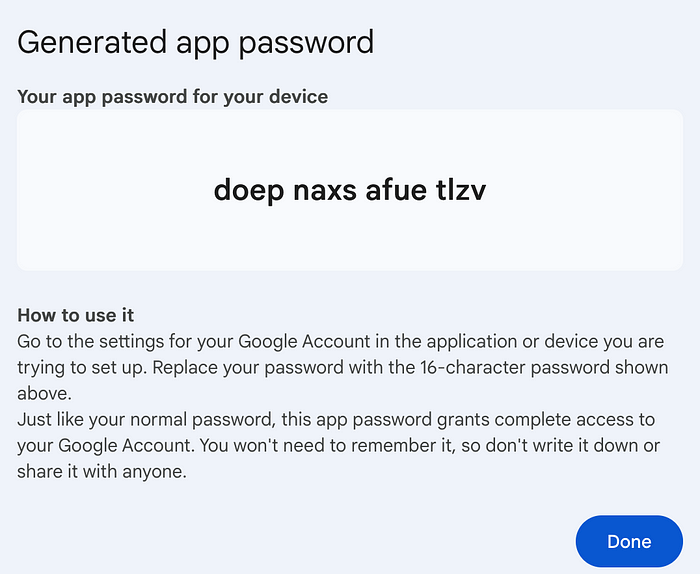
إرسال رسائل البريد الإلكتروني عبر Gmail في Django اتبع الخطوات التالية : 1. التحقق على خطوتين أول شيء نحتاجه هو إعداد التحقق من عامل 2. انتقل إلى https://myaccount.google.com/security واسمح له بالتسجيل بحسابك . 2. إنشاء تطبيق كخطوة ثانية ، نحتاج إلى إنشاء تطبيق. انتقل إلى https://myaccount.google.com/apppasswords سيعطيك كلمة مرور ، والتي سنستخدمها في Django. بعد إنشاء تطبيق ، ستتلقى كلمة مرور. احفظه ، حيث ستحتاج إليه لاحقا. 3. إعدادات جانغو: لتجنب تخزين بيانات الاعتماد مباشرة سنستخدم ملفا(.env) حيث للتعامل معه نستخدم الامر التالي pip install decouple ثم نقوم بانشاء ملف باسم .env بعدها نضع داخله EMAIL_HOST_USER=your_account@gmail.com EMAIL_HOST_PASSWORD="doep naxs afue tlzv" DEFAULT_FROM_EMAIL=Your app <your_account@gmail.com> وبعدها انتقل إلى الملف(settings.py) وأضف إعدادات خادم البريد الإلكتروني. from decouple import config EMAIL_HOST = "smtp.gmail.com" EMAIL_HOST_USER = config("EMAIL_USER") EMAIL_HOST_PASSWORD = config("EMAIL_PASSWORD") EMAIL_PORT = 587 EMAIL_USE_TLS = True DEFAULT_FROM_EMAIL = config("DEFAULT_EMAIL") بالنسبة لمستخدمي Windows ، فأنت جاهز لكن قد يواجه مستخدمو Mac خطأ أثناء الاختبار. في هذه الحالة ، ستحتاج إلى تثبيت حزمة تسمى .certifi للتاكد من المستخدم عبر التعليمة التالية pip install --upgrade certifi ثم قم بتشغيل هذا الأمر من الجهاز. قم بتحديث المسار إذا كنت تستخدم إصدارا مختلفا من Python. /Applications/Python\ 3.12/Install\ Certificates.command والان الارسال عبر الدالة send_mail كالطريقة التالية from django.core.mail import send_mail from django.shortcuts import render def index(request): subject = ( "Ali ibrahim" ) message = "This email is from Django." send_mail( subject=subject, message=message, from_email=None, recipient_list=["alicodeacm@gmail.com",'mohamad123@gmail.com'] ) return render(request, "index.html") والنتيجة النهائية


-
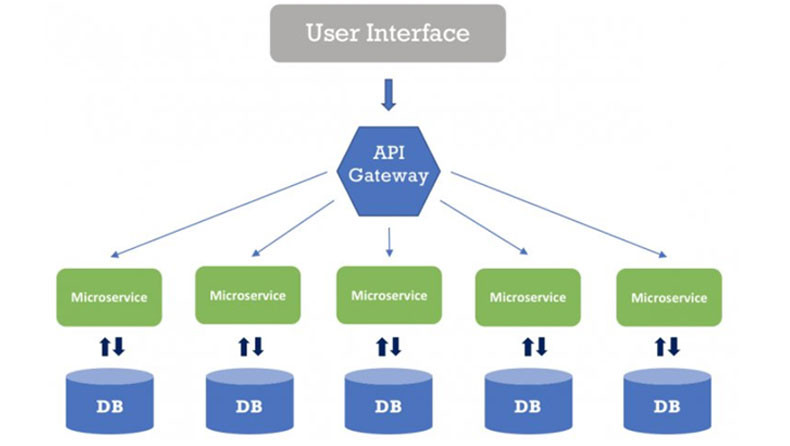
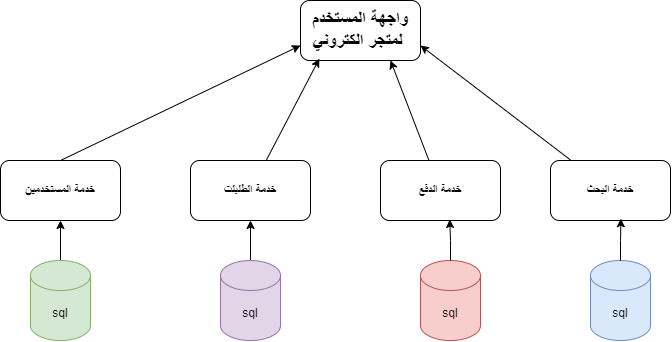
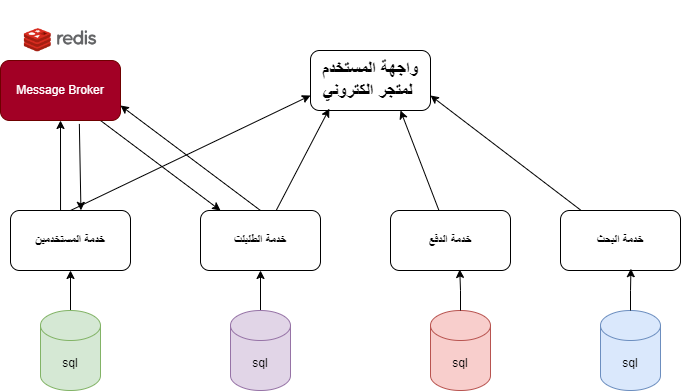
ما هي الـMicroservices؟ الـMicroservices هي نهج معماري في تطوير البرمجيات يقوم على تقسيم التطبيق إلى مجموعة من الخدمات الصغيرة والمستقلة، كل خدمة تعمل على عملية واحدة وتتواصل مع الخدمات الأخرى عبر واجهة برمجة التطبيقات (API). هذا النهج يُمكّن من تطوير ونشر وصيانة كل خدمة بشكل مستقل عن الخدمات الأخرى. عند جمع هذه الخدمات في واجهة واحدة لتكوين التطبيق بالكامل حيث يتعامل المستخدم مع واجهة التطبيق وحيدة لكن كل خدمة تنفذ بشكل مستقل عن الاخرى ويمكن ان يكون هناك تخاطب بين بعض هذه الخدمات وتتمثل بالشكل التالي: الفوائد: • الاستقلالية: كل خدمة في نموذج الـMicroservices تعمل بشكل مستقل عن الخدمات الأخرى، مما يعني أنه يمكن تحديثها، أو استبدالها، أو تطويرها دون التأثير على بقية النظام بحيث إذا فشلت خدمة ما، لا تتأثر الخدمات الأخرى. • التخصص: كل خدمة مصممة لأداء وظيفة محددة جداً، وهذا يساعد في الحفاظ على النظام نظيفًا ومنظمًا. • المرونة: يمكن توزيع الخدمات على عدة خوادم أو حتى مراكز بيانات، مما يزيد من مرونة النظام وقابليته للتوسع. • القابلية للتوسع: يسهل توسيع نطاق الخدمات حسب الحاجة. التحديات: • التعقيد: يمكن أن يزيد التعقيد في التواصل بين الخدمات. • إدارة البيانات: يجب التعامل مع تقسيم البيانات بين الخدمات المختلفة. • الأمان: يجب ضمان الأمان في التواصل بين الخدمات. مثال على التطبيق العملي لها: في تطبيق التجارة الإلكترونية، بدلاً من وجود خادم واحد كبير يحتوي على كل الوظائف، يمكن تقسيم الوظائف إلى خدمات مستقلة مثل: • خدمة المستخدمين (User Service): تتعامل مع بيانات المستخدمين. • خدمة الطلبات (Order Service): تتعامل مع عمليات الشراء والطلبات. • خدمة الاصناف (Catalog Service): تتعامل مع المنتجات والمخزون. • خدمة البحث (Search Service): تتعامل مع المنتجات والمخزون. التواصل بين الخدمات: يمكن للخدمات التواصل عبر: • رسائل الوسيط (Message Broker): حيث تُرسل الخدمات الطلبات عبر قناة رسائل مشتركة حيث الredis يعتبر نوع منه. • الاتصال المباشر: حيث تتواصل الخدمات مباشرةً مع بعضها البعض. الخلاصة: الـMicroservices تعتبر نهجاً مثالياً للمشاريع التي تتطلب مرونة عالية وسرعة في التطوير والتوسع ولكنها تأتي مع تحدياتها الخاصة. وهي ليست دائماً الحل الأمثل لكل مشروع حيث يجب تقييمها بناءً على متطلبات المشروع وقدرات الفريق أنه لديه الخبرة الكافية لإدارة هذا النوع من الأنظمة، فإنها تتطلب فهماً عميقاً للمبادئ والممارسات الجيدة، واستخدام الأدوات المناسبة للتغلب على التحديات المرتبطة بها.
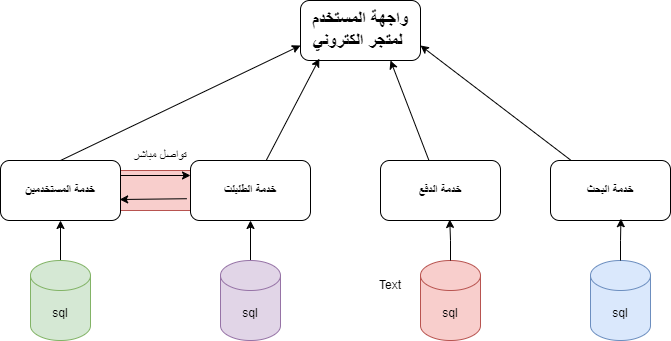
-
قبل البدء بالتفاصيل التقنية، لنتكلم قليلا لماذا ومتى نحتاج إلى اتصالات قاعدة بيانات متعددة في تطبيق Laravel الخاص بنا ؟ - تطبيق مبدأ فصل الاهتمام: فغالباً ما تنتمي البيانات المختلفة إلى مجالات أو خدمات مختلفة. - تحسين الأداء: من خلال توزيع بياناتك عبر قواعد بيانات متعددة، يمكنك تحسين أداء قاعدة البيانات. فعلى سبيل المثال، يقوم البعض باستخدام قاعدة بيانات مخصصة للعمليات الثقيلة للقراءة وأخرى للعمليات الثقيلة للكتابة. - عمليات تكامل الجهات الخارجية: في بعض الأحيان، قد تحتاج إلى الاتصال بقواعد بيانات خارجية أو قديمة لا تتوافق مع مخطط قاعدة البيانات الأساسية. تمكنك الاتصالات المتعددة من العمل مع مصادر البيانات هذه بكفاءة. - في تطبيقات التي تقدم خدمة بالاجار تسمى SAAS وخاصة في حالة تريد فصل بيانات المستخدمين عن بعضهم البعض حيث تكون الواجهة واحدة ولكن بقواعد بيانات مخصصة لكل عميل حيث تسمى هذه الهيكلية بMulti-Tenancy والآن سأقوم بشرح الخطوات لتحقيق ذلك: 1. يجب إعداد قواعد البيانات التي أريد التعامل معها: لإعداد اتصالات قاعدة بيانات متعددة نحتاج لتعريف كل اتصال منها في ملف config/database.php: // config/database.php 'connections' => [ 'mysql' => [ 'driver' => 'mysql', 'host' => env('DB_HOST', '127.0.0.1'), 'port' => env('DB_PORT', '3306'), 'database' => env('DB_DATABASE', 'default'), 'username' => env('DB_USERNAME', 'default'), 'password' => env('DB_PASSWORD', ''), // ... ], 'second_db' => [ 'driver' => 'mysql', 'host' => env('SECOND_DB_HOST', '127.0.0.1'), 'port' => env('SECOND_DB_PORT', '3306'), 'database' => env('SECOND_DB_DATABASE', 'second'), 'username' => env('SECOND_DB_USERNAME', 'second'), 'password' => env('SECOND_DB_PASSWORD', ''), // ... ], // يمكنك الإضافة بقدر ما تشائين من الاتصالات بقواعد البيانات هنا ], في هذا المثال، حددنا اتصالين بقاعدة البيانات: "mysql" (الاتصال الافتراضي) و"second_db". يمكنك إضافة المزيد من الاتصالات كما هو مطلوب، ولكل منها تكوينها الخاص.2. تعيين متغيرات البيئة: للحفاظ على أمان بيانات الوصول لقاعدة البيانات، يجب الالتزام باستخدم ملف .env لتخزينها. لذلك يجب تعيين متغيرات البيئة لكل اتصال قاعدة بيانات قمنا بانشائه كما يلي: DB_CONNECTION=mysql DB_HOST=127.0.0.1 DB_PORT=3306 DB_DATABASE=your_database DB_USERNAME=your_username DB_PASSWORD=your_password SECOND_DB_CONNECTION=mysql SECOND_DB_HOST=127.0.0.1 SECOND_DB_PORT=3306 SECOND_DB_DATABASE=second_database SECOND_DB_USERNAME=second_username SECOND_DB_PASSWORD=second_password وتأكد من تطابق أسماء متغيرات البيئة مع تلك المعرفة في config/database.php. 3. نقوم بإنشاء النماذج (models): مثلاً هنا سأقوم بإنشاء نموذج لكل قاعدة بيانات: php artisan make:model User -m php artisan make:model Product -m يقوم هذا الأمر بإنشاء ملفات النموذج وملفات الترحيل (migrations) لكل نموذج. 4. تحديد الاتصال في ملفات النموذج التي تم إنشاؤها: // app/Models/User.php protected $connection = 'mysql'; // app/Models/Product.php protected $connection = 'second_db'; 5. تشغيل عمليات الترحيل (migrate) الآن، يمكنك تشغيل عمليات الترحيل لكل اتصال على حدة: php artisan migrate php artisan migrate --database=second_db سيؤدي هذا إلى إنشاء الجداول اللازمة في قواعد البيانات الخاصة بكل منها.الآن أصبح كل نموذج يتعامل مع قاعدة بيانات مختلفة: فمثلاً للتأكد يمكنك الآن الاستعلام عن البيانات من قواعد بيانات متعددة باستخدام نماذج كل قاعدة بيانات. وفيما يلي مثال على كيفية استرداد المستخدمين والمنتجات من قاعدتي البيانات لدينا: use App\Models\User; use App\Models\Product; // Retrieve users from the 'mysql' database $users = User::all(); // Retrieve products from the 'second_db' database $products = Product::all(); وهنا يتولى لارافل مهمة توجيه استعلاماتك إلى قاعدة البيانات الصحيحة بناء على خاصية اتصال النموذج التي قمنا بوضها في كل نموذج.

- 4 اجابة
-
- 1
-

-
 يمكن القيام بذلك عبر اضافة شرط تحقق من تساوي العنصر مع الرقم 2 وبعدها طباعة مجموع 2 و 5: my_list = [1,2,3,4] for x in my_list: if x ==2: print(x + 5) يمكن تعميم الكود على اي رقم تريده وجمع له اي رقم تريده عبر اضافة متغران وجعله بالشكل التالي : حيث تم المرور على عناصر الlist واختبار تساوي الرقم مع العنصر المطلوب وبعدها زيادة له الرقم المطلوب my_list = [1, 2, 3, 4] # طلب رقم من المستخدم user_number = int(input("أدخل رقمًا تريد ان تضيف عليه من القائمة: ")) # طلب رقم الذي تريد اضافته add_number = int(input("أدخل رقم الذي تريد اضافته: ")) for x in my_list: if x == user_number: print(x + add_number) وملاحظة مهمة ان طريقة المرور على العناصر بالطريقى التي استخدمها مصطفى في التعليق الشابق تعتبر اسرع ومفيدة في عدد العناصر الكبير لكن هذه الطريقة مناسبة للقراءة اكثر ويجب انت تعرف الطريقتين
يمكن القيام بذلك عبر اضافة شرط تحقق من تساوي العنصر مع الرقم 2 وبعدها طباعة مجموع 2 و 5: my_list = [1,2,3,4] for x in my_list: if x ==2: print(x + 5) يمكن تعميم الكود على اي رقم تريده وجمع له اي رقم تريده عبر اضافة متغران وجعله بالشكل التالي : حيث تم المرور على عناصر الlist واختبار تساوي الرقم مع العنصر المطلوب وبعدها زيادة له الرقم المطلوب my_list = [1, 2, 3, 4] # طلب رقم من المستخدم user_number = int(input("أدخل رقمًا تريد ان تضيف عليه من القائمة: ")) # طلب رقم الذي تريد اضافته add_number = int(input("أدخل رقم الذي تريد اضافته: ")) for x in my_list: if x == user_number: print(x + add_number) وملاحظة مهمة ان طريقة المرور على العناصر بالطريقى التي استخدمها مصطفى في التعليق الشابق تعتبر اسرع ومفيدة في عدد العناصر الكبير لكن هذه الطريقة مناسبة للقراءة اكثر ويجب انت تعرف الطريقتين -
من المهم فهم الفرق بين "الصلة"(relevance) و"التشابه"(similarity). أن التشابه يتعلق بالتشابه في مطابقة الكلمات ، الا ان الصلة تتعلق بترابط الأفكار. يمكنك تحديد المحتوى القريب لغويا باستخدام الاستعلام على قاعدة بيانات متجهة(vector database)، ولكن تحديد المحتوى ذي الصلة واسترداده يتطلب أدوات أكثر تطورا. حيث البنية العامة لنظام الاسترجاع من الشكل التالي حيث يوجد فيه قاعدة بيانات متجهة يتم الاستعلام (query)عليها بواسطة حساب التشابه بين الاستعلام والمتجهات داخل قاعدة البيانات : فان من الاستراتيجيات المتبعة هي تقسيم الملفات الى اجزاء اصغر يمكن لنظام RAG تحديد التشابه بسرعة ودقة أكبر في أجزاء نصية أصغر منه في المستندات الكبيرة. في حين أن الأجزاء الأكبر يمكن أن تلتقط المزيد من السياق ، إلا أنها تجعل نسبة التشابه اقل فعالية وتتطلب المزيد من الوقت وتكاليف الحوسبة للمعالجة.لكن القطع الأصغر قد لا تلتقط السياق الضروري بالكامل وهذه هي مشكلتك يصعب تحديد الاجزاء ذات الصلة. في حال التقطيع كيف يمكنك التأكد من اختيار الجزء الصحيح؟ تعتمد فعالية استراتيجية التقطيع إلى حد كبير على جودة وهيكل هذه القطع اي لا يوجد طريقة لتقييم مدى جودتها سوى عن طريق مراجعة يدوية. يمكن التغلب على هذه القيود عن طريق اتباع احد الاستراتيجيتان ادخال أجزاء المتداخلة : هي طريقة لتحقيق التوازن بين كل من هذه القيود. من خلال تداخل الأجزاء ، من المحتمل أن يسترد الاستعلام بيانات كافية ذات صلة عبر متجهات متعددة من أجل إنشاء استجابة سياقية بشكل صحيح.لكن أحد القيود هو أن هذه الاستراتيجية تفترض أن جميع المعلومات التي يجب عليك استردادها يمكن العثور عليها في مستند واحد. إذا تم تقسيم السياق المطلوب عبر مستندات مختلفة متعددة، فقد تفشل وسوف تفكر في الاستفادة من الحلول مثل التسلسلات الهرمية للمستندات وهي الاستراتيجية الثانية. التدرجات الهرمية للمستندات: يعد التسلسل الهرمي للمستندات طريقة فعالة لتنظيم بياناتك لتحسين استرجاع المعلومات وتاخذ الشكل التالي. تربط التدرجات الهرمية للمستندات الأجزاء بالعقد، وتنظم العقد في العلاقات بين الأصل والابن. وتحتوي كل عقدة على ملخص للمعلومات الواردة فيها، مما يسرع نظام RAG ويعرفه بالأجزاء التي يجب استخراجها. مثال : لنفترض أن الشركة متعددة البلدان لديها 10 مكاتب للموارد البشرية وأن لكل مكتب سياسة الموارد البشرية الخاصة بكل بلد ، ولكنها تستخدم نفس النموذج لتوثيق هذه السياسات. ونتيجة لذلك، فإن وثيقة سياسة الموارد البشرية لكل مكتب لها نفس التنسيق تقريبا، ولكن كل قسم سيفصل السياسات الخاصة بكل بلد لقضاء العطلات الرسمية، والرعاية الصحية، وما إلى ذلك. في قاعدة بيانات المتجهات ، ستبدو كل فقرة "أيام العطل الرسمية" متشابهة جدا. في هذه الحالة ، يمكن للاستعلام المتجه استرداد الكثير من نفس البيانات غير المفيدة ، مما قد يؤدي إلى الضياع في الحالة العادية او في الاستراتيجية الاولى.لكن باستخدام التسلسل الهرمي للمستندات، يمكن لنظام RAG الإجابة بشكل أكثر موثوقية على سؤال حول العطلات الرسمية لمكتب دمشق من خلال البحث أولا عن المستندات ذات الصلة بمكتب دمشق. ملاحظة الاستراتيجية الثانية تتطلب خبرة اكثر في بنائها. وتتطلب خبرة خاصة بالمجال أو مشكلة محددة للإنشاء لضمان أن تكون الملخصات ذات صلة كاملة بالمهمة المطروحة. يمكن انشاء الملخصات يدويا او بواسطة ادوات ونماذج قد تساعد في عملية التلخيص
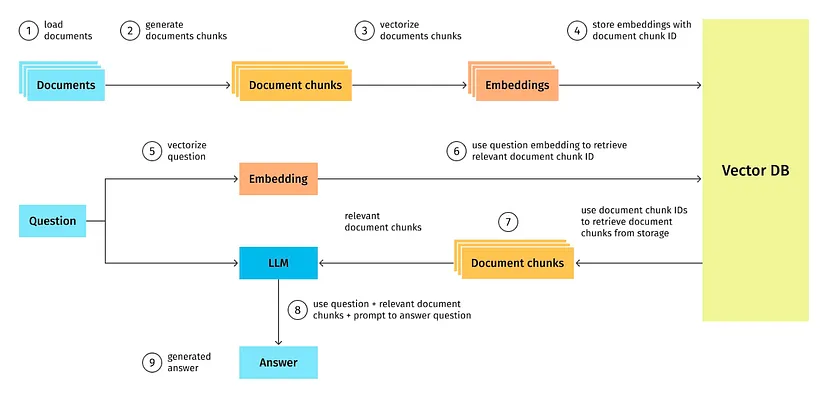
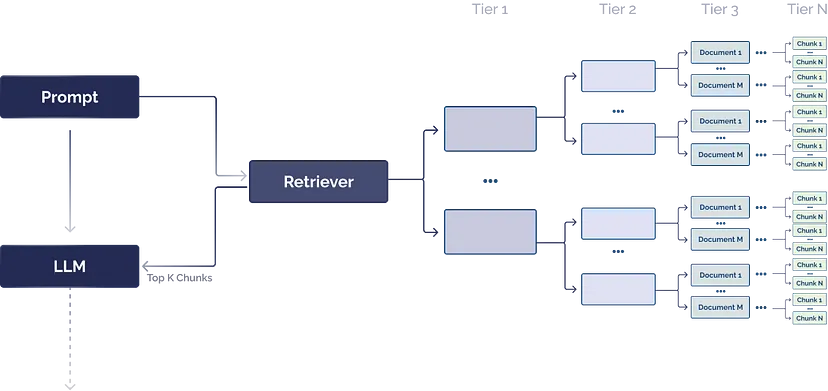
- 6 اجابة
-
- 1
-
-
الفرق بين Eloquent ORM و Query Builder في لارافل يكمن في طريقة التعامل مع قاعدة البيانات وتمثيل البيانات: Eloquent ORM: ORM هي اختصار لـ Object Relational Mapper حيث يمثل طبقة وسيطة بين قاعدة البيانات وعمليات الطلب عليها اذ يؤمن الاتصال معها دون الخوض في تعلم التعليمات الخاصة بها حيث ميزاته: هو نظام لتمثيل الجداول والعلاقات بينها في شكل كائنات (objects). يسهل إنشاء العلاقات بين الجداول والتعامل معها. يوفر طريقة سهلة لإجراء العمليات مثل الإدخال، التحديث، الحذف، والاستعلام وغيرها. تربط كل جدول في قاعدة البيانات بكائن يدعى(model). مثال عن جلب كافة المستخدمين: $users = User::all(); مثال عن إنشاء بيانات جديدة: $user = new User(); $user->name = 'Ali Ibrahim'; $user->email = 'ali@example.com'; $user->save(); Query Builder: هي أداة تسمح بإنشاء استعلامات SQL برمجياً. تناسب بناء استعلامات معقدة وتنفيذ عمليات متنوعة على البيانات. توفر مرونة أكبر في كتابة الاستعلامات البرمجية. مثال عن جلب كافة المستخدمين: $users = DB::table('users')->get(); مثال عن إنشاء بيانات جديدة: DB::table('users')->insert([ 'name' => 'Ali Ibrahim', 'email' => 'ali@example.com', ]); أيهما أفضل للاستخدام؟ الاختيار بينهما يعتمد على احتياجات المشروع وتفضيلات المطور. بشكل عام، Eloquent ORM يوفر طريقة أكثر سهولة وتجريداً للتعامل مع البيانات، بينما Query Builder يوفر مرونة أكبر في كتابة الاستعلامات على قاعدة البيانات. إذا كنت تقوم بتطوير تطبيق لارافل وتحتاج إلى طريقة بسيطة وسهلة الاستخدام للتفاعل مع قاعدة البيانات، فإن Eloquent يعد خياراً جيداً. وإذا كنت بحاجة إلى تنفيذ استعلامات معقدة أو إذا كنت بحاجة إلى استخدام ميزات غير مدعومة بواسطة Eloquent أو كنت تهتم بالسرعة، فإن Query Builder هو الخيار الأفضل. ملاحظة أخيرة: يمكن الدمج بينهما بحيث يمكن اعتماد ORM للمشروع كامل وفي بعض الحالات نستخدم Query Builders https://academy.hsoub.com/questions/24095-ما-هو-الفرق-بين-eloquent-و-query-builder-في-laravel؟/https://academy.hsoub.com/questions/24095-ما-هو-الفرق-بين-eloquent-و-query-builder-في-laravel؟/
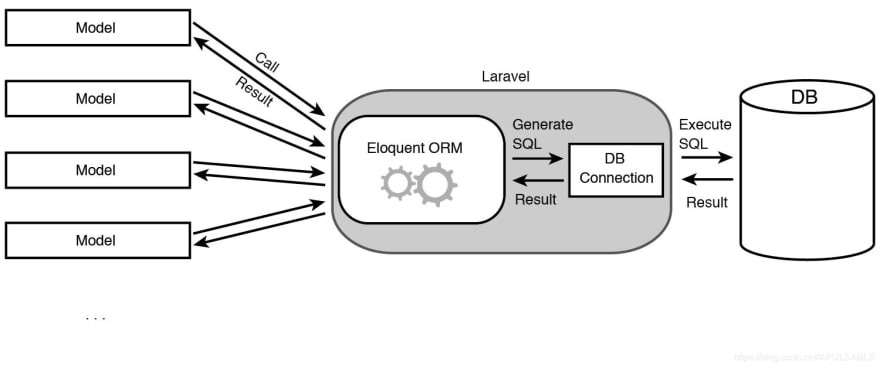
-
فهم الاساسيات: يعد الفهم الأساسي للمفاهيم الرياضية ، وخاصة الجبر الخطي وحساب التفاضل والتكامل والاحتمال ، أمرا بالغ الأهمية للنجاح في الذكاء الاصطناعي. التحولات الخطية والمصفوفات شائعة في الذكاء الاصطناعي الخوارزميات ، مما يدل على أهمية فهم هذه المفاهيم. يعد فهم الإحصاءات ، مثل الأهمية الإحصائية والتوزيع والانحدار والاحتمال ، أمرا ضروريا أيضا لتطبيقات الذكاء الاصطناعي. تعد العقلية الاستباقية والحماس للتعلم أمرا بالغ الأهمية لأولئك الذين يتطلعون إلى التقدم في الذكاء الاصطناعي ، حيث يتطور المجال باستمرار مع التطورات والتقنيات الجديدة. لذلك ، فإن الفهم الأساسي لهذه المفاهيم ضروري للنجاح في الذكاء الاصطناعي. تتطلب الذكاء الاصطناعي الأدوار مستويات متفاوتة من الفهم والإتقان في مجالات المتطلبات الأساسية ، اعتمادا على الدور. قد لا يحتاج علماء البيانات إلى فهم متعمق لجميع المفاهيم الرياضية ، في حين أن علماء الأبحاث الذين يهدفون إلى إنشاء خوارزميات الذكاء الاصطناعي جديدة قد يحتاجون إلى فهم أكثر عمقا للرياضيات. لذلك فهم اساسيات الرياضية وليس الخوص بالتفاصيل ونترك الغوص في التفاصيل للمرحلة التي تحدد المجال الذي شعرت بشغف تجاهه. يمكن اتباع الخطة التالية لنرفض على مدار السنة حيث يمكن زيادة او التلاعب بالمدة حسب الاستيعاب : الشهر 1-3: أساسيات الرياضيات والبرمجة وهياكل البيانات ومعالجتها: الرياضيات والإحصاء: ابدأ بأساسيات الجبر الخطي وحساب التفاضل والتكامل والإحصاء والاحتمالات. سيعطيك هذا أساسا قويا لما سيأتي. برمجة: تعلم بايثون ، اللغة الأكثر استخداما في الذكاء الاصطناعي. ابدأ بالأساسيات ثم انتقل إلى مفاهيم أكثر تقدما. خذ مسار مهارة أساسيات Python ومعالجة البيانات باستخدام Python Skill Track لتغطية الأساسيات ، بما في ذلك الحزم مثل NumPy. معالجة البيانات: ابدأ في التعرف على معالجة البيانات وتحليلها. تعرف على مكتبات Python مثل الباندا و NumPy ، والتي ستستخدمها لمعالجة البيانات. تعرف على كيفية تنظيف البيانات وإعدادها، وهو جزء مهم من أي مشروع الذكاء الاصطناعي أو التعلم الآلي. الشهر 4-6: تعمق أكثر في الذكاء الاصطناعي والتعلم الآلي: أساسيات الذكاء الاصطناعي: فهم ما هو الذكاء الاصطناعي وتاريخه وفروعه المختلفة. يمكن أن توفر الدورات التدريبية التي توفر أساسيات الذكاء الاصطناعي بداية جيدة. تعميق معرفتك بالتعلم الآلي: تعرف على أنواع مختلفة من خوارزميات التعلم الآلي - التعلم الخاضع للإشراف وغير الخاضع للإشراف وشبه الخاضع للإشراف والتعلم المعزز. واحرص على معرفة أهم أنواع النماذج ، وطريقة التحقق من صحة النموذج ، وضبط المعلمات الفائقة(Fine-tuning ). ووالتعرف ب TensorFlow و Keras واختم المرحلة بمعرفة عن التعلم العميق وفرقه عن خوارميات التعلم الالي وماهي اهم انواع الشبكات العصبونية. الشهر 7-9: التخصص والموضوعات المتقدمة: التعلم العميق: فهم الشبكات العصبية والتعلم العميق عبر حل امثلة لمواضيع بسيطة لانواعه المختلفة. أساسيات MLOps: تعرف على MLOps ، والذي يتعلق بتطبيق مبادئ DevOps على أنظمة التعلم الآلي. يتضمن ذلك إصدار النموذج ونشر النموذج والمراقبة والتنسيق. التخصص: بناء على اهتماماتك وتطلعاتك المهنية ، تخصص في مجال واحد - يمكن أن يكون معالجة اللغة الطبيعية أو رؤية الكمبيوتر أو التعلم المعزز أو أي مجال آخر. الشهر 10 والى النهاية - استمر في التعلم والاستكشاف: تخصص أكثر: حاول قراءة كتابين على الاقل في المجال الذي اخترته بحيث في النهاية عند قراءة عناوين في الكتاب تكون قادر على الاجابة وشرح مفهوم معين. ابق على اطلاع: تابع بانتظام المدونات والبودكاست والمجلات ذات الصلة الذكاء الاصطناعي. انضم إلى المجتمعات لتبادل الأفكار مع ممارسي الذكاء الاصطناعي الآخرين. وتذكر دائما الأخلاق في الذكاء الاصطناعي: عندما تتعلم المزيد عن الذكاء الاصطناعي ، تأكد أيضا من التعرف على الاعتبارات الأخلاقية في الذكاء الاصطناعي. نصيحة اخيرة : الذكاء الاصطناعي مجال سريع التطور. بمجرد حصولك على الأساسيات ، من المهم الاستمرار في التعلم وتحسين مهاراتك. اتبع الذكاء الاصطناعي المدونات ، واقرأ الأوراق البحثية ، وخذ دورات متقدمة ، وابحث دائما عن طرق جديدة لتحدي نفسك. ستحولك هذه العملية التكرارية من مبتدئ إلى خبير. وتذكر أن الرحلة إلى التعلم الذكاء الاصطناعي صعبة ولكنها مشوقة للغاية. لا تثبط عزيمتك إذا واجهت عقبات على طول الطريق. إنهم جزء من عملية التعلم. ضع هدفك النهائي في الاعتبار ، وابق ملتزما. بالتوفيق لك❤️
- 2 اجابة
-
- 1
-
-
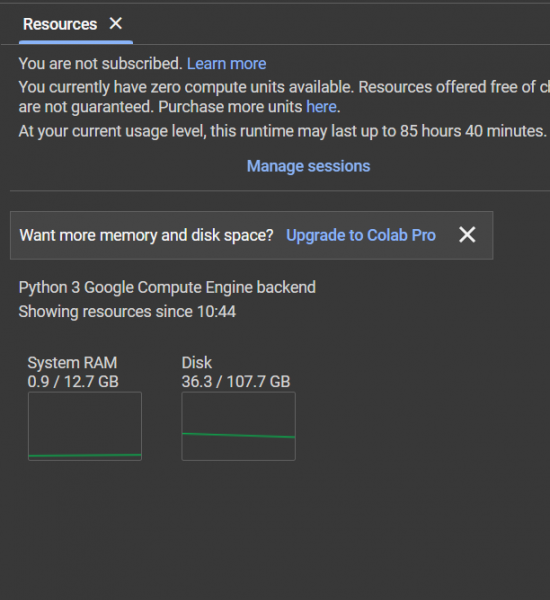
إن الحوسبة السحابية تعني توفير موارد تقنية كا(CPUوGPU والتخزين ورام) حسب الطلب عبر الإنترنت مع تسعير التكلفة حسب الاستخدام. فبدلاً من شراء مراكز البيانات والخوادم المادية وامتلاكها والاحتفاظ بها ودفع سعر عالي جدا لامتلاكها، يمكنك الوصول والاستفادة من الخدمات التكنولوجية، مثل إمكانات الحوسبة، والتخزين، وقواعد البيانات، بأسلوب يعتمد على احتياجاتك، وذلك من خلال جهة موفرة للخدمات السحابية مثل Amazon Web Services (AWS) وgoogle colab وغيرها. Google Colab (اختصار لـ Google Colaboratory) هي بيئة تطوير قائمة على السحابة تقدمها Google. يسمح للمستخدمين بكتابة وتنفيذ كود Python في متصفح الويب دون الحاجة إلى أي إعداد أو تثبيت. تم تصميم Google Colab فوق Jupyter Notebook ويوفر بيئة حوسبة مجانية مع إمكانية الوصول إلى موارد وحدة المعالجة المركزية (CPU) ووحدة معالجة الرسومات (GPU) وحتى موارد TPU. تعتبر بيئة Colab شبيهة جدا بال(notebooks jupyter) كالاتي : وتعطي موراد عالية مجانية واخرى مدفوعة وذلك حسب الحاجة , في الخطة المجانية يعطي 12G ram و 107G تخزين فهي خيار جيد جدا عند التعامل مع بيانات كبيرة او نماذج ذكاء اصطناعي يحتاج موارد عالية قد لا تتوفر في الاجهزة المكتبية الموجودة في المنزل لذلك اخدمة السحابية تؤمن لك البيئة المناسبة دون الاطرار الى جلب موارد اعلى او التعامل مع تثبيت هكذا موارد . بنسبة للذكاء الاصطناعي سيطرت Google Cloud و Azure و AWS على المساحة السحابية لبضع سنوات حتى الآن بسبب الميزات والقدرات التي توفرها وهم يقدمون خدمات متشابهة تماما لكن يوجد موفرين اخرين اقل كلفة لكن لا يوجد فهما الخدمات الموجودة في Google Cloud و Azure و AWS لكنهما حل وسيط بين الخدمة الجيدة والرخص. حيث لا توفر فقط (CPUوGPU والتخزين ورام) بل اوفر نماذج ضخمة قد يحتاج المطورون الذين يسعون إلى إنشاء تطبيقات الذكاء الاصطناعي توليدية إلى أدوات ومنصات قوية لإحياء أفكارهم. يقدم اثنان من المتنافسين الرئيسيين في مجال الحوسبة السحابية ، Amazon Web Services (AWS) و Microsoft Azure ، منصات الذكاء الاصطناعي قوية وهي AWS Bedrock و Azure OpenAI. تتضمن الميزات الرئيسية ل AWS Bedrock ما يلي: الوصول إلى نماذج تأسيسية متعددة ، بما في ذلك نموذج Titan و Falcon الذكاء الاصطناعي من Amazon. التكامل مع خدمات AWS، وتبسيط عملية التطوير. رقائق مخصصة(CPU) مصممة لتدريب نماذج الذكاء الاصطناعي ، مما قد يقلل من التكاليف للمطورين. تتضمن الميزات الرئيسية ل Azure OpenAI ما يلي: الوصول إلى سلسلة GPT-4 وسلسلة GPT-35-Turbo ونماذج سلسلة التضمين. إمكانات الضبط الدقيق(Fine-tuning) لنماذج عدة. لذلك تعد الحوسبة السحابية مهمة جدا وخاصة في المشاريع الحقيقية التي تتطلب دقة اما في حال المشاريع التي في الجامعة او المشاريع التعليمية تعتبر بسيطة لا تحتاج الى موارد كبيرة . وكما يعتبر تعلم تكامل الخدمات السحابية واحدة من المهارات الواجب على كل مهندس ذكاء اصطناعي التعامل معها.
-
الحل بسيط بالذهاب الى المسار التالي app/Exceptions/Handler.php وقومي بوضع الاستدعاء التالي في اعلى الملف use Illuminate\Auth\AuthenticationException; وبعدها ضعي التابع التالي داخل كلاس ال Handler : protected function unauthenticated($request, AuthenticationException $exception) { if ($request->expectsJson()){ return response()->json(['message' => "Token is expired"], 401); } return parent::render($request, $exception); } يمكن نغير الرسالة بتغير الرسالة التالي كما تريد او ارجاع اي رسالة او رد ترغب به Token is expired سوف يظهر الرد كالتي { "message": "Token is expired" } حيث قمنا بعمل Overriding للدالة unauthenticated باعادة تعريفها مرة اخرة وتغير الجسم الخاص بها وتعبر رسالة unauthenticated نوع من الException لذلك الموقع المناسب لها في ملف Handler الخاص بال Exception
- 3 اجابة
-
- 1
-
-
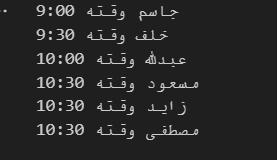
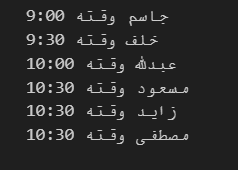
الخطأ بسبب تجاوز حدود المصفوفة كما ترا المصفوفة الاولى يختلف حجمها عن الثانية لذلك انته لهذه المشكلة ولحل المشكلة يمكن تخزين اول ثلاث طلاب في حال كانت المصفوفة مرتبة حسب الافضل students = ['جاسم', 'خلف', 'عبدلله', 'مسعود', 'زايد', 'مصطفى'] appointment_times = ['9:00', '9:30', '10:00', '10:30'] first_3_students = students[:3] first_3_appointment_times= appointment_times[:3] تسمى هذه العملية بSlicing اي اقتطاع اول 3 عناصر هنا من مصفوفة الطلاب بعدها يمكن المرور على المصفوفتات المتشابهتان بالحجم بالطريقة التالية for i in range(first_3_students): print(f"{first_3_students[i]} وقته {first_3_appointment_times[i]}") ولباقي الطلاب rest_students = students[3:] for i in range(rest_students): print(f"{first_3_students[i]} وقته {appointment_times[-1]}") الخرج : لكن ليكون الكود اكثر احترافية يمكن استعمال الدالة zip لتمشي على المصفوفتان سويا وتاخذ الطول الاقصر دون ان تعطي خطأ وبعدها يمكن المرور على باقي الطلاب واعطائهم اخر قيمة students = ['جاسم', 'خلف', 'عبدلله', 'مسعود', 'زايد', 'مصطفى'] appointment_times = ['9:00', '9:30', '10:00', '10:30'] first_3_students = students[:3] unique_appointments = {student: time for student, time in zip(first_3_students, appointment_times)} shared_appointment_time = appointment_times[-1] shared_appointments = {student: shared_appointment_time for student in students[3:]} all_appointments = {**unique_appointments, **shared_appointments} for student, time in all_appointments.items(): print(f"{student} وقته {time}") حيث العملية التالية هي وضعهم ضمن قاموس (dictionary) لنتيجة الطلاب الاوائل والطلاب الباقين على التوالي {student: shared_appointment_time for student in students[3:]} {student: shared_appointment_time for student in students[3:]} ثم دمج القاموسين عن طريق التعليمة التالية {**unique_appointments, **shared_appointments} ويكون الخرج مشابه كالاتي وفيما يلي الشكل dictionary التي تتكون من مفتاح عبارة عن الاسم والقيمة هي الوقت الخاص فيه
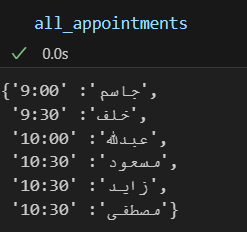
- 3 اجابة
-
- 1
-
-
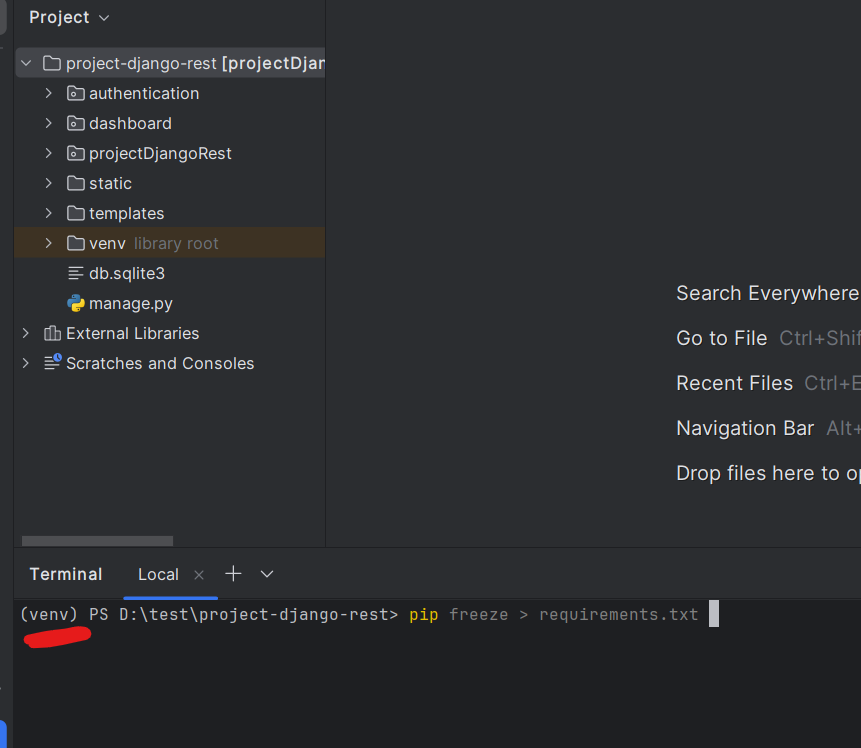
لا ترفع المكتبات الى الاستضافة لانها يجب ان تاخذ مسار محدد فالطريقة الاسلم هي انشاء ملف للمكاتب المطلوبة عبر الامر التالي ينفذ في التيرمنال في المسار الخاص بالمشروع pip freeze > requirements.txt # To update your requirements.txt file ينشأ ملف نصي ذو لاحقة txt يخزن داخله جميع المكاتب المطلوبة بهذا الشكل: حيث ينصح العمل مع بيئة افتراضية لضمان عدم جلب مكتبات لا داعي لها حيث ان التعليمة freeze تجلب اسماء المكاتب من البيئة المفعلة وفي حال عدم تفعيل بيئة افتراضية يجلب اسماء المكتبات جميعها من بايثون العامة في النظام وهذا يؤدي لجلب مكاتب قد تكون لا حاجة اليها وهذا يؤثر على المساحة على الاستضافة تصبح محجوزة لملفات مكاتب غير ضرورية وعند الرفع تنفبذ التعليمة في الخادم pip install -r requirements.txt ولمعومات اكثر توجه للجواب سابق يفصل طريقة الرفع على استضافة render https://academy.hsoub.com/questions/28164-رفع-مشروع-جانغو-على-استضافة/?do=findComment&comment=87824
-
كيفية إنشاء روبوت محادثة على واتساب باستخدام واجهة API الخاصة بواتساب للأعمال: 1) واتساب للأعمال API الخطوة المنطقية الأولى هي الوصول إلى واجهات برمجة تطبيقات WhatsApp للأعمال. هناك طريقتان للقيام بذلك: أ) بناء الروبوت بنفسك عن طريق طلب الوصول إلى واجهات برمجة تطبيقات الأعمال. ب) العمل مع الشريك الذي سيقوم بالرفع الثقيل من حيث تطوير الروبوت نيابة عنك. ولكن من الواضح أن هذا سيكلفك ذلك. حيث سنركز على الأول ، حيث سنتطلع إلى إنشاء روبوت أعمال WhatsApp الخاص بنا. توجه إلى link ، املأ هذا النموذج عادة ما يستغرق WhatsApp ما بين 4 إلى 7 أسابيع من الوقت للموافقة على طلبك. يمكن اتخاذ الخطوات القليلة التالية خلال هذه الفترة للمساعدة في الحصول على واجهات برمجة التطبيقات. 2) حساب فيسبوك للأعمال إنشاء حساب أعمال على مدير أعمال فيسبوكbusiness.facebook. ستحتاج إلى ملف تعريف Facebook لإنشاء حساب تجاري. هذه الخطوة مهمة نظرا لأن فريق Facebook يبحث عن معلومات حول مؤسستك على مدير أعمال Facebook وموقعك على الويب. 3) بيئة Twilio Sandbox أثناء انتظار الموافقة ، من الأفضل صقل مهاراتك في بيئة رمل والتي لحسن الحظ يتم توفيرها بواسطة Twilio وفقا ل Twilio ، "يتيح لك إرسال واستقبال رسائل معتمدة مسبقا إلى الأرقام التي تنضم إلى Sandbox الخاص بك ، باستخدام رقم اختبار Twilio". أ) يعطي Twilio رقم Twilio اختبارا لنا لاختبار رسائل القالب. يوفر رقم هاتف Twilio وجودا محاكيا على شبكة الهاتف. ب) تسمح لنا واجهة المستخدم بتكوين رسائل الرد على بعض الكلمات ك hi وغيرها. سيتعين عليك إنشاء نظام خلفي باستخدام Node JS أو Django (أو أي إطار عمل خلفي لهذه المسألة) لتقديم طلبات النشر إلى واجهات برمجة التطبيقات الخاصة ب Twilio. إذا كنت مهتما بتعلم مكتبة Twilio مع بايثون الرابط التالي سيكون بداية جيدة link، 4) متطلبات البنية التحتية لتطبيق WhatsApp متطلبات البنية التحتية لتشغيل واجهة برمجة تطبيقات WhatsApp Business ، يعتمد ذلك على تحميل الرسائل ، يوصي فريق WhatsApp بما لا يقل عن 250 جيجابايت SSD مع ذاكرة وصول عشوائي (RAM) بسعة 16 جيجابايت وإعداد رباعي النواة. أيضا
- 4 اجابة
-
- 1
-
-
يمكن اختصاره بالشكل التالي الى سطر واحد حيث قمنا بالاستغناء عن المتغيرات ووضعناهم بشكل مباشر حيث تعطي نفس النتيجة لكن ينصح بكتابة المتغيرات كي يكون الكود قابل للقراءة اكثر import random print( ["_" for _ in random.choice(["good", "bada"])]) يكون الخرج ['_', '_', '_', '_'] مثلما قال صديقي مصطفى ويمكنك تبديب "_ " بتغير اخر مثل char لان حلقة ال for يقوم بالمرور على احرف الكلمة المختارة حرف حرف
- 2 اجابة
-
- 1
-
-
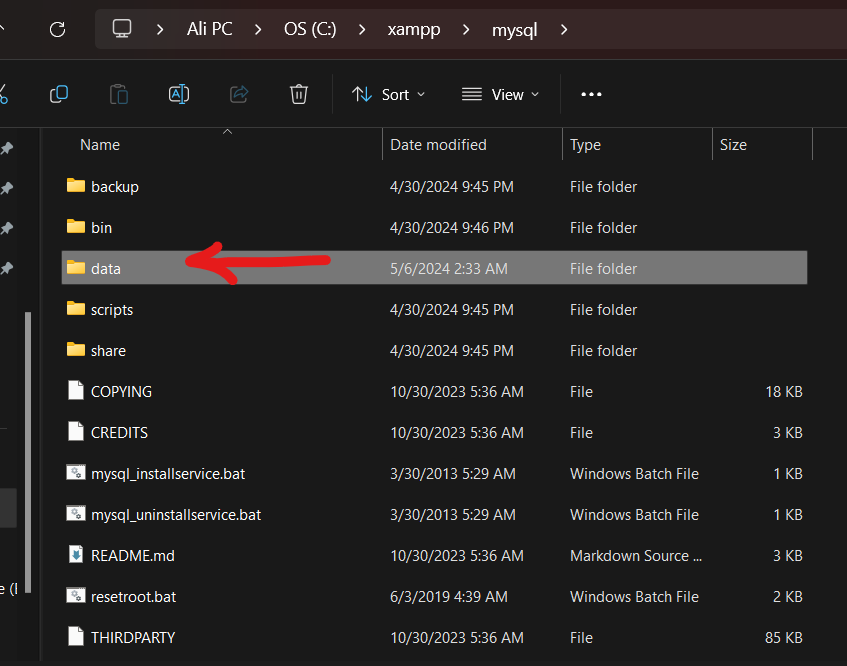
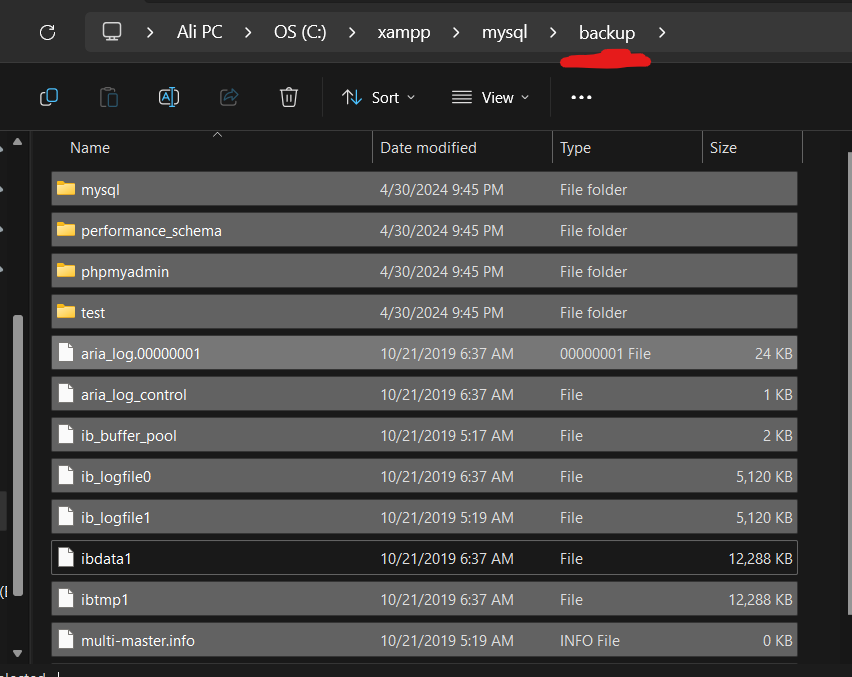
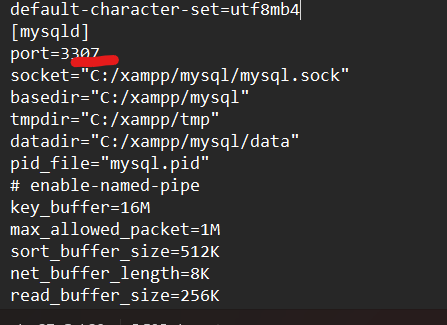
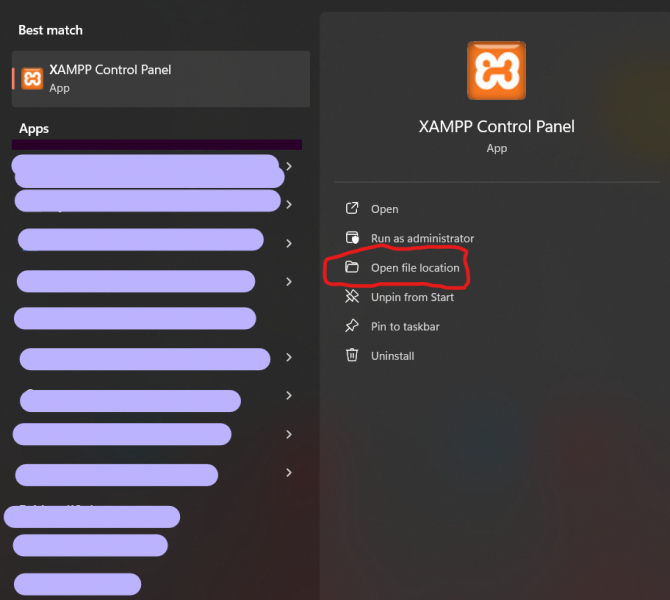
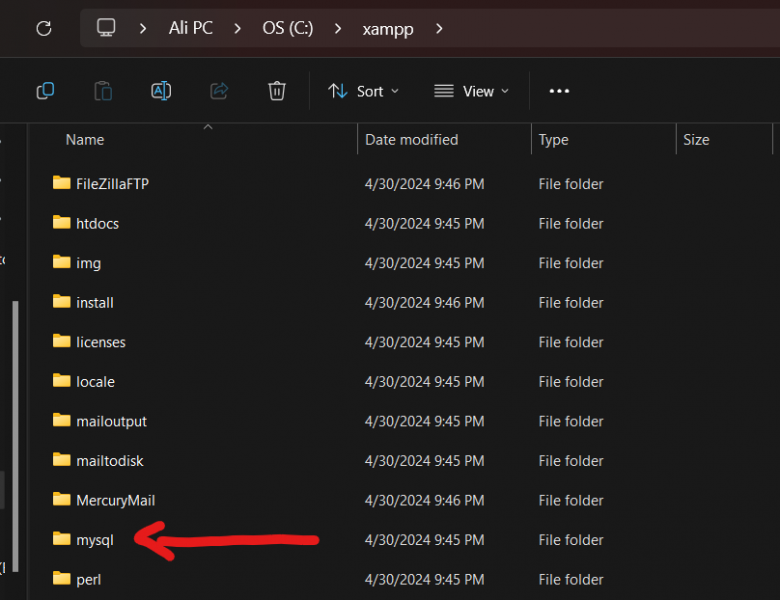
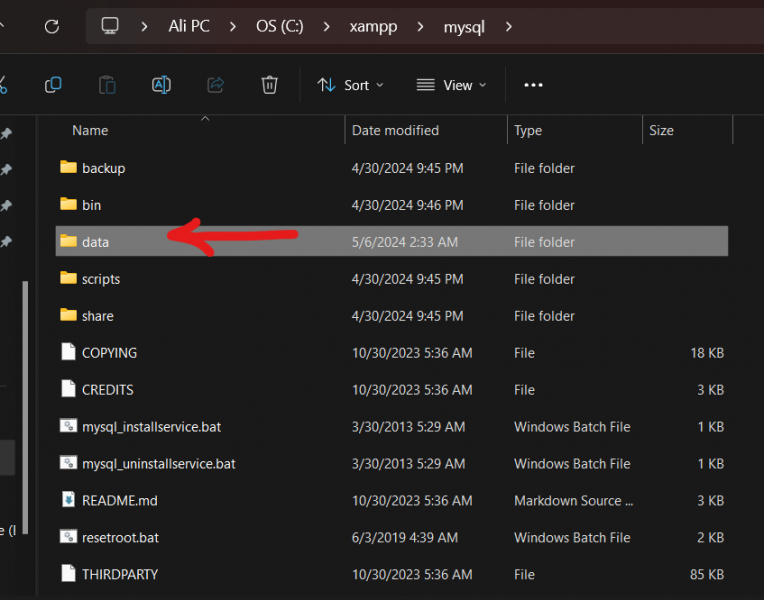
تاكد من امرين 1. تغير المنفذ(port) الى منفذ جديد حيث قد يكون المنفذ الذي تستعله خدمة MySQL محجوز حاليا، جرب اغلاق البرنامج الذي يحجز المنفذ أو قم بتغيير منفذ MySQL. ولذلك قم بالتالي اضغط my.ini<----config : وبعدها غير قيمة المنفذ الى 3307 وبعدها قم بحفظ الملف بالضغط على (ctr+ sl ) حاول اعادة تشغيل البرنامج واذا لم يعمل عليك تجريب الطريقة الثانية اولا : اذهب الى موقع تخزين ال xamp : ثانيا ادخل الى المجلد Mysql: ثالثا قم بنسخ المجلد data في نفس المكان وذلك اذا حدث خطأ ما لا تضيع شيئ منها رابعا: ادخل الة مجلد data وقم بحذف المجلدات التالية : وبعدها حذف الملفات التالية باستثناء الملف idata1 خامسا: قم بالذهاب للمجلد backup وقم بنسخ المجلدات والملفات جميعها ما عدا الملف idata1 وضعها في مجلد الdata السابق وعد الى تشغيل السيرفر مجددا


- 5 اجابة
-
- 1
-
-
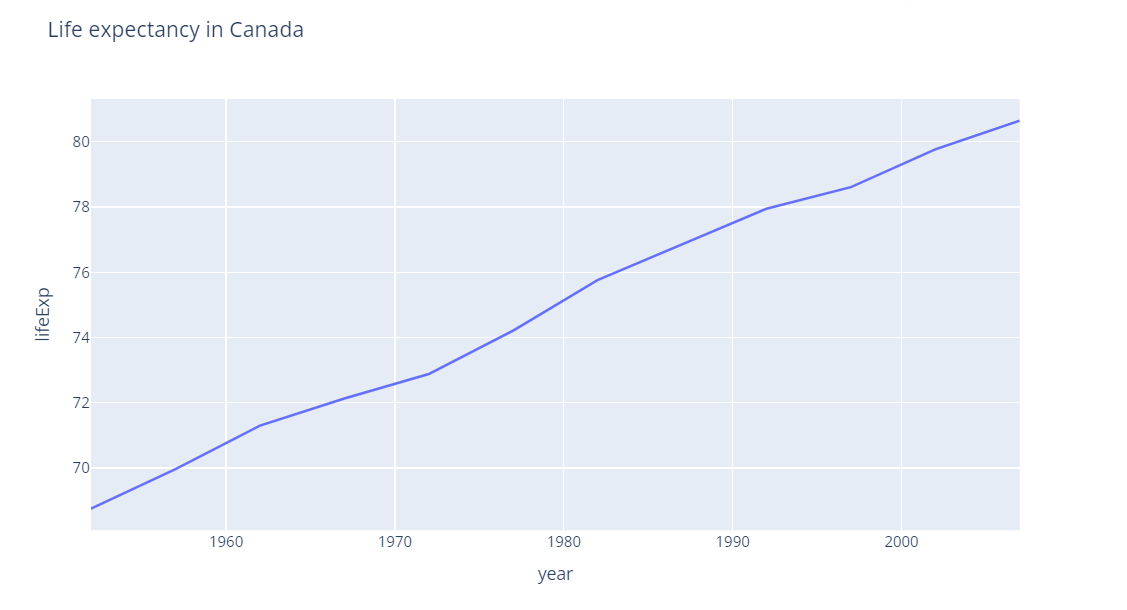
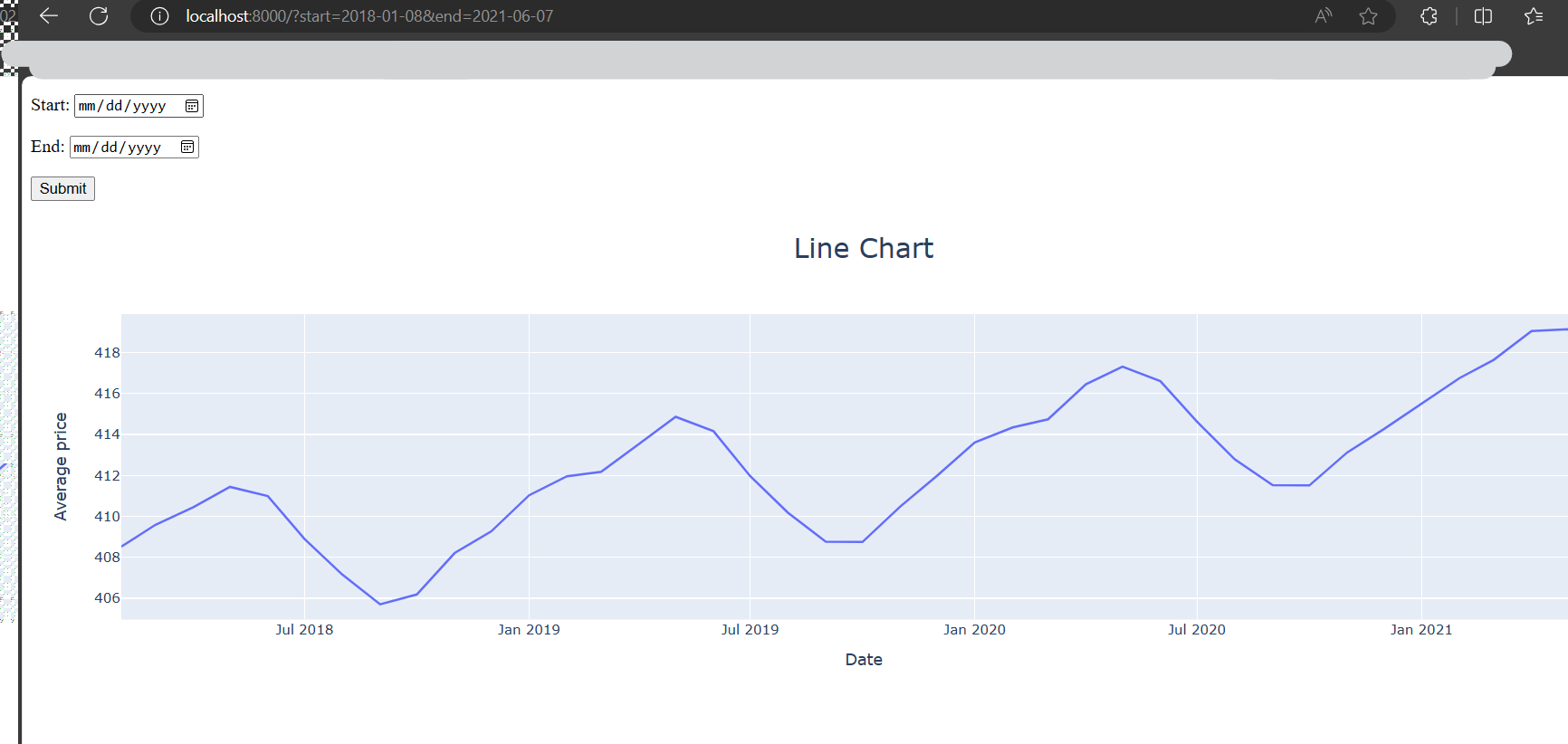
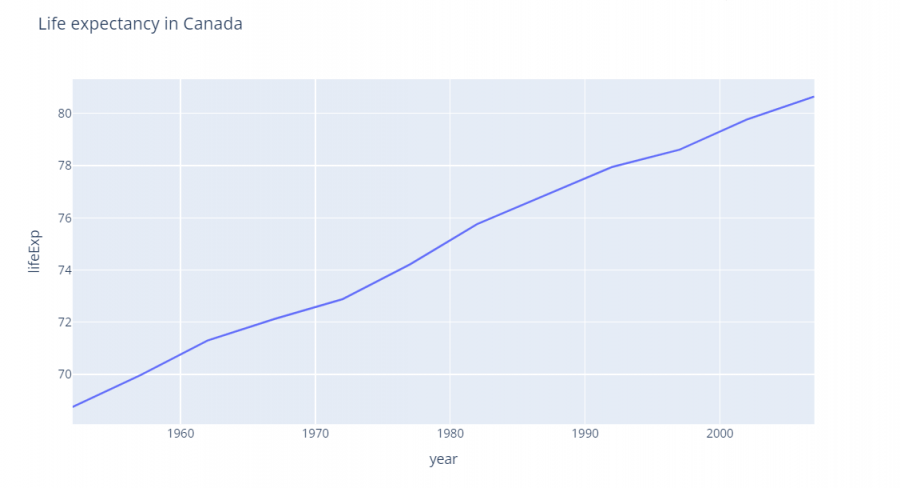
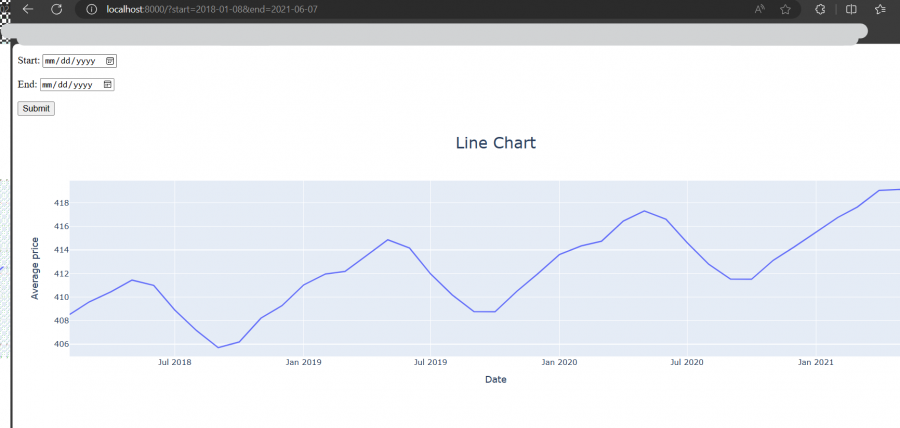
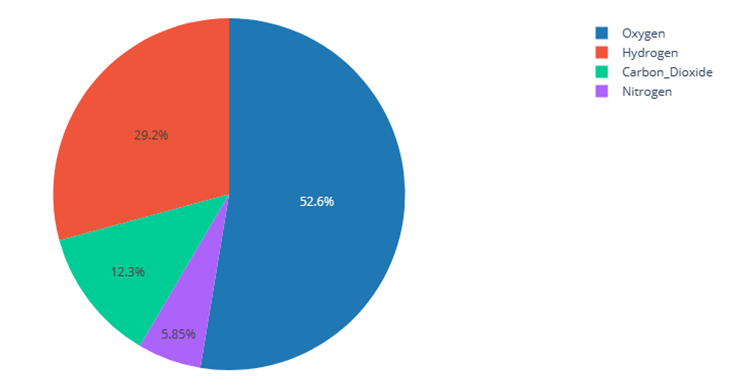
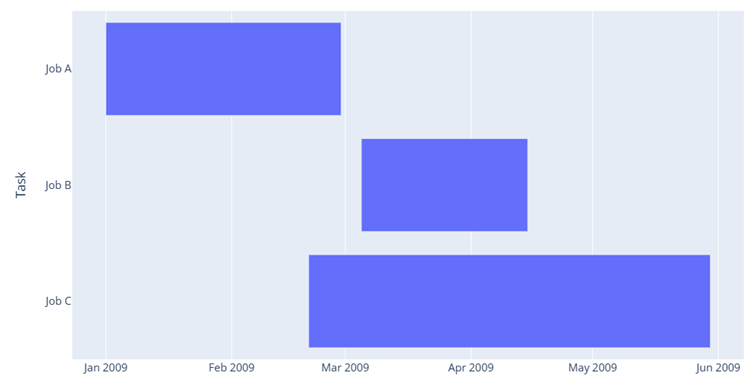
في حال كنت تسطتيع التعامل مع جافا سكربت يوجد الكثير من المكاتب والحلول المساعدة مثل canvasjs او Chart.js حيث تقدم هذه المواقع خدمات ومساعدات لانواع مخططات كثيرة ففي canvasjs : تستطيع التجول واختيار المخطط المناسب لك كالتالي : وبعد اختيارك للمخطط المطلوب يمكن تنزيله بالصيغة التي تناسبك ان كان javaScript او react او غيرها كالتالي ولديك خيار اخر اذا كنت تعرف مكتبة plotly في بايثون تقدم الكثير والكثير من انواع المخططات وتستخدم بشكل شائع في تحليل البيانات حيث ساعطيك مثال لطريقة مكاملتها مع جانغو لانها تعمل معك بشكل منفصل ايضا عن طريق النوت بوك حتى : ففي التوت بوك يمكن اظهار مخطط ال Line Chart: import plotly.express as px df = px.data.gapminder().query("country=='Canada'") fig = px.line(df, x="year", y="lifeExp", title='Life expectancy in Canada') fig.show() عن طريق التابع show يتم عرضها بشكل مباشر في نوت بوك اما لرسم مخطط Line Chart مع جانغو: نحتاج اولا لانشاء مشروع جانغو ومن ثم داخل ملف الviews : نعرف نفس التابع line الموجود في المكتبة ونمرر له القيم المراد عرضها ولكن على محور الX تكون الزمن وعلى محور y تكون متوسط الاسعار لكل زمن : كالشكل التالي: from django.shortcuts import render import plotly.express as px from core.forms import DateForm from core.models import CO2 # Create your views here. def chart(request): start = request.GET.get('start') end = request.GET.get('end') co2 = CO2.objects.all() if start: co2 = co2.filter(date__gte=start) if end: co2 = co2.filter(date__lte=end) fig = px.line( x=[c.date for c in co2], y=[c.average for c in co2], title="Line Chart", labels={'x': 'Date', 'y': 'Average price'} ) fig.update_layout( title={ 'font_size': 24, 'xanchor': 'center', 'x': 0.5 }) chart = fig.to_html() context = {'chart': chart, 'form': DateForm()} return render(request, 'core/chart.html', context) نلاحط اننا استخدمن التابع to_html وليس show وهنا سوف يتعامل معه على انه HTML ويمكن ارساله بشكل عادي الى صفحة الhtml وهمنا ارسلناهها الى الصفحة chart.html استقبال المخطط في صفحة chart.html كالتالي {{ chart|safe }} داخل الصفحة: {% extends 'core/base.html' %} {% block content %} <form method="GET" action="{% url 'chart' %}"> {{ form.as_p }} <button>Submit</button> </form> {{ chart|safe }} {% endblock content %} ونحرص على وضع كلمة safe معها كي يعتبرها المتصفح امنة للظهور ويمكن التعديل عن طريق ال CSS على شكل ومكان العرض. ويتم استدعاء التابع chart بالطريقة التالية داخل ملف ال URL: from django.urls import path from . import views urlpatterns = [ path('', views.chart, name='chart') ] لتظهر النتيجة كالشكل التالي : ويوجد انواع عديدة من المخططات وتوفرها مكتبة plotly : 1. المخططات المبعثرة (Scatter Plots): هذه المخططات رائعة لإظهار العلاقة بين متغيرين. 2. المخططات الدائرية (Pie Charts): تستخدم لإظهار نسبة أجزاء من أصل الكل. 3. مخططات الصندوق (Box Plots): تقديم ملخص مرئي لمجموعة واحدة أو أكثر من البيانات وفي عملية تحليل البيانات يمكن من خلالها اكتشاف القيم المتطرفة. 4. مخططات الكمان (Violin Plots): تشبه المخططات الصندوقية، ولكنها تظهر أيضاً الكثافة الاحتمالية. 5. مخطط الخرائط الحرارية (Heatmaps): تظهر حجم الظاهرة كاللون في بعدين (x و y). مثال: الميداليات الأولمبية التي فازت بها الدول (كوريا الجنوبية، الصين، كندا) 6. المخططات الفقاعية (Bubble Charts): مجموعة متنوعة من المخططات المبعثرة (Scatter Plots) بحجم الفقاعة الذي يمثل بُعداً إضافياً. 7. مخطط خطي (Line Chart): تمثيل رسومي يعرض المعلومات كسلسلة من نقاط البيانات، تسمى "العلامات (markers)"، متصلة بواسطة مقاطع خط مستقيم. يُستخدم عادةً لإظهار التغيرات بمرور الوقت. 8. المخططات المساحية (Area Charts): تشبه المخططات الخطية (Line Charts)، ولكن المنطقة الموجودة أسفل الخط تكون مليئة بالألوان. 9. مخطط شريطي (Bar Chart): يستخدم أشرطة ذات ارتفاعات أو أطوال مختلفة لمقارنة الكميات عبر الفئات المختلفة. ويمكن توجيهها رأسياً أو أفقياً. وهذا مثال يوضح كمية المدخنين وغير المدخنين من كلا الجنسين ذكور وإناث. 10. الخرائط الهيكلية (Treemaps): عرض البيانات الهرمية كمجموعة من المستطيلات المتداخلة. 11. مخططات جانت (Gantt Charts): غالباً ما تستخدم لإدارة المشاريع لإظهار المهام بمرور الوقت. ويوجد انواع اخرى لكن قمت بذكر اهمها

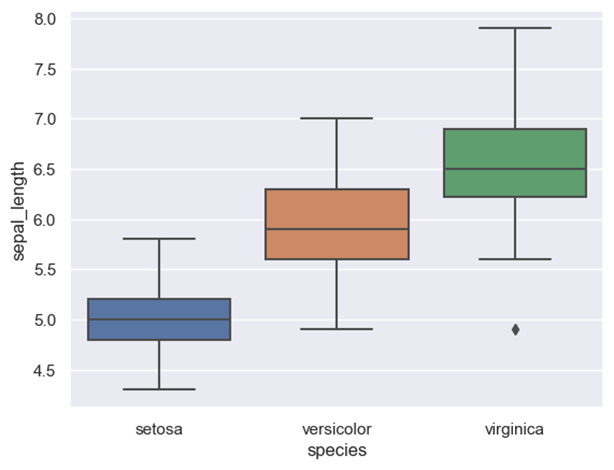
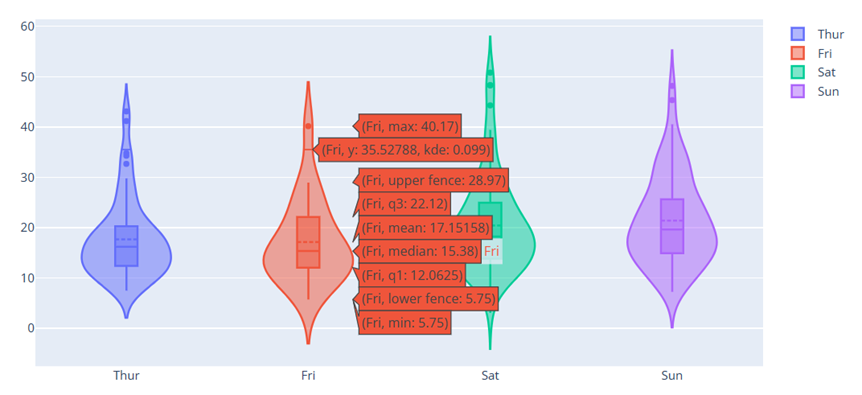

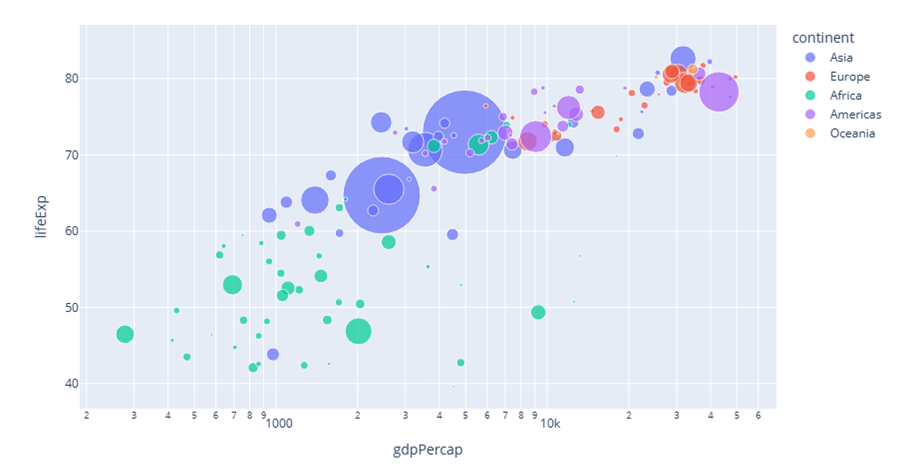
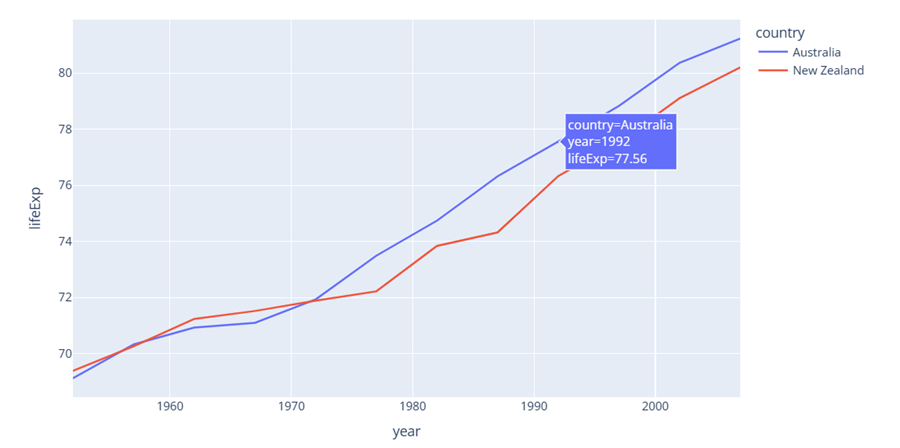


- 3 اجابة
-
- 1
-
-
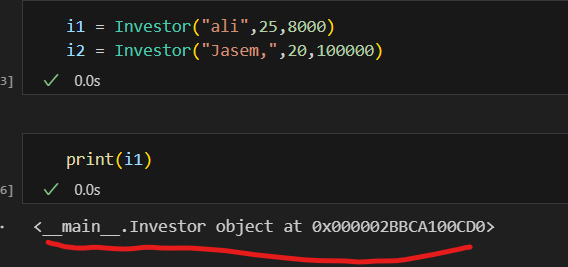
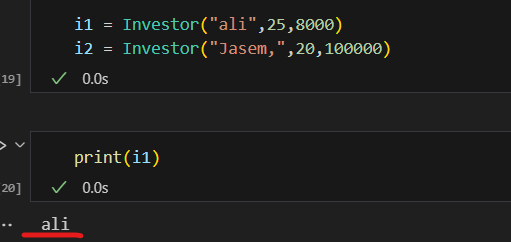
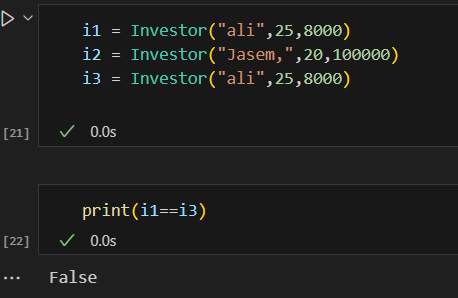
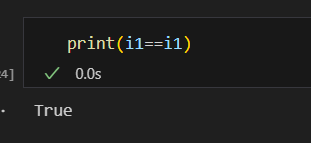
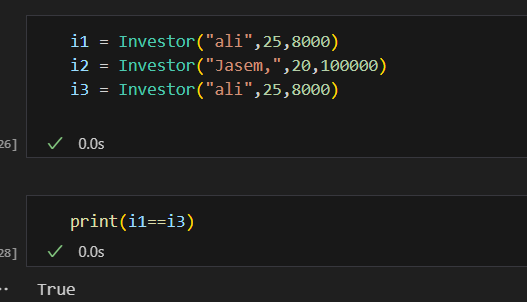
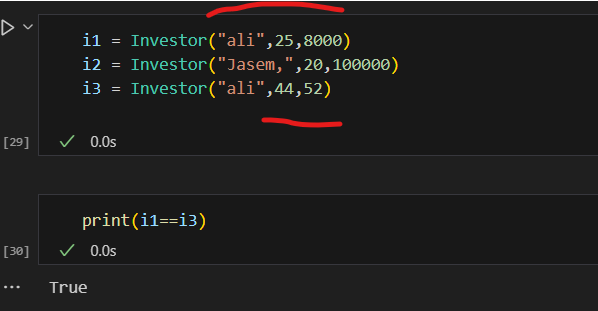
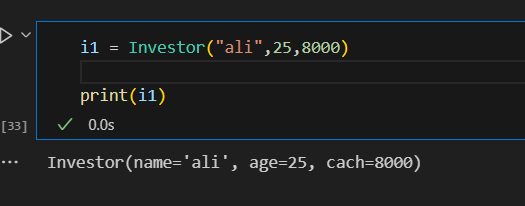
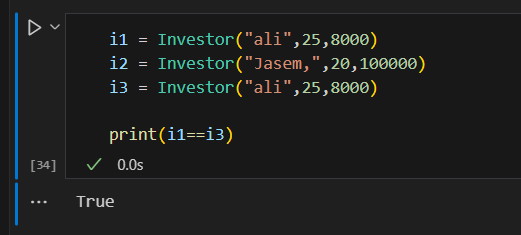
فئات البيانات في بايثون (Data Classes) تم تقديمها اول مرة من الاصدار 3.7 تقدم طريقة أنظف وأكثر كفاءة لكتابة الClasses التي نحتاج: يوجد العديد من التوابع التي نكتبها بشكل يدوي والتي تقوم ببعض الوظائف الخاصة بالClass معين سوف نتعرف على بعضها ومثال لهذه التوابع التي تسمى ( "dunder" methods ) واهمها عند تعريف Class يجب تعريف الباني (constructor) الخاص به مثال ليكن لدينا الClass الخاص بتعريف عن مستثمر حيث يتعرف عليه ب اسمه و عمره وثروته class Investor: def __init__(self,name,age,cach): self.name = name self.age = age self.age = age نلاحظ ضروة استخدام الدالة __init__ لتمكني من تعريف المستثمر i1 = Investor("ali",25,8000) i2 = Investor("Jasem,",20,100000) في حال غياب الباني (constructor) لا يمكن تمرير القيم للكائن واذا اردنا طباعة i1 يظهر نتيجة بشكل غير مفهوم كالاتي : ولحل هذه المشكلة يمكن الاستعانة بالدالة repr نضيفه على Class ونحدد من خلاله القيمة التي نريد ان نطبعا حين طباعة الكائن من الClass : class Investor: def __init__(self,name,age,cach): self.name = name self.age = age self.age = age def __repr__(self) -> str: return self.name نعيد طباعة i1 لتظهر قيمة الاسم الخاصة بهذا الكائن كالاتي : واذا اضفنا كائن اخر يشابه في بيانته الكائن الاول كالاتي i1 = Investor("ali",25,8000) i2 = Investor("Jasem,",20,100000) i3 = Investor("ali",25,8000) واختبرنا اذا كان متشابهان نلاحظ انه اعطى قيمة خطأ اي انهما غير متساويين علما لو اختبرنا عن تساوي نفس الكائن يعطي انهما مساويين اي يرجع True ويوجد دالة تساعد هذا Class في تحديد السمة التي نريد المقارنة عليها في حال اردنا تطبيق اختبار المساوات وهي الدالة eq وتعرف بالشكل التالي في حال اردنا ان يقارن على الاسم فقط : class Investor: def __init__(self,name,age,cach): self.name = name self.age = age self.age = age def __repr__(self) -> str: return self.name def __eq__(self, Other) -> bool: return self.name == Other.name في حال اعدنا الاختبار تساوي الاولمع الثالث سوف يقول انهما متشابهان كالاتي علما انه ولو غيرنا بالميزات الاخرى كالعمر والرصيد سوف يظل يراهم متشابهان وذلك بسبب تعريفك لدالة التساوي لا يؤثرفيها سوا الاسم مثال: نلاحظ بقائها تعطي انهما متساويين حيث يمكن اضافة ميزة ميزة والتاكد من تساويهما ويعتبر هذا مجهد في حال كان هناك الكثير لذلك سوف نتعرف على فائدة الData Classes التي توفر علينا مجهود هذه العمليات كالتالي : حيث نستدعي dataclass وبعدها نعرف بمفهوم decorator وهو مفهوم في برمجة كائنية التوجه تقوم بنوع من التغليف للوظائف وتعرف في بايثون بالشكل @dataclass يوضع فوق تابع اوكلاس from dataclasses import dataclass @dataclass class Investor: name : str age : int cach : float نلاحظ عدم تعريف تابع باني ولا تابع الاستعراض repr لكن امكننا تعريف كائن منه وعند طباعة الكائن يظهر بمظهر افضل ووفر علينا عناء كتابة التوابع المساعدة السابقة وعند اختبار التساوي اظهر قدرته على معرفة التساوي وعند تغير قيمة يظهر عدم التساوي وهذا شيئ منطقي لانه يقارن على كل البيانات الخاصة بالكائن لذلك نلخص ان dataclass ساعدنا عللى توفير الوقت والجهد في الخوض في معالجة هذه الامور وجعل الكود افضل واكثر احترافية وقابلية للفهم. وهي مفيدة جدا عند التعامل مع الباينات من قواعد البيانات

- 3 اجابة
-
- 1
-
-
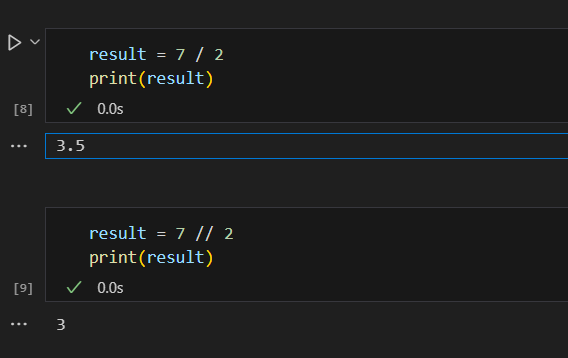
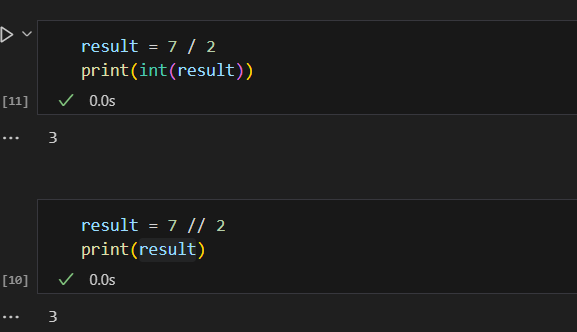
الفرق الرئيسي بين "/" و "//" هو نوع القيمة المُرجَعَة. في حالة العملية "/"، تحصل على النتيجة عائمة (float)، في حين أن العملية "//" ترجع نتيجة صحيحة (integer) دون الجزء العشري. مثال: ويمكن الاسنغناء عن القسمة عن طريق "//" وقصر نتيجة الطريقة الاولى عبر دالة int كالشكل التالي نلاحظ ادى الى نفس النتيجة حيث يمكن اختيار الطريقة التي تناسبك انت حيث القصر عن طريق int امر شائع بكل لغات البرمجة اما "//" فهو امر خاص في بايثون ويمكنك الاطلاع على باقي العمليات من خلال الرابط التالي https://wiki.hsoub.com/Python/numeric_operations
- 2 اجابة
-
- 1
-
-
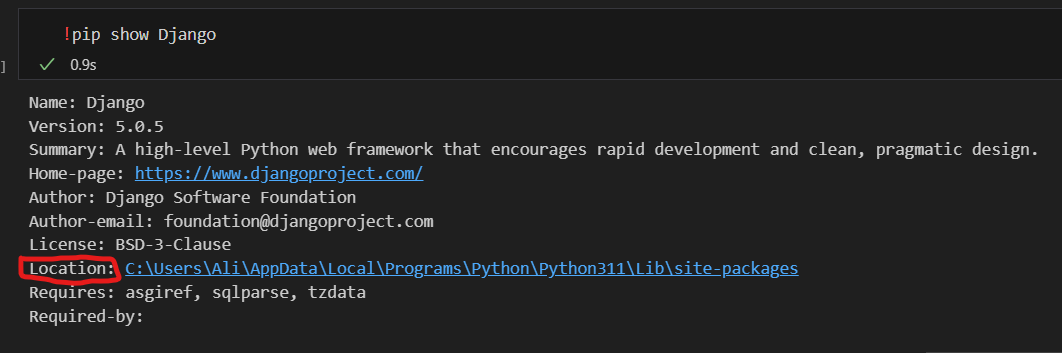
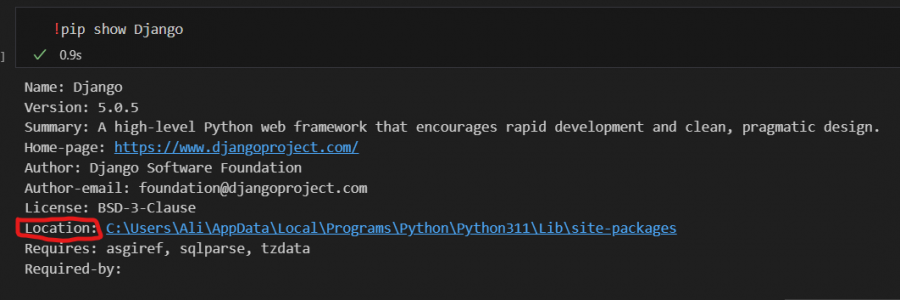
وعليكم السلام لازم تعرف ان مدير الحزم pip بثبت الحزم بمواقع مختلفة حسب النظام والبيئة. لكن بشكل افتراضي: - في نظام Linux: تتثبت في /usr/local/lib/pythonX.X/dist-packages - في نظام التشغيل Windows: مسار التثبيت العام الافتراضي هو: C:\Users\{username}\AppData\Local\Programs\Python\PythonXX\Lib\site-packages - على نظام التشغيل macOS: يقوم pip بتثبيت الحزم في المسار: /Library/Python/X.X/site-packages - في حال كنت عم تستخدم بيئة افتراضية (Virtual Environment): ال`pip` رح يثبتلك الحزم داخل مسار تلك البيئة، عادةً ضمن (مثلاً اسم البيئة env): env/lib/pythonX.X/site-packages وأريد أن أختتم بطريقة سهلة يمكنك اتباعها لمعرفة مكان تثبيت حزمة معينة: pip show <package_name> والذي سيعرض معلومات الحزمة بما في ذلك موقعها وستجد الحزم جميعها في نفس المكان. مثال ايجاد مكان تخزين Django انظر الى الموقع يظهر في الاسفل ملاحظة أخيرة: يمكنك تغيير موقع التثبيت الافتراضي عن طريق إعداد ملفات pip.ini (على نظام Windows) أو pip.conf (على نظام Linux/Mac)، لكني أنصحك عند تثبيت بايثون بترك موقع التثبيت الافتراضي لتتجنب أي مشاكل محتملة.
- 3 اجابة
-
- 1
-
-
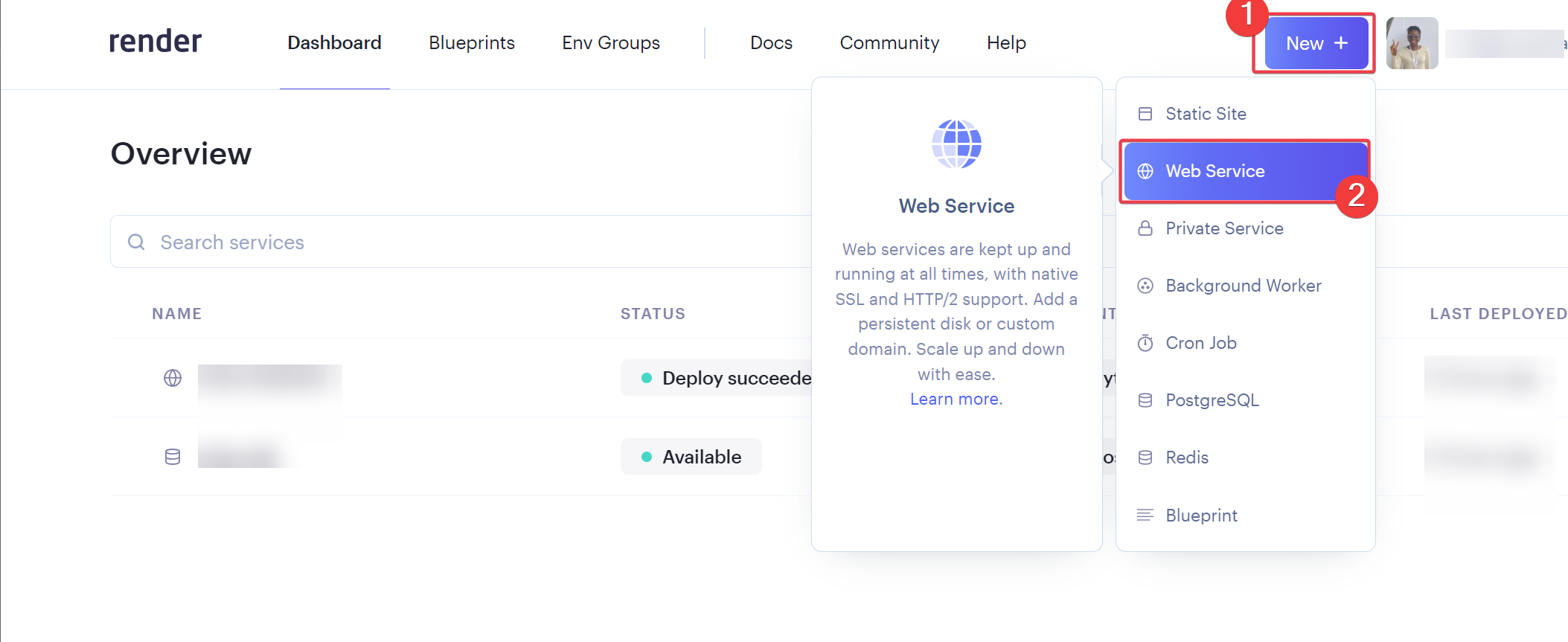
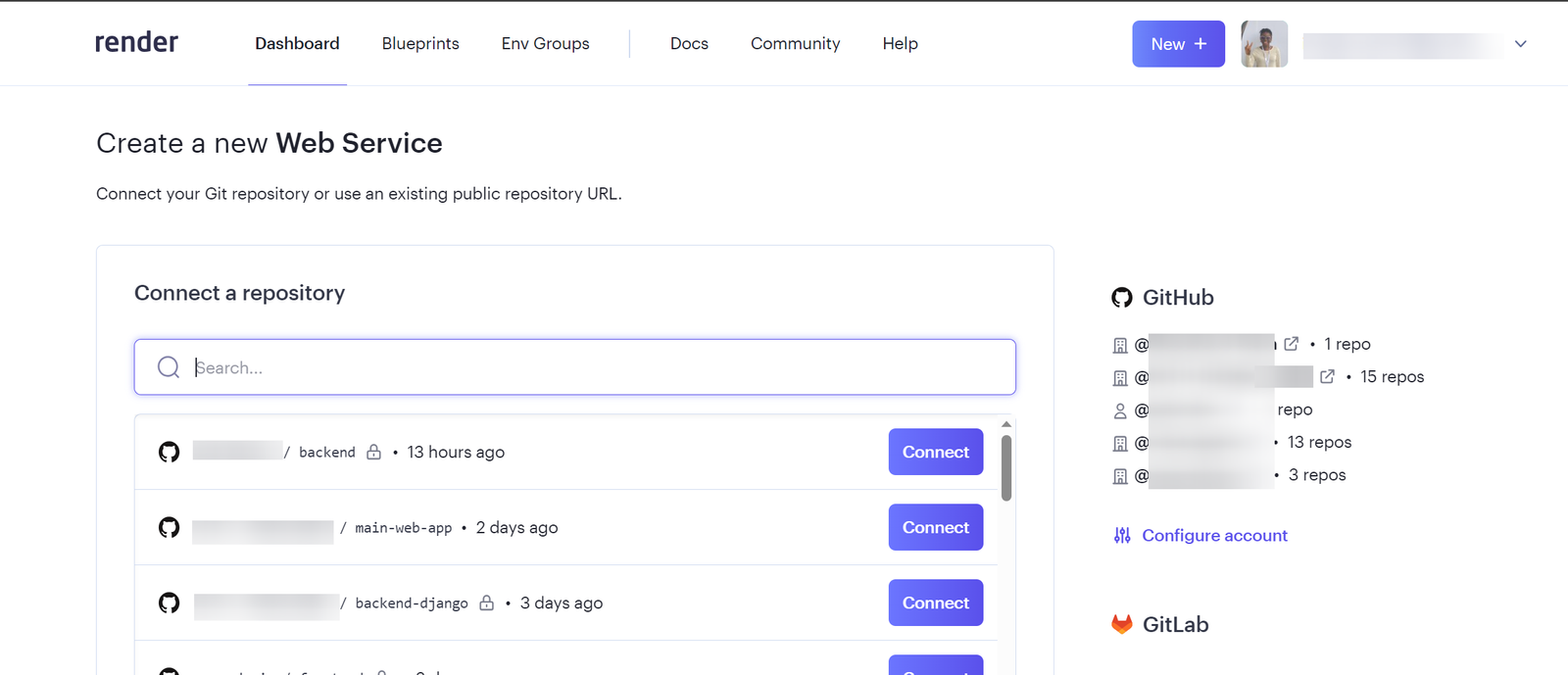
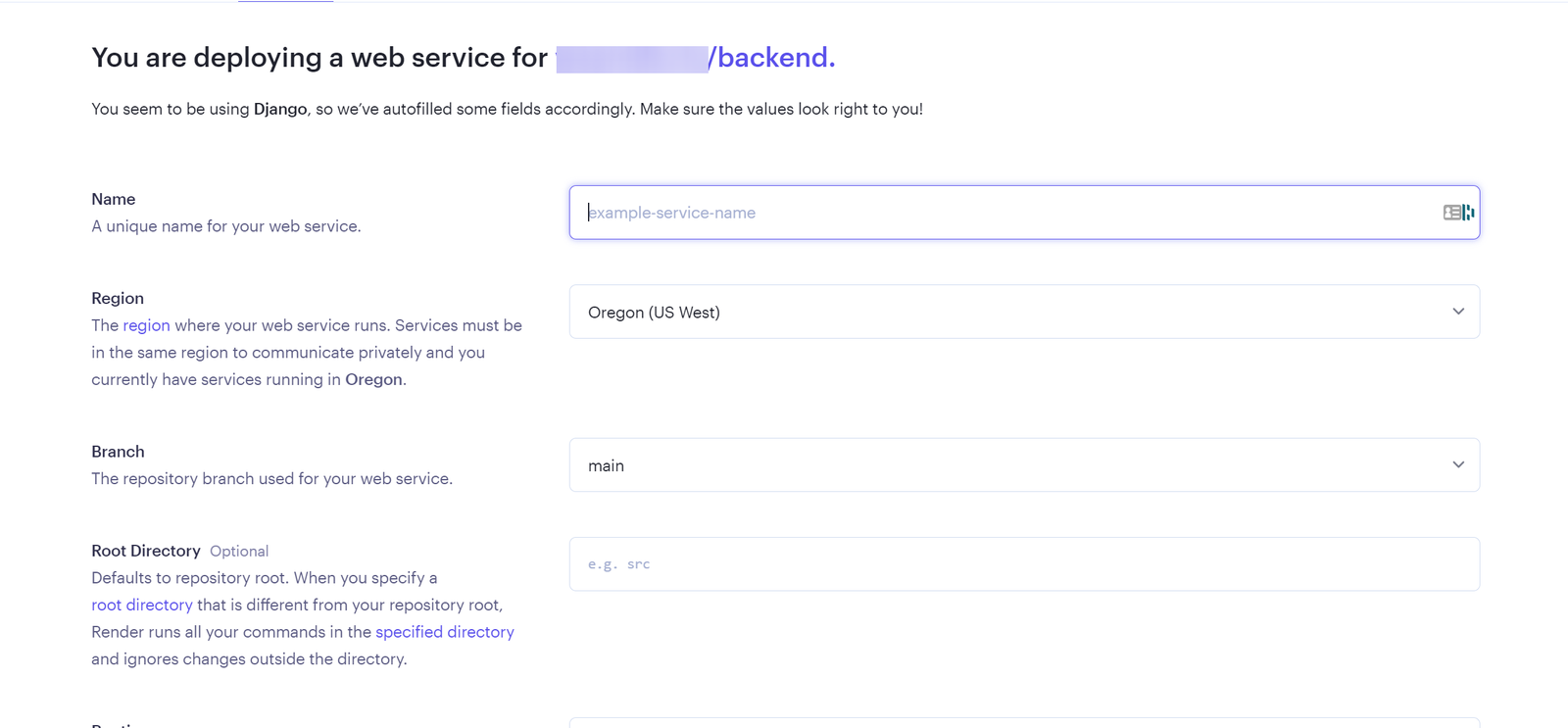
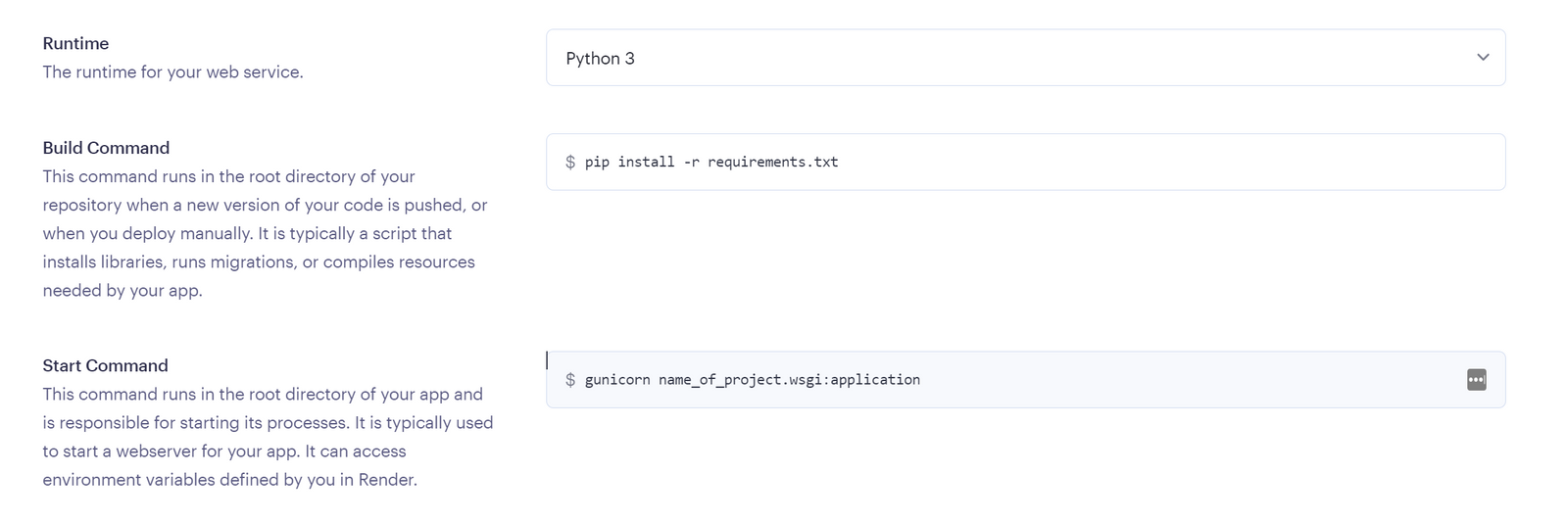
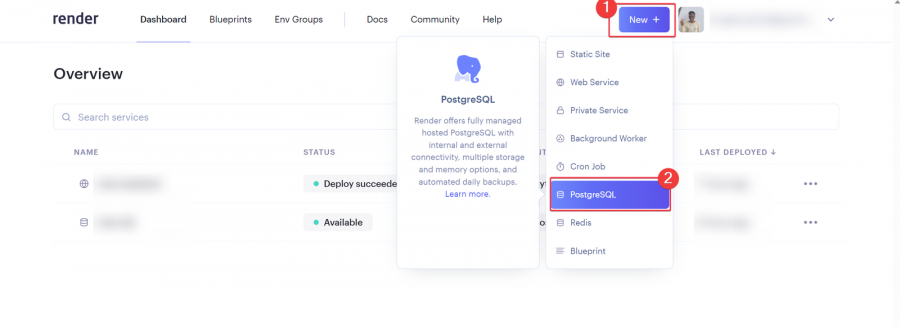
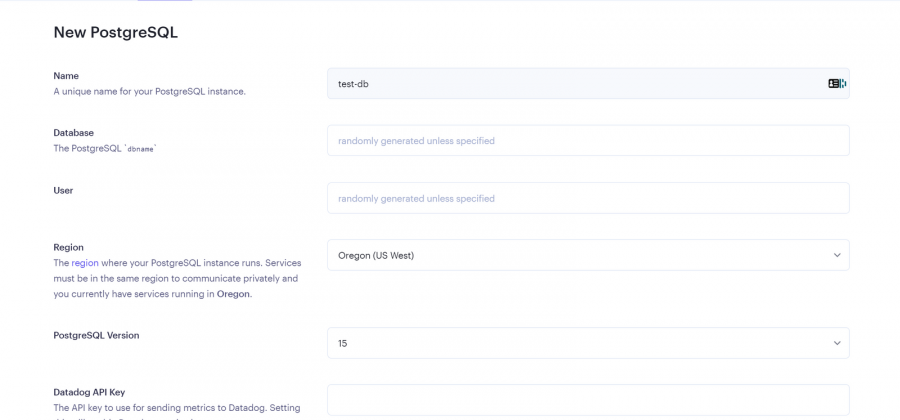
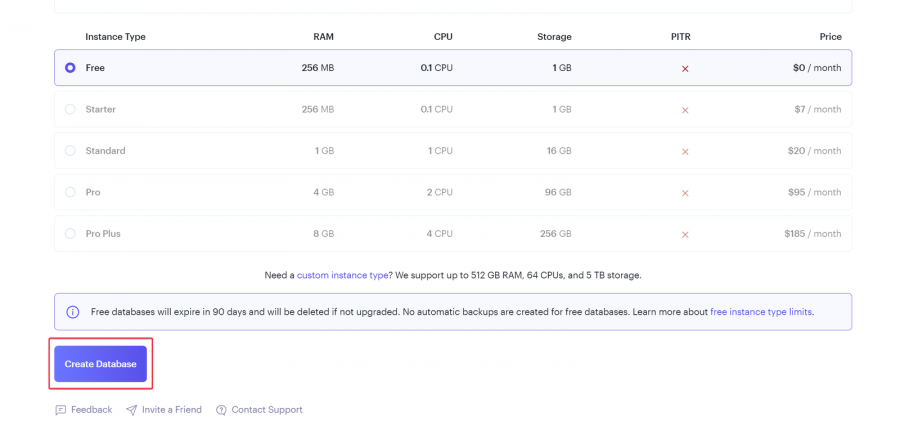
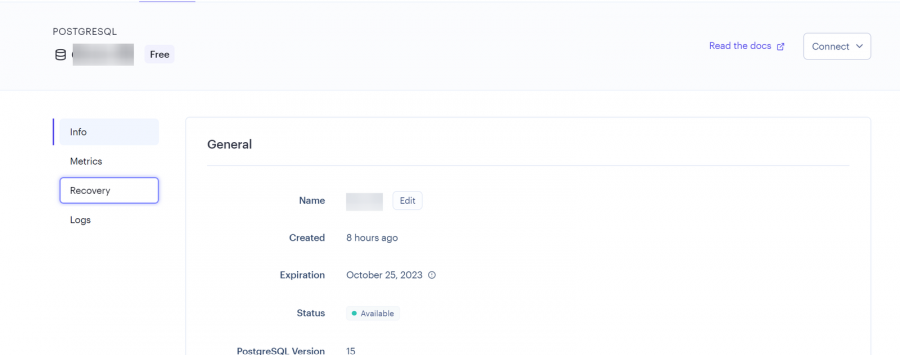
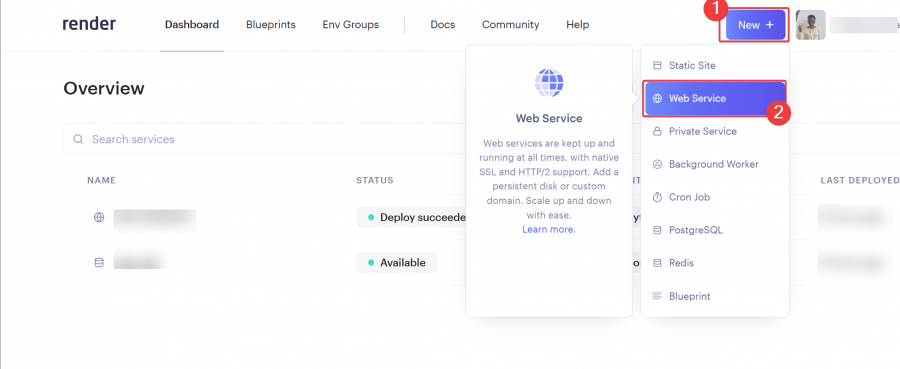
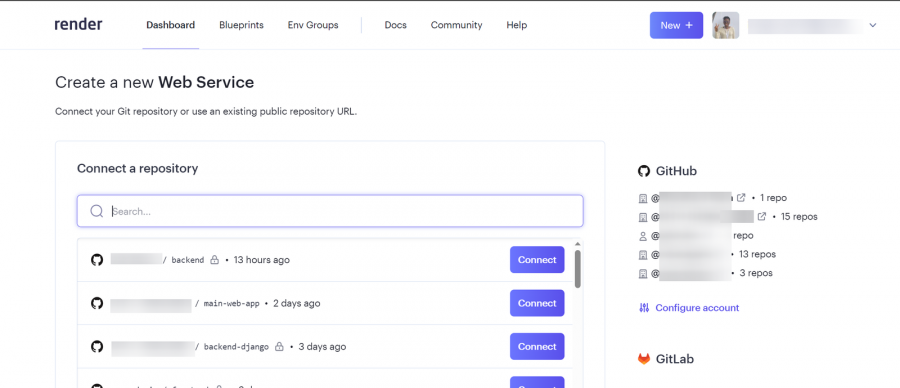
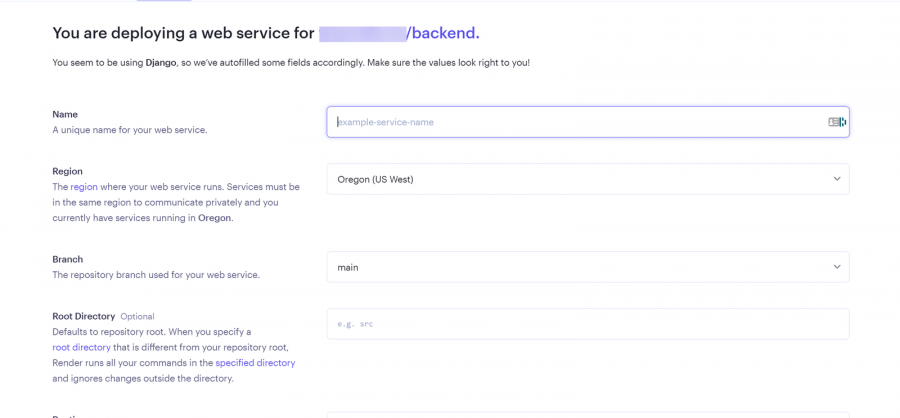
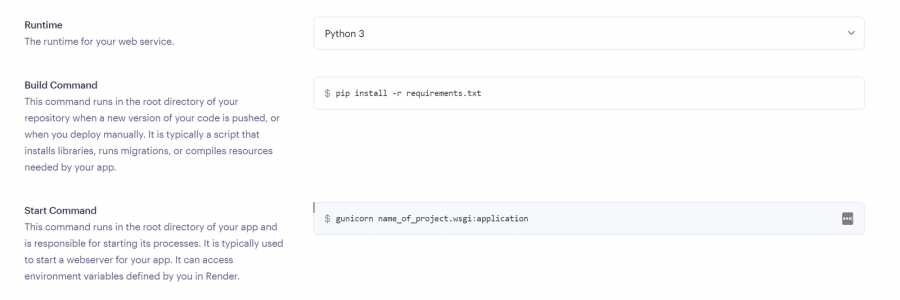
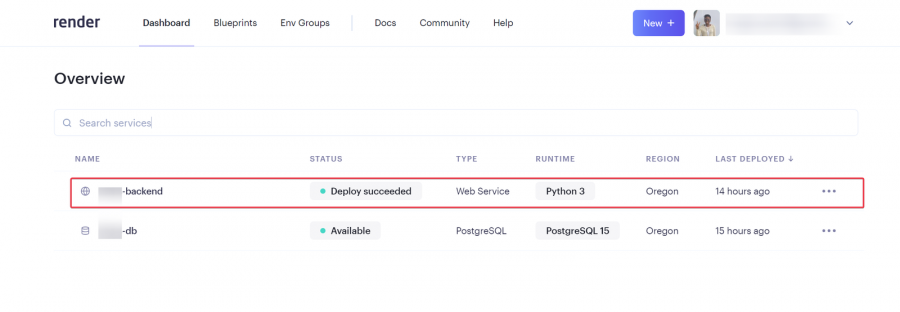
يعتمد تحديد افضل استضافة على متطلبات المشروع حيث اغلب الاستضافات تكون مجانية بقيود مثل الزمن او المساحة لكن افضل العروض المجانية هو render: لنبدأ ب render: اولا يعطيك 1G من التخزين المجاني وذلك لمدة 90 يوم فقط وبعدها اما تسجل في حساب اخر او تدفع اشتراك ولتثبيت اتبع الخطوات التالية اعداد قاعدة البيانات من نوع PostgreSQL: أولا ، توجه إلى لوحة معلومات العرض الخاصة بك وقم بإنشاء قاعدة بيانات PostgreSQL. انقر فوق الزر + جديد ، وقم بالمرور فوق PostgreSQL ، وانقر فوقه. بعد ذلك، حدد إعدادات قاعدة البيانات الخاصة بك عن طريق إعطاء مثيل قاعدة البيانات اسما. يمكنك اختيار إما السماح ل Render بتعريف اسم لقاعدة بيانات ومستخدم أو تعريفه بنفسك. حدد الخطة المجانية وانقر على إنشاء قاعدة بيانات. ملاحظة: تنتهي صلاحية كل قاعدة بيانات مجانية تم إنشاؤها على Render بعد 90 يوما من الإنشاء. لذا فقط لاحظ هذا وقم بالترقية إذا كان مشروعا مهما. يمكنك رؤية الأسعار هنا بمجرد أن تظهر الحالة في قاعدة البيانات الخاصة بك متفعلة ، فهذا يعني أن قاعدة البيانات قد تم إنشاؤها بنجاح وجاهزة للاستخدام مثل الصورة التالية. بعد ذلك توجه إلى إعدادات قاعدة البيانات الخاصة بك على عرض ونسخ عنوان URL لقاعدة البيانات الخارجية. ثم في ملف الاعدادات المشروع جانغو قم باضافة وضع الurl داخل ملف .env لأسباب أمنية. import dj-database-url import os DATABASES = { "default": dj_database_url.parse(os.environ.get("DATABASE_URL")) } بعد ذلك، قم بترحيل الجداول إلى قاعدة البيانات الجديدة لضمان نجاح الاتصال بالشكل التالي # To make migrations if this is your first time connecting to a database python manage.py makemigrations #To migrate tables set on your migrations folders python manage.py migrate إذا كان الاتصال ناجحا وقمت بترحيل جميع الجداول الخاصة بك ، فيجب أن يبدو الخرج كما يلي: أنت الآن على بعد خطوة واحدة من نشر مشروع Django الخاص بك! 🎉 كيفية إنشاء خدمة الاستضافة: هذه هي الخطوة الأخيرة لبدء مشروعك. توجه إلى لوحة معلومات العرض الخاصة بك. انقر فوق جديد + وحدد خدمة ويب قم بتوصيل GitHub الخاص بك إذا لم تكن قد قمت بذلك بالفعل ولذلك يسهل عليك عملية النشر. يجب أن يبدو هكذا : بعد ذلك ، حدد إعدادات الريبو الخاص بك. امنح تطبيقك اسما وتأكد من اتصالك بالفرع الصحيح. تاكد من تنزيل gunicorn وخادم ويب Python يعمل كبوابة بين تطبيق الويب والإنترنت. إنه مصمم للنشر لأنه يدير طلبات الويب الواردة بشكل فعال. وجلب جميع المكاتب ومتطلبات المشروع عن طريق الامر الثاني : pip install gunicorn pip freeze > requirements.txt # To update your requirements.txt file تأكد من إضافة خدمة الويب Render إلى ALLOWED_HOSTS في settings.py الخاص بك. وبعد ذلك حدد ملف المتطلبات والخادم واللغة ارجع إلى لوحة معلومات العرض وانقر على خدمة الويب المنشورة لعرض الرابط المباشر الخاص بك. لقد قمت بنشر تطبيق Django الأول الخاص بك على منصة مجانية. استمتع بخادم الويب الخاص بك لمدة 90 يوما القادمة.


- 4 اجابة
-
- 1
-
-
في حال كان لدينا مجلدان مثل مجلد مثل 'venv', 'get' نقوم باستخدام الدالة remove التي تاخذ اسم المجلد بحيث نقوم بالمرور على اسماء المجلدات ونقوم باستثنائها في حال كانت تطابق اسم الموجود في قائمة اسماء المجلدات التي نريد حذفها وهي exclude_folders في الكود التالي : import os path = 'C:\\Users\\Ali\\Desktop\\root' exclude_folders = ['venv', 'get'] for root, directories, files in os.walk(path): for folder in exclude_folders: if folder in directories: directories.remove(folder) for file in files: file_path = os.path.join(root, file) # Perform operations on file_path print(file_path) for directory in directories: directory_path = os.path.join(root, directory) # Perform operations on directory_path print(directory_path)
- 4 اجابة
-
- 1
-
-
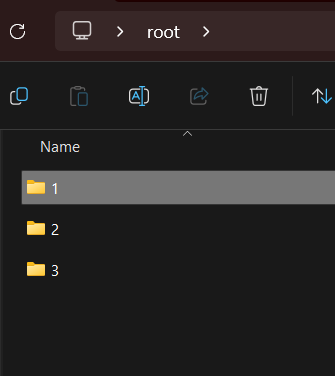
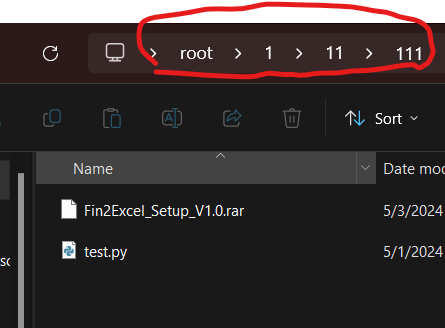
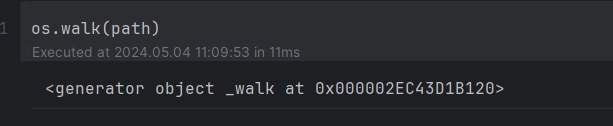
يوجد في مكتبة os يوجد مكتبة تدعى walk تأخذ مسار المجلد المراد بناء شجرة الملفات له وترجع 3 متغيرات يعبر الأول عن مسار المجلد الرئيسي والثاني عن قائمة المجدات الفرعية في هذا المجلد، وقائمة أسماء الملفات في هذا المجلد. حيث تعمل هذه الدالة بشكل تكراري حتى تمشي على جميع الملفات والمجلدات. تشبه في بنائ الشجرة الشكل التالي حيث تسبر مستوى مستوى تنتقل للمستوى الاعمق من خلال المجلدات وتكون الملفات والمجلدات الفارغة عبارة عن اوراق الشجرة مثال : حيث نريد بناء شجرة الملفات لمجلد يدعى root موجود في المسار التالي "C:\\Users\\Ali\\Desktop\\root" حيث يوجد داخله ثلاث مجلدات وداخله في المسار التالي يوجد هذه الملفات حيث نطبق الكود التالي لبناء الشجرة كما تريد حيث walk ترجع 3 متغيرات files وdirectories ونقوم بالمرور على كل الملفات والدالة walk من النوع generator اي تعيد نتيجة عند كل استدعاء لذلك يجب المرور عليها بحلقة for وهي تثبر مستوى ونتقل للمستوى الثاني حيث يعبر المستوى عن محتويات المجلد حيث تقوم بفتح المجلدات بالترتيب import os path = "C:\\Users\\Ali\\Desktop\\root" for root, directories, files in os.walk(path): for file in files: file_path = os.path.join(root, file) # Perform operations on the file_path print(file_path) for directory in directories: directory_path = os.path.join(root, directory) # Perform operations on the directory_path print(directory_path) لتظهر النتيجة بالشكل التالي
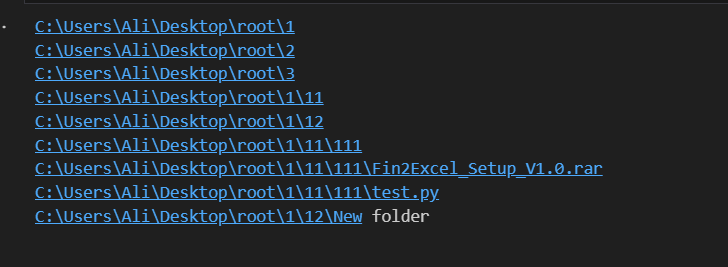
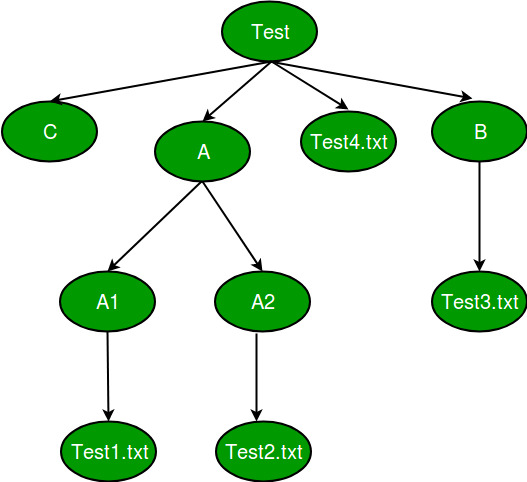
- 4 اجابة
-
- 1
-
-
في حال عملك مع لغة بايثون تأكد من تثبيت بايثون من الموقع التالي link ومن ثم تثبيت الامتداد الخاص بها في البرنامج كما يلي: تاكد عند فتح البرنامج الخاص فيك قم بفتح المجلد باكمله ليس فقط ملف واحد بشكل مباشر وتاكد من ان نهاية الملف py.
- 2 اجابة
-
- 1
-