لوحة المتصدرين




المحتوى الأكثر حصولًا على سمعة جيدة
المحتوى الأعلى تقييمًا في 11/25/23 in أجوبة
-
السلام عليكم إخوتي أحتاج مساعدة في كتابة كود Python بإستخدام مكتبة pandas لتحويل ونسخ البيانات من هذا الفورم أو هذا الشكل إلى هذا الفورم أو بهذه الكيفية بإستخدام الكود الرجاء التوضيح ولو بشيء من التفصيل وشاكر تعاونكم
 1 نقطة
1 نقطة -
السلام عليكم اي هي وظفيه dir() فيه python ?1 نقطة
-
السلام عليك احبتي اريد كود في بيثون لاستخراج النص المكتوب بخط اليد من الصوره ويعرض النتايج في عنصر نص او طباعته1 نقطة
-
وعليكم السلام، بالإضافة إلى ما تحدث عنه الأستاذ مصطفى، سوف تعلم الفرق الحقيقي بين production و developement عند الدخول في سوق العمل فمعظم الشركة تعتمدان على بيئتين أو ثلاث في حال وجود مرحلة الاختبار في حال developement هذه البيئة تكون مخصص للمطورين الموجودين في الشركة وتكون على سيرفر مستقل ومن الممكن أن تكون مشتركة مع بيئة الاختبار أو منفصلة عنها ولكن في الاغلب الاوقات تكون بيئة التطوير والاختبار على سيرفر واحد لتوفير التكاليف في حال production هذه البيئة يتم فيها إطلاق المنتج النهائي للخدمة وتكون على سيرفر مستقل وفي حال قمنا بتسمية سيرفر فمن الممكن أن تكون على اكثر من سيرفر وهذه السيرفرات مربوطة في نظام واحد في حال تعطل احدها يستطيع الاخر الرد على المستخدم ولكن يطلق عليها كمجموعة سيرفر وهنا تأتي فائدة node envirement حيث يوجد لكل بيئة متغيرات خاصة بها ونجد ذلك بشكل صريح في حال database، الاكيد أن database الخاصة ببيئة التطوير developement منفصلة عن بيئة الانتاج production من خلال اسم المستخدم كلمة السر وما إلى ذلك ولكن أنت لا تقوم بتعيين هذه القيم بشكل يدوي في كل مرة يتم وضع الكود فيها على بيئة التطوير والانتاج تقوم بوضع هذه القيم في ملفين مثلا الاول الخاص بالتطوير developement والاخر خاص بالانتاج production وتستطيع أن تضع في نفس الملف قيمة توضح على إي بيئة نعمل ثم عند وضع الكود في بيئة التطوير يقوم الكود بقراءة هذه القيم من الملف الخاص به باستخدام process.env وكذلك بالنسبة لبيئة الانتاج process.env وهذا يجعل مرحلة التطوير والانتاج اكثر عملية واقل تضيع للوقت1 نقطة
-
وعليكم السلام ورحمة الله كما تحدث الاستاذ عدنان بالإضافة ليس اسماء المتحولات والمتغيرات بل يشمل إيضا اسماء التوابع وكذلك الكائنات المأخوذه من الصفوف وكذلك اسماء المكتبات المستخدمة ضمن الكود الخاص بك import numpy def get(x): return x a = 5 b = "Hi" c = [1, 2, 3, 4] names = dir() #طباعة الخرج print(names) #الخرج ['__annotations__', '__builtins__', '__cached__', '__doc__', '__file__', '__loader__', '__name__', '__package__', '__spec__', 'a', 'b', 'c', 'get', 'numpy'] ما يهمنا الجزء الاخير حيث نلاحظ وجود المتحولات a,b,c وكذلك اسم التابع get وكذلك اسم المكتبة numpy مع ذلك نحن كمبرمجين لا نقوم باستخدام جميع ما هو متوافر باللغة البرمجية بل نستخدم حسب الحاجة وهنا ك dir من الممكن أن لا يكون لها اي استخدام على مستوى الكود لأنها لا تقدم إضافة كبيرة1 نقطة
-
وعليكم السلام ورحمة الله، يجب عليك توفير عينه بسيطة للملف الأول، إي قم برفع الملف إلى هنا لكي نستطيع مساعدتك في توفير كود لحل المشكلة1 نقطة
-
تستخدم حصرا للحصول على قائمة تحتوي على الأسماء (المتغيرات والوحدات) المتاحة في النطاق الحالي. مثال: # مثال بسيط x = 10 y = "Hello, World!" # استخدام dir() للحصول على قائمة الأسماء names = dir() # طباعة الأسماء print(names) سيعرض هذا الكود قائمة بجميع الأسماء المتاحة في النطاق الحالي، والتي هي x و y. يمكنك أيضًا استخدام dir(object) للحصول على قائمة بالأسماء المرتبطة بكائن معين. على سبيل المثال: # مثال على استخدام dir() مع كائن my_list = [1, 2, 3] # استخدام dir() للحصول على قائمة الأسماء المرتبطة بالقائمة list_names = dir(my_list) # طباعة الأسماء print(list_names) هاته هي فكرتها باختصار.1 نقطة
-
السلام عليكم هو فيه فرق بين الlist و arrry فيه الباثيون ؟1 نقطة
-
لا يوجد اختلاف بالنسبة للاساسيات في بايثون حيث أن list هي نفسها array ولكن في بايثون تمت تسميتها list اما الفرق بينها وبين اللغات الاخرى وعلى سبيل المثال جرب أن تقوم بتعبئة مصفوفة في لغة سي بلس أو جافا بعناصر مختلفة لا يمكنك ذلك حيث لا يمكن وضع سلسلة نصية مع عدد صحيح مع عدد حقيقي [1.5, 1, "111", 'c'] # هذا خاطئ في سي بلس أو جافا في حين تستطيع القيام بذلك بكل سهولة في بايثون حيث تقبل list عناصر مختلفة كالمثال السابق [1.5, 1, "111", 'c', [1, 2, 3]] # هذا صحيح في بايثون حيث تقبل عناصر مختلفة في النوع1 نقطة
-
نعم هناك فرق بين القائمة (list) والمصفوفة (array) في لغة برمجة Python. القائمة (list) هي ترتيب مرن من العناصر، حيث يمكن أن تحتوي على أي نوع من البيانات مثل الأعداد والسلاسل والقوائم الأخرى وحتى الكائنات. يمكن إضافة وحذف العناصر من القائمة وتعديلها بسهولة. على سبيل المثال: my_list = [1, 2, 3, "four", [5, 6]] أما بالنسبة ل المصفوفة (array) هي هيكل بيانات متجانس يحتوي على عناصر من نفس النوع. تستخدم المصفوفات عادة للعمليات الرياضية والعلمية ومعالجة البيانات الكبيرة. لإنشاء مصفوفة في Python ، يمكنك استخدام مكتبة NumPy التي توفر دعمًا قويًا للمصفوفات. على سبيل المثال: import numpy as np my_array = np.array([1, 2, 3, 4, 5]) المصفوفات في NumPy توفر عمليات فعالة للتعامل مع البيانات الرقمية وتنفيذ العمليات الرياضية بسرعة. كما توفر أيضًا وظائف مفيدة للتلاعب بالمصفوفات وتحويلها. لذا، إذا كنت تحتاج إلى هيكل بيانات مرن ومتنوع، فإن القائمة (list) هي الخيار المناسب. أما إذا كنت تعمل على العمليات الرياضية أو معالجة البيانات الكبيرة، فإن المصفوفة (array) في NumPy هي الخيار المناسب.1 نقطة
-
تستطيع ذلك بكل سهولة عبر نفس الكود السابق مع إضافة البداية 10 عبر وضع الاتي language_list = df['A'][10:].tolist() # حددنا اسم العمود ضمن المتحول الذي خذنا فيه البيانات print(language_list) # طباعة النتيجة لاحظ فقط وضعنا اسم العمود ضمن قوسين مصفوفة ثم قوسين مع وضع 10 ثم نقطتين إي نعني بذلك من السطر العاشر وحتى النهاية بالنسبة للعمود A1 نقطة
-
اقرا الرد السابق في اخره لقد شرحت ذلك عليك فقط تغيير اسم العمود إلى اسم العمود لديك1 نقطة
-
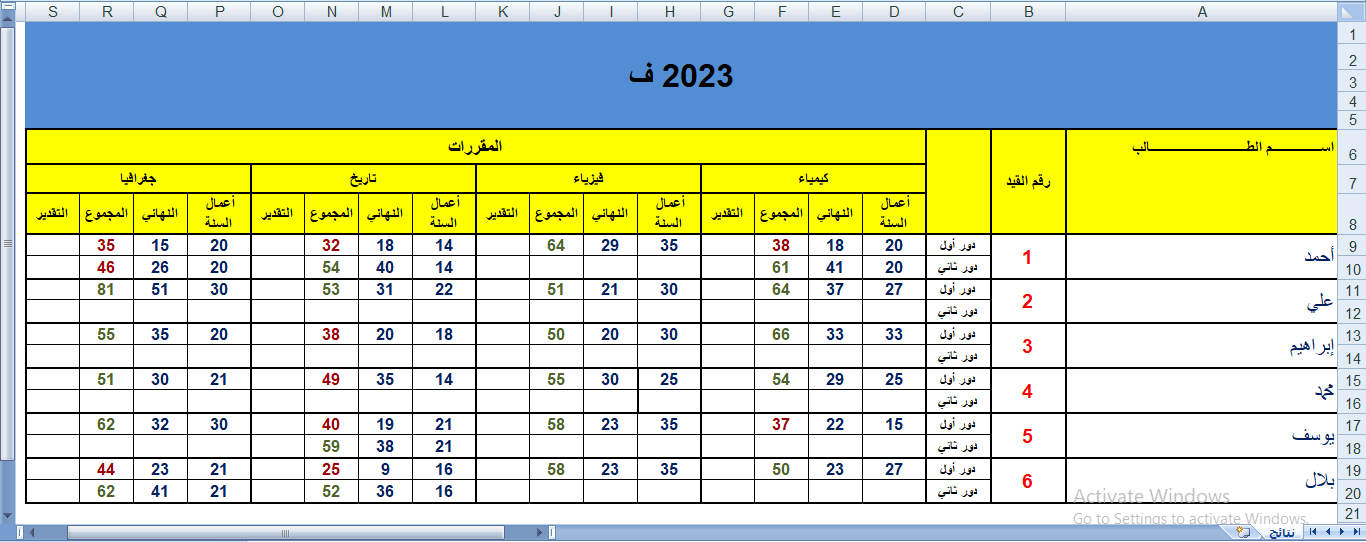
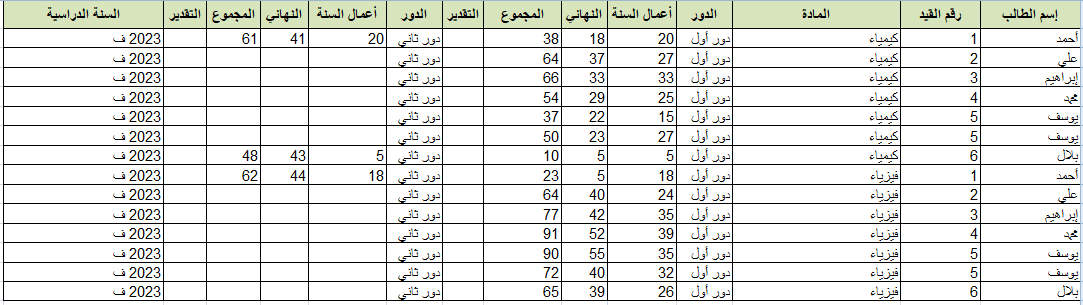
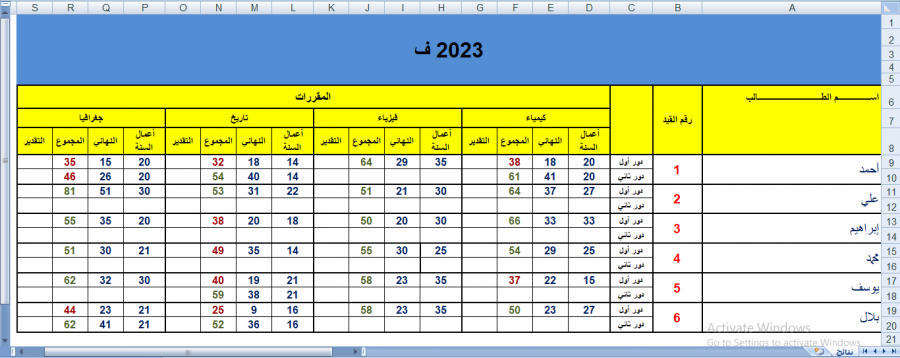
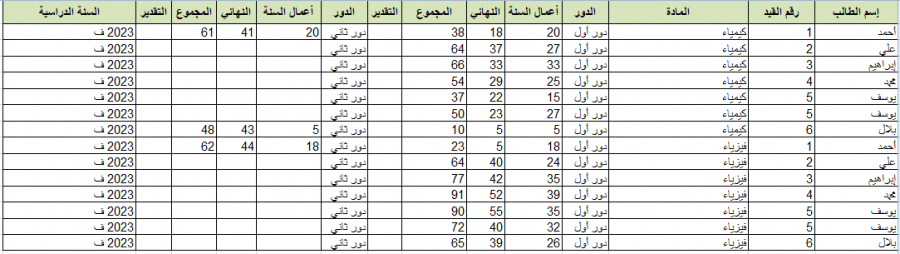
اختيار موفق في استعمال pandas للتعامل مع البيانات الموجودة في ملفات csv و excel حيث انها توفر اشكالا سهلة وبسيطة سواء للتعامل او لقراءة للبيانات وكذلك العمليات الرياضية البسيطة التي توضح معالجة للبيانات بشكل سهل وواضح. كذلك فإنها تعتمد على شكل dataframe والذي يجعل شكل البيانات سهلا وواضحا للقراءة، لذا فهي اكثر المكتبات استخداما في مجال تحليل البيانات يوجد ملف في الاسفل خاص بexecl تستطيع قراءة الملف باستخدام pandas كالاتي import pandas as pd df = pd.read_excel("test.xlsx", header=0) # قراءة الملف باستخدام المسار print(df.head()) # استعراض أول 5 اسطر من الملف تستطيع وضع عدد الاسطر التي سوف تقوم بعرضها ضمن التابع والنتيجة كالاتي Rank Language Percentageof worldpopulation(2018) 0 1 Mandarin Chinese 12.3% 1 2 Spanish 6.0% 2 3 English 5.1% 3 3 Arabic 5.1% 4 5 Hindi 3.5% لتحويل العمود langauge إلى list نستطيع كتابة الاتي language_list = df['Language'].tolist() # حددنا اسم العمود ضمن المتحول الذي خذنا فيه البيانات print(language_list) # طباعة النتيجة #الخرج الذي سيظهر ['Mandarin Chinese', 'Spanish', 'English', 'Arabic', 'Hindi', 'Bengali', 'Portuguese', 'Russian', 'Japanese', 'Western Punjabi', 'Javanese'] حيث الوظيفة tolist تحول العمود إلى قائمة list وهكذا تستطيع التعامل مع العمود عبر كتابة اسم المتحول الذي يخزن البيانات وهو هنا df ثم قوسين مع اسم العمود ضمن علامتي اقتباس test.xlsx1 نقطة
-
لايوجد اجابة صحيحة بالمطلق هنا، حيث أن القيمة الافتراضية لل state تعتمد كليا على نوع البيانات الخاص بك والسياق الذي تريده. سأعطيك بعض الأمثلة: بفرض لدينا form يحتوي على قائمة منسدلة للبلدان ليختار منها المستخدم، ففي هذه الحالة يجب اختيار أول خيار كقيمة افتراضية (اليمن) لأنه يمكن ان لايغير المستخدم القيمة الاولى الظاهرة لتبقى اليمن، فان كانت القيمة الافتراضية فارغة او null او undefinded، فانه لن يتم تخزين اليمن (القيمة الاولى الظاهرة) في حال لم يضغط المستخدم على الخيارات. const [country, setCountry] = useState("يمن") <select value={country} onChange={handleChange}> <option>اليمن</option> <option>سوريا</option> <option>مصر</option> </select> يمكن تعيين القيمة الافتراضية ل state معينة ك null او undefined لسهولة فحص ان كانت موجودة او لا، خصيصا عند التعامل مع API او مع بيانات قد يتم الحصول عليها او لا: const [data, setData] = useState(null) if (!data) { return <div>data is not fetched</div> } else { return <div>data is fetched</div> }1 نقطة