


Ali Ahmed6
-
المساهمات
85 -
تاريخ الانضمام
-
تاريخ آخر زيارة
نوع المحتوى
ريادة الأعمال
البرمجة
التصميم
DevOps
التسويق والمبيعات
العمل الحر
البرامج والتطبيقات
آخر التحديثات
قصص نجاح
أسئلة وأجوبة
كتب
دورات
أجوبة بواسطة Ali Ahmed6
-
-
السلام عليكم
# face-recognition import face_recognition import numpy from PIL import Image , ImageDraw # David Malan # تحميل الصوره david = face_recognition.load_image_file("David.png") harvard = face_recognition.load_image_file("Harvard.jpg") # locations and encodins face david_encoding = face_recognition.face_encodings(david)[0] harvard_locations = face_recognition.face_locations(harvard) harvard_encoding = face_recognition.face_encodings(harvard , harvard_locations) # draw in Image pil_image = Image.fromarray(harvard) draw = ImageDraw.Draw(pil_image) # for loop for (top , right , bottom , left) , face_encodeing in zip(harvard_locations , harvard_encoding): matches = face_recognition.compare_faces([david_encoding] , face_encodeing) best_match_index = numpy.argmin(matches) if matches[best_match_index]: box_color = "green" else: box_color = "red" draw.rectangle(((left,top) , (right,bottom)), outline=box_color , width=5) if matches[best_match_index]: text = "David Malan" else: text = "Unknown" draw.text((left,top - 20), text, fill=box_color, font=None) pil_image.save("harvard.jpg"
-
بتاريخ On 30/11/2023 at 12:33 قال عبدالباسط ابراهيم:
الشيفرة التي قمت بمشاركتها هي خوارزمية بحث ثنائي (Binary Search)، ولكن هناك بعض المشكلات في الشيفرة التي قد تؤثر على عملية البحث الصحيحة. إليك بعض المشكلات التي يمكننا تصحيحها:
- في السطر `end = start + 1` و `start = end - 1`، يجب تعديلها لتحديث قيمة `start` و `end` بناءً على قيمة `mid` بدلاً من القيم الثابتة. يمكنك تعديلها على النحو التالي:
- يجب إضافة تعليمة `break` بعد طباعة "Found" في حالة العثور على العنصر المطلوب. هذا لأنه بعد العثور على العنصر، لا يوجد حاجة للاستمرار في الحلقة. يمكنك إضافة `break` على النحو التالي:
- يجب إضافة تعليمة `else` في نهاية الحلقة لطباعة "Not Found" إذا لم يتم العثور على العنصر المطلوب. يمكنك إضافة `else` على النحو التالي:
بعد تصحيح هذه المشكلات، يجب أن تعمل الشيفرة بشكل صحيح للبحث عن العنصر المطلوب في القائمة المرتبة.
طيب استخدم نفس الشيفره عادي لو بدور علي اسماء عادي صح والا اي ؟
ولو سمحت سوال كمان هو انا ممكن استخدم الخورزميه ده فيه اي نوع يعني مثل dict وكده يعني والا الا فيه ال arr فقط؟
-
-
بتاريخ 3 دقائق مضت قال Mustafa Suleiman:
الدالة sort تستخدم خوارزميات فعالة للفرز تعتمد على الأداء، مثل Timsort.
و Timsort هي خوارزمية مركبة تجمع بين خصائص خوارزميات الفرز الدمجي (Merge Sort) والفرز الإدراجي (Insertion Sort)، مما يجعلها فعالة في معالجة مجموعات البيانات المختلفة.
بالمقابل، خوارزميات الفرز مثل Bubble Sort وSelection Sort تعتبر أبسط ولكنها أقل فعالية من حيث الأداء، خاصة عند التعامل مع مجموعات بيانات كبيرة.
لذا، عندما تحتاج إلى فرز مجموعة صغيرة من البيانات أو عامل الوقت (الأداء) أمرًا ثانويًا، بإمكانك استخدام أيِ من Bubble Sort أو Selection Sort.
ولكن في معظم الحالات، يُفضل استخدام الدالة sort في Python التي تستند إلى Timsort، خاصةً عند التعامل مع مجموعات بيانات كبيرة.
حيث تشترك خوارزميات bubble sort و selection sort في نفس تعقيد الوقت في أسوأ الحالات، وهو O(n^2)، مما يعني أن عدد العمليات التي يتعين القيام بها لفرز المصفوفة يتناسب مع مربع حجم المصفوفة.
بينما، تتمتع الدالة sort بأداء أفضل بكثير، حيث تعتمد على خوارزمية أكثر تعقيدًا، ولكنها أكثر فعالية، وتعقيد الوقت في أسوأ الحالات للدالة sort هو O(n log n)، أي أن عدد العمليات التي يتعين القيام بها لفرز المصفوفة يتناسب مع حاصل ضرب حجم المصفوفة وسجل حجم المصفوفة.
تمام , الله ينور عليك
بس سوال يعني هو انا ممكن اتعلم خورزميات Timsort ؟
-
السلام عليكم
اي الفرق بين الدله sort الموجود فيه باثيون و بين خورزميات bubble sort او selection sort ؟
وانا كامبرمج استخدم اي ؟
-
 1
1
-
-
بتاريخ 6 دقائق مضت قال Adnane Kadri:
لا تزال تحتاج تحديث نهاية النطاق (end) عندما يكون العنصر الذي نبحث عنه أقل من العنصر في منتصف النطاق. وبنفس المنطق، تحديث بداية النطاق (start) عندما يكون العنصر الذي نبحث عنه أكبر من العنصر في منتصف النطاق.
أيضا سوف تحتاج إضافة تحقق بعد الحلقة للتحقق مما إذا كان لم يتم العثور على العنصر.
شيء آخر يجب عليك القيام به هو كسر الحلقة عند الحصول على العنصر.
الناتج:arr = [2, 3, 4, 5, 6, 7, 8] start = 0 end = len(arr) - 1 n = int(input("Number: ")) while start <= end: mid = start + (end - start) // 2 if n == arr[mid]: print("Found") break # يجب إيقاف الحلقة بمجرد العثور على العنصر elif n < arr[mid]: end = mid - 1 # تحديث نهاية النطاق ليكون mid - 1 elif n > arr[mid]: start = mid + 1 # تحديث بداية النطاق ليكون mid + 1 if start > end: print("Not Found")
يا انهار ابيض , ايو صح انا نسية اكسر الحلقه وكمان نسيه الmid
شكرااا جداا والله
-
الكود ده عبار عن خورزميات البحث الثناثي
arr = [2,3,4,5,6,7,8] start = 0 end = len(arr) - 1 n = int(input("Number: ")) while start <= end: mid = start + (end - start) // 2 if n == arr[mid]: print("Found") elif n < arr[mid]: # 3 < 5 end = start + 1 # start = 0 / end = 1 elif n > arr[mid]: # 7 > 5 start = end - 1 # start = 5 else: print("No Found")
-
1
-
-
-
السلام عليكم
اي هي الحزمه google الموجود فيه لغة باثيون ؟
وهل هي مكتبه ام اطاره عمل ؟
بتاريخ 3 دقائق مضت قال Ali Ahmed6:السلام عليكم
اي هي الحزمه google الموجود فيه لغة باثيون ؟
وهل هي مكتبه ام اطاره عمل ؟
وكمان اي هو googlemaps ؟
يعني انا ازي استفيد من الحاجات ده ؟
-
1
-
-
السلام عليكم
هل تعلم اطار عمل واحد كافي مثل tensorflow فيه مجال الدكاء الاصطناعي ؟
وهل اطاره العمل PyTorch هو نفسه torch ؟
-
السلام عليكم
اي هو السودكود ؟
وامتي استخدم سودكود؟
-
بتاريخ 2 ساعة قال عمار معلا:
في البداية يجب عليك معرفة أن بايثون مبنيه على سي بلس بلس مع ذلك فأن بايثون تقوم بإدارة الذاكرة تلقائيا، بينما في سي بلس بلس يتعيين على المبرمج إدارة الذاكرة يدويا
في بايثون، يتم استخدام مفهوم (Garbage Collection) وهذ يعني أن الذاكرة التي لم تعد مستخدمة سيتم تحريرها تلقائيًا دون تدخل المبرمج، لاحظ الكود التالي
b = 10 b = 50
عندما يتم تغيير قيمة المتغير "b" إلى 50 في السطر، ستتم إزالة القيمة السابقة 10 من الذاكرة تلقائيًا
في سي بلس بلس، يتعين على المبرمج إدارة الذاكرة يدويًا كما ذكرت، يقع على عاتق المبرمج تخصيص الذاكرة وتحريرها يدويًا، على سبيل المثال، في الكود التالي:
int main() { int *pointer = new int; // تخصيص ذاكرة *pointer = 10; delete pointer; // تحرير ذاكرة return 0; }
في التعليق الأول يتم تخصيص ذاكرة جديدة باستخدام "new" عبر مفهوم المؤشرات حيث أن int يستهلك 4 بايتات من الذاكرة وبالتالي تم تخصيص هذه المساحة لنضع فيها القيمة 10 وبعدها تم تعيين قيمة المؤشر إلى 10 ثم في التعليق الثاني تم تحرير الذاكرة باستخدام "delete" يدويًا من قبل المبرمج، مما يعني أن الذاكرة التي تم تخصيصها لتخزين القيمة 10 ستتم تحريرها.
وهذا هو الفرق بينهما في إدارة الذاكرة فبايثون تقوم بإدارة الذاكرة تلقائيًا دون تدخل المبرمج مما يجعلها أكثر سهولة للاستخدام وأقل عرضة لأخطاء إدارة الذاكرة مقارنة بسي بلس بلس التي يعتمد إدارة الذاكرة لديها على المبرمج
تستطيع قراءة هذا المقال عن إدارة الذاكرة في لغة cتمام , يعني انا كامبرمج بلغه الباثيون المفروض ما اشغلش بالي باحده زي كده صح
حتي لو انا بتعلم مجال زي تعليم الاله ؟
-
السلام عليكم
كيف يتم تخزين البيانات فيه الداكرة ؟
وهل يوجد مقال علي اكادميه حاسوب بيتكلام عن انواع البيانات وكيف يتم تخزين البيانات ؟
وهل لغه باثيون بتعمل مع الداكرة زي لغة سي او جافا صح ؟
-
1
-
-
تمام , انا فهمت الحمد الله شكرااااا
-
السلام عليكم
اي هي وظفيه dir() فيه python ?
-
1
-
-
السلام عليكم
هو فيه فرق بين الlist و arrry فيه الباثيون ؟
-
1
-
-
بتاريخ منذ ساعة مضت قال عمار معلا:
لا يوجد فقط مكتبة واحدة تستخدم في حل مشكلة ضخمة مثل التقاط الصور الثقوب السوداء ف numpy مخصصة لإجراء العمليات الحسابية ومعالجة البيانات واجراء العمليات على المصفوفات
لا تستطيع استخدام مكتبة معرفة في بايثون في لغة برمجة أخرى، كل لغة لها مكتباتها الخاصة بهاشكرااااا
-
هو مكتبه الnumpy استخدمة فيه التقطه صوره الثقب الاسود ؟
وهل مكتبه الnumpy و pandas ممكن استخدمهم فيه لغة برمجه تاني غير باثيون ؟
وشكرااا جدااا
-
السلام عليكم
هل ممكن احتاج لnumpy و pandas فيه برمجه مواقع الوايب ؟
-
1
-
-
المشكله ده بس علي نظام Windows ؟ والمكتبه بتشتغل عادي جدا علي نظام الماك او لنيكس ؟
بتاريخ On 21/11/2023 at 08:32 قال عمار معلا:وعليكم السلام،
بالطبع مكتبة face_recognition مدعومة من قبل windows لكي يوجد بعض المشاكل في تثبيتها في إصدارات بايثون الاخيرة لذلك تأكد من أن الاصدار لديك إما بايثون 3.7 أو 3.8 ثم تأكد من وجود git لديك ثم تستطيع أن تقوم بتنزيل الكود المصدري عبر الاتيgit clone https://github.com/RvTechiNNovate/face_recog_dlib_file.git
ستظهر لك الصورة التالية
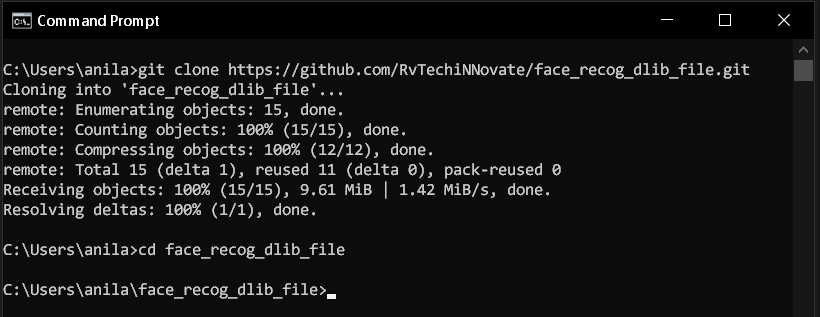
ثم قم بالدخول إلى مجلد المشروع عبر الاتيcd face_recog_dlib_fileثم بعد ذلك قم بتثبيت مكتبة dlib بحسب إصدار بايثون الذي قمت بتنزيله 3.7 أو 3.8
#Python 3.7: pip install dlib-19.19.0-cp37-cp37m-win_amd64.whl #Python 3.8: pip install dlib-19.19.0-cp38-cp38-win_amd64.whl
ثم قم بتثبيت cmake عبر الاتي
pip install cmakeسيظهر لك الصورة التالية للعمليات السابقة
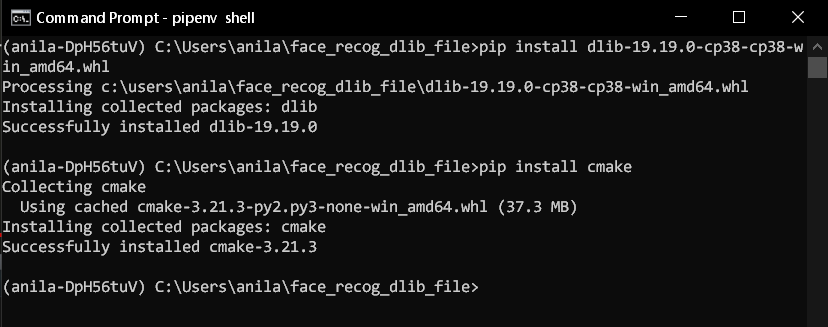
قم بعد ذلك بتحديث pip لتجنب الاخطاء ثم عملية تثبيت المكتبةpip install --upgrade pip pip install face-recognition
-
بتاريخ 2 ساعة قال عمار معلا:
وعليكم السلام،
بالطبع مكتبة face_recognition مدعومة من قبل windows لكي يوجد بعض المشاكل في تثبيتها في إصدارات بايثون الاخيرة لذلك تأكد من أن الاصدار لديك إما بايثون 3.7 أو 3.8 ثم تأكد من وجود git لديك ثم تستطيع أن تقوم بتنزيل الكود المصدري عبر الاتيgit clone https://github.com/RvTechiNNovate/face_recog_dlib_file.git
ستظهر لك الصورة التالية
ثم قم بالدخول إلى مجلد المشروع عبر الاتيcd face_recog_dlib_fileثم بعد ذلك قم بتثبيت مكتبة dlib بحسب إصدار بايثون الذي قمت بتنزيله 3.7 أو 3.8
#Python 3.7: pip install dlib-19.19.0-cp37-cp37m-win_amd64.whl #Python 3.8: pip install dlib-19.19.0-cp38-cp38-win_amd64.whl
ثم قم بتثبيت cmake عبر الاتي
pip install cmakeسيظهر لك الصورة التالية للعمليات السابقة
قم بعد ذلك بتحديث pip لتجنب الاخطاء ثم عملية تثبيت المكتبةpip install --upgrade pip pip install face-recognition
ايوه , بس انا باستخدم احدث اصدر لباثيون وهو 3.12.0 ?
-
1
-
-
السلام عليكم
هل مكتبة face-recognition غير مدعوم علي نظام Windows ؟
-
طيب تثبيت OpenCV اسهل من تثبيت face-recognition والا الموضوع بيكون صعب زي face-recognition ؟
-
سوال كمان لوسمحت
هي cv2 هي نفسه OpenCV ؟
-
1
-
اي الخطاء فيه الكود ده
في بايثون
نشر
تمام , الحمد الله حلت المشكله
شكراااا