


Ola Abbas
-
المساهمات
189 -
تاريخ الانضمام
-
تاريخ آخر زيارة












آخر الزوار
5553 زيارة للملف الشخصي




إنجازات Ola Abbas
عضو نشيط (3/3)
27
السمعة بالموقع
-

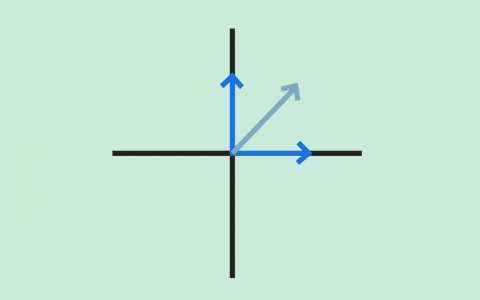 يناقش هذا المقال خاصيةً مهمةً أخرى للشعاع وهي خاصية الاتجاه، إذ ناقشنا في المقال السابق خاصية الطول، حيث تعرّف هاتان الخاصيتان الشعاع. سنوضّح في هذا المقال المواضيع التالية: المنحى Orientation أو اتجاه الحركة للأشعة ثنائية الأبعاد (مُمثَّلة في إطار إحداثي معين). الغموض عند استخدام قوس الظل arc tan لحساب الزاوية. تحويل الطول والمنحى إلى مكونات مصفوفة عمودية. قياس الزوايا بوحدتي الراديان Radian والدرجة المئوية. استخدام لغتي البرمجة سي C وجافا Java مع قوس الظل. الأشعة المحاذية للمحورين X-Y ما هو اتجاه الشعاع الذي تمثله المصفوفة العمودية (4, 0)T؟ يوازي هذا الشعاع المحور X لإطار الإحداثيات الذي نستخدمه، وسيكون هذا الشعاع غالبًا أفقيًا ويؤشّر إلى اليمين (أو يمكن القول أن الشعاع له منحى مقداره 0 درجة). للشعاع ثنائي الأبعاد الذي يحاذي محور الإحداثيات -كما هو الحال مع (4, 0)T- منحًى يسهل رؤيته، ويكون عند 0 درجة أو 90 درجة أو 180 درجة أو 270 درجة. يُعبَّر عن منحى الشعاع عادةً من خلال زاوية مع المحور x الموجب لإطار الإحداثيات، وهناك طريقتان لذلك: تُقاس الزاوية من 0 إلى 360 درجة بعكس اتجاه دوران عقارب الساعة ابتداءً من المحور x الموجب. تُقاس الزاوية من 0 إلى +180 درجة بعكس اتجاه دوران عقارب الساعة, ابتداءً من المحور x الموجب، أو تُقاس من 0 إلى -180 درجة مع اتجاه دوران عقارب الساعة ابتداءً من المحور x الموجب. حساب زاوية الشعاع عن المحور X ما هو اتجاه الشعاع a في المخطط البياني السابق؟ يكون منحى الشعاع a = (4, 4)T بزاوية مقدارها 45 درجة. يجب أن تعطي الرياضيات الإجابة نفسها، إذ يُقدَّر ميل Slope الشعاع a بما يلي: (التغير في قيمة x)/(التغير في قيمة y) = 4.0/4.0 = 1.0 بالتالي تكون الزاوية باستخدام قوس الظل هي: 45 = arc tan( 1.0 ) درجة. ليس للأشعة موقع، لذا لا يعتمد الطول ولا الاتجاه على المكان الذي ترسم فيه الشعاع، وتكون صيغة اتجاه الشعاع ثنائي الأبعاد هي: angle of (x, y)T = arc tan( y/x ) وللتأكيد يعني استخدام قوس الظل لقيمةٍ ما arc tan( z ) أنه تم العثور على الزاوية التي لها ظل tangent مقداره z، وتذكّر -عند حسابها باستخدام الآلة الحاسبة- أن الإجابة يمكن أن تكون بالراديان أو بالدرجات، إذ تمنحك معظم الآلات الحاسبة خيار استخدام أيّ من هذين التنسيقين. وبما أن الآلات الحاسبة تعطي عادةً الإجابة محصورةً بين -90.0 و +90.0 درجة (أو بين -pi و +pi راديان)، فقد تضطر إلى تعديل الإجابة (سنوضح ذلك لاحقًا). يمكنك أيضًا استخدام الآلة الحاسبة على حاسوبك، فإذا كنت تستخدم نظام التشغيل ويندوز، فانقر على الخيار "علمي Scientific" في قائمة "العرض View" للآلة الحاسبة التي تحتوي على قوس الظل arc tan الذي يمكن أن يكون له تسمية هي tan-1. ما هو منحى الشعاع الذي تمثله المصفوفة العمودية: k = (3,4)T (باستخدام الآلة الحاسبة)؟ arc tan( y/x ) = arc tan( 4/3 ) = arc tan( 1.333333333333 ) = 53.13 درجة التعامل مع القيم السالبة يوضح المخطط البياني السابق الشعاع الذي تمثله المصفوفة العمودية: k = (3,4)T، والذي حسبنا منحاه ليكون 53.13 درجةً عن محور x الموجب، وبالتالي يبدو كل شيء صحيحًا. لنحسب الآن منحى الشعاع -k = (-3,-4)T من خلال استخدام الصيغة التالية: arc tan( y/x ) = arc tan( -4/-3 ) = arc tan( 4/3 ) = arc tan( 1.333333333333 ) = 53.13 درجة لاحظ وجود خطأ، إذ أعطتنا هذه الصيغة الزاوية نفسها للشعاع الذي يؤشّر إلى الاتجاه المعاكس لاتجاه الشعاع الأول. تكمن المشكلة في فقدان المعلومات عند قسمة -4 على -3، إذ لا يمكننا تفريق هذه النتيجة عن نتيجة قسمة +4 على +3، وبالتالي هذه الصيغة ليست كافيةً لتعطيك الإجابة الصحيحة، ويجب عليك رسم الشعاع ثم تعديل الإجابة. لاحظ من المخطط البياني أن منحى الشعاع -k الذي يُعبَّر عنه بالدرجات من 0 إلى 360 بعكس اتجاه عقارب الساعة عن المحور x هو (180 + 53.13) = 233.13 درجة. ما هو منحى الشعاع الذي تمثله المصفوفة العمودية: p = (3,-4)T(استخدم تطبيق الآلة الحاسبة الموجود على حاسوبك)؟ ضع الأعداد في حاسبة ويندوز كما يلي: arc tan( y/x ) = arc tan( -4/3 ) = arc tan( -1.333333333333 ) = -53.13 درجة يبدو الحساب صحيحًا في المخطط البياني السابق، وإذا أردتَ التعبير عن الزاوية بعكس اتجاه دوران عقارب الساعة، فهي 360 - 53.130 = 306.870 درجة، ولكن سيعطيك الشعاع -p النتيجة نفسها للأسف، لذا ارسم دائمًا الشعاع عندما تحسب منحاه، بعدها يمكنك أن ترى أن الزاوية التي تريدها للشعاع -p هي 180 - 53.130 = 126.87 درجة. تتوفر الدالة atan2(y, x) في معظم لغات البرمجة، إذ تحسب هذه الدالة الزاوية بالراديان بين المحور x الموجب والنقطة المعطاة بالإحداثيات (x, y)، وتستخدِم إشارتَي x و y لتحديد الربع الصحيح للزاوية. ما هو منحى الشعاع u = (-4,-2)T ؟ (ارسم الشعاع أولًا، ثم استخدم الآلة الحاسبة)؟ عوّض القيم في الصيغة واستخدم الآلة الحاسبة لإيجاد الناتج: arc tan( y/x ) = arc tan( -2/-4 ) = arc tan( 0.5 ) = 26.565 درجة ولكن سترى عند رسم الشعاع أنه يقع في الربع الخطأ، لذا يجب أن تكون الإجابة 180 + 26.565 = 206.565 درجة. حساب السمتين (x, y) الخاصتين بالشعاع لنفترض أنك تعلم أن الشعاع يمكن تمثيله بمصفوفة عمودية (x, y)T باستخدام إطار إحداثي معين، ويمكن حساب هاتين السمتين x و y كما يلي: orientation of (x, y)T = arc tan( y/x ) |(x, y)T| = √( x2 + y2 ) ارسم الشعاع r الذي تمثله المصفوفة العمودية (4, 5)T، ثم قدّر طوله واتجاهه، وأجرِ العمليات الحسابية للحصول على الإجابة الدقيقة كما يلي: الطول: | r | = | (4,5)T | = √(16+25) = 6.40 الاتجاه: direction = arc tan{ 5/4 } = 51.34 درجة تحويل الطول والاتجاه إلى السمتين (x, y) لنفترض أن لديك طول واتجاه وتريد التعبير عنهما بشعاع عمودي ثنائي الأبعاد، يمكنك فعل ذلك باتباع الخطوات التالية: أنشئ مخططًا بيانيًا. احسب قيمة x من خلال إسقاط الطول على المحور x باستخدام length*cos( θ ). احسب قيمة y من خلال إسقاط الطول على المحور y باستخدام length*sin( θ ). تحقق من الإجابات وفق المخطط البياني. لنفترض أن لدينا شعاعًا طوله 4 ومنحاه بزاويةٍ مقدارها 150 درجة. إذًا ما هي المصفوفة العمودية التي تمثّل هذا الشعاع؟ سنمثّل هذا الشعاع بالمصفوفة العمودية ثنائية الأبعاد ( -3.464, 2.0 )T . حساب الزوايا بالراديان اتبع الخطوات التالية في هذا الحساب: أنشئ مخططًا بيانيًا كما يلي: احسب قيمة x من خلال إسقاط الطول على المحور x كما يلي: 4 * cos( 150 ) = -3.464 احسب قيمة y من خلال إسقاط الطول على المحور y كما يلي: 4 * sin( 150 ) = 2.0 تحقق من الإجابات وفق المخطط البياني (تبدو جيدة). كن حذرًا بشأن استخدام هذه الصيغ وتوقّع الإجابات الصحيحة، خاصةً عند البرمجة بلغة سي أو جافا، إذ يمكن للمكتبات الرياضية الخاصة بلغة البرمجة أن تعطي أشياءً غير متوقعة إن لم تكن حذرًا، ولكن توجد ثلاثة أماكن يجب توخي الحذر فيها بصورة خاصة وهي: من المتوقع أن يكون وسيط sin() و cos() و tan() بالراديان، والقيمة التي تعيدها atan() بالراديان. من المتوقع أن يكون وسيط معظم الدوال الرياضية من النوع double، ولكن إذا استخدمتَ عددًا عشريًا float أو عددًا صحيحًا int، فلن تحصل على رسالة خطأ، بل مجرد إجابة غريبة غير صحيحة. توجد عدة إصدارات من دالة "arc tan" في معظم مكتبات لغة سي، وكلٌ منها مخصَّص لمجال مختلف من قيم الخرج. يُعبَّر عن الزوايا عادةً بالراديان، وتُقاس الزوايا بعكس اتجاه عقارب الساعة ابتداءً من المحور x الموجب (أو تُقاس الزاوية السالبة باتجاه عقارب الساعة ابتداءً من المحور x الموجب أحيانًا)، إذ يوجد ما مقداره 2 pi راديان في الدائرة الكاملة، أي أن: ((2 pi راديان = 360 درجة لنفترض أن لدينا شعاعًا له طول length وزاوية angle! أوجد في هذه الحالة قيمة vector[0] التي تمثل المركّبة x، وأوجد قيمة vector[1] التي تمثّل المركّبة y الخاصة بهذا الشعاع. #include <math.h> double length, angle; /* طول وزاوية الشعاع */ double vector[2]; /* عناصر الشعاع */ . . . length = قيمةٌ ما angle = عددٌ ما بالدرجات vector[0] = ???? vector[1] = ???? لنفترض أن رمز pi هو M_PI، ولكن لسوء الحظ تستخدم المصرّفات Compilers المختلفة رموز PI مختلفة وتعرّفها في ترويسات ملفات مختلفة، لذا يجب أن تستخدم الرمز المناسب لنظام تشغيلك بدلًا من تعريف PI بنفسك. ملاحظة: إذا لم تكن على دراية بلغة سي، فيمكنك عَدّ هذه الشيفرة بأنها مكتوبة بلغة جافا. #include <math.h> double length, angle; double vector[2]; . . . length = قيمةٌ ما angle = عددٌ ما بالدرجات vector[0] = length * cos( angle*M_PI/180.0 ) vector[1] = length * sin( angle*M_PI/180.0 ) تدريب عملي تذكّر أولًا الخطوات التي يجب اتخاذها لتحويل الشعاع المعلوم طوله واتجاهه إلى (x,y): أنشئ مخططًا بيانيًا. احسب قيمة x من خلال إسقاط الطول على المحور x باستخدام length*cos( θ ). احسب قيمة y من خلال إسقاط الطول على المحور y باستخدام length*sin( θ ). 4: تحقق من الإجابات وفق المخطط البياني. وتبقى الخطوات نفسها إذا كانت الزاوية مُعطاةً بالراديان. تدريب 1: ليكن لدينا شعاع طوله 4.5 (بأيّ وحدة طول) وزاوية منحاه 0.70 راديان، ولنعبّر عن هذا الشعاع بالصيغة ( x, y )T كما يلي: أنشئ مخططًا بيانيًا كما يلي: احسب قيمة x من خلال إسقاط الطول على المحور x كما يلي: 4.5*cos( 0.70 ) = 3.442 احسب قيمة y بإسقاط الطول على المحور y كما يلي: 4.5*sin( 0.70 ) = 2.899 تحقق من الإجابات وفق المخطط البياني. تدريب 2: لنفترض أن الدعسوقة ليلى أضاعت صديقتها سلوى، ولكن كان مع ليلى هاتف محمول لحسن الحظ وكان: موقع ليلى عند النقطة (1, -4). موقع سلوى عند النقطة ( -4, 3). اتصل بليلى وأخبرها في أيّ اتجاه وإلى أيّ مسافة يجب أن تمشي للوصول إلى صديقتها سلوى. الحل: الاتجاه = 125.54 درجة، والمسافة = 8.60. كان عليك أن تتذكر كيفية حساب الإزاحة للحصول على الإجابة، إذ يمكنك حساب شعاع الإزاحة بين نقطتين (أو بين الدعسوقتين) كما يلي: (المكان الذي تريد أن تكون فيه) - (مكانك الحالي) = (الإزاحة التي تحتاجها) إذًا الإزاحة التي يجب أن تمشيها ليلى هي: ( -4, 3) - (1, -4) = (-5, 7) ولكن تحتاج ليلى إلى مسافة وجهة هما: المسافة: √(25 + 49) = 8.60 الاتجاه: arc tan( 7/-5 ) = arc tan( -1.4 ) = -54.46 درجة نعدّل الاتجاه بالنظر إلى المخطط البياني ويصبح الاتجاه هو: 180 - 54.46 = 125.54 درجة هل يمكن تطبيق الأفكار المتعلقة بمنحى الشعاع ثنائي الأبعاد الواردة في هذا المقال في الفضاء ثلاثي الأبعاد؟ نعم، ولكن ليس بهذه السهولة، إذ سيتطلب منحى الأشعة ثلاثية الأبعاد مزيدًا من العمل. وصلنا إلى نهاية هذا المقال الذي تعرّفنا فيه على خاصية الاتجاه الخاصة بالشعاع، وسنناقش في المقال التالي حاصل ضرب شعاع وقيمة عددية. ترجمة -وبتصرُّف- للفصل Vector Direction من كتاب Vector Math for 3D Computer Graphics لصاحبه Bradley Kjell. اقرأ أيضًا المقال السابق تعرف على خاصية الطول Length للأشعة الهندسية وكيفية حسابه. المعاملات (parameters) في جافا. الأنواع الحقيقية والصحيحة في لغة سي C.
يناقش هذا المقال خاصيةً مهمةً أخرى للشعاع وهي خاصية الاتجاه، إذ ناقشنا في المقال السابق خاصية الطول، حيث تعرّف هاتان الخاصيتان الشعاع. سنوضّح في هذا المقال المواضيع التالية: المنحى Orientation أو اتجاه الحركة للأشعة ثنائية الأبعاد (مُمثَّلة في إطار إحداثي معين). الغموض عند استخدام قوس الظل arc tan لحساب الزاوية. تحويل الطول والمنحى إلى مكونات مصفوفة عمودية. قياس الزوايا بوحدتي الراديان Radian والدرجة المئوية. استخدام لغتي البرمجة سي C وجافا Java مع قوس الظل. الأشعة المحاذية للمحورين X-Y ما هو اتجاه الشعاع الذي تمثله المصفوفة العمودية (4, 0)T؟ يوازي هذا الشعاع المحور X لإطار الإحداثيات الذي نستخدمه، وسيكون هذا الشعاع غالبًا أفقيًا ويؤشّر إلى اليمين (أو يمكن القول أن الشعاع له منحى مقداره 0 درجة). للشعاع ثنائي الأبعاد الذي يحاذي محور الإحداثيات -كما هو الحال مع (4, 0)T- منحًى يسهل رؤيته، ويكون عند 0 درجة أو 90 درجة أو 180 درجة أو 270 درجة. يُعبَّر عن منحى الشعاع عادةً من خلال زاوية مع المحور x الموجب لإطار الإحداثيات، وهناك طريقتان لذلك: تُقاس الزاوية من 0 إلى 360 درجة بعكس اتجاه دوران عقارب الساعة ابتداءً من المحور x الموجب. تُقاس الزاوية من 0 إلى +180 درجة بعكس اتجاه دوران عقارب الساعة, ابتداءً من المحور x الموجب، أو تُقاس من 0 إلى -180 درجة مع اتجاه دوران عقارب الساعة ابتداءً من المحور x الموجب. حساب زاوية الشعاع عن المحور X ما هو اتجاه الشعاع a في المخطط البياني السابق؟ يكون منحى الشعاع a = (4, 4)T بزاوية مقدارها 45 درجة. يجب أن تعطي الرياضيات الإجابة نفسها، إذ يُقدَّر ميل Slope الشعاع a بما يلي: (التغير في قيمة x)/(التغير في قيمة y) = 4.0/4.0 = 1.0 بالتالي تكون الزاوية باستخدام قوس الظل هي: 45 = arc tan( 1.0 ) درجة. ليس للأشعة موقع، لذا لا يعتمد الطول ولا الاتجاه على المكان الذي ترسم فيه الشعاع، وتكون صيغة اتجاه الشعاع ثنائي الأبعاد هي: angle of (x, y)T = arc tan( y/x ) وللتأكيد يعني استخدام قوس الظل لقيمةٍ ما arc tan( z ) أنه تم العثور على الزاوية التي لها ظل tangent مقداره z، وتذكّر -عند حسابها باستخدام الآلة الحاسبة- أن الإجابة يمكن أن تكون بالراديان أو بالدرجات، إذ تمنحك معظم الآلات الحاسبة خيار استخدام أيّ من هذين التنسيقين. وبما أن الآلات الحاسبة تعطي عادةً الإجابة محصورةً بين -90.0 و +90.0 درجة (أو بين -pi و +pi راديان)، فقد تضطر إلى تعديل الإجابة (سنوضح ذلك لاحقًا). يمكنك أيضًا استخدام الآلة الحاسبة على حاسوبك، فإذا كنت تستخدم نظام التشغيل ويندوز، فانقر على الخيار "علمي Scientific" في قائمة "العرض View" للآلة الحاسبة التي تحتوي على قوس الظل arc tan الذي يمكن أن يكون له تسمية هي tan-1. ما هو منحى الشعاع الذي تمثله المصفوفة العمودية: k = (3,4)T (باستخدام الآلة الحاسبة)؟ arc tan( y/x ) = arc tan( 4/3 ) = arc tan( 1.333333333333 ) = 53.13 درجة التعامل مع القيم السالبة يوضح المخطط البياني السابق الشعاع الذي تمثله المصفوفة العمودية: k = (3,4)T، والذي حسبنا منحاه ليكون 53.13 درجةً عن محور x الموجب، وبالتالي يبدو كل شيء صحيحًا. لنحسب الآن منحى الشعاع -k = (-3,-4)T من خلال استخدام الصيغة التالية: arc tan( y/x ) = arc tan( -4/-3 ) = arc tan( 4/3 ) = arc tan( 1.333333333333 ) = 53.13 درجة لاحظ وجود خطأ، إذ أعطتنا هذه الصيغة الزاوية نفسها للشعاع الذي يؤشّر إلى الاتجاه المعاكس لاتجاه الشعاع الأول. تكمن المشكلة في فقدان المعلومات عند قسمة -4 على -3، إذ لا يمكننا تفريق هذه النتيجة عن نتيجة قسمة +4 على +3، وبالتالي هذه الصيغة ليست كافيةً لتعطيك الإجابة الصحيحة، ويجب عليك رسم الشعاع ثم تعديل الإجابة. لاحظ من المخطط البياني أن منحى الشعاع -k الذي يُعبَّر عنه بالدرجات من 0 إلى 360 بعكس اتجاه عقارب الساعة عن المحور x هو (180 + 53.13) = 233.13 درجة. ما هو منحى الشعاع الذي تمثله المصفوفة العمودية: p = (3,-4)T(استخدم تطبيق الآلة الحاسبة الموجود على حاسوبك)؟ ضع الأعداد في حاسبة ويندوز كما يلي: arc tan( y/x ) = arc tan( -4/3 ) = arc tan( -1.333333333333 ) = -53.13 درجة يبدو الحساب صحيحًا في المخطط البياني السابق، وإذا أردتَ التعبير عن الزاوية بعكس اتجاه دوران عقارب الساعة، فهي 360 - 53.130 = 306.870 درجة، ولكن سيعطيك الشعاع -p النتيجة نفسها للأسف، لذا ارسم دائمًا الشعاع عندما تحسب منحاه، بعدها يمكنك أن ترى أن الزاوية التي تريدها للشعاع -p هي 180 - 53.130 = 126.87 درجة. تتوفر الدالة atan2(y, x) في معظم لغات البرمجة، إذ تحسب هذه الدالة الزاوية بالراديان بين المحور x الموجب والنقطة المعطاة بالإحداثيات (x, y)، وتستخدِم إشارتَي x و y لتحديد الربع الصحيح للزاوية. ما هو منحى الشعاع u = (-4,-2)T ؟ (ارسم الشعاع أولًا، ثم استخدم الآلة الحاسبة)؟ عوّض القيم في الصيغة واستخدم الآلة الحاسبة لإيجاد الناتج: arc tan( y/x ) = arc tan( -2/-4 ) = arc tan( 0.5 ) = 26.565 درجة ولكن سترى عند رسم الشعاع أنه يقع في الربع الخطأ، لذا يجب أن تكون الإجابة 180 + 26.565 = 206.565 درجة. حساب السمتين (x, y) الخاصتين بالشعاع لنفترض أنك تعلم أن الشعاع يمكن تمثيله بمصفوفة عمودية (x, y)T باستخدام إطار إحداثي معين، ويمكن حساب هاتين السمتين x و y كما يلي: orientation of (x, y)T = arc tan( y/x ) |(x, y)T| = √( x2 + y2 ) ارسم الشعاع r الذي تمثله المصفوفة العمودية (4, 5)T، ثم قدّر طوله واتجاهه، وأجرِ العمليات الحسابية للحصول على الإجابة الدقيقة كما يلي: الطول: | r | = | (4,5)T | = √(16+25) = 6.40 الاتجاه: direction = arc tan{ 5/4 } = 51.34 درجة تحويل الطول والاتجاه إلى السمتين (x, y) لنفترض أن لديك طول واتجاه وتريد التعبير عنهما بشعاع عمودي ثنائي الأبعاد، يمكنك فعل ذلك باتباع الخطوات التالية: أنشئ مخططًا بيانيًا. احسب قيمة x من خلال إسقاط الطول على المحور x باستخدام length*cos( θ ). احسب قيمة y من خلال إسقاط الطول على المحور y باستخدام length*sin( θ ). تحقق من الإجابات وفق المخطط البياني. لنفترض أن لدينا شعاعًا طوله 4 ومنحاه بزاويةٍ مقدارها 150 درجة. إذًا ما هي المصفوفة العمودية التي تمثّل هذا الشعاع؟ سنمثّل هذا الشعاع بالمصفوفة العمودية ثنائية الأبعاد ( -3.464, 2.0 )T . حساب الزوايا بالراديان اتبع الخطوات التالية في هذا الحساب: أنشئ مخططًا بيانيًا كما يلي: احسب قيمة x من خلال إسقاط الطول على المحور x كما يلي: 4 * cos( 150 ) = -3.464 احسب قيمة y من خلال إسقاط الطول على المحور y كما يلي: 4 * sin( 150 ) = 2.0 تحقق من الإجابات وفق المخطط البياني (تبدو جيدة). كن حذرًا بشأن استخدام هذه الصيغ وتوقّع الإجابات الصحيحة، خاصةً عند البرمجة بلغة سي أو جافا، إذ يمكن للمكتبات الرياضية الخاصة بلغة البرمجة أن تعطي أشياءً غير متوقعة إن لم تكن حذرًا، ولكن توجد ثلاثة أماكن يجب توخي الحذر فيها بصورة خاصة وهي: من المتوقع أن يكون وسيط sin() و cos() و tan() بالراديان، والقيمة التي تعيدها atan() بالراديان. من المتوقع أن يكون وسيط معظم الدوال الرياضية من النوع double، ولكن إذا استخدمتَ عددًا عشريًا float أو عددًا صحيحًا int، فلن تحصل على رسالة خطأ، بل مجرد إجابة غريبة غير صحيحة. توجد عدة إصدارات من دالة "arc tan" في معظم مكتبات لغة سي، وكلٌ منها مخصَّص لمجال مختلف من قيم الخرج. يُعبَّر عن الزوايا عادةً بالراديان، وتُقاس الزوايا بعكس اتجاه عقارب الساعة ابتداءً من المحور x الموجب (أو تُقاس الزاوية السالبة باتجاه عقارب الساعة ابتداءً من المحور x الموجب أحيانًا)، إذ يوجد ما مقداره 2 pi راديان في الدائرة الكاملة، أي أن: ((2 pi راديان = 360 درجة لنفترض أن لدينا شعاعًا له طول length وزاوية angle! أوجد في هذه الحالة قيمة vector[0] التي تمثل المركّبة x، وأوجد قيمة vector[1] التي تمثّل المركّبة y الخاصة بهذا الشعاع. #include <math.h> double length, angle; /* طول وزاوية الشعاع */ double vector[2]; /* عناصر الشعاع */ . . . length = قيمةٌ ما angle = عددٌ ما بالدرجات vector[0] = ???? vector[1] = ???? لنفترض أن رمز pi هو M_PI، ولكن لسوء الحظ تستخدم المصرّفات Compilers المختلفة رموز PI مختلفة وتعرّفها في ترويسات ملفات مختلفة، لذا يجب أن تستخدم الرمز المناسب لنظام تشغيلك بدلًا من تعريف PI بنفسك. ملاحظة: إذا لم تكن على دراية بلغة سي، فيمكنك عَدّ هذه الشيفرة بأنها مكتوبة بلغة جافا. #include <math.h> double length, angle; double vector[2]; . . . length = قيمةٌ ما angle = عددٌ ما بالدرجات vector[0] = length * cos( angle*M_PI/180.0 ) vector[1] = length * sin( angle*M_PI/180.0 ) تدريب عملي تذكّر أولًا الخطوات التي يجب اتخاذها لتحويل الشعاع المعلوم طوله واتجاهه إلى (x,y): أنشئ مخططًا بيانيًا. احسب قيمة x من خلال إسقاط الطول على المحور x باستخدام length*cos( θ ). احسب قيمة y من خلال إسقاط الطول على المحور y باستخدام length*sin( θ ). 4: تحقق من الإجابات وفق المخطط البياني. وتبقى الخطوات نفسها إذا كانت الزاوية مُعطاةً بالراديان. تدريب 1: ليكن لدينا شعاع طوله 4.5 (بأيّ وحدة طول) وزاوية منحاه 0.70 راديان، ولنعبّر عن هذا الشعاع بالصيغة ( x, y )T كما يلي: أنشئ مخططًا بيانيًا كما يلي: احسب قيمة x من خلال إسقاط الطول على المحور x كما يلي: 4.5*cos( 0.70 ) = 3.442 احسب قيمة y بإسقاط الطول على المحور y كما يلي: 4.5*sin( 0.70 ) = 2.899 تحقق من الإجابات وفق المخطط البياني. تدريب 2: لنفترض أن الدعسوقة ليلى أضاعت صديقتها سلوى، ولكن كان مع ليلى هاتف محمول لحسن الحظ وكان: موقع ليلى عند النقطة (1, -4). موقع سلوى عند النقطة ( -4, 3). اتصل بليلى وأخبرها في أيّ اتجاه وإلى أيّ مسافة يجب أن تمشي للوصول إلى صديقتها سلوى. الحل: الاتجاه = 125.54 درجة، والمسافة = 8.60. كان عليك أن تتذكر كيفية حساب الإزاحة للحصول على الإجابة، إذ يمكنك حساب شعاع الإزاحة بين نقطتين (أو بين الدعسوقتين) كما يلي: (المكان الذي تريد أن تكون فيه) - (مكانك الحالي) = (الإزاحة التي تحتاجها) إذًا الإزاحة التي يجب أن تمشيها ليلى هي: ( -4, 3) - (1, -4) = (-5, 7) ولكن تحتاج ليلى إلى مسافة وجهة هما: المسافة: √(25 + 49) = 8.60 الاتجاه: arc tan( 7/-5 ) = arc tan( -1.4 ) = -54.46 درجة نعدّل الاتجاه بالنظر إلى المخطط البياني ويصبح الاتجاه هو: 180 - 54.46 = 125.54 درجة هل يمكن تطبيق الأفكار المتعلقة بمنحى الشعاع ثنائي الأبعاد الواردة في هذا المقال في الفضاء ثلاثي الأبعاد؟ نعم، ولكن ليس بهذه السهولة، إذ سيتطلب منحى الأشعة ثلاثية الأبعاد مزيدًا من العمل. وصلنا إلى نهاية هذا المقال الذي تعرّفنا فيه على خاصية الاتجاه الخاصة بالشعاع، وسنناقش في المقال التالي حاصل ضرب شعاع وقيمة عددية. ترجمة -وبتصرُّف- للفصل Vector Direction من كتاب Vector Math for 3D Computer Graphics لصاحبه Bradley Kjell. اقرأ أيضًا المقال السابق تعرف على خاصية الطول Length للأشعة الهندسية وكيفية حسابه. المعاملات (parameters) في جافا. الأنواع الحقيقية والصحيحة في لغة سي C. -
 يوضح هذا المقال كيفية تعريف صفحة لحذف كائن المؤلف وتحديث كائن الكتاب للتعرّف على المزيد حول الاستمارات Forms في إطار عمل Express. استمارة حذف مؤلف سنوضح كيفية تعريف صفحة لحذف كائنات المؤلف Author، إذ ستكون استراتيجيتنا -كما ناقشنا في قسم تصميم الاستمارة- هي السماح فقط بحذف الكائنات التي لا تشير إليها كائنات أخرى، وهذا يعني أننا لن نسمح بحذف المؤلف Author إذا أشار إليه كتاب Book، ويعني ذلك من حيث التقديم أن الاستمارة يجب أن تؤكد عدم وجود كتب مرتبطة بالمؤلف قبل حذفه. tإذا كان هناك كتب مرتبطة به، فيجب أن تعرضها وتوضح أنه يجب حذفها قبل حذف كائن المؤلف Author. متحكم وجهة Get افتح الملف /controllers/authorController.js، ثم ابحث عن تابع المتحكم author_delete_get() المُصدَّر وضع مكانه الشيفرة البرمجية التالية: // عرض استمارة حذف مؤلف في طلب GET exports.author_delete_get = asyncHandler(async (req, res, next) => { // الحصول على تفاصيل المؤلف وجميع كتبه على التوازي const [author, allBooksByAuthor] = await Promise.all([ Author.findById(req.params.id).exec(), Book.find({ author: req.params.id }, "title summary").exec(), ]); if (author === null) { // لا توجد نتائج res.redirect("/catalog/authors"); } res.render("author_delete", { title: "Delete Author", author: author, author_books: allBooksByAuthor, }); }); يحصل المتحكم على معرّف نسخة المؤلف Author لحذفه من معامل عنوان URL (وهو req.params.id)، ويستخدم await لانتظار الوعد الذي أعاده التابع Promise.all() للانتظار بطريقة غير متزامنة لسجل المؤلف المُحدَّد وجميع الكتب المرتبطة به على التوازي، ويصيّر العرض author_delete.pug عند اكتمال كلتا العمليتين، مع تمرير متغيرات title و author و author_books. ملاحظة: إن لم يُعِد التابع findById() أيّ نتائج، فلن يكون المؤلف موجودًا في قاعدة البيانات، وبالتالي لا يوجد شيء يمكن حذفه، لذا نعيد التوجيه مباشرةً إلى قائمة جميع المؤلفين. if (author === null) { // لا توجد نتائج res.redirect("/catalog/authors"); } متحكم طلب وجهة Post ابحث عن تابع المتحكم author_delete_post() المُصدَّر وضع مكانه الشيفرة البرمجية التالية: // معالجة حذف مؤلف في طلب POST exports.author_delete_post = asyncHandler(async (req, res, next) => { // الحصول على تفاصيل المؤلف وجميع كتبه على التوازي const [author, allBooksByAuthor] = await Promise.all([ Author.findById(req.params.id).exec(), Book.find({ author: req.params.id }, "title summary").exec(), ]); if (allBooksByAuthor.length > 0) { // المؤلف لديه كتب، لذا اعرض باستخدام طريقة وجهة GET نفسها res.render("author_delete", { title: "Delete Author", author: author, author_books: allBooksByAuthor, }); return; } else { // المؤلف ليس لديه كتب، لذا احذف الكائن وأعِد التوجيه إلى قائمة المؤلفين await Author.findByIdAndRemove(req.body.authorid); res.redirect("/catalog/authors"); } }); نتحقق الكود أولًا من تقديم المعرّف المُرسَل عبر معاملات متن الاستمارة بدلًا من استخدام النسخة الموجودة في عنوان URL، ثم يحصل على المؤلف والكتب المرتبطة به باستخدام طريقة وِجهة GET نفسها. إن لم يكن هناك كتب، فإننا نحذف كائن المؤلف ونعيد التوجيه إلى قائمة جميع المؤلفين، وإذا كان هناك كتب، فسنعيد عرض الاستمارة مع تمرير المؤلف وقائمة الكتب لحذفها. ملاحظة: يمكننا التحقق من أن استدعاء التابع findById() يعيد أيّ نتائج، فإن لم يكن الأمر كذلك، نعرض قائمة جميع المؤلفين مباشرةً. لقد تركنا الشيفرة كما هي موضحة أعلاه للإيجاز، إذ ستظل تعيد قائمة المؤلفين إن لم يُعثَر على المعرّف، ولكن ذلك سيحدث بعد التابع findByIdAndRemove(). العرض View أنشئ العرض /views/author_delete.pug وضع فيه النص التالي: extends layout block content h1 #{title}: #{author.name} p= author.lifespan if author_books.length p #[strong Delete the following books before attempting to delete this author.] div(style='margin-left:20px;margin-top:20px') h4 Books dl each book in author_books dt a(href=book.url) #{book.title} dd #{book.summary} else p Do you really want to delete this Author? form(method='POST' action='') div.form-group input#authorid.form-control(type='hidden',name='authorid', required='true', value=author._id ) button.btn.btn-primary(type='submit') Delete يوسّع هذا العرض قالب التخطيط Layout من خلال تعديل الكتلة content، إذ يعرض تفاصيل المؤلف في أعلى الملف، ثم يتضمن تعليمة شرطية تعتمد على عدد كتب المؤلف author_books (تعليمات if و else) كما يلي: إذا كان هناك كتب مرتبطة بالمؤلف، فستسرد الصفحة الكتب وتشير إلى أنه يجب حذفها قبل حذف هذا المؤلف Author. إن لم يكن هناك كتب، فستعرض الصفحة طلبًا لتأكيد الحذف. إذا نُقِر على زر الحذف Delete، فسيُرسَل معرّف المؤلف إلى الخادم في طلب POST وسيُحذَف سجل المؤلف. إضافة عنصر تحكم الحذف Delete Control سنضيف الآن عنصر تحكم الحذف إلى عرض تفاصيل المؤلف، إذ تُعَد صفحة التفاصيل مكانًا جيدًا لحذف سجل منه. ملاحظة: سيكون عنصر التحكم مرئيًا فقط للمستخدمين المُصرَّح لهم عند التقديم الكامل، ولكن ليس لدينا نظام تصريح حاليًا. افتح العرض author_detail.pug وأضِف الأسطر التالية إلى نهايته: hr p a(href=author.url+'/delete') Delete author يجب أن يظهر عنصر التحكم الآن بوصفه رابطًا في صفحة تفاصيل المؤلف كما يلي: كيف تبدو استمارة حذف المؤلف؟ شغّل التطبيق وافتح متصفحك على العنوان "http://localhost:3000/"، ثم حدّد رابط جميع المؤلفين All authors، واختر مؤلفًا معينًا، ثم حدّد رابط حذف المؤلف Delete author. إن لم يكن لدى المؤلف كتب، فستُعرَض صفحة مثل الصفحة التالية، إذ سيحذف الخادم المؤلف ويعيد التوجيه إلى قائمة المؤلفين بعد الضغط على زر الحذف: إذا كان لدى المؤلف كتب، فسيُقدَّم عرض يشبه ما يلي، ثم يمكنك حذف الكتب من صفحات تفاصيلها (بعد تقديم الشيفرة البرمجية المتعلقة بذلك): ملاحظة: يمكن تقديم الصفحات الأخرى الخاصة بحذف الكائنات باستخدام الطريقة نفسها، لذا تركناها كتحدٍ لك. استمارة تحديث كتاب سنوضح كيفية تعريف صفحة لتحديث كائنات الكتاب Book، إذ تشبه معالجة استمارة تحديث كتاب إلى حدٍ كبير معالجة استمارة إنشاء كتاب، باستثناء أنه يجب عليك ملء الاستمارة في وِجهة GET بقيمٍ من قاعدة البيانات. متحكم وجهة Get افتح الملف "/controllers/bookController.js"، ثم ابحث عن تابع المتحكم book_update_get() المُصدَّر وضع مكانه الشيفرة البرمجية التالية: // عرض استمارة تحديث كتاب في طلب GET exports.book_update_get = asyncHandler(async (req, res, next) => { // الحصول على الكتاب والمؤلفين وأنواع الكتب للاستمارة const [book, allAuthors, allGenres] = await Promise.all([ Book.findById(req.params.id).populate("author").populate("genre").exec(), Author.find().sort({ family_name: 1 }).exec(), Genre.find().sort({ name: 1 }).exec(), ]); if (book === null) { // لا توجد نتائج const err = new Error("Book not found"); err.status = 404; return next(err); } // ميّز أنواع الكتب المختارة بوصفّها مُحدَّدة for (const genre of allGenres) { for (const book_g of book.genre) { if (genre._id.toString() === book_g._id.toString()) { genre.checked = "true"; } } } res.render("book_form", { title: "Update Book", authors: allAuthors, genres: allGenres, book: book, }); }); يحصل المتحكم على معرّف الكتاب Book لتحديثه من معامل عنوان URL (هو req.params.id)، وينتظر (باستخدام await) الوعد الذي أعاده التابع Promise.all() للحصول على سجل الكتاب Book المحدد (مع ملء حقلي نوع الكتاب والمؤلف) وجميع سجلات المؤلف Author ونوع الكتاب Genre. تتحقق الدالة عند اكتمال العمليات من العثور على أيّ كتب، فإن لم يُعثَر على أيٍّ منها، فسترسل خطأ عدم العثور على الكتاب "Book not found" إلى البرمجية الوسيطة لمعالجة الخطأ. ملاحظة: لا يُعَد عدم العثور على أيّ كتاب كنتيجة خطأً في البحث، ولكنه كذلك في هذا التطبيق لأننا نعلم أنه يجب أن يكون هناك سجل كتاب مطابق. تطبّق الشيفرة السابقة اختبار المقارنة (book===null) في دالة رد النداء، ولكن يمكن أن تضيف التابع orFail() إلى السلسلة التعاقبية الخاصة بالاستعلام. نميّز بعد ذلك أنواع الكتب المختارة حاليًا بوصفها مُحدَّدة، ثم نقدّم العرض book_form.pug، ونمرر متغيرات title والكتاب وجميع المؤلفين authors وجميع أنواع الكتب genres. متحكم وجهة Post ابحث عن تابع المتحكم book_update_post() المُصدَّر وضع مكانه الشيفرة البرمجية التالية: // معالجة تحديث كتاب في طلب POST exports.book_update_post = [ // تحويل نوع الكتاب إلى مصفوفة (req, res, next) => { if (!Array.isArray(req.body.genre)) { req.body.genre = typeof req.body.genre === "undefined" ? [] : [req.body.genre]; } next(); }, // التحقق من صحة الحقول وتطهيرها body("title", "Title must not be empty.") .trim() .isLength({ min: 1 }) .escape(), body("author", "Author must not be empty.") .trim() .isLength({ min: 1 }) .escape(), body("summary", "Summary must not be empty.") .trim() .isLength({ min: 1 }) .escape(), body("isbn", "ISBN must not be empty").trim().isLength({ min: 1 }).escape(), body("genre.*").escape(), // طلب العملية بعد التحقق من صحة البيانات وتطهيرها asyncHandler(async (req, res, next) => { // استخراج أخطاء التحقق من صحة البيانات من الطلب const errors = validationResult(req); // إنشاء كائن كتاب مع بيانات مُهرَّبة أو محذوف منها المسافات والمعرّف القديم const book = new Book({ title: req.body.title, author: req.body.author, summary: req.body.summary, isbn: req.body.isbn, genre: typeof req.body.genre === "undefined" ? [] : req.body.genre, _id: req.params.id, // هذا مطلوب، أو سيجري إسناد معرّف جديد }); if (!errors.isEmpty()) { // توجد أخطاء، لذا اعرض الاستمارة مرة أخرى مع قيم مُطهَّرة أو رسائل خطأ // الحصول على جميع المؤلفين وأنواع الكتب للاستمارة const [allAuthors, allGenres] = await Promise.all([ Author.find().exec(), Genre.find().exec(), ]); // ميّز أنواع الكتب المختارة بوصفها مُحدَّدة for (const genre of allGenres) { if (book.genre.indexOf(genre._id) > -1) { genre.checked = "true"; } } res.render("book_form", { title: "Update Book", authors: allAuthors, genres: allGenres, book: book, errors: errors.array(), }); return; } else { // البيانات الواردة من الاستمارة صالحة، لذا حدّث السجل const thebook = await Book.findByIdAndUpdate(req.params.id, book, {}); // أعِد التوجيه إلى صفحة تفاصيل الكتاب res.redirect(thebook.url); } }), ]; تُعَد هذه الشيفرة البرمجية مشابهة جدًا لشيفرة وِجهة Post التي استخدمناها لإنشاء كتاب Book، إذ نتحقق أولًا من صحة بيانات الكتاب القادمة من الاستمارة ونطهرها ونستخدمها لإنشاء كائن كتاب Book جديد مع ضبط قيمة _id الخاصة به على معرّف الكائن المُراد تحديثه. إذا كان هناك أخطاء عند التحقق من صحة البيانات، فسنعيد تصيير الاستمارة، بالإضافة إلى عرض البيانات التي أدخلها المستخدم والأخطاء وقوائم أنواع الكتب والمؤلفين. إذا لم يكن هناك أخطاء، فسنستدعي التابع Book.findByIdAndUpdate() لتحديث مستند الكتاب Book، ثم نعيد التوجيه إلى صفحة تفاصيله. العرض View ليست هناك حاجة لتغيير عرض الاستمارة (/views/book_form.pug)، إذ يناسب هذا القالب إنشاء الكتاب وتحديثه. إضافة زر تحديث افتح العرض book_detail.pug وتأكّد من وجود روابط لكل من حذف وتحديث الكتب أسفل الصفحة كما يلي: hr p a(href=book.url+'/delete') Delete Book p a(href=book.url+'/update') Update Book يجب أن تكون قادرًا الآن على تحديث الكتب من صفحة تفاصيل الكتاب. كيف تبدو استمارة تحديث الكتاب؟ شغّل التطبيق، وافتح متصفحك على العنوان "http://localhost:3000/"، ثم حدّد رابط جميع الكتب All books، واختر كتابًا معينًا، ثم حدّد رابط تحديث الكتاب Update Book. يجب أن تبدو الاستمارة تمامًا مثل صفحة إنشاء كتاب Create book، ولكن مع العنوان "Update book"، وتكون الاستمارة مملوءة مسبقًا بقيم السجل. ملاحظة: يمكن تقديم الصفحات الأخرى الخاصة بتحديث الكائنات باستخدام الطريقة نفسها، لذا تركناها كتحدٍ لك. ترجمة -وبتصرُّف- للمقالين Delete Author form و Update Book form. اقرأ المزيد المقال السابق إنشاء مكتبة محلية باستخدام Express: إضافة الكتب والمؤلفين. مدخل إلى إطار عمل الويب Express وبيئة Node.js إعداد بيئة تطوير Node مع Express توثيق Node.js باللغة العربية إطار عمل Express
يوضح هذا المقال كيفية تعريف صفحة لحذف كائن المؤلف وتحديث كائن الكتاب للتعرّف على المزيد حول الاستمارات Forms في إطار عمل Express. استمارة حذف مؤلف سنوضح كيفية تعريف صفحة لحذف كائنات المؤلف Author، إذ ستكون استراتيجيتنا -كما ناقشنا في قسم تصميم الاستمارة- هي السماح فقط بحذف الكائنات التي لا تشير إليها كائنات أخرى، وهذا يعني أننا لن نسمح بحذف المؤلف Author إذا أشار إليه كتاب Book، ويعني ذلك من حيث التقديم أن الاستمارة يجب أن تؤكد عدم وجود كتب مرتبطة بالمؤلف قبل حذفه. tإذا كان هناك كتب مرتبطة به، فيجب أن تعرضها وتوضح أنه يجب حذفها قبل حذف كائن المؤلف Author. متحكم وجهة Get افتح الملف /controllers/authorController.js، ثم ابحث عن تابع المتحكم author_delete_get() المُصدَّر وضع مكانه الشيفرة البرمجية التالية: // عرض استمارة حذف مؤلف في طلب GET exports.author_delete_get = asyncHandler(async (req, res, next) => { // الحصول على تفاصيل المؤلف وجميع كتبه على التوازي const [author, allBooksByAuthor] = await Promise.all([ Author.findById(req.params.id).exec(), Book.find({ author: req.params.id }, "title summary").exec(), ]); if (author === null) { // لا توجد نتائج res.redirect("/catalog/authors"); } res.render("author_delete", { title: "Delete Author", author: author, author_books: allBooksByAuthor, }); }); يحصل المتحكم على معرّف نسخة المؤلف Author لحذفه من معامل عنوان URL (وهو req.params.id)، ويستخدم await لانتظار الوعد الذي أعاده التابع Promise.all() للانتظار بطريقة غير متزامنة لسجل المؤلف المُحدَّد وجميع الكتب المرتبطة به على التوازي، ويصيّر العرض author_delete.pug عند اكتمال كلتا العمليتين، مع تمرير متغيرات title و author و author_books. ملاحظة: إن لم يُعِد التابع findById() أيّ نتائج، فلن يكون المؤلف موجودًا في قاعدة البيانات، وبالتالي لا يوجد شيء يمكن حذفه، لذا نعيد التوجيه مباشرةً إلى قائمة جميع المؤلفين. if (author === null) { // لا توجد نتائج res.redirect("/catalog/authors"); } متحكم طلب وجهة Post ابحث عن تابع المتحكم author_delete_post() المُصدَّر وضع مكانه الشيفرة البرمجية التالية: // معالجة حذف مؤلف في طلب POST exports.author_delete_post = asyncHandler(async (req, res, next) => { // الحصول على تفاصيل المؤلف وجميع كتبه على التوازي const [author, allBooksByAuthor] = await Promise.all([ Author.findById(req.params.id).exec(), Book.find({ author: req.params.id }, "title summary").exec(), ]); if (allBooksByAuthor.length > 0) { // المؤلف لديه كتب، لذا اعرض باستخدام طريقة وجهة GET نفسها res.render("author_delete", { title: "Delete Author", author: author, author_books: allBooksByAuthor, }); return; } else { // المؤلف ليس لديه كتب، لذا احذف الكائن وأعِد التوجيه إلى قائمة المؤلفين await Author.findByIdAndRemove(req.body.authorid); res.redirect("/catalog/authors"); } }); نتحقق الكود أولًا من تقديم المعرّف المُرسَل عبر معاملات متن الاستمارة بدلًا من استخدام النسخة الموجودة في عنوان URL، ثم يحصل على المؤلف والكتب المرتبطة به باستخدام طريقة وِجهة GET نفسها. إن لم يكن هناك كتب، فإننا نحذف كائن المؤلف ونعيد التوجيه إلى قائمة جميع المؤلفين، وإذا كان هناك كتب، فسنعيد عرض الاستمارة مع تمرير المؤلف وقائمة الكتب لحذفها. ملاحظة: يمكننا التحقق من أن استدعاء التابع findById() يعيد أيّ نتائج، فإن لم يكن الأمر كذلك، نعرض قائمة جميع المؤلفين مباشرةً. لقد تركنا الشيفرة كما هي موضحة أعلاه للإيجاز، إذ ستظل تعيد قائمة المؤلفين إن لم يُعثَر على المعرّف، ولكن ذلك سيحدث بعد التابع findByIdAndRemove(). العرض View أنشئ العرض /views/author_delete.pug وضع فيه النص التالي: extends layout block content h1 #{title}: #{author.name} p= author.lifespan if author_books.length p #[strong Delete the following books before attempting to delete this author.] div(style='margin-left:20px;margin-top:20px') h4 Books dl each book in author_books dt a(href=book.url) #{book.title} dd #{book.summary} else p Do you really want to delete this Author? form(method='POST' action='') div.form-group input#authorid.form-control(type='hidden',name='authorid', required='true', value=author._id ) button.btn.btn-primary(type='submit') Delete يوسّع هذا العرض قالب التخطيط Layout من خلال تعديل الكتلة content، إذ يعرض تفاصيل المؤلف في أعلى الملف، ثم يتضمن تعليمة شرطية تعتمد على عدد كتب المؤلف author_books (تعليمات if و else) كما يلي: إذا كان هناك كتب مرتبطة بالمؤلف، فستسرد الصفحة الكتب وتشير إلى أنه يجب حذفها قبل حذف هذا المؤلف Author. إن لم يكن هناك كتب، فستعرض الصفحة طلبًا لتأكيد الحذف. إذا نُقِر على زر الحذف Delete، فسيُرسَل معرّف المؤلف إلى الخادم في طلب POST وسيُحذَف سجل المؤلف. إضافة عنصر تحكم الحذف Delete Control سنضيف الآن عنصر تحكم الحذف إلى عرض تفاصيل المؤلف، إذ تُعَد صفحة التفاصيل مكانًا جيدًا لحذف سجل منه. ملاحظة: سيكون عنصر التحكم مرئيًا فقط للمستخدمين المُصرَّح لهم عند التقديم الكامل، ولكن ليس لدينا نظام تصريح حاليًا. افتح العرض author_detail.pug وأضِف الأسطر التالية إلى نهايته: hr p a(href=author.url+'/delete') Delete author يجب أن يظهر عنصر التحكم الآن بوصفه رابطًا في صفحة تفاصيل المؤلف كما يلي: كيف تبدو استمارة حذف المؤلف؟ شغّل التطبيق وافتح متصفحك على العنوان "http://localhost:3000/"، ثم حدّد رابط جميع المؤلفين All authors، واختر مؤلفًا معينًا، ثم حدّد رابط حذف المؤلف Delete author. إن لم يكن لدى المؤلف كتب، فستُعرَض صفحة مثل الصفحة التالية، إذ سيحذف الخادم المؤلف ويعيد التوجيه إلى قائمة المؤلفين بعد الضغط على زر الحذف: إذا كان لدى المؤلف كتب، فسيُقدَّم عرض يشبه ما يلي، ثم يمكنك حذف الكتب من صفحات تفاصيلها (بعد تقديم الشيفرة البرمجية المتعلقة بذلك): ملاحظة: يمكن تقديم الصفحات الأخرى الخاصة بحذف الكائنات باستخدام الطريقة نفسها، لذا تركناها كتحدٍ لك. استمارة تحديث كتاب سنوضح كيفية تعريف صفحة لتحديث كائنات الكتاب Book، إذ تشبه معالجة استمارة تحديث كتاب إلى حدٍ كبير معالجة استمارة إنشاء كتاب، باستثناء أنه يجب عليك ملء الاستمارة في وِجهة GET بقيمٍ من قاعدة البيانات. متحكم وجهة Get افتح الملف "/controllers/bookController.js"، ثم ابحث عن تابع المتحكم book_update_get() المُصدَّر وضع مكانه الشيفرة البرمجية التالية: // عرض استمارة تحديث كتاب في طلب GET exports.book_update_get = asyncHandler(async (req, res, next) => { // الحصول على الكتاب والمؤلفين وأنواع الكتب للاستمارة const [book, allAuthors, allGenres] = await Promise.all([ Book.findById(req.params.id).populate("author").populate("genre").exec(), Author.find().sort({ family_name: 1 }).exec(), Genre.find().sort({ name: 1 }).exec(), ]); if (book === null) { // لا توجد نتائج const err = new Error("Book not found"); err.status = 404; return next(err); } // ميّز أنواع الكتب المختارة بوصفّها مُحدَّدة for (const genre of allGenres) { for (const book_g of book.genre) { if (genre._id.toString() === book_g._id.toString()) { genre.checked = "true"; } } } res.render("book_form", { title: "Update Book", authors: allAuthors, genres: allGenres, book: book, }); }); يحصل المتحكم على معرّف الكتاب Book لتحديثه من معامل عنوان URL (هو req.params.id)، وينتظر (باستخدام await) الوعد الذي أعاده التابع Promise.all() للحصول على سجل الكتاب Book المحدد (مع ملء حقلي نوع الكتاب والمؤلف) وجميع سجلات المؤلف Author ونوع الكتاب Genre. تتحقق الدالة عند اكتمال العمليات من العثور على أيّ كتب، فإن لم يُعثَر على أيٍّ منها، فسترسل خطأ عدم العثور على الكتاب "Book not found" إلى البرمجية الوسيطة لمعالجة الخطأ. ملاحظة: لا يُعَد عدم العثور على أيّ كتاب كنتيجة خطأً في البحث، ولكنه كذلك في هذا التطبيق لأننا نعلم أنه يجب أن يكون هناك سجل كتاب مطابق. تطبّق الشيفرة السابقة اختبار المقارنة (book===null) في دالة رد النداء، ولكن يمكن أن تضيف التابع orFail() إلى السلسلة التعاقبية الخاصة بالاستعلام. نميّز بعد ذلك أنواع الكتب المختارة حاليًا بوصفها مُحدَّدة، ثم نقدّم العرض book_form.pug، ونمرر متغيرات title والكتاب وجميع المؤلفين authors وجميع أنواع الكتب genres. متحكم وجهة Post ابحث عن تابع المتحكم book_update_post() المُصدَّر وضع مكانه الشيفرة البرمجية التالية: // معالجة تحديث كتاب في طلب POST exports.book_update_post = [ // تحويل نوع الكتاب إلى مصفوفة (req, res, next) => { if (!Array.isArray(req.body.genre)) { req.body.genre = typeof req.body.genre === "undefined" ? [] : [req.body.genre]; } next(); }, // التحقق من صحة الحقول وتطهيرها body("title", "Title must not be empty.") .trim() .isLength({ min: 1 }) .escape(), body("author", "Author must not be empty.") .trim() .isLength({ min: 1 }) .escape(), body("summary", "Summary must not be empty.") .trim() .isLength({ min: 1 }) .escape(), body("isbn", "ISBN must not be empty").trim().isLength({ min: 1 }).escape(), body("genre.*").escape(), // طلب العملية بعد التحقق من صحة البيانات وتطهيرها asyncHandler(async (req, res, next) => { // استخراج أخطاء التحقق من صحة البيانات من الطلب const errors = validationResult(req); // إنشاء كائن كتاب مع بيانات مُهرَّبة أو محذوف منها المسافات والمعرّف القديم const book = new Book({ title: req.body.title, author: req.body.author, summary: req.body.summary, isbn: req.body.isbn, genre: typeof req.body.genre === "undefined" ? [] : req.body.genre, _id: req.params.id, // هذا مطلوب، أو سيجري إسناد معرّف جديد }); if (!errors.isEmpty()) { // توجد أخطاء، لذا اعرض الاستمارة مرة أخرى مع قيم مُطهَّرة أو رسائل خطأ // الحصول على جميع المؤلفين وأنواع الكتب للاستمارة const [allAuthors, allGenres] = await Promise.all([ Author.find().exec(), Genre.find().exec(), ]); // ميّز أنواع الكتب المختارة بوصفها مُحدَّدة for (const genre of allGenres) { if (book.genre.indexOf(genre._id) > -1) { genre.checked = "true"; } } res.render("book_form", { title: "Update Book", authors: allAuthors, genres: allGenres, book: book, errors: errors.array(), }); return; } else { // البيانات الواردة من الاستمارة صالحة، لذا حدّث السجل const thebook = await Book.findByIdAndUpdate(req.params.id, book, {}); // أعِد التوجيه إلى صفحة تفاصيل الكتاب res.redirect(thebook.url); } }), ]; تُعَد هذه الشيفرة البرمجية مشابهة جدًا لشيفرة وِجهة Post التي استخدمناها لإنشاء كتاب Book، إذ نتحقق أولًا من صحة بيانات الكتاب القادمة من الاستمارة ونطهرها ونستخدمها لإنشاء كائن كتاب Book جديد مع ضبط قيمة _id الخاصة به على معرّف الكائن المُراد تحديثه. إذا كان هناك أخطاء عند التحقق من صحة البيانات، فسنعيد تصيير الاستمارة، بالإضافة إلى عرض البيانات التي أدخلها المستخدم والأخطاء وقوائم أنواع الكتب والمؤلفين. إذا لم يكن هناك أخطاء، فسنستدعي التابع Book.findByIdAndUpdate() لتحديث مستند الكتاب Book، ثم نعيد التوجيه إلى صفحة تفاصيله. العرض View ليست هناك حاجة لتغيير عرض الاستمارة (/views/book_form.pug)، إذ يناسب هذا القالب إنشاء الكتاب وتحديثه. إضافة زر تحديث افتح العرض book_detail.pug وتأكّد من وجود روابط لكل من حذف وتحديث الكتب أسفل الصفحة كما يلي: hr p a(href=book.url+'/delete') Delete Book p a(href=book.url+'/update') Update Book يجب أن تكون قادرًا الآن على تحديث الكتب من صفحة تفاصيل الكتاب. كيف تبدو استمارة تحديث الكتاب؟ شغّل التطبيق، وافتح متصفحك على العنوان "http://localhost:3000/"، ثم حدّد رابط جميع الكتب All books، واختر كتابًا معينًا، ثم حدّد رابط تحديث الكتاب Update Book. يجب أن تبدو الاستمارة تمامًا مثل صفحة إنشاء كتاب Create book، ولكن مع العنوان "Update book"، وتكون الاستمارة مملوءة مسبقًا بقيم السجل. ملاحظة: يمكن تقديم الصفحات الأخرى الخاصة بتحديث الكائنات باستخدام الطريقة نفسها، لذا تركناها كتحدٍ لك. ترجمة -وبتصرُّف- للمقالين Delete Author form و Update Book form. اقرأ المزيد المقال السابق إنشاء مكتبة محلية باستخدام Express: إضافة الكتب والمؤلفين. مدخل إلى إطار عمل الويب Express وبيئة Node.js إعداد بيئة تطوير Node مع Express توثيق Node.js باللغة العربية إطار عمل Express -
 يوضح هذا المقال كيفية تعريف صفحات لإنشاء كائنات المؤلف والكتاب ونسخ الكتب للتعرّف أكثر على كيفية التعامل مع الاستمارات forms في إطار عمل Express. استمارة إنشاء مؤلف سنوضّح فيما يلي كيفية تعريف صفحة لإنشاء كائنات المؤلف Author. استيراد توابع التحقق من صحة البيانات Validation وتطهيرها Sanitization يجب طلب الدوال التي نريدها لاستخدام express-validator كما هو الحال في استمارة نوع الكتاب. افتح الملف "/controllers/authorController.js"، وأضِف السطر التالي في بداية الملف قبل دوال الوِجهة Route: const { body, validationResult } = require("express-validator"); متحكم وجهة Get ابحث عن تابع المتحكم author_create_get() المُصدَّر وضع مكانه الشيفرة البرمجية التالية التي تؤدي إلى تقديم العرض author_form.pug وتمرير متغير العنوان title: // عرض استمارة إنشاء مؤلف في طلب GET exports.author_create_get = (req, res, next) => { res.render("author_form", { title: "Create Author" }); }; متحكم وجهة Post ابحث عن تابع المتحكم author_create_post() المُصدَّر وضع مكانه الشيفرة البرمجية التالية: // معالجة إنشاء مؤلف Author في طلب POST exports.author_create_post = [ // التحقق من صحة الحقول وتطهيرها body("first_name") .trim() .isLength({ min: 1 }) .escape() .withMessage("First name must be specified.") .isAlphanumeric() .withMessage("First name has non-alphanumeric characters."), body("family_name") .trim() .isLength({ min: 1 }) .escape() .withMessage("Family name must be specified.") .isAlphanumeric() .withMessage("Family name has non-alphanumeric characters."), body("date_of_birth", "Invalid date of birth") .optional({ values: "falsy" }) .isISO8601() .toDate(), body("date_of_death", "Invalid date of death") .optional({ values: "falsy" }) .isISO8601() .toDate(), // طلب العملية بعد التحقق من صحة البيانات وتطهيرها asyncHandler(async (req, res, next) => { // استخراج أخطاء التحقق من صحة البيانات من الطلب const errors = validationResult(req); // إنشاء كائن مؤلف مع بيانات مُهرَّبة ومحذوف منها المسافات const author = new Author({ first_name: req.body.first_name, family_name: req.body.family_name, date_of_birth: req.body.date_of_birth, date_of_death: req.body.date_of_death, }); if (!errors.isEmpty()) { // توجد أخطاء، لذا اعرض الاستمارة مرة أخرى مع قيم مُطهَّرة أو رسائل خطأ res.render("author_form", { title: "Create Author", author: author, errors: errors.array(), }); return; } else { // البيانات الواردة من الاستمارة صالحة // احفظ المؤلف await author.save(); // أعِد التوجيه إلى سجل مؤلف جديد res.redirect(author.url); } }), ]; تحذير: لا تتحقق من صحة الأسماء باستخدام isAlphanumeric() كما فعلنا، نظرًا لوجود العديد من الأسماء التي تستخدم مجموعات محارف أخرى، ولكننا فعلنا ذلك لشرح كيفية استخدام أداة التحقق من صحة البيانات Validator، وكيفية ربطها بسلسلة تعاقبية مع أدوات التحقق الأخرى والإبلاغ عن الأخطاء. تماثل بنية وسلوك هذه الشيفرة البرمجية تقريبًا شيفرة إنشاء كائن نوع الكتاب Genre، إذ نتحقق أولًا من صحة البيانات ونطهرها، فإذا كانت البيانات غير صالحة سنعيد عرض الاستمارة مع البيانات التي أدخلها المستخدم في الأصل وقائمة برسائل الخطأ. وإذا كانت البيانات صالحة، سنحفظ سجل المؤلف الجديد ونعيد توجيه المستخدم إلى صفحة تفاصيل المؤلف. لا نتحقق مما إذا كان كائن المؤلف Author موجودًا مسبقًا قبل حفظه، وهذا يختلف عن معالج طلب Genre من النوع Post، إذ يمكننا ذلك بالرغم من أنه يمكن أن يكون لدينا عدة مؤلفين بالاسم نفسه. توضح شيفرة التحقق من صحة البيانات العديد من الميزات الجديدة التالية: أولًا، يمكننا إنشاء سلسلة تعاقبية من أدوات التحقق باستخدام withMessage() لتحديد رسالة الخطأ التي ستُعرَض في حالة فشل تابع التحقق السابق، مما يسهّل تقديم رسائل خطأ محددة دون الكثير من الشيفرة البرمجية المكررة. [ // التحقق من صحة الحقول وتطهيرها body("first_name") .trim() .isLength({ min: 1 }) .escape() .withMessage("First name must be specified.") .isAlphanumeric() .withMessage("First name has non-alphanumeric characters."), // … ]; ثانيًا، يمكننا استخدام الدالة optional() لإجراء عملية تحقق لاحقة فقط في حالة الإدخال في حقلٍ ما، مما يسمح بالتحقق من صحة الحقول الاختيارية، فمثلًا نتحقق فيما يلي من أن تاريخ الميلاد الاختياري هو تاريخ متوافق مع معيار ISO8601، إذ يعني تمرير كائن {values: "falsy"} أننا سنقبل إما سلسلة نصية فارغة أو null للقيمة الفارغة. [ body("date_of_birth", "Invalid date of birth") .optional({ values: "falsy" }) .isISO8601() .toDate(), ]; ثالثًا، تُستلَم المعاملات من الطلب بوصفها سلاسلًا نصية، ويمكننا استخدام toDate() أو toBoolean() لتغيير هذه الأنواع إلى أنواع جافا سكريبت المناسبة كما هو موضح في نهاية سلسلة أدوات التحقق سابقًا. العرض View أنشئ العرض "/views/author_form.pug" وضع فيه النص التالي: extends layout block content h1=title form(method='POST' action='') div.form-group label(for='first_name') First Name: input#first_name.form-control(type='text' placeholder='First name' name='first_name' required='true' value=(undefined===author ? '' : author.first_name) ) label(for='family_name') Family Name: input#family_name.form-control(type='text' placeholder='Family name' name='family_name' required='true' value=(undefined===author ? '' : author.family_name)) div.form-group label(for='date_of_birth') Date of birth: input#date_of_birth.form-control(type='date' name='date_of_birth' value=(undefined===author ? '' : author.date_of_birth) ) button.btn.btn-primary(type='submit') Submit if errors ul for error in errors li!= error.msg تماثل بنية وسلوك هذا العرض ما هو موجود في قالب genre_form.pug، لذلك لن نشرحه مرةً أخرى. ملاحظة: لا تدعم بعض المتصفحات حقل الإدخال type="date"، لذلك لن تحصل على عنصر واجهة مستخدم منتقي التاريخ أو العنصر البديل الافتراضي dd/mm/yyyy، ولكن ستحصل بدلًا من ذلك على حقل نص عادي فارغ. يتمثل أحد الحلول في إضافة السمة placeholder='dd/mm/yyyy' صراحةً، بحيث تظل تحصل على معلومات حول تنسيق النص المطلوب في المتصفحات ذات القدرات الأقل. التحدي: إضافة تاريخ الوفاة يفتقد هذا القالب حقلًا لإدخال تاريخ الوفاة date_of_death، لذا أنشئ هذا الحقل باتباع النمط نفسه لمجموعة استمارة تاريخ الميلاد. كيف تبدو استمارة المؤلف؟ شغّل التطبيق، وافتح متصفحك على العنوان "http://localhost:3000/"، ثم حدّد رابط إنشاء مؤلف جديد Create new author. إذا جرى إعداد كل شيء بصورة صحيحة، فيجب أن يبدو موقعك كما يلي، ويجب حفظ القيمة بعد إدخالها وستُنقَل إلى صفحة تفاصيل المؤلف. ملاحظة: إذا جرّبتَ تنسيقات إدخال مختلفة للتواريخ، فقد تجد أن التنسيق yyyy-mm-dd لا يتصرف بصورة صحيحة، لأن جافا سكريبت تتعامل مع سلاسل التاريخ بأنها تتضمن وقت 0 ساعة، ولكنها تتعامل أيضًا مع سلاسل التاريخ بهذا التنسيق (معيار ISO 8601) بوصفها تتضمن الوقت 0 ساعة بالتوقيت العالمي المنسَّق UTC بدلًا من التوقيت المحلي. إذا وقعت منطقتك الزمنية غرب توقيت UTC، فسيكون عرض التاريخ -لكونه محليًا- قبل يوم واحد من التاريخ الذي أدخلته، وهذه إحدى التعقيدات العديدة، مثل أسماء العائلات متعددة الكلمات والكتب متعددة المؤلفين التي لم نعالجها. استمارة إنشاء كتاب سنوضح كيفية تعريف صفحة أو استمارة لإنشاء كائنات الكتاب Book، ويُعَد ذلك أكثر تعقيدًا قليلًا من صفحات المؤلف Author أو نوع الكتاب Genre المكافئة لها، لأننا نحتاج إلى الحصول على سجلات المؤلف Author ونوع الكتاب Genre المتوفرة وعرضها في استمارة الكتاب Book. استيراد توابع التحقق من صحة البيانات وتطهيرها افتح الملف /controllers/bookController.js، وأضِف السطر التالي في بداية الملف قبل دوال الوِجهة Route: const { body, validationResult } = require("express-validator"); متحكم وجهة Get ابحث عن تابع المتحكم book_create_get() المُصدَّر وضع مكانه الشيفرة البرمجية التالية: // عرض استمارة إنشاء كتاب في طلب GET exports.book_create_get = asyncHandler(async (req, res, next) => { // الحصول على جميع المؤلفين وأنواع الكتب التي يمكننا استخدامها للإضافة إلى الكتاب const [allAuthors, allGenres] = await Promise.all([ Author.find().sort({ family_name: 1 }).exec(), Genre.find().sort({ name: 1 }).exec(), ]); res.render("book_form", { title: "Create Book", authors: allAuthors, genres: allGenres, }); }); نستخدم await لانتظار نتيجة التابع Promise.all() للحصول على جميع كائنات المؤلف Author ونوع الكتاب Genre على التوازي، وهو الأسلوب نفسه الذي استخدمناه عند عرض بيانات المكتبة، ثم تُمرَّر إلى العرض book_form.pug بوصفها متغيرات بالاسم authors و genres مع عنوان title الصفحة. متحكم وجهة Post ابحث عن تابع المتحكم book_create_post() المُصدَّر وضع مكانه الشيفرة البرمجية التالية: // معالجة إنشاء كتاب في طلب POST exports.book_create_post = [ // تحويل نوع الكتاب إلى مصفوفة (req, res, next) => { if (!Array.isArray(req.body.genre)) { req.body.genre = typeof req.body.genre === "undefined" ? [] : [req.body.genre]; } next(); }, // التحقق من صحة الحقول وتطهيرها body("title", "Title must not be empty.") .trim() .isLength({ min: 1 }) .escape(), body("author", "Author must not be empty.") .trim() .isLength({ min: 1 }) .escape(), body("summary", "Summary must not be empty.") .trim() .isLength({ min: 1 }) .escape(), body("isbn", "ISBN must not be empty").trim().isLength({ min: 1 }).escape(), body("genre.*").escape(), // طلب العملية بعد التحقق من صحة البيانات وتطهيرها asyncHandler(async (req, res, next) => { // استخراج أخطاء التحقق من صحة البيانات من الطلب const errors = validationResult(req); // إنشاء كائن كتاب مع بيانات مُهرَّبة ومحذوف منها المسافات const book = new Book({ title: req.body.title, author: req.body.author, summary: req.body.summary, isbn: req.body.isbn, genre: req.body.genre, }); if (!errors.isEmpty()) { // توجد أخطاء، لذا اعرض الاستمارة مرة أخرى مع قيم مُطهَّرة أو رسائل خطأ // احصل على جميع المؤلفين وأنواع الكتب للاستمارة const [allAuthors, allGenres] = await Promise.all([ Author.find().sort({ family_name: 1 }).exec(), Genre.find().sort({ name: 1 }).exec(), ]); // ميّز أنواع الكتب المختارة بوصفها محددة for (const genre of allGenres) { if (book.genre.includes(genre._id)) { genre.checked = "true"; } } res.render("book_form", { title: "Create Book", authors: allAuthors, genres: allGenres, book: book, errors: errors.array(), }); } else { // البيانات الواردة من الاستمارة صالحة، لذا احفظ الكتاب await book.save(); res.redirect(book.url); } }), ]; تماثل بنية وسلوك هذه الشيفرة البرمجية تقريبًا دوال وجهة Post لاستمارات النوع Genre والكاتب Author، إذ نتحقق أولًا من صحة البيانات ونطهّرها؛ فإذا كانت البيانات غير صالحة، فسنعيد عرض الاستمارة مع البيانات التي أدخلها المستخدم في الأصل وقائمة برسائل الخطأ؛ وإذا كانت البيانات صالحة، فسنحفظ سجل الكتاب Book الجديد ونعيد توجيه المستخدم إلى صفحة تفاصيل الكتاب. يتمثل الاختلاف الرئيسي فيما يتعلق بشيفرة معالجة الاستمارة الأخرى في كيفية تطهير معلومات نوع الكتاب، إذ تعيد الاستمارة مصفوفةً من عناصر Genre، بينما تعيد سلسلة نصية بالنسبة للحقول الأخرى. نحوّل أولًا الطلب إلى مصفوفة (مطلوبة للخطوة التالية) للتحقق من صحة المعلومات. [ // تحويل نوع الكتاب إلى مصفوفة (req, res, next) => { if (!Array.isArray(req.body.genre)) { req.body.genre = typeof req.body.genre === "undefined" ? [] : [req.body.genre]; } next(); }, // … ]; نستخدم بعد ذلك محرف بدل (*) في أداة التطهير للتحقق من صحة كل إدخال من مصفوفة أنواع الكتاب بصورة فردية، إذ توضح الشيفرة التالية كيفية ترجمة ذلك إلى "تطهير كل عنصر له المفتاح genre". [ // … body("genre.*").escape(), // … ]; الاختلاف الأخير فيما يتعلق بشيفرة معالجة الاستمارة الأخرى هو أنه نحتاج إلى تمرير جميع أنواع الكتب والمؤلفين الموجودين إلى الاستمارة. نكرر عبر جميع أنواع الكتب ونضيف المعامل checked="true" إلى تلك الأنواع التي كانت موجودة في بيانات Post (كما أعدنا الإنتاج في جزء الشيفرة التالي) لتمييز أنواع الكتب التي حدّدها المستخدم. // تمييز أنواع الكتب المختارة بوصفها مُحدَّدة for (const genre of results.genres) { if (book.genre.includes(genre._id)) { // اختير نوع الكتاب الحالي، لذا اضبط الراية "checked" genre.checked = "true"; } } العرض أنشئ العرض "/views/book_form.pug" وضع فيه النص التالي: extends layout block content h1= title form(method='POST' action='') div.form-group label(for='title') Title: input#title.form-control(type='text', placeholder='Name of book' name='title' required='true' value=(undefined===book ? '' : book.title) ) div.form-group label(for='author') Author: select#author.form-control(type='select', placeholder='Select author' name='author' required='true' ) for author in authors if book option(value=author._id selected=(author._id.toString()===book.author._id.toString() ? 'selected' : false) ) #{author.name} else option(value=author._id) #{author.name} div.form-group label(for='summary') Summary: textarea#summary.form-control(type='textarea', placeholder='Summary' name='summary' required='true') #{undefined===book ? '' : book.summary} div.form-group label(for='isbn') ISBN: input#isbn.form-control(type='text', placeholder='ISBN13' name='isbn' value=(undefined===book ? '' : book.isbn) required='true') div.form-group label Genre: div for genre in genres div(style='display: inline; padding-right:10px;') input.checkbox-input(type='checkbox', name='genre', id=genre._id, value=genre._id, checked=genre.checked ) label(for=genre._id) #{genre.name} button.btn.btn-primary(type='submit') Submit if errors ul for error in errors li!= error.msg تماثل بنية وسلوك هذا العرض تقريبًا بنية وسلوك القالب genre_form.pug، ولكن تكمن الاختلافات الرئيسية في كيفية تقديم حقول نوع الاختيار: Author و Genre، إذ: تُعرَض مجموعة أنواع الكتب بوصفها مربعات اختيار، وتستخدم قيمة checked التي ضبطناها في المتحكم لتحديد ما إذا كان يجب تحديد المربع أم لا. تُعرَض مجموعة المؤلفين بوصفها قائمة منسدلة مع اختيار فردي مرتبة أبجديًا، فإذا حدّد المستخدم مسبقًا مؤلف كتابٍ ما عند إصلاح قيم الحقول غير الصالحة بعد إرسال الاستمارة الأولية أو عند تحديث تفاصيل الكتاب مثلًا، فسيُعاد اختيار المؤلف عند عرض الاستمارة. نحدد في هذه الحالة المؤلف المراد اختياره من خلال موازنة معرّف خيار المؤلف الحالي مع القيمة التي أدخلها المستخدم مسبقًا والمُمرَّرة عبر المتغير book. ملاحظة: إذا كان هناك خطأ في الاستمارة المُرسَلة، فسيكون معرّف مؤلف الكتاب الجديد ومعرّفات مؤلفي الكتب الموجودين مسبقًا من النوع Schema.Types.ObjectId عند إعادة تصيير الاستمارة، لذا يجب تحويلها إلى سلاسل نصية أولًا للموازنة بينها. كيف تبدو استمارة إنشاء كتاب؟ شغّل التطبيق، وافتح متصفحك على العنوان "http://localhost:3000/"، ثم حدد رابط إنشاء كتاب جديد Create new book. إذا جرى إعداد كل شيء بصورة صحيحة، فيجب أن يبدو موقعك كما يلي، ويجب حفظ الكتاب بعد إرسال كتاب صالح وستُنقَل إلى صفحة تفاصيل الكتاب: استمارة إنشاء نسخة كتاب BookInstance سنوضح فيما يلي كيفية تعريف صفحة أو استمارة لإنشاء كائنات BookInstance، وتشبه هذه الاستمارة إلى حد كبير الاستمارة التي استخدمناها لإنشاء كائنات الكتاب Book. استيراد توابع التحقق من صحة البيانات وتطهيرها افتح الملف "/controllers/bookinstanceController.js"، وضِف السطر التالي في بداية الملف: const { body, validationResult } = require("express-validator"); متحكم وجهة Get اطلب الوحدة Book في الجزء العلوي من الملف، حيث تُعَد هذه الوحدة مطلوبة لأن كل نسخة كتاب BookInstance مرتبطة بكتاب Book معين. const Book = require("../models/book"); ابحث عن تابع المتحكم bookinstance_create_get() المُصدَّر وضع مكانه الشيفرة البرمجية التالية: // عرض استمارة إنشاء نسخة كتاب BookInstance في طلب GET exports.bookinstance_create_get = asyncHandler(async (req, res, next) => { const allBooks = await Book.find({}, "title").sort({ title: 1 }).exec(); res.render("bookinstance_form", { title: "Create BookInstance", book_list: allBooks, }); }); يحصل المتحكم على قائمة بجميع الكتب (allBooks) ويمرّرها عبر المتغير book_list إلى العرض bookinstance_form.pug مع المتغير title. لاحظ عدم تحديد أي كتاب عندما أظهرنا الاستمارة لأول مرة، وبالتالي لم يُمرّر المتغير selected_book إلى دالة التصيير ()render، ونتيجةً لذلك سيكون للمتغير selected_book قيمة undefined في القالب. متحكم وجهة Post ابحث عن تابع المتحكم bookinstance_create_post() المُصدَّر وضع مكانه الشيفرة البرمجية التالية: // معالجة إنشاء نسخة كتاب في طلب POST exports.bookinstance_create_post = [ // التحقق من صحة الحقول وتطهيرها body("book", "Book must be specified").trim().isLength({ min: 1 }).escape(), body("imprint", "Imprint must be specified") .trim() .isLength({ min: 1 }) .escape(), body("status").escape(), body("due_back", "Invalid date") .optional({ values: "falsy" }) .isISO8601() .toDate(), // طلب العملية بعد التحقق من صحة البيانات وتطهيرها asyncHandler(async (req, res, next) => { // استخراج أخطاء التحقق من صحة البيانات من الطلب const errors = validationResult(req); // إنشاء كائن نسخة كتاب BookInstance مع بيانات مُهرَّبة ومحذوف منها المسافات const bookInstance = new BookInstance({ book: req.body.book, imprint: req.body.imprint, status: req.body.status, due_back: req.body.due_back, }); if (!errors.isEmpty()) { // توجد أخطاء // اعرض الاستمارة مرة أخرى مع قيم مُطهَّرة ورسائل خطأ const allBooks = await Book.find({}, "title").sort({ title: 1 }).exec(); res.render("bookinstance_form", { title: "Create BookInstance", book_list: allBooks, selected_book: bookInstance.book._id, errors: errors.array(), bookinstance: bookInstance, }); return; } else { // البيانات الواردة من الاستمارة صالحة await bookInstance.save(); res.redirect(bookInstance.url); } }), ]; تماثل بنية وسلوك هذه الشيفرة البرمجية شيفرة إنشاء الكائنات الأخرى، إذ نتحقق أولًا من صحة البيانات ونطهرها؛ فإذا كانت البيانات غير صالحة، فسنعيد عرض الاستمارة مع البيانات التي أدخلها المستخدم في الأصل وقائمة برسائل الخطأ؛ وإذا كانت البيانات صالحة، فسنحفظ سجل نسخة الكتاب BookInstance الجديد ونعيد توجيه المستخدم إلى صفحة التفاصيل. العرض أنشئ العرض "/views/bookinstance_form.pug" وضع فيه النص التالي: extends layout block content h1=title form(method='POST' action='') div.form-group label(for='book') Book: select#book.form-control(type='select' placeholder='Select book' name='book' required='true') for book in book_list option(value=book._id, selected=(selected_book==book._id.toString() ? '' : false) ) #{book.title} div.form-group label(for='imprint') Imprint: input#imprint.form-control(type='text' placeholder='Publisher and date information' name='imprint' required='true' value=(undefined===bookinstance ? '' : bookinstance.imprint)) div.form-group label(for='due_back') Date when book available: input#due_back.form-control(type='date' name='due_back' value=(undefined===bookinstance ? '' : bookinstance.due_back_yyyy_mm_dd)) div.form-group label(for='status') Status: select#status.form-control(type='select' placeholder='Select status' name='status' required='true' ) option(value='Maintenance' selected=(undefined===bookinstance || bookinstance.status!='Maintenance' ? false:'selected')) Maintenance option(value='Available' selected=(undefined===bookinstance || bookinstance.status!='Available' ? false:'selected')) Available option(value='Loaned' selected=(undefined===bookinstance || bookinstance.status!='Loaned' ? false:'selected')) Loaned option(value='Reserved' selected=(undefined===bookinstance || bookinstance.status!='Reserved' ? false:'selected')) Reserved button.btn.btn-primary(type='submit') Submit if errors ul for error in errors li!= error.msg تماثل بنية وسلوك هذا العرض تقريبًا بنية وسلوك القالب book_form.pug، لذا لن نشرحها مرةً أخرى. ملاحظة: يجعل القالب السابق قيم الحالة Status ثابتة (في الصيانة Maintenance ومتوفر Available وغير ذلك)، ولا يتذكر القيم التي أدخلها المستخدم، فإذا رغبتَ في ذلك، ففكر في إعادة تقديم القائمة وتمرير بيانات الخيار من المتحكم وضبط القيمة المختارة عند إعادة عرض الاستمارة. كيف تبدو استمارة إنشاء نسخة كتاب؟ شغّل التطبيق، وافتح متصفحك على العنوان "http://localhost:3000/"، ثم حدد رابط إنشاء نسخة كتاب جديدة Create new book instance (copy). إذا جرى إعداد كل شيء بصورة صحيحة، فيجب أن يبدو موقعك كما يلي، ويجب حفظ نسخة الكتاب بعد إرسال نسخة كتاب صالحة وستُنقَل إلى صفحة التفاصيل: ترجمة -وبتصرُّف- للمقالات Create Author form و Create Book form و Create BookInstance form. اقرأ أيضًا المقال السابق: إنشاء مكتبة محلية باستخدام Express: إنشاء استمارة Form لأنواع الكتب الزلات البرمجية والأخطاء في جافاسكريبت تعلم لغة جافا سكريبت JavaScript مدخل إلى إطار عمل الويب Express وبيئة Node
يوضح هذا المقال كيفية تعريف صفحات لإنشاء كائنات المؤلف والكتاب ونسخ الكتب للتعرّف أكثر على كيفية التعامل مع الاستمارات forms في إطار عمل Express. استمارة إنشاء مؤلف سنوضّح فيما يلي كيفية تعريف صفحة لإنشاء كائنات المؤلف Author. استيراد توابع التحقق من صحة البيانات Validation وتطهيرها Sanitization يجب طلب الدوال التي نريدها لاستخدام express-validator كما هو الحال في استمارة نوع الكتاب. افتح الملف "/controllers/authorController.js"، وأضِف السطر التالي في بداية الملف قبل دوال الوِجهة Route: const { body, validationResult } = require("express-validator"); متحكم وجهة Get ابحث عن تابع المتحكم author_create_get() المُصدَّر وضع مكانه الشيفرة البرمجية التالية التي تؤدي إلى تقديم العرض author_form.pug وتمرير متغير العنوان title: // عرض استمارة إنشاء مؤلف في طلب GET exports.author_create_get = (req, res, next) => { res.render("author_form", { title: "Create Author" }); }; متحكم وجهة Post ابحث عن تابع المتحكم author_create_post() المُصدَّر وضع مكانه الشيفرة البرمجية التالية: // معالجة إنشاء مؤلف Author في طلب POST exports.author_create_post = [ // التحقق من صحة الحقول وتطهيرها body("first_name") .trim() .isLength({ min: 1 }) .escape() .withMessage("First name must be specified.") .isAlphanumeric() .withMessage("First name has non-alphanumeric characters."), body("family_name") .trim() .isLength({ min: 1 }) .escape() .withMessage("Family name must be specified.") .isAlphanumeric() .withMessage("Family name has non-alphanumeric characters."), body("date_of_birth", "Invalid date of birth") .optional({ values: "falsy" }) .isISO8601() .toDate(), body("date_of_death", "Invalid date of death") .optional({ values: "falsy" }) .isISO8601() .toDate(), // طلب العملية بعد التحقق من صحة البيانات وتطهيرها asyncHandler(async (req, res, next) => { // استخراج أخطاء التحقق من صحة البيانات من الطلب const errors = validationResult(req); // إنشاء كائن مؤلف مع بيانات مُهرَّبة ومحذوف منها المسافات const author = new Author({ first_name: req.body.first_name, family_name: req.body.family_name, date_of_birth: req.body.date_of_birth, date_of_death: req.body.date_of_death, }); if (!errors.isEmpty()) { // توجد أخطاء، لذا اعرض الاستمارة مرة أخرى مع قيم مُطهَّرة أو رسائل خطأ res.render("author_form", { title: "Create Author", author: author, errors: errors.array(), }); return; } else { // البيانات الواردة من الاستمارة صالحة // احفظ المؤلف await author.save(); // أعِد التوجيه إلى سجل مؤلف جديد res.redirect(author.url); } }), ]; تحذير: لا تتحقق من صحة الأسماء باستخدام isAlphanumeric() كما فعلنا، نظرًا لوجود العديد من الأسماء التي تستخدم مجموعات محارف أخرى، ولكننا فعلنا ذلك لشرح كيفية استخدام أداة التحقق من صحة البيانات Validator، وكيفية ربطها بسلسلة تعاقبية مع أدوات التحقق الأخرى والإبلاغ عن الأخطاء. تماثل بنية وسلوك هذه الشيفرة البرمجية تقريبًا شيفرة إنشاء كائن نوع الكتاب Genre، إذ نتحقق أولًا من صحة البيانات ونطهرها، فإذا كانت البيانات غير صالحة سنعيد عرض الاستمارة مع البيانات التي أدخلها المستخدم في الأصل وقائمة برسائل الخطأ. وإذا كانت البيانات صالحة، سنحفظ سجل المؤلف الجديد ونعيد توجيه المستخدم إلى صفحة تفاصيل المؤلف. لا نتحقق مما إذا كان كائن المؤلف Author موجودًا مسبقًا قبل حفظه، وهذا يختلف عن معالج طلب Genre من النوع Post، إذ يمكننا ذلك بالرغم من أنه يمكن أن يكون لدينا عدة مؤلفين بالاسم نفسه. توضح شيفرة التحقق من صحة البيانات العديد من الميزات الجديدة التالية: أولًا، يمكننا إنشاء سلسلة تعاقبية من أدوات التحقق باستخدام withMessage() لتحديد رسالة الخطأ التي ستُعرَض في حالة فشل تابع التحقق السابق، مما يسهّل تقديم رسائل خطأ محددة دون الكثير من الشيفرة البرمجية المكررة. [ // التحقق من صحة الحقول وتطهيرها body("first_name") .trim() .isLength({ min: 1 }) .escape() .withMessage("First name must be specified.") .isAlphanumeric() .withMessage("First name has non-alphanumeric characters."), // … ]; ثانيًا، يمكننا استخدام الدالة optional() لإجراء عملية تحقق لاحقة فقط في حالة الإدخال في حقلٍ ما، مما يسمح بالتحقق من صحة الحقول الاختيارية، فمثلًا نتحقق فيما يلي من أن تاريخ الميلاد الاختياري هو تاريخ متوافق مع معيار ISO8601، إذ يعني تمرير كائن {values: "falsy"} أننا سنقبل إما سلسلة نصية فارغة أو null للقيمة الفارغة. [ body("date_of_birth", "Invalid date of birth") .optional({ values: "falsy" }) .isISO8601() .toDate(), ]; ثالثًا، تُستلَم المعاملات من الطلب بوصفها سلاسلًا نصية، ويمكننا استخدام toDate() أو toBoolean() لتغيير هذه الأنواع إلى أنواع جافا سكريبت المناسبة كما هو موضح في نهاية سلسلة أدوات التحقق سابقًا. العرض View أنشئ العرض "/views/author_form.pug" وضع فيه النص التالي: extends layout block content h1=title form(method='POST' action='') div.form-group label(for='first_name') First Name: input#first_name.form-control(type='text' placeholder='First name' name='first_name' required='true' value=(undefined===author ? '' : author.first_name) ) label(for='family_name') Family Name: input#family_name.form-control(type='text' placeholder='Family name' name='family_name' required='true' value=(undefined===author ? '' : author.family_name)) div.form-group label(for='date_of_birth') Date of birth: input#date_of_birth.form-control(type='date' name='date_of_birth' value=(undefined===author ? '' : author.date_of_birth) ) button.btn.btn-primary(type='submit') Submit if errors ul for error in errors li!= error.msg تماثل بنية وسلوك هذا العرض ما هو موجود في قالب genre_form.pug، لذلك لن نشرحه مرةً أخرى. ملاحظة: لا تدعم بعض المتصفحات حقل الإدخال type="date"، لذلك لن تحصل على عنصر واجهة مستخدم منتقي التاريخ أو العنصر البديل الافتراضي dd/mm/yyyy، ولكن ستحصل بدلًا من ذلك على حقل نص عادي فارغ. يتمثل أحد الحلول في إضافة السمة placeholder='dd/mm/yyyy' صراحةً، بحيث تظل تحصل على معلومات حول تنسيق النص المطلوب في المتصفحات ذات القدرات الأقل. التحدي: إضافة تاريخ الوفاة يفتقد هذا القالب حقلًا لإدخال تاريخ الوفاة date_of_death، لذا أنشئ هذا الحقل باتباع النمط نفسه لمجموعة استمارة تاريخ الميلاد. كيف تبدو استمارة المؤلف؟ شغّل التطبيق، وافتح متصفحك على العنوان "http://localhost:3000/"، ثم حدّد رابط إنشاء مؤلف جديد Create new author. إذا جرى إعداد كل شيء بصورة صحيحة، فيجب أن يبدو موقعك كما يلي، ويجب حفظ القيمة بعد إدخالها وستُنقَل إلى صفحة تفاصيل المؤلف. ملاحظة: إذا جرّبتَ تنسيقات إدخال مختلفة للتواريخ، فقد تجد أن التنسيق yyyy-mm-dd لا يتصرف بصورة صحيحة، لأن جافا سكريبت تتعامل مع سلاسل التاريخ بأنها تتضمن وقت 0 ساعة، ولكنها تتعامل أيضًا مع سلاسل التاريخ بهذا التنسيق (معيار ISO 8601) بوصفها تتضمن الوقت 0 ساعة بالتوقيت العالمي المنسَّق UTC بدلًا من التوقيت المحلي. إذا وقعت منطقتك الزمنية غرب توقيت UTC، فسيكون عرض التاريخ -لكونه محليًا- قبل يوم واحد من التاريخ الذي أدخلته، وهذه إحدى التعقيدات العديدة، مثل أسماء العائلات متعددة الكلمات والكتب متعددة المؤلفين التي لم نعالجها. استمارة إنشاء كتاب سنوضح كيفية تعريف صفحة أو استمارة لإنشاء كائنات الكتاب Book، ويُعَد ذلك أكثر تعقيدًا قليلًا من صفحات المؤلف Author أو نوع الكتاب Genre المكافئة لها، لأننا نحتاج إلى الحصول على سجلات المؤلف Author ونوع الكتاب Genre المتوفرة وعرضها في استمارة الكتاب Book. استيراد توابع التحقق من صحة البيانات وتطهيرها افتح الملف /controllers/bookController.js، وأضِف السطر التالي في بداية الملف قبل دوال الوِجهة Route: const { body, validationResult } = require("express-validator"); متحكم وجهة Get ابحث عن تابع المتحكم book_create_get() المُصدَّر وضع مكانه الشيفرة البرمجية التالية: // عرض استمارة إنشاء كتاب في طلب GET exports.book_create_get = asyncHandler(async (req, res, next) => { // الحصول على جميع المؤلفين وأنواع الكتب التي يمكننا استخدامها للإضافة إلى الكتاب const [allAuthors, allGenres] = await Promise.all([ Author.find().sort({ family_name: 1 }).exec(), Genre.find().sort({ name: 1 }).exec(), ]); res.render("book_form", { title: "Create Book", authors: allAuthors, genres: allGenres, }); }); نستخدم await لانتظار نتيجة التابع Promise.all() للحصول على جميع كائنات المؤلف Author ونوع الكتاب Genre على التوازي، وهو الأسلوب نفسه الذي استخدمناه عند عرض بيانات المكتبة، ثم تُمرَّر إلى العرض book_form.pug بوصفها متغيرات بالاسم authors و genres مع عنوان title الصفحة. متحكم وجهة Post ابحث عن تابع المتحكم book_create_post() المُصدَّر وضع مكانه الشيفرة البرمجية التالية: // معالجة إنشاء كتاب في طلب POST exports.book_create_post = [ // تحويل نوع الكتاب إلى مصفوفة (req, res, next) => { if (!Array.isArray(req.body.genre)) { req.body.genre = typeof req.body.genre === "undefined" ? [] : [req.body.genre]; } next(); }, // التحقق من صحة الحقول وتطهيرها body("title", "Title must not be empty.") .trim() .isLength({ min: 1 }) .escape(), body("author", "Author must not be empty.") .trim() .isLength({ min: 1 }) .escape(), body("summary", "Summary must not be empty.") .trim() .isLength({ min: 1 }) .escape(), body("isbn", "ISBN must not be empty").trim().isLength({ min: 1 }).escape(), body("genre.*").escape(), // طلب العملية بعد التحقق من صحة البيانات وتطهيرها asyncHandler(async (req, res, next) => { // استخراج أخطاء التحقق من صحة البيانات من الطلب const errors = validationResult(req); // إنشاء كائن كتاب مع بيانات مُهرَّبة ومحذوف منها المسافات const book = new Book({ title: req.body.title, author: req.body.author, summary: req.body.summary, isbn: req.body.isbn, genre: req.body.genre, }); if (!errors.isEmpty()) { // توجد أخطاء، لذا اعرض الاستمارة مرة أخرى مع قيم مُطهَّرة أو رسائل خطأ // احصل على جميع المؤلفين وأنواع الكتب للاستمارة const [allAuthors, allGenres] = await Promise.all([ Author.find().sort({ family_name: 1 }).exec(), Genre.find().sort({ name: 1 }).exec(), ]); // ميّز أنواع الكتب المختارة بوصفها محددة for (const genre of allGenres) { if (book.genre.includes(genre._id)) { genre.checked = "true"; } } res.render("book_form", { title: "Create Book", authors: allAuthors, genres: allGenres, book: book, errors: errors.array(), }); } else { // البيانات الواردة من الاستمارة صالحة، لذا احفظ الكتاب await book.save(); res.redirect(book.url); } }), ]; تماثل بنية وسلوك هذه الشيفرة البرمجية تقريبًا دوال وجهة Post لاستمارات النوع Genre والكاتب Author، إذ نتحقق أولًا من صحة البيانات ونطهّرها؛ فإذا كانت البيانات غير صالحة، فسنعيد عرض الاستمارة مع البيانات التي أدخلها المستخدم في الأصل وقائمة برسائل الخطأ؛ وإذا كانت البيانات صالحة، فسنحفظ سجل الكتاب Book الجديد ونعيد توجيه المستخدم إلى صفحة تفاصيل الكتاب. يتمثل الاختلاف الرئيسي فيما يتعلق بشيفرة معالجة الاستمارة الأخرى في كيفية تطهير معلومات نوع الكتاب، إذ تعيد الاستمارة مصفوفةً من عناصر Genre، بينما تعيد سلسلة نصية بالنسبة للحقول الأخرى. نحوّل أولًا الطلب إلى مصفوفة (مطلوبة للخطوة التالية) للتحقق من صحة المعلومات. [ // تحويل نوع الكتاب إلى مصفوفة (req, res, next) => { if (!Array.isArray(req.body.genre)) { req.body.genre = typeof req.body.genre === "undefined" ? [] : [req.body.genre]; } next(); }, // … ]; نستخدم بعد ذلك محرف بدل (*) في أداة التطهير للتحقق من صحة كل إدخال من مصفوفة أنواع الكتاب بصورة فردية، إذ توضح الشيفرة التالية كيفية ترجمة ذلك إلى "تطهير كل عنصر له المفتاح genre". [ // … body("genre.*").escape(), // … ]; الاختلاف الأخير فيما يتعلق بشيفرة معالجة الاستمارة الأخرى هو أنه نحتاج إلى تمرير جميع أنواع الكتب والمؤلفين الموجودين إلى الاستمارة. نكرر عبر جميع أنواع الكتب ونضيف المعامل checked="true" إلى تلك الأنواع التي كانت موجودة في بيانات Post (كما أعدنا الإنتاج في جزء الشيفرة التالي) لتمييز أنواع الكتب التي حدّدها المستخدم. // تمييز أنواع الكتب المختارة بوصفها مُحدَّدة for (const genre of results.genres) { if (book.genre.includes(genre._id)) { // اختير نوع الكتاب الحالي، لذا اضبط الراية "checked" genre.checked = "true"; } } العرض أنشئ العرض "/views/book_form.pug" وضع فيه النص التالي: extends layout block content h1= title form(method='POST' action='') div.form-group label(for='title') Title: input#title.form-control(type='text', placeholder='Name of book' name='title' required='true' value=(undefined===book ? '' : book.title) ) div.form-group label(for='author') Author: select#author.form-control(type='select', placeholder='Select author' name='author' required='true' ) for author in authors if book option(value=author._id selected=(author._id.toString()===book.author._id.toString() ? 'selected' : false) ) #{author.name} else option(value=author._id) #{author.name} div.form-group label(for='summary') Summary: textarea#summary.form-control(type='textarea', placeholder='Summary' name='summary' required='true') #{undefined===book ? '' : book.summary} div.form-group label(for='isbn') ISBN: input#isbn.form-control(type='text', placeholder='ISBN13' name='isbn' value=(undefined===book ? '' : book.isbn) required='true') div.form-group label Genre: div for genre in genres div(style='display: inline; padding-right:10px;') input.checkbox-input(type='checkbox', name='genre', id=genre._id, value=genre._id, checked=genre.checked ) label(for=genre._id) #{genre.name} button.btn.btn-primary(type='submit') Submit if errors ul for error in errors li!= error.msg تماثل بنية وسلوك هذا العرض تقريبًا بنية وسلوك القالب genre_form.pug، ولكن تكمن الاختلافات الرئيسية في كيفية تقديم حقول نوع الاختيار: Author و Genre، إذ: تُعرَض مجموعة أنواع الكتب بوصفها مربعات اختيار، وتستخدم قيمة checked التي ضبطناها في المتحكم لتحديد ما إذا كان يجب تحديد المربع أم لا. تُعرَض مجموعة المؤلفين بوصفها قائمة منسدلة مع اختيار فردي مرتبة أبجديًا، فإذا حدّد المستخدم مسبقًا مؤلف كتابٍ ما عند إصلاح قيم الحقول غير الصالحة بعد إرسال الاستمارة الأولية أو عند تحديث تفاصيل الكتاب مثلًا، فسيُعاد اختيار المؤلف عند عرض الاستمارة. نحدد في هذه الحالة المؤلف المراد اختياره من خلال موازنة معرّف خيار المؤلف الحالي مع القيمة التي أدخلها المستخدم مسبقًا والمُمرَّرة عبر المتغير book. ملاحظة: إذا كان هناك خطأ في الاستمارة المُرسَلة، فسيكون معرّف مؤلف الكتاب الجديد ومعرّفات مؤلفي الكتب الموجودين مسبقًا من النوع Schema.Types.ObjectId عند إعادة تصيير الاستمارة، لذا يجب تحويلها إلى سلاسل نصية أولًا للموازنة بينها. كيف تبدو استمارة إنشاء كتاب؟ شغّل التطبيق، وافتح متصفحك على العنوان "http://localhost:3000/"، ثم حدد رابط إنشاء كتاب جديد Create new book. إذا جرى إعداد كل شيء بصورة صحيحة، فيجب أن يبدو موقعك كما يلي، ويجب حفظ الكتاب بعد إرسال كتاب صالح وستُنقَل إلى صفحة تفاصيل الكتاب: استمارة إنشاء نسخة كتاب BookInstance سنوضح فيما يلي كيفية تعريف صفحة أو استمارة لإنشاء كائنات BookInstance، وتشبه هذه الاستمارة إلى حد كبير الاستمارة التي استخدمناها لإنشاء كائنات الكتاب Book. استيراد توابع التحقق من صحة البيانات وتطهيرها افتح الملف "/controllers/bookinstanceController.js"، وضِف السطر التالي في بداية الملف: const { body, validationResult } = require("express-validator"); متحكم وجهة Get اطلب الوحدة Book في الجزء العلوي من الملف، حيث تُعَد هذه الوحدة مطلوبة لأن كل نسخة كتاب BookInstance مرتبطة بكتاب Book معين. const Book = require("../models/book"); ابحث عن تابع المتحكم bookinstance_create_get() المُصدَّر وضع مكانه الشيفرة البرمجية التالية: // عرض استمارة إنشاء نسخة كتاب BookInstance في طلب GET exports.bookinstance_create_get = asyncHandler(async (req, res, next) => { const allBooks = await Book.find({}, "title").sort({ title: 1 }).exec(); res.render("bookinstance_form", { title: "Create BookInstance", book_list: allBooks, }); }); يحصل المتحكم على قائمة بجميع الكتب (allBooks) ويمرّرها عبر المتغير book_list إلى العرض bookinstance_form.pug مع المتغير title. لاحظ عدم تحديد أي كتاب عندما أظهرنا الاستمارة لأول مرة، وبالتالي لم يُمرّر المتغير selected_book إلى دالة التصيير ()render، ونتيجةً لذلك سيكون للمتغير selected_book قيمة undefined في القالب. متحكم وجهة Post ابحث عن تابع المتحكم bookinstance_create_post() المُصدَّر وضع مكانه الشيفرة البرمجية التالية: // معالجة إنشاء نسخة كتاب في طلب POST exports.bookinstance_create_post = [ // التحقق من صحة الحقول وتطهيرها body("book", "Book must be specified").trim().isLength({ min: 1 }).escape(), body("imprint", "Imprint must be specified") .trim() .isLength({ min: 1 }) .escape(), body("status").escape(), body("due_back", "Invalid date") .optional({ values: "falsy" }) .isISO8601() .toDate(), // طلب العملية بعد التحقق من صحة البيانات وتطهيرها asyncHandler(async (req, res, next) => { // استخراج أخطاء التحقق من صحة البيانات من الطلب const errors = validationResult(req); // إنشاء كائن نسخة كتاب BookInstance مع بيانات مُهرَّبة ومحذوف منها المسافات const bookInstance = new BookInstance({ book: req.body.book, imprint: req.body.imprint, status: req.body.status, due_back: req.body.due_back, }); if (!errors.isEmpty()) { // توجد أخطاء // اعرض الاستمارة مرة أخرى مع قيم مُطهَّرة ورسائل خطأ const allBooks = await Book.find({}, "title").sort({ title: 1 }).exec(); res.render("bookinstance_form", { title: "Create BookInstance", book_list: allBooks, selected_book: bookInstance.book._id, errors: errors.array(), bookinstance: bookInstance, }); return; } else { // البيانات الواردة من الاستمارة صالحة await bookInstance.save(); res.redirect(bookInstance.url); } }), ]; تماثل بنية وسلوك هذه الشيفرة البرمجية شيفرة إنشاء الكائنات الأخرى، إذ نتحقق أولًا من صحة البيانات ونطهرها؛ فإذا كانت البيانات غير صالحة، فسنعيد عرض الاستمارة مع البيانات التي أدخلها المستخدم في الأصل وقائمة برسائل الخطأ؛ وإذا كانت البيانات صالحة، فسنحفظ سجل نسخة الكتاب BookInstance الجديد ونعيد توجيه المستخدم إلى صفحة التفاصيل. العرض أنشئ العرض "/views/bookinstance_form.pug" وضع فيه النص التالي: extends layout block content h1=title form(method='POST' action='') div.form-group label(for='book') Book: select#book.form-control(type='select' placeholder='Select book' name='book' required='true') for book in book_list option(value=book._id, selected=(selected_book==book._id.toString() ? '' : false) ) #{book.title} div.form-group label(for='imprint') Imprint: input#imprint.form-control(type='text' placeholder='Publisher and date information' name='imprint' required='true' value=(undefined===bookinstance ? '' : bookinstance.imprint)) div.form-group label(for='due_back') Date when book available: input#due_back.form-control(type='date' name='due_back' value=(undefined===bookinstance ? '' : bookinstance.due_back_yyyy_mm_dd)) div.form-group label(for='status') Status: select#status.form-control(type='select' placeholder='Select status' name='status' required='true' ) option(value='Maintenance' selected=(undefined===bookinstance || bookinstance.status!='Maintenance' ? false:'selected')) Maintenance option(value='Available' selected=(undefined===bookinstance || bookinstance.status!='Available' ? false:'selected')) Available option(value='Loaned' selected=(undefined===bookinstance || bookinstance.status!='Loaned' ? false:'selected')) Loaned option(value='Reserved' selected=(undefined===bookinstance || bookinstance.status!='Reserved' ? false:'selected')) Reserved button.btn.btn-primary(type='submit') Submit if errors ul for error in errors li!= error.msg تماثل بنية وسلوك هذا العرض تقريبًا بنية وسلوك القالب book_form.pug، لذا لن نشرحها مرةً أخرى. ملاحظة: يجعل القالب السابق قيم الحالة Status ثابتة (في الصيانة Maintenance ومتوفر Available وغير ذلك)، ولا يتذكر القيم التي أدخلها المستخدم، فإذا رغبتَ في ذلك، ففكر في إعادة تقديم القائمة وتمرير بيانات الخيار من المتحكم وضبط القيمة المختارة عند إعادة عرض الاستمارة. كيف تبدو استمارة إنشاء نسخة كتاب؟ شغّل التطبيق، وافتح متصفحك على العنوان "http://localhost:3000/"، ثم حدد رابط إنشاء نسخة كتاب جديدة Create new book instance (copy). إذا جرى إعداد كل شيء بصورة صحيحة، فيجب أن يبدو موقعك كما يلي، ويجب حفظ نسخة الكتاب بعد إرسال نسخة كتاب صالحة وستُنقَل إلى صفحة التفاصيل: ترجمة -وبتصرُّف- للمقالات Create Author form و Create Book form و Create BookInstance form. اقرأ أيضًا المقال السابق: إنشاء مكتبة محلية باستخدام Express: إنشاء استمارة Form لأنواع الكتب الزلات البرمجية والأخطاء في جافاسكريبت تعلم لغة جافا سكريبت JavaScript مدخل إلى إطار عمل الويب Express وبيئة Node -
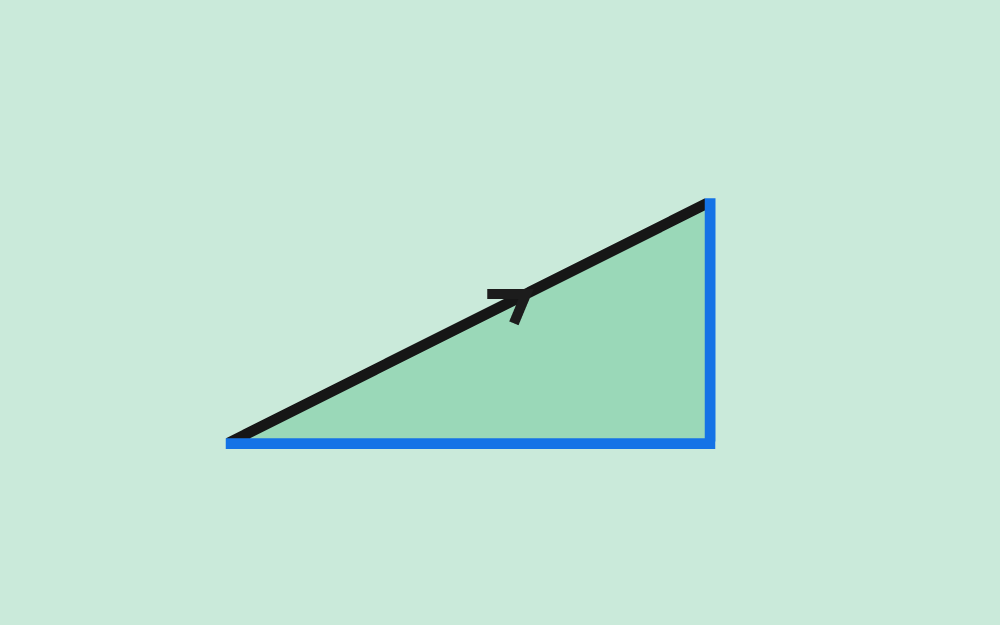 يناقش هذا المقال طول Length الأشعة وكيفية حساب هذا الطول باستخدام تمثيل المصفوفة العمودية للأشعة، وسنناقش في المقال التالي خاصيةً أخرى للأشعة، وهي خاصية الاتجاه Direction؛ إذ للأشعة بجميع أبعادها خاصيتان هما: الطول والاتجاه، ولكن سنستخدم أشعة في فضاء ثنائي الأبعاد للسهولة. سنوضّح في هذا المقال المواضيع التالية: طول الأشعة ثنائية وثلاثية الأبعاد. صيغة فيثاغورس. حساب طول الشعاع من خلال تمثيله بالمصفوفة العمودية. طول الشعاع الصفري. طول الشعاع السالب. الأشعة المحاذية للمحورين X-Y ما هو طول الشعاع التالي الذي تمثله المصفوفة العمودية (3, 0)T؟ يمكن القول أن الطول يساوي 3 وحدات. إذا كان هناك شعاع ثنائي الأبعاد يحاذي المحور x، فإن المصفوفة العمودية التي تمثله لها قيمة غير صفرية في العنصر الأول، وصفر في العنصر الثاني، إذ من السهل تحديد طول الشعاع الأخضر المُمثَّل بالمصفوفة العمودية (3, 0)Tفي المخطط البياني التالي، فالطول هو قيمة العنصر الوحيد غير الصفري في تلك المصفوفة. يحاذي الشعاع a (الشعاع الأزرق في المخطط البياني السابق) المحور y، ومصفوفته هي (0, 4)T، فما هو طول الشعاع a؟ طوله 4 وحدات، إذ يمكن قراءته من المخطط البياني، ولكن ليس للشعاع موقع ثابت طبعًا، لذلك يمكن رسم الشعاع a في أيّ مكان وسيكون له الطول نفسه. صيغة فيثاغورس يوضح المخطط البياني التالي شعاعين بطول 3 و4 مع الشعاع الجديد h: من الصعب معرفة طول الشعاع h، ولكنه ليس صعبًا كثيرًا؛ خاصةً إذا كنت على معرفة بقاعدة "3، 4، 5 في المثلثات قائمة الزاوية"، إذ يمكن ترتيب الأشعة الثلاثة في مثلث قائم الزاوية، بحيث يكون h هو الوتر، والضلعان الآخران هما 3 و 4؛ وبالتالي فإن طول h يساوي 5 باستخدام صيغة فيثاغورس والتي هي: (طول الوتر)2 = (طول الضلع القائمة الأولى)2 + (طول الضلع القائمة الثانية)2 إذا استخدمنا صيغة فيثاغورس مع مثلث قائم الزاوية له ضلعان قائمان طولهما 3 و 4، فسنحصل على طول الوتر كما يلي: (طول الوتر)2 = 32 + 42 (طول الوتر)2 = 9 + 16 = 25 (طول الوتر) = 5 إذًا ما هو طول الوتر في المثلث القائم الزاوية الذي طول ضلعيه 6 و 8؟ وما طول الوتر في المثلث القائم الزاوية الذي طول ضلعيه القائمين 6 و 8؟ سنستخدم للحل صيغة فيثاغورس كما يلي: الطول2 = 62 + 62 الطول2 = 36 + 64 = 100 الطول = 10 استخدام صيغة فيثاغورس لحساب طول الأشعة يمكن استخدام صيغة فيثاغورس لحساب طول الشعاع ثنائي الأبعاد. لنفترض أن الشعاع تمثّله المصفوفة العمودية (x, y)T، لذا ضع ذيل الشعاع عند نقطة الأصل، ثم أنشئ مثلثًا من خلال رسم الضلعين الآخرين كما في المخطط البياني السابق: side_1 = (x, 0)T side_2 = (0, y)T طول الضلع الأول side_1 هو x، وطول الضلع الثاني side_2 هو y، وبالتالي ينتج لدينا أن الطول: length (x, y)T = √( xT + yT ) يمثّل الرمز √ الجذرَ التربيعي الموجب في هذه الصيغة، إذ لا نريد بالطبع أن يكون الطول سالبًا. ما طول الشعاع الذي تمثله المصفوفة العمودية (4, 3)T؟ الطول يساوي 5.0، إذ يمكنك استخدام الصيغة السابقة، أو إدراك أنه مثلث قائم زاوية آخر أطول أضلاعه 3-4-5. الرمز المستخدم لطول الشعاع تعمل صيغة فيثاغورس مع الأشعة المحاذية للمحاور كما يلي: length of( (8,0)T ) = √( 8*8 + 0*0 ) = 8 لا يُعَد الاستمرار في قول "طول ( ) أو length of ( )" مناسبًا، لذا يوجد رمزٌ لذلك وهو: طول | a | = ( a ) للرمز a شريطٌ عمودي من كل جانب، وتستخدم الكتب أحيانًا شريطين عموديين على كل جانب، وبالتالي تكون الصيغة كما يلي: | (x, y)T | = √( x2 + y2 ) إذا كان g = (1, 1)T، فما هو | g | ؟ نعوّض في الصيغة كما يلي: | g | = √( 12 + 12 ) = √2.0 = 1.414213562373 لاحظ أن الطول ليس 1.0 ولا 2.0، وهذا خطأ يقع فيه بعض الأشخاص. إثبات متراجحة المثلث تذكّر أن طول مجموع شعاعين أقل من أو يساوي مجموع طولي هذين الشعاعين: طول ( v + u ) <= طول ( u ) + طول ( v ) وفي الصيغة الجديدة: | u + v | <= | u | + | v | لتكن لدينا الأشعة المُمثَّلة بالمصفوفات العمودية التالية: u = (3, 4)T v = (3, -4)T w = u + v = (6, 0)T يوضّح المخطط البياني التالي كيفية عمل متراجحة المثلث في هذا المثال، إذ يكون مجموع طولي الشعاعين الأحمر والأزرق أقل من طول الشعاع الأخضر. ولكن هل يمكن تطبيق ذلك عدديًا؟ وما هي قيمة كلٍّ من | u | و | v | و | w |؟ إجابة: u = (3, 4)T وبالتالي: | u | = 5 v = (3, -4)T وبالتالي: | v | = 5 w = u + v = (6, 0)T وبالتالي: | w | = 6 طبعًا 6 < 5 + 5 مما يدل على أن: | u + v | <= | u | + | v | تدريب عملي لا تكون عناصر الشعاع عادةً قيمًا صحيحةً بسيطة، ولتكن لدينا مثلًا بعض الأشعة المُمثَّلة بمصفوفات عمودية تحتوي على كسور عشرية في عناصرها كما يلي: q = (2.2, 3.6)T r = (-4.8, -2.2)T s = q + r يمكن طبعًا استخدام صيغة فيثاغورس، ولكنك ستحتاج إلى آلة حاسبة لاستخدامها. | (x, y)T | = √( x2 + y2 ) ما هي أطوال الأشعة q و r و s؟ | q | = √( 2.22.2 + 3.63.6 ) = √( 4.84 + 12.96 ) = √ 17.8 = 4.219 | r | = √( -4.8* -4.8 + -2.2 * -2.2 ) = √( 23.04 + 4.84 ) = √ 27.88 = 5.280 | s | = √( -2.6 * -2.6 + 1.4*1.4 ) = √( 6.76 + 1.96 ) = √ 8.72 = 2.953 يكون | s | أصغر من | q | + | r | كما هو متوقع. حساب طول الأشعة ثلاثية الأبعاد تكون للأشعة ثلاثية الأبعاد خاصية الطول، ويمكن استخدام الصيغة فيثاغورس نفسها لحساب الطول، إذ يكون طول الشعاع الذي تمثله مصفوفة مكونة من ثلاثة مكونات هو: | (x, y, z)T | = √( x2 + y2 + z2) كما في المثال التالي: | (1, 2, 3)T | = √( 12 + 22 + 32 ) = √( 1 + 4 + 9 ) = √14 = 3.742 إذًا لنحسب طول (2, -4, 4)T و (-1, -2, 3)T كما يلي: | (2, -4, 4)T | = √( 2 * 2 + -4 * -4 + 4 * 4) = √( 4+ 16 + 16 ) = √36 = 6 | (-1, -2, 3)T | = √( -1 * -1 + -2 * -2 + 3 * 3) = √( 1 + 4 + 9 ) = √14 = 3.742 يعطي تربيع عناصر الشعاع ناتج جمع للقيم الموجبة (أو الصفرية)، مما يضمن أن يكون الطول قيمة موجبة (أو صفرًا). الأشعة الهندسية ضع في بالك أن الأشعة هي كائنات هندسية، أي يُعبَّر عنها بطولٍ واتجاه في الفضاء. تُمثَّل الأشعة بالمصفوفات العمودية، وتفترض صيغ حساب الطول في هذا المقال استخدام إطار إحداثي وأن الأشعة مُمثَّلة بمصفوفات عمودية ضمن هذا الإطار. يمكن أن يناقش أيّ كتابٍ خاص بالرسوميات الحاسوبية كيفية استخدام الإحداثيات المتجانسة Homogeneous Coordinates لتمثيل الأشعة، إذ تستخدم هذه الطريقة مصفوفات عمودية مكونة من 4 مكونات لتمثيل الأشعة في فضاء ثلاثي الأبعاد، ويتطلب حساب طول الشعاع المُمثَّل بهذه الطريقة تعديل الصيغ، مع تجاهل المكون الرابع للمصفوفة العمودية. لا تقلق بشأن هذه الطريقة حاليًا، إذ سنوضّح التفاصيل لاحقًا، وخذ الوقت الكافي لفهم فكرة أن المصفوفات العمودية التي نستخدمها ليست الطريقة الوحيدة لتمثيل الأشعة، وأن خاصية الطول هي خاصة بالشعاع، وليست خاصة بالمصفوفة العمودية التي تمثل هذا الشعاع، لذا قد تتساءل عن وجود أيّ أهمية لتمييز شيء ما عن تمثيله في علوم الحاسوب! حسنًا، نعم هناك أهمية طبعًا، ويُعَد ذلك من أهم الأفكار في علوم الحاسوب. ليكن لدينًا مثلًا المخطط البياني التالي الذي يحتوي شعاعًا وإطارين للإحداثيات هما: إطار رمادي فاتح وإطار برتقالي. نمثّل الشعاع بالمصفوفة العمودية (8, 6)T في الإطار الرمادي الفاتح، ونمثّله في الإطار البرتقالي بالمصفوفة العمودية (9.8, 2)T، ولنفترض أن المحاور في كلا الإطارين مُدرَّجة باستخدام الوحدات نفسها (سم مثلًا). يكون طول الشعاع باستخدام التمثيل الأول هو: √( 82 + 62 ) = √( 64 + 36 )= √( 100 )= 10.0 ويكون طول الشعاع باستخدام التمثيل الثاني هو: √( 9.82 + 22 ) = √( 96 + 4 ) = √( 100 ) = 10.0 ولكن هل ستنجح العملية الحسابية إذا وضعنا ذيل الشعاع في مكان آخر من الإطار؟ نعم، فليس للشعاع موضع محدّد، لذلك يمكن وضع الذيل في أيّ مكان تريده. الطول قيمة موجبة أو صفرية بما أن مربع الطول يساوي مجموع المربعات، وينتج عن تربيع الأعداد الحقيقية قيمة صفرية أو موجبة، فهذا يعني أنه يجب أن يكون الطول دائمًا صفرًا أو عددًا موجبًا. | a | = | (a1, a2, a3 )T | = √( a12 + a22 + a32 ) >= 0 يكون طول الشعاع ثلاثي الأبعاد صفرًا فقط عندما يكون هذا الشعاع هو الشعاع الصفري، إذ يُمثَّل الشعاع الصفري ثلاثي الأبعاد في جميع الإطارات الإحداثية كما يلي: 0 = (0, 0, 0)T ويكون طول الشعاع الصفري هو: | 0 | = √( 02 + 02 + 02 ) = 0 يكون طول الشعاع الصفري ثنائي الأبعاد صفرًا أيضًا، وهو الشعاع ثنائي الأبعاد الوحيد الذي يكون طوله صفرًا. إذًا هل سيكون للشعاعين المتساويين الطول نفسه، وهل سيكون الشعاعان اللذان لهما الطول نفسه متساويين دائمًا؟ سيكون للشعاعين المتساويين الطول نفسه، إذ يجب أن تكون عناصرهما المتقابلة متساويةً، لذا يجب أن تكون عمليات التربيع المتقابلة متساوية أيضًا، وبالتالي يجب أن يكون المجموع متساويًا، ويجب أن يكون الطول متساويًا. لن يكون الشعاعان اللذان لهما الطول نفسه متساويين دائمًا، إذ يمكن أن يكون مجموع مربعات العناصر متساويًا دون أن تكون العناصر نفسها متساوية. طول الشعاع السالب إذا كان v شعاعًا، فإن -v هو شعاع يؤشّر إلى الاتجاه المعاكس، وإذا كان تمثيل v هو (a, b, c)T، فسيكون تمثيل -v هو (-a, -b, -c)T، فما هي العلاقة بين طول الشعاعين v وطول -v؟ العلاقة هي: | v | = |-v| الأشعة ذات الاتجاهات المتعاكسة يوضّح المخطط البياني التالي بيانيًا شعاعين باتجاهين متعاكسين في فضاء ثنائي الأبعاد: يمكنك تمثيل المخطط البياني السابق رياضيًا كما يلي: | v | = |(a, b, c)T| = √( a2 + b2 + c2) |-v | = |(-a, -b, -c)T| = √( -a2 + -b2 + -c2) = √( a2 + b2 + c2 ) يمكن القول أن الشعاعين لهما الطول نفسه، ولكنهما يؤشّران إلى اتجاهين متعاكسين كما سنوضّح في المقال التالي. يمكن حساب طول الشعاع الذي تمثله المصفوفة العمودية (1, -1, 1 )T كما يلي: √( 12 + -12 + 12) = √3 ترجمة -وبتصرُّف- للفصل Vector Length من كتاب Vector Math for 3D Computer Graphics لصاحبه Bradley Kjell. اقرأ أيضًا المقال السابق: كيفية جمع الأشعة الهندسية للتصاميم ثلاثية الأبعاد كيفية جمع وطرح المصفوفات العمودية والمصفوفات السطرية الأشعة والنقاط والمصفوفات العمودية في الرسوميات الحاسوبية ثلاثية الأبعاد التعرف على النقاط والخطوط في الرسوميات الحاسوبية ثلاثية الأبعاد
يناقش هذا المقال طول Length الأشعة وكيفية حساب هذا الطول باستخدام تمثيل المصفوفة العمودية للأشعة، وسنناقش في المقال التالي خاصيةً أخرى للأشعة، وهي خاصية الاتجاه Direction؛ إذ للأشعة بجميع أبعادها خاصيتان هما: الطول والاتجاه، ولكن سنستخدم أشعة في فضاء ثنائي الأبعاد للسهولة. سنوضّح في هذا المقال المواضيع التالية: طول الأشعة ثنائية وثلاثية الأبعاد. صيغة فيثاغورس. حساب طول الشعاع من خلال تمثيله بالمصفوفة العمودية. طول الشعاع الصفري. طول الشعاع السالب. الأشعة المحاذية للمحورين X-Y ما هو طول الشعاع التالي الذي تمثله المصفوفة العمودية (3, 0)T؟ يمكن القول أن الطول يساوي 3 وحدات. إذا كان هناك شعاع ثنائي الأبعاد يحاذي المحور x، فإن المصفوفة العمودية التي تمثله لها قيمة غير صفرية في العنصر الأول، وصفر في العنصر الثاني، إذ من السهل تحديد طول الشعاع الأخضر المُمثَّل بالمصفوفة العمودية (3, 0)Tفي المخطط البياني التالي، فالطول هو قيمة العنصر الوحيد غير الصفري في تلك المصفوفة. يحاذي الشعاع a (الشعاع الأزرق في المخطط البياني السابق) المحور y، ومصفوفته هي (0, 4)T، فما هو طول الشعاع a؟ طوله 4 وحدات، إذ يمكن قراءته من المخطط البياني، ولكن ليس للشعاع موقع ثابت طبعًا، لذلك يمكن رسم الشعاع a في أيّ مكان وسيكون له الطول نفسه. صيغة فيثاغورس يوضح المخطط البياني التالي شعاعين بطول 3 و4 مع الشعاع الجديد h: من الصعب معرفة طول الشعاع h، ولكنه ليس صعبًا كثيرًا؛ خاصةً إذا كنت على معرفة بقاعدة "3، 4، 5 في المثلثات قائمة الزاوية"، إذ يمكن ترتيب الأشعة الثلاثة في مثلث قائم الزاوية، بحيث يكون h هو الوتر، والضلعان الآخران هما 3 و 4؛ وبالتالي فإن طول h يساوي 5 باستخدام صيغة فيثاغورس والتي هي: (طول الوتر)2 = (طول الضلع القائمة الأولى)2 + (طول الضلع القائمة الثانية)2 إذا استخدمنا صيغة فيثاغورس مع مثلث قائم الزاوية له ضلعان قائمان طولهما 3 و 4، فسنحصل على طول الوتر كما يلي: (طول الوتر)2 = 32 + 42 (طول الوتر)2 = 9 + 16 = 25 (طول الوتر) = 5 إذًا ما هو طول الوتر في المثلث القائم الزاوية الذي طول ضلعيه 6 و 8؟ وما طول الوتر في المثلث القائم الزاوية الذي طول ضلعيه القائمين 6 و 8؟ سنستخدم للحل صيغة فيثاغورس كما يلي: الطول2 = 62 + 62 الطول2 = 36 + 64 = 100 الطول = 10 استخدام صيغة فيثاغورس لحساب طول الأشعة يمكن استخدام صيغة فيثاغورس لحساب طول الشعاع ثنائي الأبعاد. لنفترض أن الشعاع تمثّله المصفوفة العمودية (x, y)T، لذا ضع ذيل الشعاع عند نقطة الأصل، ثم أنشئ مثلثًا من خلال رسم الضلعين الآخرين كما في المخطط البياني السابق: side_1 = (x, 0)T side_2 = (0, y)T طول الضلع الأول side_1 هو x، وطول الضلع الثاني side_2 هو y، وبالتالي ينتج لدينا أن الطول: length (x, y)T = √( xT + yT ) يمثّل الرمز √ الجذرَ التربيعي الموجب في هذه الصيغة، إذ لا نريد بالطبع أن يكون الطول سالبًا. ما طول الشعاع الذي تمثله المصفوفة العمودية (4, 3)T؟ الطول يساوي 5.0، إذ يمكنك استخدام الصيغة السابقة، أو إدراك أنه مثلث قائم زاوية آخر أطول أضلاعه 3-4-5. الرمز المستخدم لطول الشعاع تعمل صيغة فيثاغورس مع الأشعة المحاذية للمحاور كما يلي: length of( (8,0)T ) = √( 8*8 + 0*0 ) = 8 لا يُعَد الاستمرار في قول "طول ( ) أو length of ( )" مناسبًا، لذا يوجد رمزٌ لذلك وهو: طول | a | = ( a ) للرمز a شريطٌ عمودي من كل جانب، وتستخدم الكتب أحيانًا شريطين عموديين على كل جانب، وبالتالي تكون الصيغة كما يلي: | (x, y)T | = √( x2 + y2 ) إذا كان g = (1, 1)T، فما هو | g | ؟ نعوّض في الصيغة كما يلي: | g | = √( 12 + 12 ) = √2.0 = 1.414213562373 لاحظ أن الطول ليس 1.0 ولا 2.0، وهذا خطأ يقع فيه بعض الأشخاص. إثبات متراجحة المثلث تذكّر أن طول مجموع شعاعين أقل من أو يساوي مجموع طولي هذين الشعاعين: طول ( v + u ) <= طول ( u ) + طول ( v ) وفي الصيغة الجديدة: | u + v | <= | u | + | v | لتكن لدينا الأشعة المُمثَّلة بالمصفوفات العمودية التالية: u = (3, 4)T v = (3, -4)T w = u + v = (6, 0)T يوضّح المخطط البياني التالي كيفية عمل متراجحة المثلث في هذا المثال، إذ يكون مجموع طولي الشعاعين الأحمر والأزرق أقل من طول الشعاع الأخضر. ولكن هل يمكن تطبيق ذلك عدديًا؟ وما هي قيمة كلٍّ من | u | و | v | و | w |؟ إجابة: u = (3, 4)T وبالتالي: | u | = 5 v = (3, -4)T وبالتالي: | v | = 5 w = u + v = (6, 0)T وبالتالي: | w | = 6 طبعًا 6 < 5 + 5 مما يدل على أن: | u + v | <= | u | + | v | تدريب عملي لا تكون عناصر الشعاع عادةً قيمًا صحيحةً بسيطة، ولتكن لدينا مثلًا بعض الأشعة المُمثَّلة بمصفوفات عمودية تحتوي على كسور عشرية في عناصرها كما يلي: q = (2.2, 3.6)T r = (-4.8, -2.2)T s = q + r يمكن طبعًا استخدام صيغة فيثاغورس، ولكنك ستحتاج إلى آلة حاسبة لاستخدامها. | (x, y)T | = √( x2 + y2 ) ما هي أطوال الأشعة q و r و s؟ | q | = √( 2.22.2 + 3.63.6 ) = √( 4.84 + 12.96 ) = √ 17.8 = 4.219 | r | = √( -4.8* -4.8 + -2.2 * -2.2 ) = √( 23.04 + 4.84 ) = √ 27.88 = 5.280 | s | = √( -2.6 * -2.6 + 1.4*1.4 ) = √( 6.76 + 1.96 ) = √ 8.72 = 2.953 يكون | s | أصغر من | q | + | r | كما هو متوقع. حساب طول الأشعة ثلاثية الأبعاد تكون للأشعة ثلاثية الأبعاد خاصية الطول، ويمكن استخدام الصيغة فيثاغورس نفسها لحساب الطول، إذ يكون طول الشعاع الذي تمثله مصفوفة مكونة من ثلاثة مكونات هو: | (x, y, z)T | = √( x2 + y2 + z2) كما في المثال التالي: | (1, 2, 3)T | = √( 12 + 22 + 32 ) = √( 1 + 4 + 9 ) = √14 = 3.742 إذًا لنحسب طول (2, -4, 4)T و (-1, -2, 3)T كما يلي: | (2, -4, 4)T | = √( 2 * 2 + -4 * -4 + 4 * 4) = √( 4+ 16 + 16 ) = √36 = 6 | (-1, -2, 3)T | = √( -1 * -1 + -2 * -2 + 3 * 3) = √( 1 + 4 + 9 ) = √14 = 3.742 يعطي تربيع عناصر الشعاع ناتج جمع للقيم الموجبة (أو الصفرية)، مما يضمن أن يكون الطول قيمة موجبة (أو صفرًا). الأشعة الهندسية ضع في بالك أن الأشعة هي كائنات هندسية، أي يُعبَّر عنها بطولٍ واتجاه في الفضاء. تُمثَّل الأشعة بالمصفوفات العمودية، وتفترض صيغ حساب الطول في هذا المقال استخدام إطار إحداثي وأن الأشعة مُمثَّلة بمصفوفات عمودية ضمن هذا الإطار. يمكن أن يناقش أيّ كتابٍ خاص بالرسوميات الحاسوبية كيفية استخدام الإحداثيات المتجانسة Homogeneous Coordinates لتمثيل الأشعة، إذ تستخدم هذه الطريقة مصفوفات عمودية مكونة من 4 مكونات لتمثيل الأشعة في فضاء ثلاثي الأبعاد، ويتطلب حساب طول الشعاع المُمثَّل بهذه الطريقة تعديل الصيغ، مع تجاهل المكون الرابع للمصفوفة العمودية. لا تقلق بشأن هذه الطريقة حاليًا، إذ سنوضّح التفاصيل لاحقًا، وخذ الوقت الكافي لفهم فكرة أن المصفوفات العمودية التي نستخدمها ليست الطريقة الوحيدة لتمثيل الأشعة، وأن خاصية الطول هي خاصة بالشعاع، وليست خاصة بالمصفوفة العمودية التي تمثل هذا الشعاع، لذا قد تتساءل عن وجود أيّ أهمية لتمييز شيء ما عن تمثيله في علوم الحاسوب! حسنًا، نعم هناك أهمية طبعًا، ويُعَد ذلك من أهم الأفكار في علوم الحاسوب. ليكن لدينًا مثلًا المخطط البياني التالي الذي يحتوي شعاعًا وإطارين للإحداثيات هما: إطار رمادي فاتح وإطار برتقالي. نمثّل الشعاع بالمصفوفة العمودية (8, 6)T في الإطار الرمادي الفاتح، ونمثّله في الإطار البرتقالي بالمصفوفة العمودية (9.8, 2)T، ولنفترض أن المحاور في كلا الإطارين مُدرَّجة باستخدام الوحدات نفسها (سم مثلًا). يكون طول الشعاع باستخدام التمثيل الأول هو: √( 82 + 62 ) = √( 64 + 36 )= √( 100 )= 10.0 ويكون طول الشعاع باستخدام التمثيل الثاني هو: √( 9.82 + 22 ) = √( 96 + 4 ) = √( 100 ) = 10.0 ولكن هل ستنجح العملية الحسابية إذا وضعنا ذيل الشعاع في مكان آخر من الإطار؟ نعم، فليس للشعاع موضع محدّد، لذلك يمكن وضع الذيل في أيّ مكان تريده. الطول قيمة موجبة أو صفرية بما أن مربع الطول يساوي مجموع المربعات، وينتج عن تربيع الأعداد الحقيقية قيمة صفرية أو موجبة، فهذا يعني أنه يجب أن يكون الطول دائمًا صفرًا أو عددًا موجبًا. | a | = | (a1, a2, a3 )T | = √( a12 + a22 + a32 ) >= 0 يكون طول الشعاع ثلاثي الأبعاد صفرًا فقط عندما يكون هذا الشعاع هو الشعاع الصفري، إذ يُمثَّل الشعاع الصفري ثلاثي الأبعاد في جميع الإطارات الإحداثية كما يلي: 0 = (0, 0, 0)T ويكون طول الشعاع الصفري هو: | 0 | = √( 02 + 02 + 02 ) = 0 يكون طول الشعاع الصفري ثنائي الأبعاد صفرًا أيضًا، وهو الشعاع ثنائي الأبعاد الوحيد الذي يكون طوله صفرًا. إذًا هل سيكون للشعاعين المتساويين الطول نفسه، وهل سيكون الشعاعان اللذان لهما الطول نفسه متساويين دائمًا؟ سيكون للشعاعين المتساويين الطول نفسه، إذ يجب أن تكون عناصرهما المتقابلة متساويةً، لذا يجب أن تكون عمليات التربيع المتقابلة متساوية أيضًا، وبالتالي يجب أن يكون المجموع متساويًا، ويجب أن يكون الطول متساويًا. لن يكون الشعاعان اللذان لهما الطول نفسه متساويين دائمًا، إذ يمكن أن يكون مجموع مربعات العناصر متساويًا دون أن تكون العناصر نفسها متساوية. طول الشعاع السالب إذا كان v شعاعًا، فإن -v هو شعاع يؤشّر إلى الاتجاه المعاكس، وإذا كان تمثيل v هو (a, b, c)T، فسيكون تمثيل -v هو (-a, -b, -c)T، فما هي العلاقة بين طول الشعاعين v وطول -v؟ العلاقة هي: | v | = |-v| الأشعة ذات الاتجاهات المتعاكسة يوضّح المخطط البياني التالي بيانيًا شعاعين باتجاهين متعاكسين في فضاء ثنائي الأبعاد: يمكنك تمثيل المخطط البياني السابق رياضيًا كما يلي: | v | = |(a, b, c)T| = √( a2 + b2 + c2) |-v | = |(-a, -b, -c)T| = √( -a2 + -b2 + -c2) = √( a2 + b2 + c2 ) يمكن القول أن الشعاعين لهما الطول نفسه، ولكنهما يؤشّران إلى اتجاهين متعاكسين كما سنوضّح في المقال التالي. يمكن حساب طول الشعاع الذي تمثله المصفوفة العمودية (1, -1, 1 )T كما يلي: √( 12 + -12 + 12) = √3 ترجمة -وبتصرُّف- للفصل Vector Length من كتاب Vector Math for 3D Computer Graphics لصاحبه Bradley Kjell. اقرأ أيضًا المقال السابق: كيفية جمع الأشعة الهندسية للتصاميم ثلاثية الأبعاد كيفية جمع وطرح المصفوفات العمودية والمصفوفات السطرية الأشعة والنقاط والمصفوفات العمودية في الرسوميات الحاسوبية ثلاثية الأبعاد التعرف على النقاط والخطوط في الرسوميات الحاسوبية ثلاثية الأبعاد -
 يوضح هذا المقال كيفية تعريف صفحة لإنشاء كائنات النوع Genre، إذ يُعَد ذلك مكانًا جيدًا لتعلم التعامل مع الاستمارات Forms لأن الاستمارة الخاصة بنوع الكتاب Genre تحتوي على حقل واحد فقط هو اسم النوع name وبدون اعتماديات، ويجب إعداد الوجهات Routes والمتحكمات Controllers والعروض Views لهذه الصفحة مثلها مثل أيّ صفحة أخرى. استيراد توابع التحقق من صحة البيانات Validation وتطهيرها Sanitization يمكن استخدام express-validator في المتحكمات من خلال طلب require الدوال التي نريد استخدامها للتحقق من صحة حقول النماذج من الوحدة 'express-validator'. افتح الملف "/controllers/genreController.js"، وأضف السطر التالي في بداية الملف قبل أيٍّ من دوال معالج الوجهة: const { body, validationResult } = require("express-validator"); ملاحظة: تسمح الصيغة السابقة باستخدام body و validationResult بوصفهما دوال وسيطة كما سترى في قسم طلب الوجهة من النوع Post، وهي تكافئ ما يلي: const validator = require("express-validator"); const body = validator.body; const validationResult = validator.validationResult; متحكم وجهة Get ابحث عن تابع المتحكم genre_create_get() المُصدَّر وضع مكانه الشيفرة البرمجية التالية التي تؤدي إلى تقديم التصيير genre_form.pug وتمرير متغير العنوان: // عرض استمارة إنشاء نوع كتاب في طلب GET exports.genre_create_get = (req, res, next) => { res.render("genre_form", { title: "Create Genre" }); }; لاحظ أن ذلك يؤدي إلى وضع دالة معالج وجهة Express "العادي" مكان المعالج غير المتزامن للعنصر البديل الذي أضفناه في مقال الوجهات والمتحكمات. لا حاجة للمغلّف asyncHandler() لهذه الوجهة، لأنه لا يحتوي على أيّ شيفرة برمجية يمكنها رمي استثناء. متحكم وجهة Post ابحث عن تابع المتحكم genre_create_post() المُصدَّر وضع مكانه الشيفرة البرمجية التالية: // معالجة إنشاء نوع كتاب Genre في طلب POST exports.genre_create_post = [ // التحقق من صحة حقل الاسم وتطهيره body("name", "Genre name must contain at least 3 characters") .trim() .isLength({ min: 3 }) .escape(), // طلب العملية بعد التحقق من صحة البيانات وتطهيرها asyncHandler(async (req, res, next) => { // استخراج أخطاء التحقق من صحة البيانات من الطلب const errors = validationResult(req); // إنشاء كائن نوع كتاب مع بيانات مُهرَّبة ومحذوف منها المسافات const genre = new Genre({ name: req.body.name }); if (!errors.isEmpty()) { // توجد أخطاء، لذا اعرض الاستمارة مرة أخرى مع قيم مُطهَّرة أو رسائل خطأ res.render("genre_form", { title: "Create Genre", genre: genre, errors: errors.array(), }); return; } else { // البيانات الواردة من الاستمارة صالحة // تحقق مما إذا كان نوع الكتاب الذي يحمل الاسم نفسه موجود مسبقًا const genreExists = await Genre.findOne({ name: req.body.name }).exec(); if (genreExists) { // نوع الكتاب موجود مسبقًا، لذا أعِد التوجيه إلى صفحة تفاصيل هذا النوع res.redirect(genreExists.url); } else { await genre.save(); // حُفِظ نوع الكتاب الجديد، لذا أعِد التوجيه إلى صفحة تفاصيل نوع الكتاب res.redirect(genre.url); } } }), ]; أول شيء يجب ملاحظته هو أن المتحكم يحدّد مصفوفة من الدوال الوسيطة بدلًا من وجود دالة وسيطة واحدة مع الوسائط (req, res, next)، وتُمرَّر المصفوفة إلى دالة الموجِّه ويُستدعَى كل تابع حسب ترتيبه. ملاحظة: يُعَد هذا الأسلوب ضروريًا، لأن أدوات التحقق من صحة البيانات Validators هي دوال وسيطة. يعرِّف التابع الأول في المصفوفة أداة التحقق من صحة الجسم (body()) التي تتحقق من صحة الحقل وتطهّره، وتستخدم الدالةtrim() لإزالة أي مسافة بيضاء لاحقة أو بادئة، وتتحقق من أن حقل الاسم name غير فارغ، ثم تستخدم الدالة escape() لإزالة أيّ محارف HTML خطيرة. [ // تحقق من أن حقل الاسم غير فارغ body("name", "Genre name must contain at least 3 characters") .trim() .isLength({ min: 3 }) .escape(), // … ]; بعد تحديد أدوات التحقق من الصحة، ننشئ دالة وسيطة لاستخراج أيّ أخطاء في عملية التحقق من صحة البيانات، إذ نستخدم التابع isEmpty() للتحقق ما إذا كان هناك أيّ أخطاء في نتيجة التحقق من صحة البيانات، وإذا كان هناك أخطاء، فسنصيّر الاستمارة مرةً أخرى، ونمرّر كائن نوع الكتاب المُطهَّر ومصفوفة رسائل الخطأ (errors.array()). // طلب العملية بعد التحقق من صحة البيانات وتطهيرها asyncHandler(async (req, res, next) => { // استخراج أخطاء التحقق من صحة البيانات من الطلب const errors = validationResult(req); // إنشاء كائن نوع كتاب مع بيانات مُهرَّبة ومحذوف منها المسافات const genre = new Genre({ name: req.body.name }); if (!errors.isEmpty()) { // توجد أخطاء، لذا اعرض الاستمارة مرة أخرى مع قيم مُطهَّرة أو رسائل خطأ res.render("genre_form", { title: "Create Genre", genre: genre, errors: errors.array(), }); return; } else { // البيانات الواردة من الاستمارة صالحة // … } }); إذا كانت بيانات اسم نوع الكتاب صالحة، فسنتحقق من وجود نوع كتاب Genre يحمل الاسم نفسه، لأننا لا نريد إنشاء نسخ مكررة. إذا كان الأمر كذلك، فسنعيد التوجيه إلى صفحة تفاصيل نوع الكتاب الموجود مسبقًا، وإن لم يكن الأمر كذلك، فسنحفظ نوع الكتاب Genre الجديد ونعيد التوجيه إلى صفحة تفاصيله. لاحظ أننا ننتظر باستخدام await نتيجة استعلام قاعدة البيانات باتباع النمط نفسه لمعالجات الوِجهة الأخرى. // تحقق مما إذا كان نوع الكتاب الذي يحمل الاسم نفسه موجودًا مسبقًا const genreExists = await Genre.findOne({ name: req.body.name }).exec(); if (genreExists) { // نوع الكتاب موجود مسبقًا، لذا أعِد التوجيه إلى صفحة تفاصيله res.redirect(genreExists.url); } else { await genre.save(); // حُفِظ نوع الكتاب الجديد، لذا أعِد التوجيه إلى صفحة تفاصيل نوع الكتاب res.redirect(genre.url); } سنستخدم هذا النمط في جميع المتحكمات اللاحقة، إذ سنشغّل أدوات التحقق من صحة البيانات (مع أدوات التطهير)، ثم نتحقق من الأخطاء وإما نعيد عرض الاستمارة مع معلومات الخطأ أو نحفظ البيانات. العرض View يُصيّر العرض نفسه في كل من متحكمات أو وِجهات GET و POST عندما ننشئ نوع كتاب Genre جديد (وسيُستخدَم لاحقًا عند تحديث نوع كتاب Genre) ، ولكن في حالة GET تكون الاستمارة فارغة ونمرر متغير العنوان فقط، بينما في حالة POST قد يكون المستخدم قد أدخل بيانات غير صالحة سابقًا ، لذا نمرّر في المتغير genre نسخة مُطهَّرة من البيانات المُدخَلة ونمرّر مصفوفة من رسائل الخطأ في المتغير errors. توضح الشيفرة التالية شيفرة المتحكم لتصيير القالب في كلتا الحالتين: // تصيير وِجهة GET res.render("genre_form", { title: "Create Genre" }); // تصيير وِجهة POST res.render("genre_form", { title: "Create Genre", genre, errors: errors.array(), }); أنشئ العرض "/views/genre_form.pug" وضع فيه النص التالي: extends layout block content h1 #{title} form(method='POST' action='') div.form-group label(for='name') Genre: input#name.form-control(type='text', placeholder='Fantasy, Poetry etc.' name='name' required='true' value=(undefined===genre ? '' : genre.name) ) button.btn.btn-primary(type='submit') Submit if errors ul for error in errors li!= error.msg يُعَد أغلب هذا القالب مألوفًا من مقال سابق، إذ سنوسّع أولًا القالب الأساسي layout.pug ونعدّل الكتلة block التي اسمها 'content'، ثم لدينا عنوان مع المتغير title الذي مرّرناه من المتحكم عبر التابع render(). لدينا بعد ذلك شيفرة Pug الخاصة باستمارة HTML التي تستخدم method="POST" لإرسال البيانات إلى الخادم، وستُرسَل البيانات إلى عنوان URL نفسه الخاص بالصفحة لأن الإجراء action هو سلسلة نصية فارغة. تعرِّف الاستمارة حقلًا واحدًا مطلوبًا من النوع النصي "text" اسمه "name"يمثل اسم نوع الكتاب، وتعتمد القيمة الافتراضية للحقل على ما إذا كان المتغير genre مُعرَّفًا أم لا. إذا اُستدعِي هذا الحقل من وِجهة GET، فسيكون فارغًا لأنها استمارة جديدة، وإذا اُستدعِي من وِجهة POST، فسيحتوي على القيمة غير الصالحة التي أدخلها المستخدم في الأصل. الجزء الأخير من الصفحة هو شيفرة الخطأ التي تؤدي إلى طباعة قائمة الأخطاء، إذا كان متغير الخطأ مُعرَّفًا، وبالتالي لن يظهر هذا القسم عند عرض القالب في وجهة GET. ملاحظة: عرضنا طريقة واحدة فقط لتصيير الأخطاء، ويمكنك أيضًا الحصول على أسماء الحقول المتأثرة من متغير الخطأ، واستخدامها للتحكم في مكان عرض رسائل الخطأ، وما إذا أدرتَ تطبيق شيفرة CSS مخصصة وغير ذلك. كيف تبدو استمارة نوع الكتاب؟ شغّل التطبيق، وافتح متصفحك على العنوان "http://localhost:3000/"، ثم حدّد رابط إنشاء نوع كتاب جديد Create new genre. إذا جرى إعداد كل شيء بصورة صحيحة، فيجب أن يبدو موقعك كما يلي، ويجب حفظ القيمة بعد إدخالها وستُنقَل إلى صفحة تفاصيل نوع الكتاب: الخطأ الوحيد الذي نتحقق منه من طرف الخادم هو أن حقل نوع الكتاب يجب ألّا يكون فارغًا. توضح لقطة الشاشة التالية كيف ستبدو قائمة الأخطاء إن لم تقدّم نوع كتاب (المحدَّد باللون الأحمر): ملاحظة: تستخدم عملية التحقق من صحة البيانات التابع trim() لضمان عدم قبول المسافة البيضاء بوصفها اسمًا لنوع الكتاب، ويمكننا أيضًا التحقق من أن الحقل ليس فارغًا من طرف العميل من خلال إضافة القيمة required='true' إلى تعريف الحقل في الاستمارة. input#name.form-control(type='text', placeholder='Fantasy, Poetry etc.' name='name' value=(undefined===genre ? '' : genre.name), required='true' ) ترجمة -وبتصرُّف- للمقال Create genre form. اقرأ المزيد المقال السابق إنشاء موقع مكتبة محلية باستخدام Express. الاستمارات (forms) في متصفح الويب وكيفية التعامل معها في جافاسكربت. تطبيق عملي لتعلم جانغو - الجزء الثامن: العمل مع الاستمارات Forms. إرسال البيانات واستلامها عبر الشبكة في جافاسكريبت
يوضح هذا المقال كيفية تعريف صفحة لإنشاء كائنات النوع Genre، إذ يُعَد ذلك مكانًا جيدًا لتعلم التعامل مع الاستمارات Forms لأن الاستمارة الخاصة بنوع الكتاب Genre تحتوي على حقل واحد فقط هو اسم النوع name وبدون اعتماديات، ويجب إعداد الوجهات Routes والمتحكمات Controllers والعروض Views لهذه الصفحة مثلها مثل أيّ صفحة أخرى. استيراد توابع التحقق من صحة البيانات Validation وتطهيرها Sanitization يمكن استخدام express-validator في المتحكمات من خلال طلب require الدوال التي نريد استخدامها للتحقق من صحة حقول النماذج من الوحدة 'express-validator'. افتح الملف "/controllers/genreController.js"، وأضف السطر التالي في بداية الملف قبل أيٍّ من دوال معالج الوجهة: const { body, validationResult } = require("express-validator"); ملاحظة: تسمح الصيغة السابقة باستخدام body و validationResult بوصفهما دوال وسيطة كما سترى في قسم طلب الوجهة من النوع Post، وهي تكافئ ما يلي: const validator = require("express-validator"); const body = validator.body; const validationResult = validator.validationResult; متحكم وجهة Get ابحث عن تابع المتحكم genre_create_get() المُصدَّر وضع مكانه الشيفرة البرمجية التالية التي تؤدي إلى تقديم التصيير genre_form.pug وتمرير متغير العنوان: // عرض استمارة إنشاء نوع كتاب في طلب GET exports.genre_create_get = (req, res, next) => { res.render("genre_form", { title: "Create Genre" }); }; لاحظ أن ذلك يؤدي إلى وضع دالة معالج وجهة Express "العادي" مكان المعالج غير المتزامن للعنصر البديل الذي أضفناه في مقال الوجهات والمتحكمات. لا حاجة للمغلّف asyncHandler() لهذه الوجهة، لأنه لا يحتوي على أيّ شيفرة برمجية يمكنها رمي استثناء. متحكم وجهة Post ابحث عن تابع المتحكم genre_create_post() المُصدَّر وضع مكانه الشيفرة البرمجية التالية: // معالجة إنشاء نوع كتاب Genre في طلب POST exports.genre_create_post = [ // التحقق من صحة حقل الاسم وتطهيره body("name", "Genre name must contain at least 3 characters") .trim() .isLength({ min: 3 }) .escape(), // طلب العملية بعد التحقق من صحة البيانات وتطهيرها asyncHandler(async (req, res, next) => { // استخراج أخطاء التحقق من صحة البيانات من الطلب const errors = validationResult(req); // إنشاء كائن نوع كتاب مع بيانات مُهرَّبة ومحذوف منها المسافات const genre = new Genre({ name: req.body.name }); if (!errors.isEmpty()) { // توجد أخطاء، لذا اعرض الاستمارة مرة أخرى مع قيم مُطهَّرة أو رسائل خطأ res.render("genre_form", { title: "Create Genre", genre: genre, errors: errors.array(), }); return; } else { // البيانات الواردة من الاستمارة صالحة // تحقق مما إذا كان نوع الكتاب الذي يحمل الاسم نفسه موجود مسبقًا const genreExists = await Genre.findOne({ name: req.body.name }).exec(); if (genreExists) { // نوع الكتاب موجود مسبقًا، لذا أعِد التوجيه إلى صفحة تفاصيل هذا النوع res.redirect(genreExists.url); } else { await genre.save(); // حُفِظ نوع الكتاب الجديد، لذا أعِد التوجيه إلى صفحة تفاصيل نوع الكتاب res.redirect(genre.url); } } }), ]; أول شيء يجب ملاحظته هو أن المتحكم يحدّد مصفوفة من الدوال الوسيطة بدلًا من وجود دالة وسيطة واحدة مع الوسائط (req, res, next)، وتُمرَّر المصفوفة إلى دالة الموجِّه ويُستدعَى كل تابع حسب ترتيبه. ملاحظة: يُعَد هذا الأسلوب ضروريًا، لأن أدوات التحقق من صحة البيانات Validators هي دوال وسيطة. يعرِّف التابع الأول في المصفوفة أداة التحقق من صحة الجسم (body()) التي تتحقق من صحة الحقل وتطهّره، وتستخدم الدالةtrim() لإزالة أي مسافة بيضاء لاحقة أو بادئة، وتتحقق من أن حقل الاسم name غير فارغ، ثم تستخدم الدالة escape() لإزالة أيّ محارف HTML خطيرة. [ // تحقق من أن حقل الاسم غير فارغ body("name", "Genre name must contain at least 3 characters") .trim() .isLength({ min: 3 }) .escape(), // … ]; بعد تحديد أدوات التحقق من الصحة، ننشئ دالة وسيطة لاستخراج أيّ أخطاء في عملية التحقق من صحة البيانات، إذ نستخدم التابع isEmpty() للتحقق ما إذا كان هناك أيّ أخطاء في نتيجة التحقق من صحة البيانات، وإذا كان هناك أخطاء، فسنصيّر الاستمارة مرةً أخرى، ونمرّر كائن نوع الكتاب المُطهَّر ومصفوفة رسائل الخطأ (errors.array()). // طلب العملية بعد التحقق من صحة البيانات وتطهيرها asyncHandler(async (req, res, next) => { // استخراج أخطاء التحقق من صحة البيانات من الطلب const errors = validationResult(req); // إنشاء كائن نوع كتاب مع بيانات مُهرَّبة ومحذوف منها المسافات const genre = new Genre({ name: req.body.name }); if (!errors.isEmpty()) { // توجد أخطاء، لذا اعرض الاستمارة مرة أخرى مع قيم مُطهَّرة أو رسائل خطأ res.render("genre_form", { title: "Create Genre", genre: genre, errors: errors.array(), }); return; } else { // البيانات الواردة من الاستمارة صالحة // … } }); إذا كانت بيانات اسم نوع الكتاب صالحة، فسنتحقق من وجود نوع كتاب Genre يحمل الاسم نفسه، لأننا لا نريد إنشاء نسخ مكررة. إذا كان الأمر كذلك، فسنعيد التوجيه إلى صفحة تفاصيل نوع الكتاب الموجود مسبقًا، وإن لم يكن الأمر كذلك، فسنحفظ نوع الكتاب Genre الجديد ونعيد التوجيه إلى صفحة تفاصيله. لاحظ أننا ننتظر باستخدام await نتيجة استعلام قاعدة البيانات باتباع النمط نفسه لمعالجات الوِجهة الأخرى. // تحقق مما إذا كان نوع الكتاب الذي يحمل الاسم نفسه موجودًا مسبقًا const genreExists = await Genre.findOne({ name: req.body.name }).exec(); if (genreExists) { // نوع الكتاب موجود مسبقًا، لذا أعِد التوجيه إلى صفحة تفاصيله res.redirect(genreExists.url); } else { await genre.save(); // حُفِظ نوع الكتاب الجديد، لذا أعِد التوجيه إلى صفحة تفاصيل نوع الكتاب res.redirect(genre.url); } سنستخدم هذا النمط في جميع المتحكمات اللاحقة، إذ سنشغّل أدوات التحقق من صحة البيانات (مع أدوات التطهير)، ثم نتحقق من الأخطاء وإما نعيد عرض الاستمارة مع معلومات الخطأ أو نحفظ البيانات. العرض View يُصيّر العرض نفسه في كل من متحكمات أو وِجهات GET و POST عندما ننشئ نوع كتاب Genre جديد (وسيُستخدَم لاحقًا عند تحديث نوع كتاب Genre) ، ولكن في حالة GET تكون الاستمارة فارغة ونمرر متغير العنوان فقط، بينما في حالة POST قد يكون المستخدم قد أدخل بيانات غير صالحة سابقًا ، لذا نمرّر في المتغير genre نسخة مُطهَّرة من البيانات المُدخَلة ونمرّر مصفوفة من رسائل الخطأ في المتغير errors. توضح الشيفرة التالية شيفرة المتحكم لتصيير القالب في كلتا الحالتين: // تصيير وِجهة GET res.render("genre_form", { title: "Create Genre" }); // تصيير وِجهة POST res.render("genre_form", { title: "Create Genre", genre, errors: errors.array(), }); أنشئ العرض "/views/genre_form.pug" وضع فيه النص التالي: extends layout block content h1 #{title} form(method='POST' action='') div.form-group label(for='name') Genre: input#name.form-control(type='text', placeholder='Fantasy, Poetry etc.' name='name' required='true' value=(undefined===genre ? '' : genre.name) ) button.btn.btn-primary(type='submit') Submit if errors ul for error in errors li!= error.msg يُعَد أغلب هذا القالب مألوفًا من مقال سابق، إذ سنوسّع أولًا القالب الأساسي layout.pug ونعدّل الكتلة block التي اسمها 'content'، ثم لدينا عنوان مع المتغير title الذي مرّرناه من المتحكم عبر التابع render(). لدينا بعد ذلك شيفرة Pug الخاصة باستمارة HTML التي تستخدم method="POST" لإرسال البيانات إلى الخادم، وستُرسَل البيانات إلى عنوان URL نفسه الخاص بالصفحة لأن الإجراء action هو سلسلة نصية فارغة. تعرِّف الاستمارة حقلًا واحدًا مطلوبًا من النوع النصي "text" اسمه "name"يمثل اسم نوع الكتاب، وتعتمد القيمة الافتراضية للحقل على ما إذا كان المتغير genre مُعرَّفًا أم لا. إذا اُستدعِي هذا الحقل من وِجهة GET، فسيكون فارغًا لأنها استمارة جديدة، وإذا اُستدعِي من وِجهة POST، فسيحتوي على القيمة غير الصالحة التي أدخلها المستخدم في الأصل. الجزء الأخير من الصفحة هو شيفرة الخطأ التي تؤدي إلى طباعة قائمة الأخطاء، إذا كان متغير الخطأ مُعرَّفًا، وبالتالي لن يظهر هذا القسم عند عرض القالب في وجهة GET. ملاحظة: عرضنا طريقة واحدة فقط لتصيير الأخطاء، ويمكنك أيضًا الحصول على أسماء الحقول المتأثرة من متغير الخطأ، واستخدامها للتحكم في مكان عرض رسائل الخطأ، وما إذا أدرتَ تطبيق شيفرة CSS مخصصة وغير ذلك. كيف تبدو استمارة نوع الكتاب؟ شغّل التطبيق، وافتح متصفحك على العنوان "http://localhost:3000/"، ثم حدّد رابط إنشاء نوع كتاب جديد Create new genre. إذا جرى إعداد كل شيء بصورة صحيحة، فيجب أن يبدو موقعك كما يلي، ويجب حفظ القيمة بعد إدخالها وستُنقَل إلى صفحة تفاصيل نوع الكتاب: الخطأ الوحيد الذي نتحقق منه من طرف الخادم هو أن حقل نوع الكتاب يجب ألّا يكون فارغًا. توضح لقطة الشاشة التالية كيف ستبدو قائمة الأخطاء إن لم تقدّم نوع كتاب (المحدَّد باللون الأحمر): ملاحظة: تستخدم عملية التحقق من صحة البيانات التابع trim() لضمان عدم قبول المسافة البيضاء بوصفها اسمًا لنوع الكتاب، ويمكننا أيضًا التحقق من أن الحقل ليس فارغًا من طرف العميل من خلال إضافة القيمة required='true' إلى تعريف الحقل في الاستمارة. input#name.form-control(type='text', placeholder='Fantasy, Poetry etc.' name='name' value=(undefined===genre ? '' : genre.name), required='true' ) ترجمة -وبتصرُّف- للمقال Create genre form. اقرأ المزيد المقال السابق إنشاء موقع مكتبة محلية باستخدام Express. الاستمارات (forms) في متصفح الويب وكيفية التعامل معها في جافاسكربت. تطبيق عملي لتعلم جانغو - الجزء الثامن: العمل مع الاستمارات Forms. إرسال البيانات واستلامها عبر الشبكة في جافاسكريبت -
 سنتعرف في هذا المقال على كيفية إنشاء الصفحة الرئيسية لموقع المكتبة المحلية LocalLibrary وصفحات قوائم الكتب والمؤلفين ونسخ الكتب وأنواعها، وسنوضح كيفية تنسيق التاريخ باستخدام المكتبة Luxon، كما سنتعرف على كيفية إنشاء صفحات تفاصيل الكتب وأنواعها ونسخها وتفاصيل المؤلفين. صفحة الموقع الرئيسية ستكون الصفحة الأولى التي سننشئها هي الصفحة الرئيسية لموقع الويب، والتي يمكن الوصول إليها إما من جذر الموقع / أو من الدليل catalog/، مما سيؤدي إلى عرض بعض النصوص الثابتة التي تصف الموقع، مع الأعداد المحسوبة ديناميكيًا لأنواع السجلات المختلفة في قاعدة البيانات. أنشأنا مسبقًا وجهةً Route للصفحة الرئيسية، ولإكمال هذه الصفحة، يجب تحديث دالة المتحكم لجلب أعداد السجلات من قاعدة البيانات وإنشاء عرض (قالب) يمكننا استخدامه لعرض الصفحة. ملاحظة: سنستخدم مكتبة Mongoose للحصول على معلومات قاعدة البيانات، لذا لا بد من إعادة قراءة قسم البحث عن السجلات من مقال استخدام قاعدة البيانات باستخدام مكتبة Mongoose. الوجهة Route أنشأنا وِجهات صفحة الفهرس في مقال الوجهات والمتحكمات، إذ عرّفنا جميع دوال الوجهات في الملف "/routes/catalog.js": // الحصول على صفحة الدليل الرئيسية router.get("/", book_controller.index); //يُربَط مع /catalog/ لأننا نستورد الوجهة مع البادئة /catalog تملك دالة متحكم الكتاب index المُمرَّرة بوصفها معاملًا (book_controller.index) تقديم بديل placeholder implementation مُعرَّف في الملف /controllers/bookController.js: exports.index = asyncHandler(async (req, res, next) => { res.send("NOT IMPLEMENTED: Site Home Page"); }); تُعَد هذه الدالة هي دالة المتحكم التي نوسّعها للحصول على معلومات من نماذجنا ثم عرضها باستخدام عرض (قالب). المتحكم Controller تحتاج دالة المتحكم index إلى جلب معلومات حول عدد سجلات الكتب Book ونسخ الكتب BookInstance (جميعها) ونسخ الكتب BookInstance (المتاحة) والمؤلفين Author وأنواع الكتب Genre الموجودة في قاعدة البيانات، وعرض هذه البيانات في قالب لإنشاء صفحة HTML، ثم إعادتها في استجابة HTTP. افتح الملف /controllers/bookController.js، إذ سترى الدالة index() المستورَدة بالقرب من أعلى الملف. const Book = require("../models/book"); const asyncHandler = require("express-async-handler"); exports.index = asyncHandler(async (req, res, next) => { res.send("NOT IMPLEMENTED: Site Home Page"); }); ضع جزء الشيفرة التالي مكان الشيفرة السابقة، فأول شيء تفعله هذه الشيفرة هو استيراد (أو طلب require()) جميع النماذج Models، إذ نحتاج إلى ذلك لأننا سنستخدمها للحصول على عدد المستندات. تطلب الشيفرة أيضًا "express-async-handler" الذي يوفّر مغلِّفًا Wrapper لالتقاط الاستثناءات التي تُرمَى في دوال معالج الوِجهة. const Book = require("../models/book"); const Author = require("../models/author"); const Genre = require("../models/genre"); const BookInstance = require("../models/bookinstance"); const asyncHandler = require("express-async-handler"); exports.index = asyncHandler(async (req, res, next) => { // الحصول على تفاصيل عدد الكتب ونسخها والمؤلفين وأنواع الكتب (على التوازي) const [ numBooks, numBookInstances, numAvailableBookInstances, numAuthors, numGenres, ] = await Promise.all([ Book.countDocuments({}).exec(), BookInstance.countDocuments({}).exec(), BookInstance.countDocuments({ status: "Available" }).exec(), Author.countDocuments({}).exec(), Genre.countDocuments({}).exec(), ]); res.render("index", { title: "Local Library Home", book_count: numBooks, book_instance_count: numBookInstances, book_instance_available_count: numAvailableBookInstances, author_count: numAuthors, genre_count: numGenres, }); }); نستخدم التابع countDocuments() للحصول على عدد نسخ كل نموذج، ويُستدعَى هذا التابع في نموذج مع مجموعة اختيارية من الشروط لمطابقتها وإعادة كائن استعلام Query. يمكن تنفيذ الاستعلام من خلال استدعاء التابع exec()، والذي يعيد وعدًا Promise إما يجري الوفاء به مع نتيجة أو يُرفض إذا كان هناك خطأ في قاعدة البيانات. تُعَد الاستعلامات الخاصة بأعداد المستندات مستقلة عن بعضها بعضًا، لذا نستخدم التابع Promise.all() لتنفيذها على التوازي، ويعيد هذا التابع وعدًا جديدًا ننتظره باستخدام await حتى ينتهي، إذ يتوقف التنفيذ مؤقتًا في هذه الدالة عند await. يجري الوفاء بالوعد الذي يعيده all() عند اكتمال جميع الاستعلامات، ويستمر تنفيذ دالة معالج الوجهة، ويملأ هذا الوعد المصفوفةَ بنتائج استعلامات قاعدة البيانات. نستدعي بعد ذلك التابع res.render()، ونحدّد عرضًا (قالبًا) بالاسم "index" وكائنات تربط نتائج استعلامات قاعدة البيانات مع قالب العرض، إذ تتوفر البيانات على شكل أزواج مفتاح-قيمة key-value، ويمكن الوصول إليها في القالب باستخدام المفتاح. لاحظ أن الشيفرة البرمجية بسيطة جدًا لأنه يمكننا افتراض نجاح استعلامات قاعدة البيانات، وإذا فشلت أيٌّ من عمليات قاعدة البيانات، فسيكتشف asyncHandler() الاستثناء المُرمَى ويمرّره إلى معالج البرمجية الوسيطة التالية next في السلسلة. العرض View افتح العرض "/views/index.pug" وضع فيه المحتوى التالي بدلًا من محتواه الموجود مسبقًا: extends layout block content h1= title p Welcome to #[em LocalLibrary], a very basic Express website developed as a tutorial example on the Mozilla Developer Network. h1 Dynamic content p The library has the following record counts: ul li #[strong Books:] !{book_count} li #[strong Copies:] !{book_instance_count} li #[strong Copies available:] !{book_instance_available_count} li #[strong Authors:] !{author_count} li #[strong Genres:] !{genre_count} يُعَد العرض واضحًا، إذ نوسّع القالب الأساسي layout.pug من خلال تعديل الكتلة block التي اسمها 'content'. سيكون العنوان h1 الأول هو النص المُهرَّب للمتغير title المُمرَّر إلى التابع render()، ولاحظ استخدام 'h1=' بحيث يجري التعامل مع النص الذي يليه بوصفه تعبير جافا سكريبت، ثم نضمّن فقرةً تعرّف بالمكتبة المحلية LocalLibrary. نسرد عدد النسخ من كل نموذج تحت عنوان المحتوى الديناميكي Dynamic content. لاحظ أن قيم القالب للبيانات هي المفاتيح المُحدَّدة عند استدعاء التابع render() في دالة معالج الوِجهة. ملاحظة: لم نهرّب قيم العد، إذ استخدمنا صيغة {}!، لأن قيم العد محسوبة، ولكن إذا وفّر المستخدمون النهائيون المعلومات، فسنهرّب المتغير لعرضه. كيف تبدو الصفحة الرئيسية؟ أنشأنا حتى الآن كل ما هو مطلوب لعرض صفحة الفهرس، لذا شغّل التطبيق وافتح متصفحك على العنوان "http://localhost:3000/". إذا جرى إعداد كل شيء بصورة صحيحة، فيجب أن يبدو موقعك كما يلي: ملاحظة: لن تتمكّن من استخدام روابط الشريط الجانبي حاليًا لأن عناوين URL والعروض والقوالب الخاصة بهذه الصفحات غير مُعرَّفة بعد، وإذا حاولت الوصول إليها، فستحصل على أخطاء مثل "NOT IMPLEMENTED: Book list" اعتمادًا على الرابط الذي تنقر عليه، إذ تُحدَّد هذه السلسلة النصية الحرفية -التي سنضع مكانها البيانات المناسبة- في المتحكمات المختلفة التي تكون موجودة ضمن الملف "controllers". صفحة قائمة الكتب سنقدّم الآن صفحة قائمة الكتب، إذ تعرض هذه الصفحة قائمةً بجميع الكتب الموجودة في قاعدة البيانات مع مؤلفها والعنوان الخاص بكل كتاب، والذي يكون رابطًا تشعبيًا hyperlink لصفحة تفاصيل الكتاب المرتبطة به. المتحكم يجب أن تحصل دالة متحكم قائمة الكتب على قائمة بجميع كائنات الكتاب Book في قاعدة البيانات، ثم تفرزها وتمرّرها إلى القالب لعرضها. افتح الملف "/controllers/bookController.js"، وابحث عن تابع المتحكم book_list() المُصدَّر وضع مكانه الشيفرة البرمجية التالية: // عرض قائمة جميع الكتب exports.book_list = asyncHandler(async (req, res, next) => { const allBooks = await Book.find({}, "title author") .sort({ title: 1 }) .populate("author") .exec(); res.render("book_list", { title: "Book List", book_list: allBooks }); }); يستدعي معالج الوجهة Route Handler الدالة find() للنموذج Book، ويختار إعادة العنوان title والمؤلف author فقط لأننا لسنا بحاجة إلى الحقول الأخرى (سيعيد أيضًا الحقل _id والحقول الافتراضية)، ويفرز النتائج حسب العنوان أبجديًا باستخدام التابع sort(). نستدعي أيضًا التابع populate() للنموذج Book مع تحديد الحقل author، مما سيؤدي إلى استبدال معرّف مؤلف الكتاب المُخزَّن بتفاصيل المؤلف الكاملة، ثم يُستدعَى التابع exec() في نهاية السلسلة التعاقبية daisy-chained لتنفيذ الاستعلام وإعادة الوعد. يستخدم معالج الوِجهة await لانتظار الوعد، مما يؤدي إلى إيقاف التنفيذ حتى استقراره. إذا جرى الوفاء بالوعد، فستُحفَظ نتائج الاستعلام في المتغير allBooks ويستمر المعالج في التنفيذ. يستدعي الجزء الأخير من معالج الوِجهة التابع render()، ويحدد القالب book_list (.pug) ويمرر قيم title و book_list إلى القالب. العرض View أنشئ العرض "/views/book_list.pug" وضع فيه المحتوى التالي: extends layout block content h1= title ul each book in book_list li a(href=book.url) #{book.title} | (#{book.author.name}) else li There are no books. يوسّع العرض القالبَ الأساسي layout.pug ويعدّل الكتلة block التي اسمها 'content'، ويعرض العنوان title الذي مرّرناه من المتحكم (باستخدام التابع render()) ويتكرر عبر المتغير book_list باستخدام صيغة each-in-else. يُنشَأ عنصر قائمة لكل كتاب، إذ تعرض هذه القائمة عنوان الكتاب كرابط إلى صفحة تفاصيل الكتاب متبوعًا باسم المؤلف، وإذا لم يكن هناك كتب في book_list، فستُنفَّذ تعليمة else، ويعرض نص عدم وجود كتب "There are no books". ملاحظة: نستخدم book.url لتوفير رابط إلى سجل تفاصيل كل كتاب (قدّمنا هذه الوجهة، ولكن لم نقدّم الصفحة الخاصة بها بعد)، وهي خاصية افتراضية لنموذج الكتاب Book الذي يستخدم الحقل _id الخاص بنسخة النموذج لإنشاء مسار عنوان URL فريد. من المهم تعريف كل كتاب على سطرين، باستخدام الشريط العمودي | في السطر الثاني، ويُعَد هذا الأسلوب ضروريًا لأنه إذا كان اسم المؤلف موجودًا في السطر السابق، فسيكون جزءًا من الرابط التشعبي. كيف تبدو صفحة قائمة الكتب؟ شغّل التطبيق (راجع قسم اختبار الوجهات من مقال الوجهات والمتحكمات للاطلاع على الأوامر ذات الصلة) وافتح متصفحك على العنوان "http://localhost:3000/"، ثم حدّد رابط "جميع الكتب All books". إذا جرى إعداد كل شيء بصورة صحيحة، فيجب أن يبدو موقعك كما يلي: صفحة قائمة نسخ الكتب BookInstance سنقدّم الآن قائمة بجميع نسخ الكتب BookInstance في المكتبة، إذ يجب أن تتضمن الصفحة عنوان الكتاب Book المرتبط بكل نسخة كتاب BookInstance (مرتبطة برابط إلى صفحة تفاصيلها) مع المعلومات الأخرى في نموذج BookInstance، بما في ذلك الحالة والناشر والمعرِّف الفريد لكل نسخة، ويجب ربط نص المعرّف الفريد برابط إلى صفحة تفاصيل نسخة الكتاب BookInstance. المتحكم يجب أن يحصل متحكم قائمة BookInstance على قائمة بجميع نسخ الكتاب، ويجب ملء معلومات الكتاب المرتبطة بها، ثم تمرير القائمة إلى القالب لعرضها. افتح الملف "/controllers/bookinstanceController.js"، وابحث عن تابع المتحكم bookinstance_list() المُصدَّر وضع مكانه الشيفرة البرمجية التالية: // عرض قائمة جميع نسخ الكتب exports.bookinstance_list = asyncHandler(async (req, res, next) => { const allBookInstances = await BookInstance.find().populate("book").exec(); res.render("bookinstance_list", { title: "Book Instance List", bookinstance_list: allBookInstances, }); }); يستدعي معالج الوجهة الدالةَ find() للنموذج BookInstance، ثم يتبعه في سلسلة تعاقبية استدعاءٌ للتابع populate() مع حقل الكتاب book، والذي سيضع مستند كتاب Book كامل مكان معرّف الكتاب المُخزَّن لكل BookInstance، ثم يُستدعَى التابع exec() في نهاية السلسلة التعاقبية لتنفيذ الاستعلام وإعادة الوعد. يستخدم معالج الوِجهة await لانتظار الوعد، مما يؤدي إلى إيقاف التنفيذ حتى استقراره. إذا جرى الوفاء بالوعد، فستُحفَظ نتائج الاستعلام في المتغير allBookInstances ويستمر المعالج في التنفيذ. يستدعي الجزء الأخير من الشيفرة البرمجية التابع render()، ويحدد القالب bookinstance_list (.pug) ويمرر قيم title و bookinstance_list إلى القالب. العرض View أنشئ العرض "/views/bookinstance_list.pug" وضع فيه المحتوى التالي: extends layout block content h1= title ul each val in bookinstance_list li a(href=val.url) #{val.book.title} : #{val.imprint} - if val.status=='Available' span.text-success #{val.status} else if val.status=='Maintenance' span.text-danger #{val.status} else span.text-warning #{val.status} if val.status!='Available' span (Due: #{val.due_back} ) else li There are no book copies in this library. يماثل هذا العرض العروض الأخرى، إذ يوسّع التخطيط، ويبدّل كتلة المحتوى content، ويعرض العنوان title المُمرَّر من المتحكم، ويتكرر عبر جميع نسخ الكتاب في bookinstance_list. نعرض لكل نسخة حالتها، وإن لم يكن الكتاب متاحًا، فسيُعرَض تاريخ استرجاعه المتوقع. قدّمنا ميزة جديدة، إذ يمكننا استخدام الصيغة النقطية بعد الوسم لإسناد صنف، لذلك سيُصرَّف span.text-success إلى <span class="text-success">، ويمكن كتابته أيضًا في Pug بالشكل التالي: span(class="text-success") كيف تبدو صفحة قائمة نسخ الكتب؟ شغّل التطبيق، وافتح متصفحك على العنوان "http://localhost:3000/" ثم حدد رابط جميع نسخ الكتاب All book-instances. إذا جرى إعداد كل شيء بصورة صحيحة، فيجب أن يبدو موقعك كما يلي: تنسيق التاريخ باستخدام مكتبة Luxon لا يبدو العرض الافتراضي للتواريخ في نماذجنا جميلًا: Mon Apr 10 2020 15:49:58 GMT+1100 (AUS Eastern Daylight Time) لذا سنوضح في هذا القسم كيفية تحديث صفحة قائمة نسخ الكتاب BookInstance List من القسم السابق من أجل عرض حقل due_date بتنسيق أكثر ملاءمة مثل: Apr 10th, 2023. الطريقة التي سنستخدمها هي إنشاء خاصية افتراضية في نموذج BookInstance، والتي تعيد التاريخ المُنسَّق. سنطبّق التنسيق الفعلي باستخدام مكتبة Luxon، وهي مكتبة قوية وحديثة وسهلة الاستخدام لتحليل التواريخ والتحقق من صحتها ومعالجتها وتنسيقها وجعلها تواريخًا محلية. ملاحظة: يمكن استخدام مكتبة Luxon لتنسيق السلاسل النصية مباشرةً في قوالب Pug، أو يمكننا تنسيق السلسلة النصية في عدد من الأماكن الأخرى. يتيح استخدام خاصية افتراضية الحصول على التاريخ المُنسَّق باستخدام الطريقة نفسها للحصول على تاريخ الاسترجاع due_date حاليًا. تثبيت مكتبة Luxon أدخل الأمر التالي في جذر المشروع: npm install luxon إنشاء الخاصية الافتراضية افتح الملف "./models/bookinstance.js"، ثم استورد مكتبة Luxon في أعلى هذا الملف كما يلي: const { DateTime } = require("luxon"); ضِف الخاصية الافتراضية due_back_formatted بعد خاصية URL مباشرةً. BookInstanceSchema.virtual("due_back_formatted").get(function () { return DateTime.fromJSDate(this.due_back).toLocaleString(DateTime.DATE_MED); }); ملاحظة: يمكن لمكتبة Luxon استيراد السلاسل النصية بتنسيقات متعددة وتصديرها إلى كلٍّ من التنسيقات المُعرَّفة مسبقًا والتنسيقات الحرة free-form formats، إذ نستخدم في حالتنا التابع fromJSDate() لاستيراد سلسلة تاريخ جافا سكريبت و toLocaleString() لإخراج التاريخ بتنسيق DATE_MED باللغة الإنجليزية: Apr 10th, 2023. اطلع على توثيق مكتبة Luxon الخاص بالتنسيق للحصول على معلومات حول التنسيقات الأخرى وجعل سلسلة التاريخ عالمية. تحديث العرض افتح العرض "/views/bookinstance_list.pug" وضع due_back_formatted بدلًا من due_back. if val.status != 'Available' //span (Due: #{val.due_back} ) span (Due: #{val.due_back_formatted} ) إذا انتقلت إلى جميع نسخ الكتاب All book-instances في الشريط الجانبي، فيجب أن ترى أن جميع تواريخ الاسترجاع أجمل بكثير. صفحة قائمة المؤلفين يجب أن تعرض صفحة قائمة المؤلفين قائمة بجميع المؤلفين في قاعدة البيانات، مع ربط اسم كل مؤلف برابط إلى صفحة تفاصيل المؤلف المرتبطة به، ويجب إدراج تاريخ الميلاد وتاريخ الوفاة بعد الاسم الموجود على السطر نفسه. المتحكم يجب أن تحصل دالة متحكم قائمة المؤلفين على قائمة بجميع نسخ المؤلف Author، ثم تمرّرها إلى القالب لعرضها. افتح الملف "/controllers/authorController.js"، ثم ابحث عن تابع المتحكم المُصدَّر author_list() بالقرب من أعلى الملف وضع مكانه الشيفرة البرمجية التالية: // عرض قائمة جميع المؤلفين exports.author_list = asyncHandler(async (req, res, next) => { const allAuthors = await Author.find().sort({ family_name: 1 }).exec(); res.render("author_list", { title: "Author List", author_list: allAuthors, }); }); تتبع دالة متحكم الوجهة النمط نفسه المُتبَع في صفحات القوائم الأخرى، إذ تعرّف استعلامًا لنموذج المؤلف Author باستخدام دالة find() للحصول على جميع المؤلفين والتابع sort() لفرزهم حسب family_name بترتيب أبجدي، ثم يُستدعَى التابع exec() في نهاية السلسلة التعاقبية لتنفيذ الاستعلام وإعادة الوعد الذي يمكن أن تنتظره الدالة باستخدام await. يعرض معالج الوجهة قالب author_list(.pug) بعد الوفاء بالوعد، ويمرر عنوان title الصفحة وقائمة المؤلفين (allAuthors) باستخدام مفاتيح القالب. العرض أنشئ العرض "/views/author_list.pug" وضع المحتوى التالي بدل المحتوى الموجود مسبقًا: extends layout block content h1= title ul each author in author_list li a(href=author.url) #{author.name} | (#{author.date_of_birth} - #{author.date_of_death}) else li There are no authors. شغّل التطبيق وافتح متصفحك على العنوان "http://localhost:3000/"، ثم حدد رابط جميع المؤلفين "All authors". إذا جرى إعداد كل شيء بصورة صحيحة، فيجب أن تبدو الصفحة كما يلي: ملاحظة: لا يُعَد مظهر تواريخ العمر الافتراضي للمؤلف جميلًا، ويمكنك تحسينه باستخدام الأسلوب نفسه الذي استخدمناه في قائمة نسخ الكتب BookInstance من خلال إضافة الخاصية الافتراضية للعمر الخاص بنموذج المؤلف Author. يمكن ألا يكون المؤلف ميتًا أو يمكن أن يكون لديه بيانات ولادة أو وفاة مفقودة، لذا يجب تجاهل التواريخ المفقودة أو المراجع التي تشير إلى خاصيات غير موجودة. تتمثل إحدى طرق التعامل مع ذلك في إعادة إما تاريخ مُنسَّق أو سلسلة فارغة اعتمادًا على ما إذا كانت الخاصية مُعرَّفةً أم لا، مثل: return this.date_of_birth ? DateTime.fromJSDate(this.date_of_birth).toLocaleString(DateTime.DATE_MED) : ''; صفحة قائمة أنواع الكتب Genre - التحدي يجب عليك في هذا القسم تقديم صفحة قائمة أنواع الكتب، إذ يجب أن تعرض الصفحة قائمة بجميع أنواع الكتب الموجودة في قاعدة البيانات، مع ربط كل نوع برابط إلى صفحة التفاصيل المرتبطة به بحيث تحصل على الصفحة التالية: يجب أن تحصل دالة متحكم قائمة الأنواع على قائمة بجميع نسخ الأنواع Genre، ثم تمرّرها إلى القالب لعرضها باتباع الخطوات التالية: يجب تعديل التابع genre_list() في الملف "/controllers/genreController.js". يماثل تقديم هذا التابع تقريبًا متحكم التابع author_list()، ثم يجب فرز النتائج حسب الاسم بترتيب تصاعدي. يجب تسمية القالب المراد عرضه بالاسم genre_list.pug. يجب أن يمرر القالب المراد عرضه متغيرات العنوان title (الذي هو 'Genre List') و genre_list (قائمة أنواع الكتب المُعادة من دالة رد النداء Genre.find()). يجب أن يتطابق العرض مع لقطة الشاشة أو المتطلبات السابقة، إذ يجب أن يكون له بنية أو تنسيق مشابه جدًا لعرض قائمة المؤلفين باستثناء أن أنواع الكتب لا تحتوي على تواريخ. صفحة تفاصيل أنواع الكتب Genre يجب أن تعرض صفحة تفاصيل أنواع الكتب المعلومات الخاصة بنسخة نوع كتاب معينة باستخدام قيمة الحقل _id المُولَّد تلقائيًا بوصفه المعرِّف. يُرمَّز معرّف سجل نوع الكتاب المطلوب في نهاية عنوان URL ويُستخرَج تلقائيًا بناءً على تعريف الوجهة (/genre/:id)، ثم يجري الوصول إليه ضمن المتحكم باستخدام معاملات الطلب: req.params.id. يجب أن تعرض الصفحة اسم نوع الكتاب وقائمة بجميع الكتب في هذا النوع مع روابط إلى صفحة تفاصيل كل كتاب. المتحكم افتح الملف "/controllers/genreController.js" واطلب وحدة الكتاب Book في بداية الملف، إذ يجب أن يطلب الملف باستخدام الدالة require() الوحدة Genre و "express-async-handler". const Book = require("../models/book"); ابحث عن تابع المتحكم genre_detail() المُصدَّر وضع مكانه الشيفرة البرمجية التالية: // عرض صفحة التفاصيل لنوع كتاب معين exports.genre_detail = asyncHandler(async (req, res, next) => { // الحصول على تفاصيل نوع الكتاب وجميع الكتب المرتبطة به (على التوازي) const [genre, booksInGenre] = await Promise.all([ Genre.findById(req.params.id).exec(), Book.find({ genre: req.params.id }, "title summary").exec(), ]); if (genre === null) { // لا توجد نتائج const err = new Error("Genre not found"); err.status = 404; return next(err); } res.render("genre_detail", { title: "Genre Detail", genre: genre, genre_books: booksInGenre, }); }); نستخدم التابع Genre.findById() أولًا للحصول على معلومات نوع كتاب لمعرّف معين، والتابع Book.find() للحصول على جميع سجلات الكتب التي لها نفس معرّف نوع الكتاب المرتبط بها. لا يعتمد هذان الطلبان على بعضهما، لذا نستخدم التابع Promise.all() لتشغيل استعلامات قاعدة البيانات على التوازي، إذ وضّحنا هذا الأسلوب لتشغيل الاستعلامات على التوازي عندما أنشأنا [الصفحة الرئيسية](رابط المقال السابق)). ننتظر باستخدام await الوعد المُعاد، ثم نتحقق من النتائج عندما يستقر؛ فإذا لم يكن نوع الكتاب موجودًا في قاعدة البيانات (أي يمكن أن يكون محذوفًا)، فسيعيد التابع findById() بنجاح بدون نتائج، ونريد في هذه الحالة عرض صفحة عدم وجوده "not found"، لذلك ننشئ كائن خطأ Error ونمرّره إلى دالة البرمجية الوسيطة التالية next في السلسلة. ملاحظة: تنتقل الأخطاء -المُمرَّرة إلى دالة البرمجية الوسيطة التالية next- إلى شيفرة معالجة الأخطاء التي جرى إعدادها عندما أنشأنا التطبيق الهيكلي (اطلع على قسم معالجة الأخطاء لمزيد من المعلومات). إذا عُثِر على نوع الكتاب genre، فسنستدعي التابع render() لتقديم العرض، إذ يكون قالب العرض هو genre_detail (.pug). تُمرَّر قيم title و genre و booksInGenre إلى القالب باستخدام المفاتيح المقابلة (title و genre و genre_books). العرض أنشئ العرض "/views/genre_detail.pug" وضع فيه المحتوى التالي: extends layout block content h1 Genre: #{genre.name} div(style='margin-left:20px;margin-top:20px') h4 Books dl each book in genre_books dt a(href=book.url) #{book.title} dd #{book.summary} else p This genre has no books يشابه هذا العرض جميع قوالبنا الأخرى، ولكن يتمثل الاختلاف الرئيسي في أننا لا نستخدم title المُمرَّر إلى العنوان الأول، بالرغم من استخدامه في قالب layout.pug الأساسي لضبط عنوان الصفحة. كيف تبدو صفحة تفاصيل نوع الكتاب؟ شغّل التطبيق وافتح متصفحك على العنوان "http://localhost:3000/"، ثم حدد رابط جميع أنواع الكتب "All genres"، ثم حدّد أحد هذه الأنواع مثل النوع "Fantasy". إذا جرى إعداد كل شيء بصورة صحيحة، فيجب أن تبدو صفحتك كما يلي: ملاحظة: يمكن أن تحصل على خطأ مشابه لما يلي: Cast to ObjectId failed for value " 59347139895ea23f9430ecbb" at path "_id" for model "Genre" وهو خطأ Mongoose سببه عدم تحويل req.params.id أو أي معرّف ID آخر إلى ()mongoose.Types.ObjectId، ويعود السبب الأكثر شيوعًا لذلك إلى اختلاف الرقم المعرّف عن المعرّف الحقيقي، ويمكن حل هذه المشكلة من خلال استخدام ()Mongoose.prototype.isValidObjectId لفحص المعرّف إذا كان صالحًا. صفحة تفاصيل الكتاب يجب أن تحصل صفحة تفاصيل الكتاب على المعلومات الخاصة بكتابٍ Book معين يُحدَّد باستخدام قيمة الحقل _id المُولَّد تلقائيًا، إضافةً إلى معلومات حول كل نسخة مرتبطة به في المكتبة BookInstance. ينبغي ربط أيّ مؤلف أو نوع أو نسخة كتاب نعرضها برابط إلى صفحة التفاصيل المرتبطة بهذا العنصر. المتحكم افتح الملف "/controllers/bookController.js"، وابحث عن تابع المتحكم book_detail() المُصدَّر وضع مكانه الشيفرة البرمجية التالية: // عرض صفحة تفاصيل كتاب معين exports.book_detail = asyncHandler(async (req, res, next) => { // الحصول على تفاصيل الكتب ونسخ الكتب لكتاب معين const [book, bookInstances] = await Promise.all([ Book.findById(req.params.id).populate("author").populate("genre").exec(), BookInstance.find({ book: req.params.id }).exec(), ]); if (book === null) { // لا توجد نتائج const err = new Error("Book not found"); err.status = 404; return next(err); } res.render("book_detail", { title: book.title, book: book, book_instances: bookInstances, }); }); ملاحظة: لا نحتاج إلى طلب أيّ وحدات إضافية حاليًا، إذ استوردنا مسبقًا الاعتماديات عندما قدّمنا متحكم الصفحة الرئيسية. استخدمنا الأسلوب نفسه الموضح في صفحة تفاصيل نوع الكتاب، إذ تستخدم دالةُ متحكم الوجهة التابعَ Promise.all() للاستعلام عن الكتاب Book المُحدَّد والنسخ المرتبطة به BookInstance على التوازي. إذا لم يُعثَر على كتاب مطابق، فسيُعاد كائن خطأ مع الخطأ "404: Not Found"، وإذا عُثِر على الكتاب، فستُعرَض معلومات قاعدة البيانات المسترجَعة باستخدام قالب "book_detail". نمرر results.book.title أثناء عرض صفحة الويب، نظرًا لاستخدام المفتاح "title" لإعطاء اسم لصفحة الويب كما هو مُعرَّف في ترويسة القالب "layout.pug". العرض أنشئ العرض "/views/book_detail.pug" وضِف إليه المحتوى التالي: extends layout block content h1 Title: #{book.title} p #[strong Author:] a(href=book.author.url) #{book.author.name} p #[strong Summary:] #{book.summary} p #[strong ISBN:] #{book.isbn} p #[strong Genre:] each val, index in book.genre a(href=val.url) #{val.name} if index < book.genre.length - 1 |, div(style='margin-left:20px;margin-top:20px') h4 Copies each val in book_instances hr if val.status=='Available' p.text-success #{val.status} else if val.status=='Maintenance' p.text-danger #{val.status} else p.text-warning #{val.status} p #[strong Imprint:] #{val.imprint} if val.status!='Available' p #[strong Due back:] #{val.due_back} p #[strong Id:] a(href=val.url) #{val._id} else p There are no copies of this book in the library. وضّحنا كل شيء تقريبًا في هذا القالب سابقًا، فلا حاجة للإعادة. ملاحظة: يمكن تقديم قائمة أنواع الكتب المرتبطة بالكتاب في القالب على النحو التالي، إذ تُضاف فاصلة بعد كل نوع مرتبط بالكتاب باستثناء النوع الأخير: p #[strong Genre:] each val, index in book.genre a(href=val.url) #{val.name} if index < book.genre.length - 1 |, كيف تبدو صفحة تفاصيل الكتاب؟ شغّل التطبيق وافتح متصفحك على العنوان "http://localhost:3000/"، ثم حدد رابط جميع الكتب All books، وحدد أحد هذه الكتب. إذا جرى إعداد كل شيء بصورة صحيحة، فيجب أن تبدو صفحتك كما يلي: صفحة تفاصيل المؤلف يجب أن تعرض صفحة تفاصيل المؤلف معلومات المؤلف Author، والذي يُحدَّد باستخدام قيمة الحقل _id المُولَّد تلقائيًا، إضافةً إلى قائمة بجميع كائنات الكتاب Book المرتبطة بهذا المؤلف Author. المتحكم افتح الملف "/controllers/authorController.js"، ثم ضِف السطر التالي إلى بداية الملف لطلب -باستخدام الدالة require()- الوحدة Book التي تحتاجها صفحة تفاصيل المؤلف، ويجب أن تكون الوحدات الأخرى مثل "express-async-handler" موجودة مسبقًا. const Book = require("../models/book"); ابحث عن تابع المتحكم author_detail() المُصدَّر وضع مكانه الشيفرة البرمجية التالية: // عرض صفحة تفاصيل مؤلف مُحدَّد exports.author_detail = asyncHandler(async (req, res, next) => { // الحصول على تفاصيل المؤلف وجميع كتبه (على التوازي) const [author, allBooksByAuthor] = await Promise.all([ Author.findById(req.params.id).exec(), Book.find({ author: req.params.id }, "title summary").exec(), ]); if (author === null) { // لا توجد نتائج const err = new Error("Author not found"); err.status = 404; return next(err); } res.render("author_detail", { title: "Author Detail", author: author, author_books: allBooksByAuthor, }); }); يماثل هذا الأسلوب المتبع تمامًا الأسلوب الموضح في صفحة تفاصيل نوع الكتاب، إذ تستخدم دالةُ متحكم الوجهة التابعَ Promise.all() للاستعلام عن المؤلف Author ونسخ الكتب Book المرتبطة بها على التوازي. إذا لم يُعثَر على مؤلف مطابق، فسيُرسَل كائن خطأ إلى برمجية Express الوسيطة لمعالجة الأخطاء، وإذا عُثِر على المؤلف، فستُعرَض معلومات قاعدة البيانات المُسترجَعة باستخدام قالب تفاصيل المؤلف "author_detail". العرض أنشئ العرض "/views/author_detail.pug" وضع فيه المحتوى التالي: extends layout block content h1 Author: #{author.name} p #{author.date_of_birth} - #{author.date_of_death} div(style='margin-left:20px;margin-top:20px') h4 Books dl each book in author_books dt a(href=book.url) #{book.title} dd #{book.summary} else p This author has no books. وضّحنا كل شيء تقريبًا في هذا القالب سابقًا، فلا حاجة للإعادة. كيف تبدو صفحة تفاصيل المؤلف؟ شغّل التطبيق وافتح متصفحك على العنوان "http://localhost:3000/"، ثم حدد رابط جميع المؤلفين All Authors، ثم حدد أحد المؤلفين. إذا جرى إعداد كل شيء بصورة صحيحة، فيجب أن يبدو موقعك كما يلي: ملاحظة: لا تبدو تواريخ عمر المؤلف جميلة، لذا سنحسّنها في التحدي الأخير من هذا المقال. صفحة تفاصيل نسخ الكتب BookInstance يجب أن تعرض صفحة تفاصيل نسخ الكتاب BookInstance المعلومات الخاصة بكل نسخة كتاب والمُحدَّدة باستخدام قيمة الحقل _id المُولَّد تلقائيًا، إذ تتضمن هذه المعلومات اسم الكتاب Book بوصفه رابطًا إلى صفحة تفاصيل الكتاب، إضافةً إلى معلومات أخرى في السجل. المتحكم افتح الملف "/controllers/bookinstanceController.js"، ثم ابحث عن تابع المتحكم bookinstance_detail() المُصدَّر وضع مكانه الشيفرة البرمجية التالية: // عرض صفحة تفاصيل نسخة كتاب معينة exports.bookinstance_detail = asyncHandler(async (req, res, next) => { const bookInstance = await BookInstance.findById(req.params.id) .populate("book") .exec(); if (bookInstance === null) { // لا توجد نتائج const err = new Error("Book copy not found"); err.status = 404; return next(err); } res.render("bookinstance_detail", { title: "Book:", bookinstance: bookInstance, }); }); يشابه هذا التقديم ما استخدمناه لصفحات تفاصيل النماذج الأخرى، إذ تستدعي دالة متحكم الوجهة التابع BookInstance.findById() مع معرّف نسخة كتاب معين مُستخرَج من عنوان URL (باستخدام الوجهة Route)، ويمكن الوصول إليه في المتحكم باستخدام معاملات الطلب: req.params.id، ثم تستدعي التابع populate() للحصول على تفاصيل الكتاب Book المرتبط به. إذا لم يُعثَر على نسخة كتاب BookInstance مطابقة، فسيُرسَل خطأ إلى برمجية Express الوسيطة، وإلّا فستُعرَض البيانات المُعادة باستخدام طريقة العرض bookinstance_detail.pug. العرض أنشئ العرض "/views/bookinstance_detail.pug" وضع فيه المحتوى التالي: extends layout block content h1 ID: #{bookinstance._id} p #[strong Title:] a(href=bookinstance.book.url) #{bookinstance.book.title} p #[strong Imprint:] #{bookinstance.imprint} p #[strong Status:] if bookinstance.status=='Available' span.text-success #{bookinstance.status} else if bookinstance.status=='Maintenance' span.text-danger #{bookinstance.status} else span.text-warning #{bookinstance.status} if bookinstance.status!='Available' p #[strong Due back:] #{bookinstance.due_back} وضّحنا كل شيء تقريبًا في هذا القالب سابقًا، فلا حاجة للإعادة. كيف تبدو صفحة تفاصيل نسخ الكتاب؟ شغّل التطبيق وافتح متصفحك على العنوان "http://localhost:3000/"، ثم حدّد رابط جميع نسخ الكتب All book-instances، وحدّد أحد هذه العناصر. إذا جرى إعداد كل شيء بصورة صحيحة، فيجب أن تبدو موقعك كما يلي: تحدى نفسك تستخدم معظم التواريخ المعروضة حاليًا على الموقع تنسيق جافا سكريبت الافتراضي مثل: Tue Oct 06 2020 15:49:58 GMT+1100 (AUS Eastern Daylight Time) لذا يتمثل التحدي في هذا المقال في تحسين مظهر عرض التاريخ لمعلومات عمر المؤلف Author (تاريخ الوفاة والميلاد) ولصفحات تفاصيل نسخ الكتب لاستخدام التنسيق Oct 6th, 2016. ملاحظة: يمكنك استخدام نفس الأسلوب الذي استخدمناه لقائمة نسخ الكتب في المقال السابق من خلال إضافة خاصية العمر Lifespan الافتراضية إلى نموذج المؤلف Author واستخدام مكتبة Luxon لتنسيق سلاسل التاريخ. يجب عليك اتباع الخطوات التالية لإكمال هذا التحدي: ضع المتغير due_back_formatted مكان due_back في صفحة تفاصيل نسخ الكتاب. حدّث نموذج المؤلف Author لإضافة خاصية العمر الافتراضية، إذ يجب أن يبدو مثل: date_of_birth - date_of_death، ويكون لكلا القيمتين تنسيق التاريخ BookInstance.due_back_formatted. استخدم Author.lifespan في جميع العروض حيث تستخدم حاليًا date_of_birth و date_of_death صراحةً. ترجمة -وبتصرُّف- للمقالات Home page و Book list page و BookInstance list page و Date formatting using luxon و Author list page and Genre list page challenge و Genre detail page و Book detail page و Author detail page و BookInstance detail page and challenge. اقرأ المزيد المقال السابق مقدمة إلى القوالب Template في Express: إنشاء القالب الأساسي لموقع مكتبة محلية مثالًا. تطبيق عملي لتعلم Express - الجزء الأول: إنشاء موقع ويب هيكلي لمكتبة محلية. تطبيق عملي لتعلم إطار عمل جانغو - الجزء الأول: إنشاء موقع ويب هيكلي لمكتبة محلية.
سنتعرف في هذا المقال على كيفية إنشاء الصفحة الرئيسية لموقع المكتبة المحلية LocalLibrary وصفحات قوائم الكتب والمؤلفين ونسخ الكتب وأنواعها، وسنوضح كيفية تنسيق التاريخ باستخدام المكتبة Luxon، كما سنتعرف على كيفية إنشاء صفحات تفاصيل الكتب وأنواعها ونسخها وتفاصيل المؤلفين. صفحة الموقع الرئيسية ستكون الصفحة الأولى التي سننشئها هي الصفحة الرئيسية لموقع الويب، والتي يمكن الوصول إليها إما من جذر الموقع / أو من الدليل catalog/، مما سيؤدي إلى عرض بعض النصوص الثابتة التي تصف الموقع، مع الأعداد المحسوبة ديناميكيًا لأنواع السجلات المختلفة في قاعدة البيانات. أنشأنا مسبقًا وجهةً Route للصفحة الرئيسية، ولإكمال هذه الصفحة، يجب تحديث دالة المتحكم لجلب أعداد السجلات من قاعدة البيانات وإنشاء عرض (قالب) يمكننا استخدامه لعرض الصفحة. ملاحظة: سنستخدم مكتبة Mongoose للحصول على معلومات قاعدة البيانات، لذا لا بد من إعادة قراءة قسم البحث عن السجلات من مقال استخدام قاعدة البيانات باستخدام مكتبة Mongoose. الوجهة Route أنشأنا وِجهات صفحة الفهرس في مقال الوجهات والمتحكمات، إذ عرّفنا جميع دوال الوجهات في الملف "/routes/catalog.js": // الحصول على صفحة الدليل الرئيسية router.get("/", book_controller.index); //يُربَط مع /catalog/ لأننا نستورد الوجهة مع البادئة /catalog تملك دالة متحكم الكتاب index المُمرَّرة بوصفها معاملًا (book_controller.index) تقديم بديل placeholder implementation مُعرَّف في الملف /controllers/bookController.js: exports.index = asyncHandler(async (req, res, next) => { res.send("NOT IMPLEMENTED: Site Home Page"); }); تُعَد هذه الدالة هي دالة المتحكم التي نوسّعها للحصول على معلومات من نماذجنا ثم عرضها باستخدام عرض (قالب). المتحكم Controller تحتاج دالة المتحكم index إلى جلب معلومات حول عدد سجلات الكتب Book ونسخ الكتب BookInstance (جميعها) ونسخ الكتب BookInstance (المتاحة) والمؤلفين Author وأنواع الكتب Genre الموجودة في قاعدة البيانات، وعرض هذه البيانات في قالب لإنشاء صفحة HTML، ثم إعادتها في استجابة HTTP. افتح الملف /controllers/bookController.js، إذ سترى الدالة index() المستورَدة بالقرب من أعلى الملف. const Book = require("../models/book"); const asyncHandler = require("express-async-handler"); exports.index = asyncHandler(async (req, res, next) => { res.send("NOT IMPLEMENTED: Site Home Page"); }); ضع جزء الشيفرة التالي مكان الشيفرة السابقة، فأول شيء تفعله هذه الشيفرة هو استيراد (أو طلب require()) جميع النماذج Models، إذ نحتاج إلى ذلك لأننا سنستخدمها للحصول على عدد المستندات. تطلب الشيفرة أيضًا "express-async-handler" الذي يوفّر مغلِّفًا Wrapper لالتقاط الاستثناءات التي تُرمَى في دوال معالج الوِجهة. const Book = require("../models/book"); const Author = require("../models/author"); const Genre = require("../models/genre"); const BookInstance = require("../models/bookinstance"); const asyncHandler = require("express-async-handler"); exports.index = asyncHandler(async (req, res, next) => { // الحصول على تفاصيل عدد الكتب ونسخها والمؤلفين وأنواع الكتب (على التوازي) const [ numBooks, numBookInstances, numAvailableBookInstances, numAuthors, numGenres, ] = await Promise.all([ Book.countDocuments({}).exec(), BookInstance.countDocuments({}).exec(), BookInstance.countDocuments({ status: "Available" }).exec(), Author.countDocuments({}).exec(), Genre.countDocuments({}).exec(), ]); res.render("index", { title: "Local Library Home", book_count: numBooks, book_instance_count: numBookInstances, book_instance_available_count: numAvailableBookInstances, author_count: numAuthors, genre_count: numGenres, }); }); نستخدم التابع countDocuments() للحصول على عدد نسخ كل نموذج، ويُستدعَى هذا التابع في نموذج مع مجموعة اختيارية من الشروط لمطابقتها وإعادة كائن استعلام Query. يمكن تنفيذ الاستعلام من خلال استدعاء التابع exec()، والذي يعيد وعدًا Promise إما يجري الوفاء به مع نتيجة أو يُرفض إذا كان هناك خطأ في قاعدة البيانات. تُعَد الاستعلامات الخاصة بأعداد المستندات مستقلة عن بعضها بعضًا، لذا نستخدم التابع Promise.all() لتنفيذها على التوازي، ويعيد هذا التابع وعدًا جديدًا ننتظره باستخدام await حتى ينتهي، إذ يتوقف التنفيذ مؤقتًا في هذه الدالة عند await. يجري الوفاء بالوعد الذي يعيده all() عند اكتمال جميع الاستعلامات، ويستمر تنفيذ دالة معالج الوجهة، ويملأ هذا الوعد المصفوفةَ بنتائج استعلامات قاعدة البيانات. نستدعي بعد ذلك التابع res.render()، ونحدّد عرضًا (قالبًا) بالاسم "index" وكائنات تربط نتائج استعلامات قاعدة البيانات مع قالب العرض، إذ تتوفر البيانات على شكل أزواج مفتاح-قيمة key-value، ويمكن الوصول إليها في القالب باستخدام المفتاح. لاحظ أن الشيفرة البرمجية بسيطة جدًا لأنه يمكننا افتراض نجاح استعلامات قاعدة البيانات، وإذا فشلت أيٌّ من عمليات قاعدة البيانات، فسيكتشف asyncHandler() الاستثناء المُرمَى ويمرّره إلى معالج البرمجية الوسيطة التالية next في السلسلة. العرض View افتح العرض "/views/index.pug" وضع فيه المحتوى التالي بدلًا من محتواه الموجود مسبقًا: extends layout block content h1= title p Welcome to #[em LocalLibrary], a very basic Express website developed as a tutorial example on the Mozilla Developer Network. h1 Dynamic content p The library has the following record counts: ul li #[strong Books:] !{book_count} li #[strong Copies:] !{book_instance_count} li #[strong Copies available:] !{book_instance_available_count} li #[strong Authors:] !{author_count} li #[strong Genres:] !{genre_count} يُعَد العرض واضحًا، إذ نوسّع القالب الأساسي layout.pug من خلال تعديل الكتلة block التي اسمها 'content'. سيكون العنوان h1 الأول هو النص المُهرَّب للمتغير title المُمرَّر إلى التابع render()، ولاحظ استخدام 'h1=' بحيث يجري التعامل مع النص الذي يليه بوصفه تعبير جافا سكريبت، ثم نضمّن فقرةً تعرّف بالمكتبة المحلية LocalLibrary. نسرد عدد النسخ من كل نموذج تحت عنوان المحتوى الديناميكي Dynamic content. لاحظ أن قيم القالب للبيانات هي المفاتيح المُحدَّدة عند استدعاء التابع render() في دالة معالج الوِجهة. ملاحظة: لم نهرّب قيم العد، إذ استخدمنا صيغة {}!، لأن قيم العد محسوبة، ولكن إذا وفّر المستخدمون النهائيون المعلومات، فسنهرّب المتغير لعرضه. كيف تبدو الصفحة الرئيسية؟ أنشأنا حتى الآن كل ما هو مطلوب لعرض صفحة الفهرس، لذا شغّل التطبيق وافتح متصفحك على العنوان "http://localhost:3000/". إذا جرى إعداد كل شيء بصورة صحيحة، فيجب أن يبدو موقعك كما يلي: ملاحظة: لن تتمكّن من استخدام روابط الشريط الجانبي حاليًا لأن عناوين URL والعروض والقوالب الخاصة بهذه الصفحات غير مُعرَّفة بعد، وإذا حاولت الوصول إليها، فستحصل على أخطاء مثل "NOT IMPLEMENTED: Book list" اعتمادًا على الرابط الذي تنقر عليه، إذ تُحدَّد هذه السلسلة النصية الحرفية -التي سنضع مكانها البيانات المناسبة- في المتحكمات المختلفة التي تكون موجودة ضمن الملف "controllers". صفحة قائمة الكتب سنقدّم الآن صفحة قائمة الكتب، إذ تعرض هذه الصفحة قائمةً بجميع الكتب الموجودة في قاعدة البيانات مع مؤلفها والعنوان الخاص بكل كتاب، والذي يكون رابطًا تشعبيًا hyperlink لصفحة تفاصيل الكتاب المرتبطة به. المتحكم يجب أن تحصل دالة متحكم قائمة الكتب على قائمة بجميع كائنات الكتاب Book في قاعدة البيانات، ثم تفرزها وتمرّرها إلى القالب لعرضها. افتح الملف "/controllers/bookController.js"، وابحث عن تابع المتحكم book_list() المُصدَّر وضع مكانه الشيفرة البرمجية التالية: // عرض قائمة جميع الكتب exports.book_list = asyncHandler(async (req, res, next) => { const allBooks = await Book.find({}, "title author") .sort({ title: 1 }) .populate("author") .exec(); res.render("book_list", { title: "Book List", book_list: allBooks }); }); يستدعي معالج الوجهة Route Handler الدالة find() للنموذج Book، ويختار إعادة العنوان title والمؤلف author فقط لأننا لسنا بحاجة إلى الحقول الأخرى (سيعيد أيضًا الحقل _id والحقول الافتراضية)، ويفرز النتائج حسب العنوان أبجديًا باستخدام التابع sort(). نستدعي أيضًا التابع populate() للنموذج Book مع تحديد الحقل author، مما سيؤدي إلى استبدال معرّف مؤلف الكتاب المُخزَّن بتفاصيل المؤلف الكاملة، ثم يُستدعَى التابع exec() في نهاية السلسلة التعاقبية daisy-chained لتنفيذ الاستعلام وإعادة الوعد. يستخدم معالج الوِجهة await لانتظار الوعد، مما يؤدي إلى إيقاف التنفيذ حتى استقراره. إذا جرى الوفاء بالوعد، فستُحفَظ نتائج الاستعلام في المتغير allBooks ويستمر المعالج في التنفيذ. يستدعي الجزء الأخير من معالج الوِجهة التابع render()، ويحدد القالب book_list (.pug) ويمرر قيم title و book_list إلى القالب. العرض View أنشئ العرض "/views/book_list.pug" وضع فيه المحتوى التالي: extends layout block content h1= title ul each book in book_list li a(href=book.url) #{book.title} | (#{book.author.name}) else li There are no books. يوسّع العرض القالبَ الأساسي layout.pug ويعدّل الكتلة block التي اسمها 'content'، ويعرض العنوان title الذي مرّرناه من المتحكم (باستخدام التابع render()) ويتكرر عبر المتغير book_list باستخدام صيغة each-in-else. يُنشَأ عنصر قائمة لكل كتاب، إذ تعرض هذه القائمة عنوان الكتاب كرابط إلى صفحة تفاصيل الكتاب متبوعًا باسم المؤلف، وإذا لم يكن هناك كتب في book_list، فستُنفَّذ تعليمة else، ويعرض نص عدم وجود كتب "There are no books". ملاحظة: نستخدم book.url لتوفير رابط إلى سجل تفاصيل كل كتاب (قدّمنا هذه الوجهة، ولكن لم نقدّم الصفحة الخاصة بها بعد)، وهي خاصية افتراضية لنموذج الكتاب Book الذي يستخدم الحقل _id الخاص بنسخة النموذج لإنشاء مسار عنوان URL فريد. من المهم تعريف كل كتاب على سطرين، باستخدام الشريط العمودي | في السطر الثاني، ويُعَد هذا الأسلوب ضروريًا لأنه إذا كان اسم المؤلف موجودًا في السطر السابق، فسيكون جزءًا من الرابط التشعبي. كيف تبدو صفحة قائمة الكتب؟ شغّل التطبيق (راجع قسم اختبار الوجهات من مقال الوجهات والمتحكمات للاطلاع على الأوامر ذات الصلة) وافتح متصفحك على العنوان "http://localhost:3000/"، ثم حدّد رابط "جميع الكتب All books". إذا جرى إعداد كل شيء بصورة صحيحة، فيجب أن يبدو موقعك كما يلي: صفحة قائمة نسخ الكتب BookInstance سنقدّم الآن قائمة بجميع نسخ الكتب BookInstance في المكتبة، إذ يجب أن تتضمن الصفحة عنوان الكتاب Book المرتبط بكل نسخة كتاب BookInstance (مرتبطة برابط إلى صفحة تفاصيلها) مع المعلومات الأخرى في نموذج BookInstance، بما في ذلك الحالة والناشر والمعرِّف الفريد لكل نسخة، ويجب ربط نص المعرّف الفريد برابط إلى صفحة تفاصيل نسخة الكتاب BookInstance. المتحكم يجب أن يحصل متحكم قائمة BookInstance على قائمة بجميع نسخ الكتاب، ويجب ملء معلومات الكتاب المرتبطة بها، ثم تمرير القائمة إلى القالب لعرضها. افتح الملف "/controllers/bookinstanceController.js"، وابحث عن تابع المتحكم bookinstance_list() المُصدَّر وضع مكانه الشيفرة البرمجية التالية: // عرض قائمة جميع نسخ الكتب exports.bookinstance_list = asyncHandler(async (req, res, next) => { const allBookInstances = await BookInstance.find().populate("book").exec(); res.render("bookinstance_list", { title: "Book Instance List", bookinstance_list: allBookInstances, }); }); يستدعي معالج الوجهة الدالةَ find() للنموذج BookInstance، ثم يتبعه في سلسلة تعاقبية استدعاءٌ للتابع populate() مع حقل الكتاب book، والذي سيضع مستند كتاب Book كامل مكان معرّف الكتاب المُخزَّن لكل BookInstance، ثم يُستدعَى التابع exec() في نهاية السلسلة التعاقبية لتنفيذ الاستعلام وإعادة الوعد. يستخدم معالج الوِجهة await لانتظار الوعد، مما يؤدي إلى إيقاف التنفيذ حتى استقراره. إذا جرى الوفاء بالوعد، فستُحفَظ نتائج الاستعلام في المتغير allBookInstances ويستمر المعالج في التنفيذ. يستدعي الجزء الأخير من الشيفرة البرمجية التابع render()، ويحدد القالب bookinstance_list (.pug) ويمرر قيم title و bookinstance_list إلى القالب. العرض View أنشئ العرض "/views/bookinstance_list.pug" وضع فيه المحتوى التالي: extends layout block content h1= title ul each val in bookinstance_list li a(href=val.url) #{val.book.title} : #{val.imprint} - if val.status=='Available' span.text-success #{val.status} else if val.status=='Maintenance' span.text-danger #{val.status} else span.text-warning #{val.status} if val.status!='Available' span (Due: #{val.due_back} ) else li There are no book copies in this library. يماثل هذا العرض العروض الأخرى، إذ يوسّع التخطيط، ويبدّل كتلة المحتوى content، ويعرض العنوان title المُمرَّر من المتحكم، ويتكرر عبر جميع نسخ الكتاب في bookinstance_list. نعرض لكل نسخة حالتها، وإن لم يكن الكتاب متاحًا، فسيُعرَض تاريخ استرجاعه المتوقع. قدّمنا ميزة جديدة، إذ يمكننا استخدام الصيغة النقطية بعد الوسم لإسناد صنف، لذلك سيُصرَّف span.text-success إلى <span class="text-success">، ويمكن كتابته أيضًا في Pug بالشكل التالي: span(class="text-success") كيف تبدو صفحة قائمة نسخ الكتب؟ شغّل التطبيق، وافتح متصفحك على العنوان "http://localhost:3000/" ثم حدد رابط جميع نسخ الكتاب All book-instances. إذا جرى إعداد كل شيء بصورة صحيحة، فيجب أن يبدو موقعك كما يلي: تنسيق التاريخ باستخدام مكتبة Luxon لا يبدو العرض الافتراضي للتواريخ في نماذجنا جميلًا: Mon Apr 10 2020 15:49:58 GMT+1100 (AUS Eastern Daylight Time) لذا سنوضح في هذا القسم كيفية تحديث صفحة قائمة نسخ الكتاب BookInstance List من القسم السابق من أجل عرض حقل due_date بتنسيق أكثر ملاءمة مثل: Apr 10th, 2023. الطريقة التي سنستخدمها هي إنشاء خاصية افتراضية في نموذج BookInstance، والتي تعيد التاريخ المُنسَّق. سنطبّق التنسيق الفعلي باستخدام مكتبة Luxon، وهي مكتبة قوية وحديثة وسهلة الاستخدام لتحليل التواريخ والتحقق من صحتها ومعالجتها وتنسيقها وجعلها تواريخًا محلية. ملاحظة: يمكن استخدام مكتبة Luxon لتنسيق السلاسل النصية مباشرةً في قوالب Pug، أو يمكننا تنسيق السلسلة النصية في عدد من الأماكن الأخرى. يتيح استخدام خاصية افتراضية الحصول على التاريخ المُنسَّق باستخدام الطريقة نفسها للحصول على تاريخ الاسترجاع due_date حاليًا. تثبيت مكتبة Luxon أدخل الأمر التالي في جذر المشروع: npm install luxon إنشاء الخاصية الافتراضية افتح الملف "./models/bookinstance.js"، ثم استورد مكتبة Luxon في أعلى هذا الملف كما يلي: const { DateTime } = require("luxon"); ضِف الخاصية الافتراضية due_back_formatted بعد خاصية URL مباشرةً. BookInstanceSchema.virtual("due_back_formatted").get(function () { return DateTime.fromJSDate(this.due_back).toLocaleString(DateTime.DATE_MED); }); ملاحظة: يمكن لمكتبة Luxon استيراد السلاسل النصية بتنسيقات متعددة وتصديرها إلى كلٍّ من التنسيقات المُعرَّفة مسبقًا والتنسيقات الحرة free-form formats، إذ نستخدم في حالتنا التابع fromJSDate() لاستيراد سلسلة تاريخ جافا سكريبت و toLocaleString() لإخراج التاريخ بتنسيق DATE_MED باللغة الإنجليزية: Apr 10th, 2023. اطلع على توثيق مكتبة Luxon الخاص بالتنسيق للحصول على معلومات حول التنسيقات الأخرى وجعل سلسلة التاريخ عالمية. تحديث العرض افتح العرض "/views/bookinstance_list.pug" وضع due_back_formatted بدلًا من due_back. if val.status != 'Available' //span (Due: #{val.due_back} ) span (Due: #{val.due_back_formatted} ) إذا انتقلت إلى جميع نسخ الكتاب All book-instances في الشريط الجانبي، فيجب أن ترى أن جميع تواريخ الاسترجاع أجمل بكثير. صفحة قائمة المؤلفين يجب أن تعرض صفحة قائمة المؤلفين قائمة بجميع المؤلفين في قاعدة البيانات، مع ربط اسم كل مؤلف برابط إلى صفحة تفاصيل المؤلف المرتبطة به، ويجب إدراج تاريخ الميلاد وتاريخ الوفاة بعد الاسم الموجود على السطر نفسه. المتحكم يجب أن تحصل دالة متحكم قائمة المؤلفين على قائمة بجميع نسخ المؤلف Author، ثم تمرّرها إلى القالب لعرضها. افتح الملف "/controllers/authorController.js"، ثم ابحث عن تابع المتحكم المُصدَّر author_list() بالقرب من أعلى الملف وضع مكانه الشيفرة البرمجية التالية: // عرض قائمة جميع المؤلفين exports.author_list = asyncHandler(async (req, res, next) => { const allAuthors = await Author.find().sort({ family_name: 1 }).exec(); res.render("author_list", { title: "Author List", author_list: allAuthors, }); }); تتبع دالة متحكم الوجهة النمط نفسه المُتبَع في صفحات القوائم الأخرى، إذ تعرّف استعلامًا لنموذج المؤلف Author باستخدام دالة find() للحصول على جميع المؤلفين والتابع sort() لفرزهم حسب family_name بترتيب أبجدي، ثم يُستدعَى التابع exec() في نهاية السلسلة التعاقبية لتنفيذ الاستعلام وإعادة الوعد الذي يمكن أن تنتظره الدالة باستخدام await. يعرض معالج الوجهة قالب author_list(.pug) بعد الوفاء بالوعد، ويمرر عنوان title الصفحة وقائمة المؤلفين (allAuthors) باستخدام مفاتيح القالب. العرض أنشئ العرض "/views/author_list.pug" وضع المحتوى التالي بدل المحتوى الموجود مسبقًا: extends layout block content h1= title ul each author in author_list li a(href=author.url) #{author.name} | (#{author.date_of_birth} - #{author.date_of_death}) else li There are no authors. شغّل التطبيق وافتح متصفحك على العنوان "http://localhost:3000/"، ثم حدد رابط جميع المؤلفين "All authors". إذا جرى إعداد كل شيء بصورة صحيحة، فيجب أن تبدو الصفحة كما يلي: ملاحظة: لا يُعَد مظهر تواريخ العمر الافتراضي للمؤلف جميلًا، ويمكنك تحسينه باستخدام الأسلوب نفسه الذي استخدمناه في قائمة نسخ الكتب BookInstance من خلال إضافة الخاصية الافتراضية للعمر الخاص بنموذج المؤلف Author. يمكن ألا يكون المؤلف ميتًا أو يمكن أن يكون لديه بيانات ولادة أو وفاة مفقودة، لذا يجب تجاهل التواريخ المفقودة أو المراجع التي تشير إلى خاصيات غير موجودة. تتمثل إحدى طرق التعامل مع ذلك في إعادة إما تاريخ مُنسَّق أو سلسلة فارغة اعتمادًا على ما إذا كانت الخاصية مُعرَّفةً أم لا، مثل: return this.date_of_birth ? DateTime.fromJSDate(this.date_of_birth).toLocaleString(DateTime.DATE_MED) : ''; صفحة قائمة أنواع الكتب Genre - التحدي يجب عليك في هذا القسم تقديم صفحة قائمة أنواع الكتب، إذ يجب أن تعرض الصفحة قائمة بجميع أنواع الكتب الموجودة في قاعدة البيانات، مع ربط كل نوع برابط إلى صفحة التفاصيل المرتبطة به بحيث تحصل على الصفحة التالية: يجب أن تحصل دالة متحكم قائمة الأنواع على قائمة بجميع نسخ الأنواع Genre، ثم تمرّرها إلى القالب لعرضها باتباع الخطوات التالية: يجب تعديل التابع genre_list() في الملف "/controllers/genreController.js". يماثل تقديم هذا التابع تقريبًا متحكم التابع author_list()، ثم يجب فرز النتائج حسب الاسم بترتيب تصاعدي. يجب تسمية القالب المراد عرضه بالاسم genre_list.pug. يجب أن يمرر القالب المراد عرضه متغيرات العنوان title (الذي هو 'Genre List') و genre_list (قائمة أنواع الكتب المُعادة من دالة رد النداء Genre.find()). يجب أن يتطابق العرض مع لقطة الشاشة أو المتطلبات السابقة، إذ يجب أن يكون له بنية أو تنسيق مشابه جدًا لعرض قائمة المؤلفين باستثناء أن أنواع الكتب لا تحتوي على تواريخ. صفحة تفاصيل أنواع الكتب Genre يجب أن تعرض صفحة تفاصيل أنواع الكتب المعلومات الخاصة بنسخة نوع كتاب معينة باستخدام قيمة الحقل _id المُولَّد تلقائيًا بوصفه المعرِّف. يُرمَّز معرّف سجل نوع الكتاب المطلوب في نهاية عنوان URL ويُستخرَج تلقائيًا بناءً على تعريف الوجهة (/genre/:id)، ثم يجري الوصول إليه ضمن المتحكم باستخدام معاملات الطلب: req.params.id. يجب أن تعرض الصفحة اسم نوع الكتاب وقائمة بجميع الكتب في هذا النوع مع روابط إلى صفحة تفاصيل كل كتاب. المتحكم افتح الملف "/controllers/genreController.js" واطلب وحدة الكتاب Book في بداية الملف، إذ يجب أن يطلب الملف باستخدام الدالة require() الوحدة Genre و "express-async-handler". const Book = require("../models/book"); ابحث عن تابع المتحكم genre_detail() المُصدَّر وضع مكانه الشيفرة البرمجية التالية: // عرض صفحة التفاصيل لنوع كتاب معين exports.genre_detail = asyncHandler(async (req, res, next) => { // الحصول على تفاصيل نوع الكتاب وجميع الكتب المرتبطة به (على التوازي) const [genre, booksInGenre] = await Promise.all([ Genre.findById(req.params.id).exec(), Book.find({ genre: req.params.id }, "title summary").exec(), ]); if (genre === null) { // لا توجد نتائج const err = new Error("Genre not found"); err.status = 404; return next(err); } res.render("genre_detail", { title: "Genre Detail", genre: genre, genre_books: booksInGenre, }); }); نستخدم التابع Genre.findById() أولًا للحصول على معلومات نوع كتاب لمعرّف معين، والتابع Book.find() للحصول على جميع سجلات الكتب التي لها نفس معرّف نوع الكتاب المرتبط بها. لا يعتمد هذان الطلبان على بعضهما، لذا نستخدم التابع Promise.all() لتشغيل استعلامات قاعدة البيانات على التوازي، إذ وضّحنا هذا الأسلوب لتشغيل الاستعلامات على التوازي عندما أنشأنا [الصفحة الرئيسية](رابط المقال السابق)). ننتظر باستخدام await الوعد المُعاد، ثم نتحقق من النتائج عندما يستقر؛ فإذا لم يكن نوع الكتاب موجودًا في قاعدة البيانات (أي يمكن أن يكون محذوفًا)، فسيعيد التابع findById() بنجاح بدون نتائج، ونريد في هذه الحالة عرض صفحة عدم وجوده "not found"، لذلك ننشئ كائن خطأ Error ونمرّره إلى دالة البرمجية الوسيطة التالية next في السلسلة. ملاحظة: تنتقل الأخطاء -المُمرَّرة إلى دالة البرمجية الوسيطة التالية next- إلى شيفرة معالجة الأخطاء التي جرى إعدادها عندما أنشأنا التطبيق الهيكلي (اطلع على قسم معالجة الأخطاء لمزيد من المعلومات). إذا عُثِر على نوع الكتاب genre، فسنستدعي التابع render() لتقديم العرض، إذ يكون قالب العرض هو genre_detail (.pug). تُمرَّر قيم title و genre و booksInGenre إلى القالب باستخدام المفاتيح المقابلة (title و genre و genre_books). العرض أنشئ العرض "/views/genre_detail.pug" وضع فيه المحتوى التالي: extends layout block content h1 Genre: #{genre.name} div(style='margin-left:20px;margin-top:20px') h4 Books dl each book in genre_books dt a(href=book.url) #{book.title} dd #{book.summary} else p This genre has no books يشابه هذا العرض جميع قوالبنا الأخرى، ولكن يتمثل الاختلاف الرئيسي في أننا لا نستخدم title المُمرَّر إلى العنوان الأول، بالرغم من استخدامه في قالب layout.pug الأساسي لضبط عنوان الصفحة. كيف تبدو صفحة تفاصيل نوع الكتاب؟ شغّل التطبيق وافتح متصفحك على العنوان "http://localhost:3000/"، ثم حدد رابط جميع أنواع الكتب "All genres"، ثم حدّد أحد هذه الأنواع مثل النوع "Fantasy". إذا جرى إعداد كل شيء بصورة صحيحة، فيجب أن تبدو صفحتك كما يلي: ملاحظة: يمكن أن تحصل على خطأ مشابه لما يلي: Cast to ObjectId failed for value " 59347139895ea23f9430ecbb" at path "_id" for model "Genre" وهو خطأ Mongoose سببه عدم تحويل req.params.id أو أي معرّف ID آخر إلى ()mongoose.Types.ObjectId، ويعود السبب الأكثر شيوعًا لذلك إلى اختلاف الرقم المعرّف عن المعرّف الحقيقي، ويمكن حل هذه المشكلة من خلال استخدام ()Mongoose.prototype.isValidObjectId لفحص المعرّف إذا كان صالحًا. صفحة تفاصيل الكتاب يجب أن تحصل صفحة تفاصيل الكتاب على المعلومات الخاصة بكتابٍ Book معين يُحدَّد باستخدام قيمة الحقل _id المُولَّد تلقائيًا، إضافةً إلى معلومات حول كل نسخة مرتبطة به في المكتبة BookInstance. ينبغي ربط أيّ مؤلف أو نوع أو نسخة كتاب نعرضها برابط إلى صفحة التفاصيل المرتبطة بهذا العنصر. المتحكم افتح الملف "/controllers/bookController.js"، وابحث عن تابع المتحكم book_detail() المُصدَّر وضع مكانه الشيفرة البرمجية التالية: // عرض صفحة تفاصيل كتاب معين exports.book_detail = asyncHandler(async (req, res, next) => { // الحصول على تفاصيل الكتب ونسخ الكتب لكتاب معين const [book, bookInstances] = await Promise.all([ Book.findById(req.params.id).populate("author").populate("genre").exec(), BookInstance.find({ book: req.params.id }).exec(), ]); if (book === null) { // لا توجد نتائج const err = new Error("Book not found"); err.status = 404; return next(err); } res.render("book_detail", { title: book.title, book: book, book_instances: bookInstances, }); }); ملاحظة: لا نحتاج إلى طلب أيّ وحدات إضافية حاليًا، إذ استوردنا مسبقًا الاعتماديات عندما قدّمنا متحكم الصفحة الرئيسية. استخدمنا الأسلوب نفسه الموضح في صفحة تفاصيل نوع الكتاب، إذ تستخدم دالةُ متحكم الوجهة التابعَ Promise.all() للاستعلام عن الكتاب Book المُحدَّد والنسخ المرتبطة به BookInstance على التوازي. إذا لم يُعثَر على كتاب مطابق، فسيُعاد كائن خطأ مع الخطأ "404: Not Found"، وإذا عُثِر على الكتاب، فستُعرَض معلومات قاعدة البيانات المسترجَعة باستخدام قالب "book_detail". نمرر results.book.title أثناء عرض صفحة الويب، نظرًا لاستخدام المفتاح "title" لإعطاء اسم لصفحة الويب كما هو مُعرَّف في ترويسة القالب "layout.pug". العرض أنشئ العرض "/views/book_detail.pug" وضِف إليه المحتوى التالي: extends layout block content h1 Title: #{book.title} p #[strong Author:] a(href=book.author.url) #{book.author.name} p #[strong Summary:] #{book.summary} p #[strong ISBN:] #{book.isbn} p #[strong Genre:] each val, index in book.genre a(href=val.url) #{val.name} if index < book.genre.length - 1 |, div(style='margin-left:20px;margin-top:20px') h4 Copies each val in book_instances hr if val.status=='Available' p.text-success #{val.status} else if val.status=='Maintenance' p.text-danger #{val.status} else p.text-warning #{val.status} p #[strong Imprint:] #{val.imprint} if val.status!='Available' p #[strong Due back:] #{val.due_back} p #[strong Id:] a(href=val.url) #{val._id} else p There are no copies of this book in the library. وضّحنا كل شيء تقريبًا في هذا القالب سابقًا، فلا حاجة للإعادة. ملاحظة: يمكن تقديم قائمة أنواع الكتب المرتبطة بالكتاب في القالب على النحو التالي، إذ تُضاف فاصلة بعد كل نوع مرتبط بالكتاب باستثناء النوع الأخير: p #[strong Genre:] each val, index in book.genre a(href=val.url) #{val.name} if index < book.genre.length - 1 |, كيف تبدو صفحة تفاصيل الكتاب؟ شغّل التطبيق وافتح متصفحك على العنوان "http://localhost:3000/"، ثم حدد رابط جميع الكتب All books، وحدد أحد هذه الكتب. إذا جرى إعداد كل شيء بصورة صحيحة، فيجب أن تبدو صفحتك كما يلي: صفحة تفاصيل المؤلف يجب أن تعرض صفحة تفاصيل المؤلف معلومات المؤلف Author، والذي يُحدَّد باستخدام قيمة الحقل _id المُولَّد تلقائيًا، إضافةً إلى قائمة بجميع كائنات الكتاب Book المرتبطة بهذا المؤلف Author. المتحكم افتح الملف "/controllers/authorController.js"، ثم ضِف السطر التالي إلى بداية الملف لطلب -باستخدام الدالة require()- الوحدة Book التي تحتاجها صفحة تفاصيل المؤلف، ويجب أن تكون الوحدات الأخرى مثل "express-async-handler" موجودة مسبقًا. const Book = require("../models/book"); ابحث عن تابع المتحكم author_detail() المُصدَّر وضع مكانه الشيفرة البرمجية التالية: // عرض صفحة تفاصيل مؤلف مُحدَّد exports.author_detail = asyncHandler(async (req, res, next) => { // الحصول على تفاصيل المؤلف وجميع كتبه (على التوازي) const [author, allBooksByAuthor] = await Promise.all([ Author.findById(req.params.id).exec(), Book.find({ author: req.params.id }, "title summary").exec(), ]); if (author === null) { // لا توجد نتائج const err = new Error("Author not found"); err.status = 404; return next(err); } res.render("author_detail", { title: "Author Detail", author: author, author_books: allBooksByAuthor, }); }); يماثل هذا الأسلوب المتبع تمامًا الأسلوب الموضح في صفحة تفاصيل نوع الكتاب، إذ تستخدم دالةُ متحكم الوجهة التابعَ Promise.all() للاستعلام عن المؤلف Author ونسخ الكتب Book المرتبطة بها على التوازي. إذا لم يُعثَر على مؤلف مطابق، فسيُرسَل كائن خطأ إلى برمجية Express الوسيطة لمعالجة الأخطاء، وإذا عُثِر على المؤلف، فستُعرَض معلومات قاعدة البيانات المُسترجَعة باستخدام قالب تفاصيل المؤلف "author_detail". العرض أنشئ العرض "/views/author_detail.pug" وضع فيه المحتوى التالي: extends layout block content h1 Author: #{author.name} p #{author.date_of_birth} - #{author.date_of_death} div(style='margin-left:20px;margin-top:20px') h4 Books dl each book in author_books dt a(href=book.url) #{book.title} dd #{book.summary} else p This author has no books. وضّحنا كل شيء تقريبًا في هذا القالب سابقًا، فلا حاجة للإعادة. كيف تبدو صفحة تفاصيل المؤلف؟ شغّل التطبيق وافتح متصفحك على العنوان "http://localhost:3000/"، ثم حدد رابط جميع المؤلفين All Authors، ثم حدد أحد المؤلفين. إذا جرى إعداد كل شيء بصورة صحيحة، فيجب أن يبدو موقعك كما يلي: ملاحظة: لا تبدو تواريخ عمر المؤلف جميلة، لذا سنحسّنها في التحدي الأخير من هذا المقال. صفحة تفاصيل نسخ الكتب BookInstance يجب أن تعرض صفحة تفاصيل نسخ الكتاب BookInstance المعلومات الخاصة بكل نسخة كتاب والمُحدَّدة باستخدام قيمة الحقل _id المُولَّد تلقائيًا، إذ تتضمن هذه المعلومات اسم الكتاب Book بوصفه رابطًا إلى صفحة تفاصيل الكتاب، إضافةً إلى معلومات أخرى في السجل. المتحكم افتح الملف "/controllers/bookinstanceController.js"، ثم ابحث عن تابع المتحكم bookinstance_detail() المُصدَّر وضع مكانه الشيفرة البرمجية التالية: // عرض صفحة تفاصيل نسخة كتاب معينة exports.bookinstance_detail = asyncHandler(async (req, res, next) => { const bookInstance = await BookInstance.findById(req.params.id) .populate("book") .exec(); if (bookInstance === null) { // لا توجد نتائج const err = new Error("Book copy not found"); err.status = 404; return next(err); } res.render("bookinstance_detail", { title: "Book:", bookinstance: bookInstance, }); }); يشابه هذا التقديم ما استخدمناه لصفحات تفاصيل النماذج الأخرى، إذ تستدعي دالة متحكم الوجهة التابع BookInstance.findById() مع معرّف نسخة كتاب معين مُستخرَج من عنوان URL (باستخدام الوجهة Route)، ويمكن الوصول إليه في المتحكم باستخدام معاملات الطلب: req.params.id، ثم تستدعي التابع populate() للحصول على تفاصيل الكتاب Book المرتبط به. إذا لم يُعثَر على نسخة كتاب BookInstance مطابقة، فسيُرسَل خطأ إلى برمجية Express الوسيطة، وإلّا فستُعرَض البيانات المُعادة باستخدام طريقة العرض bookinstance_detail.pug. العرض أنشئ العرض "/views/bookinstance_detail.pug" وضع فيه المحتوى التالي: extends layout block content h1 ID: #{bookinstance._id} p #[strong Title:] a(href=bookinstance.book.url) #{bookinstance.book.title} p #[strong Imprint:] #{bookinstance.imprint} p #[strong Status:] if bookinstance.status=='Available' span.text-success #{bookinstance.status} else if bookinstance.status=='Maintenance' span.text-danger #{bookinstance.status} else span.text-warning #{bookinstance.status} if bookinstance.status!='Available' p #[strong Due back:] #{bookinstance.due_back} وضّحنا كل شيء تقريبًا في هذا القالب سابقًا، فلا حاجة للإعادة. كيف تبدو صفحة تفاصيل نسخ الكتاب؟ شغّل التطبيق وافتح متصفحك على العنوان "http://localhost:3000/"، ثم حدّد رابط جميع نسخ الكتب All book-instances، وحدّد أحد هذه العناصر. إذا جرى إعداد كل شيء بصورة صحيحة، فيجب أن تبدو موقعك كما يلي: تحدى نفسك تستخدم معظم التواريخ المعروضة حاليًا على الموقع تنسيق جافا سكريبت الافتراضي مثل: Tue Oct 06 2020 15:49:58 GMT+1100 (AUS Eastern Daylight Time) لذا يتمثل التحدي في هذا المقال في تحسين مظهر عرض التاريخ لمعلومات عمر المؤلف Author (تاريخ الوفاة والميلاد) ولصفحات تفاصيل نسخ الكتب لاستخدام التنسيق Oct 6th, 2016. ملاحظة: يمكنك استخدام نفس الأسلوب الذي استخدمناه لقائمة نسخ الكتب في المقال السابق من خلال إضافة خاصية العمر Lifespan الافتراضية إلى نموذج المؤلف Author واستخدام مكتبة Luxon لتنسيق سلاسل التاريخ. يجب عليك اتباع الخطوات التالية لإكمال هذا التحدي: ضع المتغير due_back_formatted مكان due_back في صفحة تفاصيل نسخ الكتاب. حدّث نموذج المؤلف Author لإضافة خاصية العمر الافتراضية، إذ يجب أن يبدو مثل: date_of_birth - date_of_death، ويكون لكلا القيمتين تنسيق التاريخ BookInstance.due_back_formatted. استخدم Author.lifespan في جميع العروض حيث تستخدم حاليًا date_of_birth و date_of_death صراحةً. ترجمة -وبتصرُّف- للمقالات Home page و Book list page و BookInstance list page و Date formatting using luxon و Author list page and Genre list page challenge و Genre detail page و Book detail page و Author detail page و BookInstance detail page and challenge. اقرأ المزيد المقال السابق مقدمة إلى القوالب Template في Express: إنشاء القالب الأساسي لموقع مكتبة محلية مثالًا. تطبيق عملي لتعلم Express - الجزء الأول: إنشاء موقع ويب هيكلي لمكتبة محلية. تطبيق عملي لتعلم إطار عمل جانغو - الجزء الأول: إنشاء موقع ويب هيكلي لمكتبة محلية. -
 القالب Template هو ملف نصي يحدّد بنية أو تخطيط ملف الخرج مع استخدام العناصر البديلة لتمثيل مكان إدراج البيانات عند عرض القالب، ويُشار إلى القوالب في إطار عمل Express بوصفها عروضًا Views. خيارات قوالب Express يمكن استخدام إطار عمل Express مع العديد من محرّكات عرض القوالب المختلفة، إذ سنستخدم في هذا المقال Pug (المعروفة سابقًا باسم Jade) لقوالبنا، والتي تُعَد لغة قوالب Node الأكثر شيوعًا، وتصف نفسها بأنها صيغة نظيفة وحساسة للمسافات لكتابة شيفرة HTML وهي متأثرة كثيرًا بلغة Haml. تستخدم لغات القوالب المختلفة طرقًا مختلفة لتعريف التخطيط Layout وتحديد العناصر البديلة للبيانات، إذ يستخدم بعضها شيفرة HTML لتعريف التخطيط، ويستخدم بعضها الآخر تنسيقات توصيف مختلفة يمكن تحويلها إلى شيفرة HTML. تُعَد Pug من النوع الثاني، إذ تستخدم تمثيلًا للغة HTML، إذ تُمثَّل الكلمةُ الأولى في أيّ سطر عنصرَ HTML، وتُستخدَم المسافة البادئة في الأسطر اللاحقة لتمثيل التداخل، وتكون النتيجة تعريف صفحة تُترجَم مباشرةً إلى شيفرة HTML، ولكنها أكثر إيجازًا وأسهل قراءة. ملاحظة: سلبية استخدام Pug أنها حساسة للمسافات البادئة والمسافات البيضاء، فإذا أضفتَ مسافة إضافية في المكان الخطأ، فقد تحصل على رمز خطأ غير مساعد، ولكن يصبح من السهل جدًا قراءة قوالبك وصيانتها بعد الانتهاء منها. ضبط القوالب ضبطنا موقع المكتبة المحلية LocalLibrary لاستخدام Pug عندما أنشأنا موقع الويب الهيكلي، إذ يجب أن تُضمَّن وحدة pug بوصفها اعتمادية في ملف package.json الخاص بموقع الويب، ويجب أن ترى إعدادات الضبط التالية في الملف app.js؛ إذ تخبرنا هذه الإعدادات أننا نستخدم Pug بوصفها محرّك عرض، وأن إطار عمل Express يجب أن يبحث عن القوالب في المجلد الفرعي "/views". // إعداد محرك العروض app.set("views", path.join(__dirname, "views")); app.set("view engine", "pug"); إذا بحثتَ في مجلد العروض views، فسترى ملفات ".pug" للعروض الافتراضية الخاصة بالمشروع، ويتضمن ذلك عرض الصفحة الرئيسية index.pug والقالب الأساسي layout.pug الذي يجب أن نضع مكانه محتوانا. /express-locallibrary-tutorial //the project root /views error.pug index.pug layout.pug صيغة القوالب يوضّح ملف القالب التالي العديد من ميزات Pug الأكثر فائدة، فأول شيء يجب ملاحظته هو أن الملف يربط بنية ملف HTML نموذجي مع الكلمة الأولى في كل سطر (تقريبًا) التي تكون عنصر HTML، ومع المسافة البادئة التي تُستخدَم للإشارة إلى العناصر المتداخلة، فمثلًا يوجد عنصر body داخل عنصر html، وتوجد عناصر الفقرة (p) داخل عنصر body وغير ذلك، وتكون العناصر غير المتداخلة مثل الفقرات الفردية موجودةً في أسطر منفصلة. doctype html html(lang="en") head title= title script(type='text/javascript'). body h1= title p This is a line with #[em some emphasis] and #[strong strong text] markup. p This line has un-escaped data: !{'<em> is emphasized</em>'} and escaped data: #{'<em> is not emphasized</em>'}. | This line follows on. p= 'Evaluated and <em>escaped expression</em>:' + title <!-- مباشرةً HTML يمكنك إضافة تعليقات--> // يمكنك إضافة تعليقات جافاسكربت ذات سطر واحد وتُنشَأ في تعليقات HTML //- يضمن تقديم تعليق جافاسكربت مؤلف من سطر واحد مع "-//" عدم عرض التعليق بوصفه شيفرة HTML p A line with a link a(href='/catalog/authors') Some link text | and some extra text. #container.col if title p A variable named "title" exists. else p A variable named "title" does not exist. p. Pug is a terse and simple template language with a strong focus on performance and powerful features. h2 Generate a list ul each val in [1, 2, 3, 4, 5] li= val تُعرَّف سمات العنصر بين أقواس بعد العنصر المرتبط بها، وتُعرَّف السمات ضمن الأقواس في قوائم مفصولٌ بينها بفواصل أو بمسافات بيضاء لأزواج أسماء السمات وقيمها مثل: script(type='text/javascript'), link(rel='stylesheet', href='/stylesheets/style.css') أو meta(name='viewport' content='width=device-width initial-scale=1') جرى تهريب escaped قيم جميع السمات مثل تحويل محارف مثل المحرف "<" إلى ما يكافئها من شيفرة HTML مثل ">" لمنع هجمات حقن شيفرة جافا سكريبت أو هجمات السكريبتات العابرة للمواقع cross-site scripting attacks - أو اختصارًا XSS. إذا كان الوسم متبوعًا بعلامة مساواة، فسيُتعامَل مع النص التالي بوصفه تعبير جافا سكريبت، فمثلًا سيكون محتوى الوسم h1 في السطر الأول متغير title (إما مُعرَّفًا في الملف أو مُمرَّرًا إلى القالب من إطار عمل Express). يكون محتوى الفقرة في السطر الثاني سلسلة نصية متعاقبة مع المتغير title. يكون السلوك الافتراضي في كلتا الحالتين هو تهريب السطر. h1= title p= 'Evaluated and <em>escaped expression</em>:' + title إذا لم يكن هناك رمز مساواة بعد الوسم، فسيُتعامَل مع المحتوى بوصفه نصًا عاديًا، إذ يمكنك ضمن النص العادي إدخال البيانات التي جرى تهريبها والتي لم يجرِ تهريبها باستخدام الصيغتين {}# و {}! على التوالي، ويمكنك أيضًا إضافة شيفرة HTML خام ضمن النص العادي. p This is a line with #[em some emphasis] and #[strong strong text] markup. p This line has an un-escaped string: !{'<em> is emphasized</em>'}, an escaped string: #{'<em> is not emphasized</em>'}, and escaped variables: #{title}. ملاحظة: سترغب دائمًا في تهريب البيانات من المستخدمين باستخدام صيغة {}#، وقد تُعرَض البيانات التي يمكن الوثوق بها، مثل أعداد السجلات المُولَّدة وما إلى ذلك دون تهريب القيم. يمكنك استخدام محرف الشريط العمودي ('|') في بداية السطر للإشارة إلى النص العادي، فمثلًا سيُعرَض النص الإضافي التالي على سطر الرابط نفسه، ولكنه لن يمثل رابطًا: a(href='http://someurl/') Link text | Plain text تسمح Pug بإجراء عمليات شرطية باستخدام if و else و else if و unless مثل: if title p A variable named "title" exists else p A variable named "title" does not exist يمكنك أيضًا إجراء عمليات الحلقة أو التكرار باستخدام صيغة each-in أو while، إذ أنشأنا في جزء الشيفرة البرمجية التالي حلقةً تكرارية تمر عبر عناصر مصفوفة لعرض قائمة متغيرات. لاحظ استخدام ''li=' لتقييم "val" بوصفه متغيرًا، ويمكن أيضًا تمرير القيمة التي تكررها إلى القالب بوصفها متغيرًا. ul each val in [1, 2, 3, 4, 5] li= val تدعم الصيغة أيضًا التعليقات (التي يمكن عرضها في الخرج أو عدم عرضها وفق ما تريده)، والمخاليط Mixins لإنشاء كتل من الشيفرة البرمجية قابلة لإعادة الاستخدام، وتعليمات الحالة، والعديد من الميزات الأخرى. اطلع على توثيق Pug لمزيد من المعلومات. توسيع القوالب من المعتاد أن يكون لجميع الصفحات بنية مشتركة عبر الموقع، بما في ذلك شيفرة HTML المعيارية لرأس وتذييل الصفحة وقسم التنقل navigation وغير ذلك، لذا تسمح Pug بالتصريح عن قالب أساسي ثم توسيعه، وتبديل الأجزاء المختلفة من كل صفحة بدلًا من إجبار المطورين على تكرار هذه الشيفرة المتداولة "Boilerplate" في كل صفحة. يبدو مثلًا القالب الأساسي layout.pug الذي أنشأناه في المشروع الهيكلي كما يلي: doctype html html head title= title link(rel='stylesheet', href='/stylesheets/style.css') body block content يُستخدَم الوسم block لتمييز أقسام المحتوى التي يمكن استبدالها في قالب مشتق، فإن لم يُعاد تعريف الكتلة، فسيُستخدَم تقديمها في الصنف الأساسي. يوضح القالب index.pug الافتراضي -الذي أنشأناه لمشروعنا الهيكلي- كيفية تعديل القالب الأساسي، إذ يحدّد الوسم extends القالب الأساسي المراد استخدامه، ثم نستخدم block section_name للإشارة إلى المحتوى الجديد للقسم الذي سنعدّله. extends layout block content h1= title p Welcome to #{title} القالب الأساسي لموقع المكتبة المحلية LocalLibrary فهمنا كيفية توسيع القوالب باستخدام Pug، وسنبدأ الآن بإنشاء قالب أساسي لمشروعنا، والذي سيحتوي على شريط جانبي مع روابط للصفحات التي نريد إنشائها في المقالات لاحقًا مثل صفحات عرض وإنشاء الكتب وأنواعها والمؤلفين وغير ذلك، وسيحتوي على منطقة للمحتوى الرئيسي سنعدّلها في كل صفحة من صفحاتنا. افتح القالب /views/layout.pug وضع الشيفرة التالية مكان المحتوى الموجود مسبقًا: doctype html html(lang='en') head title= title meta(charset='utf-8') meta(name='viewport', content='width=device-width, initial-scale=1') link(rel="stylesheet", href="https://cdn.jsdelivr.net/npm/bootstrap@4.6.2/dist/css/bootstrap.min.css", integrity="sha384-xOolHFLEh07PJGoPkLv1IbcEPTNtaed2xpHsD9ESMhqIYd0nLMwNLD69Npy4HI+N", crossorigin="anonymous") script(src="https://code.jquery.com/jquery-3.5.1.slim.min.js", integrity="sha384-DfXdz2htPH0lsSSs5nCTpuj/zy4C+OGpamoFVy38MVBnE+IbbVYUew+OrCXaRkfj", crossorigin="anonymous") script(src="https://cdn.jsdelivr.net/npm/bootstrap@4.6.2/dist/js/bootstrap.min.js", integrity="sha384-+sLIOodYLS7CIrQpBjl+C7nPvqq+FbNUBDunl/OZv93DB7Ln/533i8e/mZXLi/P+", crossorigin="anonymous") link(rel='stylesheet', href='/stylesheets/style.css') body div(class='container-fluid') div(class='row') div(class='col-sm-2') block sidebar ul(class='sidebar-nav') li a(href='/catalog') Home li a(href='/catalog/books') All books li a(href='/catalog/authors') All authors li a(href='/catalog/genres') All genres li a(href='/catalog/bookinstances') All book-instances li hr li a(href='/catalog/author/create') Create new author li a(href='/catalog/genre/create') Create new genre li a(href='/catalog/book/create') Create new book li a(href='/catalog/bookinstance/create') Create new book instance (copy) div(class='col-sm-10') block content يتضمن القالب شيفرة جافا سكريبت و CSS من بوتستراب Bootstrap لتحسين تخطيط وعرض صفحة HTML؛ إذ يُعَد استخدام بوتستراب أو أي إطار عمل ويب آخر من طرف العميل طريقةً سريعة لإنشاء صفحة جذابة يمكن أن تتناسب مع أحجام المتصفحات المختلفة، ويتيح أيضًا التعامل مع عرض الصفحة دون الحاجة إلى الدخول في التفاصيل، إذ نريد فقط التركيز على الشيفرة البرمجية من طرف الخادم حاليًا. ملاحظة: تكون السكربتات مُحمَّلة على أصول مختلطة، لذا يجب السماح صراحةً بتحميل هذه الملفات لاحقًا عندما نضيف برمجية وسيطة للأمان. اطلع على فقرة استخدام حزمة Helmet للحماية من الثغرات المعروفة من مقال النشر في بيئة الإنتاج لمزيد من المعلومات. يجب أن يكون التخطيط واضحًا إلى حدٍ ما إذا قرأت القسم السابق. لاحظ استخدام كتلة block content بوصفها عنصرًا بديلًا للمكان الذي سيوضع فيه محتوى صفحاتنا. يشير القالب الأساسي أيضًا إلى ملف CSS محلي (style.css) الذي يوفر بعض التنسيق الإضافي. افتح الملف "/public/stylesheets/style.css" وضع شيفرة CSS التالية مكان محتواه: .sidebar-nav { margin-top: 20px; padding: 0; list-style: none; } لدينا الآن قالب أساسي لإنشاء صفحات مع شريط جانبي، وسنستخدمه في المقالات التالية لتعريف الصفحات الفردية. ترجمة -وبتصرُّف- للمقالين Template primer و LocalLibrary base template. اقرأ المزيد المقال السابق: تطبيق عملي لتعلم Express - الجزء الخامس: النشر في بيئة الإنتاج كيفية استخدام القوالب في تطبيقات فلاسك Flask. مدخل إلى إطار عمل الويب Express وبيئة Node مدخل إلى express إنشاء مدوّنة باستخدام Node.js و Express (الجزء الأول)
القالب Template هو ملف نصي يحدّد بنية أو تخطيط ملف الخرج مع استخدام العناصر البديلة لتمثيل مكان إدراج البيانات عند عرض القالب، ويُشار إلى القوالب في إطار عمل Express بوصفها عروضًا Views. خيارات قوالب Express يمكن استخدام إطار عمل Express مع العديد من محرّكات عرض القوالب المختلفة، إذ سنستخدم في هذا المقال Pug (المعروفة سابقًا باسم Jade) لقوالبنا، والتي تُعَد لغة قوالب Node الأكثر شيوعًا، وتصف نفسها بأنها صيغة نظيفة وحساسة للمسافات لكتابة شيفرة HTML وهي متأثرة كثيرًا بلغة Haml. تستخدم لغات القوالب المختلفة طرقًا مختلفة لتعريف التخطيط Layout وتحديد العناصر البديلة للبيانات، إذ يستخدم بعضها شيفرة HTML لتعريف التخطيط، ويستخدم بعضها الآخر تنسيقات توصيف مختلفة يمكن تحويلها إلى شيفرة HTML. تُعَد Pug من النوع الثاني، إذ تستخدم تمثيلًا للغة HTML، إذ تُمثَّل الكلمةُ الأولى في أيّ سطر عنصرَ HTML، وتُستخدَم المسافة البادئة في الأسطر اللاحقة لتمثيل التداخل، وتكون النتيجة تعريف صفحة تُترجَم مباشرةً إلى شيفرة HTML، ولكنها أكثر إيجازًا وأسهل قراءة. ملاحظة: سلبية استخدام Pug أنها حساسة للمسافات البادئة والمسافات البيضاء، فإذا أضفتَ مسافة إضافية في المكان الخطأ، فقد تحصل على رمز خطأ غير مساعد، ولكن يصبح من السهل جدًا قراءة قوالبك وصيانتها بعد الانتهاء منها. ضبط القوالب ضبطنا موقع المكتبة المحلية LocalLibrary لاستخدام Pug عندما أنشأنا موقع الويب الهيكلي، إذ يجب أن تُضمَّن وحدة pug بوصفها اعتمادية في ملف package.json الخاص بموقع الويب، ويجب أن ترى إعدادات الضبط التالية في الملف app.js؛ إذ تخبرنا هذه الإعدادات أننا نستخدم Pug بوصفها محرّك عرض، وأن إطار عمل Express يجب أن يبحث عن القوالب في المجلد الفرعي "/views". // إعداد محرك العروض app.set("views", path.join(__dirname, "views")); app.set("view engine", "pug"); إذا بحثتَ في مجلد العروض views، فسترى ملفات ".pug" للعروض الافتراضية الخاصة بالمشروع، ويتضمن ذلك عرض الصفحة الرئيسية index.pug والقالب الأساسي layout.pug الذي يجب أن نضع مكانه محتوانا. /express-locallibrary-tutorial //the project root /views error.pug index.pug layout.pug صيغة القوالب يوضّح ملف القالب التالي العديد من ميزات Pug الأكثر فائدة، فأول شيء يجب ملاحظته هو أن الملف يربط بنية ملف HTML نموذجي مع الكلمة الأولى في كل سطر (تقريبًا) التي تكون عنصر HTML، ومع المسافة البادئة التي تُستخدَم للإشارة إلى العناصر المتداخلة، فمثلًا يوجد عنصر body داخل عنصر html، وتوجد عناصر الفقرة (p) داخل عنصر body وغير ذلك، وتكون العناصر غير المتداخلة مثل الفقرات الفردية موجودةً في أسطر منفصلة. doctype html html(lang="en") head title= title script(type='text/javascript'). body h1= title p This is a line with #[em some emphasis] and #[strong strong text] markup. p This line has un-escaped data: !{'<em> is emphasized</em>'} and escaped data: #{'<em> is not emphasized</em>'}. | This line follows on. p= 'Evaluated and <em>escaped expression</em>:' + title <!-- مباشرةً HTML يمكنك إضافة تعليقات--> // يمكنك إضافة تعليقات جافاسكربت ذات سطر واحد وتُنشَأ في تعليقات HTML //- يضمن تقديم تعليق جافاسكربت مؤلف من سطر واحد مع "-//" عدم عرض التعليق بوصفه شيفرة HTML p A line with a link a(href='/catalog/authors') Some link text | and some extra text. #container.col if title p A variable named "title" exists. else p A variable named "title" does not exist. p. Pug is a terse and simple template language with a strong focus on performance and powerful features. h2 Generate a list ul each val in [1, 2, 3, 4, 5] li= val تُعرَّف سمات العنصر بين أقواس بعد العنصر المرتبط بها، وتُعرَّف السمات ضمن الأقواس في قوائم مفصولٌ بينها بفواصل أو بمسافات بيضاء لأزواج أسماء السمات وقيمها مثل: script(type='text/javascript'), link(rel='stylesheet', href='/stylesheets/style.css') أو meta(name='viewport' content='width=device-width initial-scale=1') جرى تهريب escaped قيم جميع السمات مثل تحويل محارف مثل المحرف "<" إلى ما يكافئها من شيفرة HTML مثل ">" لمنع هجمات حقن شيفرة جافا سكريبت أو هجمات السكريبتات العابرة للمواقع cross-site scripting attacks - أو اختصارًا XSS. إذا كان الوسم متبوعًا بعلامة مساواة، فسيُتعامَل مع النص التالي بوصفه تعبير جافا سكريبت، فمثلًا سيكون محتوى الوسم h1 في السطر الأول متغير title (إما مُعرَّفًا في الملف أو مُمرَّرًا إلى القالب من إطار عمل Express). يكون محتوى الفقرة في السطر الثاني سلسلة نصية متعاقبة مع المتغير title. يكون السلوك الافتراضي في كلتا الحالتين هو تهريب السطر. h1= title p= 'Evaluated and <em>escaped expression</em>:' + title إذا لم يكن هناك رمز مساواة بعد الوسم، فسيُتعامَل مع المحتوى بوصفه نصًا عاديًا، إذ يمكنك ضمن النص العادي إدخال البيانات التي جرى تهريبها والتي لم يجرِ تهريبها باستخدام الصيغتين {}# و {}! على التوالي، ويمكنك أيضًا إضافة شيفرة HTML خام ضمن النص العادي. p This is a line with #[em some emphasis] and #[strong strong text] markup. p This line has an un-escaped string: !{'<em> is emphasized</em>'}, an escaped string: #{'<em> is not emphasized</em>'}, and escaped variables: #{title}. ملاحظة: سترغب دائمًا في تهريب البيانات من المستخدمين باستخدام صيغة {}#، وقد تُعرَض البيانات التي يمكن الوثوق بها، مثل أعداد السجلات المُولَّدة وما إلى ذلك دون تهريب القيم. يمكنك استخدام محرف الشريط العمودي ('|') في بداية السطر للإشارة إلى النص العادي، فمثلًا سيُعرَض النص الإضافي التالي على سطر الرابط نفسه، ولكنه لن يمثل رابطًا: a(href='http://someurl/') Link text | Plain text تسمح Pug بإجراء عمليات شرطية باستخدام if و else و else if و unless مثل: if title p A variable named "title" exists else p A variable named "title" does not exist يمكنك أيضًا إجراء عمليات الحلقة أو التكرار باستخدام صيغة each-in أو while، إذ أنشأنا في جزء الشيفرة البرمجية التالي حلقةً تكرارية تمر عبر عناصر مصفوفة لعرض قائمة متغيرات. لاحظ استخدام ''li=' لتقييم "val" بوصفه متغيرًا، ويمكن أيضًا تمرير القيمة التي تكررها إلى القالب بوصفها متغيرًا. ul each val in [1, 2, 3, 4, 5] li= val تدعم الصيغة أيضًا التعليقات (التي يمكن عرضها في الخرج أو عدم عرضها وفق ما تريده)، والمخاليط Mixins لإنشاء كتل من الشيفرة البرمجية قابلة لإعادة الاستخدام، وتعليمات الحالة، والعديد من الميزات الأخرى. اطلع على توثيق Pug لمزيد من المعلومات. توسيع القوالب من المعتاد أن يكون لجميع الصفحات بنية مشتركة عبر الموقع، بما في ذلك شيفرة HTML المعيارية لرأس وتذييل الصفحة وقسم التنقل navigation وغير ذلك، لذا تسمح Pug بالتصريح عن قالب أساسي ثم توسيعه، وتبديل الأجزاء المختلفة من كل صفحة بدلًا من إجبار المطورين على تكرار هذه الشيفرة المتداولة "Boilerplate" في كل صفحة. يبدو مثلًا القالب الأساسي layout.pug الذي أنشأناه في المشروع الهيكلي كما يلي: doctype html html head title= title link(rel='stylesheet', href='/stylesheets/style.css') body block content يُستخدَم الوسم block لتمييز أقسام المحتوى التي يمكن استبدالها في قالب مشتق، فإن لم يُعاد تعريف الكتلة، فسيُستخدَم تقديمها في الصنف الأساسي. يوضح القالب index.pug الافتراضي -الذي أنشأناه لمشروعنا الهيكلي- كيفية تعديل القالب الأساسي، إذ يحدّد الوسم extends القالب الأساسي المراد استخدامه، ثم نستخدم block section_name للإشارة إلى المحتوى الجديد للقسم الذي سنعدّله. extends layout block content h1= title p Welcome to #{title} القالب الأساسي لموقع المكتبة المحلية LocalLibrary فهمنا كيفية توسيع القوالب باستخدام Pug، وسنبدأ الآن بإنشاء قالب أساسي لمشروعنا، والذي سيحتوي على شريط جانبي مع روابط للصفحات التي نريد إنشائها في المقالات لاحقًا مثل صفحات عرض وإنشاء الكتب وأنواعها والمؤلفين وغير ذلك، وسيحتوي على منطقة للمحتوى الرئيسي سنعدّلها في كل صفحة من صفحاتنا. افتح القالب /views/layout.pug وضع الشيفرة التالية مكان المحتوى الموجود مسبقًا: doctype html html(lang='en') head title= title meta(charset='utf-8') meta(name='viewport', content='width=device-width, initial-scale=1') link(rel="stylesheet", href="https://cdn.jsdelivr.net/npm/bootstrap@4.6.2/dist/css/bootstrap.min.css", integrity="sha384-xOolHFLEh07PJGoPkLv1IbcEPTNtaed2xpHsD9ESMhqIYd0nLMwNLD69Npy4HI+N", crossorigin="anonymous") script(src="https://code.jquery.com/jquery-3.5.1.slim.min.js", integrity="sha384-DfXdz2htPH0lsSSs5nCTpuj/zy4C+OGpamoFVy38MVBnE+IbbVYUew+OrCXaRkfj", crossorigin="anonymous") script(src="https://cdn.jsdelivr.net/npm/bootstrap@4.6.2/dist/js/bootstrap.min.js", integrity="sha384-+sLIOodYLS7CIrQpBjl+C7nPvqq+FbNUBDunl/OZv93DB7Ln/533i8e/mZXLi/P+", crossorigin="anonymous") link(rel='stylesheet', href='/stylesheets/style.css') body div(class='container-fluid') div(class='row') div(class='col-sm-2') block sidebar ul(class='sidebar-nav') li a(href='/catalog') Home li a(href='/catalog/books') All books li a(href='/catalog/authors') All authors li a(href='/catalog/genres') All genres li a(href='/catalog/bookinstances') All book-instances li hr li a(href='/catalog/author/create') Create new author li a(href='/catalog/genre/create') Create new genre li a(href='/catalog/book/create') Create new book li a(href='/catalog/bookinstance/create') Create new book instance (copy) div(class='col-sm-10') block content يتضمن القالب شيفرة جافا سكريبت و CSS من بوتستراب Bootstrap لتحسين تخطيط وعرض صفحة HTML؛ إذ يُعَد استخدام بوتستراب أو أي إطار عمل ويب آخر من طرف العميل طريقةً سريعة لإنشاء صفحة جذابة يمكن أن تتناسب مع أحجام المتصفحات المختلفة، ويتيح أيضًا التعامل مع عرض الصفحة دون الحاجة إلى الدخول في التفاصيل، إذ نريد فقط التركيز على الشيفرة البرمجية من طرف الخادم حاليًا. ملاحظة: تكون السكربتات مُحمَّلة على أصول مختلطة، لذا يجب السماح صراحةً بتحميل هذه الملفات لاحقًا عندما نضيف برمجية وسيطة للأمان. اطلع على فقرة استخدام حزمة Helmet للحماية من الثغرات المعروفة من مقال النشر في بيئة الإنتاج لمزيد من المعلومات. يجب أن يكون التخطيط واضحًا إلى حدٍ ما إذا قرأت القسم السابق. لاحظ استخدام كتلة block content بوصفها عنصرًا بديلًا للمكان الذي سيوضع فيه محتوى صفحاتنا. يشير القالب الأساسي أيضًا إلى ملف CSS محلي (style.css) الذي يوفر بعض التنسيق الإضافي. افتح الملف "/public/stylesheets/style.css" وضع شيفرة CSS التالية مكان محتواه: .sidebar-nav { margin-top: 20px; padding: 0; list-style: none; } لدينا الآن قالب أساسي لإنشاء صفحات مع شريط جانبي، وسنستخدمه في المقالات التالية لتعريف الصفحات الفردية. ترجمة -وبتصرُّف- للمقالين Template primer و LocalLibrary base template. اقرأ المزيد المقال السابق: تطبيق عملي لتعلم Express - الجزء الخامس: النشر في بيئة الإنتاج كيفية استخدام القوالب في تطبيقات فلاسك Flask. مدخل إلى إطار عمل الويب Express وبيئة Node مدخل إلى express إنشاء مدوّنة باستخدام Node.js و Express (الجزء الأول) -
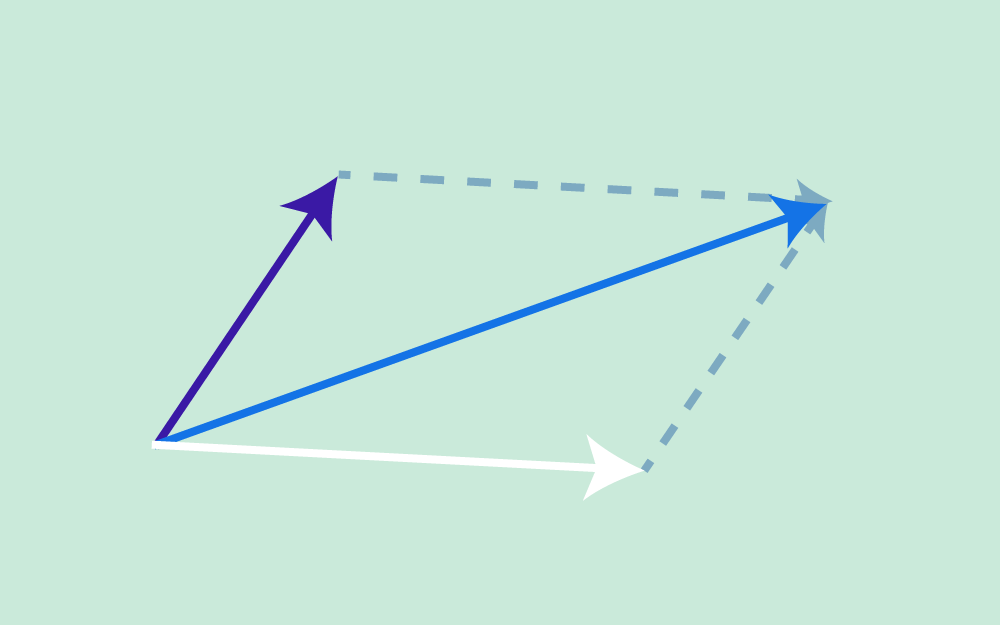 تعرّفنا في المقال السابق على جمع المصفوفات العمودية الذي يُعَد إجراءً سهلًا، وسنوضّح في هذا المقال سبب كون هذا الإجراء مفيدًا من خلال مناقشة كيفية تمثيله لعملية جمع الأشعة. سنتعرّف في هذا المقال على المواضيع التالية: جمع الأشعة. جمع الأشعة باستخدام قاعدة الرأس إلى الذيل Head to Tail. قاعدة الرأس إلى الذيل في فضاء ثلاثي الأبعاد. الخاصية التجميعية Associative لجمع الأشعة. الخاصية التبديلية Commutative لجمع الأشعة. الإطارات الإحداثية Coordinate Frames. تمثيل النقاط الهندسية باستخدام إطارات الإحداثيات والمصفوفات العمودية. تمثيل الأشعة باستخدام المصفوفات العمودية. جمع الأشعة باستخدام المصفوفات العمودية. استخدام متوازي الأضلاع في عملية جمع الأشعة. متراجحة المثلث Triangle Inequality. الأشعة المرتبطة الخطية Collinear. جمع الأشعة الصفرية. عملية جمع شعاع ونقطة. تذكير: اجمع المصفوفتين العموديتين التاليتين: a = ( 3, 2 )T b = (-2, 1 )T والجواب هو: a + b = ( 1, 3 )T الأشعة في الفضاء ثنائي الأبعاد تُعَد الأشعة كائنات هندسية يمكن تمثيلها بطرق متعددة، ولكن يجب أن نفهم الفرق بين الكائن الهندسي (مثل النقطة أو الشعاع)، وطريقة تمثيله (باستخدام مصفوفة عمودية غالبًا). يوضّح المخطط البياني السابق النقاط A و B و C في فضاء ثنائي الأبعاد؛ حيث يُعبَّر عن الإزاحة Displacement بمسافة واتجاه، فالشعاع u هو الإزاحة من النقطة A إلى النقطة B، أما الشعاع v فهو الإزاحة من النقطة B إلى النقطة C. بينما يعبٌر الشعاع w عن الإزاحة من النقطة A إلى النقطة C؛ ويكون تأثير التحرك عبر الإزاحة u ثم عبر الإزاحة v هو تأثير التحرك عبر الإزاحة w نفسه وبالتالي يمكن القول أن: u + v = w عدم اعتمادية عملية جمع الأشعة على موضعها هل تعتمد عملية جمع الأشعة على مكان وجودها؟ لا، فليس للأشعة موضع محدّد. توضّح النقاط في المخطط البياني السابق كيفية حساب التأثير المشترك لإزاحتين من خلال جمعهما، ولكن لم يتضمّن جمعُ الإزاحات النقاط فعليًا، حيث يظهر جمع الأشعة عادةً كما في المخطط البياني السابق، الذي يوضح أن تأثير التحرك عبر الإزاحة u ثم التحرك عبر الإزاحة v هو تأثير التحرك عبر الإزاحة w نفسه. لنفترض مثلًا أنك ترغب في نقل جميع نقاط كائن هندسي عبر الإزاحة u، ثم عبر الإزاحة v. يمكنك تطبيق ذلك من خلال تحريك كل نقطة عبر الإزاحة w. قاعدة الرأس إلى الذيل Head-to-Tail جرب رسم الخط الذي يمثل مجموع الشعاعين s و t: والحل باستخدام قاعدة الرأس إلى الذيل هو: يمكن جمع الشعاعين v و u في المخطط البياني التالي من خلال تحريك الشعاع v مع الحفاظ على طوله ومنحاه Orientation حتى يلمس ذيلُ هذا الشعاع رأسَ الشعاع u، والناتج هو الشعاع المتشكّل من ذيل الشعاع u إلى رأس الشعاع v: اجمع الشعاعين e و d: والحل هو: يوضّح المخطط البياني السابق تحريك الشعاع e للأعلى حتى يلامس ذيله رأس الشعاع d، والناتج هو الشعاع المتشكّل من ذيل الشعاع d إلى رأس الشعاع e . جمع الأشعة في الفضاء ثلاثي الأبعاد يوضّح المخطط البياني التالي جمع الشعاعين a و b ثلاثيّي الأبعاد لتشكيل الشعاع c. وضعنا الصندوق ثلاثي الأبعاد للمساعدة على تصوّر الأبعاد الثلاثية، إذ تعمل قاعدة الرأس إلى الذيل في الفضاء ثلاثي الأبعاد أيضًا. تحدّد قاعدة الرأس إلى الذيل مثلثًا مُوجَّهًا في الفضاء ثلاثي الأبعاد عند جمع شعاعين في فضاء ثلاثي الأبعاد. الخاصية التجميعية Associative لجمع الأشعة هل يمكن جمع ثلاثة أشعة مثل الأشعة a و b و d في المخطط البياني التالي؟ نعم يمكن ذلك، والنتيجة هي الإزاحة الإجمالية الناتجة عن اتباع كل شعاع بدوره. يوضّح المخطط البياني التالي نتيجة جمع (a + b) + d = c + d، والنتيجة هي شعاع بطول واتجاه مماثل لقطر الشكل. يوضّح المخطط البياني التالي نتيجة جمع a + (b + d)، والنتيجة هي نفسها، ويُعَد ذلك دليلًا على الخاصية التجميعية لجمع الأشعة: a + (b + c) = (a + b) + c يمكن تطبيق هذه القاعدة في جميع الأبعاد، إذ تكون الأشعة الهندسية للرسوميات الحاسوبية غالبًا ثنائية وثلاثية الأبعاد بالرغم من إمكانية وجود أبعاد أعلى بصورة عامة. تعني الخاصية التجميعية أنه يمكن كتابة مجموع عدة أشعة مثل: a + b + c + d + e بدون قوسين. الخاصية التبديلية Commutative لجمع الأشعة لنفترض أنك تمشي مسافة خمس بنايات شمالًا، ثم ثلاث بنايات شرقًا، ولكن إذا مشيت ثلاث بنايات شرقًا ثم خمس بنايات شمالًا، فهل ستصل إلى المكان نفسه؟ نعم، هذا صحيح. يُعَد جمع الأشعة عملية تبديلية مثل جمع الأعداد الحقيقية تمامًا: a + b = b + a إذا بدأت من النقطة P، فسينتهي بك الأمر في المكان نفسه بغض النظر عن الإزاحة (a أو b) التي ستأخذها أولًا. سينتج الشعاع c عن كلٍّ من عمليتي الجمع a + b و b + a عند تطبيق قاعدة الرأس إلى الذيل، ولكن هل يمكن تطبيق الخاصية التبديلية على جميع الأبعاد؟ نعم، يمكن ذلك. تمثيل النقاط باستخدام المصفوفات العمودية يمكن تمثيل النقاط باستخدام المصفوفات العمودية، ولكن يجب أولًا اتخاذ قرار بشأن الإطار الإحداثي Coordinate Frame الذي يُسمَّى أحيانًا بالإطار فقط. ويتكون الإطار الإحداثي من نقطة مميزة P0 تسمى نقطة الأصل Origin، ومن محور لكل بُعد يُسمَّى X و Y غالبًا، فهناك محوران في الفضاء ثنائي الأبعاد، وثلاثة محاور تُسمَّى X و Y و Z في الفضاء ثلاثي الأبعاد. لنبدأ بالفضاء ثنائي الأبعاد، حيث يُظهِر المخطط البياني الأيسر عالمًا افتراضيًا بسيطًا إلى حدٍ ما في فضاء ثنائي الأبعاد، إذ تكون النقاط والأشعة موجودةً في الفضاء بصورة مستقلة عن أيّ إطار إحداثي، بينما يوضّح المخطط البياني الأوسط العالم الافتراضي نفسه مع إطار إحداثي يتكون من نقطة معينة P0 ومحورين، وتُمثَّل النقطة A في هذا الإطار الإحداثي بالمصفوفة العمودية (2, 2)T. يُظهر المخطط البياني الأيمن العالم الافتراضي نفسه مع إطار إحداثي مختلف، إذ تُمثَّل النقطة A في هذا الإطار الإحداثي بالمصفوفة العمودية (2, 3)T. إذًا، كيف تُمثَّل النقطة B باستخدام الإطار الإحداثي الأول، وباستخدام الإطار الإحداثي الثاني؟ تُمثَّل النقطة B باستخدام الإطار الإحداثي الأول بالمصفوفة العمودية (6, 2)T، وتُمثَّل باستخدام الإطار الإحداثي الثاني بالمصفوفة العمودية (4.8, 1.6)T. تمثيل النقاط باستخدام إطارات إحداثية مختلفة الفكرة الأساسية -والمربكة في كثير من الأحيان- هي أنه يوجد في برنامج الرسوميات عالم افتراضي واحد، ولكن قد يكون هناك أيّ عددٍ من الإطارات الإحداثية قيد الاستخدام، إذ لكل كائنٍ إطاره الخاص غالبًا، بحيث يُستخدَم إطار مختلف لوصف مواقع الكائنات؛ ويمكن استخدام إطارٍ آخر لمجال الرؤية، ويُعَد ذلك شيئًا تفعله فعليًا طوال الوقت مع العالم الحقيقي، ولكنه يكون الجزء الصعب في معرفة كيفية العمل مع العالم الافتراضي. لنفترض أن لديك مزهريةً موضوعةً على طاولة مثلًا، وأنت تتحدث مع صديق عبر الهاتف وترغب في وصف المزهرية له ومكانها وكيف تبدو لك. يمكنك وصف المزهرية بأنها كرة مركزها نقطة الأصل ومتقاطعة مع أسطوانة محورها هو المحور y، ويُعَد ذلك وصفًا للمزهرية في إطارها الخاص. يمكنك وصف موقع المزهرية بأنه "يبعد 20 سم تقريبًا من الحافة الأمامية للطاولة و30 سم من الحافة اليمنى"، واستخدمنا بذلك إطارًا آخر لوصف الموقع. يمكنك أيضًا التحدث عن كيفية مشاهدتك للطاولة من مسافة 2 متر تقريبًا وارتفاع 1.5 متر، ويستخدم ذلك إطارًا آخر لوصف مجال رؤيتك. يمكن أن تتجول أيضًا حول الطاولة معجبًا بالمزهرية الجميلة، وعندها يجب أن تستخدم إطارًا آخر لوصف مجال رؤيتك الجديد. لنفترض أنك خرجت للمشي، واقترب منك شخص غريب وسألك عن الاتجاهات إلى مكتب البريد، فما هو إطار الإحداثيات الذي ستستخدمه؟ هل ستستخدم خط العرض وخط الطول استنادًا إلى جرينتش في إنجلترا؟ أم ستستخدم عدد مباني المدينة على يسار ويمين موقعك الحالي؟ حسنًا، إن لم يكن لدى هذا الشخص الغريب جهاز استقبال GPS، فيُرجَّح أن يكون إطار إحداثيات مباني المدينة هو الأكثر فائدة. تمثيل الأشعة باستخدام المصفوفات العمودية لنعُد إلى عالمنا الافتراضي، حيث تكون الإزاحة من النقطة A إلى النقطة B هي الشعاع v، ولكن لا يعتمد الشعاع على أيّ نظام إحداثي. يمكن تمثيل الإزاحة باستخدام نظام الإحداثيات الأول (المخطط البياني الأوسط) بأنها: (الفرق في إحداثيات y, الفرق في إحداثيات x) وبالتالي تكون الإزاحة هي: (4, 0)T في هذا المخطط البياني، أي التحرّك بمقدار 4 وحدات من النقطة A باتجاه المحور x للوصول إلى النقطة B، بينما يُمثَّل الشعاع نفسه بالمصفوفة العمودية (2.8, -1.4)T في نظام الإحداثيات الثاني (الرسم البياني الأيمن). تُمثَّل كلٌّ من النقاط والأشعة باستخدام المصفوفات العمودية، فهل يُحتمَل أن يكون ذلك مربكًا؟ نعم هذا محتمل، إذ يؤدي هذا الارتباك إلى استخدام الإحداثيات المتجانسة Homogeneous Coordinates، والتي هي طريقة أخرى لتمثيل النقاط والأشعة باستخدام المصفوفات العمودية، ولكننا لن نشرحها في في هذا المقال. تمثيل جمع الأشعة باستخدام جمع المصفوفات العمودية إذا كانت الأشعة مُمثلَّة بالمصفوفات العمودية، فسنمثّل جمع الأشعة بجمع المصفوفات العمودية كما يلي: a = ( 3, 2 )T b = ( -2, 1 )T a + b = c = ( 1, 3 )T يوضح المخطط البياني السابق قاعدة الرأس إلى الذيل المُستخدَمة لجمع الشعاعين a و b للحصول على الشعاع c، وينتج عن جمع المصفوفتين العموديتين a و b المصفوفة العمودية c التي هي التمثيل الصحيح للشعاع c. تغيير ترتيب معاملات عملية الجمع مع الإجابة نفسها جرب حساب c = b + a للمصفوفتين العموديتين a و b السابقتين نفسهما، وستكون الإجابة نفسها هي: b + a = c = ( 1, 3 )T اتبع الخطوات التالية التي يكون فيها الشعاع b بمثابة شعاع البداية لإنشاء الرسم البياني التالي: ارسم الشعاع الأول b على شكل سهم، بحيث يكون ذيله عند نقطة الأصل. ارسم الشعاع الثاني a على شكل سهم، بحيث يكون ذيله عند نقطة رأس الشعاع الأول. يكون مجموعهما هو السهم المتشكّل من نقطة الأصل إلى رأس الشعاع الثاني. ملاحظة: تذكّر أن الأشعة ليس لها موقع محدّد، لذا يمكنك رسم مثيل للشعاع بحيث يبدأ ذيله من أيّ نقطة تريدها. يجب أن تكون نتيجة الجمع هي نفسها بما أن جمع الأشعة عملية تبديلية. تذكير: تُعَد عملية جمع الأشعة وجمع المصفوفات العمودية عملية تجميعية أيضًا. تدريب عملي ليكن لدينا الشعاعان: R = ( 4, 3 )T S = ( 1, 2 )T أوجد ناتج عملية الجمع: T = R + S يمكنك إيجاد الناتج من خلال استخدام جمع المصفوفات العمودية وقاعدة الرأس إلى الذيل، وسيكون الناتج عند تطبيق القاعدة هو: T = (5, 5)T ولنجمع الآن الشعاعين بترتيب معاكس كما يلي: T = S + R حيث يكون الشعاعان هما: S = ( 1, 2 )T R = ( 4, 3 )T وتبقى الإجابة نفسها: T = (5, 5)T استخدام متوازي الأضلاع في عملية جمع الأشعة هناك طريقتان لتشكيل عملية الجمع: T = S + R T = R + S حيث يكون الشعاعان هما: R = ( 4, 3 )T S = ( 1, 2 )T هناك طريقتان للرسم اعتمادًا على ذيل السهم الذي تضعه عند نقطة الأصل، بحيث إذا استخدمتَ كلا الطريقتين، فستحصل على متوازي أضلاع مع ناتج جمع الأشعة الذي يُمثَّل بسهم قطري يبدأ ذيله من نقطة الأصل. قد تتساءل عن ما هو متوازي الأضلاع Parallelogram وعمّا إذا كانت مادة الهندسة التي تعلّمتها في المدرسة الثانوية غامضة قليلًا، فمتوازي الأضلاع هو شكل رباعي فيه كل ضلعين متقابلين متوازيين ومتساويين في الطول، مثل السهمين الأزرقين الممثلين للشعاع s اللذين لهما الطول والاتجاه نفسه، والسهمين الأخضرين الممثلين للشعاع r اللذين لهما الطول والاتجاه نفسه. رحلة ثنائية الاتجاه أوجد ناتج ما يلي: w = u + v إذا كان: u = ( -3, 2 )T v = ( 1, -5 )T والجواب هو: w = ( -2, -3 )T يوضح المخطط البياني السابق عملية الجمع w= u + v. لنفترض أن نملةً ما تبدأ التحرك من نقطة الأصل وتسير على طول الشعاع u، ثم تسير على طول الشعاع v حتى تصل إلى رأس الشعاع w، وتبدأ النملة الثانية من نقطة الأصل وتسير على طول الشعاع w حتى تصل إلى نهايته، وبالتالي ستصل كلتا النملتين إلى النقطة نفسها. جمع الإزاحات وجمع الأطوال غير متساويين هل مشت النملتان المسافة نفسها في المثال السابق؟ في هذه الحالة، لا! فمن الواضح أن المشي في خط مستقيم إلى الوِجهة النهائية أقصر. لا يُعَد جمع الإزاحات (أو الأشعة) مثل جمع أطوالها، إذ ينتج عن جمع الشعاعين u و v شعاع أقصر من طول الشعاع u مع طول الشعاع v في المثال السابق؛ ويمكنك ملاحظة ذلك حاليًا من خلال النظر إلى المخطط البياني السابق، وتذكّر أن "الخط المستقيم هو المسافة الأقصر بين نقطتين" (سنناقش ذلك لاحقًا باستخدام صيغة فيثاغورس). تسمى هذه الحقيقة الرياضية بمتراجحة المثلث Triangle Inequality، وهي تنص على أن ناتج جمع أي طولين من أضلاع المثلث أكبر من طول الضلع الثالث. طول (v + u) <= طول (u) + طول (v) إليك حالة يكون فيها طول ناتج الجمع أقصر بكثير من مجموع الأطوال: e = ( 5, 4 )T g = ( -4.9, -3.9 )T e + g = (0 .1, 0.1 )T ملاحظة: نقلنا الشعاع g قليلًا من المكان الذي ينبغي أن يكون فيه للتوضيح. الأشعة ذات الاتجاه نفسه هل يمكنك التفكير في حالة يكون فيها طول ناتج الجمع مساويًا لمجموع طولي شعاعي الدخل؟ نعم يمكن ذلك إذا كان لأحد الشعاعين اتجاه الشعاع الآخر. يمكن توضيح هذه الحالة في المخطط البياني التالي، إذ تُستخدَم قاعدة الرأس إلى الذيل لجمع شعاعين يؤشّران إلى الاتجاه نفسه، وتُسمَّى الأشعة ذات الاتجاه نفسه بأنها مرتبطة خطية Collinear. نقلنا شعاع ناتج الجمع قليلًا عن مكانه الصحيح حتى تتمكّن من رؤيته. بعد ذلك جمعنا الشعاعين (4, 3)T و (2, 1.5)T، والناتج هو (6, 4.5)T. يمكنك حاليًا تحديد ما إذا كان هناك شعاعان لهما الاتجاه نفسه من خلال النظر إلى الصورة أو باستخدام المفاهيم الهندسية، وستتعرّف لاحقًا على إجراءٍ لاختبار ما إذا كان هناك شعاعان يؤشّران إلى الاتجاه نفسه. يعبِّر هذا المثال عن حالةٍ تطبِّق إشارة المساواة "=" الموجودة في الصيغة التالية: طول (v + u) <= طول (u) + طول (v) جمع الأشعة الصفرية هل يمكنك التفكير في حالةٍ أخرى تطبّق إشارة المساواة "=" الموجودة في الصيغة السابقة؟ نعم، عندما يكون أحد الشعاعين شعاعًا صفريًا كما يلي: طول (0 + u) <= طول (u) + طول (0) اجمع المصفوفة الصفرية ( 0, 0 )T مع المصفوفة ( 4, 3 )T، فإذا مثّلت المضفوفة ( 0, 0 )T شعاع إزاحة، فهذا يعني عدم تطبيق أيّ شيء لتغيير موضع الشعاع الآخر. جمع النقاط والأشعة لنفترض أنك تريد جمع الشعاع (1, 2)T والنقطة (4, 4)T. إذا كان ذلك منطقيًا، فأجرِ هذه العملية، وما هو نوع الكائن الناتج؟ يكون الناتج نقطة كما يلي: (4, 4)T + (1, 2)T = ( 5, 6 )T إذا كان الشعاع (1, 2)T إزاحة (أي مقدار يمكن تغيير قيمة x به، ومقدار يمكن تغيير قيمة y به)، فيجب أن تكون النتيجة نقطة في موقع جديد كما يلي: (4, 4)T + (1, 2)T = ( 5, 6 )T هذه إحدى الحالات التي يكون فيها استخدام التمثيل (أي المصفوفات العمودية) نفسه لكل من النقاط والأشعة أمرًا مربكًا، لذا يجب عليك تتبّع نوع الكائن الذي تمثله كل مصفوفة. تنتج نقطةٌ عن جمع شعاع إزاحة ونقطة كما في المخطط البياني التالي: يُعَد جمع كائنين رياضيين من نوعين مختلفين غريبًا قليلًا، ولا تنسَ أن إشارة الجمع "+" إشارة قابلة للتحميل الزائد overloaded. الانسحاب Translation تُسمَّى عملية جمع شعاع ونقطة بالانسحاب Translation، ويُقال أحيانًا أن النقطة الأصلية مسحوبةً إلى موقع جديد. قد تكون المصطلحات هنا مربكةً قليلًا، إذ ينتج عن جمع شعاع ونقطة من الناحية الرياضية نقطةٌ جديدة، بحيث تبقى النقطة الأولى دون تغيير، ولكن من الجيد التفكير في الصور "التي تتحرك عبر الشاشة" عند جمع أشعة الإزاحة والنقاط الخاصة بها في مصطلحات الرسوميات الحاسوبية، لذا قد تسمع أحيانًا مصطلحات مثل "تحريك نقطة" و"النقطة القديمة" و"النقطة الجديدة". لقد رأينا تطبيق العمليات التالية: شعاع + شعاع. نقطة + شعاع. نقطة - نقطة. فهل تفترض أنه يمكن إجراء العملية نقطة + نقطة؟ لا يُعَد جمع نقطتين شيئًا هندسيًا. يمكنك تشكيل مجموع شعاعين عموديين يمثلان نقاطًا ميكانيكيًا، ولكن النتيجة لا تكون ذات معنى فعلي. لقد وصلنا إلى نهاية هذا المقال، وسنناقش في المقال التالي العمليات على الأشعة بصورة أكبر، وسنناقش لاحقًا مزيدًا من العمليات على الأشعة. ترجمة -وبتصرُّف- للفصل Vector Addition من كتاب Vector Math for 3D Computer Graphics لصاحبه Bradley Kjell. اقرأ أيضًا المقال السابق: كيفية جمع وطرح المصفوفات العمودية والمصفوفات السطرية الأشعة والنقاط والمصفوفات العمودية في الرسوميات الحاسوبية ثلاثية الأبعاد التعرف على النقاط والخطوط في الرسوميات الحاسوبية ثلاثية الأبعاد
تعرّفنا في المقال السابق على جمع المصفوفات العمودية الذي يُعَد إجراءً سهلًا، وسنوضّح في هذا المقال سبب كون هذا الإجراء مفيدًا من خلال مناقشة كيفية تمثيله لعملية جمع الأشعة. سنتعرّف في هذا المقال على المواضيع التالية: جمع الأشعة. جمع الأشعة باستخدام قاعدة الرأس إلى الذيل Head to Tail. قاعدة الرأس إلى الذيل في فضاء ثلاثي الأبعاد. الخاصية التجميعية Associative لجمع الأشعة. الخاصية التبديلية Commutative لجمع الأشعة. الإطارات الإحداثية Coordinate Frames. تمثيل النقاط الهندسية باستخدام إطارات الإحداثيات والمصفوفات العمودية. تمثيل الأشعة باستخدام المصفوفات العمودية. جمع الأشعة باستخدام المصفوفات العمودية. استخدام متوازي الأضلاع في عملية جمع الأشعة. متراجحة المثلث Triangle Inequality. الأشعة المرتبطة الخطية Collinear. جمع الأشعة الصفرية. عملية جمع شعاع ونقطة. تذكير: اجمع المصفوفتين العموديتين التاليتين: a = ( 3, 2 )T b = (-2, 1 )T والجواب هو: a + b = ( 1, 3 )T الأشعة في الفضاء ثنائي الأبعاد تُعَد الأشعة كائنات هندسية يمكن تمثيلها بطرق متعددة، ولكن يجب أن نفهم الفرق بين الكائن الهندسي (مثل النقطة أو الشعاع)، وطريقة تمثيله (باستخدام مصفوفة عمودية غالبًا). يوضّح المخطط البياني السابق النقاط A و B و C في فضاء ثنائي الأبعاد؛ حيث يُعبَّر عن الإزاحة Displacement بمسافة واتجاه، فالشعاع u هو الإزاحة من النقطة A إلى النقطة B، أما الشعاع v فهو الإزاحة من النقطة B إلى النقطة C. بينما يعبٌر الشعاع w عن الإزاحة من النقطة A إلى النقطة C؛ ويكون تأثير التحرك عبر الإزاحة u ثم عبر الإزاحة v هو تأثير التحرك عبر الإزاحة w نفسه وبالتالي يمكن القول أن: u + v = w عدم اعتمادية عملية جمع الأشعة على موضعها هل تعتمد عملية جمع الأشعة على مكان وجودها؟ لا، فليس للأشعة موضع محدّد. توضّح النقاط في المخطط البياني السابق كيفية حساب التأثير المشترك لإزاحتين من خلال جمعهما، ولكن لم يتضمّن جمعُ الإزاحات النقاط فعليًا، حيث يظهر جمع الأشعة عادةً كما في المخطط البياني السابق، الذي يوضح أن تأثير التحرك عبر الإزاحة u ثم التحرك عبر الإزاحة v هو تأثير التحرك عبر الإزاحة w نفسه. لنفترض مثلًا أنك ترغب في نقل جميع نقاط كائن هندسي عبر الإزاحة u، ثم عبر الإزاحة v. يمكنك تطبيق ذلك من خلال تحريك كل نقطة عبر الإزاحة w. قاعدة الرأس إلى الذيل Head-to-Tail جرب رسم الخط الذي يمثل مجموع الشعاعين s و t: والحل باستخدام قاعدة الرأس إلى الذيل هو: يمكن جمع الشعاعين v و u في المخطط البياني التالي من خلال تحريك الشعاع v مع الحفاظ على طوله ومنحاه Orientation حتى يلمس ذيلُ هذا الشعاع رأسَ الشعاع u، والناتج هو الشعاع المتشكّل من ذيل الشعاع u إلى رأس الشعاع v: اجمع الشعاعين e و d: والحل هو: يوضّح المخطط البياني السابق تحريك الشعاع e للأعلى حتى يلامس ذيله رأس الشعاع d، والناتج هو الشعاع المتشكّل من ذيل الشعاع d إلى رأس الشعاع e . جمع الأشعة في الفضاء ثلاثي الأبعاد يوضّح المخطط البياني التالي جمع الشعاعين a و b ثلاثيّي الأبعاد لتشكيل الشعاع c. وضعنا الصندوق ثلاثي الأبعاد للمساعدة على تصوّر الأبعاد الثلاثية، إذ تعمل قاعدة الرأس إلى الذيل في الفضاء ثلاثي الأبعاد أيضًا. تحدّد قاعدة الرأس إلى الذيل مثلثًا مُوجَّهًا في الفضاء ثلاثي الأبعاد عند جمع شعاعين في فضاء ثلاثي الأبعاد. الخاصية التجميعية Associative لجمع الأشعة هل يمكن جمع ثلاثة أشعة مثل الأشعة a و b و d في المخطط البياني التالي؟ نعم يمكن ذلك، والنتيجة هي الإزاحة الإجمالية الناتجة عن اتباع كل شعاع بدوره. يوضّح المخطط البياني التالي نتيجة جمع (a + b) + d = c + d، والنتيجة هي شعاع بطول واتجاه مماثل لقطر الشكل. يوضّح المخطط البياني التالي نتيجة جمع a + (b + d)، والنتيجة هي نفسها، ويُعَد ذلك دليلًا على الخاصية التجميعية لجمع الأشعة: a + (b + c) = (a + b) + c يمكن تطبيق هذه القاعدة في جميع الأبعاد، إذ تكون الأشعة الهندسية للرسوميات الحاسوبية غالبًا ثنائية وثلاثية الأبعاد بالرغم من إمكانية وجود أبعاد أعلى بصورة عامة. تعني الخاصية التجميعية أنه يمكن كتابة مجموع عدة أشعة مثل: a + b + c + d + e بدون قوسين. الخاصية التبديلية Commutative لجمع الأشعة لنفترض أنك تمشي مسافة خمس بنايات شمالًا، ثم ثلاث بنايات شرقًا، ولكن إذا مشيت ثلاث بنايات شرقًا ثم خمس بنايات شمالًا، فهل ستصل إلى المكان نفسه؟ نعم، هذا صحيح. يُعَد جمع الأشعة عملية تبديلية مثل جمع الأعداد الحقيقية تمامًا: a + b = b + a إذا بدأت من النقطة P، فسينتهي بك الأمر في المكان نفسه بغض النظر عن الإزاحة (a أو b) التي ستأخذها أولًا. سينتج الشعاع c عن كلٍّ من عمليتي الجمع a + b و b + a عند تطبيق قاعدة الرأس إلى الذيل، ولكن هل يمكن تطبيق الخاصية التبديلية على جميع الأبعاد؟ نعم، يمكن ذلك. تمثيل النقاط باستخدام المصفوفات العمودية يمكن تمثيل النقاط باستخدام المصفوفات العمودية، ولكن يجب أولًا اتخاذ قرار بشأن الإطار الإحداثي Coordinate Frame الذي يُسمَّى أحيانًا بالإطار فقط. ويتكون الإطار الإحداثي من نقطة مميزة P0 تسمى نقطة الأصل Origin، ومن محور لكل بُعد يُسمَّى X و Y غالبًا، فهناك محوران في الفضاء ثنائي الأبعاد، وثلاثة محاور تُسمَّى X و Y و Z في الفضاء ثلاثي الأبعاد. لنبدأ بالفضاء ثنائي الأبعاد، حيث يُظهِر المخطط البياني الأيسر عالمًا افتراضيًا بسيطًا إلى حدٍ ما في فضاء ثنائي الأبعاد، إذ تكون النقاط والأشعة موجودةً في الفضاء بصورة مستقلة عن أيّ إطار إحداثي، بينما يوضّح المخطط البياني الأوسط العالم الافتراضي نفسه مع إطار إحداثي يتكون من نقطة معينة P0 ومحورين، وتُمثَّل النقطة A في هذا الإطار الإحداثي بالمصفوفة العمودية (2, 2)T. يُظهر المخطط البياني الأيمن العالم الافتراضي نفسه مع إطار إحداثي مختلف، إذ تُمثَّل النقطة A في هذا الإطار الإحداثي بالمصفوفة العمودية (2, 3)T. إذًا، كيف تُمثَّل النقطة B باستخدام الإطار الإحداثي الأول، وباستخدام الإطار الإحداثي الثاني؟ تُمثَّل النقطة B باستخدام الإطار الإحداثي الأول بالمصفوفة العمودية (6, 2)T، وتُمثَّل باستخدام الإطار الإحداثي الثاني بالمصفوفة العمودية (4.8, 1.6)T. تمثيل النقاط باستخدام إطارات إحداثية مختلفة الفكرة الأساسية -والمربكة في كثير من الأحيان- هي أنه يوجد في برنامج الرسوميات عالم افتراضي واحد، ولكن قد يكون هناك أيّ عددٍ من الإطارات الإحداثية قيد الاستخدام، إذ لكل كائنٍ إطاره الخاص غالبًا، بحيث يُستخدَم إطار مختلف لوصف مواقع الكائنات؛ ويمكن استخدام إطارٍ آخر لمجال الرؤية، ويُعَد ذلك شيئًا تفعله فعليًا طوال الوقت مع العالم الحقيقي، ولكنه يكون الجزء الصعب في معرفة كيفية العمل مع العالم الافتراضي. لنفترض أن لديك مزهريةً موضوعةً على طاولة مثلًا، وأنت تتحدث مع صديق عبر الهاتف وترغب في وصف المزهرية له ومكانها وكيف تبدو لك. يمكنك وصف المزهرية بأنها كرة مركزها نقطة الأصل ومتقاطعة مع أسطوانة محورها هو المحور y، ويُعَد ذلك وصفًا للمزهرية في إطارها الخاص. يمكنك وصف موقع المزهرية بأنه "يبعد 20 سم تقريبًا من الحافة الأمامية للطاولة و30 سم من الحافة اليمنى"، واستخدمنا بذلك إطارًا آخر لوصف الموقع. يمكنك أيضًا التحدث عن كيفية مشاهدتك للطاولة من مسافة 2 متر تقريبًا وارتفاع 1.5 متر، ويستخدم ذلك إطارًا آخر لوصف مجال رؤيتك. يمكن أن تتجول أيضًا حول الطاولة معجبًا بالمزهرية الجميلة، وعندها يجب أن تستخدم إطارًا آخر لوصف مجال رؤيتك الجديد. لنفترض أنك خرجت للمشي، واقترب منك شخص غريب وسألك عن الاتجاهات إلى مكتب البريد، فما هو إطار الإحداثيات الذي ستستخدمه؟ هل ستستخدم خط العرض وخط الطول استنادًا إلى جرينتش في إنجلترا؟ أم ستستخدم عدد مباني المدينة على يسار ويمين موقعك الحالي؟ حسنًا، إن لم يكن لدى هذا الشخص الغريب جهاز استقبال GPS، فيُرجَّح أن يكون إطار إحداثيات مباني المدينة هو الأكثر فائدة. تمثيل الأشعة باستخدام المصفوفات العمودية لنعُد إلى عالمنا الافتراضي، حيث تكون الإزاحة من النقطة A إلى النقطة B هي الشعاع v، ولكن لا يعتمد الشعاع على أيّ نظام إحداثي. يمكن تمثيل الإزاحة باستخدام نظام الإحداثيات الأول (المخطط البياني الأوسط) بأنها: (الفرق في إحداثيات y, الفرق في إحداثيات x) وبالتالي تكون الإزاحة هي: (4, 0)T في هذا المخطط البياني، أي التحرّك بمقدار 4 وحدات من النقطة A باتجاه المحور x للوصول إلى النقطة B، بينما يُمثَّل الشعاع نفسه بالمصفوفة العمودية (2.8, -1.4)T في نظام الإحداثيات الثاني (الرسم البياني الأيمن). تُمثَّل كلٌّ من النقاط والأشعة باستخدام المصفوفات العمودية، فهل يُحتمَل أن يكون ذلك مربكًا؟ نعم هذا محتمل، إذ يؤدي هذا الارتباك إلى استخدام الإحداثيات المتجانسة Homogeneous Coordinates، والتي هي طريقة أخرى لتمثيل النقاط والأشعة باستخدام المصفوفات العمودية، ولكننا لن نشرحها في في هذا المقال. تمثيل جمع الأشعة باستخدام جمع المصفوفات العمودية إذا كانت الأشعة مُمثلَّة بالمصفوفات العمودية، فسنمثّل جمع الأشعة بجمع المصفوفات العمودية كما يلي: a = ( 3, 2 )T b = ( -2, 1 )T a + b = c = ( 1, 3 )T يوضح المخطط البياني السابق قاعدة الرأس إلى الذيل المُستخدَمة لجمع الشعاعين a و b للحصول على الشعاع c، وينتج عن جمع المصفوفتين العموديتين a و b المصفوفة العمودية c التي هي التمثيل الصحيح للشعاع c. تغيير ترتيب معاملات عملية الجمع مع الإجابة نفسها جرب حساب c = b + a للمصفوفتين العموديتين a و b السابقتين نفسهما، وستكون الإجابة نفسها هي: b + a = c = ( 1, 3 )T اتبع الخطوات التالية التي يكون فيها الشعاع b بمثابة شعاع البداية لإنشاء الرسم البياني التالي: ارسم الشعاع الأول b على شكل سهم، بحيث يكون ذيله عند نقطة الأصل. ارسم الشعاع الثاني a على شكل سهم، بحيث يكون ذيله عند نقطة رأس الشعاع الأول. يكون مجموعهما هو السهم المتشكّل من نقطة الأصل إلى رأس الشعاع الثاني. ملاحظة: تذكّر أن الأشعة ليس لها موقع محدّد، لذا يمكنك رسم مثيل للشعاع بحيث يبدأ ذيله من أيّ نقطة تريدها. يجب أن تكون نتيجة الجمع هي نفسها بما أن جمع الأشعة عملية تبديلية. تذكير: تُعَد عملية جمع الأشعة وجمع المصفوفات العمودية عملية تجميعية أيضًا. تدريب عملي ليكن لدينا الشعاعان: R = ( 4, 3 )T S = ( 1, 2 )T أوجد ناتج عملية الجمع: T = R + S يمكنك إيجاد الناتج من خلال استخدام جمع المصفوفات العمودية وقاعدة الرأس إلى الذيل، وسيكون الناتج عند تطبيق القاعدة هو: T = (5, 5)T ولنجمع الآن الشعاعين بترتيب معاكس كما يلي: T = S + R حيث يكون الشعاعان هما: S = ( 1, 2 )T R = ( 4, 3 )T وتبقى الإجابة نفسها: T = (5, 5)T استخدام متوازي الأضلاع في عملية جمع الأشعة هناك طريقتان لتشكيل عملية الجمع: T = S + R T = R + S حيث يكون الشعاعان هما: R = ( 4, 3 )T S = ( 1, 2 )T هناك طريقتان للرسم اعتمادًا على ذيل السهم الذي تضعه عند نقطة الأصل، بحيث إذا استخدمتَ كلا الطريقتين، فستحصل على متوازي أضلاع مع ناتج جمع الأشعة الذي يُمثَّل بسهم قطري يبدأ ذيله من نقطة الأصل. قد تتساءل عن ما هو متوازي الأضلاع Parallelogram وعمّا إذا كانت مادة الهندسة التي تعلّمتها في المدرسة الثانوية غامضة قليلًا، فمتوازي الأضلاع هو شكل رباعي فيه كل ضلعين متقابلين متوازيين ومتساويين في الطول، مثل السهمين الأزرقين الممثلين للشعاع s اللذين لهما الطول والاتجاه نفسه، والسهمين الأخضرين الممثلين للشعاع r اللذين لهما الطول والاتجاه نفسه. رحلة ثنائية الاتجاه أوجد ناتج ما يلي: w = u + v إذا كان: u = ( -3, 2 )T v = ( 1, -5 )T والجواب هو: w = ( -2, -3 )T يوضح المخطط البياني السابق عملية الجمع w= u + v. لنفترض أن نملةً ما تبدأ التحرك من نقطة الأصل وتسير على طول الشعاع u، ثم تسير على طول الشعاع v حتى تصل إلى رأس الشعاع w، وتبدأ النملة الثانية من نقطة الأصل وتسير على طول الشعاع w حتى تصل إلى نهايته، وبالتالي ستصل كلتا النملتين إلى النقطة نفسها. جمع الإزاحات وجمع الأطوال غير متساويين هل مشت النملتان المسافة نفسها في المثال السابق؟ في هذه الحالة، لا! فمن الواضح أن المشي في خط مستقيم إلى الوِجهة النهائية أقصر. لا يُعَد جمع الإزاحات (أو الأشعة) مثل جمع أطوالها، إذ ينتج عن جمع الشعاعين u و v شعاع أقصر من طول الشعاع u مع طول الشعاع v في المثال السابق؛ ويمكنك ملاحظة ذلك حاليًا من خلال النظر إلى المخطط البياني السابق، وتذكّر أن "الخط المستقيم هو المسافة الأقصر بين نقطتين" (سنناقش ذلك لاحقًا باستخدام صيغة فيثاغورس). تسمى هذه الحقيقة الرياضية بمتراجحة المثلث Triangle Inequality، وهي تنص على أن ناتج جمع أي طولين من أضلاع المثلث أكبر من طول الضلع الثالث. طول (v + u) <= طول (u) + طول (v) إليك حالة يكون فيها طول ناتج الجمع أقصر بكثير من مجموع الأطوال: e = ( 5, 4 )T g = ( -4.9, -3.9 )T e + g = (0 .1, 0.1 )T ملاحظة: نقلنا الشعاع g قليلًا من المكان الذي ينبغي أن يكون فيه للتوضيح. الأشعة ذات الاتجاه نفسه هل يمكنك التفكير في حالة يكون فيها طول ناتج الجمع مساويًا لمجموع طولي شعاعي الدخل؟ نعم يمكن ذلك إذا كان لأحد الشعاعين اتجاه الشعاع الآخر. يمكن توضيح هذه الحالة في المخطط البياني التالي، إذ تُستخدَم قاعدة الرأس إلى الذيل لجمع شعاعين يؤشّران إلى الاتجاه نفسه، وتُسمَّى الأشعة ذات الاتجاه نفسه بأنها مرتبطة خطية Collinear. نقلنا شعاع ناتج الجمع قليلًا عن مكانه الصحيح حتى تتمكّن من رؤيته. بعد ذلك جمعنا الشعاعين (4, 3)T و (2, 1.5)T، والناتج هو (6, 4.5)T. يمكنك حاليًا تحديد ما إذا كان هناك شعاعان لهما الاتجاه نفسه من خلال النظر إلى الصورة أو باستخدام المفاهيم الهندسية، وستتعرّف لاحقًا على إجراءٍ لاختبار ما إذا كان هناك شعاعان يؤشّران إلى الاتجاه نفسه. يعبِّر هذا المثال عن حالةٍ تطبِّق إشارة المساواة "=" الموجودة في الصيغة التالية: طول (v + u) <= طول (u) + طول (v) جمع الأشعة الصفرية هل يمكنك التفكير في حالةٍ أخرى تطبّق إشارة المساواة "=" الموجودة في الصيغة السابقة؟ نعم، عندما يكون أحد الشعاعين شعاعًا صفريًا كما يلي: طول (0 + u) <= طول (u) + طول (0) اجمع المصفوفة الصفرية ( 0, 0 )T مع المصفوفة ( 4, 3 )T، فإذا مثّلت المضفوفة ( 0, 0 )T شعاع إزاحة، فهذا يعني عدم تطبيق أيّ شيء لتغيير موضع الشعاع الآخر. جمع النقاط والأشعة لنفترض أنك تريد جمع الشعاع (1, 2)T والنقطة (4, 4)T. إذا كان ذلك منطقيًا، فأجرِ هذه العملية، وما هو نوع الكائن الناتج؟ يكون الناتج نقطة كما يلي: (4, 4)T + (1, 2)T = ( 5, 6 )T إذا كان الشعاع (1, 2)T إزاحة (أي مقدار يمكن تغيير قيمة x به، ومقدار يمكن تغيير قيمة y به)، فيجب أن تكون النتيجة نقطة في موقع جديد كما يلي: (4, 4)T + (1, 2)T = ( 5, 6 )T هذه إحدى الحالات التي يكون فيها استخدام التمثيل (أي المصفوفات العمودية) نفسه لكل من النقاط والأشعة أمرًا مربكًا، لذا يجب عليك تتبّع نوع الكائن الذي تمثله كل مصفوفة. تنتج نقطةٌ عن جمع شعاع إزاحة ونقطة كما في المخطط البياني التالي: يُعَد جمع كائنين رياضيين من نوعين مختلفين غريبًا قليلًا، ولا تنسَ أن إشارة الجمع "+" إشارة قابلة للتحميل الزائد overloaded. الانسحاب Translation تُسمَّى عملية جمع شعاع ونقطة بالانسحاب Translation، ويُقال أحيانًا أن النقطة الأصلية مسحوبةً إلى موقع جديد. قد تكون المصطلحات هنا مربكةً قليلًا، إذ ينتج عن جمع شعاع ونقطة من الناحية الرياضية نقطةٌ جديدة، بحيث تبقى النقطة الأولى دون تغيير، ولكن من الجيد التفكير في الصور "التي تتحرك عبر الشاشة" عند جمع أشعة الإزاحة والنقاط الخاصة بها في مصطلحات الرسوميات الحاسوبية، لذا قد تسمع أحيانًا مصطلحات مثل "تحريك نقطة" و"النقطة القديمة" و"النقطة الجديدة". لقد رأينا تطبيق العمليات التالية: شعاع + شعاع. نقطة + شعاع. نقطة - نقطة. فهل تفترض أنه يمكن إجراء العملية نقطة + نقطة؟ لا يُعَد جمع نقطتين شيئًا هندسيًا. يمكنك تشكيل مجموع شعاعين عموديين يمثلان نقاطًا ميكانيكيًا، ولكن النتيجة لا تكون ذات معنى فعلي. لقد وصلنا إلى نهاية هذا المقال، وسنناقش في المقال التالي العمليات على الأشعة بصورة أكبر، وسنناقش لاحقًا مزيدًا من العمليات على الأشعة. ترجمة -وبتصرُّف- للفصل Vector Addition من كتاب Vector Math for 3D Computer Graphics لصاحبه Bradley Kjell. اقرأ أيضًا المقال السابق: كيفية جمع وطرح المصفوفات العمودية والمصفوفات السطرية الأشعة والنقاط والمصفوفات العمودية في الرسوميات الحاسوبية ثلاثية الأبعاد التعرف على النقاط والخطوط في الرسوميات الحاسوبية ثلاثية الأبعاد -
 سنناقش في هذا المقال كيفية جمع وطرح المصفوفات العمودية والسطرية ولكن لنتعرّف على بعض المصطلحات التي سنستخدمها: النقطة Point: كائن هندسي، وهو موقع في فضاء ثلاثي الأبعاد أو ثنائي الأبعاد. الشعاع Vector: كائن هندسي له خصائص الاتجاه والطول، ولكن ليس لديه خاصية الموقع. المصفوفة العمودية Column Matrix: قائمة مرتبة من الأعداد تُرتَّب ضمن عمود. المصفوفة السطرية Row Matrix: قائمة مرتبة من الأعداد تُرتَّب ضمن صف. العنصر Element: أحد الأعداد التي تشكل المصفوفة العمودية أو السطرية. البعد Dimension: عدد العناصر في مصفوفة عمودية أو سطرية. الإزاحة Displacement: هو الفرق بين موقعين، ويعبَّر عنه باستخدام شعاع. كما سنوضّح في هذا المقال المواضيع التالية: منقول Transpose المصفوفة العمودية أو السطرية. جمع المصفوفات العمودية والمصفوفات السطرية. الخاصية التبديلية لجمع المصفوفات. الخاصية التجميعية لجمع المصفوفات. طرح المصفوفات العمودية والمصفوفات السطرية. الخاصية غير التبديلية لطرح المصفوفات. منقول مصفوفة Transposition ماذا تُسمَّى عملية قَلب مصفوفة العمودية، أو ماذا تُسمَّى عملية قَلب مصفوفة سطرية إلى مصفوفة عمودية؟ تسمّى عملية المنقول Transposition. تُعَد المصفوفة السطرية والمصفوفة العمودية من نوعين مختلفين حتى لو كان لهما البعد نفسه وتحتويان على العناصر نفسها، لذا يُستخدَم الحرف العُلوي "T" عند كتابة مصفوفة عمودية مثل صفٍ من الأعداد، إذ يكون العنصر الأول في المصفوفة العمودية هو العنصر الموجود أعلى العمود، ويكون العنصر الأول في المصفوفة السطرية هو العنصر الموجود على يسار الصف. سنوضح فيما يلي طريقتين لكتابة المصفوفة العمودية نفسها، إذ تُكتَب عناصر المصفوفة العمودية بالطريقة نفسها بغض النظر عن كيفية عرض المصفوفة العمودية. يعني وجودُ حرف T العُلوي في المصفوفة العمودية قلبَ العمود إلى صف، وينتج عنه مصفوفة سطرية، وتستخدم بعض الكتب حرف t صغير. ما هو : (1, 2, 3)T T؟ ( 1, 2, 3 )T T = ( 1, 2, 3 ) يؤدي تطبيق المنقول مرتين إلى العودة إلى ما بدأت به. يبدو هذا واضحًا الآن، ولكن قد يكون من المفيد تذكّر ذلك لاحقًا عند تطبيق المعالجة الجبرية. جمع المصفوفات العمودية يمكن جمع مصفوفتين عموديتين لهما البُعد نفسه، وتنتج مصفوفة عمودية لها البعد نفسه أيضًا، وينطبق الشيء نفسه على المصفوفات السطرية. تُطبَّق عملية الجمع من خلال جمع العناصر المتقابلة لمصفوفات الدخل لإنتاج العناصر المقابلة لمصفوفة الخرج كما يلي: ( 42, -12 )T + ( 8, 24 )T = ( 50, 12 )T ( 32.98, -24.71, 9.392 )T + ( -32.98, +24.71, -9.392 )T = (0, 0, 0)T ( 9.2, -8.6, 3.21, 48.7 ) + ( -2.1, 4.3, 1.0, 2.3 ) = ( 7.1, -4.3, 4.21, 51.0 ) ( 1, 2, 3 ) + ( 10, 20, 30 ) = ( 11, 22, 33 ) إذا كان a و b مصفوفتين من النوع نفسه، فإن a + b = c يعني أن كل عنصر ci = ai + bi أوجد ناتج ما يلي: ( 2, -2 )T + ( 8, 6 )T الجواب: ( 2, -2 )T + ( 8, 6 )T = ( 10, 4 )T جمع المصفوفات ثلاثية الأبعاد يجب أن تكون المصفوفات التي تجمعها لها البُعد والنوع نفسه سواءً كانت عمودية أم سطرية. يجري التعامل مع كل بُعد بصورة مستقلة عن الأبعاد الأخرى عند جمع المصفوفات، فمثلًا سيكون لديك ثلاث عمليات جمع منفصلة باستخدام العمليات الحسابية العادية عند جمع مصفوفتين عموديتين ثلاثيتي الأبعاد، إذ تُجمَع العناصر الأولى من المصفوفات التي تمثل معاملات عملية الجمع لتكوين العنصر الأول من المصفوفة الناتجة. أوجد ناتج ما يلي: ( 8, 4, 6 )T + ( 2, -2, 9 )T ( 2, -2, 9 )T + ( 8, 4, 6 )T الجواب: ( 8, 4, 6 )T + ( 2, -2, 9 )T = ( 10, 2, 15 )T ( 2, -2, 9 )T + ( 8, 4, 6 )T = ( 10, 2, 15 )T الخاصية التبديلية Commutative لجمع المصفوفات تُعَد عملية جمع المصفوفات عملية تبديلية، أي أن: a + b = b + a، وينطبق ذلك على المصفوفات السطرية والعمودية بجميع أبعادها، إذ يمكن القول أن: a + b + c = b + c + a = c + a + b = …... تعني الخاصية التبديلية أن ترتيب جمع المصفوفات غير مهم، إذ تعمل المصفوفات باستخدام طريقة عمل الأعداد نفسها بالنسبة للجمع: 1 + 2 = 2 + 1، فالمصفوفات والأعداد عادةً لا تعمل بالطريقة نفسها ولكنها كذلك بالنسبة لعملية الجمع. أوجد ناتج ما يلي: ( -1, -2, 3 )T + ( 1, 2, -3 )T الجواب: ( -1, -2, 3 )T + ( 1, 2, -3 )T = ( 0, 0, 0 )T المصفوفة العمودية الصفرية ليكن لدينا مثلًا مصفوفة صفرية كما يلي: ( 73.6, -41.4 )T + ( 0.0, 0.0 )T = (73.6, -41.4 )T تُسمَّى المصفوفة التي تكون جميع عناصرها أصفارًا بالمصفوفة الصفرية Zero Matrix، ويكون ناتج جمع المصفوفة الصفرية والمصفوفة a لهما النوع نفسه هو المصفوفة a. نرمّز المصفوفة الصفرية بالرمز 0 (صفر بالخط العريض) الذي يختلف عن 0 (العدد الحقيقي صفر)، ويحدّد السياق الذي ترى فيه الرمز 0 ما إذا كانت مصفوفة صفرية سطرية أم عمودية وعدد العناصر التي تحتوي عليها. فإذا رأيت (73.6, -41.4 )T + 0 ، فيمكنك أن تفترض ما هو النوع الصحيح للمصفوفة 0 والمناسب للتعبير. الخاصية التجميعية Associative لجمع المصفوفات أوجد ناتج ما يلي: ( 2, 5, -9 ) + ( -32.034, 94.79, 201.062 ) + ( -2, -5, 9 ) الجواب: ( 2, 5, -9 ) + ( -32.034, 94.79, 201.062 ) + ( -2, -5, 9 ) = ( -32.034, 94.79, 201.062 ) + ( -2, -5, 9 ) + ( 2, 5, -9 ) = ---------------------------- ( -32.034, 94.79, 201.062 ) + ( 0, 0, 0) = ( -32.034, 94.79, 201.062 ) قد يفقد بعض الطلاب صبرهم عندما يجمّعون المصفوفتين الأوليتين، ثم يجمّعون الناتج مع المصفوفة الثالثة، ولكن يدرك بعضهم أنه يمكن إعادة ترتيب المصفوفات إلى ترتيب أكثر ملاءمة بما أن جمع المصفوفات يُعَد عملية تبديلية، إذ يمكنهم اختيار عملية الجمع "+" التي يريدون تطبيقها أولًا بعد أن تصبح المصفوفات في ترتيب مناسب. يُعَدّ جمع المصفوفات عملية تجميعية، وهذا يعني أن: ( a + b ) + c = a + ( b + c ) أي يمكن جمع المصفوفتين a و b ثم جمع النتيجة مع المصفوفة c، وستكون النتيجة النهائية هي نفسها كما لو جمعت المصفوفة a إلى نتيجة جمع المصفوفتين b و c. يمكن تطبيق ذلك على المصفوفات السطرية والعمودية بجميع أبعادها. هل يمكنك إيجاد ناتج ما يلي في الوقت المناسب؟ ( 25.1, -19.6 ) + ( -5.0, 9.0 ) + ( 12.4, 8.92 ) + ( -20.1, 10.6 ) الجواب: ( 25.1, -19.6 ) + ( -5.0, 9.0 ) + ( 12.4, 8.92 ) + ( -20.1, 10.6 ) = ------------- --------------- \ / \ / \ / \ / ( 25.1, -19.6 ) + ( 12.4, 8.92 ) + ( -25.1, 19.6 ) --------------- --------------- \ / \ / \ / \ / \ / ( 0.0, 0.0 ) + ( 12.4, 8.92 ) = ( 12.4, 8.92 ) بعض الأشياء التي لا يمكن استخدامها عند جمع المصفوفات يعني الرمز "+" زيادة التحميل Overloaded في مصطلحات علوم الحاسوب، مما يعني أن العملية المُستدعاة تعتمد على نوع المعاملات، فمثلًا: يعني الرمز + هنا جمع أعداد حقيقية: 1.34 + -9.06 يعني الرمز + هنا جمع مصفوفات عمودية: ( 84.02, 90.31 )T + ( -14.23, 10.85 )T بينما لا تعطي الأمور التالية أيّ معنًى: لا يمكن جمع عدد ومصفوفة: 34.5 + ( 84.02, 90.31 )T لا يمكن جمع مصفوفة سطرية ومصفوفة عمودية: ( 84.02, 90.31 ) + ( -14.23, 10.85 )T * لا يمكن جمع مصفوفات ذات أبعاد مختلفة: ( 84.02, 90.31 ) + ( -14.23, 10.85, 32.75 ) تكون هذه المشاكل واضحة عند كتابة العناصر كما سبق، ولكنها تكون أقل وضوحًا عند استخدام الرموز المتغيرة كما يلي: لا يمكن جمع عدد ومصفوفة a + x. يجب التأكد من أن المعاملين x + y من النوع نفسه. يمكن إجراء عملية الجمع: ( 4.5, x1, w ) + ( -2.3, 3, y2 ) كما يلي: ( 4.5, x1, w ) + ( -2.3, 3, y2 ) = ( 2.2, x1 +3, w+ y2 ) طرح المصفوفات يمكن طرح مصفوفتين من النوع نفسه وتنتج مصفوفة ثالثة من ذات النوع، إذ يمكن طرح مصفوفتين من خلال طرح العناصر المتقابلة، مع الحرص على إبقاء العناصر بالترتيب نفسه كما يلي: (10, 8, 12 ) - (2, 14, 9 ) = ( 10 - 2, 8 - 14, 12 - 9 ) = ( 8, -6, 3 ) إذا كانت a و b مصفوفتان من النوع نفسه، فإن a - b = c تعني أن كل عنصر ci = ai - bi ليست عملية الطرح تبديلية أوجد ناتج ما يلي: (22, 5, -12 ) - (10, -5, 3 ) (10, -5, 3 ) - (22, 5, -12 ) الجواب: (22, 5, -12 ) - (10, -5, 3 ) = ( 22 - 10, 5 - (-5), -12 - 3 ) = ( 12, 10, -15 ) (10, -5, 3 ) - (22, 5, -12 ) = ( 10 - 22, (-5) - 5, 3 - (-12) ) = (-12, -10, 15 ) حقيقة رياضية: لا تُعَد عملية الطرح تبديلية، وهذا يعني أنه لا يمكنك تغيير الترتيب عند طرح المصفوفتين a - b. يمكن إيجاد معاكس مصفوفة -a من خلال إيجاد معاكس كل عنصر من عناصر هذه المصفوفة كما يلي: -(22, 5, -12 ) = ( -22, -5, 12 ) -( 19.2, 28.6, 0.0 )T = ( -19.2, -28.6, 0.0 )T يمكن القول أنه إذا كانت a هي ( a0, a1, …, a2) فإن -a تعني (-a0, -a1, …, -a2). إدخال الإشارة السالبة داخل الأقواس أوجد ناتج عملية الطرح التالية: ( -7.2, -98.6, 0.0 )T - ( -2.2, -2.4, 3.0 )T الجواب: ( -7.2, -98.6, 0.0 )T - ( -2.2, -2.4, 3.0 )T = ( -7.2 -(-2.2), -98.6 -(-2.4), 0.0 - 3.0)T = ( -5.0, -96.2, - 3.0)T ولكن قد تجد أن الطريقة التالية أسهل للحل: ( -7.2, -98.6, 0.0 )T - ( -2.2, -2.4, 3.0 )T = ( -7.2, -98.6, 0.0 )T + ( +2.2, +2.4, -3.0 )T = ( -5.0, -96.2, - 3.0)T اُستخدِمت الإشارة السالبة الخارجية لعكس إشارة المصفوفة الثانية، ثم تُجمَع المصفوفتان الناتجتان كما يلي: a - b = a + (-b) قد يكون من المفيد تذكّر ذلك، حيث يمكنك عكس إشارة المصفوفات بحيث تكون العملية هي جمع المصفوفات ثم إعادة ترتيب عملية الجمع لأن عملية الجمع تُعَد عملية تبديلية: a - b + c - d = a + (-b) + c + (-d) = (-d) + a + c + (-b) = الجمع بأيّ ترتيب تريده إليك بعض الحقائق الأخرى: a + (-a) = 0 a - a = 0 لاحظ أن 0 هي المصفوفة الصفرية، ولها نوع المصفوفة a نفسه ولكن تكون جميع عناصرها صفر. أجرِ العملية التالية: ( 4, -5, 6.2 ) + ( -43.132, 13.6, 86.5 ) - ( 4, -5, -4.8 ) حاول إعادة الترتيب بدلًا من التسرع والحساب مباشرةً: ( 4, -5, 6.2 ) + ( -43.132, 13.6, 86.5 ) - ( 4, -5, -4.8 ) = ( 4, -5, 6.2 ) + ( -43.132, 13.6, 86.5 ) + ( -4, 5, 4.8 ) = ( 4, -5, 6.2 ) + ( -4, 5, 4.8 ) + ( -43.132, 13.6, 86.5 ) = ( 0, 0, 11 ) + ( -43.132, 13.6, 86.5 ) = (-43.132, 13.6, 97.5 ) وقد تتخطى بعض الخطوات إذا حاولت الحساب ذهنيًا. تدريب عملي أولًا، ما هو مجموع الإزاحات الثلاثة التالية: d = ( -12.4, 14.8, 0.0 )T e = ( 6.2, -10.2, 17.0 )T f= ( 6.2, -4.6, -17.0 )T والناتج هو: (0.0, 0.0 0.0)T. ثانيًا، أوجد قيمة x و y و z بحيث يكون ما يلي صحيحًا: a = ( 8.6, 7.4, 3.9 ) b = ( 4.2, 2.2, -3.0 ) c = ( x, y, z ) a + b + c = 0 وبالتالي يمكن كتابة ما يلي: a + b + c = ( 12.8, 9.6, 0.9 ) + (x, y, z) = ( 12.8+x, 9.6+y, 0.9+z ) = (0, 0, 0) لذا يجب أن يكون: 12.8 + x = 0; x = -12.8 9.6 + y = 0; y = -9.6 0.9 + z = 0; z = -0.9 استخدام الجبر في جمع وطرح المصفوفات كان التمرين السابق هو العثور على عناصر المصفوفة c عندما: a** + b + c = 0**، ولكن إن لم تكن على علمٍ أنها مصفوفات، فقد تميل إلى حل هذا التمرين باستخدام جبر الأعداد الحقيقية real كما يلي: a + b + c = 0 a + b = -c + 0 (a + b) = -c -(a + b) = c يمكن استخدام هذه الطريقة طالما أن المصفوفات من النوع نفسه، والعمليات هي جمع "+" أو طرح "-" فقط، وبالتالي يمكنك التظاهر بأنك تطبّق عمليات جبرية عادية. لاحظ أن المعادلة الأخيرة تعني "اجمع a مع b، ثم اعكس إشارة النتيجة لتحصل على c". لنتعمق أكثر ولننظر فقط إلى العناصر الأولى من المصفوفات: ( a0, … ) + ( b0, … ) + ( c0, … ) = ( 0, …) ( a0, … ) + ( b0, … ) = -( c0, … ) + ( 0, …) ( a0, … ) + ( b0, … ) = -(c0, … ) ( a0 + b0, … ) = -( c0, … ) -( a0 + b0, … ) = ( c0, … ) -( a0 + b0) = c0 إذا كان ذلك غير منظم بالنسبة لك، فامسح ذهنيًا بعض الأشياء غير المرغوب فيها كما يلي: a0 + b0 + c0 = 0 a0 + b0 = -c0 + 0 a0 + b0 = -c0 a0 + b0 = -c0 -( a0 + b0) = c0 وتتبع العناصر الأخرى النمط نفسه، وبالتالي تكون النتيجة صحيحة بالنسبة للمصفوفة ككل. أوجد قيمة c1 و c0 بحيث يكون ما يلي صحيحًا: a = ( -4, 2 )T b = ( 8, 3 )T c = ( c0, c1 )T a + b + c = 0 ويكون الحل باستخدام الطريقة التالية: a + b + c = 0 a + b = -c ( 4, 5 )T = -( c0, c1 )T -( 4, 5 )T = ( c0, c1 )T (-4, -5 )T = ( c0, c1 )T وبالتالي: c0 = -4 c1 = -5 وصلنا إلى نهاية المقال الذي تعلّمنا من خلاله كيفية جمع وطرح المصفوفات وسنوظّف هذه المعرفة في المقال التالي لتعلّم كيفية جمع [الأشعة](رابط المقال التالي). ترجمة -وبتصرُّف- للفصل Matrix Addition من كتاب Vector Math for 3D Computer Graphics لصاحبه Bradley Kjell. اقرأ المزيد المقال السابق الأشعة والنقاط والمصفوفات العمودية في الرسوميات الحاسوبية ثلاثية الأبعاد. أنواع البيانات والعمليات الأساسية في لغة بايثون.
سنناقش في هذا المقال كيفية جمع وطرح المصفوفات العمودية والسطرية ولكن لنتعرّف على بعض المصطلحات التي سنستخدمها: النقطة Point: كائن هندسي، وهو موقع في فضاء ثلاثي الأبعاد أو ثنائي الأبعاد. الشعاع Vector: كائن هندسي له خصائص الاتجاه والطول، ولكن ليس لديه خاصية الموقع. المصفوفة العمودية Column Matrix: قائمة مرتبة من الأعداد تُرتَّب ضمن عمود. المصفوفة السطرية Row Matrix: قائمة مرتبة من الأعداد تُرتَّب ضمن صف. العنصر Element: أحد الأعداد التي تشكل المصفوفة العمودية أو السطرية. البعد Dimension: عدد العناصر في مصفوفة عمودية أو سطرية. الإزاحة Displacement: هو الفرق بين موقعين، ويعبَّر عنه باستخدام شعاع. كما سنوضّح في هذا المقال المواضيع التالية: منقول Transpose المصفوفة العمودية أو السطرية. جمع المصفوفات العمودية والمصفوفات السطرية. الخاصية التبديلية لجمع المصفوفات. الخاصية التجميعية لجمع المصفوفات. طرح المصفوفات العمودية والمصفوفات السطرية. الخاصية غير التبديلية لطرح المصفوفات. منقول مصفوفة Transposition ماذا تُسمَّى عملية قَلب مصفوفة العمودية، أو ماذا تُسمَّى عملية قَلب مصفوفة سطرية إلى مصفوفة عمودية؟ تسمّى عملية المنقول Transposition. تُعَد المصفوفة السطرية والمصفوفة العمودية من نوعين مختلفين حتى لو كان لهما البعد نفسه وتحتويان على العناصر نفسها، لذا يُستخدَم الحرف العُلوي "T" عند كتابة مصفوفة عمودية مثل صفٍ من الأعداد، إذ يكون العنصر الأول في المصفوفة العمودية هو العنصر الموجود أعلى العمود، ويكون العنصر الأول في المصفوفة السطرية هو العنصر الموجود على يسار الصف. سنوضح فيما يلي طريقتين لكتابة المصفوفة العمودية نفسها، إذ تُكتَب عناصر المصفوفة العمودية بالطريقة نفسها بغض النظر عن كيفية عرض المصفوفة العمودية. يعني وجودُ حرف T العُلوي في المصفوفة العمودية قلبَ العمود إلى صف، وينتج عنه مصفوفة سطرية، وتستخدم بعض الكتب حرف t صغير. ما هو : (1, 2, 3)T T؟ ( 1, 2, 3 )T T = ( 1, 2, 3 ) يؤدي تطبيق المنقول مرتين إلى العودة إلى ما بدأت به. يبدو هذا واضحًا الآن، ولكن قد يكون من المفيد تذكّر ذلك لاحقًا عند تطبيق المعالجة الجبرية. جمع المصفوفات العمودية يمكن جمع مصفوفتين عموديتين لهما البُعد نفسه، وتنتج مصفوفة عمودية لها البعد نفسه أيضًا، وينطبق الشيء نفسه على المصفوفات السطرية. تُطبَّق عملية الجمع من خلال جمع العناصر المتقابلة لمصفوفات الدخل لإنتاج العناصر المقابلة لمصفوفة الخرج كما يلي: ( 42, -12 )T + ( 8, 24 )T = ( 50, 12 )T ( 32.98, -24.71, 9.392 )T + ( -32.98, +24.71, -9.392 )T = (0, 0, 0)T ( 9.2, -8.6, 3.21, 48.7 ) + ( -2.1, 4.3, 1.0, 2.3 ) = ( 7.1, -4.3, 4.21, 51.0 ) ( 1, 2, 3 ) + ( 10, 20, 30 ) = ( 11, 22, 33 ) إذا كان a و b مصفوفتين من النوع نفسه، فإن a + b = c يعني أن كل عنصر ci = ai + bi أوجد ناتج ما يلي: ( 2, -2 )T + ( 8, 6 )T الجواب: ( 2, -2 )T + ( 8, 6 )T = ( 10, 4 )T جمع المصفوفات ثلاثية الأبعاد يجب أن تكون المصفوفات التي تجمعها لها البُعد والنوع نفسه سواءً كانت عمودية أم سطرية. يجري التعامل مع كل بُعد بصورة مستقلة عن الأبعاد الأخرى عند جمع المصفوفات، فمثلًا سيكون لديك ثلاث عمليات جمع منفصلة باستخدام العمليات الحسابية العادية عند جمع مصفوفتين عموديتين ثلاثيتي الأبعاد، إذ تُجمَع العناصر الأولى من المصفوفات التي تمثل معاملات عملية الجمع لتكوين العنصر الأول من المصفوفة الناتجة. أوجد ناتج ما يلي: ( 8, 4, 6 )T + ( 2, -2, 9 )T ( 2, -2, 9 )T + ( 8, 4, 6 )T الجواب: ( 8, 4, 6 )T + ( 2, -2, 9 )T = ( 10, 2, 15 )T ( 2, -2, 9 )T + ( 8, 4, 6 )T = ( 10, 2, 15 )T الخاصية التبديلية Commutative لجمع المصفوفات تُعَد عملية جمع المصفوفات عملية تبديلية، أي أن: a + b = b + a، وينطبق ذلك على المصفوفات السطرية والعمودية بجميع أبعادها، إذ يمكن القول أن: a + b + c = b + c + a = c + a + b = …... تعني الخاصية التبديلية أن ترتيب جمع المصفوفات غير مهم، إذ تعمل المصفوفات باستخدام طريقة عمل الأعداد نفسها بالنسبة للجمع: 1 + 2 = 2 + 1، فالمصفوفات والأعداد عادةً لا تعمل بالطريقة نفسها ولكنها كذلك بالنسبة لعملية الجمع. أوجد ناتج ما يلي: ( -1, -2, 3 )T + ( 1, 2, -3 )T الجواب: ( -1, -2, 3 )T + ( 1, 2, -3 )T = ( 0, 0, 0 )T المصفوفة العمودية الصفرية ليكن لدينا مثلًا مصفوفة صفرية كما يلي: ( 73.6, -41.4 )T + ( 0.0, 0.0 )T = (73.6, -41.4 )T تُسمَّى المصفوفة التي تكون جميع عناصرها أصفارًا بالمصفوفة الصفرية Zero Matrix، ويكون ناتج جمع المصفوفة الصفرية والمصفوفة a لهما النوع نفسه هو المصفوفة a. نرمّز المصفوفة الصفرية بالرمز 0 (صفر بالخط العريض) الذي يختلف عن 0 (العدد الحقيقي صفر)، ويحدّد السياق الذي ترى فيه الرمز 0 ما إذا كانت مصفوفة صفرية سطرية أم عمودية وعدد العناصر التي تحتوي عليها. فإذا رأيت (73.6, -41.4 )T + 0 ، فيمكنك أن تفترض ما هو النوع الصحيح للمصفوفة 0 والمناسب للتعبير. الخاصية التجميعية Associative لجمع المصفوفات أوجد ناتج ما يلي: ( 2, 5, -9 ) + ( -32.034, 94.79, 201.062 ) + ( -2, -5, 9 ) الجواب: ( 2, 5, -9 ) + ( -32.034, 94.79, 201.062 ) + ( -2, -5, 9 ) = ( -32.034, 94.79, 201.062 ) + ( -2, -5, 9 ) + ( 2, 5, -9 ) = ---------------------------- ( -32.034, 94.79, 201.062 ) + ( 0, 0, 0) = ( -32.034, 94.79, 201.062 ) قد يفقد بعض الطلاب صبرهم عندما يجمّعون المصفوفتين الأوليتين، ثم يجمّعون الناتج مع المصفوفة الثالثة، ولكن يدرك بعضهم أنه يمكن إعادة ترتيب المصفوفات إلى ترتيب أكثر ملاءمة بما أن جمع المصفوفات يُعَد عملية تبديلية، إذ يمكنهم اختيار عملية الجمع "+" التي يريدون تطبيقها أولًا بعد أن تصبح المصفوفات في ترتيب مناسب. يُعَدّ جمع المصفوفات عملية تجميعية، وهذا يعني أن: ( a + b ) + c = a + ( b + c ) أي يمكن جمع المصفوفتين a و b ثم جمع النتيجة مع المصفوفة c، وستكون النتيجة النهائية هي نفسها كما لو جمعت المصفوفة a إلى نتيجة جمع المصفوفتين b و c. يمكن تطبيق ذلك على المصفوفات السطرية والعمودية بجميع أبعادها. هل يمكنك إيجاد ناتج ما يلي في الوقت المناسب؟ ( 25.1, -19.6 ) + ( -5.0, 9.0 ) + ( 12.4, 8.92 ) + ( -20.1, 10.6 ) الجواب: ( 25.1, -19.6 ) + ( -5.0, 9.0 ) + ( 12.4, 8.92 ) + ( -20.1, 10.6 ) = ------------- --------------- \ / \ / \ / \ / ( 25.1, -19.6 ) + ( 12.4, 8.92 ) + ( -25.1, 19.6 ) --------------- --------------- \ / \ / \ / \ / \ / ( 0.0, 0.0 ) + ( 12.4, 8.92 ) = ( 12.4, 8.92 ) بعض الأشياء التي لا يمكن استخدامها عند جمع المصفوفات يعني الرمز "+" زيادة التحميل Overloaded في مصطلحات علوم الحاسوب، مما يعني أن العملية المُستدعاة تعتمد على نوع المعاملات، فمثلًا: يعني الرمز + هنا جمع أعداد حقيقية: 1.34 + -9.06 يعني الرمز + هنا جمع مصفوفات عمودية: ( 84.02, 90.31 )T + ( -14.23, 10.85 )T بينما لا تعطي الأمور التالية أيّ معنًى: لا يمكن جمع عدد ومصفوفة: 34.5 + ( 84.02, 90.31 )T لا يمكن جمع مصفوفة سطرية ومصفوفة عمودية: ( 84.02, 90.31 ) + ( -14.23, 10.85 )T * لا يمكن جمع مصفوفات ذات أبعاد مختلفة: ( 84.02, 90.31 ) + ( -14.23, 10.85, 32.75 ) تكون هذه المشاكل واضحة عند كتابة العناصر كما سبق، ولكنها تكون أقل وضوحًا عند استخدام الرموز المتغيرة كما يلي: لا يمكن جمع عدد ومصفوفة a + x. يجب التأكد من أن المعاملين x + y من النوع نفسه. يمكن إجراء عملية الجمع: ( 4.5, x1, w ) + ( -2.3, 3, y2 ) كما يلي: ( 4.5, x1, w ) + ( -2.3, 3, y2 ) = ( 2.2, x1 +3, w+ y2 ) طرح المصفوفات يمكن طرح مصفوفتين من النوع نفسه وتنتج مصفوفة ثالثة من ذات النوع، إذ يمكن طرح مصفوفتين من خلال طرح العناصر المتقابلة، مع الحرص على إبقاء العناصر بالترتيب نفسه كما يلي: (10, 8, 12 ) - (2, 14, 9 ) = ( 10 - 2, 8 - 14, 12 - 9 ) = ( 8, -6, 3 ) إذا كانت a و b مصفوفتان من النوع نفسه، فإن a - b = c تعني أن كل عنصر ci = ai - bi ليست عملية الطرح تبديلية أوجد ناتج ما يلي: (22, 5, -12 ) - (10, -5, 3 ) (10, -5, 3 ) - (22, 5, -12 ) الجواب: (22, 5, -12 ) - (10, -5, 3 ) = ( 22 - 10, 5 - (-5), -12 - 3 ) = ( 12, 10, -15 ) (10, -5, 3 ) - (22, 5, -12 ) = ( 10 - 22, (-5) - 5, 3 - (-12) ) = (-12, -10, 15 ) حقيقة رياضية: لا تُعَد عملية الطرح تبديلية، وهذا يعني أنه لا يمكنك تغيير الترتيب عند طرح المصفوفتين a - b. يمكن إيجاد معاكس مصفوفة -a من خلال إيجاد معاكس كل عنصر من عناصر هذه المصفوفة كما يلي: -(22, 5, -12 ) = ( -22, -5, 12 ) -( 19.2, 28.6, 0.0 )T = ( -19.2, -28.6, 0.0 )T يمكن القول أنه إذا كانت a هي ( a0, a1, …, a2) فإن -a تعني (-a0, -a1, …, -a2). إدخال الإشارة السالبة داخل الأقواس أوجد ناتج عملية الطرح التالية: ( -7.2, -98.6, 0.0 )T - ( -2.2, -2.4, 3.0 )T الجواب: ( -7.2, -98.6, 0.0 )T - ( -2.2, -2.4, 3.0 )T = ( -7.2 -(-2.2), -98.6 -(-2.4), 0.0 - 3.0)T = ( -5.0, -96.2, - 3.0)T ولكن قد تجد أن الطريقة التالية أسهل للحل: ( -7.2, -98.6, 0.0 )T - ( -2.2, -2.4, 3.0 )T = ( -7.2, -98.6, 0.0 )T + ( +2.2, +2.4, -3.0 )T = ( -5.0, -96.2, - 3.0)T اُستخدِمت الإشارة السالبة الخارجية لعكس إشارة المصفوفة الثانية، ثم تُجمَع المصفوفتان الناتجتان كما يلي: a - b = a + (-b) قد يكون من المفيد تذكّر ذلك، حيث يمكنك عكس إشارة المصفوفات بحيث تكون العملية هي جمع المصفوفات ثم إعادة ترتيب عملية الجمع لأن عملية الجمع تُعَد عملية تبديلية: a - b + c - d = a + (-b) + c + (-d) = (-d) + a + c + (-b) = الجمع بأيّ ترتيب تريده إليك بعض الحقائق الأخرى: a + (-a) = 0 a - a = 0 لاحظ أن 0 هي المصفوفة الصفرية، ولها نوع المصفوفة a نفسه ولكن تكون جميع عناصرها صفر. أجرِ العملية التالية: ( 4, -5, 6.2 ) + ( -43.132, 13.6, 86.5 ) - ( 4, -5, -4.8 ) حاول إعادة الترتيب بدلًا من التسرع والحساب مباشرةً: ( 4, -5, 6.2 ) + ( -43.132, 13.6, 86.5 ) - ( 4, -5, -4.8 ) = ( 4, -5, 6.2 ) + ( -43.132, 13.6, 86.5 ) + ( -4, 5, 4.8 ) = ( 4, -5, 6.2 ) + ( -4, 5, 4.8 ) + ( -43.132, 13.6, 86.5 ) = ( 0, 0, 11 ) + ( -43.132, 13.6, 86.5 ) = (-43.132, 13.6, 97.5 ) وقد تتخطى بعض الخطوات إذا حاولت الحساب ذهنيًا. تدريب عملي أولًا، ما هو مجموع الإزاحات الثلاثة التالية: d = ( -12.4, 14.8, 0.0 )T e = ( 6.2, -10.2, 17.0 )T f= ( 6.2, -4.6, -17.0 )T والناتج هو: (0.0, 0.0 0.0)T. ثانيًا، أوجد قيمة x و y و z بحيث يكون ما يلي صحيحًا: a = ( 8.6, 7.4, 3.9 ) b = ( 4.2, 2.2, -3.0 ) c = ( x, y, z ) a + b + c = 0 وبالتالي يمكن كتابة ما يلي: a + b + c = ( 12.8, 9.6, 0.9 ) + (x, y, z) = ( 12.8+x, 9.6+y, 0.9+z ) = (0, 0, 0) لذا يجب أن يكون: 12.8 + x = 0; x = -12.8 9.6 + y = 0; y = -9.6 0.9 + z = 0; z = -0.9 استخدام الجبر في جمع وطرح المصفوفات كان التمرين السابق هو العثور على عناصر المصفوفة c عندما: a** + b + c = 0**، ولكن إن لم تكن على علمٍ أنها مصفوفات، فقد تميل إلى حل هذا التمرين باستخدام جبر الأعداد الحقيقية real كما يلي: a + b + c = 0 a + b = -c + 0 (a + b) = -c -(a + b) = c يمكن استخدام هذه الطريقة طالما أن المصفوفات من النوع نفسه، والعمليات هي جمع "+" أو طرح "-" فقط، وبالتالي يمكنك التظاهر بأنك تطبّق عمليات جبرية عادية. لاحظ أن المعادلة الأخيرة تعني "اجمع a مع b، ثم اعكس إشارة النتيجة لتحصل على c". لنتعمق أكثر ولننظر فقط إلى العناصر الأولى من المصفوفات: ( a0, … ) + ( b0, … ) + ( c0, … ) = ( 0, …) ( a0, … ) + ( b0, … ) = -( c0, … ) + ( 0, …) ( a0, … ) + ( b0, … ) = -(c0, … ) ( a0 + b0, … ) = -( c0, … ) -( a0 + b0, … ) = ( c0, … ) -( a0 + b0) = c0 إذا كان ذلك غير منظم بالنسبة لك، فامسح ذهنيًا بعض الأشياء غير المرغوب فيها كما يلي: a0 + b0 + c0 = 0 a0 + b0 = -c0 + 0 a0 + b0 = -c0 a0 + b0 = -c0 -( a0 + b0) = c0 وتتبع العناصر الأخرى النمط نفسه، وبالتالي تكون النتيجة صحيحة بالنسبة للمصفوفة ككل. أوجد قيمة c1 و c0 بحيث يكون ما يلي صحيحًا: a = ( -4, 2 )T b = ( 8, 3 )T c = ( c0, c1 )T a + b + c = 0 ويكون الحل باستخدام الطريقة التالية: a + b + c = 0 a + b = -c ( 4, 5 )T = -( c0, c1 )T -( 4, 5 )T = ( c0, c1 )T (-4, -5 )T = ( c0, c1 )T وبالتالي: c0 = -4 c1 = -5 وصلنا إلى نهاية المقال الذي تعلّمنا من خلاله كيفية جمع وطرح المصفوفات وسنوظّف هذه المعرفة في المقال التالي لتعلّم كيفية جمع [الأشعة](رابط المقال التالي). ترجمة -وبتصرُّف- للفصل Matrix Addition من كتاب Vector Math for 3D Computer Graphics لصاحبه Bradley Kjell. اقرأ المزيد المقال السابق الأشعة والنقاط والمصفوفات العمودية في الرسوميات الحاسوبية ثلاثية الأبعاد. أنواع البيانات والعمليات الأساسية في لغة بايثون. -
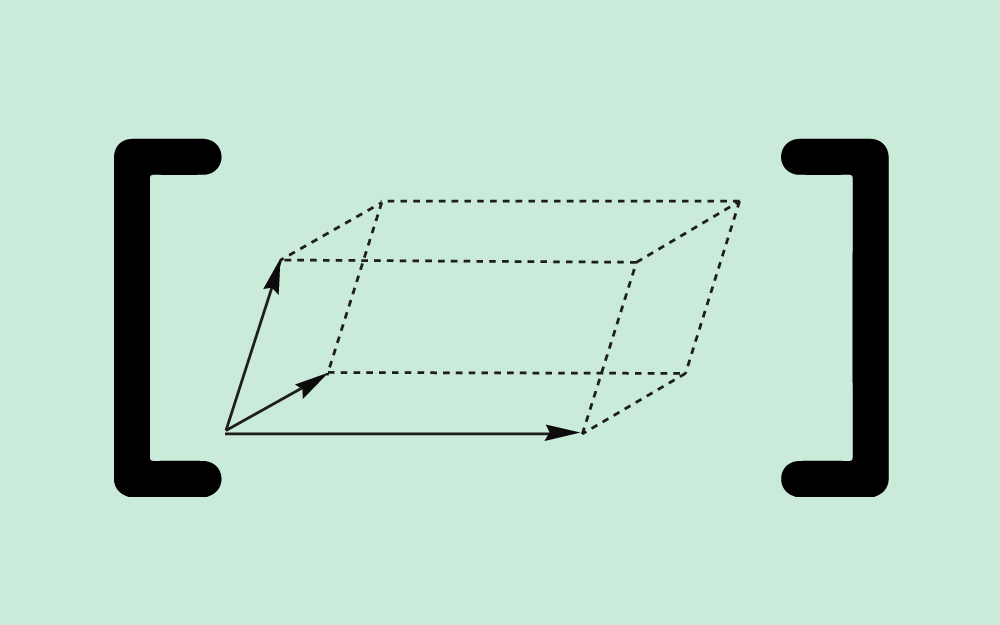 سنناقش في هذا المقال كائنات الرسوميات الحاسوبية التي هي الأشعة والنقاط وكيفية تمثيلها في الحاسوب بوصفها مصفوفات عمودية، فالمصفوفة العمودية column matrix هي كائن رياضي له العديد من الاستخدامات إلى جانب استخدامه في الرسوميات الحاسوبية، ولكن سنتعرف في هذا المقال على كيفية استخدامها في الرسوميات الحاسوبية فقط. سنتعرّف في هذا المقال على المواضيع التالية: نمذجة وعرض الرسوميات الحاسوبية. النقاط والأشعة الهندسية. المصفوفات العمودية والسطرية. حساب الإزاحات. مساواة المصفوفات العمودية. أسماء المصفوفات العمودية وعناصرها. تمثيل النقاط باستخدام المصفوفات العمودية. تُعَد النقاط والأشعة الهندسية ضروريةً في الرسوميات الحاسوبية، ويجب تمثيلها بطريقة تسهّل التعامل معها، لذا تُعَد المصفوفة العمودية الخيار المعتاد لذلك. تستخدم بعض كتب الرسوميات مصطلح الشعاع العمودي Column Vector للتعبير عن الكائن الذي نسميه في مقالنا بالمصفوفة العمودية، إذ يُعَد ذلك مجرد اختلافٍ في المصطلحات ولا يؤثر على المفاهيم أو الصيغ التي سنوضّحها لاحقًا، ولكن المشكلة الأسوأ هي أن بعض الكتب تستخدم المصفوفات السطرية Row Matrices، فالمصفوفات العمودية والمصفوفات السطرية متكافئة، ولكن المعادلات المكتوبة باستخدام المصفوفات السطرية ليست هي نفسها المكتوبة باستخدام المصفوفات العمودية. يمكننا ضبط هذه الاختلافات، ولكنها مزعجة قليلًا. مثال مشهد السائح الافتراضي ما هما نوعا الكائنات الهندسية التي يمكن تمثيلها باستخدام المصفوفات العمودية؟ هما النقاط والأشعة. تتكون الرسوميات الحاسوبية من نشاطين: أولهما إنشاء عالم خيالي ثلاثي الأبعاد في الحاسوب، وثانيهما إنتاج صور ثنائية الأبعاد لذلك العالم من نقاط نظر مختلفة. يشبه برنامج الرسوميات السائحَ الذي يتجول في معالم طبيعية رائعة ويلتقط الصور بالكاميرا، ويُجهَّز السائح الافتراضي بكاميرا سينمائية مع الرسوم المتحركة الحاسوبية. يتكون المشهد الخيالي من كائنات في فضاء ثلاثي الأبعاد، ويُحدَّد كل كائن باستخدام النقاط والخطوط التي تقع على سطحه مثل المشهد الشتوي السابق لصاحبه توان فان Tuan Phan. يتكون هذا النموذج من نقاط وقطع مستقيمة تربط بينها، وهناك حاجة إلى مزيدٍ من العمل لملء المنطقة بين القطع المستقيمة ولتطبيق الإضاءة للحصول على صورة واقعية. صورة المشهد الكاملة هل يمكن تمثيل الكرة باستخدام النقاط والخطوط؟ نعم، بالتأكيد. انظر إلى جسد رجل الثلج، إذ يبدو الشكل وكأنه كرة عند ملء المضلعات. هذه هي الصورة الكاملة، مع ملء المضلعات وتطبيق الإضاءة وإلقاء قليلٍ من ندف الثلج. يمكنك طلب نماذج من الكرات والأسطوانات والأقماع ووضعها في مشهدك في المكان الذي تريده باستخدام حزم الرسوميات الحاسوبية ثلاثية الأبعاد مثل OpenGL التي تملأ أيضًا المضلعات تلقائيًا وتطبّق نموذج الإضاءة لإنتاج تظليل واقعي. مشهد افتراضي آخر هل يمكن لسائحنا الافتراضي أن يتجول في مشهد الثلوج الافتراضي ويلتقط صورة مختلفة؟ نعم، يمكنه ذلك. يضع نموذج المشهد الثلجي كائنات مختلفة في فضاء ثلاثي الأبعاد، وبالتالي يمكن لسائحنا الافتراضي أن يتجول على يمين رجل الثلج ويلتقط صورةً أخرى ثنائية الأبعاد باستخدام الكاميرا الافتراضية، إذ أُنتِجت الصورة السابقة باستخدام النموذج والإضاءة نفسها، ولكن مع وضعٍ مختلف للكاميرا. الشعاع Vector ما هي النقطة؟ وضحنا في المقال السابق مفهوم النقطة بأنها موقع في الفضاء، حيث تُعَد النقطة في الهندسة موقعًا في الفضاء فليس لها حجم وخاصيتها الوحيدة هي الموقع، بينما تكون النقطة عادةً في الرسوميات الحاسوبية هي رأس الشكل ثلاثي الأبعاد. أما الشعاع الهندسي فله خاصيتان: الطول والاتجاه، ولكن ليس له موقع ثابت في الفضاء، فإذا كان له موقع ثابت، فسيكون قطعة مستقيمة. قد يكون الحديث عن شيء ليس له موقع أمرًا غريبًا، ولكنه يسهّل تطبيق الرسوميات الحاسوبية ثلاثية الأبعاد. يسمى هذا المزيج من "المسافة والاتجاه" بالإزاحة Displacement أحيانًا، ويمكن تطبيق الإزاحة نفسها (أي إزاحة واحدة فقط) على كل نقطة من النقاط المختلفة. لنفترض أن لدينا المكعب التالي مثلًا، إذ يحتوي الوجه الأمامي على أربعة رؤوس (أربع نقاط). إذا تحركتَ من كل نقطة من هذه النقاط بمقدار المسافة والاتجاه نفسه، فستصل إلى النقاط الأربعة للوجه الخلفي. تمثل العبارة "المسافة والاتجاه نفسه" الشعاعَ الذي يظهر بوصفه خطًا مع رأس سهم، ويوضح الشكل التالي هذا الشعاع أربع مرات، مرة واحدة لكل نقطة من الوجه. المصفوفة العمودية لنفترض أنك قضيت عطلة الربيع على الشاطئ والشمس مشرقة، فهل يسطع ضوء الشمس في الاتجاه نفسه لكل الموجودين على الشاطئ؟ نعم، إذ يكون "الاتجاه نحو الشمس" نفسه لكل الموجودين على الشاطئ، وبالتالي فهو شعاع. نهتم أحيانًا بالاتجاه فقط دون الاهتمام بالموقع أو بالطول كما في السؤال السابق، لذا نستخدم الشعاع لهذا الغرض، فطوله ليس مهمًا، لأننا نستخدم طولًا واحدًا في كثير من الأحيان. نهتم في أحيانٍ أخرى بكلٍ من الاتجاه والحجم، وعندها يُستخدَم كلٌّ من اتجاه وطول الشعاع. يمكن تمثيل الشعاع بقائمةٍ من الأعداد تدعى المصفوفة العمودية، والتي هي قائمة مرتبة من الأعداد المكتوبة ضمن عمود. تستخدم بعض الكتب كلمة "شعاع" لتعبّر عن فكرة الشعاع وتمثيله بوصفه ترتيبًا لثلاثة أعداد، ولكن يمكن أن يكون ذلك مربكًا أحيانًا. إليك فيما يلي مثالًا لمصفوفة عمودية: يسمى كل عددٍ في المصفوفة العمودية عنصرًا Element، وتكون هذه الأعداد حقيقية real، ويسمى عدد العناصر في الشعاع بالبُعد Dimension. المصفوفة السطرية Row Matrix هي قائمة مرتبة من الأعداد المكتوبة في صف واحد مثل المصفوفة السطرية: (12.5, -9.34). سنمثّل الأشعة دائمًا باستخدام مصفوفات عمودية بهدف التناسق، وتمثل بعض الكتب الأشعة باستخدام مصفوفات سطرية، إذ لا يحدث ذلك فرقًا جوهريًا، ولكنه يغيّر بعض الصيغ الرياضية قليلًا. ما هو عدد العناصر الموجودة في كل مصفوفة عمودية؟ الجواب هو: استخدام المتغيرات بوصفها عناصر مصفوفة يمكن أن تكون عناصر المصفوفة العمودية متغيرات variables كما يلي: يُعطَى العنصر الأول في المصفوفة العمودية أحيانًا الفهرس "0" أوالفهرس "1" أحيانًا. العرض المناسب للمصفوفة العمودية هل المصفوفة العمودية التالية: هي المصفوفة العمودية التالية نفسها؟ لا يمكن ذلك، فالمصفوفة العمودية هي قائمة مرتبة من الأعداد، وهذا يعني أن كل موضع في المصفوفة العمودية يحتوي على عدد أو متغير معين. يُعَد مظهر المصفوفات العمودية غريبًا في النصوص المطبوعة، لذا من الشائع كتابتها كما يلي: (2.9, -4.6, 0.0) T يرمز الحرف "T" إلى منقول المصفوفة Transpose الذي يعني تحويل الصفوف إلى أعمدة (سنوضح لاحقًا بالتفصيل معنى المنقول). المساواة بين المصفوفات هل المصفوفة (1.2, -3.9, 0.0) تساوي المصفوفة (1.2, -3.9, 0.0)T؟ لا، فالمصفوفة الأولى هي مصفوفة سطرية، والمصفوفة الثانية هي مصفوفة عمودية، أي مكتوبة ضمن صف، ولكن الحرف "T" يعني أنها مصفوفة عمودية، إذ تُعَد المصفوفات السطرية والمصفوفات العمودية أنواعًا مختلفة من الكائنات، ولا يمكن أن تكون متساوية. ربما لم نميّز سابقًا بين المصفوفات السطرية والمصفوفات العمودية، ولم نوضِّح اختلاف الأشعة الهندسية عن المصفوفات العمودية المستخدمة لتمثيل هذه الأشعة، إذ يمكن أن تبدو هذه الاختلافات صعبة حاليًا، ولكن أبقِها حاضرةً في ذهنك لتجنب الالتباس مستقبلًا. يمكن أن تكون المصفوفتان العموديتان متساويتين إذا كانت: كلتا المصفوفتين مصفوفةً عمودية. لكل منهما البعد (عدد العناصر) نفسه. العناصر المقابلة لبعضها البعض في المصفوفتين متساوية. يمكن أن تكون المصفوفتان السطريتان متساويتين إذا كان: كلتا المصفوفتين مصفوفات سطرية. لكل منهما البعد (عدد العناصر) نفسه. العناصر المقابلة لبعضها البعض في المصفوفتين متساوية. الفروق الدقيقة بين المصفوفات هل المصفوفتان السطريتان (8.0, -1.63, 7.0, 0.0) و (8.0, -1.63, 7.0, 1.0) متساويتان؟ لا. يمكن مقارنة المصفوفات من النوع نفسه فقط، إذ يمكنك المقارنة بين مصفوفتين عموديتين ثلاثيتي الأبعاد، أو مصفوفتين سطريتين رباعيتي الأبعاد مثلًا، فليس من المنطقي مقارنة مصفوفة سطرية ثلاثية الأبعاد مع مصفوفة عمودية ثلاثية الأبعاد. ( 6, 8, 12, -3 )T = ( 6, 8, 12, -3)T ( 6, 8, 12, -3 ) = ( 6, 8, 12, -3 ) ( 6, 8, 12, -3 ) ≠ ( -2.3, 8, 12, -3 ) ( 6, 8, 12, -3 )T ≠ ( 6, 8, 12, -3 ) ( 6, 8, 12, -3 )T ≠ ( 6, 8, 12 )T يمثل المحرف ≠ عدم المساواة (قد يكون من الصعب رؤيته باستخدام متصفح الويب). تكون القواعد أحيانًا مريحة وتؤدي إلى عدم الدقة في التمييز بين المصفوفات السطرية والمصفوفات العمودية، ولكن سيؤدي إبقاء التمييز بينها واضحًا إلى تجنب الارتباك مستقبلًا. هل تُعَد المصفوفتان العموديتان (1.53, -0.03, 9.03, 0.0, +8.64)T و (1.53, -0.03, 9.03, 1.0, -8.64)T متساويتين؟ لا، ليستا متساويتين. أسماء المصفوفات من المفيد أن يكون للمصفوفات أسماء، إذ يُستخدَم عادةً حرف صغير بخط عريض لمصفوفة سطرية أو عمودية كما يلي: a = ( 1.2, -3.6 ) x = ( x1, x2, x3, x4 ) r = ( r0, r1 )T من المعتاد استخدام الأسماء من بداية أحرف الأبجدية الإنجليزية للمصفوفات العمودية التي تكون عناصرها معروفة مثل المصفوفة a السابقة، واستخدام الأسماء من نهاية أحرف الأبجدية الإنجليزية للمصفوفات العمودية التي تكون عناصرها متغيرات. تكون أسماء عناصر المصفوفة العمودية غالبًا مؤلفة من اسم المصفوفة العمودية الكاملة مع رمز سفلي مثل المصفوفة العمودية r وعناصرها r0 وr1. من الصعب كتابة الأحرف ذات الخط العريض بالقلم الرصاص أو بالطباشير، لذا بدلًا من ذلك يُوضَع سهم أو شريط فوق اسم المصفوفة العمودية كما يلي: _ -> x x لنفترض أن لدينا ما يلي: x = ( x1, x2 ) y = ( 3.2, -8.6 ) x = y ما الذي يجب أن يكون صحيحًا بشأن x1 و x2؟ x1 = 3.2 و x2 = -8.6 تمثيل الأشعة باستخدام المصفوفات العمودية تُستخدَم المصفوفات العمودية لتمثيل الأشعة وتُستخدَم لتمثيل النقاط أيضًا. يُستخدَم في الفضاء ثنائي الأبعاد نوع البيانات نفسه -وتكون مصفوفات عمودية ثنائية الأبعاد- لتمثيل نوعين مختلفين من الكائنات الهندسية هما النقاط والأشعة، ويُعَد ذلك أمرًا مربكًا، لذا سنصحح هذا الوضع لاحقًا. يوضح الشكل السابق شعاع الإزاحة الذي يمثل الفرق بين نقطتين في المستوي x-y، إذ نستخدم حاليًا أمثلةً في فضاء ثنائي الأبعاد، وسيأتي الفضاء ثلاثي الأبعاد لاحقًا. النقطة A لها الإحداثيات: x=2 و y=1، ويمكن تمثيلها بمصفوفة عمودية: (2, 1)T. النقطة B لها الإحداثيات: x=7 و y=3، ويمكن تمثيلها بمصفوفة عمودية: (7, 3)T. يمكن حساب الإزاحة من النقطة A إلى النقطة B في مسألتين منفصلتين هما: الإزاحة x هي الفرق بين قيم X أي: 7-2 = 5. الإزاحة y هي الفرق بين قيم Y أي: 3-1 = 2. وشعاع الإزاحة المُعبَّر عنه بمصفوفة هو: (5, 2)T = d. تُصوَّر أشعة الإزاحة على شكل سهم يربط بين نقطتين، إذ تكون النقطة A هي ذيل الشعاع، والنقطة B هي رأس الشعاع في الرسم البياني، ولكن تذكّر أن الأشعة ليس لها موضع، لذا يُعَد هذا الرسم مجرد مكان مناسب لرسمها، ولا يعبّر عن موضعها. الإزاحة Displacement تمثل المصفوفة العمودية d شعاع الإزاحة من النقطة A إلى النقطة B، فما هي المصفوفة العمودية التي تمثل الإزاحة من النقطة B إلى النقطة A؟ الإزاحة من النقطة B إلى النقطة A هي: الإزاحة x هي: 2-7 = -5 الإزاحة y هي: 1-3 = -2 وبالتالي فإن المصفوفة العمودية التي تمثل الإزاحة هي: (-5, -2)T = e يؤشر شعاع الإزاحة إلى الاتجاه المعاكس عند زيارة النقاط بالترتيب المعاكس، ويكون كل عنصر ناتجًا عن ضرب القيمة القديمة بالعدد -1 في المصفوفة العمودية. تختلف الإزاحة من النقطة A إلى النقطة B عن الإزاحة من النقطة B إلى النقطة A، إذ يمكن التفكير في الإزاحة بوصفها "إرشادات حول كيفية المشي من نقطة إلى أخرى"؛ لذا إذا كنت واقفًا عند النقطة A وترغب في الوصول إلى النقطة B، فإن الإزاحة (5, 2)T تقول "امشِ 5 وحدات في الاتجاه الموجب X، ثم امشِ وحدتين في الاتجاه الموجب Y". تحتاج بالطبع إلى اتجاهات مختلفة للانتقال من النقطة B إلى النقطة A، حيث تقول الإزاحة (-5, -2)T "امشِ 5 وحدات في الاتجاه السالب X، ثم امشِ وحدتين في الاتجاه السالب Y"، مما يعيدك إلى النقطة A. يمكن التعبير عن الإزاحة من نقطة البداية إلى نقطة النهاية كما يلي: الإزاحة = (x نقطة النهاية - x نقطة البداية, y نقطة النهاية - y نقطة البداية)T لنفترض أن النقطة C هي: x=4, y=2 وأن النقطة D هي: x=3, y= 5، فما هي المصفوفة العمودية التي تمثل الإزاحة من C إلى D؟ X لنقطة النهاية - X لنقطة البداية = 3 - 4 = -1 Y لنقطة النهاية - Y لنقطة البداية = 5 - 2 = 3 إذًا فالمصفوفة العمودية هي: (-1, 3)T قراءة الإزاحات من الرسوم البيانية الورقية يوضح الرسم البياني التالي شعاعًا بين نقطتين، حيث يمكن قراءة عناصر الإزاحة بين النقطتين من الرسم البياني من خلال حساب عدد المربعات من ذيل الشعاع إلى رأسه: (-3, 5)T. افعل الشيء ذاته الآن مع الرسم البياني التالي: ما هي الإزاحة من النقطة E إلى النقطة F؟ الإزاحة هي: (7, 3)T للتحقق من إجابتك، ابدأ من نقطة البداية واتبع التعليمات التالية: امشِ بمقدار 7 وحدات على محور X، ثم امشِ بمقدار 3 وحدات على محور Y. إذا كانت إجابتك صحيحة، فسينتهي بك الأمر عند نقطة النهاية. ليس للأشعة موقع محدد ما هي الإزاحة من النقطة G: (-3, 4)T إلى النقطة H: (5, -2)T؟ يمكن الإجابة على هذا السؤال من خلال طرح قيم نقطة البداية G من القيم المقابلة لنقطة النهاية H ويعطي ذلك: (8, -6)T. احسب الآن الإزاحة من النقطة M إلى النقطة N في الرسم البياني التالي من خلال طرح قيم نقطة البداية N من القيم المقابلة لنقطة النهاية M، ويعطي ذلك: (8, -6)T، وهي القيمة نفسها للرسم البياني السابق. يُعَد شعاع الإزاحة هندسيًا من النقطة G إلى النقطة H هو شعاع الإزاحة نفسه من النقطة M إلى النقطة N، وتكون المصفوفتان العموديتان متساويتين باستخدام قاعدة مساواة المصفوفات العمودية. يُعَد ذلك منطقيًا، لأنك تقطع المسافة والاتجاه نفسه للمشي من النقطة M إلى النقطة N عند المشي من النقطة G إلى النقطة H، وبالتالي توضح هذه الرسوم البيانية الإزاحات مع الطول والاتجاه نفسه ولكن مع نقاط بداية مختلفة، فليس للأشعة موقعٌ محدد. من الشائع رسم الشعاع على شكل سهم في الرسوم البيانية، ذيله عند نقطة ورأسه عند نقطة أخرى، ولكن يمكن أن يمثل أيّ سهم له الطول والاتجاه نفسه هذا الشعاع. طرح النقاط هل تُعَدّ الإزاحة بين نقطتين فريدة؟ نعم، هذا صحيح. يمكن كتابة صيغة حساب شعاع الإزاحة على النحو التالي، إذ تساوي الإزاحة من النقطة S (نقطة البداية) إلى النقطة F (نقطة النهاية) ما يلي: F - S = ( Xf , Yf )T - ( Xs , Ys )T = ( Xf-Xs , Yf-Ys )T تُستخدَم نقطتان في هذه العملية لإنتاج شعاع واحد، فمن الغريب أن ينتج عن طرح كائنين لهما النوع نفسه كائنٌ من نوع آخر، وهذا يقودنا إلى السؤال التالي: إذا طرحنا نقطةً ثلاثية الأبعاد من نقطة أخرى ثلاثية الأبعاد، فهل ستكون النتيجة شعاعًا؟ نعم، إذ تعمل هذه الطريقة في الفضاء ثلاثي الأبعاد وثنائي الأبعاد. تدريب عملي لحساب الإزاحة لنفترض أن النملة ريم ضاعت عند النقطة (8, 4)T، فأوجد الإزاحة التي ستوصِلها إلى صديقتها سلمى عند النقطة (2, 2)T، أو ما هي الإزاحة التي يجب أن تتحرك بها ريم للعثور على صديقتها سلمى؟ لنطرح النقاط (سلمى - ريم): (2, 2)T - (8, 4)T = (-6, -2)T ستحصل على الإجابة نفسها من خلال عدّ مربعات ورقة الرسم البياني. استخدام الأعداد الحقيقية قد نرغب في تجنب الأعداد السالبة وبالتالي سنحسب الإزاحة بصورة غير صحيحة، إذ يُعَد وجود إزاحات سالبة أمرًا طبيعيًا، فالجزء "السلبي" مطلوب لإظهار الاتجاه. شيء آخر يجب أخذه في الحسبان وهو أن عناصر المصفوفة العمودية هي أعداد حقيقية، ولكن استخدمنا في الأمثلة أعدادًا صحيحة لتسهيل الأمور فقط، فلا يوجد أيّ خطأ في المصفوفة العمودية (-1.2304, 9.3382)T. لنفترض أن لدينا النقطتان: النقطة B وهي: ( 4.75, 6.23 ) والنقطة A وهي: ( 1.25, 4.03 )، فما هي الإزاحة من النقطة A إلى النقطة B؟ الإزاحة من النقطة A إلى النقطة B هي: ( 4.75, 6.23 ) - ( 1.25, 4.03 ) = ( 3.50, 2.20 )T وصلنا إلى نهاية هذا المقال، وسنناقش في المقال التالي العمليات على الأشعة والعمليات المكافئة باستخدام المصفوفات العمودية. ترجمة -وبتصرُّف- للفصل Vectors, Points, and Column Matrices من كتاب Vector Math for 3D Computer Graphics لصاحبه Bradley Kjell. اقرأ المزيد المقال السابق التعرف على النقاط والخطوط في الرسوميات الحاسوبية ثلاثية الأبعاد. الرسم باستخدام الأدوات المساعدة في كريتا دليلك الشامل إلى أنواع البيانات.
سنناقش في هذا المقال كائنات الرسوميات الحاسوبية التي هي الأشعة والنقاط وكيفية تمثيلها في الحاسوب بوصفها مصفوفات عمودية، فالمصفوفة العمودية column matrix هي كائن رياضي له العديد من الاستخدامات إلى جانب استخدامه في الرسوميات الحاسوبية، ولكن سنتعرف في هذا المقال على كيفية استخدامها في الرسوميات الحاسوبية فقط. سنتعرّف في هذا المقال على المواضيع التالية: نمذجة وعرض الرسوميات الحاسوبية. النقاط والأشعة الهندسية. المصفوفات العمودية والسطرية. حساب الإزاحات. مساواة المصفوفات العمودية. أسماء المصفوفات العمودية وعناصرها. تمثيل النقاط باستخدام المصفوفات العمودية. تُعَد النقاط والأشعة الهندسية ضروريةً في الرسوميات الحاسوبية، ويجب تمثيلها بطريقة تسهّل التعامل معها، لذا تُعَد المصفوفة العمودية الخيار المعتاد لذلك. تستخدم بعض كتب الرسوميات مصطلح الشعاع العمودي Column Vector للتعبير عن الكائن الذي نسميه في مقالنا بالمصفوفة العمودية، إذ يُعَد ذلك مجرد اختلافٍ في المصطلحات ولا يؤثر على المفاهيم أو الصيغ التي سنوضّحها لاحقًا، ولكن المشكلة الأسوأ هي أن بعض الكتب تستخدم المصفوفات السطرية Row Matrices، فالمصفوفات العمودية والمصفوفات السطرية متكافئة، ولكن المعادلات المكتوبة باستخدام المصفوفات السطرية ليست هي نفسها المكتوبة باستخدام المصفوفات العمودية. يمكننا ضبط هذه الاختلافات، ولكنها مزعجة قليلًا. مثال مشهد السائح الافتراضي ما هما نوعا الكائنات الهندسية التي يمكن تمثيلها باستخدام المصفوفات العمودية؟ هما النقاط والأشعة. تتكون الرسوميات الحاسوبية من نشاطين: أولهما إنشاء عالم خيالي ثلاثي الأبعاد في الحاسوب، وثانيهما إنتاج صور ثنائية الأبعاد لذلك العالم من نقاط نظر مختلفة. يشبه برنامج الرسوميات السائحَ الذي يتجول في معالم طبيعية رائعة ويلتقط الصور بالكاميرا، ويُجهَّز السائح الافتراضي بكاميرا سينمائية مع الرسوم المتحركة الحاسوبية. يتكون المشهد الخيالي من كائنات في فضاء ثلاثي الأبعاد، ويُحدَّد كل كائن باستخدام النقاط والخطوط التي تقع على سطحه مثل المشهد الشتوي السابق لصاحبه توان فان Tuan Phan. يتكون هذا النموذج من نقاط وقطع مستقيمة تربط بينها، وهناك حاجة إلى مزيدٍ من العمل لملء المنطقة بين القطع المستقيمة ولتطبيق الإضاءة للحصول على صورة واقعية. صورة المشهد الكاملة هل يمكن تمثيل الكرة باستخدام النقاط والخطوط؟ نعم، بالتأكيد. انظر إلى جسد رجل الثلج، إذ يبدو الشكل وكأنه كرة عند ملء المضلعات. هذه هي الصورة الكاملة، مع ملء المضلعات وتطبيق الإضاءة وإلقاء قليلٍ من ندف الثلج. يمكنك طلب نماذج من الكرات والأسطوانات والأقماع ووضعها في مشهدك في المكان الذي تريده باستخدام حزم الرسوميات الحاسوبية ثلاثية الأبعاد مثل OpenGL التي تملأ أيضًا المضلعات تلقائيًا وتطبّق نموذج الإضاءة لإنتاج تظليل واقعي. مشهد افتراضي آخر هل يمكن لسائحنا الافتراضي أن يتجول في مشهد الثلوج الافتراضي ويلتقط صورة مختلفة؟ نعم، يمكنه ذلك. يضع نموذج المشهد الثلجي كائنات مختلفة في فضاء ثلاثي الأبعاد، وبالتالي يمكن لسائحنا الافتراضي أن يتجول على يمين رجل الثلج ويلتقط صورةً أخرى ثنائية الأبعاد باستخدام الكاميرا الافتراضية، إذ أُنتِجت الصورة السابقة باستخدام النموذج والإضاءة نفسها، ولكن مع وضعٍ مختلف للكاميرا. الشعاع Vector ما هي النقطة؟ وضحنا في المقال السابق مفهوم النقطة بأنها موقع في الفضاء، حيث تُعَد النقطة في الهندسة موقعًا في الفضاء فليس لها حجم وخاصيتها الوحيدة هي الموقع، بينما تكون النقطة عادةً في الرسوميات الحاسوبية هي رأس الشكل ثلاثي الأبعاد. أما الشعاع الهندسي فله خاصيتان: الطول والاتجاه، ولكن ليس له موقع ثابت في الفضاء، فإذا كان له موقع ثابت، فسيكون قطعة مستقيمة. قد يكون الحديث عن شيء ليس له موقع أمرًا غريبًا، ولكنه يسهّل تطبيق الرسوميات الحاسوبية ثلاثية الأبعاد. يسمى هذا المزيج من "المسافة والاتجاه" بالإزاحة Displacement أحيانًا، ويمكن تطبيق الإزاحة نفسها (أي إزاحة واحدة فقط) على كل نقطة من النقاط المختلفة. لنفترض أن لدينا المكعب التالي مثلًا، إذ يحتوي الوجه الأمامي على أربعة رؤوس (أربع نقاط). إذا تحركتَ من كل نقطة من هذه النقاط بمقدار المسافة والاتجاه نفسه، فستصل إلى النقاط الأربعة للوجه الخلفي. تمثل العبارة "المسافة والاتجاه نفسه" الشعاعَ الذي يظهر بوصفه خطًا مع رأس سهم، ويوضح الشكل التالي هذا الشعاع أربع مرات، مرة واحدة لكل نقطة من الوجه. المصفوفة العمودية لنفترض أنك قضيت عطلة الربيع على الشاطئ والشمس مشرقة، فهل يسطع ضوء الشمس في الاتجاه نفسه لكل الموجودين على الشاطئ؟ نعم، إذ يكون "الاتجاه نحو الشمس" نفسه لكل الموجودين على الشاطئ، وبالتالي فهو شعاع. نهتم أحيانًا بالاتجاه فقط دون الاهتمام بالموقع أو بالطول كما في السؤال السابق، لذا نستخدم الشعاع لهذا الغرض، فطوله ليس مهمًا، لأننا نستخدم طولًا واحدًا في كثير من الأحيان. نهتم في أحيانٍ أخرى بكلٍ من الاتجاه والحجم، وعندها يُستخدَم كلٌّ من اتجاه وطول الشعاع. يمكن تمثيل الشعاع بقائمةٍ من الأعداد تدعى المصفوفة العمودية، والتي هي قائمة مرتبة من الأعداد المكتوبة ضمن عمود. تستخدم بعض الكتب كلمة "شعاع" لتعبّر عن فكرة الشعاع وتمثيله بوصفه ترتيبًا لثلاثة أعداد، ولكن يمكن أن يكون ذلك مربكًا أحيانًا. إليك فيما يلي مثالًا لمصفوفة عمودية: يسمى كل عددٍ في المصفوفة العمودية عنصرًا Element، وتكون هذه الأعداد حقيقية real، ويسمى عدد العناصر في الشعاع بالبُعد Dimension. المصفوفة السطرية Row Matrix هي قائمة مرتبة من الأعداد المكتوبة في صف واحد مثل المصفوفة السطرية: (12.5, -9.34). سنمثّل الأشعة دائمًا باستخدام مصفوفات عمودية بهدف التناسق، وتمثل بعض الكتب الأشعة باستخدام مصفوفات سطرية، إذ لا يحدث ذلك فرقًا جوهريًا، ولكنه يغيّر بعض الصيغ الرياضية قليلًا. ما هو عدد العناصر الموجودة في كل مصفوفة عمودية؟ الجواب هو: استخدام المتغيرات بوصفها عناصر مصفوفة يمكن أن تكون عناصر المصفوفة العمودية متغيرات variables كما يلي: يُعطَى العنصر الأول في المصفوفة العمودية أحيانًا الفهرس "0" أوالفهرس "1" أحيانًا. العرض المناسب للمصفوفة العمودية هل المصفوفة العمودية التالية: هي المصفوفة العمودية التالية نفسها؟ لا يمكن ذلك، فالمصفوفة العمودية هي قائمة مرتبة من الأعداد، وهذا يعني أن كل موضع في المصفوفة العمودية يحتوي على عدد أو متغير معين. يُعَد مظهر المصفوفات العمودية غريبًا في النصوص المطبوعة، لذا من الشائع كتابتها كما يلي: (2.9, -4.6, 0.0) T يرمز الحرف "T" إلى منقول المصفوفة Transpose الذي يعني تحويل الصفوف إلى أعمدة (سنوضح لاحقًا بالتفصيل معنى المنقول). المساواة بين المصفوفات هل المصفوفة (1.2, -3.9, 0.0) تساوي المصفوفة (1.2, -3.9, 0.0)T؟ لا، فالمصفوفة الأولى هي مصفوفة سطرية، والمصفوفة الثانية هي مصفوفة عمودية، أي مكتوبة ضمن صف، ولكن الحرف "T" يعني أنها مصفوفة عمودية، إذ تُعَد المصفوفات السطرية والمصفوفات العمودية أنواعًا مختلفة من الكائنات، ولا يمكن أن تكون متساوية. ربما لم نميّز سابقًا بين المصفوفات السطرية والمصفوفات العمودية، ولم نوضِّح اختلاف الأشعة الهندسية عن المصفوفات العمودية المستخدمة لتمثيل هذه الأشعة، إذ يمكن أن تبدو هذه الاختلافات صعبة حاليًا، ولكن أبقِها حاضرةً في ذهنك لتجنب الالتباس مستقبلًا. يمكن أن تكون المصفوفتان العموديتان متساويتين إذا كانت: كلتا المصفوفتين مصفوفةً عمودية. لكل منهما البعد (عدد العناصر) نفسه. العناصر المقابلة لبعضها البعض في المصفوفتين متساوية. يمكن أن تكون المصفوفتان السطريتان متساويتين إذا كان: كلتا المصفوفتين مصفوفات سطرية. لكل منهما البعد (عدد العناصر) نفسه. العناصر المقابلة لبعضها البعض في المصفوفتين متساوية. الفروق الدقيقة بين المصفوفات هل المصفوفتان السطريتان (8.0, -1.63, 7.0, 0.0) و (8.0, -1.63, 7.0, 1.0) متساويتان؟ لا. يمكن مقارنة المصفوفات من النوع نفسه فقط، إذ يمكنك المقارنة بين مصفوفتين عموديتين ثلاثيتي الأبعاد، أو مصفوفتين سطريتين رباعيتي الأبعاد مثلًا، فليس من المنطقي مقارنة مصفوفة سطرية ثلاثية الأبعاد مع مصفوفة عمودية ثلاثية الأبعاد. ( 6, 8, 12, -3 )T = ( 6, 8, 12, -3)T ( 6, 8, 12, -3 ) = ( 6, 8, 12, -3 ) ( 6, 8, 12, -3 ) ≠ ( -2.3, 8, 12, -3 ) ( 6, 8, 12, -3 )T ≠ ( 6, 8, 12, -3 ) ( 6, 8, 12, -3 )T ≠ ( 6, 8, 12 )T يمثل المحرف ≠ عدم المساواة (قد يكون من الصعب رؤيته باستخدام متصفح الويب). تكون القواعد أحيانًا مريحة وتؤدي إلى عدم الدقة في التمييز بين المصفوفات السطرية والمصفوفات العمودية، ولكن سيؤدي إبقاء التمييز بينها واضحًا إلى تجنب الارتباك مستقبلًا. هل تُعَد المصفوفتان العموديتان (1.53, -0.03, 9.03, 0.0, +8.64)T و (1.53, -0.03, 9.03, 1.0, -8.64)T متساويتين؟ لا، ليستا متساويتين. أسماء المصفوفات من المفيد أن يكون للمصفوفات أسماء، إذ يُستخدَم عادةً حرف صغير بخط عريض لمصفوفة سطرية أو عمودية كما يلي: a = ( 1.2, -3.6 ) x = ( x1, x2, x3, x4 ) r = ( r0, r1 )T من المعتاد استخدام الأسماء من بداية أحرف الأبجدية الإنجليزية للمصفوفات العمودية التي تكون عناصرها معروفة مثل المصفوفة a السابقة، واستخدام الأسماء من نهاية أحرف الأبجدية الإنجليزية للمصفوفات العمودية التي تكون عناصرها متغيرات. تكون أسماء عناصر المصفوفة العمودية غالبًا مؤلفة من اسم المصفوفة العمودية الكاملة مع رمز سفلي مثل المصفوفة العمودية r وعناصرها r0 وr1. من الصعب كتابة الأحرف ذات الخط العريض بالقلم الرصاص أو بالطباشير، لذا بدلًا من ذلك يُوضَع سهم أو شريط فوق اسم المصفوفة العمودية كما يلي: _ -> x x لنفترض أن لدينا ما يلي: x = ( x1, x2 ) y = ( 3.2, -8.6 ) x = y ما الذي يجب أن يكون صحيحًا بشأن x1 و x2؟ x1 = 3.2 و x2 = -8.6 تمثيل الأشعة باستخدام المصفوفات العمودية تُستخدَم المصفوفات العمودية لتمثيل الأشعة وتُستخدَم لتمثيل النقاط أيضًا. يُستخدَم في الفضاء ثنائي الأبعاد نوع البيانات نفسه -وتكون مصفوفات عمودية ثنائية الأبعاد- لتمثيل نوعين مختلفين من الكائنات الهندسية هما النقاط والأشعة، ويُعَد ذلك أمرًا مربكًا، لذا سنصحح هذا الوضع لاحقًا. يوضح الشكل السابق شعاع الإزاحة الذي يمثل الفرق بين نقطتين في المستوي x-y، إذ نستخدم حاليًا أمثلةً في فضاء ثنائي الأبعاد، وسيأتي الفضاء ثلاثي الأبعاد لاحقًا. النقطة A لها الإحداثيات: x=2 و y=1، ويمكن تمثيلها بمصفوفة عمودية: (2, 1)T. النقطة B لها الإحداثيات: x=7 و y=3، ويمكن تمثيلها بمصفوفة عمودية: (7, 3)T. يمكن حساب الإزاحة من النقطة A إلى النقطة B في مسألتين منفصلتين هما: الإزاحة x هي الفرق بين قيم X أي: 7-2 = 5. الإزاحة y هي الفرق بين قيم Y أي: 3-1 = 2. وشعاع الإزاحة المُعبَّر عنه بمصفوفة هو: (5, 2)T = d. تُصوَّر أشعة الإزاحة على شكل سهم يربط بين نقطتين، إذ تكون النقطة A هي ذيل الشعاع، والنقطة B هي رأس الشعاع في الرسم البياني، ولكن تذكّر أن الأشعة ليس لها موضع، لذا يُعَد هذا الرسم مجرد مكان مناسب لرسمها، ولا يعبّر عن موضعها. الإزاحة Displacement تمثل المصفوفة العمودية d شعاع الإزاحة من النقطة A إلى النقطة B، فما هي المصفوفة العمودية التي تمثل الإزاحة من النقطة B إلى النقطة A؟ الإزاحة من النقطة B إلى النقطة A هي: الإزاحة x هي: 2-7 = -5 الإزاحة y هي: 1-3 = -2 وبالتالي فإن المصفوفة العمودية التي تمثل الإزاحة هي: (-5, -2)T = e يؤشر شعاع الإزاحة إلى الاتجاه المعاكس عند زيارة النقاط بالترتيب المعاكس، ويكون كل عنصر ناتجًا عن ضرب القيمة القديمة بالعدد -1 في المصفوفة العمودية. تختلف الإزاحة من النقطة A إلى النقطة B عن الإزاحة من النقطة B إلى النقطة A، إذ يمكن التفكير في الإزاحة بوصفها "إرشادات حول كيفية المشي من نقطة إلى أخرى"؛ لذا إذا كنت واقفًا عند النقطة A وترغب في الوصول إلى النقطة B، فإن الإزاحة (5, 2)T تقول "امشِ 5 وحدات في الاتجاه الموجب X، ثم امشِ وحدتين في الاتجاه الموجب Y". تحتاج بالطبع إلى اتجاهات مختلفة للانتقال من النقطة B إلى النقطة A، حيث تقول الإزاحة (-5, -2)T "امشِ 5 وحدات في الاتجاه السالب X، ثم امشِ وحدتين في الاتجاه السالب Y"، مما يعيدك إلى النقطة A. يمكن التعبير عن الإزاحة من نقطة البداية إلى نقطة النهاية كما يلي: الإزاحة = (x نقطة النهاية - x نقطة البداية, y نقطة النهاية - y نقطة البداية)T لنفترض أن النقطة C هي: x=4, y=2 وأن النقطة D هي: x=3, y= 5، فما هي المصفوفة العمودية التي تمثل الإزاحة من C إلى D؟ X لنقطة النهاية - X لنقطة البداية = 3 - 4 = -1 Y لنقطة النهاية - Y لنقطة البداية = 5 - 2 = 3 إذًا فالمصفوفة العمودية هي: (-1, 3)T قراءة الإزاحات من الرسوم البيانية الورقية يوضح الرسم البياني التالي شعاعًا بين نقطتين، حيث يمكن قراءة عناصر الإزاحة بين النقطتين من الرسم البياني من خلال حساب عدد المربعات من ذيل الشعاع إلى رأسه: (-3, 5)T. افعل الشيء ذاته الآن مع الرسم البياني التالي: ما هي الإزاحة من النقطة E إلى النقطة F؟ الإزاحة هي: (7, 3)T للتحقق من إجابتك، ابدأ من نقطة البداية واتبع التعليمات التالية: امشِ بمقدار 7 وحدات على محور X، ثم امشِ بمقدار 3 وحدات على محور Y. إذا كانت إجابتك صحيحة، فسينتهي بك الأمر عند نقطة النهاية. ليس للأشعة موقع محدد ما هي الإزاحة من النقطة G: (-3, 4)T إلى النقطة H: (5, -2)T؟ يمكن الإجابة على هذا السؤال من خلال طرح قيم نقطة البداية G من القيم المقابلة لنقطة النهاية H ويعطي ذلك: (8, -6)T. احسب الآن الإزاحة من النقطة M إلى النقطة N في الرسم البياني التالي من خلال طرح قيم نقطة البداية N من القيم المقابلة لنقطة النهاية M، ويعطي ذلك: (8, -6)T، وهي القيمة نفسها للرسم البياني السابق. يُعَد شعاع الإزاحة هندسيًا من النقطة G إلى النقطة H هو شعاع الإزاحة نفسه من النقطة M إلى النقطة N، وتكون المصفوفتان العموديتان متساويتين باستخدام قاعدة مساواة المصفوفات العمودية. يُعَد ذلك منطقيًا، لأنك تقطع المسافة والاتجاه نفسه للمشي من النقطة M إلى النقطة N عند المشي من النقطة G إلى النقطة H، وبالتالي توضح هذه الرسوم البيانية الإزاحات مع الطول والاتجاه نفسه ولكن مع نقاط بداية مختلفة، فليس للأشعة موقعٌ محدد. من الشائع رسم الشعاع على شكل سهم في الرسوم البيانية، ذيله عند نقطة ورأسه عند نقطة أخرى، ولكن يمكن أن يمثل أيّ سهم له الطول والاتجاه نفسه هذا الشعاع. طرح النقاط هل تُعَدّ الإزاحة بين نقطتين فريدة؟ نعم، هذا صحيح. يمكن كتابة صيغة حساب شعاع الإزاحة على النحو التالي، إذ تساوي الإزاحة من النقطة S (نقطة البداية) إلى النقطة F (نقطة النهاية) ما يلي: F - S = ( Xf , Yf )T - ( Xs , Ys )T = ( Xf-Xs , Yf-Ys )T تُستخدَم نقطتان في هذه العملية لإنتاج شعاع واحد، فمن الغريب أن ينتج عن طرح كائنين لهما النوع نفسه كائنٌ من نوع آخر، وهذا يقودنا إلى السؤال التالي: إذا طرحنا نقطةً ثلاثية الأبعاد من نقطة أخرى ثلاثية الأبعاد، فهل ستكون النتيجة شعاعًا؟ نعم، إذ تعمل هذه الطريقة في الفضاء ثلاثي الأبعاد وثنائي الأبعاد. تدريب عملي لحساب الإزاحة لنفترض أن النملة ريم ضاعت عند النقطة (8, 4)T، فأوجد الإزاحة التي ستوصِلها إلى صديقتها سلمى عند النقطة (2, 2)T، أو ما هي الإزاحة التي يجب أن تتحرك بها ريم للعثور على صديقتها سلمى؟ لنطرح النقاط (سلمى - ريم): (2, 2)T - (8, 4)T = (-6, -2)T ستحصل على الإجابة نفسها من خلال عدّ مربعات ورقة الرسم البياني. استخدام الأعداد الحقيقية قد نرغب في تجنب الأعداد السالبة وبالتالي سنحسب الإزاحة بصورة غير صحيحة، إذ يُعَد وجود إزاحات سالبة أمرًا طبيعيًا، فالجزء "السلبي" مطلوب لإظهار الاتجاه. شيء آخر يجب أخذه في الحسبان وهو أن عناصر المصفوفة العمودية هي أعداد حقيقية، ولكن استخدمنا في الأمثلة أعدادًا صحيحة لتسهيل الأمور فقط، فلا يوجد أيّ خطأ في المصفوفة العمودية (-1.2304, 9.3382)T. لنفترض أن لدينا النقطتان: النقطة B وهي: ( 4.75, 6.23 ) والنقطة A وهي: ( 1.25, 4.03 )، فما هي الإزاحة من النقطة A إلى النقطة B؟ الإزاحة من النقطة A إلى النقطة B هي: ( 4.75, 6.23 ) - ( 1.25, 4.03 ) = ( 3.50, 2.20 )T وصلنا إلى نهاية هذا المقال، وسنناقش في المقال التالي العمليات على الأشعة والعمليات المكافئة باستخدام المصفوفات العمودية. ترجمة -وبتصرُّف- للفصل Vectors, Points, and Column Matrices من كتاب Vector Math for 3D Computer Graphics لصاحبه Bradley Kjell. اقرأ المزيد المقال السابق التعرف على النقاط والخطوط في الرسوميات الحاسوبية ثلاثية الأبعاد. الرسم باستخدام الأدوات المساعدة في كريتا دليلك الشامل إلى أنواع البيانات. -
 أنشأتَ واختبرتَ موقع المكتبة المحلية LocalLibrary، ويجب الآن تثبيته على خادم ويب عام ليصل إليه موظفو المكتبة وأعضاؤها عبر الإنترنت. يقدّم هذا المقال نظرة عامة حول كيفية البحث عن مضيف لنشر موقعك، وما عليك فعله لتجهيز موقعك لمرحلة الإنتاج. المتطلبات الأساسية: إكمال المقالات السابقة من هذه السلسلة بما في ذلك مقال عرض بيانات المكتبة والعمل مع الاستمارات. الهدف: معرفة مكان وكيفية نشر تطبيق Express في بيئة الإنتاج. يجب استضافة موقعك بعد الانتهاء منه (أو الانتهاء منه "بما يكفي" لبدء الاختبار العام) في مكان أعم ويمكن الوصول إليه من أجهزة أخرى غير حاسوبك الشخصي الخاص بالتطوير. عملتَ حتى الآن في بيئة تطوير باستخدام خادم ويب تطوير Express/Node لمشاركة موقعك على المتصفح أو الشبكة المحلية، وشغّلتَ موقعك باستخدام إعدادات تطوير (غير آمنة) بحيث يمكن الوصول إلى معلومات تنقيح الأخطاء والمعلومات الخاصة الأخرى. يجب عليك أولًا تنفيذ الخطوات التالية قبل أن تتمكّن من استضافة موقع ويب خارجيًا: اختيار بيئة لاستضافة تطبيق Express. إجراء بعض التغييرات على إعدادات مشروعك. إعداد بنية تحتية على مستوى الإنتاج لتخديم موقع الويب. يقدّم هذا المقال بعض الإرشادات حول الخيارات المتاحة لاختيار موقع استضافة، ونظرة ًعامة مختصرة على ما يجب تطبيقه لتجهيز تطبيق Express لبيئة الإنتاج، ويقدم مثالًا عمليًا لكيفية تثبيت موقع المكتبة المحلية LocalLibrary على خدمة الاستضافة السحابية Railway. ما هي بيئة الإنتاج؟ بيئة الإنتاج هي البيئة التي يوفّرها حاسوب الخادم إذ ستشغِّل موقعك للاستخدام الخارجي، وتشمل هذه البيئة ما يلي: عتاد الحاسوب الذي يعمل عليه الموقع. نظام التشغيل، مثل لينكس أو ويندوز. وقت التشغيل الخاص بلغة البرمجة ومكتبات أطر العمل التي كُتِب عليها موقعك. خادم الويب المُستخدَم لتخديم الصفحات والمحتويات الأخرى، مثل خادم إنجن إكس Nginx وأباتشي Apache. البنية التحتية لخادم الويب وتتضمن خادم الويب والوكيل العكسي Reverse Proxy وموازن الحِمل Load Balancer وغير ذلك. قواعد البيانات التي يعتمد عليها موقعك. يمكن أن يكون حاسوب الخادم موجودًا في مقر عملك ومتصلًا بالإنترنت من خلال رابط سريع، ولكن يمكن استخدام حاسوب مستضاف على السحابة، وهذا يعني تنفيذ شيفرتك البرمجية على بعض الحواسيب البعيدة (أو على حاسوب افتراضي) في مركز أو مراكز بيانات شركتك المضيفة. يقدّم الخادم البعيد عادةً مستوًى مضمونًا من موارد المعالجة، مثل وحدة المعالجة المركزية والذاكرة RAM وذاكرة التخزين وغير ذلك والاتصال بالإنترنت بسعر معين. يشار إلى هذا النوع من عتاد المعالجة والتشبيك الذي يمكن الوصول إليه عن بُعد باسم البنية التحتية كخدمة Infrastructure as a Service -أو IaaS اختصارًا. يوفّر العديد من بائعي خدمة IaaS خيارات التثبيت المُسبَق لنظام تشغيل معين، والذي يجب تثبيت مكونات بيئتك الإنتاجية الأخرى عليه، ويسمح لك البائعون الآخرون باختيار بيئات كاملة الميزات، ويمكن أن يتضمن ذلك إعداد بيئة Node الكاملة. ملاحظة: يمكن للبيئات المبنية مسبقًا أن تسهّل إعداد موقعك لأنها تقلل من عملية الضبط Configuration، ولكن يمكن أن تقيّدك الخيارات المتاحة بخادم غير مألوف لك (أو بمكونات أخرى) ويمكن أن تستند إلى نسخة أقدم من نظام التشغيل. يُفضَّل غالبًا تثبيت المكونات بنفسك حتى تحصل على المكونات التي تريدها، وبالتالي ستعرف من أين تبدأ عندما تحتاج إلى ترقية أجزاء من النظام. يدعم مزوّدو الاستضافة الآخرون إطار عمل Express بوصفه جزءًا من استضافة المنصة كخدمة Platform as a Service -أو PaaS اختصارًا، فلا داعي للقلق في هذا النوع من الاستضافة بشأن معظم أجزاء بيئتك الإنتاجية (الخوادم وموازنو الحِمل load balancers وغيرها) لأن المنصة المضيفة تهتم بهذه الأشياء نيابةً عنك، مما يجعل النشر سهلًا جدًا، لأنك تحتاج فقط إلى التركيز على تطبيق الويب وليس على بنية الخادم التحتية الأخرى. سيختار بعض المطورين المرونة المتزايدة التي توفرها استضافة IaaS على حساب استضافة PaaS، بينما سيقدّر المطورون الآخرون تقليل تكاليف الصيانة وسهولة توسيع نطاق استضافة PaaS. يكون إعداد موقعك على نظام PaaS أسهل بكثير في البداية، وهذا ما سنفعله في هذا المقال. ملاحظة: إذا اخترت مزوّد استضافة متوافق مع Node/Express، فيجب أن يقدّم إرشادات حول كيفية إعداد موقع Express باستخدام عمليات ضبط مختلفة لخادم الويب وخادم التطبيق والوكيل العكسي وغير ذلك. اختيار مزود الاستضافة يوجد العديد من مزوّدات الاستضافة المعروفة التي تدعم بنشاط أو تعمل بصورة جيدة مع بيئة Node و Express، ويوفّر هؤلاء البائعون أنواعًا مختلفة من البيئات (IaaS و PaaS) ومستويات مختلفة من موارد المعالجة والشبكات بأسعار مختلفة. ملاحظة: هناك الكثير من حلول الاستضافة، ويمكن أن تتغير خدماتها وأسعارها بمرور الوقت. سنقدّم بعض الخيارات، ولكن يجدر بك التحقق من هذه الخيارات وغيرها قبل اختيار مزود الاستضافة. إليك بعض الأشياء التي يجب مراعاتها عند اختيار المضيف: مدى انشغال موقعك المُحتمَل وتكلفة البيانات وموارد المعالجة المطلوبة لتلبية هذا المطلب. مستوى الدعم للتوسّع أفقيًا (إضافة المزيد من الأجهزة) وعموديًا (الترقية إلى أجهزة أقوى) وتكاليف ذلك. مكان مراكز بيانات المزوّد، أي المكان الذي يكون الوصول إليه أسرع. أداء وقت التشغيل ووقت التعطل السابقَين للمضيف. الأدوات المتوفرة لإدارة الموقع، لمعرفة إذا كانت سهلة الاستخدام وآمنة، مثل استخدام بروتوكول SFTP أو استخدام بروتوكول FTP. أطر العمل المبنية مسبقًا لمراقبة خادمك. القيود المعروفة، إذ سيوقِف بعض المضيفين عمدًا خدمات معينة مثل البريد الإلكتروني، ويقدّم البعض الآخر فقط عددًا معينًا من ساعات "النشاط" في بعض مستويات الأسعار، أو يقدّم فقط قدرًا صغيرًا من التخزين. الفوائد الإضافية، إذ ستقدّم بعض المزوّدات أسماء نطاقات مجانية ودعمًا لشهادات SSL التي يمكن أن يتعيّن عليك دفع ثمنها. معرفة ما إذا كان المستوى "المجاني" الذي تعتمد عليه تنتهي صلاحيته بمرور الوقت، وما إذا كانت تكلفة التهجير Migrating إلى مستوًى أغلى تعني أنه كان من الأفضل استخدام بعض الخدمات الأخرى من البداية. هناك عددٌ قليل جدًا من المواقع التي توفر بيئات معالجة "مجانية" مخصصة للتقييم والاختبار في البداية، وتكون عادةً بيئات مُقيَّدة أو محدودة الموارد إلى حدٍ ما، ويجب أن تدرك أنه يمكن أن تنتهي صلاحيتها بعد فترة أولية أو يكون لديها قيود أخرى، ولكنها رائعة لاختبار المواقع ذات حركة المرور المنخفضة في بيئة مُستضافة، ويمكن أن توفر تهجيرًا سهلًا للدفع مقابل المزيد من الموارد عندما يصبح موقعك أكثر انشغالًا. تشمل الخيارات الشائعة في هذه الفئة Railway و Python Anywhere و Amazon Web Services و Microsoft Azure وغير ذلك. يقدّم معظم المزوّدين مستوًى أساسيًا مخصصًا لمواقع الإنتاج الصغيرة، والذي يوفّر مستويات أكثر فائدة من قدرة المعالجة وقيودًا أقل. يُعَد Heroku و Digital Ocean و Python Anywhere أمثلة على مزودي الاستضافة المشهورة التي لديها مستوى معالجة أساسي غير مكلف نسبيًا (في نطاق يتراوح بين 5 و 10 دولارات أمريكية شهريًا). ملاحظة: تذكّر أن السعر ليس معيار الاختيار الوحيد، فإذا كان موقعك ناجحًا، فيمكن أن تكون قابلية التوسع هي الأهم. تجهيز موقعك للنشر الأشياء الرئيسية التي يجب التفكير فيها عند نشر موقعك هي أمان الويب والأداء، إذ ستحتاج في الحد الأدنى إلى إزالة تعقّب المكدس المُضمَّن في صفحات الخطأ أثناء التطوير، وترتيب التسجيل، وضبط الترويسات المناسبة لتجنب العديد من هجمات الأمان الشائعة، لذا سنحدّد في الأقسام الفرعية التالية أهم التغييرات الواجب إجراؤها على تطبيقك. ملاحظة: هناك نصائح مفيدة أخرى في توثيق Express، لذا اطلع على أفضل ممارسات عملية الإنتاج: الأداء والموثوقية والأمان، واعتبارات نشر مشاريع Node.js وExpress على الويب. ضبط قاعدة البيانات استخدمنا حتى الآن قاعدة بيانات واحدة ثابتة في الملف app.js، وبسبب عدم احتواء قاعدة بيانات التطوير على معلومات نخشى من كشفها أو إتلافها، فليس هناك خطورة في حال تسريبها، ولكن في حال كنا نتعامل مع بيانات حقيقية، مثل معلومات المستخدم الشخصية، ستكون حماية تلك البيانات أمرًا مهمًا جدًا. نريد عادةً أن نكون قادرين على امتلاك قاعدة بيانات مختلفة لكل من الإنتاج والتطوير وكذلك الاحتفاظ بقاعدة بيانات الإنتاج منفصلة أيضًا عن الشيفرة المصدرية بهدف حمايتها. إذا كان مزود الاستضافة الخاص بك داعمًا لمتغيرات البيئة من خلال واجهة الويب، ستكون إحدى الطرق لتحقيق ما سبق هي جعل الخادم يحصل على عنوان URL لقاعدة البيانات من متغير البيئة، لذلك سنعدّل موقع المكتبة المحلية LocalLibrary للحصول على معرّف URI لقاعدة البيانات من بيئة نظام التشغيل (إذا كان معرّفًا)، وإلّا فسنستخدم قاعدة بيانات التطوير الخاصة بنا. افتح الملف app.js وابحث عن السطر الذي يضبط متغير اتصال قاعدة بيانات MongoDB، والذي سيبدو كما يلي: const mongoDB = "mongodb+srv://your_user_name:your_password@cluster0.lz91hw2.mongodb.net/local_library?retryWrites=true&w=majority"; ضع الشيفرة التالية مكان السطر السابق، إذ تستخدم هذه الشيفرة process.env.MONGODB_URI للحصول على سلسلة الاتصال النصية من متغير البيئة MONGODB_URI إذا جرى ضبطه، واستخدم عنوان URL لقاعدة بياناتك بدلًا من العنصر البديل فيما يلي: // إعداد اتصال mongoose const dev_db_url = const mongoose = require("mongoose"); mongoose.set("strictQuery", false); const dev_db_url = "mongodb+srv://your_user_name:your_password@cluster0.lz91hw2.mongodb.net/local_library?retryWrites=true&w=majority"; const mongoDB = process.env.MONGODB_URI || dev_db_url; main().catch((err) => console.log(err)); async function main() { await mongoose.connect(mongoDB); } ضبط متغير البيئة NODE_ENV على القيمة production يمكننا إزالة تعقّب المكدس في صفحات الخطأ من خلال ضبط متغير البيئة NODE_ENV على قيمة الإنتاج 'production'، إذ يُضبَط على قيمة التطوير 'development' افتراضيًا. يؤدي ضبط المتغير على قيمة الإنتاج إلى إنشاء رسائل خطأ أقل تفصيلًا، بالإضافة إلى التخزين المؤقت لقوالب العرض وملفات CSS المُولَّدة من توسّعات شيفرة CSS، وتشير الاختبارات إلى أن ضبط متغير البيئة NODE_ENV على الإنتاج يمكن أن يحسن أداء التطبيق بمقدار ثلاثة أضعاف. يمكن إجراء هذا التغيير إما باستخدام export، أو ملف بيئة، أو نظام تهيئة لنظام التشغيل. ملاحظة: يُعَد ذلك تغييرًا تجريه في إعداد بيئتك بدلًا من إجرائه في تطبيقك، ولكنه جدير بالذكر حاليًا، إذ سنوضح كيفية ضبطه لمثال الاستضافة الآتي. التسجيل المناسب يمكن أن يكون لتسجيل الاستدعاءات تأثير على موقع الويب الذي يمتلك حركة مرور عالية، إذ يمكن أن تحتاج إلى تسجيل نشاط موقع الويب في بيئة الإنتاج، مثل تعقّب حركة المرور، أو تسجيل استدعاءات واجهة برمجة التطبيقات، ولكن يجب أن تحاول تقليل كمية التسجيل المُضافة لأغراض تنقيح الأخطاء Debugging. تتمثل إحدى طرق تقليل تسجيل "تنقيح الأخطاء" في بيئة الإنتاج في استخدام وحدة مثل الوحدة debug التي تسمح لك بالتحكم في التسجيل الذي يُجرَى من خلال ضبط متغير بيئة، فمثلًا يوضح جزء الشيفرة البرمجية التالي كيف يمكنك إعداد تسجيل المؤلف "author"، إذ يُصرَّح عن المتغير debug بالاسم author، وستُعرَض البادئة "author" تلقائيًا لجميع السجلات من هذا الكائن. const debug = require("debug")("author"); // عرض استمارة تحديث المؤلف باستخدام GET exports.author_update_get = asyncHandler(async (req, res, next) => { const author = await Author.findById(req.params.id).exec(); if (author === null) { // لا توجد نتائج debug(`id not found on update: ${req.params.id}`); const err = new Error("Author not found"); err.status = 404; return next(err); } res.render("author_form", { title: "Update Author", author: author }); }); يمكنك بعد ذلك تفعيل مجموعة معينة من السجلات من خلال تحديدها بوصفها قائمة مفصول بين عناصرها بفواصل في متغير بيئة DEBUG، ويمكنك ضبط المتغيرات لعرض سجلات المؤلف والكتاب كما هو موضح فيما يلي (المحارف البديلة Wildcards مدعومة أيضًا): # في نظام ويندوز set DEBUG=author,book # في نظام لينكس export DEBUG="author,book" ملاحظة: يمكن أن تحل استدعاءات debug محل التسجيل الذي ربما طبّقته مسبقًا باستخدام console.log() أو console.error()، لذا ضع التسجيل باستخدام وحدة debug مكان استدعاءات console.log() في شيفرتك البرمجية، وشغّل التسجيل وأوقفه في بيئة التطوير من خلال ضبط المتغير DEBUG ولاحظ تأثير ذلك على التسجيل. إذا كنت بحاجة إلى تسجيل نشاط موقع الويب، يمكنك استخدام مكتبة تسجيل مثل Winston أو Bunyan. اطلع على أفضل ممارسات عملية الإنتاج: الأداء والموثوقية لمزيد من المعلومات. استخدم ضغط gzip أو deflate للاستجابة تضغط خوادم الويب غالبًا استجابة HTTP المُرسَلة إلى العميل، مما يقلل من الوقت المطلوب للعميل للحصول على الصفحة وتحميلها. سيعتمد تابع الضغط المُستخدَم على توابع فك الضغط التي يدعمها العميل في الطلب، إذ ستُرسَل الاستجابة بحيث تكون غير مضغوطة عندما تكون توابع الضغط غير مدعومة. يمكنك إضافة ذلك إلى موقعك باستخدام برمجية الضغط الوسيطة compression، لذا ثبّتها في جذر مشروعك من خلال تشغيل الأمر التالي: npm install compression افتح الملف "./app.js" واطلب مكتبة الضغط. ضِف مكتبة الضغط إلى سلسلة البرمجيات الوسيطة باستخدام التابع use() الذي يجب أن يظهر قبل أي وجهات Routes تريد ضغطها (جميع الوجهات في حالتنا): const catalogRouter = require("./routes/catalog"); // استيراد الوجهات لمنطقة الدليل "catalog" من موقعك const compression = require("compression"); // إنشاء كائن تطبيق Express const app = express(); // … app.use(compression()); // ضغط جميع الوجهات app.use(express.static(path.join(__dirname, "public"))); app.use("/", indexRouter); app.use("/users", usersRouter); app.use("/catalog", catalogRouter); // إضافة وجهات الدليل catalog إلى سلسلة البرمجيات الوسيطة // … ملاحظة: لن تَستخدمَ هذه البرمجيات الوسيطة لموقع الويب الذي يمتلك حركة مرور عالية في بيئة الإنتاج، لذا يمكنك استخدام وكيل عكسي مثل Nginx بدلًا من ذلك. استخدام حزمة Helmet للحماية من الثغرات المعروفة تُعَد Helmet حزمة برمجيات وسيطة يمكنها ضبط ترويسات HTTP المناسبة التي تساعد في حماية تطبيقك من ثغرات الويب المعروفة. اطّلع على توثيقها للحصول على مزيد من المعلومات حول الترويسات التي تضبطها والثغرات الأمنية التي تحميك منها. ثبّتها في جذر مشروعك من خلال تشغيل الأمر التالي: npm install helmet افتح الملف "./app.js" واطلب مكتبة helmet، ثم ضِف الوحدة إلى سلسلة البرمجيات الوسيطة باستخدام التابع use(): const compression = require("compression"); const helmet = require("helmet"); // إنشاء كائن تطبيق Express const app = express(); // إضافة حزمة helmet إلى سلسلة البرمجيات الوسيطة // ضبط ترويسات CSP للسماح بتخديم Bootstrap و Jquery app.use( helmet.contentSecurityPolicy({ directives: { "script-src": ["'self'", "code.jquery.com", "cdn.jsdelivr.net"], }, }), ); // … يمكن أن نضيف التابع app.use(helmet()); لإضافة مجموعة فرعية من الترويسات المتعلقة بالأمان والتي تكون منطقية لمعظم المواقع، ولكننا نضمّن بعض سكربتات بوتستراب bootstrap و jQuery في قالب موقع المكتبة المحلية LocalLibrary الأساسي، مما يؤدي إلى انتهاك سياسة أمان المحتوى Content Security Policy -أو CSP اختصارًا- الافتراضية الخاصة بحزمة helmet، والتي لا تسمح بتحميل السكربتات العابرة للمواقع. يمكن السماح بتحميل هذه السكربتات من خلال تعديل ضبط helmet بحيث تُضبَط موجّهات CSP للسماح بتحميل السكربت من النطاقات المُشار إليها، ويمكنك بالنسبة لخادمك إضافة أو تعطيل ترويسات محددة حسب الحاجة باتباع الإرشادات الخاصة باستخدام helmet. إضافة معدل محدود إلى وجهات واجهة برمجة التطبيقات API تُعَد Express-rate-limit حزمة برمجية وسيطة يمكن استخدامها للحد من الطلبات المتكررة لواجهات برمجة التطبيقات API والنقاط النهائية، فهناك العديد من الأسباب التي يمكن أن تؤدي إلى زيادة الطلبات على موقعك مثل هجمات حجب الخدمة أو هجمات القوة الغاشمة أو حتى مجرد عميل أو سكربت لا يتصرف كما هو متوقع، ويمكن أن تُحاسَب على حركة المرور الإضافية بغض النظر عن مشاكل الأداء التي يمكن أن تنشأ عن كثرة الطلبات التي تتسبب في إبطاء خادمك. يمكن استخدام حزمة Express-rate-limit للحد من عدد الطلبات التي يمكن إجراؤها على وجهة معينة أو مجموعة من الوِجهات. يمكنك الاطلاع على مقال الهجمات الأمنية Security Attacks في الشبكات الحاسوبية على أكاديمية حسوب لمزيد من المعلومات حول أنواع الهجمات الأمنية. ثبّت هذه الحزمة في جذر مشروعك من خلال تشغيل الأمر التالي: npm install express-rate-limit افتح الملف "./app.js" واطلب مكتبة express-rate-limit كما يلي، ثم ضِف الوحدة إلى سلسلة البرمجيات الوسيطة باستخدام التابع use(): const compression = require("compression"); const helmet = require("helmet"); const app = express(); // إعداد محدِّد المعدل إلى عشرين طلبًا في الدقيقة كحد أعلى const RateLimit = require("express-rate-limit"); const limiter = RateLimit({ windowMs: 1 * 60 * 1000, // 1 دقيقة max: 20, }); // طبّق محدّد المعدّل على جميع الطلبات app.use(limiter); // … ملاحظة: يحدّد الأمر السابق جميع الطلبات لتكون 20 طلبًا في الدقيقة، ولكن يمكنك تغييره حسب الحاجة. يمكن أيضًا استخدام خدمات خارجية مثل Cloudflare إذا كنت بحاجة إلى مزيد من الحماية المتقدمة ضد هجمات حجب الخدمة أو أنواع أخرى من الهجمات. تطبيق عملي: تثبيت موقع المكتبة المحلية LocalLibrary على منصة Railway يقدّم هذا القسم شرحًا عمليًا لكيفية تثبيت موقع المكتبة المحلية LocalLibrary على منصة Railway. سبب استخدام Railway اخترنا استخدام منصة Railway لعدة أسباب هي: تمتلك Railway مستوًى مجانيًا لخطة بداية مع بعض القيود، إذ من المهم أن تكون بأسعار مقبولة لجميع المطورين. تهتم Railway بمعظم البنية التحتية، فلا حاجة للقلق بشأن الخوادم وموازني الحِمل والوكلاء العكسيين وغير ذلك، مما يجعل البدء أسهل بكثير. تركّز Railway على تجربة المطور للتطوير والنشر، مما يؤدي إلى وجود منحنى تعليمي أسرع وأسلس من العديد من البدائل الأخرى. تُعَد المهارات والمفاهيم التي ستتعلمها عند استخدام Railway قابلة للتحويل، إذ تمتلك Railway بعض الميزات الجديدة الممتازة، ولكن تستخدم خدماتُ الاستضافة الشائعة الأخرى العديدَ من الأفكار والأساليب نفسها. لا تؤثر قيود الخدمات والخطط على استخدامنا لمنصة Railway في مثالنا، فمثلًا: تقدّم خطة البداية 500 ساعة فقط من وقت النشر المستمر كل شهر و5 دولارات من الرصيد الذي يُستهلَك بناءً على الاستخدام، ويُعاد ضبط الساعات والرصيد ويجب إعادة نشر المشاريع في نهاية كل شهر. تعني هذه القيود أنه يمكنك تشغيل هذا المثال بصورة مستمرة لمدة 21 يومًا تقريبًا، ويُعَد ذلك أكثر من كافٍ للتطوير والاختبار، ولكن لن تتمكّن من استخدام هذه الخطة لموقع حقيقي للإنتاج. تحتوي بيئة خطة البداية على 512 ميجابايت فقط من الذاكرة RAM و1 جيجابايت من ذاكرة التخزين، وهذا أكثر من كافٍ لمثالنا. لا توجد سوى منطقة واحدة مدعومة وهي الولايات المتحدة الأمريكية حاليًا، إذ يمكن أن تكون الخدمة خارج هذه المنطقة أبطأ أو تحظرها القوانين المحلية. يمكن العثور على قيود أخرى في توثيق خطط Railway للدفع. تبدو الخدمة موثوقة جدًا، وإذا كانت مناسبة لك، فإن الأسعار يمكن التنبؤ بها، ويكون توسيع تطبيقك سهلًا جدًا. تعَد Railway مناسبة لاستضافة مثالنا، ولكن يجب أن تأخذ الوقت الكافي لتحديد ما إذا كانت مناسبة لموقعك. كيفية عمل Railway يُشغَّل كل تطبيق ويب في حاوية افتراضية معزولة ومستقلة خاصة به، لذا يجب أن تكون Railway قادرة على إعداد البيئة والاعتماديات المناسبة، وفهم كيفية إطلاقها لتنفيذ تطبيقك. تجعل Railway هذا الأمر سهلًا، إذ يمكنها التعرف تلقائيًا على العديد من أطر عمل وبيئات تطبيقات الويب المختلفة وتثبيتها بناءً على استخدامها "للمصطلحات الشائعة"، فمثلًا تتعرّف Railway على تطبيقات Node لأن لديها ملف package.json، ويمكنها تحديد مدير الحزم المُستخدَم للبناء من ملف "القفل Lock". إذا احتوى التطبيق على ملف package-lock.json مثلًا، فستعرف Railway أنها ستستخدم مدير حزم npm لتثبيت الحزم، وإذا وجدت yarn.lock فستعرف أنها ستستخدم yarn. ستبحث Railway -بعد تثبيت جميع الاعتماديات- عن سكربتات بالاسم "build" و "start" في ملف الحزمة، وستستخدمها لبناء وتشغيل الشيفرة البرمجية. ملاحظة: تستخدم Railway حزمة Nixpacks للتعرف على العديد من أطر عمل تطبيقات الويب المكتوبة بلغات برمجة مختلفة. لا حاجة إلى معرفة أيّ شيء آخر لهذا المقال، ولكن يمكنك معرفة المزيد حول خيارات نشر تطبيقات Node في توثيق Nixpacks. يمكن للتطبيق بعد تشغيله ضبط نفسه باستخدام المعلومات المقدمة في متغيرات البيئة، فمثلًا يجب أن يحصل التطبيق الذي يستخدم قاعدة بيانات على العنوان باستخدام متغير، ويمكن أن تستضيف Railway خدمة قاعدة البيانات نفسها أو على أي مزوّد آخر. يتفاعل المطورون مع Railway من خلال موقع Railway وباستخدام أداة واجهة سطر أوامر CLI خاصة، إذ تسمح لك واجهة CLI بربط مستودع غيت هب GitHub محلي بمشروع Railway، ورفع المستودع من الفرع المحلي إلى الموقع المباشر، وفحص سجلات العملية الجارية، وإعداد متغيرات الضبط والحصول عليها وغير ذلك. من أهم الميزات أنه يمكنك استخدام واجهة CLI لتشغيل مشروعك المحلي مع متغيرات البيئة نفسها للمشروع المباشر. يجب وضع تطبيق Express الخاص بنا في مستودع غيت git وإجراء بعض التغييرات الطفيفة ليعمل تطبيقنا على Railway، ثم يمكننا إعداد حساب على Railway وتثبيت موقعنا وقاعدة البيانات وتجربة عميل Railway. وهذا هو كل ما تحتاجه من معلومات في البداية. إنشاء مستودع للتطبيق على غيت هب GitHub تتكامل Railway تكاملًا وثيقًا مع غيت هب ونظام التحكم في إصدارات الشيفرة المصدرية git، ويمكنك ضبطها لنشر التحديثات تلقائيًا عند إجراء تغييرات إلى مستودع أو فرع معين على غيت هب، أو يمكنك دفع فرع الشيفرة المحلية الحالي مباشرةً إلى النشر الخاص بمنصة Railway باستخدام واجهة CLI. ملاحظة: يُعَد استخدام نظام إدارة الشيفرة المصدرية مثل غيت هب ممارسة جيدة لتطوير البرمجيات، فإذا كنت تستخدم غيت هب لإدارة شيفرتك المصدرية مسبقًا، فتخطى هذه الخطوة. هناك العديد من الطرق للعمل مع git، ومن أسهلها إعداد حساب على غيت هب أولًا وإنشاء المستودع عليه، ثم المزامنة معه محليًا كما يلي: انتقل إلى موقع GitHub الرسمي وأنشئ حسابًا عليه. انقر على ارتباط + في شريط الأدوات العلوي وحدّد خيار "مستودع جديد New repository" بعد تسجيل الدخول. املأ جميع الحقول في هذه الاستمارة، إذ يمكن أن تكون هذه الحقول غير إلزامية، ولكن يُوصَى بها بشدة. أدخل اسم المستودع الجديد والوصف، فمثلًا يمكنك استخدام الاسم "express-locallibrary-tutorial" والوصف "Local Library website written in Express (Node)" (موقع المكتبة المحلية المكتوب باستخدام Express). اختر الخيار Node في قائمة الاختيار Add .gitignore. اختر الترخيص المفضل لديك في قائمة الاختيار Add license. تحقق من تهيئة المستودع باستخدام README. تحذير: سيجعل الوصول الافتراضي العام "Public" جميع الشيفرة البرمجية المصدرية -بما في ذلك اسم المستخدم وكلمة المرور لقاعدة البيانات- مرئيةً لأي شخص على الإنترنت، لذا تأكد من أن الشيفرة البرمجية المصدرية لا تقرأ اعتماديات إلّا من متغيرات البيئة ولا تحتوي على أيّ اعتماديات ثابتة، وإلّا حدد الخيار خاص "Private" للسماح فقط لأشخاص محدَّدين برؤية الشيفرة المصدرية. اضغط على إنشاء مستودع Create repository. انقر فوق الزر الأخضر نسخ Clone أو تنزيل Download في صفحة مستودعك الجديد. انسخ قيمة URL من حقل النص الموجود في مربع الحوار الذي يظهر، فإذا استخدمت اسم المستودع "express-locallibrary-tutorial"، فيجب أن يكون عنوان URL مثل العنوان: https://github.com/<your_git_user_id>/express-locallibrary-tutorial.git. انتهينا من إنشاء المستودع، ويجب الآن نسخه على حاسوبك المحلي باتباع الخطوات التالية: أولًا، ثبّت git على حاسوبك المحلي، إذ يمكنك العثور على نسخ لأنظمة مختلفة. ثانيًا، افتح موجه الأوامر أو الطرفية وانسخ مستودعك باستخدام عنوان URL الذي نسخته سابقًا كما في الأمر التالي: git clone https://github.com/<your_git_user_id>/express-locallibrary-tutorial.git سيؤدي هذا الأمر إلى إنشاء المستودع في المجلد الحالي. ثالثًا، انتقل إلى مجلد المستودع باستخدام الأمر التالي: cd express-locallibrary-tutorial أخيرًا، انسخ ملفات تطبيقك المصدرية في مجلد المستودع، ثم اجعلها جزءًا من المستودع باستخدام git كما يلي: أولًا، انسخ تطبيق Express إلى هذا المجلد باستثناء المجلد "/node_modules" الذي يحتوي على ملفات الاعتماديات التي يجب جلبها من مدير حزم npm حسب الحاجة. ثانيًا، افتح موجه الأوامر أو الطرفية واستخدم الأمر add لإضافة جميع الملفات إلى git كما يلي: git add -A ثالثًا، استخدم الأمر status للتحقق من صحة جميع الملفات التي تريد تثبيتها commit، إذ نريد تضمين الملفات المصدرية، وليس الملفات الثنائية والمؤقتة وما إلى ذلك، إذ يجب أن تبدو كما يلي: > git status ويكون الخرج الناتج بعد تنفيذ هذا الأمر على النحو التالي: On branch main Your branch is up-to-date with 'origin/main'. Changes to be committed: (use "git reset HEAD <file>..." to unstage) new file: … رابعًا، ثبّت باستخدام commit الملفات في مستودعك المحلي عندما تكون راضيًا عن النتيجة، إذ يكافئ ذلك الإقرار بالتغييرات وجعلها جزءًا رسميًا من المستودع المحلي. git commit -m "First version of application moved into GitHub" خامسًا، لم يتغيّر المستودع البعيد حتى الآن، لذا يجب مزامنة (باستخدام الأمر push) مستودعك المحلي مع مستودع GitHub البعيد باستخدام الأمر التالي: git push origin main يجب أن تكون قادرًا عند اكتمال هذه العملية على العودة إلى صفحة غيت حيث أنشأت مستودعك، وتحديث الصفحة، ويجب ملاحظة رفع كامل التطبيق. يمكنك الاستمرار في تحديث مستودعك مع تغير الملفات باستخدام دورة أوامر الإضافة add والتثبيت commit والدفع push. ملاحظة: يمكنك الآن إنشاء نسخة احتياطية من شيفرة مشروعك البرمجية، إذ يمكن أن تكون بعض التغييرات التي سنجريها في الأقسام التالية مفيدة للنشر (أو للتطوير) على أي خدمة استضافة، ويمكن أن تكون بعض التغييرات الأخرى غير مفيدة. أفضل طريقة لذلك هي استخدام git لإدارة الإصدارات، إذ يمكنك باستخدامه الرجوع إلى إصدار سابق معين، ويمكنك الاحتفاظ به في فرع منفصل عن التغييرات الإنتاجية واختيار أيّ تغييرات للتنقل بين فروع الإنتاج والتطوير. يستحق تعلم غيت Git الجهد المبذول، لذا اطلع على مجموعة مقالات Git في أكاديمية حسوب. يُعَد نسخ ملفاتك في موقع آخر الطريقة الأسهل، ولكن يمكنك استخدام أيّ طريقة تتناسب مع معرفتك لنظام git. تحديث التطبيق ليعمل على Railway سنشرح في هذا القسم التغييرات التي يجب إجراؤها على تطبيق المكتبة المحلية LocalLibrary ليعمل على Railway، ولكن لن تمنعك هذه التغييرات من استخدام الاختبار وسير العمل المحلي الذي تعلمناه مسبقًا. ضبط نسخة Node يحتوي الملف package.json على كل ما تحتاجه Railway للعمل على اعتماديات تطبيقك وتحديد الملف الواجب تشغيله لبدء تشغيل موقعك، ولكن المعلومات المهمة الوحيدة المفقودة من الملف package.json الحالي هي نسخة Node، إذ يمكنك العثور على نسخة Node التي نستخدمها للتطوير من خلال إدخال الأمر التالي: >node --version v16.17.1 افتح الملف package.json وأضِف المعلومات التالية في قسم engines > node (مع استخدام رقم النسخة في نظامك): { "name": "express-locallibrary-tutorial", "version": "0.0.0", "engines": { "node": ">=16.17.1" }, "private": true, // … لاحظ أن هناك طرقًا أخرى لتوفير نسخة Node على Railway، ولكننا نستخدم الملف package.json لأنه الأسلوب الذي تدعمه العديد من الخدمات على نطاق واسع. لاحظ أيضًا أن Railway لن تستخدم بالضرورة نسخة Node الدقيقة التي تحددها، إذ ستستخدم نسخةً لها رقم النسخة الرئيسي نفسه. الحصول على الاعتماديات وإعادة الاختبار لنختبر الموقع مرةً أخرى ونتأكد من أنه لم يتأثر بأيٍّ من التغييرات التي أجريناها. أولًا، يجب جلب الاعتماديات (تذكّر أننا لم ننسخ المجلد node_modules في شجرة git)، إذ يمكنك ذلك من خلال تشغيل الأمر التالي في طرفيتك ضمن جذر المشروع: npm install شغّل الموقع (اطّلع على فقرة اختبار الوجهات في مقال الوجهات والمتحكمات لمعرفة الأوامر ذات الصلة) وتحقق من أن الموقع لا يزال يتصرف كما هو متوقع. حفظ التغييرات على غيت هب GitHub احفظ الآن جميع التغييرات التي أجريتها على غيت هب، وأدخِل الأوامر التالية في الطرفية أثناء وجودك في مستودعك: git add -A git commit -m "Added files and changes required for deployment" git push origin main يجب أن نكون جاهزين الآن لبدء نشر موقع المكتبة المحلية LocalLibrary على Railway. الحصول على حساب على Railway يجب أولًا إنشاء حساب لبدء استخدام Railway باتباع الخطوات التالية: اذهب إلى موقع Railway الرسمي وانقر على ارتباط تسجيل الدخول Login في شريط الأدوات العلوي. اختر GitHub في النافذة المنبثقة لتسجيل الدخول باستخدام اعتماديات GitHub الخاصة بك. يمكن أن تحتاج بعد ذلك إلى الانتقال إلى بريدك الإلكتروني والتحقق من حسابك. ستسجل بعد ذلك الدخول إلى لوحة تحكم Railway. النشر على Railway من GitHub يجب الآن إعداد Railway لنشر موقع مكتبتنا من GitHub، لذا اختر أولًا خيار لوحة التحكم Dashboard من القائمة العلوية للموقع، ثم حدّد زر مشروع جديد New Project: ستعرض Railway قائمةً بالخيارات الخاصة بالمشروع الجديد، بما في ذلك خيار نشر مشروع من قالب أنشأته لأول مرة في حسابك على GitHub، وعددًا من قواعد البيانات، لذا حدد خيار النشر Deploy from GitHub repo. ستُعرَض جميع المشاريع في مستودعات GitHub التي شاركتها مع Railway أثناء عملية الإعداد، ولكنك ستختار مستودع GitHub الخاص بموقع المكتبة المحلية: <user-name>/express-locallibrary-tutorial. أكّد النشر من خلال تحديد خيار النشر حالًا Deploy Now. ستحمّل Railway بعد ذلك مشروعك وتنشره، مع عرض التقدم في نافذة عمليات النشر Deployments، ثم سترى شيئًا يشبه ما يلي عند اكتمال النشر بنجاح: اختر الآن نافذة الإعدادات Settings، ثم انتقل إلى الأسفل إلى قسم النطاقات Domains، واضغط على زر توليد نطاق Generate Domain. سيؤدي ذلك إلى نشر الموقع ووضع النطاق في مكان الزر كما هو موضح فيما يلي: حدّد عنوان URL للنطاق لفتح تطبيق المكتبة. لاحظ فتح موقع المكتبة المحلية باستخدام بيانات التطوير الخاصة بك لأننا لم نحدّد قاعدة بيانات الإنتاج. تجهيز وتوصيل قاعدة بيانات MongoDb لننشئ الآن قاعدة بيانات MongoDB الخاصة بالإنتاج لاستخدامها بدلًا من استخدام بيانات التطوير، إذ سننشئ قاعدة البيانات بوصفها جزءًا من مشروع تطبيق Railway، بالرغم من أنه لا يوجد ما يمنعك من إنشائها في مشروعها المنفصل أو استخدام قاعدة بيانات MongoDB Atlas لبيانات الإنتاج، كما فعلت مع قاعدة بيانات التطوير. حدّد الخيار Dashboard من قائمة الموقع العلوية على Railway ثم حدد مشروع تطبيقك، الذي يحتوي حاليًا على خدمة واحدة فقط لتطبيقك، والتي يمكن اختيارها لضبط المتغيرات وتفاصيل الخدمة الأخرى، ثم حدّد الزر جديد New، والذي يستخدم لإضافة خدمات إلى المشروع الحالي. حدد قاعدة البيانات Database عندما يُطلَب منك تحديد نوع الخدمة لإضافتها. حدّد بعد ذلك خيار الإضافة Add MongoDB لبدء إضافة قاعدة البيانات. ستجهز Railway بعد ذلك خدمةً تحتوي على قاعدة بيانات فارغة في المشروع نفسه، وسترى عند الانتهاء كلًا من التطبيق وخدمات قاعدة البيانات في عرض المشروع. حدّد خدمة MongoDB لعرض معلومات حول قاعدة البيانات، ثم افتح نافذة "الاتصال Connect" وانسخ "عنوان URL لاتصال Mongo"، وهو عنوان قاعدة البيانات. يمكن جعل تطبيق المكتبة يصل إلى هذا العنوان من خلال إضافته إلى عملية التطبيق باستخدام متغير بيئة، لذا افتح أولًا خدمة التطبيق، ثم حدّد نافذة المتغيرات Variables واضغط على زر متغير جديد New Variable. أدخِل اسم المتغير MONGODB_URI وعنوان URL للاتصال الذي نسخته لقاعدة البيانات، فالمتغير MONGODB_URI هو اسم متغير البيئة الذي ضبطنا التطبيق منه لقراءة عنوان قاعدة البيانات، وسيظهر لديك ما يلي: حدّد بعد ذلك زر الإضافة Add لإضافة المتغير. تعيد Railway تشغيل تطبيقك عندما تحدّث المتغيرات. إذا فحصتَ الصفحة الرئيسية الآن، فيجب أن تظهِر قيمًا صفرية لأعداد الكائنات، إذ تعني التغييرات السابقة أننا نستخدم الآن قاعدة بيانات جديدة (فارغة). متغيرات الضبط الأخرى تذكّر من القسم السابق أننا بحاجة إلى ضبط NODE_ENV على قيمة الإنتاج 'production' لتحسين الأداء وإنشاء رسائل خطأ أقل تفصيلًا، ويمكننا فعل ذلك في الشاشة نفسها التي ضبطنا منها المتغير MONGODB_URI. افتح خدمة التطبيق، ثم حدد نافذة المتغيرات Variables، إذ سترى أن المتغير MONGODB_URI مُعرَّف مسبقًا، واضغط على زر متغير جديد New Variable. أدخل NODE_ENV بوصفه اسم المتغير الجديد و production بوصفه اسم البيئة، ثم اضغط على زر الإضافة Add. ضُبِط وأُعِدّ تطبيق المكتبة المحلية للاستخدام في بيئة الإنتاج، ويمكنك إضافة البيانات عبر واجهة موقع الويب ويجب أن تعمل بالطريقة نفسها التي كانت تعمل بها أثناء عملية التطوير (مع وصول أقل إلى معلومات تنقيح الأخطاء للصفحات غير الصالحة). ملاحظة: إذا أدرتَ إضافة بعض البيانات للاختبار، فيمكنك استخدام السكربت populatedb مع عنوان URL لقاعدة بيانات MongoDB الخاصة بالإنتاج كما ناقشنا في مقال استخدام قاعدة البيانات باستخدام مكتبة Mongoose. تثبيت العميل نزّل وثبّت عميل Railway لنظام تشغيلك المحلي باتباع التعليمات الواردة في توثيق Railway. ستتمكن من تشغيل الأوامر بعد تثبيت العميل. تتضمن بعض العمليات الأكثر أهمية نشر المجلد الحالي لحاسوبك إلى مشروع Railway المرتبط به دون الحاجة للرفع على GitHub، وتشغيل مشروعك محليًا باستخدام الإعدادات نفسها الموجودة على خادم الإنتاج. يمكنك الحصول على قائمة بجميع الأوامر الممكنة من خلال إدخال الأمر التالي في الطرفية: railway help تنقيح الأخطاء Debugging يوفّر عميل Railway الأمر logs لإظهار السجلات الأخيرة (يتوفر سجل كامل على الموقع لكل مشروع): railway logs الخلاصة وصلنا إلى نهاية مقالنا حول إعداد تطبيقات Express في بيئة الإنتاج، وكذلك إلى نهاية سلسلة مقالات إطار عمل Express، لذا نأمل أنها كانت مفيدة لك، ولا تنسَ أنه يمكنك التحقق من النسخة الكاملة من الشيفرة المصدرية على GitHub. ترجمة -وبتصرُّف- للمقال Express Tutorial Part 7: Deploying to production. اقرأ المزيد المقال السابق تطبيق عملي لتعلم Express - الجزء الرابع: عرض بيانات المكتبة والعمل مع الاستمارات. مرحلة نشر التطبيق في عملية تطوير الويب. تطبيق عملي لتعلم جانغو - الجزء 10: نشر تطبيق جانغو في بيئة الإنتاج.
أنشأتَ واختبرتَ موقع المكتبة المحلية LocalLibrary، ويجب الآن تثبيته على خادم ويب عام ليصل إليه موظفو المكتبة وأعضاؤها عبر الإنترنت. يقدّم هذا المقال نظرة عامة حول كيفية البحث عن مضيف لنشر موقعك، وما عليك فعله لتجهيز موقعك لمرحلة الإنتاج. المتطلبات الأساسية: إكمال المقالات السابقة من هذه السلسلة بما في ذلك مقال عرض بيانات المكتبة والعمل مع الاستمارات. الهدف: معرفة مكان وكيفية نشر تطبيق Express في بيئة الإنتاج. يجب استضافة موقعك بعد الانتهاء منه (أو الانتهاء منه "بما يكفي" لبدء الاختبار العام) في مكان أعم ويمكن الوصول إليه من أجهزة أخرى غير حاسوبك الشخصي الخاص بالتطوير. عملتَ حتى الآن في بيئة تطوير باستخدام خادم ويب تطوير Express/Node لمشاركة موقعك على المتصفح أو الشبكة المحلية، وشغّلتَ موقعك باستخدام إعدادات تطوير (غير آمنة) بحيث يمكن الوصول إلى معلومات تنقيح الأخطاء والمعلومات الخاصة الأخرى. يجب عليك أولًا تنفيذ الخطوات التالية قبل أن تتمكّن من استضافة موقع ويب خارجيًا: اختيار بيئة لاستضافة تطبيق Express. إجراء بعض التغييرات على إعدادات مشروعك. إعداد بنية تحتية على مستوى الإنتاج لتخديم موقع الويب. يقدّم هذا المقال بعض الإرشادات حول الخيارات المتاحة لاختيار موقع استضافة، ونظرة ًعامة مختصرة على ما يجب تطبيقه لتجهيز تطبيق Express لبيئة الإنتاج، ويقدم مثالًا عمليًا لكيفية تثبيت موقع المكتبة المحلية LocalLibrary على خدمة الاستضافة السحابية Railway. ما هي بيئة الإنتاج؟ بيئة الإنتاج هي البيئة التي يوفّرها حاسوب الخادم إذ ستشغِّل موقعك للاستخدام الخارجي، وتشمل هذه البيئة ما يلي: عتاد الحاسوب الذي يعمل عليه الموقع. نظام التشغيل، مثل لينكس أو ويندوز. وقت التشغيل الخاص بلغة البرمجة ومكتبات أطر العمل التي كُتِب عليها موقعك. خادم الويب المُستخدَم لتخديم الصفحات والمحتويات الأخرى، مثل خادم إنجن إكس Nginx وأباتشي Apache. البنية التحتية لخادم الويب وتتضمن خادم الويب والوكيل العكسي Reverse Proxy وموازن الحِمل Load Balancer وغير ذلك. قواعد البيانات التي يعتمد عليها موقعك. يمكن أن يكون حاسوب الخادم موجودًا في مقر عملك ومتصلًا بالإنترنت من خلال رابط سريع، ولكن يمكن استخدام حاسوب مستضاف على السحابة، وهذا يعني تنفيذ شيفرتك البرمجية على بعض الحواسيب البعيدة (أو على حاسوب افتراضي) في مركز أو مراكز بيانات شركتك المضيفة. يقدّم الخادم البعيد عادةً مستوًى مضمونًا من موارد المعالجة، مثل وحدة المعالجة المركزية والذاكرة RAM وذاكرة التخزين وغير ذلك والاتصال بالإنترنت بسعر معين. يشار إلى هذا النوع من عتاد المعالجة والتشبيك الذي يمكن الوصول إليه عن بُعد باسم البنية التحتية كخدمة Infrastructure as a Service -أو IaaS اختصارًا. يوفّر العديد من بائعي خدمة IaaS خيارات التثبيت المُسبَق لنظام تشغيل معين، والذي يجب تثبيت مكونات بيئتك الإنتاجية الأخرى عليه، ويسمح لك البائعون الآخرون باختيار بيئات كاملة الميزات، ويمكن أن يتضمن ذلك إعداد بيئة Node الكاملة. ملاحظة: يمكن للبيئات المبنية مسبقًا أن تسهّل إعداد موقعك لأنها تقلل من عملية الضبط Configuration، ولكن يمكن أن تقيّدك الخيارات المتاحة بخادم غير مألوف لك (أو بمكونات أخرى) ويمكن أن تستند إلى نسخة أقدم من نظام التشغيل. يُفضَّل غالبًا تثبيت المكونات بنفسك حتى تحصل على المكونات التي تريدها، وبالتالي ستعرف من أين تبدأ عندما تحتاج إلى ترقية أجزاء من النظام. يدعم مزوّدو الاستضافة الآخرون إطار عمل Express بوصفه جزءًا من استضافة المنصة كخدمة Platform as a Service -أو PaaS اختصارًا، فلا داعي للقلق في هذا النوع من الاستضافة بشأن معظم أجزاء بيئتك الإنتاجية (الخوادم وموازنو الحِمل load balancers وغيرها) لأن المنصة المضيفة تهتم بهذه الأشياء نيابةً عنك، مما يجعل النشر سهلًا جدًا، لأنك تحتاج فقط إلى التركيز على تطبيق الويب وليس على بنية الخادم التحتية الأخرى. سيختار بعض المطورين المرونة المتزايدة التي توفرها استضافة IaaS على حساب استضافة PaaS، بينما سيقدّر المطورون الآخرون تقليل تكاليف الصيانة وسهولة توسيع نطاق استضافة PaaS. يكون إعداد موقعك على نظام PaaS أسهل بكثير في البداية، وهذا ما سنفعله في هذا المقال. ملاحظة: إذا اخترت مزوّد استضافة متوافق مع Node/Express، فيجب أن يقدّم إرشادات حول كيفية إعداد موقع Express باستخدام عمليات ضبط مختلفة لخادم الويب وخادم التطبيق والوكيل العكسي وغير ذلك. اختيار مزود الاستضافة يوجد العديد من مزوّدات الاستضافة المعروفة التي تدعم بنشاط أو تعمل بصورة جيدة مع بيئة Node و Express، ويوفّر هؤلاء البائعون أنواعًا مختلفة من البيئات (IaaS و PaaS) ومستويات مختلفة من موارد المعالجة والشبكات بأسعار مختلفة. ملاحظة: هناك الكثير من حلول الاستضافة، ويمكن أن تتغير خدماتها وأسعارها بمرور الوقت. سنقدّم بعض الخيارات، ولكن يجدر بك التحقق من هذه الخيارات وغيرها قبل اختيار مزود الاستضافة. إليك بعض الأشياء التي يجب مراعاتها عند اختيار المضيف: مدى انشغال موقعك المُحتمَل وتكلفة البيانات وموارد المعالجة المطلوبة لتلبية هذا المطلب. مستوى الدعم للتوسّع أفقيًا (إضافة المزيد من الأجهزة) وعموديًا (الترقية إلى أجهزة أقوى) وتكاليف ذلك. مكان مراكز بيانات المزوّد، أي المكان الذي يكون الوصول إليه أسرع. أداء وقت التشغيل ووقت التعطل السابقَين للمضيف. الأدوات المتوفرة لإدارة الموقع، لمعرفة إذا كانت سهلة الاستخدام وآمنة، مثل استخدام بروتوكول SFTP أو استخدام بروتوكول FTP. أطر العمل المبنية مسبقًا لمراقبة خادمك. القيود المعروفة، إذ سيوقِف بعض المضيفين عمدًا خدمات معينة مثل البريد الإلكتروني، ويقدّم البعض الآخر فقط عددًا معينًا من ساعات "النشاط" في بعض مستويات الأسعار، أو يقدّم فقط قدرًا صغيرًا من التخزين. الفوائد الإضافية، إذ ستقدّم بعض المزوّدات أسماء نطاقات مجانية ودعمًا لشهادات SSL التي يمكن أن يتعيّن عليك دفع ثمنها. معرفة ما إذا كان المستوى "المجاني" الذي تعتمد عليه تنتهي صلاحيته بمرور الوقت، وما إذا كانت تكلفة التهجير Migrating إلى مستوًى أغلى تعني أنه كان من الأفضل استخدام بعض الخدمات الأخرى من البداية. هناك عددٌ قليل جدًا من المواقع التي توفر بيئات معالجة "مجانية" مخصصة للتقييم والاختبار في البداية، وتكون عادةً بيئات مُقيَّدة أو محدودة الموارد إلى حدٍ ما، ويجب أن تدرك أنه يمكن أن تنتهي صلاحيتها بعد فترة أولية أو يكون لديها قيود أخرى، ولكنها رائعة لاختبار المواقع ذات حركة المرور المنخفضة في بيئة مُستضافة، ويمكن أن توفر تهجيرًا سهلًا للدفع مقابل المزيد من الموارد عندما يصبح موقعك أكثر انشغالًا. تشمل الخيارات الشائعة في هذه الفئة Railway و Python Anywhere و Amazon Web Services و Microsoft Azure وغير ذلك. يقدّم معظم المزوّدين مستوًى أساسيًا مخصصًا لمواقع الإنتاج الصغيرة، والذي يوفّر مستويات أكثر فائدة من قدرة المعالجة وقيودًا أقل. يُعَد Heroku و Digital Ocean و Python Anywhere أمثلة على مزودي الاستضافة المشهورة التي لديها مستوى معالجة أساسي غير مكلف نسبيًا (في نطاق يتراوح بين 5 و 10 دولارات أمريكية شهريًا). ملاحظة: تذكّر أن السعر ليس معيار الاختيار الوحيد، فإذا كان موقعك ناجحًا، فيمكن أن تكون قابلية التوسع هي الأهم. تجهيز موقعك للنشر الأشياء الرئيسية التي يجب التفكير فيها عند نشر موقعك هي أمان الويب والأداء، إذ ستحتاج في الحد الأدنى إلى إزالة تعقّب المكدس المُضمَّن في صفحات الخطأ أثناء التطوير، وترتيب التسجيل، وضبط الترويسات المناسبة لتجنب العديد من هجمات الأمان الشائعة، لذا سنحدّد في الأقسام الفرعية التالية أهم التغييرات الواجب إجراؤها على تطبيقك. ملاحظة: هناك نصائح مفيدة أخرى في توثيق Express، لذا اطلع على أفضل ممارسات عملية الإنتاج: الأداء والموثوقية والأمان، واعتبارات نشر مشاريع Node.js وExpress على الويب. ضبط قاعدة البيانات استخدمنا حتى الآن قاعدة بيانات واحدة ثابتة في الملف app.js، وبسبب عدم احتواء قاعدة بيانات التطوير على معلومات نخشى من كشفها أو إتلافها، فليس هناك خطورة في حال تسريبها، ولكن في حال كنا نتعامل مع بيانات حقيقية، مثل معلومات المستخدم الشخصية، ستكون حماية تلك البيانات أمرًا مهمًا جدًا. نريد عادةً أن نكون قادرين على امتلاك قاعدة بيانات مختلفة لكل من الإنتاج والتطوير وكذلك الاحتفاظ بقاعدة بيانات الإنتاج منفصلة أيضًا عن الشيفرة المصدرية بهدف حمايتها. إذا كان مزود الاستضافة الخاص بك داعمًا لمتغيرات البيئة من خلال واجهة الويب، ستكون إحدى الطرق لتحقيق ما سبق هي جعل الخادم يحصل على عنوان URL لقاعدة البيانات من متغير البيئة، لذلك سنعدّل موقع المكتبة المحلية LocalLibrary للحصول على معرّف URI لقاعدة البيانات من بيئة نظام التشغيل (إذا كان معرّفًا)، وإلّا فسنستخدم قاعدة بيانات التطوير الخاصة بنا. افتح الملف app.js وابحث عن السطر الذي يضبط متغير اتصال قاعدة بيانات MongoDB، والذي سيبدو كما يلي: const mongoDB = "mongodb+srv://your_user_name:your_password@cluster0.lz91hw2.mongodb.net/local_library?retryWrites=true&w=majority"; ضع الشيفرة التالية مكان السطر السابق، إذ تستخدم هذه الشيفرة process.env.MONGODB_URI للحصول على سلسلة الاتصال النصية من متغير البيئة MONGODB_URI إذا جرى ضبطه، واستخدم عنوان URL لقاعدة بياناتك بدلًا من العنصر البديل فيما يلي: // إعداد اتصال mongoose const dev_db_url = const mongoose = require("mongoose"); mongoose.set("strictQuery", false); const dev_db_url = "mongodb+srv://your_user_name:your_password@cluster0.lz91hw2.mongodb.net/local_library?retryWrites=true&w=majority"; const mongoDB = process.env.MONGODB_URI || dev_db_url; main().catch((err) => console.log(err)); async function main() { await mongoose.connect(mongoDB); } ضبط متغير البيئة NODE_ENV على القيمة production يمكننا إزالة تعقّب المكدس في صفحات الخطأ من خلال ضبط متغير البيئة NODE_ENV على قيمة الإنتاج 'production'، إذ يُضبَط على قيمة التطوير 'development' افتراضيًا. يؤدي ضبط المتغير على قيمة الإنتاج إلى إنشاء رسائل خطأ أقل تفصيلًا، بالإضافة إلى التخزين المؤقت لقوالب العرض وملفات CSS المُولَّدة من توسّعات شيفرة CSS، وتشير الاختبارات إلى أن ضبط متغير البيئة NODE_ENV على الإنتاج يمكن أن يحسن أداء التطبيق بمقدار ثلاثة أضعاف. يمكن إجراء هذا التغيير إما باستخدام export، أو ملف بيئة، أو نظام تهيئة لنظام التشغيل. ملاحظة: يُعَد ذلك تغييرًا تجريه في إعداد بيئتك بدلًا من إجرائه في تطبيقك، ولكنه جدير بالذكر حاليًا، إذ سنوضح كيفية ضبطه لمثال الاستضافة الآتي. التسجيل المناسب يمكن أن يكون لتسجيل الاستدعاءات تأثير على موقع الويب الذي يمتلك حركة مرور عالية، إذ يمكن أن تحتاج إلى تسجيل نشاط موقع الويب في بيئة الإنتاج، مثل تعقّب حركة المرور، أو تسجيل استدعاءات واجهة برمجة التطبيقات، ولكن يجب أن تحاول تقليل كمية التسجيل المُضافة لأغراض تنقيح الأخطاء Debugging. تتمثل إحدى طرق تقليل تسجيل "تنقيح الأخطاء" في بيئة الإنتاج في استخدام وحدة مثل الوحدة debug التي تسمح لك بالتحكم في التسجيل الذي يُجرَى من خلال ضبط متغير بيئة، فمثلًا يوضح جزء الشيفرة البرمجية التالي كيف يمكنك إعداد تسجيل المؤلف "author"، إذ يُصرَّح عن المتغير debug بالاسم author، وستُعرَض البادئة "author" تلقائيًا لجميع السجلات من هذا الكائن. const debug = require("debug")("author"); // عرض استمارة تحديث المؤلف باستخدام GET exports.author_update_get = asyncHandler(async (req, res, next) => { const author = await Author.findById(req.params.id).exec(); if (author === null) { // لا توجد نتائج debug(`id not found on update: ${req.params.id}`); const err = new Error("Author not found"); err.status = 404; return next(err); } res.render("author_form", { title: "Update Author", author: author }); }); يمكنك بعد ذلك تفعيل مجموعة معينة من السجلات من خلال تحديدها بوصفها قائمة مفصول بين عناصرها بفواصل في متغير بيئة DEBUG، ويمكنك ضبط المتغيرات لعرض سجلات المؤلف والكتاب كما هو موضح فيما يلي (المحارف البديلة Wildcards مدعومة أيضًا): # في نظام ويندوز set DEBUG=author,book # في نظام لينكس export DEBUG="author,book" ملاحظة: يمكن أن تحل استدعاءات debug محل التسجيل الذي ربما طبّقته مسبقًا باستخدام console.log() أو console.error()، لذا ضع التسجيل باستخدام وحدة debug مكان استدعاءات console.log() في شيفرتك البرمجية، وشغّل التسجيل وأوقفه في بيئة التطوير من خلال ضبط المتغير DEBUG ولاحظ تأثير ذلك على التسجيل. إذا كنت بحاجة إلى تسجيل نشاط موقع الويب، يمكنك استخدام مكتبة تسجيل مثل Winston أو Bunyan. اطلع على أفضل ممارسات عملية الإنتاج: الأداء والموثوقية لمزيد من المعلومات. استخدم ضغط gzip أو deflate للاستجابة تضغط خوادم الويب غالبًا استجابة HTTP المُرسَلة إلى العميل، مما يقلل من الوقت المطلوب للعميل للحصول على الصفحة وتحميلها. سيعتمد تابع الضغط المُستخدَم على توابع فك الضغط التي يدعمها العميل في الطلب، إذ ستُرسَل الاستجابة بحيث تكون غير مضغوطة عندما تكون توابع الضغط غير مدعومة. يمكنك إضافة ذلك إلى موقعك باستخدام برمجية الضغط الوسيطة compression، لذا ثبّتها في جذر مشروعك من خلال تشغيل الأمر التالي: npm install compression افتح الملف "./app.js" واطلب مكتبة الضغط. ضِف مكتبة الضغط إلى سلسلة البرمجيات الوسيطة باستخدام التابع use() الذي يجب أن يظهر قبل أي وجهات Routes تريد ضغطها (جميع الوجهات في حالتنا): const catalogRouter = require("./routes/catalog"); // استيراد الوجهات لمنطقة الدليل "catalog" من موقعك const compression = require("compression"); // إنشاء كائن تطبيق Express const app = express(); // … app.use(compression()); // ضغط جميع الوجهات app.use(express.static(path.join(__dirname, "public"))); app.use("/", indexRouter); app.use("/users", usersRouter); app.use("/catalog", catalogRouter); // إضافة وجهات الدليل catalog إلى سلسلة البرمجيات الوسيطة // … ملاحظة: لن تَستخدمَ هذه البرمجيات الوسيطة لموقع الويب الذي يمتلك حركة مرور عالية في بيئة الإنتاج، لذا يمكنك استخدام وكيل عكسي مثل Nginx بدلًا من ذلك. استخدام حزمة Helmet للحماية من الثغرات المعروفة تُعَد Helmet حزمة برمجيات وسيطة يمكنها ضبط ترويسات HTTP المناسبة التي تساعد في حماية تطبيقك من ثغرات الويب المعروفة. اطّلع على توثيقها للحصول على مزيد من المعلومات حول الترويسات التي تضبطها والثغرات الأمنية التي تحميك منها. ثبّتها في جذر مشروعك من خلال تشغيل الأمر التالي: npm install helmet افتح الملف "./app.js" واطلب مكتبة helmet، ثم ضِف الوحدة إلى سلسلة البرمجيات الوسيطة باستخدام التابع use(): const compression = require("compression"); const helmet = require("helmet"); // إنشاء كائن تطبيق Express const app = express(); // إضافة حزمة helmet إلى سلسلة البرمجيات الوسيطة // ضبط ترويسات CSP للسماح بتخديم Bootstrap و Jquery app.use( helmet.contentSecurityPolicy({ directives: { "script-src": ["'self'", "code.jquery.com", "cdn.jsdelivr.net"], }, }), ); // … يمكن أن نضيف التابع app.use(helmet()); لإضافة مجموعة فرعية من الترويسات المتعلقة بالأمان والتي تكون منطقية لمعظم المواقع، ولكننا نضمّن بعض سكربتات بوتستراب bootstrap و jQuery في قالب موقع المكتبة المحلية LocalLibrary الأساسي، مما يؤدي إلى انتهاك سياسة أمان المحتوى Content Security Policy -أو CSP اختصارًا- الافتراضية الخاصة بحزمة helmet، والتي لا تسمح بتحميل السكربتات العابرة للمواقع. يمكن السماح بتحميل هذه السكربتات من خلال تعديل ضبط helmet بحيث تُضبَط موجّهات CSP للسماح بتحميل السكربت من النطاقات المُشار إليها، ويمكنك بالنسبة لخادمك إضافة أو تعطيل ترويسات محددة حسب الحاجة باتباع الإرشادات الخاصة باستخدام helmet. إضافة معدل محدود إلى وجهات واجهة برمجة التطبيقات API تُعَد Express-rate-limit حزمة برمجية وسيطة يمكن استخدامها للحد من الطلبات المتكررة لواجهات برمجة التطبيقات API والنقاط النهائية، فهناك العديد من الأسباب التي يمكن أن تؤدي إلى زيادة الطلبات على موقعك مثل هجمات حجب الخدمة أو هجمات القوة الغاشمة أو حتى مجرد عميل أو سكربت لا يتصرف كما هو متوقع، ويمكن أن تُحاسَب على حركة المرور الإضافية بغض النظر عن مشاكل الأداء التي يمكن أن تنشأ عن كثرة الطلبات التي تتسبب في إبطاء خادمك. يمكن استخدام حزمة Express-rate-limit للحد من عدد الطلبات التي يمكن إجراؤها على وجهة معينة أو مجموعة من الوِجهات. يمكنك الاطلاع على مقال الهجمات الأمنية Security Attacks في الشبكات الحاسوبية على أكاديمية حسوب لمزيد من المعلومات حول أنواع الهجمات الأمنية. ثبّت هذه الحزمة في جذر مشروعك من خلال تشغيل الأمر التالي: npm install express-rate-limit افتح الملف "./app.js" واطلب مكتبة express-rate-limit كما يلي، ثم ضِف الوحدة إلى سلسلة البرمجيات الوسيطة باستخدام التابع use(): const compression = require("compression"); const helmet = require("helmet"); const app = express(); // إعداد محدِّد المعدل إلى عشرين طلبًا في الدقيقة كحد أعلى const RateLimit = require("express-rate-limit"); const limiter = RateLimit({ windowMs: 1 * 60 * 1000, // 1 دقيقة max: 20, }); // طبّق محدّد المعدّل على جميع الطلبات app.use(limiter); // … ملاحظة: يحدّد الأمر السابق جميع الطلبات لتكون 20 طلبًا في الدقيقة، ولكن يمكنك تغييره حسب الحاجة. يمكن أيضًا استخدام خدمات خارجية مثل Cloudflare إذا كنت بحاجة إلى مزيد من الحماية المتقدمة ضد هجمات حجب الخدمة أو أنواع أخرى من الهجمات. تطبيق عملي: تثبيت موقع المكتبة المحلية LocalLibrary على منصة Railway يقدّم هذا القسم شرحًا عمليًا لكيفية تثبيت موقع المكتبة المحلية LocalLibrary على منصة Railway. سبب استخدام Railway اخترنا استخدام منصة Railway لعدة أسباب هي: تمتلك Railway مستوًى مجانيًا لخطة بداية مع بعض القيود، إذ من المهم أن تكون بأسعار مقبولة لجميع المطورين. تهتم Railway بمعظم البنية التحتية، فلا حاجة للقلق بشأن الخوادم وموازني الحِمل والوكلاء العكسيين وغير ذلك، مما يجعل البدء أسهل بكثير. تركّز Railway على تجربة المطور للتطوير والنشر، مما يؤدي إلى وجود منحنى تعليمي أسرع وأسلس من العديد من البدائل الأخرى. تُعَد المهارات والمفاهيم التي ستتعلمها عند استخدام Railway قابلة للتحويل، إذ تمتلك Railway بعض الميزات الجديدة الممتازة، ولكن تستخدم خدماتُ الاستضافة الشائعة الأخرى العديدَ من الأفكار والأساليب نفسها. لا تؤثر قيود الخدمات والخطط على استخدامنا لمنصة Railway في مثالنا، فمثلًا: تقدّم خطة البداية 500 ساعة فقط من وقت النشر المستمر كل شهر و5 دولارات من الرصيد الذي يُستهلَك بناءً على الاستخدام، ويُعاد ضبط الساعات والرصيد ويجب إعادة نشر المشاريع في نهاية كل شهر. تعني هذه القيود أنه يمكنك تشغيل هذا المثال بصورة مستمرة لمدة 21 يومًا تقريبًا، ويُعَد ذلك أكثر من كافٍ للتطوير والاختبار، ولكن لن تتمكّن من استخدام هذه الخطة لموقع حقيقي للإنتاج. تحتوي بيئة خطة البداية على 512 ميجابايت فقط من الذاكرة RAM و1 جيجابايت من ذاكرة التخزين، وهذا أكثر من كافٍ لمثالنا. لا توجد سوى منطقة واحدة مدعومة وهي الولايات المتحدة الأمريكية حاليًا، إذ يمكن أن تكون الخدمة خارج هذه المنطقة أبطأ أو تحظرها القوانين المحلية. يمكن العثور على قيود أخرى في توثيق خطط Railway للدفع. تبدو الخدمة موثوقة جدًا، وإذا كانت مناسبة لك، فإن الأسعار يمكن التنبؤ بها، ويكون توسيع تطبيقك سهلًا جدًا. تعَد Railway مناسبة لاستضافة مثالنا، ولكن يجب أن تأخذ الوقت الكافي لتحديد ما إذا كانت مناسبة لموقعك. كيفية عمل Railway يُشغَّل كل تطبيق ويب في حاوية افتراضية معزولة ومستقلة خاصة به، لذا يجب أن تكون Railway قادرة على إعداد البيئة والاعتماديات المناسبة، وفهم كيفية إطلاقها لتنفيذ تطبيقك. تجعل Railway هذا الأمر سهلًا، إذ يمكنها التعرف تلقائيًا على العديد من أطر عمل وبيئات تطبيقات الويب المختلفة وتثبيتها بناءً على استخدامها "للمصطلحات الشائعة"، فمثلًا تتعرّف Railway على تطبيقات Node لأن لديها ملف package.json، ويمكنها تحديد مدير الحزم المُستخدَم للبناء من ملف "القفل Lock". إذا احتوى التطبيق على ملف package-lock.json مثلًا، فستعرف Railway أنها ستستخدم مدير حزم npm لتثبيت الحزم، وإذا وجدت yarn.lock فستعرف أنها ستستخدم yarn. ستبحث Railway -بعد تثبيت جميع الاعتماديات- عن سكربتات بالاسم "build" و "start" في ملف الحزمة، وستستخدمها لبناء وتشغيل الشيفرة البرمجية. ملاحظة: تستخدم Railway حزمة Nixpacks للتعرف على العديد من أطر عمل تطبيقات الويب المكتوبة بلغات برمجة مختلفة. لا حاجة إلى معرفة أيّ شيء آخر لهذا المقال، ولكن يمكنك معرفة المزيد حول خيارات نشر تطبيقات Node في توثيق Nixpacks. يمكن للتطبيق بعد تشغيله ضبط نفسه باستخدام المعلومات المقدمة في متغيرات البيئة، فمثلًا يجب أن يحصل التطبيق الذي يستخدم قاعدة بيانات على العنوان باستخدام متغير، ويمكن أن تستضيف Railway خدمة قاعدة البيانات نفسها أو على أي مزوّد آخر. يتفاعل المطورون مع Railway من خلال موقع Railway وباستخدام أداة واجهة سطر أوامر CLI خاصة، إذ تسمح لك واجهة CLI بربط مستودع غيت هب GitHub محلي بمشروع Railway، ورفع المستودع من الفرع المحلي إلى الموقع المباشر، وفحص سجلات العملية الجارية، وإعداد متغيرات الضبط والحصول عليها وغير ذلك. من أهم الميزات أنه يمكنك استخدام واجهة CLI لتشغيل مشروعك المحلي مع متغيرات البيئة نفسها للمشروع المباشر. يجب وضع تطبيق Express الخاص بنا في مستودع غيت git وإجراء بعض التغييرات الطفيفة ليعمل تطبيقنا على Railway، ثم يمكننا إعداد حساب على Railway وتثبيت موقعنا وقاعدة البيانات وتجربة عميل Railway. وهذا هو كل ما تحتاجه من معلومات في البداية. إنشاء مستودع للتطبيق على غيت هب GitHub تتكامل Railway تكاملًا وثيقًا مع غيت هب ونظام التحكم في إصدارات الشيفرة المصدرية git، ويمكنك ضبطها لنشر التحديثات تلقائيًا عند إجراء تغييرات إلى مستودع أو فرع معين على غيت هب، أو يمكنك دفع فرع الشيفرة المحلية الحالي مباشرةً إلى النشر الخاص بمنصة Railway باستخدام واجهة CLI. ملاحظة: يُعَد استخدام نظام إدارة الشيفرة المصدرية مثل غيت هب ممارسة جيدة لتطوير البرمجيات، فإذا كنت تستخدم غيت هب لإدارة شيفرتك المصدرية مسبقًا، فتخطى هذه الخطوة. هناك العديد من الطرق للعمل مع git، ومن أسهلها إعداد حساب على غيت هب أولًا وإنشاء المستودع عليه، ثم المزامنة معه محليًا كما يلي: انتقل إلى موقع GitHub الرسمي وأنشئ حسابًا عليه. انقر على ارتباط + في شريط الأدوات العلوي وحدّد خيار "مستودع جديد New repository" بعد تسجيل الدخول. املأ جميع الحقول في هذه الاستمارة، إذ يمكن أن تكون هذه الحقول غير إلزامية، ولكن يُوصَى بها بشدة. أدخل اسم المستودع الجديد والوصف، فمثلًا يمكنك استخدام الاسم "express-locallibrary-tutorial" والوصف "Local Library website written in Express (Node)" (موقع المكتبة المحلية المكتوب باستخدام Express). اختر الخيار Node في قائمة الاختيار Add .gitignore. اختر الترخيص المفضل لديك في قائمة الاختيار Add license. تحقق من تهيئة المستودع باستخدام README. تحذير: سيجعل الوصول الافتراضي العام "Public" جميع الشيفرة البرمجية المصدرية -بما في ذلك اسم المستخدم وكلمة المرور لقاعدة البيانات- مرئيةً لأي شخص على الإنترنت، لذا تأكد من أن الشيفرة البرمجية المصدرية لا تقرأ اعتماديات إلّا من متغيرات البيئة ولا تحتوي على أيّ اعتماديات ثابتة، وإلّا حدد الخيار خاص "Private" للسماح فقط لأشخاص محدَّدين برؤية الشيفرة المصدرية. اضغط على إنشاء مستودع Create repository. انقر فوق الزر الأخضر نسخ Clone أو تنزيل Download في صفحة مستودعك الجديد. انسخ قيمة URL من حقل النص الموجود في مربع الحوار الذي يظهر، فإذا استخدمت اسم المستودع "express-locallibrary-tutorial"، فيجب أن يكون عنوان URL مثل العنوان: https://github.com/<your_git_user_id>/express-locallibrary-tutorial.git. انتهينا من إنشاء المستودع، ويجب الآن نسخه على حاسوبك المحلي باتباع الخطوات التالية: أولًا، ثبّت git على حاسوبك المحلي، إذ يمكنك العثور على نسخ لأنظمة مختلفة. ثانيًا، افتح موجه الأوامر أو الطرفية وانسخ مستودعك باستخدام عنوان URL الذي نسخته سابقًا كما في الأمر التالي: git clone https://github.com/<your_git_user_id>/express-locallibrary-tutorial.git سيؤدي هذا الأمر إلى إنشاء المستودع في المجلد الحالي. ثالثًا، انتقل إلى مجلد المستودع باستخدام الأمر التالي: cd express-locallibrary-tutorial أخيرًا، انسخ ملفات تطبيقك المصدرية في مجلد المستودع، ثم اجعلها جزءًا من المستودع باستخدام git كما يلي: أولًا، انسخ تطبيق Express إلى هذا المجلد باستثناء المجلد "/node_modules" الذي يحتوي على ملفات الاعتماديات التي يجب جلبها من مدير حزم npm حسب الحاجة. ثانيًا، افتح موجه الأوامر أو الطرفية واستخدم الأمر add لإضافة جميع الملفات إلى git كما يلي: git add -A ثالثًا، استخدم الأمر status للتحقق من صحة جميع الملفات التي تريد تثبيتها commit، إذ نريد تضمين الملفات المصدرية، وليس الملفات الثنائية والمؤقتة وما إلى ذلك، إذ يجب أن تبدو كما يلي: > git status ويكون الخرج الناتج بعد تنفيذ هذا الأمر على النحو التالي: On branch main Your branch is up-to-date with 'origin/main'. Changes to be committed: (use "git reset HEAD <file>..." to unstage) new file: … رابعًا، ثبّت باستخدام commit الملفات في مستودعك المحلي عندما تكون راضيًا عن النتيجة، إذ يكافئ ذلك الإقرار بالتغييرات وجعلها جزءًا رسميًا من المستودع المحلي. git commit -m "First version of application moved into GitHub" خامسًا، لم يتغيّر المستودع البعيد حتى الآن، لذا يجب مزامنة (باستخدام الأمر push) مستودعك المحلي مع مستودع GitHub البعيد باستخدام الأمر التالي: git push origin main يجب أن تكون قادرًا عند اكتمال هذه العملية على العودة إلى صفحة غيت حيث أنشأت مستودعك، وتحديث الصفحة، ويجب ملاحظة رفع كامل التطبيق. يمكنك الاستمرار في تحديث مستودعك مع تغير الملفات باستخدام دورة أوامر الإضافة add والتثبيت commit والدفع push. ملاحظة: يمكنك الآن إنشاء نسخة احتياطية من شيفرة مشروعك البرمجية، إذ يمكن أن تكون بعض التغييرات التي سنجريها في الأقسام التالية مفيدة للنشر (أو للتطوير) على أي خدمة استضافة، ويمكن أن تكون بعض التغييرات الأخرى غير مفيدة. أفضل طريقة لذلك هي استخدام git لإدارة الإصدارات، إذ يمكنك باستخدامه الرجوع إلى إصدار سابق معين، ويمكنك الاحتفاظ به في فرع منفصل عن التغييرات الإنتاجية واختيار أيّ تغييرات للتنقل بين فروع الإنتاج والتطوير. يستحق تعلم غيت Git الجهد المبذول، لذا اطلع على مجموعة مقالات Git في أكاديمية حسوب. يُعَد نسخ ملفاتك في موقع آخر الطريقة الأسهل، ولكن يمكنك استخدام أيّ طريقة تتناسب مع معرفتك لنظام git. تحديث التطبيق ليعمل على Railway سنشرح في هذا القسم التغييرات التي يجب إجراؤها على تطبيق المكتبة المحلية LocalLibrary ليعمل على Railway، ولكن لن تمنعك هذه التغييرات من استخدام الاختبار وسير العمل المحلي الذي تعلمناه مسبقًا. ضبط نسخة Node يحتوي الملف package.json على كل ما تحتاجه Railway للعمل على اعتماديات تطبيقك وتحديد الملف الواجب تشغيله لبدء تشغيل موقعك، ولكن المعلومات المهمة الوحيدة المفقودة من الملف package.json الحالي هي نسخة Node، إذ يمكنك العثور على نسخة Node التي نستخدمها للتطوير من خلال إدخال الأمر التالي: >node --version v16.17.1 افتح الملف package.json وأضِف المعلومات التالية في قسم engines > node (مع استخدام رقم النسخة في نظامك): { "name": "express-locallibrary-tutorial", "version": "0.0.0", "engines": { "node": ">=16.17.1" }, "private": true, // … لاحظ أن هناك طرقًا أخرى لتوفير نسخة Node على Railway، ولكننا نستخدم الملف package.json لأنه الأسلوب الذي تدعمه العديد من الخدمات على نطاق واسع. لاحظ أيضًا أن Railway لن تستخدم بالضرورة نسخة Node الدقيقة التي تحددها، إذ ستستخدم نسخةً لها رقم النسخة الرئيسي نفسه. الحصول على الاعتماديات وإعادة الاختبار لنختبر الموقع مرةً أخرى ونتأكد من أنه لم يتأثر بأيٍّ من التغييرات التي أجريناها. أولًا، يجب جلب الاعتماديات (تذكّر أننا لم ننسخ المجلد node_modules في شجرة git)، إذ يمكنك ذلك من خلال تشغيل الأمر التالي في طرفيتك ضمن جذر المشروع: npm install شغّل الموقع (اطّلع على فقرة اختبار الوجهات في مقال الوجهات والمتحكمات لمعرفة الأوامر ذات الصلة) وتحقق من أن الموقع لا يزال يتصرف كما هو متوقع. حفظ التغييرات على غيت هب GitHub احفظ الآن جميع التغييرات التي أجريتها على غيت هب، وأدخِل الأوامر التالية في الطرفية أثناء وجودك في مستودعك: git add -A git commit -m "Added files and changes required for deployment" git push origin main يجب أن نكون جاهزين الآن لبدء نشر موقع المكتبة المحلية LocalLibrary على Railway. الحصول على حساب على Railway يجب أولًا إنشاء حساب لبدء استخدام Railway باتباع الخطوات التالية: اذهب إلى موقع Railway الرسمي وانقر على ارتباط تسجيل الدخول Login في شريط الأدوات العلوي. اختر GitHub في النافذة المنبثقة لتسجيل الدخول باستخدام اعتماديات GitHub الخاصة بك. يمكن أن تحتاج بعد ذلك إلى الانتقال إلى بريدك الإلكتروني والتحقق من حسابك. ستسجل بعد ذلك الدخول إلى لوحة تحكم Railway. النشر على Railway من GitHub يجب الآن إعداد Railway لنشر موقع مكتبتنا من GitHub، لذا اختر أولًا خيار لوحة التحكم Dashboard من القائمة العلوية للموقع، ثم حدّد زر مشروع جديد New Project: ستعرض Railway قائمةً بالخيارات الخاصة بالمشروع الجديد، بما في ذلك خيار نشر مشروع من قالب أنشأته لأول مرة في حسابك على GitHub، وعددًا من قواعد البيانات، لذا حدد خيار النشر Deploy from GitHub repo. ستُعرَض جميع المشاريع في مستودعات GitHub التي شاركتها مع Railway أثناء عملية الإعداد، ولكنك ستختار مستودع GitHub الخاص بموقع المكتبة المحلية: <user-name>/express-locallibrary-tutorial. أكّد النشر من خلال تحديد خيار النشر حالًا Deploy Now. ستحمّل Railway بعد ذلك مشروعك وتنشره، مع عرض التقدم في نافذة عمليات النشر Deployments، ثم سترى شيئًا يشبه ما يلي عند اكتمال النشر بنجاح: اختر الآن نافذة الإعدادات Settings، ثم انتقل إلى الأسفل إلى قسم النطاقات Domains، واضغط على زر توليد نطاق Generate Domain. سيؤدي ذلك إلى نشر الموقع ووضع النطاق في مكان الزر كما هو موضح فيما يلي: حدّد عنوان URL للنطاق لفتح تطبيق المكتبة. لاحظ فتح موقع المكتبة المحلية باستخدام بيانات التطوير الخاصة بك لأننا لم نحدّد قاعدة بيانات الإنتاج. تجهيز وتوصيل قاعدة بيانات MongoDb لننشئ الآن قاعدة بيانات MongoDB الخاصة بالإنتاج لاستخدامها بدلًا من استخدام بيانات التطوير، إذ سننشئ قاعدة البيانات بوصفها جزءًا من مشروع تطبيق Railway، بالرغم من أنه لا يوجد ما يمنعك من إنشائها في مشروعها المنفصل أو استخدام قاعدة بيانات MongoDB Atlas لبيانات الإنتاج، كما فعلت مع قاعدة بيانات التطوير. حدّد الخيار Dashboard من قائمة الموقع العلوية على Railway ثم حدد مشروع تطبيقك، الذي يحتوي حاليًا على خدمة واحدة فقط لتطبيقك، والتي يمكن اختيارها لضبط المتغيرات وتفاصيل الخدمة الأخرى، ثم حدّد الزر جديد New، والذي يستخدم لإضافة خدمات إلى المشروع الحالي. حدد قاعدة البيانات Database عندما يُطلَب منك تحديد نوع الخدمة لإضافتها. حدّد بعد ذلك خيار الإضافة Add MongoDB لبدء إضافة قاعدة البيانات. ستجهز Railway بعد ذلك خدمةً تحتوي على قاعدة بيانات فارغة في المشروع نفسه، وسترى عند الانتهاء كلًا من التطبيق وخدمات قاعدة البيانات في عرض المشروع. حدّد خدمة MongoDB لعرض معلومات حول قاعدة البيانات، ثم افتح نافذة "الاتصال Connect" وانسخ "عنوان URL لاتصال Mongo"، وهو عنوان قاعدة البيانات. يمكن جعل تطبيق المكتبة يصل إلى هذا العنوان من خلال إضافته إلى عملية التطبيق باستخدام متغير بيئة، لذا افتح أولًا خدمة التطبيق، ثم حدّد نافذة المتغيرات Variables واضغط على زر متغير جديد New Variable. أدخِل اسم المتغير MONGODB_URI وعنوان URL للاتصال الذي نسخته لقاعدة البيانات، فالمتغير MONGODB_URI هو اسم متغير البيئة الذي ضبطنا التطبيق منه لقراءة عنوان قاعدة البيانات، وسيظهر لديك ما يلي: حدّد بعد ذلك زر الإضافة Add لإضافة المتغير. تعيد Railway تشغيل تطبيقك عندما تحدّث المتغيرات. إذا فحصتَ الصفحة الرئيسية الآن، فيجب أن تظهِر قيمًا صفرية لأعداد الكائنات، إذ تعني التغييرات السابقة أننا نستخدم الآن قاعدة بيانات جديدة (فارغة). متغيرات الضبط الأخرى تذكّر من القسم السابق أننا بحاجة إلى ضبط NODE_ENV على قيمة الإنتاج 'production' لتحسين الأداء وإنشاء رسائل خطأ أقل تفصيلًا، ويمكننا فعل ذلك في الشاشة نفسها التي ضبطنا منها المتغير MONGODB_URI. افتح خدمة التطبيق، ثم حدد نافذة المتغيرات Variables، إذ سترى أن المتغير MONGODB_URI مُعرَّف مسبقًا، واضغط على زر متغير جديد New Variable. أدخل NODE_ENV بوصفه اسم المتغير الجديد و production بوصفه اسم البيئة، ثم اضغط على زر الإضافة Add. ضُبِط وأُعِدّ تطبيق المكتبة المحلية للاستخدام في بيئة الإنتاج، ويمكنك إضافة البيانات عبر واجهة موقع الويب ويجب أن تعمل بالطريقة نفسها التي كانت تعمل بها أثناء عملية التطوير (مع وصول أقل إلى معلومات تنقيح الأخطاء للصفحات غير الصالحة). ملاحظة: إذا أدرتَ إضافة بعض البيانات للاختبار، فيمكنك استخدام السكربت populatedb مع عنوان URL لقاعدة بيانات MongoDB الخاصة بالإنتاج كما ناقشنا في مقال استخدام قاعدة البيانات باستخدام مكتبة Mongoose. تثبيت العميل نزّل وثبّت عميل Railway لنظام تشغيلك المحلي باتباع التعليمات الواردة في توثيق Railway. ستتمكن من تشغيل الأوامر بعد تثبيت العميل. تتضمن بعض العمليات الأكثر أهمية نشر المجلد الحالي لحاسوبك إلى مشروع Railway المرتبط به دون الحاجة للرفع على GitHub، وتشغيل مشروعك محليًا باستخدام الإعدادات نفسها الموجودة على خادم الإنتاج. يمكنك الحصول على قائمة بجميع الأوامر الممكنة من خلال إدخال الأمر التالي في الطرفية: railway help تنقيح الأخطاء Debugging يوفّر عميل Railway الأمر logs لإظهار السجلات الأخيرة (يتوفر سجل كامل على الموقع لكل مشروع): railway logs الخلاصة وصلنا إلى نهاية مقالنا حول إعداد تطبيقات Express في بيئة الإنتاج، وكذلك إلى نهاية سلسلة مقالات إطار عمل Express، لذا نأمل أنها كانت مفيدة لك، ولا تنسَ أنه يمكنك التحقق من النسخة الكاملة من الشيفرة المصدرية على GitHub. ترجمة -وبتصرُّف- للمقال Express Tutorial Part 7: Deploying to production. اقرأ المزيد المقال السابق تطبيق عملي لتعلم Express - الجزء الرابع: عرض بيانات المكتبة والعمل مع الاستمارات. مرحلة نشر التطبيق في عملية تطوير الويب. تطبيق عملي لتعلم جانغو - الجزء 10: نشر تطبيق جانغو في بيئة الإنتاج. -
 أصبحنا الآن جاهزين لإضافة الصفحات التي تعرض كتب موقع المكتبة المحلية LocalLibrary وبيانات أخرى، إذ ستتضمن هذه الصفحات صفحةً رئيسية توضح عدد السجلات لكل نوع نموذج Model وعددًا من صفحات القائمة والصفحات التفصيلية لجميع النماذج، وبالتالي سنكتسب خبرةً عملية في الحصول على السجلات من قاعدة البيانات واستخدام القوالب. سنشرح أيضًا في هذا المقال كيفية العمل مع استمارات HTML في إطار عمل Express باستخدام لغة القوالب Pug، إذ سنناقش كيفية كتابة استمارات لإنشاء المستندات وتحديثها وحذفها من قاعدة بيانات الموقع. المتطلبات الأساسية: إكمال المقالات السابقة من هذه السلسلة بما في ذلك مقال الوِجهات Routes والمتحكمات Controllers. الهدف: فهم كيفية إجراء عمليات قاعدة البيانات غير المتزامنة باستخدام async/await، واستخدام لغة القوالب Pug، والحصول على البيانات من عنوان URL في دوال المتحكمات، وكتابة الاستمارات للحصول على البيانات من المستخدمين وتحديث قاعدة البيانات باستخدام هذه البيانات. عرض بيانات المكتبة عرّفنا في المقالات السابقة نماذجَ Mongoose التي يمكننا استخدامها للتفاعل مع قاعدة بيانات وأنشأنا بعض سجلات المكتبة الأولية، ثم أنشأنا جميع الوِجهات Routes اللازمة لموقع المكتبة المحلية LocalLibrary، ولكن مع دوال متحكمات وهمية dummy، وهي دوال متحكمات هيكلية تعيد فقط رسالة "not implemented" عند الوصول إلى الصفحة. تتمثل الخطوة التالية في توفير عمليات تقديم مناسبة للصفحات التي تعرض معلومات المكتبة، إذ سنتعرّف على تقديم الصفحات التي تعرض استمارات لإنشاء المعلومات أو تحديثها أو حذفها، ويتضمن ذلك تحديث دوال المتحكمات لجلب السجلات باستخدام النماذج وتعريف القوالب لعرض هذه المعلومات للمستخدمين. سنبدأ بتقديم موضوعات عامة أو أولية توضح كيفية إدارة العمليات غير المتزامنة في دوال المتحكمات وكيفية كتابة القوالب باستخدام مكتبة القوالب Pug، ثم سنوفّر عمليات تقديم لكل صفحة من صفحاتنا الرئيسية المُعَدّة للقراءة فقط مع شرح موجز لأي ميزات خاصة أو جديدة تستخدمها، وبالتالي يجب أن يكون لديك فهم جيد وشامل لكيفية عمل الوجهات والدوال غير المتزامنة والعروض Views والنماذج عمليًا. تمر المواضيع التالية بعملية إضافة الميزات المختلفة المطلوبة لعرض صفحات الموقع المطلوبة، إذ يجب أن تطبّق كل قسم منها عمليًا قبل الانتقال إلى القسم التالي: مقدمة إلى القوالب Template، وإنشاء القالب الأساسي لموقع مكتبة محلية مثالًا. إنشاء الصفحة الرئيسية وصفحات القوائم لموقع المكتبة المحلية التي تتضمن: صفحة قائمة الكتب. صفحة قائمة نسخ الكتب BookInstance. تنسيق التاريخ باستخدام مكتبة Luxon. صفحة قائمة المؤلفين وتحدي صفحة قائمة أنواع الكتب. إنشاء صفحات التفاصيل لموقع المكتبة المحلية التي تتضمن: صفحة تفاصيل نوع الكتاب. صفحة تفاصيل الكتاب. صفحة تفاصيل المؤلف. صفحة تفاصيل نسخ الكتاب والتحدي. أنشأنا جميع الصفحات المُعَدّة للقراءة فقط الخاصة بموقعنا وهي: صفحة رئيسية تعرض عدد نسخ كلّ نموذج من نماذجنا، وصفحات قائمة وتفاصيل الكتب ونسخ الكتب والمؤلفين وأنواع الكتب، واكتسبنا الكثير من المعرفة الأساسية حول المتحكمات وإدارة التحكم في التدفق عند استخدام العمليات غير المتزامنة، وإنشاء عروض باستخدام مكتبة القوالب Pug، والاستعلام في قاعدة بيانات الموقع باستخدام النماذج، وتمرير المعلومات إلى العرض، وإنشاء القوالب وتوسيعها، وستعلّمك التحديات أيضًا عن معالجة التاريخ باستخدام مكتبة Luxon. سننشئ الآن استمارات HTML وشيفرة معالجة الاستمارات لبدء تعديل البيانات التي يخزنها الموقع. العمل مع الاستمارات استمارة HTML هي مجموعة مؤلفة من حقل أو عنصر واجهة مستخدم واحد أو أكثر على صفحة الويب، والتي يمكن استخدامها لجمع المعلومات من المستخدمين لإرسالها إلى الخادم، وتُعَد آليةً مرنة لتجميع مدخلات المستخدم نظرًا لوجود مدخلات مناسبة في الاستمارة التي تكون متاحة لإدخال العديد من أنواع البيانات المختلفة مثل مربعات النص ومربعات الاختيار وأزرار الاختيار ومنتقيات التاريخ وما إلى ذلك. تُعَد الاستمارات أيضًا طريقةً آمنة نسبيًا لمشاركة البيانات مع الخادم، لأنها تسمح بإرسال البيانات في طلبات POST مع الحماية من هجمات طلبات التزوير عبر المواقع. يمكن أن يكون التعامل مع الاستمارات معقدًا، إذ يحتاج المطورون إلى كتابة شيفرة HTML للاستمارة، والتحقق من صحة البيانات المُدخَلة وتطهيرها Sanitize بصورة صحيحة على الخادم وربما في المتصفح أيضًا، وإعادة نشر الاستمارة مع رسائل خطأ لإعلام المستخدمين بأي حقول غير صالحة، والتعامل مع البيانات عند إرسالها بنجاح، وأخيرًا الرد على المستخدم بطريقةٍ ما للإشارة إلى النجاح. سنوضح في هذا المقال كيفية تنفيذ هذه العمليات في إطار عمل Express، إذ سنوسّع موقع المكتبة المحلية LocalLibrary للسماح للمستخدمين بإنشاء عناصر وتعديلها وحذفها من المكتبة. ملاحظة: لم نتطرق إلى كيفية تقييد وجهات Routes معينة للمستخدمين المستوثقين أو المُصرَّح لهم، لذلك سيتمكن أيّ مستخدم من إجراء تغييرات على قاعدة البيانات. استمارات HTML اطّلع أولًا على نظرة عامة موجزة على استمارات HTML. ليكن لدينا استمارة HTML البسيطة التالية مع حقل نص واحد لإدخال اسم "الفريق" والتسمية Label المرتبطة به: تُعرَّف الاستمارات في لغة HTML بوصفها مجموعة من العناصر ضمن وسوم <form>…</form> التي تحتوي على عنصر إدخال input واحد على الأقل من النوع type="submit". <form action="/team_name_url/" method="post"> <label for="team_name">Enter name: </label> <input id="team_name" type="text" name="name_field" value="Default name for team." /> <input type="submit" value="OK" /> </form> ضمّنا في المثال السابق حقلًا نصيًا واحدًا فقط لإدخال اسم الفريق، ولكن يمكن أن تحتوي الاستمارة على أيّ عدد من عناصر الإدخال الأخرى والتسميات Labels المرتبطة بها. تعرّف السمة type الخاصة بالحقل نوع عنصر واجهة المستخدم الذي سيُعرَض، وتُستخدَم سمات الاسم name والمعرّف id الخاصة بالحقل لتعريف الحقل في شيفرة جافا سكريبت Javascript أو CSS أو HTML، بينما تعرّف السمة value القيمة الأولية للحقل عند عرضه لأول مرة. تُحدَّد تسمية الفريق المطابقة باستخدام الوسم label (مثل التسمية "Enter name" السابقة)، مع حقل for الذي يحتوي على قيمة معرّف id لحقل الإدخال input المرتبط به. يُعرَض حقل الإدخال submit بوصفه زرًا افتراضيًا، إذ يمكن للمستخدم الضغط عليه لرفع البيانات التي تحتويها عناصر الإدخال الأخرى إلى الخادم، وهي اسم الفريق team_name فقط في مثالنا. تعرّف سمات الاستمارة تابع HTTP وهو method المستخدَم لإرسال البيانات وهدف البيانات على الخادم (السمة action) كما يلي: action: هو المورد أو عنوان URL، إذ ستُرسَل البيانات للمعالجة عند إرسال الاستمارة. إن لم تُضبَط هذه السمة، أو ضُبِطت بوصفها سلسلة نصية فارغة، فستُرسَل الاستمارة إلى عنوان URL للصفحة الحالية. method: تابع HTTP المُستخدَم لإرسال البيانات: إما POST أو GET. يجب دائمًا استخدام تابع POST إذا أدّت البيانات إلى تغييرٍ في قاعدة بيانات الخادم، لأنه يسمح بمقاومة أكبر لهجمات طلبات التزوير عبر المواقع. يجب استخدام تابع GET فقط للاستمارات التي لا تغير بيانات المستخدم (مثل استمارة البحث)، ويوصَى به عندما تريد أن تكون قادرًا على وضع إشارة مرجعية على عنوان URL أو مشاركته. عملية معالجة الاستمارة تستخدم معالجة الاستمارة الأساليب نفسها التي تعلمناها لعرض معلومات النماذج Models، إذ ترسِل الوِجهة طلبنا إلى دالة متحكم تطبّق أيّ إجراءات قاعدة بيانات مطلوبة بما في ذلك قراءة البيانات من النماذج، ثم تولّد صفحة HTML وتعيدها، ولكن ما يعقّد الأمور هو أن الخادم يحتاج أيضًا إلى أن يكون قادرًا على معالجة البيانات التي يقدّمها المستخدم، وإعادة عرض الاستمارة مع معلومات الخطأ عند وجود مشاكل. يوضّح المخطط التالي عملية معالجة طلبات الاستمارة، بدءًا من طلب الصفحة التي تحتوي على استمارة (كما هو موضّح باللون الأخضر): الأشياء الرئيسية التي يجب أن تطبقها شيفرة معالجة الاستمارة هي: عرض الاستمارة الافتراضية في المرة الأولى التي يطلبها المستخدم. يمكن أن تحتوي الاستمارة على حقول فارغة (إذا أنشأتَ سجلًا جديدًا مثلًا)، أو يمكن ملؤها مسبقًا بالقيم الأولية (إذا غيّرتَ سجلًا أو كان لديك قيم أولية افتراضية مفيدة مثلًا). تلقي البيانات التي يرسلها المستخدم في طلب HTTP من النوع POST مثلًا. التحقق من صحة البيانات وتطهيرها. إذا كان هناك بيانات غير صالحة، فأعِد عرض الاستمارة مع أيّ قيم يملأها المستخدم ورسائل خطأ للحقول التي تحتوي على مشاكل. إذا كانت جميع البيانات صالحة، فطبّق الإجراءات المطلوبة، مثل حفظ البيانات في قاعدة البيانات وإرسال إشعار بالبريد الإلكتروني وإعادة نتيجة البحث وتحميل ملف وإلخ. إعادة توجيه المستخدم إلى صفحة أخرى بعد اكتمال جميع الإجراءات. تُقدَّم شيفرة معالجة الاستمارة غالبًا باستخدام وِجهة GET للعرض الأولي للاستمارة ووجهة POST إلى المسار نفسه للتعامل مع التحقق من صحة بيانات الاستمارة ومعالجتها، إذ سنستخدم هذا الأسلوب في هذا المقال. لا يوفّر إطار عمل Express أيّ دعم لعمليات معالجة الاستمارة، ولكن يمكنه استخدام البرمجيات الوسيطة لمعالجة معاملات POST و GET من الاستمارة وللتحقق من صحة أو تطهير قيمها. التحقق من صحة البيانات وتطهيرها يجب التحقق من صحة البيانات الواردة من النموذج وتطهيرها قبل تخزينها كما يلي: تتحقق عملية التحقق من صحة البيانات Validation من أن القيم المُدخَلة مناسبة لكل حقل، أي أنها ضمن المجال الصحيح والتنسيق الصحيح وإلخ وأن هذه القيم متوفرة لجميع الحقول المطلوبة. تزيل أو تستبدل عملية التطهير Sanitization المحارف الموجودة في البيانات التي يمكن أن تُستخدَم لإرسال محتوًى ضار إلى الخادم. سنستخدم في هذا المقال الوحدة express-validator الشائعة لإجراء كلٍّ من التحقق من صحة بيانات الاستمارة وتطهيرها، إذ يمكننا ثثبيتها من خلال تشغيل الأمر التالي في جذر المشروع: npm install express-validator ملاحظة: يوفر دليل وحدة express-validator على غيت هب GitHub نظرة عامة جيدة على واجهة برمجة التطبيقات، لذا نوصيك بقراءته للحصول على فكرة عن جميع إمكانياتها بما في ذلك استخدام التحقق من صحة المخطط Schema Validation وإنشاء أدوات تحقق مخصصة، إذ سنشرح فيما يلي فقط جزءًا مفيدًا لموقع المكتبة المحلية. يمكن استخدام أداة التحقق من صحة البيانات Validator في المتحكمات من خلال تحديد الدوال التي نريد استيرادها من وحدة express-validator كما يلي: const { body, validationResult } = require("express-validator"); هناك العديد من الدوال المتاحة، مما يسمح بفحص وتطهير البيانات الواردة من معاملات الطلب وجسمه وترويساته وملفات تعريف الارتباط cookies وغير ذلك أو جميعها معًا في وقت واحد، إذ سنستخدم في هذا المقال body و validationResult (كما هو مطلوب سابقًا). تُعرَّف الدوال على النحو التالي: أولًا، body([fields, message]) التي تحدّد مجموعة من الحقول في متن الطلب (معامل POST) للتحقق من صحة البيانات و/أو تطهيرها مع رسالة خطأ اختيارية يمكن عرضها إذا فشلت الاختبارات. تتمثل معايير التحقق من صحة البيانات وتطهيرها بسلسلة متعاقبة في تابع body()، فمثلًا يحدّد السطر التالي أولًا أننا نتحقق من حقل "الاسم name" وأن خطأ التحقق من صحة البيانات سيضبط رسالة الخطأ "اسم فارغ Empty name"، ثم نستدعي تابع التطهير trim() لإزالة المسافة من بداية السلسلة ونهايتها، ثم isLength() للتحقق من أن السلسلة النصية الناتجة ليست فارغة. أخيرًا، نستدعي escape() لإزالة محارف HTML من المتغير الذي يمكن استخدامه في هجمات كتابة سكربتات جافا سكربت العابرة للمواقع. [ // … body("name", "Empty name").trim().isLength({ min: 1 }).escape(), // … ]; يتحقق الاختبار التالي من أن حقل العمر age هو تاريخ صالح ويستخدم optional() لتحديد أن السلاسل النصية الخالية والفارغة لن تفشل في التحقق من صحة البيانات. [ // … body("age", "Invalid age") .optional({ values: "falsy" }) .isISO8601() .toDate(), // … ]; يمكنك أيضًا استخدام سلسلة متعاقبة لأدوات التحقق من صحة البيانات المختلفة وإضافة الرسائل التي تُعرَض إذا كانت أدوات التحقق السابقة صحيحة. [ // … body("name") .trim() .isLength({ min: 1 }) .withMessage("Name empty.") .isAlpha() .withMessage("Name must be alphabet letters."), // … ]; ثانيًا، الدالة validationResult(req) التي تشغّل عملية التحقق من صحة البيانات، وتتيح الأخطاء بصيغة كائن النتيجة validation، وتستدعَى في دالة رد نداء منفصلة كما هو موضح فيما يلي: asyncHandler(async (req, res, next) => { // استخراج رسائل التحقق من صحة البيانات من الطلب const errors = validationResult(req); if (!errors.isEmpty()) { // هناك أخطاء، لذا اعرض الاستمارة مرة أخرى مع القيم المُطهَّرة أو رسائل الأخطاء // يمكن إعادة رسائل الخطأ في مصفوفة باستخدام errors.array() } else { // البيانات الواردة من الاستمارة صالحة } }); نستخدم التابع isEmpty() الخاص بنتيجة التحقق من صحة البيانات للتحقق مما إذا كان هناك أخطاء، والتابع array() للحصول على مجموعة رسائل الخطأ (اطلع على قسم معالجة التحقق من صحة البيانات للحصول على مزيد من المعلومات). تُعَد سلاسل التحقق من صحة البيانات وتطهيرها برمجيات وسيطة يجب تمريرها إلى معالج وجهة Express، إذ نطبّق ذلك بطريقة غير مباشرة باستخدام المتحكم، وتعمل أدوات التحقق من صحة البيانات وتطهيرها بالترتيب المُحدَّد عند تشغيل البرمجية الوسيطة. سنغطي بعض الأمثلة الحقيقية عندما نطبق استمارات موقع المكتبة المحلية LocalLibrary. تصميم الاستمارة ترتبط أو تعتمد العديد من النماذج في المكتبة على بعضها بعضًا، إذ يتطلب الكتاب Book مؤلفًا Author ويمكن أن يكون له نوع Genre واحد أو أكثر، مما يؤدي إلى التساؤل حول كيفية التعامل مع الحالة التي يرغب فيها المستخدم في: إنشاء كائن عندما لا تكون الكائنات المرتبطة به موجودةً بعد، مثل كتاب لم يُعرَّف كائن المؤلف فيه. حذف كائن لا يزال كائن آخر يستخدمه مثل حذف كائن النوع Genre الذي لا يزال كائن الكتاب Book يستخدمه. سنبسّط العمل في هذا المشروع بالقول إن الاستمارة يمكنها فقط: إنشاء كائن يستخدم كائنات موجودة فعليًا، لذلك يجب على المستخدمين إنشاء النسخ المطلوبة من المؤلف Author ونوع الكتاب Genre قبل محاولة إنشاء أي كائنات Book. حذف كائن إن لم تشِر إليه كائنات أخرى، فمثلًا لن تتمكّن من حذف كتاب Book حتى حذف جميع كائنات BookInstance المرتبطة به. ملاحظة: يمكن أن يسمح لك التقديم الأكثر مرونة بإنشاء كائنات معتمدة على بعضها البعض عند إنشاء كائن جديد، وحذف أيّ كائن في أي وقت من خلال حذف الكائنات المعتمدة عليه أو إزالة المراجع التي تشير إلى الكائن المحذوف من قاعدة البيانات مثلًا. الوجهات Routes سنحتاج إلى وجهتين لهما نمط عنوان URL نفسه لتقديم شيفرة معالجة الاستمارة، إذ تُستخدَم الوجهة الأولى GET لعرض استمارة فارغة جديدة لإنشاء الكائن، وتُستخدَم الوجهة الثانية (POST) للتحقق من صحة البيانات التي أدخلها المستخدم، ثم حفظ المعلومات وإعادة التوجيه إلى صفحة التفاصيل (إذا كانت البيانات صالحة) أو إعادة عرض الاستمارة مع وجود أخطاء (إذا كانت البيانات غير صالحة). أنشأنا الوجهات مسبقًا لجميع صفحات إنشاء النموذج في الملف "/routes/catalog.js" مثل وجهات نوع الكتب التالية: // طلب GET لإنشاء نوع كتاب Genre، إذ يجب أن يأتي قبل الوجهة التي تعرض نوع الكتاب (تستخدم المعرّف id) router.get("/genre/create", genre_controller.genre_create_get); // طلب POST لإنشاء نوع كتاب router.post("/genre/create", genre_controller.genre_create_post); توضّح المواضيع التالية عملية إضافة الاستمارات المطلوبة إلى تطبيقنا، إذ يجب العمل على كل منها ثم الانتقال إلى الموضوع التالي: إنشاء استمارة نوع الكتاب Genre: تعريف صفحة لإنشاء كائنات Genre. إنشاء استمارة المؤلف Author واستمارة الكتاب Book واستمارة نسخة الكتاب BookInstance: تعريف صفحة لإنشاء كائنات Author وتعريف صفحة أو استمارة لإنشاء كائنات Book وتعريف صفحة أو استمارة لإنشاء كائنات BookInstance. حذف استمارة المؤلف Author وتحديث استمارة الكتاب Book: تعريف صفحة لحذف كائنات Author وتعريف صفحة لتحديث كائنات Book. تحدى نفسك طبّق صفحات الحذف لنماذج Book و BookInstance و Genre واربطها بصفحات التفاصيل المتعلقة بها باستخدام الطريقة نفسها لصفحة حذف المؤلف، ويجب أن تتبع الصفحات أسلوب التصميم نفسه بحيث: إذا كان هناك مراجع إلى كائن من كائنات أخرى، فيجب عرض هذه الكائنات الأخرى مع ملاحظة أنه لا يمكن حذف هذا السجل حتى حذف الكائنات. إن لم يكن هناك مراجع أخرى إلى الكائن، فيجب أن يطالب العرض بحذفه، وإذا ضغط المستخدم على زر الحذف، فيجب حذف السجل. إليك بعض النصائح لتطبيقها: يشبه حذفُ الكائن Genre حذفَ الكائن Author تمامًا، فكلا الكائنين يعتمد عليهما الكائن Book، لذلك لا يمكنك حذف الكائن إلّا عند حذف الكتب المرتبطة به في كلتا الحالتين. يحدث الشيء نفسه عند حذف الكائن Book أيضًا، إذ يجب التحقق أولًا من عدم وجود كائنات BookInstance مرتبطة به. يُعَد حذف الكائن BookInstance أسهل ما في الأمر لأنه لا توجد كائنات معتمدة عليه، إذ يمكنك في هذه الحالة العثور على السجل وحذفه. طبّق صفحات التحديث لنماذج BookInstance و Author و Genre، واربطها بصفحات التفاصيل المرتبطة بها بالطريقة نفسها لصفحة تحديث الكتاب. واتبع أيضًا النصائح التالية: تُعَد صفحة تحديث الكتاب التي طبّقناها للتو هي الأصعب، ويمكن استخدام الأنماط نفسها لصفحات التحديث للكائنات الأخرى. يُعَد حقل تاريخ وفاة المؤلف Author وتاريخ ميلاده وحقل تاريخ استرجاع نسخة الكتاب BookInstance تنسيقًا خاطئًا لإدخاله في حقل إدخال التاريخ في الاستمارة، إذ يتطلب بياناتٍ في الاستمارة بالتنسيق: "YYYY-MM-DD". أسهل طريقة للتغلب على ذلك هي تعريف خاصية افتراضية جديدة للتواريخ التي تنسّق التواريخ بصورة مناسبة، ثم استخدام هذا الحقل في قوالب العرض المرتبطة به. إذا واجهتك مشكلة، فهناك أمثلة لصفحات التحديث يمكنك الاطلاع عليها. الخلاصة توفّر حزم Express و node والحزم الخارجية لمدير حزم npm كل ما تحتاجه لإضافة استمارات إلى موقع الويب، إذ تعلمت في هذا المقال كيفية إنشاء استمارات باستخدام Pug والتحقق من صحة بيانات الإدخال وتطهيرها باستخدام express-validator وإضافة السجلات وحذفها وتعديلها في قاعدة البيانات، ويجب أن تفهم الآن كيفية إضافة الاستمارات الأساسية وشيفرة معالجة الاستمارات إلى مواقع Node الخاصة بك. ترجمة -وبتصرُّف- للمقالين Express Tutorial Part 5: Displaying library data و Express Tutorial Part 6: Working with forms. اقرأ أيضًا المقال السابق تطبيق عملي لتعلم Express - الجزء الثالث: الوجهات Routes والمتحكمات Controllers. الاستمارات (forms) في متصفح الويب وكيفية التعامل معها في جافاسكربت. اإرسال الاستمارات (form submit) ومعالجتها في جافاسكربت.
أصبحنا الآن جاهزين لإضافة الصفحات التي تعرض كتب موقع المكتبة المحلية LocalLibrary وبيانات أخرى، إذ ستتضمن هذه الصفحات صفحةً رئيسية توضح عدد السجلات لكل نوع نموذج Model وعددًا من صفحات القائمة والصفحات التفصيلية لجميع النماذج، وبالتالي سنكتسب خبرةً عملية في الحصول على السجلات من قاعدة البيانات واستخدام القوالب. سنشرح أيضًا في هذا المقال كيفية العمل مع استمارات HTML في إطار عمل Express باستخدام لغة القوالب Pug، إذ سنناقش كيفية كتابة استمارات لإنشاء المستندات وتحديثها وحذفها من قاعدة بيانات الموقع. المتطلبات الأساسية: إكمال المقالات السابقة من هذه السلسلة بما في ذلك مقال الوِجهات Routes والمتحكمات Controllers. الهدف: فهم كيفية إجراء عمليات قاعدة البيانات غير المتزامنة باستخدام async/await، واستخدام لغة القوالب Pug، والحصول على البيانات من عنوان URL في دوال المتحكمات، وكتابة الاستمارات للحصول على البيانات من المستخدمين وتحديث قاعدة البيانات باستخدام هذه البيانات. عرض بيانات المكتبة عرّفنا في المقالات السابقة نماذجَ Mongoose التي يمكننا استخدامها للتفاعل مع قاعدة بيانات وأنشأنا بعض سجلات المكتبة الأولية، ثم أنشأنا جميع الوِجهات Routes اللازمة لموقع المكتبة المحلية LocalLibrary، ولكن مع دوال متحكمات وهمية dummy، وهي دوال متحكمات هيكلية تعيد فقط رسالة "not implemented" عند الوصول إلى الصفحة. تتمثل الخطوة التالية في توفير عمليات تقديم مناسبة للصفحات التي تعرض معلومات المكتبة، إذ سنتعرّف على تقديم الصفحات التي تعرض استمارات لإنشاء المعلومات أو تحديثها أو حذفها، ويتضمن ذلك تحديث دوال المتحكمات لجلب السجلات باستخدام النماذج وتعريف القوالب لعرض هذه المعلومات للمستخدمين. سنبدأ بتقديم موضوعات عامة أو أولية توضح كيفية إدارة العمليات غير المتزامنة في دوال المتحكمات وكيفية كتابة القوالب باستخدام مكتبة القوالب Pug، ثم سنوفّر عمليات تقديم لكل صفحة من صفحاتنا الرئيسية المُعَدّة للقراءة فقط مع شرح موجز لأي ميزات خاصة أو جديدة تستخدمها، وبالتالي يجب أن يكون لديك فهم جيد وشامل لكيفية عمل الوجهات والدوال غير المتزامنة والعروض Views والنماذج عمليًا. تمر المواضيع التالية بعملية إضافة الميزات المختلفة المطلوبة لعرض صفحات الموقع المطلوبة، إذ يجب أن تطبّق كل قسم منها عمليًا قبل الانتقال إلى القسم التالي: مقدمة إلى القوالب Template، وإنشاء القالب الأساسي لموقع مكتبة محلية مثالًا. إنشاء الصفحة الرئيسية وصفحات القوائم لموقع المكتبة المحلية التي تتضمن: صفحة قائمة الكتب. صفحة قائمة نسخ الكتب BookInstance. تنسيق التاريخ باستخدام مكتبة Luxon. صفحة قائمة المؤلفين وتحدي صفحة قائمة أنواع الكتب. إنشاء صفحات التفاصيل لموقع المكتبة المحلية التي تتضمن: صفحة تفاصيل نوع الكتاب. صفحة تفاصيل الكتاب. صفحة تفاصيل المؤلف. صفحة تفاصيل نسخ الكتاب والتحدي. أنشأنا جميع الصفحات المُعَدّة للقراءة فقط الخاصة بموقعنا وهي: صفحة رئيسية تعرض عدد نسخ كلّ نموذج من نماذجنا، وصفحات قائمة وتفاصيل الكتب ونسخ الكتب والمؤلفين وأنواع الكتب، واكتسبنا الكثير من المعرفة الأساسية حول المتحكمات وإدارة التحكم في التدفق عند استخدام العمليات غير المتزامنة، وإنشاء عروض باستخدام مكتبة القوالب Pug، والاستعلام في قاعدة بيانات الموقع باستخدام النماذج، وتمرير المعلومات إلى العرض، وإنشاء القوالب وتوسيعها، وستعلّمك التحديات أيضًا عن معالجة التاريخ باستخدام مكتبة Luxon. سننشئ الآن استمارات HTML وشيفرة معالجة الاستمارات لبدء تعديل البيانات التي يخزنها الموقع. العمل مع الاستمارات استمارة HTML هي مجموعة مؤلفة من حقل أو عنصر واجهة مستخدم واحد أو أكثر على صفحة الويب، والتي يمكن استخدامها لجمع المعلومات من المستخدمين لإرسالها إلى الخادم، وتُعَد آليةً مرنة لتجميع مدخلات المستخدم نظرًا لوجود مدخلات مناسبة في الاستمارة التي تكون متاحة لإدخال العديد من أنواع البيانات المختلفة مثل مربعات النص ومربعات الاختيار وأزرار الاختيار ومنتقيات التاريخ وما إلى ذلك. تُعَد الاستمارات أيضًا طريقةً آمنة نسبيًا لمشاركة البيانات مع الخادم، لأنها تسمح بإرسال البيانات في طلبات POST مع الحماية من هجمات طلبات التزوير عبر المواقع. يمكن أن يكون التعامل مع الاستمارات معقدًا، إذ يحتاج المطورون إلى كتابة شيفرة HTML للاستمارة، والتحقق من صحة البيانات المُدخَلة وتطهيرها Sanitize بصورة صحيحة على الخادم وربما في المتصفح أيضًا، وإعادة نشر الاستمارة مع رسائل خطأ لإعلام المستخدمين بأي حقول غير صالحة، والتعامل مع البيانات عند إرسالها بنجاح، وأخيرًا الرد على المستخدم بطريقةٍ ما للإشارة إلى النجاح. سنوضح في هذا المقال كيفية تنفيذ هذه العمليات في إطار عمل Express، إذ سنوسّع موقع المكتبة المحلية LocalLibrary للسماح للمستخدمين بإنشاء عناصر وتعديلها وحذفها من المكتبة. ملاحظة: لم نتطرق إلى كيفية تقييد وجهات Routes معينة للمستخدمين المستوثقين أو المُصرَّح لهم، لذلك سيتمكن أيّ مستخدم من إجراء تغييرات على قاعدة البيانات. استمارات HTML اطّلع أولًا على نظرة عامة موجزة على استمارات HTML. ليكن لدينا استمارة HTML البسيطة التالية مع حقل نص واحد لإدخال اسم "الفريق" والتسمية Label المرتبطة به: تُعرَّف الاستمارات في لغة HTML بوصفها مجموعة من العناصر ضمن وسوم <form>…</form> التي تحتوي على عنصر إدخال input واحد على الأقل من النوع type="submit". <form action="/team_name_url/" method="post"> <label for="team_name">Enter name: </label> <input id="team_name" type="text" name="name_field" value="Default name for team." /> <input type="submit" value="OK" /> </form> ضمّنا في المثال السابق حقلًا نصيًا واحدًا فقط لإدخال اسم الفريق، ولكن يمكن أن تحتوي الاستمارة على أيّ عدد من عناصر الإدخال الأخرى والتسميات Labels المرتبطة بها. تعرّف السمة type الخاصة بالحقل نوع عنصر واجهة المستخدم الذي سيُعرَض، وتُستخدَم سمات الاسم name والمعرّف id الخاصة بالحقل لتعريف الحقل في شيفرة جافا سكريبت Javascript أو CSS أو HTML، بينما تعرّف السمة value القيمة الأولية للحقل عند عرضه لأول مرة. تُحدَّد تسمية الفريق المطابقة باستخدام الوسم label (مثل التسمية "Enter name" السابقة)، مع حقل for الذي يحتوي على قيمة معرّف id لحقل الإدخال input المرتبط به. يُعرَض حقل الإدخال submit بوصفه زرًا افتراضيًا، إذ يمكن للمستخدم الضغط عليه لرفع البيانات التي تحتويها عناصر الإدخال الأخرى إلى الخادم، وهي اسم الفريق team_name فقط في مثالنا. تعرّف سمات الاستمارة تابع HTTP وهو method المستخدَم لإرسال البيانات وهدف البيانات على الخادم (السمة action) كما يلي: action: هو المورد أو عنوان URL، إذ ستُرسَل البيانات للمعالجة عند إرسال الاستمارة. إن لم تُضبَط هذه السمة، أو ضُبِطت بوصفها سلسلة نصية فارغة، فستُرسَل الاستمارة إلى عنوان URL للصفحة الحالية. method: تابع HTTP المُستخدَم لإرسال البيانات: إما POST أو GET. يجب دائمًا استخدام تابع POST إذا أدّت البيانات إلى تغييرٍ في قاعدة بيانات الخادم، لأنه يسمح بمقاومة أكبر لهجمات طلبات التزوير عبر المواقع. يجب استخدام تابع GET فقط للاستمارات التي لا تغير بيانات المستخدم (مثل استمارة البحث)، ويوصَى به عندما تريد أن تكون قادرًا على وضع إشارة مرجعية على عنوان URL أو مشاركته. عملية معالجة الاستمارة تستخدم معالجة الاستمارة الأساليب نفسها التي تعلمناها لعرض معلومات النماذج Models، إذ ترسِل الوِجهة طلبنا إلى دالة متحكم تطبّق أيّ إجراءات قاعدة بيانات مطلوبة بما في ذلك قراءة البيانات من النماذج، ثم تولّد صفحة HTML وتعيدها، ولكن ما يعقّد الأمور هو أن الخادم يحتاج أيضًا إلى أن يكون قادرًا على معالجة البيانات التي يقدّمها المستخدم، وإعادة عرض الاستمارة مع معلومات الخطأ عند وجود مشاكل. يوضّح المخطط التالي عملية معالجة طلبات الاستمارة، بدءًا من طلب الصفحة التي تحتوي على استمارة (كما هو موضّح باللون الأخضر): الأشياء الرئيسية التي يجب أن تطبقها شيفرة معالجة الاستمارة هي: عرض الاستمارة الافتراضية في المرة الأولى التي يطلبها المستخدم. يمكن أن تحتوي الاستمارة على حقول فارغة (إذا أنشأتَ سجلًا جديدًا مثلًا)، أو يمكن ملؤها مسبقًا بالقيم الأولية (إذا غيّرتَ سجلًا أو كان لديك قيم أولية افتراضية مفيدة مثلًا). تلقي البيانات التي يرسلها المستخدم في طلب HTTP من النوع POST مثلًا. التحقق من صحة البيانات وتطهيرها. إذا كان هناك بيانات غير صالحة، فأعِد عرض الاستمارة مع أيّ قيم يملأها المستخدم ورسائل خطأ للحقول التي تحتوي على مشاكل. إذا كانت جميع البيانات صالحة، فطبّق الإجراءات المطلوبة، مثل حفظ البيانات في قاعدة البيانات وإرسال إشعار بالبريد الإلكتروني وإعادة نتيجة البحث وتحميل ملف وإلخ. إعادة توجيه المستخدم إلى صفحة أخرى بعد اكتمال جميع الإجراءات. تُقدَّم شيفرة معالجة الاستمارة غالبًا باستخدام وِجهة GET للعرض الأولي للاستمارة ووجهة POST إلى المسار نفسه للتعامل مع التحقق من صحة بيانات الاستمارة ومعالجتها، إذ سنستخدم هذا الأسلوب في هذا المقال. لا يوفّر إطار عمل Express أيّ دعم لعمليات معالجة الاستمارة، ولكن يمكنه استخدام البرمجيات الوسيطة لمعالجة معاملات POST و GET من الاستمارة وللتحقق من صحة أو تطهير قيمها. التحقق من صحة البيانات وتطهيرها يجب التحقق من صحة البيانات الواردة من النموذج وتطهيرها قبل تخزينها كما يلي: تتحقق عملية التحقق من صحة البيانات Validation من أن القيم المُدخَلة مناسبة لكل حقل، أي أنها ضمن المجال الصحيح والتنسيق الصحيح وإلخ وأن هذه القيم متوفرة لجميع الحقول المطلوبة. تزيل أو تستبدل عملية التطهير Sanitization المحارف الموجودة في البيانات التي يمكن أن تُستخدَم لإرسال محتوًى ضار إلى الخادم. سنستخدم في هذا المقال الوحدة express-validator الشائعة لإجراء كلٍّ من التحقق من صحة بيانات الاستمارة وتطهيرها، إذ يمكننا ثثبيتها من خلال تشغيل الأمر التالي في جذر المشروع: npm install express-validator ملاحظة: يوفر دليل وحدة express-validator على غيت هب GitHub نظرة عامة جيدة على واجهة برمجة التطبيقات، لذا نوصيك بقراءته للحصول على فكرة عن جميع إمكانياتها بما في ذلك استخدام التحقق من صحة المخطط Schema Validation وإنشاء أدوات تحقق مخصصة، إذ سنشرح فيما يلي فقط جزءًا مفيدًا لموقع المكتبة المحلية. يمكن استخدام أداة التحقق من صحة البيانات Validator في المتحكمات من خلال تحديد الدوال التي نريد استيرادها من وحدة express-validator كما يلي: const { body, validationResult } = require("express-validator"); هناك العديد من الدوال المتاحة، مما يسمح بفحص وتطهير البيانات الواردة من معاملات الطلب وجسمه وترويساته وملفات تعريف الارتباط cookies وغير ذلك أو جميعها معًا في وقت واحد، إذ سنستخدم في هذا المقال body و validationResult (كما هو مطلوب سابقًا). تُعرَّف الدوال على النحو التالي: أولًا، body([fields, message]) التي تحدّد مجموعة من الحقول في متن الطلب (معامل POST) للتحقق من صحة البيانات و/أو تطهيرها مع رسالة خطأ اختيارية يمكن عرضها إذا فشلت الاختبارات. تتمثل معايير التحقق من صحة البيانات وتطهيرها بسلسلة متعاقبة في تابع body()، فمثلًا يحدّد السطر التالي أولًا أننا نتحقق من حقل "الاسم name" وأن خطأ التحقق من صحة البيانات سيضبط رسالة الخطأ "اسم فارغ Empty name"، ثم نستدعي تابع التطهير trim() لإزالة المسافة من بداية السلسلة ونهايتها، ثم isLength() للتحقق من أن السلسلة النصية الناتجة ليست فارغة. أخيرًا، نستدعي escape() لإزالة محارف HTML من المتغير الذي يمكن استخدامه في هجمات كتابة سكربتات جافا سكربت العابرة للمواقع. [ // … body("name", "Empty name").trim().isLength({ min: 1 }).escape(), // … ]; يتحقق الاختبار التالي من أن حقل العمر age هو تاريخ صالح ويستخدم optional() لتحديد أن السلاسل النصية الخالية والفارغة لن تفشل في التحقق من صحة البيانات. [ // … body("age", "Invalid age") .optional({ values: "falsy" }) .isISO8601() .toDate(), // … ]; يمكنك أيضًا استخدام سلسلة متعاقبة لأدوات التحقق من صحة البيانات المختلفة وإضافة الرسائل التي تُعرَض إذا كانت أدوات التحقق السابقة صحيحة. [ // … body("name") .trim() .isLength({ min: 1 }) .withMessage("Name empty.") .isAlpha() .withMessage("Name must be alphabet letters."), // … ]; ثانيًا، الدالة validationResult(req) التي تشغّل عملية التحقق من صحة البيانات، وتتيح الأخطاء بصيغة كائن النتيجة validation، وتستدعَى في دالة رد نداء منفصلة كما هو موضح فيما يلي: asyncHandler(async (req, res, next) => { // استخراج رسائل التحقق من صحة البيانات من الطلب const errors = validationResult(req); if (!errors.isEmpty()) { // هناك أخطاء، لذا اعرض الاستمارة مرة أخرى مع القيم المُطهَّرة أو رسائل الأخطاء // يمكن إعادة رسائل الخطأ في مصفوفة باستخدام errors.array() } else { // البيانات الواردة من الاستمارة صالحة } }); نستخدم التابع isEmpty() الخاص بنتيجة التحقق من صحة البيانات للتحقق مما إذا كان هناك أخطاء، والتابع array() للحصول على مجموعة رسائل الخطأ (اطلع على قسم معالجة التحقق من صحة البيانات للحصول على مزيد من المعلومات). تُعَد سلاسل التحقق من صحة البيانات وتطهيرها برمجيات وسيطة يجب تمريرها إلى معالج وجهة Express، إذ نطبّق ذلك بطريقة غير مباشرة باستخدام المتحكم، وتعمل أدوات التحقق من صحة البيانات وتطهيرها بالترتيب المُحدَّد عند تشغيل البرمجية الوسيطة. سنغطي بعض الأمثلة الحقيقية عندما نطبق استمارات موقع المكتبة المحلية LocalLibrary. تصميم الاستمارة ترتبط أو تعتمد العديد من النماذج في المكتبة على بعضها بعضًا، إذ يتطلب الكتاب Book مؤلفًا Author ويمكن أن يكون له نوع Genre واحد أو أكثر، مما يؤدي إلى التساؤل حول كيفية التعامل مع الحالة التي يرغب فيها المستخدم في: إنشاء كائن عندما لا تكون الكائنات المرتبطة به موجودةً بعد، مثل كتاب لم يُعرَّف كائن المؤلف فيه. حذف كائن لا يزال كائن آخر يستخدمه مثل حذف كائن النوع Genre الذي لا يزال كائن الكتاب Book يستخدمه. سنبسّط العمل في هذا المشروع بالقول إن الاستمارة يمكنها فقط: إنشاء كائن يستخدم كائنات موجودة فعليًا، لذلك يجب على المستخدمين إنشاء النسخ المطلوبة من المؤلف Author ونوع الكتاب Genre قبل محاولة إنشاء أي كائنات Book. حذف كائن إن لم تشِر إليه كائنات أخرى، فمثلًا لن تتمكّن من حذف كتاب Book حتى حذف جميع كائنات BookInstance المرتبطة به. ملاحظة: يمكن أن يسمح لك التقديم الأكثر مرونة بإنشاء كائنات معتمدة على بعضها البعض عند إنشاء كائن جديد، وحذف أيّ كائن في أي وقت من خلال حذف الكائنات المعتمدة عليه أو إزالة المراجع التي تشير إلى الكائن المحذوف من قاعدة البيانات مثلًا. الوجهات Routes سنحتاج إلى وجهتين لهما نمط عنوان URL نفسه لتقديم شيفرة معالجة الاستمارة، إذ تُستخدَم الوجهة الأولى GET لعرض استمارة فارغة جديدة لإنشاء الكائن، وتُستخدَم الوجهة الثانية (POST) للتحقق من صحة البيانات التي أدخلها المستخدم، ثم حفظ المعلومات وإعادة التوجيه إلى صفحة التفاصيل (إذا كانت البيانات صالحة) أو إعادة عرض الاستمارة مع وجود أخطاء (إذا كانت البيانات غير صالحة). أنشأنا الوجهات مسبقًا لجميع صفحات إنشاء النموذج في الملف "/routes/catalog.js" مثل وجهات نوع الكتب التالية: // طلب GET لإنشاء نوع كتاب Genre، إذ يجب أن يأتي قبل الوجهة التي تعرض نوع الكتاب (تستخدم المعرّف id) router.get("/genre/create", genre_controller.genre_create_get); // طلب POST لإنشاء نوع كتاب router.post("/genre/create", genre_controller.genre_create_post); توضّح المواضيع التالية عملية إضافة الاستمارات المطلوبة إلى تطبيقنا، إذ يجب العمل على كل منها ثم الانتقال إلى الموضوع التالي: إنشاء استمارة نوع الكتاب Genre: تعريف صفحة لإنشاء كائنات Genre. إنشاء استمارة المؤلف Author واستمارة الكتاب Book واستمارة نسخة الكتاب BookInstance: تعريف صفحة لإنشاء كائنات Author وتعريف صفحة أو استمارة لإنشاء كائنات Book وتعريف صفحة أو استمارة لإنشاء كائنات BookInstance. حذف استمارة المؤلف Author وتحديث استمارة الكتاب Book: تعريف صفحة لحذف كائنات Author وتعريف صفحة لتحديث كائنات Book. تحدى نفسك طبّق صفحات الحذف لنماذج Book و BookInstance و Genre واربطها بصفحات التفاصيل المتعلقة بها باستخدام الطريقة نفسها لصفحة حذف المؤلف، ويجب أن تتبع الصفحات أسلوب التصميم نفسه بحيث: إذا كان هناك مراجع إلى كائن من كائنات أخرى، فيجب عرض هذه الكائنات الأخرى مع ملاحظة أنه لا يمكن حذف هذا السجل حتى حذف الكائنات. إن لم يكن هناك مراجع أخرى إلى الكائن، فيجب أن يطالب العرض بحذفه، وإذا ضغط المستخدم على زر الحذف، فيجب حذف السجل. إليك بعض النصائح لتطبيقها: يشبه حذفُ الكائن Genre حذفَ الكائن Author تمامًا، فكلا الكائنين يعتمد عليهما الكائن Book، لذلك لا يمكنك حذف الكائن إلّا عند حذف الكتب المرتبطة به في كلتا الحالتين. يحدث الشيء نفسه عند حذف الكائن Book أيضًا، إذ يجب التحقق أولًا من عدم وجود كائنات BookInstance مرتبطة به. يُعَد حذف الكائن BookInstance أسهل ما في الأمر لأنه لا توجد كائنات معتمدة عليه، إذ يمكنك في هذه الحالة العثور على السجل وحذفه. طبّق صفحات التحديث لنماذج BookInstance و Author و Genre، واربطها بصفحات التفاصيل المرتبطة بها بالطريقة نفسها لصفحة تحديث الكتاب. واتبع أيضًا النصائح التالية: تُعَد صفحة تحديث الكتاب التي طبّقناها للتو هي الأصعب، ويمكن استخدام الأنماط نفسها لصفحات التحديث للكائنات الأخرى. يُعَد حقل تاريخ وفاة المؤلف Author وتاريخ ميلاده وحقل تاريخ استرجاع نسخة الكتاب BookInstance تنسيقًا خاطئًا لإدخاله في حقل إدخال التاريخ في الاستمارة، إذ يتطلب بياناتٍ في الاستمارة بالتنسيق: "YYYY-MM-DD". أسهل طريقة للتغلب على ذلك هي تعريف خاصية افتراضية جديدة للتواريخ التي تنسّق التواريخ بصورة مناسبة، ثم استخدام هذا الحقل في قوالب العرض المرتبطة به. إذا واجهتك مشكلة، فهناك أمثلة لصفحات التحديث يمكنك الاطلاع عليها. الخلاصة توفّر حزم Express و node والحزم الخارجية لمدير حزم npm كل ما تحتاجه لإضافة استمارات إلى موقع الويب، إذ تعلمت في هذا المقال كيفية إنشاء استمارات باستخدام Pug والتحقق من صحة بيانات الإدخال وتطهيرها باستخدام express-validator وإضافة السجلات وحذفها وتعديلها في قاعدة البيانات، ويجب أن تفهم الآن كيفية إضافة الاستمارات الأساسية وشيفرة معالجة الاستمارات إلى مواقع Node الخاصة بك. ترجمة -وبتصرُّف- للمقالين Express Tutorial Part 5: Displaying library data و Express Tutorial Part 6: Working with forms. اقرأ أيضًا المقال السابق تطبيق عملي لتعلم Express - الجزء الثالث: الوجهات Routes والمتحكمات Controllers. الاستمارات (forms) في متصفح الويب وكيفية التعامل معها في جافاسكربت. اإرسال الاستمارات (form submit) ومعالجتها في جافاسكربت. -
 سنوضح في هذا المقال الأدوات الرياضية المُستخدَمة في الرسوميات الحاسوبية ثلاثية الأبعاد Three Dimensional Computer Graphics -أو 3D Graphics اختصارًا، إذ يبني برنامج الرسوميات ثلاثية الأبعاد مشهدًا مكونًا من كائنات ثلاثية الأبعاد في فضاء ثلاثي الأبعاد، ثم تُنتَج صور ثنائية الأبعاد من المشهد ثلاثي الأبعاد، ويُمثَّل المشهد بوصفه هيكل بيانات في ذاكرة الحاسوب، وتُعَد الصورة ثنائية الأبعاد عادةً هي الصورة الموجودة على واجهة شاشة الحاسوب. تتكون الكائنات ثلاثية الأبعاد من نقاط وخطوط ومضلعات، إذ لا بد أنك تعرف ماهية هذه المفاهيم، ولكننا سنوضح في هذا المقال هذه المفاهيم ونقدم بعض المفردات الخاصة بالرسوميات الحاسوبية حتى نبدأ من أرضية مشتركة، إذ سنتعرّف على المواضيع التالية: النقاط. الخطوط. المثلثات. تمثيل النقاط والخطوط. إطارات الإحداثيات. تحديد الإحداثيات. تأثير تغيير الإطارات على الإحداثيات. الأشعة. تمثيل الأشعة. هناك شيئان أساسيان في الهندسة هما النقاط والخطوط، إذًا لنتعرف على هذين المفهومين، ولكن لنبدأ بالإجابة على سؤال "ما هي النقطة؟". النقطة ما هي النقطة؟ النقطة هي موقع في الفضاء. النقطة الهندسية هي موقع في الفضاء بدون أيّ خصائص أخرى، إذ لا تملك طولًا أو عرضًا أو سماكة، وتعَد موقعًا مجردًا. لن يساعدك هذا التعريف لمفهوم النقطة إن لم يكن لديك فهمٌ مسبق له، إذ تشير عبارة "موقع في الفضاء" إلى مفهوم كلمة "نقطة" نفسه، ولا يمكن للتعريف أن ينقل لك مفهومًا لا تملكه مسبقًا. لا يوجد تعريف لكلمة نقطة في الهندسة، فالنقطة هي إحدى المفاهيم الأولية غير المُعرَّفة التي تُستخدَم لتعريف الكائنات الأخرى، إذ تعطي الكتب أمثلةً عنها وتأمل أن تبني بنفسك مفهومًا منها بطريقةٍ ما بدلًا من إعطائك تعريفًا لها. تُظهر الصورة التالية قبتين على أحد المباني، وتُعَد هذه الصورة ثنائية الأبعاد، لكن فكّر في المبنى الفعلي ثلاثيّ الأبعاد، وركّز على القضيب المعدني (النهائي) الموجود أعلى القبة الأقرب. إذًا، تحدّد النهايةُ الحادة للقضيب المعدني موقعًا دقيقًا بحسب مقياس المبنى، إذ يمكننا تصور هذا الموقع بوصفه نقطة. ما هي النقاط فيزيائيا؟ لنفترض أن هذا القضيب المعدني أمامك على مكتبك، فهل تُعَد نهايته نقطة؟ غالبًا لا، إذ تكون النهاية غير حادة جدًا بحسب هذا المقياس، بحيث لا يمكن عدّها نقطة. تعبّر النقطة عن المثالية، إذ تكون نهاية القضيب المعدني بحسب مقياس المبنى صغيرةً بما يكفي لعَدّها موقعًا محددًا، وبالتالي يمكن عدّها نقطة، ولكن تكون نهايته غير حادة جدًا بحسب مقياس مكتبك بحيث لا يمكنها تحديد موقع واحد فعلًا. يجب أن يتناقص حجم هذا القضيب المعدني إلى حجم الدبوس بحسب مقياس المكتب، وبالتالي يمكنك أن تحدّد نهايته نقطةً ما. لكن إذا وضعت الدبوس تحت المجهر، فستكون نهايته غير حادة جدًا بالنسبة لهذا المقياس مرة أخرى، وبالتالي يجب أن تتقلص أكثر إلى حجم البكتيريا مثلًا قبل أن تتمكن النهاية من تحديد نقطة ما، لكن أصبحت نهاية القضيب المعدني مرةً أخرى سميكةً جدًا بحسب مقياس البكتيريا بحيث لا يمكنها تحديد الموقع بدقة. إذًا تعبّر النقاط في الفضاء ثلاثي الأبعاد عن المثالية، إذ تكون النهاية الحادة للقضيب المعدني دقيقةً بما يكفي لتكون نقطة بالنسبة لنموذج المبنى الحاسوبي، ولا يلزم تحديد الحواف والمستويات والأشكال الأخرى التي يتكون منها المبنى بدقة أكبر. النقاط في الفضاء ما هو موقع نهاية القضيب المعدني الأبعد في الفضاء؟ انظر إلى الصورة مرةً أخرى وتخيل العلاقة بين نقطتي نهايتي القضيبين المعدنيين، إذ لا توجد إجابة فعلية ضرورية حاليًا. تكون نقاط النهاية للقضيبين المعدنيين في مواقع محدّدة من العالم الحقيقي real world، وسنحدّد هذه المواقع باستخدام إطار إحداثي لاحقًا، ولكن لنفكر الآن فقط في النقاط الموجودة في الفضاء. تضع في برامج الرسوميات ثلاثية الأبعاد نقاطًا وخطوطًا وأشياءً أخرى في الفضاء، ثم تسقطها على صورة ثنائية الأبعاد، ويحاكي ذلك ما حدث عند إنتاج الصورة باستخدام الكاميرا، إذ تكون نهايات القضيبين المعدنيين فيزيائيًا نقاطًا في الفضاء ثلاثي الأبعاد. تسقط العدسة كامل المشهد على مستشعر الصور ثنائية الأبعاد، وتحدد نهايات القضبان المعدنية في الصورة ثنائية الأبعاد نقطتين ثنائيتي الأبعاد. الخطوط ما المسافة بين النقطتين عند طرفي القضيبين المعدنيين؟ يمكن أن نخمن أن المسافة حوالي 30 مترًا. يكون الحكم على العمق صعبًا في الصورة ثنائية الأبعاد في أغلب الأحيان، إذ تُفقَد معلومات العمق عند إنتاج صورة ثنائية الأبعاد من مشهد ثلاثي الأبعاد (إما مشهد حقيقي أو مشهد في الحاسوب). فكر الآن في القطعة المستقيمة Line Segment الواقعة بين النقطتين، والتي هي المسار المستقيم بين نقطتين بدون سماكة، ولا توجد سوى قطعة مستقيمة واحدة بين النقطتين. إن لم يكن لديك مفهوم مسبق عن "الخط"، فلن يكون التعريف السابق كافيًا لتعلمه، إذ تشير عبارة "المسار المستقيم" إلى مفهوم الخط الذي عرّفناه. تتعامل غالبًا مع القطع المستقيمة في الرسوميات ثلاثية الأبعاد، بينما تستمر الخطوط بلا نهاية في الهندسة، إذ تكون القطعة المستقيمة جزءًا من الخط بين نقطتين. لا يُعرَّف الخط العالمي في كتب الهندسة عادةً، وهو -مثل النقطة- مفهوم غير مُعرَّف يستخدم لتعريف كائنات أخرى، إذ تقدّم الكتب صورًا وأمثلة عن الخطوط، وتأمل أن تفهم بطريقة أو بأخرى ما هو الخط من خلال النظر إليها. يستخدم بعض الأشخاص مصطلح "خط" بينما يجب عليهم استخدام مصطلح "قطعة مستقيمة" الذي سنستخدمه في هذا المقال، نظرًا لأن القطع المستقيمة شائعة جدًا. القطع المستقيمة هل يمكنك تمديد stretch طول السلك بين النقطتين؟ نعم، من الناحية المفاهيمية على الأقل. يوجد سلك رفيع ممتد بين القضيبين المعدنيين بحسب مقياس المبنى، والذي يعبر عن تقريبٍ لقطعة مستقيمة، وكما تعلم يتعلق هذا الأمر بالمقياس، إذ يُرجَّح أن يكون السلك أسمك من الخط المرسوم بقلم رصاص، فالسلك الموجود على مكتبك سميك جدًا بحيث لا يمكن عدّه قطعة مستقيمة. بينما يكون الخط المرسوم بقلم الرصاص الرفيع والمستقيم رفيعًا بدرجة كافية لعدّه خطًا هندسيًا، وإذا كان سميكًا جدًا، فيمكن أن يكون طول خيط العنكبوت الممتد بين نقطتين مناسبًا. لكن يمكن عَدّ الأسلاك المدروسة على المستوى المعماري بمثابة قطع مستقيمة، ويمكنك بناء نموذج هندسي للمبنى باستخدام القطع المستقيمة لتمثيل الحواف. المثلثات جرّب رسم مثلث يربط بين القضيبين المعدنيين والزاوية العلوية اليسرى من السور الأبيض كما في الصورة التالية: يمكن إنشاء المثلث من خلال ربط ثلاث نقاط في فضاء ثلاثي الأبعاد بقطع مستقيمة، فإذا لم تقع النقاط الثلاث جميعها على الخط نفسه، فستحدّد ثلاث نقاط في الفضاء مثلثًا فريدًا. تُعَد المثلثات الموجودة في الفضاء مهمةً في الرسوميات ثلاثية الأبعاد، إذ تُنشَأ الكائنات ثلاثية الأبعاد التي تشكّل المشهد من المثلثات والمضلعات المسطحة الأخرى. المثلث الموجود في الصورة ثنائية الأبعاد هو إسقاط للمثلث ثلاثي الأبعاد في المشهد، ولكن يشوه الإسقاطُ المثلثَ ثلاثيّ الأبعاد، فالمثلث ثلاثي الأبعاد أكبر بكثير من المثلث ثنائي الأبعاد، وتكون الزوايا مختلفة. لنفترض أن الكائن ثلاثي الأبعاد في المشهد مكونٌ من عدة مثلثات، ولنسقط كل مثلث على صورة ثنائية الأبعاد، والنتيجة هي النسخة المُسقَطة من الكائن ثلاثي الأبعاد. يتكون السور الشبكي الأبيض في المبنى من العديد من المثلثات، وتُظهِر نسخة السور الشبكي الموجودة في الصورة جميع هذه المثلثات التي تسقطها عدسة الكاميرا. التمثيل باستخدام إطار إحداثيات هل تحتاج إلى إطار إحداثي -أي نظام مع تسمية النقاط بالإحداثيات x و y و z- للحديث عن النقاط والخطوط والأشكال المستوية؟ في الحقيقة لا حاجة لذلك. يمكنك التفكير في النقاط والخطوط والأشكال المستوية التي تشكّل المشهد ثلاثي الأبعاد دون استخدام نظام إحداثي، وهذا ما كنا نفعله في الحقيقة، ولكن يجب تمثيل هذه الكائنات بطريقة أو بأخرى والتعامل معها في رسوميات الحاسوب، ولذلك نحتاج إلى طريقة لتمثيلها. اختر نقطةً مناسبة في المشهد ثلاثي الأبعاد وأطلِق عليها اسم نقطة الأصل Origin، وحدد ثلاثة خطوط تسمى X و Y و Z والتي تمر عبر نقطة الأصل، وتكون الخطوط الثلاثة عادةً متعامدة على بعضها بعضًا، ويسمى كل خط محورًا Axis. اختر اتجاهًا إيجابيًا لكل خط، فهناك عدة خيارات لذلك، ولكن لنستخدم الخيار الموضّح في الصورة السابقة. تمثل كل نقطة من المحور X مسافةً فريدةً (موجبة أو سالبة أو صفر) من نقطة الأصل، فمثلًا تقع زاوية المبنى الموجودة على المحور X على مسافة 2.4 متر (8 أقدام) تقريبًا من نقطة الأصل. الإحداثيات تقع نقطة الأصل على ارتفاع صفر، ولكن على أي ارتفاع تقع نقطة نهاية القضيب المعدني الأقرب تقريبًا؟ يمكن القول أن ارتفاعها حوالي 3.6 مترًا (10 أقدام). أو يمكنك القول أن y=3.6 بالنسبة لنقطة نهاية القضيب المعدني، إذ يمكن إسناد تمثيل لأيّ نقطة في مشهدنا ثلاثيّ الأبعاد من خلال قياس المسافة على طول المحاور الثلاثة، إذ سنضع هذه المسافات الثلاث في مصفوفة عمودية على النحو التالي في هذا المقال (وفي العديد من كتب الرسوميات الحاسوبية): قد تكون معتادًا على وضع الإحداثيات الثلاثة في صف ثلاثي مثل (x, y, z)، ولكن سيتبين أنه من الملائم أكثر وضعها في مصفوفة عمودية كما ذكرنا بالنسبة للرسوميات الحاسوبية، فمثلًا إحداثيات زاوية المبنى التي تقع على طول المحور X هي تقريبًا: تحديد الإحداثيات ما هي إحداثيات نقطة زاوية الشبكة البيضاء على طول الحافة العلوية (المسمَّاة P0)؟ يمكن القول أنها تقريبًا: احسب عند تحديد الإحداثيات قياس المسافة على طول الخطوط الموازية لمحاور الإحداثيات، إذ ستشكّل الخطوط التي تستخدمها مستطيلًا أو أوجه صندوق. تشكّل الخطوط السوداء المنقطة المستخدمة للنقطة Q0 مستطيلًا، ويعطي قياس أضلاع المستطيل الإحداثيات التالية: من الصعب معرفة إحداثيات النقطة Q1، فالصورة ثنائية الأبعاد، ولكن المشهد الذي تظهره ثلاثي الأبعاد، وبالتالي فإن المحور Z مشوه، ولكن تشكل الخطوط المنقطة في المشهد ثلاثي الأبعاد صندوقًا، فقياس جميع الزوايا 90 درجة. مزيد من النقاط يمكن تقدير إحداثيات النقطة Q1 بالقيم التالية: لنعُد الآن إلى مشهدنا الواقعي، إذ يبلغ طول الشبكة البيضاء تقريبًا حوالي 2.4 متر (8 أقدام) من كل جانب. النقطة وتمثيلها يمكن تخمين إحداثيات طرف القضيب المعدني الأقرب بالقيم التالية: تُعَد المصفوفة العمودية كائنًا رياضيًا يمثل النقطة باستخدام إطار الإحداثيات الذي اخترناه، ولكن ليست هذه المصفوفة العمودية هي النقطة بحد ذاتها، فالمصفوفة العمودية والنقطة شيئان مختلفان، إذ يُستخدَم أحدهما لتمثيل الآخر مثل استخدام اسمك لتمثيلك. نأمل أن يكون ذلك واضحًا، ولكنه سيكون غامضًا بالنسبة للطلاب الذين يحاولون تخطي مواضيع رياضيات الرسوميات الحاسوبية بسرعة، مما يؤدي إلى ندمهم في نهاية المطاف، إذ يمكن أن يمثل كتاب الرسوميات الحاسوبية النقطة نفسها بعدة طرق مختلفة، لذا من الضروري الفصل بين أفكار النقطة الهندسية والطرق المتعددة التي يمكن تمثيلها باستخدامها. ملاحظة: يتحدث الأشخاص في أغلب الأحيان عرضيًا ويقولون أشياء مثل "النقطة (4, 12, -4)"، كما لو كان هذا الصف الثلاثي من الأرقام متطابقًا مع النقطة، ولكن يُستخدَم ذلك للراحة فقط، إذ ينبغي عليهم أن يقولوا: "النقطة المُمثَّلة في نظام الإحداثيات الذي اخترناه بالتمثيل (4, 12, -4)." تأثير تغيير الإطارات على الإحداثيات هل تقاس المسافات على طول محاور الإحداثيات بوحدة القدم أم بالأمتار؟ لا يهم، طالما أنك تستخدمها بصورة متناسقة. لا تُوضَع إطارات الإحداثيات المستخدمة في كتب الرياضيات في مشهد من العالم الحقيقي عادةً، لذلك لا يُعبَّر عن المسافات بأيّ وحدة معينة، ولكن يتعين عليك تحديد الوحدات التي تستخدمها عندما تنشئ عالمًا ثلاثي الأبعاد في الحاسوب. تُظهر الصورة التالية عالمًا ثلاثيّ الأبعاد مع وضع إطارٍ إحداثي مختلف فيه، إذ تبقى النقاط في العالم نفسها كما كانت سابقًا، ولكن سيكون لديها تمثيلات مختلفة مع إطار إحداثي مختلف: مثلنا النقطة المسمَّاة P1 بما يلي في الإطار السابق: ستكون الآن المسافات على طول المحاور في الإطار الجديد (الأخضر) مختلفة، فالمصفوفة العمودية التي تمثل النقطة P1 في الإطار الجديد هي تقريبًا: لم نمارس الرياضيات بصورة دقيقة هنا، بل نظرنا إلى الصورة وخمّنا المسافات فقط، لذا حاول أن تفعل الشيء نفسه، فالهدف ليس حساب أي شيء، بل التفكير في النقاط في الفضاء. للنقطة نفسها تمثيلات مختلفة في كل إطار، لذا يجب أن تعرف الإطار المُستخدَم عندما تمثل نقطةً بمصفوفة عمودية. ضوء الشمس يمكن تقدير إحداثيات النقطة P0 على الحافة العلوية للشبكة المبينة في الصورة أعلاه بالمصفوفة العمودية التالية: ولكن هذه القيم مجرد تقدير فقط. انظر إلى صورة المبنى مرةً أخرى، إذ تضيء الشمسُ المشهد، ولكنها ليست موجودة في الصورة، إذ يأتي ضوء الشمس في المشهد قطريًا من خارج المشهد إلى يساره. الأشعة Vector ارسم ذهنيًا بعض الخطوط في الصورة التي تظهر ضوء الشمس كما في الشكل التالي: يتدفق الضوء من أعلى اليسار عندما تنظر إلى المبنى، إذ تمثل الصورة ضوء الشمس بأسهم. حاول التفكير في المشهد ثلاثي الأبعاد بالرغم من أن الصورة ثنائية الأبعاد، فالاتجاه الذي يتحرك فيه الضوء موضَّح بالسهم، ويمثل طول السهم مثلًا شدة الضوء. توجد عدة أسهم في الصورة، إلا أنّ أيّ سهمٍ يكفي لتمثيل الضوء وشدته. يمكن تمثيل اتجاه الضوء وشدته بشعاع، والذي هو كائن هندسي له خاصيتان هما: الطول والاتجاه. للضوء الصادر من الشمس خاصيتان، هما: السطوع والاتجاه (مع تجاهل معلومات اللون)، ويتناسب طول الشعاع مع سطوع الضوء. يمكن تمثيل الرياح أيضًا بشعاع، فالرياح لها اتجاه وسرعة، إذ تنتقل ذرة من الغبار مع اتجاه الريح، ويتناسب طول الشعاع مع سرعة ذرة الغبار. ليس للشعاع موضع، إذ تُظهِر الصورة السابقة عدة أسهم تمثل تدفق الضوء القادم من الشمس، ولكن يمكن رسم الأسهم في أيّ مكان طالما أن اتجاهها وطولها هو نفسه. تمثيل الأشعة هل تفترض أن برنامج الرسوميات الحاسوبية يحتاج إلى تمثيل شدة الضوء واتجاهه؟ نعم، في الحقيقة هناك حاجة لذلك. تُستخدَم الأشعة لعدة أغراض في رسوميات الحاسوب ثلاثية الأبعاد، لذلك يجب أن تُمثَّل بطريقة يمكن للبرامج التعامل معها، ويحدث ذلك باستخدام الأرقام. لاحظ أن الصورة التالية تتضمن الآن إطار إحداثياتنا: يُمثَّل الشعاع بمصفوفة عمودية كما هو الحال مع النقاط، ويمكن أن يكون من المربك إلى حدٍ ما أن تُمثَّل النقاط والأشعة باستخدام الشيء نفسه، ولكن ذلك سيثبت أنه هذه الطريقة مناسبة ليتعامل معها الحاسوب. يمكن تمثيل الشعاع بمصفوفة عمودية باتباع الخطوات التالية: اختر إطارًا إحداثيًا. احسب طول X (موجب أو سالب) من ذيل الشعاع إلى رأسه. 3.احسب طول Y (موجب أو سالب) من ذيل الشعاع إلى رأسه. احسب طول Z (موجب أو سالب) من ذيل الشعاع إلى رأسه. ضع هذه الأرقام الثلاثة في عمود. إحدى الطرق الملائمة لذلك هي وضع ذيل الشعاع عند نقطة الأصل، ثم قراءة قيم x و y و z عند رأسه. الأشعة والإطارات كم مترًا في الاتجاه X للمسافة بين رأس الأسهم عن ذيلها في الصورة؟ يمكن أن نخمنها بمقدار حوالي 0.9 متر (3 أقدام). كم مترًا في الاتجاه Y يبعد الرأس عن الذيل؟ يمكن أن نخمنها بمقدار 1.2- متر (-4 أقدام). كم مترًا في الاتجاه Z يبعد الرأس من الذيل؟ يمكن أن نخمنها بمقدار 0.9- متر (-3 أقدام). إذًا، الشعاع الذي يعطي شدة واتجاه ضوء الشمس في الصورة هو: تمثل المصفوفة العمودية السابقة الشعاع باستخدام إطار الإحداثيات الذي اخترناه، ولكنها ليست الشعاع نفسه. إذا اخترنا إطارًا إحداثيًا مختلفًا، فسيكون الشعاع في المشهد الحقيقي هو نفسه، ولكن سيتغير تمثيله باستخدام الإطار الجديد، وسنواصل في المقال التالي هذه المناقشة. مراجعة سريعة: للنقطة خاصية واحدة فقط هي: الموقع. للشعاع خاصيتان، هما: الطول والاتجاه ولكن ليس له موقع. ترجمة -وبتصرُّف- للفصل Points and Lines من كتاب Vector Math for 3D Computer Graphics لصاحبه Bradley Kjell. اقرأ أيضًا تعرف على أشهر برامج وتطبيقات تصميم الصور والرسوميات قواعد تصميم الرسوم البيانية قواعد التعامل مع الصور والرسوميات
سنوضح في هذا المقال الأدوات الرياضية المُستخدَمة في الرسوميات الحاسوبية ثلاثية الأبعاد Three Dimensional Computer Graphics -أو 3D Graphics اختصارًا، إذ يبني برنامج الرسوميات ثلاثية الأبعاد مشهدًا مكونًا من كائنات ثلاثية الأبعاد في فضاء ثلاثي الأبعاد، ثم تُنتَج صور ثنائية الأبعاد من المشهد ثلاثي الأبعاد، ويُمثَّل المشهد بوصفه هيكل بيانات في ذاكرة الحاسوب، وتُعَد الصورة ثنائية الأبعاد عادةً هي الصورة الموجودة على واجهة شاشة الحاسوب. تتكون الكائنات ثلاثية الأبعاد من نقاط وخطوط ومضلعات، إذ لا بد أنك تعرف ماهية هذه المفاهيم، ولكننا سنوضح في هذا المقال هذه المفاهيم ونقدم بعض المفردات الخاصة بالرسوميات الحاسوبية حتى نبدأ من أرضية مشتركة، إذ سنتعرّف على المواضيع التالية: النقاط. الخطوط. المثلثات. تمثيل النقاط والخطوط. إطارات الإحداثيات. تحديد الإحداثيات. تأثير تغيير الإطارات على الإحداثيات. الأشعة. تمثيل الأشعة. هناك شيئان أساسيان في الهندسة هما النقاط والخطوط، إذًا لنتعرف على هذين المفهومين، ولكن لنبدأ بالإجابة على سؤال "ما هي النقطة؟". النقطة ما هي النقطة؟ النقطة هي موقع في الفضاء. النقطة الهندسية هي موقع في الفضاء بدون أيّ خصائص أخرى، إذ لا تملك طولًا أو عرضًا أو سماكة، وتعَد موقعًا مجردًا. لن يساعدك هذا التعريف لمفهوم النقطة إن لم يكن لديك فهمٌ مسبق له، إذ تشير عبارة "موقع في الفضاء" إلى مفهوم كلمة "نقطة" نفسه، ولا يمكن للتعريف أن ينقل لك مفهومًا لا تملكه مسبقًا. لا يوجد تعريف لكلمة نقطة في الهندسة، فالنقطة هي إحدى المفاهيم الأولية غير المُعرَّفة التي تُستخدَم لتعريف الكائنات الأخرى، إذ تعطي الكتب أمثلةً عنها وتأمل أن تبني بنفسك مفهومًا منها بطريقةٍ ما بدلًا من إعطائك تعريفًا لها. تُظهر الصورة التالية قبتين على أحد المباني، وتُعَد هذه الصورة ثنائية الأبعاد، لكن فكّر في المبنى الفعلي ثلاثيّ الأبعاد، وركّز على القضيب المعدني (النهائي) الموجود أعلى القبة الأقرب. إذًا، تحدّد النهايةُ الحادة للقضيب المعدني موقعًا دقيقًا بحسب مقياس المبنى، إذ يمكننا تصور هذا الموقع بوصفه نقطة. ما هي النقاط فيزيائيا؟ لنفترض أن هذا القضيب المعدني أمامك على مكتبك، فهل تُعَد نهايته نقطة؟ غالبًا لا، إذ تكون النهاية غير حادة جدًا بحسب هذا المقياس، بحيث لا يمكن عدّها نقطة. تعبّر النقطة عن المثالية، إذ تكون نهاية القضيب المعدني بحسب مقياس المبنى صغيرةً بما يكفي لعَدّها موقعًا محددًا، وبالتالي يمكن عدّها نقطة، ولكن تكون نهايته غير حادة جدًا بحسب مقياس مكتبك بحيث لا يمكنها تحديد موقع واحد فعلًا. يجب أن يتناقص حجم هذا القضيب المعدني إلى حجم الدبوس بحسب مقياس المكتب، وبالتالي يمكنك أن تحدّد نهايته نقطةً ما. لكن إذا وضعت الدبوس تحت المجهر، فستكون نهايته غير حادة جدًا بالنسبة لهذا المقياس مرة أخرى، وبالتالي يجب أن تتقلص أكثر إلى حجم البكتيريا مثلًا قبل أن تتمكن النهاية من تحديد نقطة ما، لكن أصبحت نهاية القضيب المعدني مرةً أخرى سميكةً جدًا بحسب مقياس البكتيريا بحيث لا يمكنها تحديد الموقع بدقة. إذًا تعبّر النقاط في الفضاء ثلاثي الأبعاد عن المثالية، إذ تكون النهاية الحادة للقضيب المعدني دقيقةً بما يكفي لتكون نقطة بالنسبة لنموذج المبنى الحاسوبي، ولا يلزم تحديد الحواف والمستويات والأشكال الأخرى التي يتكون منها المبنى بدقة أكبر. النقاط في الفضاء ما هو موقع نهاية القضيب المعدني الأبعد في الفضاء؟ انظر إلى الصورة مرةً أخرى وتخيل العلاقة بين نقطتي نهايتي القضيبين المعدنيين، إذ لا توجد إجابة فعلية ضرورية حاليًا. تكون نقاط النهاية للقضيبين المعدنيين في مواقع محدّدة من العالم الحقيقي real world، وسنحدّد هذه المواقع باستخدام إطار إحداثي لاحقًا، ولكن لنفكر الآن فقط في النقاط الموجودة في الفضاء. تضع في برامج الرسوميات ثلاثية الأبعاد نقاطًا وخطوطًا وأشياءً أخرى في الفضاء، ثم تسقطها على صورة ثنائية الأبعاد، ويحاكي ذلك ما حدث عند إنتاج الصورة باستخدام الكاميرا، إذ تكون نهايات القضيبين المعدنيين فيزيائيًا نقاطًا في الفضاء ثلاثي الأبعاد. تسقط العدسة كامل المشهد على مستشعر الصور ثنائية الأبعاد، وتحدد نهايات القضبان المعدنية في الصورة ثنائية الأبعاد نقطتين ثنائيتي الأبعاد. الخطوط ما المسافة بين النقطتين عند طرفي القضيبين المعدنيين؟ يمكن أن نخمن أن المسافة حوالي 30 مترًا. يكون الحكم على العمق صعبًا في الصورة ثنائية الأبعاد في أغلب الأحيان، إذ تُفقَد معلومات العمق عند إنتاج صورة ثنائية الأبعاد من مشهد ثلاثي الأبعاد (إما مشهد حقيقي أو مشهد في الحاسوب). فكر الآن في القطعة المستقيمة Line Segment الواقعة بين النقطتين، والتي هي المسار المستقيم بين نقطتين بدون سماكة، ولا توجد سوى قطعة مستقيمة واحدة بين النقطتين. إن لم يكن لديك مفهوم مسبق عن "الخط"، فلن يكون التعريف السابق كافيًا لتعلمه، إذ تشير عبارة "المسار المستقيم" إلى مفهوم الخط الذي عرّفناه. تتعامل غالبًا مع القطع المستقيمة في الرسوميات ثلاثية الأبعاد، بينما تستمر الخطوط بلا نهاية في الهندسة، إذ تكون القطعة المستقيمة جزءًا من الخط بين نقطتين. لا يُعرَّف الخط العالمي في كتب الهندسة عادةً، وهو -مثل النقطة- مفهوم غير مُعرَّف يستخدم لتعريف كائنات أخرى، إذ تقدّم الكتب صورًا وأمثلة عن الخطوط، وتأمل أن تفهم بطريقة أو بأخرى ما هو الخط من خلال النظر إليها. يستخدم بعض الأشخاص مصطلح "خط" بينما يجب عليهم استخدام مصطلح "قطعة مستقيمة" الذي سنستخدمه في هذا المقال، نظرًا لأن القطع المستقيمة شائعة جدًا. القطع المستقيمة هل يمكنك تمديد stretch طول السلك بين النقطتين؟ نعم، من الناحية المفاهيمية على الأقل. يوجد سلك رفيع ممتد بين القضيبين المعدنيين بحسب مقياس المبنى، والذي يعبر عن تقريبٍ لقطعة مستقيمة، وكما تعلم يتعلق هذا الأمر بالمقياس، إذ يُرجَّح أن يكون السلك أسمك من الخط المرسوم بقلم رصاص، فالسلك الموجود على مكتبك سميك جدًا بحيث لا يمكن عدّه قطعة مستقيمة. بينما يكون الخط المرسوم بقلم الرصاص الرفيع والمستقيم رفيعًا بدرجة كافية لعدّه خطًا هندسيًا، وإذا كان سميكًا جدًا، فيمكن أن يكون طول خيط العنكبوت الممتد بين نقطتين مناسبًا. لكن يمكن عَدّ الأسلاك المدروسة على المستوى المعماري بمثابة قطع مستقيمة، ويمكنك بناء نموذج هندسي للمبنى باستخدام القطع المستقيمة لتمثيل الحواف. المثلثات جرّب رسم مثلث يربط بين القضيبين المعدنيين والزاوية العلوية اليسرى من السور الأبيض كما في الصورة التالية: يمكن إنشاء المثلث من خلال ربط ثلاث نقاط في فضاء ثلاثي الأبعاد بقطع مستقيمة، فإذا لم تقع النقاط الثلاث جميعها على الخط نفسه، فستحدّد ثلاث نقاط في الفضاء مثلثًا فريدًا. تُعَد المثلثات الموجودة في الفضاء مهمةً في الرسوميات ثلاثية الأبعاد، إذ تُنشَأ الكائنات ثلاثية الأبعاد التي تشكّل المشهد من المثلثات والمضلعات المسطحة الأخرى. المثلث الموجود في الصورة ثنائية الأبعاد هو إسقاط للمثلث ثلاثي الأبعاد في المشهد، ولكن يشوه الإسقاطُ المثلثَ ثلاثيّ الأبعاد، فالمثلث ثلاثي الأبعاد أكبر بكثير من المثلث ثنائي الأبعاد، وتكون الزوايا مختلفة. لنفترض أن الكائن ثلاثي الأبعاد في المشهد مكونٌ من عدة مثلثات، ولنسقط كل مثلث على صورة ثنائية الأبعاد، والنتيجة هي النسخة المُسقَطة من الكائن ثلاثي الأبعاد. يتكون السور الشبكي الأبيض في المبنى من العديد من المثلثات، وتُظهِر نسخة السور الشبكي الموجودة في الصورة جميع هذه المثلثات التي تسقطها عدسة الكاميرا. التمثيل باستخدام إطار إحداثيات هل تحتاج إلى إطار إحداثي -أي نظام مع تسمية النقاط بالإحداثيات x و y و z- للحديث عن النقاط والخطوط والأشكال المستوية؟ في الحقيقة لا حاجة لذلك. يمكنك التفكير في النقاط والخطوط والأشكال المستوية التي تشكّل المشهد ثلاثي الأبعاد دون استخدام نظام إحداثي، وهذا ما كنا نفعله في الحقيقة، ولكن يجب تمثيل هذه الكائنات بطريقة أو بأخرى والتعامل معها في رسوميات الحاسوب، ولذلك نحتاج إلى طريقة لتمثيلها. اختر نقطةً مناسبة في المشهد ثلاثي الأبعاد وأطلِق عليها اسم نقطة الأصل Origin، وحدد ثلاثة خطوط تسمى X و Y و Z والتي تمر عبر نقطة الأصل، وتكون الخطوط الثلاثة عادةً متعامدة على بعضها بعضًا، ويسمى كل خط محورًا Axis. اختر اتجاهًا إيجابيًا لكل خط، فهناك عدة خيارات لذلك، ولكن لنستخدم الخيار الموضّح في الصورة السابقة. تمثل كل نقطة من المحور X مسافةً فريدةً (موجبة أو سالبة أو صفر) من نقطة الأصل، فمثلًا تقع زاوية المبنى الموجودة على المحور X على مسافة 2.4 متر (8 أقدام) تقريبًا من نقطة الأصل. الإحداثيات تقع نقطة الأصل على ارتفاع صفر، ولكن على أي ارتفاع تقع نقطة نهاية القضيب المعدني الأقرب تقريبًا؟ يمكن القول أن ارتفاعها حوالي 3.6 مترًا (10 أقدام). أو يمكنك القول أن y=3.6 بالنسبة لنقطة نهاية القضيب المعدني، إذ يمكن إسناد تمثيل لأيّ نقطة في مشهدنا ثلاثيّ الأبعاد من خلال قياس المسافة على طول المحاور الثلاثة، إذ سنضع هذه المسافات الثلاث في مصفوفة عمودية على النحو التالي في هذا المقال (وفي العديد من كتب الرسوميات الحاسوبية): قد تكون معتادًا على وضع الإحداثيات الثلاثة في صف ثلاثي مثل (x, y, z)، ولكن سيتبين أنه من الملائم أكثر وضعها في مصفوفة عمودية كما ذكرنا بالنسبة للرسوميات الحاسوبية، فمثلًا إحداثيات زاوية المبنى التي تقع على طول المحور X هي تقريبًا: تحديد الإحداثيات ما هي إحداثيات نقطة زاوية الشبكة البيضاء على طول الحافة العلوية (المسمَّاة P0)؟ يمكن القول أنها تقريبًا: احسب عند تحديد الإحداثيات قياس المسافة على طول الخطوط الموازية لمحاور الإحداثيات، إذ ستشكّل الخطوط التي تستخدمها مستطيلًا أو أوجه صندوق. تشكّل الخطوط السوداء المنقطة المستخدمة للنقطة Q0 مستطيلًا، ويعطي قياس أضلاع المستطيل الإحداثيات التالية: من الصعب معرفة إحداثيات النقطة Q1، فالصورة ثنائية الأبعاد، ولكن المشهد الذي تظهره ثلاثي الأبعاد، وبالتالي فإن المحور Z مشوه، ولكن تشكل الخطوط المنقطة في المشهد ثلاثي الأبعاد صندوقًا، فقياس جميع الزوايا 90 درجة. مزيد من النقاط يمكن تقدير إحداثيات النقطة Q1 بالقيم التالية: لنعُد الآن إلى مشهدنا الواقعي، إذ يبلغ طول الشبكة البيضاء تقريبًا حوالي 2.4 متر (8 أقدام) من كل جانب. النقطة وتمثيلها يمكن تخمين إحداثيات طرف القضيب المعدني الأقرب بالقيم التالية: تُعَد المصفوفة العمودية كائنًا رياضيًا يمثل النقطة باستخدام إطار الإحداثيات الذي اخترناه، ولكن ليست هذه المصفوفة العمودية هي النقطة بحد ذاتها، فالمصفوفة العمودية والنقطة شيئان مختلفان، إذ يُستخدَم أحدهما لتمثيل الآخر مثل استخدام اسمك لتمثيلك. نأمل أن يكون ذلك واضحًا، ولكنه سيكون غامضًا بالنسبة للطلاب الذين يحاولون تخطي مواضيع رياضيات الرسوميات الحاسوبية بسرعة، مما يؤدي إلى ندمهم في نهاية المطاف، إذ يمكن أن يمثل كتاب الرسوميات الحاسوبية النقطة نفسها بعدة طرق مختلفة، لذا من الضروري الفصل بين أفكار النقطة الهندسية والطرق المتعددة التي يمكن تمثيلها باستخدامها. ملاحظة: يتحدث الأشخاص في أغلب الأحيان عرضيًا ويقولون أشياء مثل "النقطة (4, 12, -4)"، كما لو كان هذا الصف الثلاثي من الأرقام متطابقًا مع النقطة، ولكن يُستخدَم ذلك للراحة فقط، إذ ينبغي عليهم أن يقولوا: "النقطة المُمثَّلة في نظام الإحداثيات الذي اخترناه بالتمثيل (4, 12, -4)." تأثير تغيير الإطارات على الإحداثيات هل تقاس المسافات على طول محاور الإحداثيات بوحدة القدم أم بالأمتار؟ لا يهم، طالما أنك تستخدمها بصورة متناسقة. لا تُوضَع إطارات الإحداثيات المستخدمة في كتب الرياضيات في مشهد من العالم الحقيقي عادةً، لذلك لا يُعبَّر عن المسافات بأيّ وحدة معينة، ولكن يتعين عليك تحديد الوحدات التي تستخدمها عندما تنشئ عالمًا ثلاثي الأبعاد في الحاسوب. تُظهر الصورة التالية عالمًا ثلاثيّ الأبعاد مع وضع إطارٍ إحداثي مختلف فيه، إذ تبقى النقاط في العالم نفسها كما كانت سابقًا، ولكن سيكون لديها تمثيلات مختلفة مع إطار إحداثي مختلف: مثلنا النقطة المسمَّاة P1 بما يلي في الإطار السابق: ستكون الآن المسافات على طول المحاور في الإطار الجديد (الأخضر) مختلفة، فالمصفوفة العمودية التي تمثل النقطة P1 في الإطار الجديد هي تقريبًا: لم نمارس الرياضيات بصورة دقيقة هنا، بل نظرنا إلى الصورة وخمّنا المسافات فقط، لذا حاول أن تفعل الشيء نفسه، فالهدف ليس حساب أي شيء، بل التفكير في النقاط في الفضاء. للنقطة نفسها تمثيلات مختلفة في كل إطار، لذا يجب أن تعرف الإطار المُستخدَم عندما تمثل نقطةً بمصفوفة عمودية. ضوء الشمس يمكن تقدير إحداثيات النقطة P0 على الحافة العلوية للشبكة المبينة في الصورة أعلاه بالمصفوفة العمودية التالية: ولكن هذه القيم مجرد تقدير فقط. انظر إلى صورة المبنى مرةً أخرى، إذ تضيء الشمسُ المشهد، ولكنها ليست موجودة في الصورة، إذ يأتي ضوء الشمس في المشهد قطريًا من خارج المشهد إلى يساره. الأشعة Vector ارسم ذهنيًا بعض الخطوط في الصورة التي تظهر ضوء الشمس كما في الشكل التالي: يتدفق الضوء من أعلى اليسار عندما تنظر إلى المبنى، إذ تمثل الصورة ضوء الشمس بأسهم. حاول التفكير في المشهد ثلاثي الأبعاد بالرغم من أن الصورة ثنائية الأبعاد، فالاتجاه الذي يتحرك فيه الضوء موضَّح بالسهم، ويمثل طول السهم مثلًا شدة الضوء. توجد عدة أسهم في الصورة، إلا أنّ أيّ سهمٍ يكفي لتمثيل الضوء وشدته. يمكن تمثيل اتجاه الضوء وشدته بشعاع، والذي هو كائن هندسي له خاصيتان هما: الطول والاتجاه. للضوء الصادر من الشمس خاصيتان، هما: السطوع والاتجاه (مع تجاهل معلومات اللون)، ويتناسب طول الشعاع مع سطوع الضوء. يمكن تمثيل الرياح أيضًا بشعاع، فالرياح لها اتجاه وسرعة، إذ تنتقل ذرة من الغبار مع اتجاه الريح، ويتناسب طول الشعاع مع سرعة ذرة الغبار. ليس للشعاع موضع، إذ تُظهِر الصورة السابقة عدة أسهم تمثل تدفق الضوء القادم من الشمس، ولكن يمكن رسم الأسهم في أيّ مكان طالما أن اتجاهها وطولها هو نفسه. تمثيل الأشعة هل تفترض أن برنامج الرسوميات الحاسوبية يحتاج إلى تمثيل شدة الضوء واتجاهه؟ نعم، في الحقيقة هناك حاجة لذلك. تُستخدَم الأشعة لعدة أغراض في رسوميات الحاسوب ثلاثية الأبعاد، لذلك يجب أن تُمثَّل بطريقة يمكن للبرامج التعامل معها، ويحدث ذلك باستخدام الأرقام. لاحظ أن الصورة التالية تتضمن الآن إطار إحداثياتنا: يُمثَّل الشعاع بمصفوفة عمودية كما هو الحال مع النقاط، ويمكن أن يكون من المربك إلى حدٍ ما أن تُمثَّل النقاط والأشعة باستخدام الشيء نفسه، ولكن ذلك سيثبت أنه هذه الطريقة مناسبة ليتعامل معها الحاسوب. يمكن تمثيل الشعاع بمصفوفة عمودية باتباع الخطوات التالية: اختر إطارًا إحداثيًا. احسب طول X (موجب أو سالب) من ذيل الشعاع إلى رأسه. 3.احسب طول Y (موجب أو سالب) من ذيل الشعاع إلى رأسه. احسب طول Z (موجب أو سالب) من ذيل الشعاع إلى رأسه. ضع هذه الأرقام الثلاثة في عمود. إحدى الطرق الملائمة لذلك هي وضع ذيل الشعاع عند نقطة الأصل، ثم قراءة قيم x و y و z عند رأسه. الأشعة والإطارات كم مترًا في الاتجاه X للمسافة بين رأس الأسهم عن ذيلها في الصورة؟ يمكن أن نخمنها بمقدار حوالي 0.9 متر (3 أقدام). كم مترًا في الاتجاه Y يبعد الرأس عن الذيل؟ يمكن أن نخمنها بمقدار 1.2- متر (-4 أقدام). كم مترًا في الاتجاه Z يبعد الرأس من الذيل؟ يمكن أن نخمنها بمقدار 0.9- متر (-3 أقدام). إذًا، الشعاع الذي يعطي شدة واتجاه ضوء الشمس في الصورة هو: تمثل المصفوفة العمودية السابقة الشعاع باستخدام إطار الإحداثيات الذي اخترناه، ولكنها ليست الشعاع نفسه. إذا اخترنا إطارًا إحداثيًا مختلفًا، فسيكون الشعاع في المشهد الحقيقي هو نفسه، ولكن سيتغير تمثيله باستخدام الإطار الجديد، وسنواصل في المقال التالي هذه المناقشة. مراجعة سريعة: للنقطة خاصية واحدة فقط هي: الموقع. للشعاع خاصيتان، هما: الطول والاتجاه ولكن ليس له موقع. ترجمة -وبتصرُّف- للفصل Points and Lines من كتاب Vector Math for 3D Computer Graphics لصاحبه Bradley Kjell. اقرأ أيضًا تعرف على أشهر برامج وتطبيقات تصميم الصور والرسوميات قواعد تصميم الرسوم البيانية قواعد التعامل مع الصور والرسوميات -
 سنُعِدّ في هذا المقال الوجهات Routes (شيفرة معالجة عناوين URL، ويسميها البعض بالموجهات) باستخدام دوال معالجة وهمية dummy لجميع النقاط النهائية للموارد التي سنحتاجها في موقع المكتبة المحلية LocalLibrary. سيكون لدينا في النهاية بنية معيارية لشيفرة معالجة الوجهات، والتي يمكننا توسيعها باستخدام دوال معالجة حقيقية في المقالات اللاحقة، وسيصبح لدينا أيضًا فهم جيد لكيفية إنشاء وجهات معيارية باستخدام إطار عمل Express. المتطلبات الأساسية: الاطلاع على مقال مدخل إلى إطار عمل الويب Express، وإكمال المقالات السابقة من هذه السلسلة بما في ذلك مقال استخدام قاعدة البيانات. الهدف: فهم كيفية إنشاء وجهات بسيطة وإعداد جميع النقاط النهائية لعناوين URL. تعرّفنا في المقال السابق على نماذج Mongoose للتفاعل مع قاعدة البيانات، واستخدمنا سكربتًا مستقلًا لإنشاء بعض سجلات المكتبة الأولية، ويمكننا الآن كتابة الشيفرة البرمجية لتقديم تلك المعلومات للمستخدمين. يجب أولًا تحديد المعلومات التي نريد عرضها في صفحاتنا، ثم تعريف عناوين URL المناسبة لإعادة تلك الموارد، ثم يجب إنشاء الوجهات (معالجات عناوين URL) والعروض Views (القوالب Templates) لعرض تلك الصفحات. يوضح المخطط البياني الآتي التدفق الرئيسي للبيانات والأشياء التي يجب تقديمها عند التعامل مع طلب أو استجابة HTTP، ويُوضّح العروض والوجهات والمتحكّمات التي تمثل الدوال التي تفصل الشيفرة البرمجية لتوجيه الطلبات من هذه الشيفرة التي تعالج الطلبات فعليًا. أنشأنا النماذج مسبقًا، فالأشياء الرئيسية التي يجب إنشاؤها هي: "الوجهات Routes" لتوجيه الطلبات المدعومة وأيّ معلومات مُشفَّرة في عناوين URL للطلب إلى دوال المتحكم المناسبة. دوال المتحكم للحصول على البيانات المطلوبة من النماذج وإنشاء صفحة HTML تعرض البيانات وإعادتها إلى المستخدم لعرضها في المتصفح. العروض (القوالب) التي تستخدمها المتحكمات لتقديم البيانات. يمكن أن يكون لدينا في النهاية صفحات لإظهار القوائم والمعلومات التفصيلية للكتب وأنواعها والمؤلفين ونسخ الكتب، وصفحات لإنشاء السجلات وتحديثها وحذفها. تُعَد هذه المعلومات كثيرة لعرضها في مقال واحد، لذلك سيركز معظم هذا المقال على إعداد الوجهات والمتحكمات لإعادة محتوًى "وهمي"، وسنوسّع توابع المتحكم في مقالاتنا اللاحقة للعمل مع بيانات النموذج. يوفّر القسم الأول التالي نظرةً عامةً موجزة حول كيفية استخدام برمجية Express الوسيطة Router، ثم سنستخدم ذلك في الأقسام اللاحقة عند إعداد وجهات موقع المكتبة المحلية LocalLibrary. مقدمة إلى الوجهات الوجهة هي قسم من شيفرة Express التي تربط بين فعل HTTP، مثل GET و POST و PUT و DELETE وإلخ مع مسار أو نمط URL ودالة تُستدعى لمعالجة هذا النمط. هناك عدة طرق لإنشاء الوجهات، وسنستخدم في هذا المقال البرمجية الوسيطة express.Router لأنها تسمح بتجميع معالجات الوجهات لجزء معين من الموقع مع بعضها البعض والوصول إليها باستخدام بادئة prefix وجهة مشتركة. سنحتفظ بجميع الوجهات المتعلقة بالمكتبة في وحدة "دليل catalog"، وإذا أضفنا وجهات لمعالجة حسابات المستخدمين أو لدوال أخرى، فيمكننا الاحتفاظ بها مُجمَّعةً بصورة منفصلة. ملاحظة: ناقشنا سابقًا وجهات تطبيق Express باختصار في مقال سابق. يشبه استخدام كائن الموجّه Router إلى حدٍ كبير تعريف الوجهات مباشرةً في كائن تطبيق Express باستثناء تقديم دعم أفضل للتقسيم إلى وحدات Modularization (كما سننافش في القسم التالي). يوفر الجزء المتبقي من هذا القسم نظرةً عامة حول كيفية استخدام الكائن Router لتعريف الوجهات. تعريف واستخدام وحدات وجهة منفصلة تقدم الشيفرة البرمجية التالية مثالًا عن كيفية إنشاء وحدة وجهة ثم استخدامها في تطبيق Express. أولًا، ننشئ وجهات لميزة الويكي wiki في وحدة بالاسم "wiki.js"، إذ تستورد هذه الشيفرة البرمجية كائن تطبيق Express، وتستخدمه للحصول على كائن Router، ثم تضيف بعض الوجهات إليه باستخدام التابع get()، ثم تصدّر الوحدةُ الكائنَ Router. // wiki.js: وحدة وجهة ويكي Wiki const express = require("express"); const router = express.Router(); // وجهة الصفحة الرئيسية router.get("/", function (req, res) { res.send("Wiki home page"); }); // وجهة صفحة About router.get("/about", function (req, res) { res.send("About this wiki"); }); module.exports = router; ملاحظة: عرّفنا في الشيفرة السابقة دوال رد النداء Callbacks الخاصة بمعالج الوجهة مباشرةً في دوال وجهة، وسنعرّف في موقع المكتبة المحلية LocalLibrary دوال رد النداء هذه في متحكم وحدة منفصل. يمكن استخدام وحدة وجهة في ملف تطبيقنا الرئيسي من خلال طلب وحدة الوجهة (wiki.js) باستخدام الدالة require()، ثم استدعاء الدالة use() في تطبيق Express لإضافة كائن Router إلى مسار معالجة البرمجية الوسيطة مع تحديد مسار URL الخاص بالويكي "wiki". const wiki = require("./wiki.js"); // … app.use("/wiki", wiki); ويمكن بعد ذلك الوصول إلى الوجهتين المُعرَّفتين في وحدة وجهة wiki من /wiki/ و /wiki/about/. دوال الوجهة تعرّف الوحدة السابقة بعضًا من دوال الوجهة، إذ تُعرَّف الوجهة "about" (التي سنعيد إنتاجها فيما يلي) باستخدام التابع Router.get()، والذي يستجيب فقط لطلبات HTTP من النوع GET. الوسيط الأول لهذا التابع هو مسار URL والوسيط الثاني هو دالة رد نداء تُستدعَى عند تلقي طلب HTTP من النوع GET مع المسار. router.get("/about", function (req, res) { res.send("About this wiki"); }); تأخذ دالة رد النداء ثلاثة وسائط تُسمَّى عادة req و res و next، والتي ستحتوي على كائن طلب HTTP واستجابة HTTP والدالة التالية next في سلسلة البرمجيات الوسيطة. ملاحظة: تُعَد دوال Router برمجيات Express وسيطة، مما يعني أنها يجب إما إكمال (أو الاستجابة) للطلب أو استدعاء الدالة next في السلسلة، إذ نكمل في حالتنا الطلب باستخدام التابع send()، لذلك لا يُستخدَم الوسيط next ونختار عدم تحديده. تأخذ دالة router السابقة دالة رد نداء واحدة، ولكن يمكنك تحديد عدة وسائط لدوال رد النداء أو مصفوفة من دوال رد النداء. تُعَد كل دالة جزءًا من سلسلة البرمجيات الوسيطة، وستُستدعَى بالترتيب نفسه لإضافتها إلى السلسلة (إلّا إذا أكملت الدالة السابقة الطلب). تستدعي دالة رد النداء في مثالنا التابع send() في الاستجابة لإعادة السلسلة النصية "About this wiki" عندما نتلقى طلب GET مع المسار ("/about"). هناك عدد من توابع الاستجابة الأخرى لإنهاء دورة الطلب/الاستجابة، فمثلًا يمكنك استدعاء التابع res.json() لإرسال استجابة JSON أو التابع res.sendFile() لإرسال ملف. يُعَد التابع render() تابع الاستجابة الذي سنستخدمه غالبًا أثناء بناء المكتبة، والذي ينشئ ويعيد ملفات HTML باستخدام القوالب والبيانات (سنتحدث عن ذلك في مقالٍ لاحق). أفعال HTTP تستخدم أمثلة الوجهات السابقة التابع Router.get() للاستجابة على طلبات HTTP من النوع GET مع مسار معين. يوفّر الكائن Router أيضًا توابع وجهة لجميع أفعال HTTP الأخرى، والتي تُستخدَم غالبًا بنفس الطريقة تمامًا ومن هذه التوابع: post() و put() و delete() و options() و trace() و copy() و lock() و mkcol() و move() و purge() و propfind() و proppatch() و unlock() و report() و mkactivity() و checkout() و merge() و m-search() و notify() و subscribe() و unsubscribe() و patch() و search() و connect(). تتصرف الشيفرة البرمجية التالية مثلًا مثل وجهة /about السابقة، ولكنها تستجيب فقط لطلبات HTTP من النوع POST: router.post("/about", (req, res) => { res.send("About this wiki"); }); مسارات الوجهة تعرِّف مساراتُ الوجهة النقاطَ النهائية التي يمكن إجراء الطلبات عندها، فالأمثلة التي رأيناها حتى الآن كانت مجرد سلاسل نصية، واُستخدِمت كما هو مكتوب تمامًا مثل: '/' و '/about' و '/book' و '/any-random.path'. يمكن أن تكون مسارات الوجهة أيضًا أنماطًا من السلاسل النصية التي تستخدم شكلًا من صيغ التعابير النمطية لتعريف أنماط النقاط النهائية التي ستجري مطابقتها. نوضح فيما يلي هذه الصيغة (لاحظ تفسير الشَرطة الواصلة (-) والنقطة (.) حرفيًا باستخدام المسارات المستندة إلى السلاسل النصية): ?: يجب أن تحتوي النقطة النهائية endpoint على 0 أو 1 من المحرف السابق (أو المجموعة)، فمثلًا سيتطابق مسار الوجهة '/ab?cd' مع النقاط النهائية acd أو abcd. +: يجب أن تحتوي النقطة النهائية على واحد أو أكثر من المحرف السابق (أو المجموعة)، فمثلًا سيتطابق مسار الوجهة '/ab+cd' مع النقاط النهائية abcd و abbcd و abbbcd وإلخ. *: يمكن أن تحتوي النقطة النهائية على سلسلة نصية عشوائية في مكان المحرف *، فمثلًا سيتطابق مسار الوجهة '/ab*cd' مع النقاط النهائية abcd و abXcd و abSOMErandomTEXTcd وإلخ. (): تجميع تطابق مجموعة من المحارف لإجراء عملية أخرى عليها، فمثلًا سينفّذ '/ab(cd)?e' تطابق ? على المجموعة (cd)، إذ سيتطابق مع abe و abcde. يمكن أن تكون مسارات الوجهة أيضًا تعابير نمطية Regular Expressions في لغة جافا سكريبت JavaScript، فمثلًا سيتطابق مسار الوجهة التالي مع catfish و dogfish، ولكن لن يتطابق مع catflap و catfishhead وما إلى ذلك. لاحظ أن مسار التعبير النمطي يستخدم صياغة التعابير النمطية، وهي ليست سلسلة نصية بين علامات اقتباس كما في الحالات السابقة. app.get(/.*fish$/, function (req, res) { // … }); ملاحظة: ستستخدم معظم الوجهات في موقع المكتبة المحلية LocalLibrary سلاسلًا نصية ولن تستخدم تعابيرًا نمطية، وسنستخدم أيضًا معاملات الوجهات كما سنناقش في القسم التالي. معاملات الوجهة تُسمَّى معاملات الوجهة بأجزاء Segments عنوان URL المُستخدَمة لالتقاط القيم في مواضع محددة من عنوان URL، إذ تُسبَق هذه المقاطع بنقطتين ثم الاسم (مثل /:your_parameter_name/). تُخزَّن القيم المُلتقَطة في كائن req.params من خلال استخدام أسماء المعاملات بوصفها مفاتيحًا، مثل req.params.your_parameter_name. ليكن لدينا مثلًا عنوان URL مُشفَّر يحتوي على معلومات حول المستخدمين والكتب: http://localhost:3000/users/34/books/8989، إذ يمكننا استخراج هذه المعلومات كما هو موضح فيما يلي باستخدام معاملات مسار userId و bookId: app.get("/users/:userId/books/:bookId", (req, res) => { // الوصول إلى userId باستخدام req.params.userId // الوصول إلى bookId باستخدام req.params.bookId res.send(req.params); }); يجب أن تتكون أسماء معاملات الوجهة من "محارف كلمات"، أي A-Z و a-z و0-9 و _. ملاحظة: ستجري مطابقة عنوان "/book/create" مع وجهة مثل الوجهة /book/:bookId، والتي ستستخرج قيمة "bookId" الخاصة بالإنشاء 'create'. ستُستخدَم الوجهة الأولى التي تطابق عنوان URL الوارد، لذلك إذا أردتَ معالجة عناوين /book/create بصورة منفصلة، فيجب تعريف معالج الوجهة قبل الوجهة /book/:bookId. هذا كل ما تحتاجه لبدء استخدام الوجهات، ولكن يمكنك العثور على مزيد من المعلومات في مقال كيفية تحديد الوجهات وأنواع طلبات HTTP وفي توثيق Express: التوجيه الأساسي ودليل التوجيه. توضح الأقسام التالية كيفية إعداد الوجهات والمتحكمات لموقع المكتبة المحلية. معالجة الأخطاء في دوال الوجهة تحتوي جميع دوال الوجهة الموضحة سابقًا على وسائط req و res التي تمثل الطلب والاستجابة على التوالي. تُستدعَى دوال الوجهة أيضًا مع وسيط ثالث هو next، والذي يمكن استخدامه لتمرير الأخطاء إلى سلسلة برمجيات Express الوسيطة. توضح الشيفرة التالية كيفية إنجاز ذلك باستخدام مثال استعلام قاعدة البيانات الذي يأخذ دالة رد نداء ويعيد إما خطأ err أو بعض النتائج. تُستدعَى next مع خطأ err بوصفه قيمة معاملها الأول عند إعادة خطأ err، وسينتقل هذا الخطأ في النهاية إلى شيفرة معالجة الأخطاء العامة، وتُعاد البيانات المطلوبة ثم تُستخدَم في الاستجابة في حالة النجاح. router.get("/about", (req, res, next) => { About.find({}).exec((err, queryResults) => { if (err) { return next(err); } // اعرض شيئًا ما في حالة النجاح res.render("about_view", { title: "About", list: queryResults }); }); }); معالجة الاستثناءات في دوال الوجهة يوضح القسم السابق كيف يتوقع إطار عمل Express أن تعيد دوال الوجهة أخطاءً، إذ صُمِّم إطار العمل للاستخدام مع الدوال غير المتزامنة التي تأخذ دالة رد نداء (مع خطأ وووسيط النتيجة)، والتي تُستدعَى عند اكتمال العملية. يُعَد ذلك مشكلة لأننا سنجري لاحقًا استعلامات قاعدة بيانات Mongoose التي تستخدم واجهات برمجة تطبيقات مستندة إلى الوعود promise، والتي يمكن أن تؤدي إلى رمي استثناءات في دوال الوجهة بدلًا من إعادة الأخطاء في دالة رد النداء. يمكن أن يعالج إطار العمل الاستثناءات بصورة صحيحة من خلال اكتشافها ثم توجيهها بوصفها أخطاءً كما هو موضح في القسم السابق. ملاحظة: من المتوقع أن يعالج Express 5 التجريبي استثناءات جافا سكريبت بطريقة أصيلة. ليكن لدينا المثال البسيط من القسم السابق مع وجود About.find().exec() بوصفه استعلام قاعدة بيانات يعيد وعدًا، إذ يمكن كتابة دالة الوجهة ضمن كتلة try...catch كما يلي: exports.get("/about", async function (req, res, next) { try { const successfulResult = await About.find({}).exec(); res.render("about_view", { title: "About", list: successfulResult }); } catch (error) { return next(error); } }); يُعَد ذلك كمًا كبيرًا جدًا من الشيفرة البرمجية المتداولة لإضافتها إلى كل دالة، لذا سنستخدم بدلًا من ذلك وحدة express-async-handler التي تعرّف دالة تغليف تخفي كتلة try...catch والشيفرة البرمجية لتوجيه الخطأ، وبالتالي أصبح المثال نفسه الآن بسيطًا جدًا، لأننا نحتاج فقط إلى كتابة شيفرة برمجية للحالة التي نفترض فيها النجاح: // استيراد الوحدة const asyncHandler = require("express-async-handler"); exports.get( "/about", asyncHandler(async (req, res, next) => { const successfulResult = await About.find({}).exec(); res.render("about_view", { title: "About", list: successfulResult }); }), ); الوجهات اللازمة لموقع المكتبة المحلية سنعرض فيما يلي عناوين URL التي سنحتاجها لصفحاتنا، إذ نضع اسم كل نموذج من نماذجنا (الكتاب ونسخة الكتاب ونوع الكتاب والمؤلف) مكان الكائن object، والكائنات objects هي جمع كائن، والمعرّف id هو نسخة فريدة من الحقل (_id) تُعطَى لكل نسخة من نموذج Mongoose افتراضيًا. catalog/: الصفحة الرئيسية أو صفحة الفهرس. catalog/<objects>/: قائمة بجميع الكتب أو نسخها أو أنواعها أو المؤلفين، مثل /catalog/books/ و /catalog/genres/ وغير ذلك. catalog/<object>/<id>: صفحة التفاصيل لكتاب أو نسخة أو نوع أو مؤلف معين مع قيمة الحقل _id المُحدَّدة، مثل /catalog/book/584493c1f4887f06c0e67d37. catalog/<object>/create: استمارة إنشاء كتاب أو نسخة أو نوع أو مؤلف جديد، مثل /catalog/book/create. catalog/<object>/<id>/update: استمارة لتحديث كتاب أو نسخة أو نوع أو مؤلف معين مع قيمة الحقل _id المُحدَّدة، مثل /catalog/book/584493c1f4887f06c0e67d37/update. catalog/<object>/<id>/delete: استمارة لحذف كتاب أو نسخة أو نوع أو مؤلف معين مع قيمة الحقل _id المُحدَّدة، مثل /catalog/book/584493c1f4887f06c0e67d37/delete. لا تشفِّر الصفحة الرئيسية الأولى وصفحات القائمة أيّ معلومات إضافية، فبينما تعتمد النتائج المُعادة على نوع النموذج والمحتوى في قاعدة البيانات، ستبقى الاستعلامات المُنفَّذة للحصول على المعلومات نفسها دائمًا، وبالمثل، ستكون الشيفرة البرمجية المُنفَّذة لإنشاء الكائن نفسها دائمًا. تُستخدَم عناوين URL الأخرى للعمل على نسخةٍ من مستند أو نموذج معين، وتشفّر هوية العنصر في عنوان URL (كما هو موضّح في العنصر <id> سابقًا). سنستخدم معاملات المسار لاستخراج المعلومات المشفرة وتمريرها إلى معالج الوجهة، وسنستخدمها في مقال لاحق لتحديد المعلومات التي نحصل عليها من قاعدة البيانات ديناميكيًا. نحتاج فقط إلى وجهة واحدة لكل مورد من نوع معين من خلال تشفير المعلومات في عنوان URL، مثل استخدام وجهة واحدة للتعامل مع عرض عنصر كتاب واحد. ملاحظة: يسمح إطار عمل Express بإنشاء عناوين URL الخاصة بك بالطريقة التي تريدها، إذ يمكنك تشفير المعلومات في متن عنوان URL أو استخدام معاملات URL من النوع GET (مثل /book/?id=6). يجب أن تظل عناوين URL نظيفة ومنطقية وقابلة للقراءة بغض النظر عن الطريقة التي تستخدمها. سننشئ فيما يلي دوال رد نداء معالجة الوجهة وشيفرة الوجهة البرمجية لجميع عناوين URL السابقة. إنشاء دوال رد النداء لمعالجة الوجهة سننشئ أولًا جميع دوال رد النداء الوهمية أو الهيكلية التي ستُستدعَى لاحقًا قبل أن نعرّف الوجهات، وستُخزَّن دوال رد النداء في وحدات متحكمات منفصلة لكل من Book و BookInstance و Genre و Author، إذ يمكنك استخدام أي بنية ملفات أو وحدات، ولكن تبدو الطريقة التي سنستخدمها مناسبة ودقيقة لهذا المشروع. ابدأ بإنشاء مجلدٍ للمتحكمات في جذر المشروع /controllers، ثم أنشئ ملفات أو وحدات منفصلة للمتحكمات للتعامل مع كل نموذج كما يلي: /express-locallibrary-tutorial //the project root /controllers authorController.js bookController.js bookinstanceController.js genreController.js ستستخدم المتحكمات الوحدة express-async-handler، لذا ثبّتها في المكتبة باستخدام npm قبل المتابعة كما يلي: npm install --save express-async-handler متحكم المؤلف Author افتح الملف "/controllers/authorController.js" واكتب فيه الشيفرة البرمجية التالية: const Author = require("../models/author"); const asyncHandler = require("express-async-handler"); // عرض قائمة بجميع المؤلفين exports.author_list = asyncHandler(async (req, res, next) => { res.send("NOT IMPLEMENTED: Author list"); }); // عرض صفحة التفاصيل لمؤلف معين exports.author_detail = asyncHandler(async (req, res, next) => { res.send(`NOT IMPLEMENTED: Author detail: ${req.params.id}`); }); // عرض استمارة إنشاء مؤلف باستخدام GET exports.author_create_get = asyncHandler(async (req, res, next) => { res.send("NOT IMPLEMENTED: Author create GET"); }); // معالجة إنشاء مؤلف باستخدام POST exports.author_create_post = asyncHandler(async (req, res, next) => { res.send("NOT IMPLEMENTED: Author create POST"); }); // عرض استمارة حذف المؤلف باستخدام GET exports.author_delete_get = asyncHandler(async (req, res, next) => { res.send("NOT IMPLEMENTED: Author delete GET"); }); // معالجة حذف المؤلف باستخدام POST exports.author_delete_post = asyncHandler(async (req, res, next) => { res.send("NOT IMPLEMENTED: Author delete POST"); }); // عرض استمارة تحديث المؤلف باستخدام GET exports.author_update_get = asyncHandler(async (req, res, next) => { res.send("NOT IMPLEMENTED: Author update GET"); }); // معالجة تحديث المؤلف باستخدام POST exports.author_update_post = asyncHandler(async (req, res, next) => { res.send("NOT IMPLEMENTED: Author update POST"); }); تطلب الوحدة أولًا نموذج المؤلف Author الذي سنستخدمه لاحقًا للوصول إلى بياناتنا وتحديثها، والمغلِّف asyncHandler الذي سنستخدمه لالتقاط الاستثناءات من دوال معالج الوجهة، ثم تصدِّر دوالًا لكل عنوان من عناوين URL التي نرغب في معالجتها. لاحظ أن عمليات الإنشاء والتحديث والحذف تستخدم الاستمارات Forms، وبالتالي تملك توابعًا إضافية لمعالجة طلبات الاستمارة من النوع Post، وسنناقش هذه التوابع في مقال لاحق. تستخدم جميع الدوال الدالة المُغلِّفة Wrapper السابقة في معالجة الاستثناءات في دوال الوجهة مع وسائط للطلب والاستجابة والدالة التالية next، وتستجيب الدوال بسلسلة نصية تشير إلى أن الصفحة المرتبطة لم تُنشَأ بعد. إذا كان من المتوقع أن تتلقى دالة المتحكم معاملات المسار، فستكون هذه المعاملات هي الخرج الموجود في سلسلة الرسالة النصية (لاحظ req.params.id). لاحظ أنه يمكن ألّا تحتوي بعض دوال الوجهة بعد تقديمها على أي شيفرة برمجية يمكنها أن ترمي استثناءات، ولكن يمكننا تغيير تلك الدوال إلى دوال معالجة وجهة عادية عند الوصول إليها. متحكم نسخة الكتاب BookInstance افتح الملف /controllers/bookinstanceController.js وانسخ الشيفرة البرمجية التالية التي تتبع نمطًا مطابقًا لوحدة المتحكم Author: const BookInstance = require("../models/bookinstance"); const asyncHandler = require("express-async-handler"); // عرض قائمة بجميع نسخ الكتب BookInstance exports.bookinstance_list = asyncHandler(async (req, res, next) => { res.send("NOT IMPLEMENTED: BookInstance list"); }); // عرض صفحة تفاصيل نسخة كتاب BookInstance معينة exports.bookinstance_detail = asyncHandler(async (req, res, next) => { res.send(`NOT IMPLEMENTED: BookInstance detail: ${req.params.id}`); }); // عرض استمارة إنشاء نسخة الكتاب BookInstance باستخدام GET exports.bookinstance_create_get = asyncHandler(async (req, res, next) => { res.send("NOT IMPLEMENTED: BookInstance create GET"); }); // معالجة إنشاء نسخة كتاب BookInstance باستخدام POST exports.bookinstance_create_post = asyncHandler(async (req, res, next) => { res.send("NOT IMPLEMENTED: BookInstance create POST"); }); // عرض استمارة حذف نسخة كتاب BookInstance باستخدام GET exports.bookinstance_delete_get = asyncHandler(async (req, res, next) => { res.send("NOT IMPLEMENTED: BookInstance delete GET"); }); // معالجة حذف نسخة كتاب BookInstance باستخدام POST exports.bookinstance_delete_post = asyncHandler(async (req, res, next) => { res.send("NOT IMPLEMENTED: BookInstance delete POST"); }); // عرض استمارة تحديث نسخة كتاب BookInstance باستخدام GET exports.bookinstance_update_get = asyncHandler(async (req, res, next) => { res.send("NOT IMPLEMENTED: BookInstance update GET"); }); // معالجة تحديث نسخة الكتاب باستخدام POST exports.bookinstance_update_post = asyncHandler(async (req, res, next) => { res.send("NOT IMPLEMENTED: BookInstance update POST"); }); متحكم نوع الكتاب Genre افتح الملف /controllers/genreController.js والصق فيه النص التالي الذي يتبع نمطًا مطابقًا لملفات Author و BookInstance: const Genre = require("../models/genre"); const asyncHandler = require("express-async-handler"); // عرض قائمة بجميع أنواع الكتب Genre exports.genre_list = asyncHandler(async (req, res, next) => { res.send("NOT IMPLEMENTED: Genre list"); }); // عرض صفحة تفاصيل نوع كتاب Genre معين exports.genre_detail = asyncHandler(async (req, res, next) => { res.send(`NOT IMPLEMENTED: Genre detail: ${req.params.id}`); }); // عرض استمارة إنشاء نوع الكتاب Genre باستخدام GET exports.genre_create_get = asyncHandler(async (req, res, next) => { res.send("NOT IMPLEMENTED: Genre create GET"); }); // معالجة إنشاء نوع كتاب Genre باستخدام POST exports.genre_create_post = asyncHandler(async (req, res, next) => { res.send("NOT IMPLEMENTED: Genre create POST"); }); // عرض استمارة حذف نوع كتاب Genre باستخدام GET exports.genre_delete_get = asyncHandler(async (req, res, next) => { res.send("NOT IMPLEMENTED: Genre delete GET"); }); // معالجة حذف نوع كتاب Genre باستخدام POST exports.genre_delete_post = asyncHandler(async (req, res, next) => { res.send("NOT IMPLEMENTED: Genre delete POST"); }); // عرض استمارة تحديث نوع كتاب Genre باستخدام GET exports.genre_update_get = asyncHandler(async (req, res, next) => { res.send("NOT IMPLEMENTED: Genre update GET"); }); // معالجة تحديث نوع كتاب Genre باستخدام POST exports.genre_update_post = asyncHandler(async (req, res, next) => { res.send("NOT IMPLEMENTED: Genre update POST"); }); متحكم الكتاب Book افتح الملف /controllers/bookController.js وانسخ الشيفرة البرمجية التالية، إذ يتبع هذا الملف النمط المتبع نفسه في وحدات المتحكمات الأخرى، ولكنه يحتوي أيضًا على الدالة index() لعرض صفحة الترحيب بالموقع: const Book = require("../models/book"); const asyncHandler = require("express-async-handler"); exports.index = asyncHandler(async (req, res, next) => { res.send("NOT IMPLEMENTED: Site Home Page"); }); // عرض قائمة بجميع الكتب exports.book_list = asyncHandler(async (req, res, next) => { res.send("NOT IMPLEMENTED: Book list"); }); // عرض صفحة تفاصيل كتاب معين exports.book_detail = asyncHandler(async (req, res, next) => { res.send(`NOT IMPLEMENTED: Book detail: ${req.params.id}`); }); // عرض استمارة إنشاء كتاب باستخدام GET exports.book_create_get = asyncHandler(async (req, res, next) => { res.send("NOT IMPLEMENTED: Book create GET"); }); // معالجة إنشاء كتاب باستخدام POST exports.book_create_post = asyncHandler(async (req, res, next) => { res.send("NOT IMPLEMENTED: Book create POST"); }); // عرض استمارة حذف كتاب باستخدام GET exports.book_delete_get = asyncHandler(async (req, res, next) => { res.send("NOT IMPLEMENTED: Book delete GET"); }); // معالجة حذف كتاب باستخدام POST exports.book_delete_post = asyncHandler(async (req, res, next) => { res.send("NOT IMPLEMENTED: Book delete POST"); }); // عرض استمارة تحديث كتاب باستخدام GET exports.book_update_get = asyncHandler(async (req, res, next) => { res.send("NOT IMPLEMENTED: Book update GET"); }); // معالجة تحديث كتاب باستخدام POST exports.book_update_post = asyncHandler(async (req, res, next) => { res.send("NOT IMPLEMENTED: Book update POST"); }); إنشاء دليل وحدات الوجهة سننشئ الآن وجهات لجميع عناوين URL التي يحتاجها موقع المكتبة المحلية LocalLibrary، والتي ستستدعي دوال المتحكمات التي عرّفناها في الأقسام السابقة. تحتوي البنية الهيكلية للموقع مسبقًا على المجلد "./routes" الذي يحتوي على وجهات لصفحة الفهرس index والمستخدمين users. أنشئ ملف وجهة آخر هو catalog.js ضمن هذا المجلد كما يلي: /express-locallibrary-tutorial //the project root /routes index.js users.js catalog.js افتح الملف /routes/catalog.js وانسخ الشيفرة البرمجية التالية: const express = require("express"); const router = express.Router(); // طلب وحدات المتحكمات const book_controller = require("../controllers/bookController"); const author_controller = require("../controllers/authorController"); const genre_controller = require("../controllers/genreController"); const book_instance_controller = require("../controllers/bookinstanceController"); /// وجهات الكتاب /// // الحصول على صفحة الدليل الرئيسية router.get("/", book_controller.index); // طلب GET لإنشاء كتاب. يجب أن يأتي هذا الطلب قبل الوجهات Routes التي تعرض الكتاب (يستخدم المعرّف id) router.get("/book/create", book_controller.book_create_get); // طلب POST لإنشاء كتاب router.post("/book/create", book_controller.book_create_post); // طلب GET لحذف كتاب router.get("/book/:id/delete", book_controller.book_delete_get); // طلب POST لحذف كتاب router.post("/book/:id/delete", book_controller.book_delete_post); // طلب GET لتحديث كتاب router.get("/book/:id/update", book_controller.book_update_get); // طلب POST لتحديث كتاب router.post("/book/:id/update", book_controller.book_update_post); // طلب GET لكتاب واحد router.get("/book/:id", book_controller.book_detail); // طلب GET لقائمة جميع عناصر الكتب router.get("/books", book_controller.book_list); /// وجهات المؤلف /// // طلب GET لإنشاء مؤلف Author. يجب أن يأتي هذا الطلب قبل وجهة المعرّف (مثل عرض مؤلف) router.get("/author/create", author_controller.author_create_get); // طلب POST لإنشاء مؤلف router.post("/author/create", author_controller.author_create_post); // طلب GET لحذف مؤلف router.get("/author/:id/delete", author_controller.author_delete_get); // طلب POST لحذف مؤلف router.post("/author/:id/delete", author_controller.author_delete_post); // طلب GET لتحديث مؤلف router.get("/author/:id/update", author_controller.author_update_get); // طلب POST لتحديث مؤلف router.post("/author/:id/update", author_controller.author_update_post); // طلب GET لمؤلف واحد router.get("/author/:id", author_controller.author_detail); // طلب GET لقائمة جميع المؤلفين router.get("/authors", author_controller.author_list); /// وجهات نوع الكتاب GENRE /// // طلب GET لإنشاء نوع كتاب. يجب أن يأتي هذا الطلب قبل الوجهة التي تعرض نوع الكتاب (يستخدم المعرّف) router.get("/genre/create", genre_controller.genre_create_get); // طلب POST لإنشاء نوع كتاب router.post("/genre/create", genre_controller.genre_create_post); // طلب GET لحذف نوع كتاب router.get("/genre/:id/delete", genre_controller.genre_delete_get); // طلب POST لحذف نوع كتاب router.post("/genre/:id/delete", genre_controller.genre_delete_post); // طلب GET لتحديث نوع كتاب router.get("/genre/:id/update", genre_controller.genre_update_get); // طلب POST لتحديث نوع كتاب router.post("/genre/:id/update", genre_controller.genre_update_post); // طلب GET لنوع كتاب واحد router.get("/genre/:id", genre_controller.genre_detail); // طلب GET لقائمة جميع أنواع الكتب router.get("/genres", genre_controller.genre_list); /// طرق نسخ الكتب BOOKINSTANCE /// // طلب GET لإنشاء نسخة كتاب BookInstance. يجب أن يأتي هذا الطلب قبل الوجهة التي تعرض نسخة الكتاب (يستخدم المعرّف) router.get( "/bookinstance/create", book_instance_controller.bookinstance_create_get, ); // طلب POST لإنشاء نسخة كتاب router.post( "/bookinstance/create", book_instance_controller.bookinstance_create_post, ); // طلب GET لحذف نسخة كتاب router.get( "/bookinstance/:id/delete", book_instance_controller.bookinstance_delete_get, ); // طلب POST لحذف نسخة كتاب router.post( "/bookinstance/:id/delete", book_instance_controller.bookinstance_delete_post, ); // طلب GET لتحديث نسخة الكتاب router.get( "/bookinstance/:id/update", book_instance_controller.bookinstance_update_get, ); // طلب POST لتحديث نسخة كتاب router.post( "/bookinstance/:id/update", book_instance_controller.bookinstance_update_post, ); // طلب GET لنسخة كتاب واحدة router.get("/bookinstance/:id", book_instance_controller.bookinstance_detail); // طلب GET لقائمة جميع نسخ الكتاب router.get("/bookinstances", book_instance_controller.bookinstance_list); module.exports = router; تطلب الوحدة كائن Express ثم تستخدمه لإنشاء كائن Router، إذ تُضبَط جميع الوجهات في هذا الكائن الذي يُصدَّر لاحقًا. تُعرّف الوجهات إما باستخدام تابع .get() أو تابع .post() للكائن Router، وتُعرّف جميع المسارات باستخدام سلاسل نصية، إذ لا نستخدم أنماط سلاسل نصية أو تعابيرًا نمطية. تستخدم الوجهات التي تعمل على بعض الموارد المحددة (مثل الكتاب) معاملاتِ المسار للحصول على معرّف الكائن من عنوان URL، وتُستورَد جميع دوال المعالجة من وحدات المتحكمات التي أنشأناها في القسم السابق. تحديث وحدة وجهة صفحة الفهرس ضبطنا جميع وجهاتنا الجديدة، ولكن لا يزال لدينا الوجهة إلى الصفحة الأصلية، ولكن لنعيد التوجيه إلى صفحة الفهرس الجديدة التي أنشأناها في المسار '/catalog' بدلًا من ذلك. افتح الملف /routes/index.js وضع الدالة التالية بدلًا من الوجهة الحالية: // الحصول على الصفحة الرئيسية router.get("/", function (req, res) { res.redirect("/catalog"); }); ملاحظة: استخدمنا تابع الاستجابة redirect() الذي يؤدي إلى إعادة التوجيه إلى الصفحة المحددة، مع إرسال رمز حالة HTTP الذي هو "302 Found" افتراضيًا، ويمكنك تغيير رمز الحالة المُعاد إن لزم الأمر وتوفير مسارات مطلقة أو نسبية. يمكنك الاطلاع على مقال رموز الإجابة في HTTP والمقال كيفية استكشاف وإصلاح رموز أخطاء HTTP الشائعةعلى أكاديمية حسوب لمزيدٍ من المعلومات حول رموز حالة HTTP. تحديث الملف app.js تتمثل الخطوة الأخيرة في إضافة الوجهات إلى سلسلة البرمجيات الوسيطة في الملف app.js، لذا افتح هذا الملف، واطلب وجهة الدليل بعد الوجهات الأخرى من خلال إضافة السطر الثالث التالي بعد السطرين الآخرين الموجودين مسبقًا في الملف: var indexRouter = require("./routes/index"); var usersRouter = require("./routes/users"); const catalogRouter = require("./routes/catalog"); // استيراد الوجهات لمنطقة "الدليل" في الموقع ضِف بعد ذلك وجهة الدليل catalog إلى مكدس البرمجيات الوسيطة بعد الوجهات الأخرى من خلال إضافة السطر الثالث التالي بعد السطرين الآخرين الموجودين مسبقًا في الملف: app.use("/", indexRouter); app.use("/users", usersRouter); app.use("/catalog", catalogRouter); // إضافة وجهات الدليل إلى سلسلة البرمجيات الوسيطة ملاحظة: أضفنا وحدة دليلنا في المسار '/catalog' الذي سيكون البادئة لجميع المسارات المحدَّدة في وحدة الدليل، فمثلًا سيكون عنوان URL هو /catalog/books/ للوصول إلى قائمة الكتب. يجب أن يكون لدينا الآن مسارات ودوال هيكلية مُفعَّلة لجميع عناوين URL التي سندعمها في موقع المكتبة المحلية LocalLibrary. اختبار الوجهات أولًا، ابدأ تشغيل موقع الويب بالطريقة المعتادة، فالطريقة الافتراضية في أنظمة التشغيل هي: // نظام ويندوز SET DEBUG=express-locallibrary-tutorial:* & npm start // ماك أو لينكس DEBUG=express-locallibrary-tutorial:* npm start ولكن إذا سبق لك إعداد nodemon، فيمكنك بدلًا من ذلك استخدام ما يلي: npm run serverstart انتقل بعد ذلك إلى عدد من عناوين URL الخاصة بموقع المكتبة المحلية LocalLibrary وتحقق من عدم ظهور صفحة خطأ (HTTP 404). إليك مجموعة صغيرة من عناوين URL: http://localhost:3000/ http://localhost:3000/catalog http://localhost:3000/catalog/books http://localhost:3000/catalog/bookinstances/ http://localhost:3000/catalog/authors/ http://localhost:3000/catalog/genres/ http://localhost:3000/catalog/book/5846437593935e2f8c2aa226 http://localhost:3000/catalog/book/create الخلاصة أنشأنا جميع الوجهات الخاصة بموقعنا، مع دوال المتحكمات الوهمية التي يمكننا ملؤها بتقديم كامل في مقالات لاحقة، وتعلمنا الكثير من المعلومات الأساسية حول وجهات Express والتعامل مع الاستثناءات وبعض الأساليب لبناء الوجهات والمتحكمات. سننشئ في المقال التالي صفحة ترحيب مناسبة للموقع باستخدام العروض (القوالب) والمعلومات المخزنة في نماذجنا، وسننشئ استمارات HTML وشيفرة معالجة الاستمارات لبدء تعديل البيانات التي يخزنها الموقع. ترجمة -وبتصرُّف- للمقال Express Tutorial Part 4: Routes and controllers. اقرأ أيضًا المقال السابق تطبيق عملي لتعلم Express - الجزء الثاني: استخدام قاعدة البيانات باستخدام مكتبة Mongoose. إنشاء خادم ويب في Node.js باستخدام الوحدة HTTP. المتحكّمات Controllers والعروض Views في إطار العمل Rails.
سنُعِدّ في هذا المقال الوجهات Routes (شيفرة معالجة عناوين URL، ويسميها البعض بالموجهات) باستخدام دوال معالجة وهمية dummy لجميع النقاط النهائية للموارد التي سنحتاجها في موقع المكتبة المحلية LocalLibrary. سيكون لدينا في النهاية بنية معيارية لشيفرة معالجة الوجهات، والتي يمكننا توسيعها باستخدام دوال معالجة حقيقية في المقالات اللاحقة، وسيصبح لدينا أيضًا فهم جيد لكيفية إنشاء وجهات معيارية باستخدام إطار عمل Express. المتطلبات الأساسية: الاطلاع على مقال مدخل إلى إطار عمل الويب Express، وإكمال المقالات السابقة من هذه السلسلة بما في ذلك مقال استخدام قاعدة البيانات. الهدف: فهم كيفية إنشاء وجهات بسيطة وإعداد جميع النقاط النهائية لعناوين URL. تعرّفنا في المقال السابق على نماذج Mongoose للتفاعل مع قاعدة البيانات، واستخدمنا سكربتًا مستقلًا لإنشاء بعض سجلات المكتبة الأولية، ويمكننا الآن كتابة الشيفرة البرمجية لتقديم تلك المعلومات للمستخدمين. يجب أولًا تحديد المعلومات التي نريد عرضها في صفحاتنا، ثم تعريف عناوين URL المناسبة لإعادة تلك الموارد، ثم يجب إنشاء الوجهات (معالجات عناوين URL) والعروض Views (القوالب Templates) لعرض تلك الصفحات. يوضح المخطط البياني الآتي التدفق الرئيسي للبيانات والأشياء التي يجب تقديمها عند التعامل مع طلب أو استجابة HTTP، ويُوضّح العروض والوجهات والمتحكّمات التي تمثل الدوال التي تفصل الشيفرة البرمجية لتوجيه الطلبات من هذه الشيفرة التي تعالج الطلبات فعليًا. أنشأنا النماذج مسبقًا، فالأشياء الرئيسية التي يجب إنشاؤها هي: "الوجهات Routes" لتوجيه الطلبات المدعومة وأيّ معلومات مُشفَّرة في عناوين URL للطلب إلى دوال المتحكم المناسبة. دوال المتحكم للحصول على البيانات المطلوبة من النماذج وإنشاء صفحة HTML تعرض البيانات وإعادتها إلى المستخدم لعرضها في المتصفح. العروض (القوالب) التي تستخدمها المتحكمات لتقديم البيانات. يمكن أن يكون لدينا في النهاية صفحات لإظهار القوائم والمعلومات التفصيلية للكتب وأنواعها والمؤلفين ونسخ الكتب، وصفحات لإنشاء السجلات وتحديثها وحذفها. تُعَد هذه المعلومات كثيرة لعرضها في مقال واحد، لذلك سيركز معظم هذا المقال على إعداد الوجهات والمتحكمات لإعادة محتوًى "وهمي"، وسنوسّع توابع المتحكم في مقالاتنا اللاحقة للعمل مع بيانات النموذج. يوفّر القسم الأول التالي نظرةً عامةً موجزة حول كيفية استخدام برمجية Express الوسيطة Router، ثم سنستخدم ذلك في الأقسام اللاحقة عند إعداد وجهات موقع المكتبة المحلية LocalLibrary. مقدمة إلى الوجهات الوجهة هي قسم من شيفرة Express التي تربط بين فعل HTTP، مثل GET و POST و PUT و DELETE وإلخ مع مسار أو نمط URL ودالة تُستدعى لمعالجة هذا النمط. هناك عدة طرق لإنشاء الوجهات، وسنستخدم في هذا المقال البرمجية الوسيطة express.Router لأنها تسمح بتجميع معالجات الوجهات لجزء معين من الموقع مع بعضها البعض والوصول إليها باستخدام بادئة prefix وجهة مشتركة. سنحتفظ بجميع الوجهات المتعلقة بالمكتبة في وحدة "دليل catalog"، وإذا أضفنا وجهات لمعالجة حسابات المستخدمين أو لدوال أخرى، فيمكننا الاحتفاظ بها مُجمَّعةً بصورة منفصلة. ملاحظة: ناقشنا سابقًا وجهات تطبيق Express باختصار في مقال سابق. يشبه استخدام كائن الموجّه Router إلى حدٍ كبير تعريف الوجهات مباشرةً في كائن تطبيق Express باستثناء تقديم دعم أفضل للتقسيم إلى وحدات Modularization (كما سننافش في القسم التالي). يوفر الجزء المتبقي من هذا القسم نظرةً عامة حول كيفية استخدام الكائن Router لتعريف الوجهات. تعريف واستخدام وحدات وجهة منفصلة تقدم الشيفرة البرمجية التالية مثالًا عن كيفية إنشاء وحدة وجهة ثم استخدامها في تطبيق Express. أولًا، ننشئ وجهات لميزة الويكي wiki في وحدة بالاسم "wiki.js"، إذ تستورد هذه الشيفرة البرمجية كائن تطبيق Express، وتستخدمه للحصول على كائن Router، ثم تضيف بعض الوجهات إليه باستخدام التابع get()، ثم تصدّر الوحدةُ الكائنَ Router. // wiki.js: وحدة وجهة ويكي Wiki const express = require("express"); const router = express.Router(); // وجهة الصفحة الرئيسية router.get("/", function (req, res) { res.send("Wiki home page"); }); // وجهة صفحة About router.get("/about", function (req, res) { res.send("About this wiki"); }); module.exports = router; ملاحظة: عرّفنا في الشيفرة السابقة دوال رد النداء Callbacks الخاصة بمعالج الوجهة مباشرةً في دوال وجهة، وسنعرّف في موقع المكتبة المحلية LocalLibrary دوال رد النداء هذه في متحكم وحدة منفصل. يمكن استخدام وحدة وجهة في ملف تطبيقنا الرئيسي من خلال طلب وحدة الوجهة (wiki.js) باستخدام الدالة require()، ثم استدعاء الدالة use() في تطبيق Express لإضافة كائن Router إلى مسار معالجة البرمجية الوسيطة مع تحديد مسار URL الخاص بالويكي "wiki". const wiki = require("./wiki.js"); // … app.use("/wiki", wiki); ويمكن بعد ذلك الوصول إلى الوجهتين المُعرَّفتين في وحدة وجهة wiki من /wiki/ و /wiki/about/. دوال الوجهة تعرّف الوحدة السابقة بعضًا من دوال الوجهة، إذ تُعرَّف الوجهة "about" (التي سنعيد إنتاجها فيما يلي) باستخدام التابع Router.get()، والذي يستجيب فقط لطلبات HTTP من النوع GET. الوسيط الأول لهذا التابع هو مسار URL والوسيط الثاني هو دالة رد نداء تُستدعَى عند تلقي طلب HTTP من النوع GET مع المسار. router.get("/about", function (req, res) { res.send("About this wiki"); }); تأخذ دالة رد النداء ثلاثة وسائط تُسمَّى عادة req و res و next، والتي ستحتوي على كائن طلب HTTP واستجابة HTTP والدالة التالية next في سلسلة البرمجيات الوسيطة. ملاحظة: تُعَد دوال Router برمجيات Express وسيطة، مما يعني أنها يجب إما إكمال (أو الاستجابة) للطلب أو استدعاء الدالة next في السلسلة، إذ نكمل في حالتنا الطلب باستخدام التابع send()، لذلك لا يُستخدَم الوسيط next ونختار عدم تحديده. تأخذ دالة router السابقة دالة رد نداء واحدة، ولكن يمكنك تحديد عدة وسائط لدوال رد النداء أو مصفوفة من دوال رد النداء. تُعَد كل دالة جزءًا من سلسلة البرمجيات الوسيطة، وستُستدعَى بالترتيب نفسه لإضافتها إلى السلسلة (إلّا إذا أكملت الدالة السابقة الطلب). تستدعي دالة رد النداء في مثالنا التابع send() في الاستجابة لإعادة السلسلة النصية "About this wiki" عندما نتلقى طلب GET مع المسار ("/about"). هناك عدد من توابع الاستجابة الأخرى لإنهاء دورة الطلب/الاستجابة، فمثلًا يمكنك استدعاء التابع res.json() لإرسال استجابة JSON أو التابع res.sendFile() لإرسال ملف. يُعَد التابع render() تابع الاستجابة الذي سنستخدمه غالبًا أثناء بناء المكتبة، والذي ينشئ ويعيد ملفات HTML باستخدام القوالب والبيانات (سنتحدث عن ذلك في مقالٍ لاحق). أفعال HTTP تستخدم أمثلة الوجهات السابقة التابع Router.get() للاستجابة على طلبات HTTP من النوع GET مع مسار معين. يوفّر الكائن Router أيضًا توابع وجهة لجميع أفعال HTTP الأخرى، والتي تُستخدَم غالبًا بنفس الطريقة تمامًا ومن هذه التوابع: post() و put() و delete() و options() و trace() و copy() و lock() و mkcol() و move() و purge() و propfind() و proppatch() و unlock() و report() و mkactivity() و checkout() و merge() و m-search() و notify() و subscribe() و unsubscribe() و patch() و search() و connect(). تتصرف الشيفرة البرمجية التالية مثلًا مثل وجهة /about السابقة، ولكنها تستجيب فقط لطلبات HTTP من النوع POST: router.post("/about", (req, res) => { res.send("About this wiki"); }); مسارات الوجهة تعرِّف مساراتُ الوجهة النقاطَ النهائية التي يمكن إجراء الطلبات عندها، فالأمثلة التي رأيناها حتى الآن كانت مجرد سلاسل نصية، واُستخدِمت كما هو مكتوب تمامًا مثل: '/' و '/about' و '/book' و '/any-random.path'. يمكن أن تكون مسارات الوجهة أيضًا أنماطًا من السلاسل النصية التي تستخدم شكلًا من صيغ التعابير النمطية لتعريف أنماط النقاط النهائية التي ستجري مطابقتها. نوضح فيما يلي هذه الصيغة (لاحظ تفسير الشَرطة الواصلة (-) والنقطة (.) حرفيًا باستخدام المسارات المستندة إلى السلاسل النصية): ?: يجب أن تحتوي النقطة النهائية endpoint على 0 أو 1 من المحرف السابق (أو المجموعة)، فمثلًا سيتطابق مسار الوجهة '/ab?cd' مع النقاط النهائية acd أو abcd. +: يجب أن تحتوي النقطة النهائية على واحد أو أكثر من المحرف السابق (أو المجموعة)، فمثلًا سيتطابق مسار الوجهة '/ab+cd' مع النقاط النهائية abcd و abbcd و abbbcd وإلخ. *: يمكن أن تحتوي النقطة النهائية على سلسلة نصية عشوائية في مكان المحرف *، فمثلًا سيتطابق مسار الوجهة '/ab*cd' مع النقاط النهائية abcd و abXcd و abSOMErandomTEXTcd وإلخ. (): تجميع تطابق مجموعة من المحارف لإجراء عملية أخرى عليها، فمثلًا سينفّذ '/ab(cd)?e' تطابق ? على المجموعة (cd)، إذ سيتطابق مع abe و abcde. يمكن أن تكون مسارات الوجهة أيضًا تعابير نمطية Regular Expressions في لغة جافا سكريبت JavaScript، فمثلًا سيتطابق مسار الوجهة التالي مع catfish و dogfish، ولكن لن يتطابق مع catflap و catfishhead وما إلى ذلك. لاحظ أن مسار التعبير النمطي يستخدم صياغة التعابير النمطية، وهي ليست سلسلة نصية بين علامات اقتباس كما في الحالات السابقة. app.get(/.*fish$/, function (req, res) { // … }); ملاحظة: ستستخدم معظم الوجهات في موقع المكتبة المحلية LocalLibrary سلاسلًا نصية ولن تستخدم تعابيرًا نمطية، وسنستخدم أيضًا معاملات الوجهات كما سنناقش في القسم التالي. معاملات الوجهة تُسمَّى معاملات الوجهة بأجزاء Segments عنوان URL المُستخدَمة لالتقاط القيم في مواضع محددة من عنوان URL، إذ تُسبَق هذه المقاطع بنقطتين ثم الاسم (مثل /:your_parameter_name/). تُخزَّن القيم المُلتقَطة في كائن req.params من خلال استخدام أسماء المعاملات بوصفها مفاتيحًا، مثل req.params.your_parameter_name. ليكن لدينا مثلًا عنوان URL مُشفَّر يحتوي على معلومات حول المستخدمين والكتب: http://localhost:3000/users/34/books/8989، إذ يمكننا استخراج هذه المعلومات كما هو موضح فيما يلي باستخدام معاملات مسار userId و bookId: app.get("/users/:userId/books/:bookId", (req, res) => { // الوصول إلى userId باستخدام req.params.userId // الوصول إلى bookId باستخدام req.params.bookId res.send(req.params); }); يجب أن تتكون أسماء معاملات الوجهة من "محارف كلمات"، أي A-Z و a-z و0-9 و _. ملاحظة: ستجري مطابقة عنوان "/book/create" مع وجهة مثل الوجهة /book/:bookId، والتي ستستخرج قيمة "bookId" الخاصة بالإنشاء 'create'. ستُستخدَم الوجهة الأولى التي تطابق عنوان URL الوارد، لذلك إذا أردتَ معالجة عناوين /book/create بصورة منفصلة، فيجب تعريف معالج الوجهة قبل الوجهة /book/:bookId. هذا كل ما تحتاجه لبدء استخدام الوجهات، ولكن يمكنك العثور على مزيد من المعلومات في مقال كيفية تحديد الوجهات وأنواع طلبات HTTP وفي توثيق Express: التوجيه الأساسي ودليل التوجيه. توضح الأقسام التالية كيفية إعداد الوجهات والمتحكمات لموقع المكتبة المحلية. معالجة الأخطاء في دوال الوجهة تحتوي جميع دوال الوجهة الموضحة سابقًا على وسائط req و res التي تمثل الطلب والاستجابة على التوالي. تُستدعَى دوال الوجهة أيضًا مع وسيط ثالث هو next، والذي يمكن استخدامه لتمرير الأخطاء إلى سلسلة برمجيات Express الوسيطة. توضح الشيفرة التالية كيفية إنجاز ذلك باستخدام مثال استعلام قاعدة البيانات الذي يأخذ دالة رد نداء ويعيد إما خطأ err أو بعض النتائج. تُستدعَى next مع خطأ err بوصفه قيمة معاملها الأول عند إعادة خطأ err، وسينتقل هذا الخطأ في النهاية إلى شيفرة معالجة الأخطاء العامة، وتُعاد البيانات المطلوبة ثم تُستخدَم في الاستجابة في حالة النجاح. router.get("/about", (req, res, next) => { About.find({}).exec((err, queryResults) => { if (err) { return next(err); } // اعرض شيئًا ما في حالة النجاح res.render("about_view", { title: "About", list: queryResults }); }); }); معالجة الاستثناءات في دوال الوجهة يوضح القسم السابق كيف يتوقع إطار عمل Express أن تعيد دوال الوجهة أخطاءً، إذ صُمِّم إطار العمل للاستخدام مع الدوال غير المتزامنة التي تأخذ دالة رد نداء (مع خطأ وووسيط النتيجة)، والتي تُستدعَى عند اكتمال العملية. يُعَد ذلك مشكلة لأننا سنجري لاحقًا استعلامات قاعدة بيانات Mongoose التي تستخدم واجهات برمجة تطبيقات مستندة إلى الوعود promise، والتي يمكن أن تؤدي إلى رمي استثناءات في دوال الوجهة بدلًا من إعادة الأخطاء في دالة رد النداء. يمكن أن يعالج إطار العمل الاستثناءات بصورة صحيحة من خلال اكتشافها ثم توجيهها بوصفها أخطاءً كما هو موضح في القسم السابق. ملاحظة: من المتوقع أن يعالج Express 5 التجريبي استثناءات جافا سكريبت بطريقة أصيلة. ليكن لدينا المثال البسيط من القسم السابق مع وجود About.find().exec() بوصفه استعلام قاعدة بيانات يعيد وعدًا، إذ يمكن كتابة دالة الوجهة ضمن كتلة try...catch كما يلي: exports.get("/about", async function (req, res, next) { try { const successfulResult = await About.find({}).exec(); res.render("about_view", { title: "About", list: successfulResult }); } catch (error) { return next(error); } }); يُعَد ذلك كمًا كبيرًا جدًا من الشيفرة البرمجية المتداولة لإضافتها إلى كل دالة، لذا سنستخدم بدلًا من ذلك وحدة express-async-handler التي تعرّف دالة تغليف تخفي كتلة try...catch والشيفرة البرمجية لتوجيه الخطأ، وبالتالي أصبح المثال نفسه الآن بسيطًا جدًا، لأننا نحتاج فقط إلى كتابة شيفرة برمجية للحالة التي نفترض فيها النجاح: // استيراد الوحدة const asyncHandler = require("express-async-handler"); exports.get( "/about", asyncHandler(async (req, res, next) => { const successfulResult = await About.find({}).exec(); res.render("about_view", { title: "About", list: successfulResult }); }), ); الوجهات اللازمة لموقع المكتبة المحلية سنعرض فيما يلي عناوين URL التي سنحتاجها لصفحاتنا، إذ نضع اسم كل نموذج من نماذجنا (الكتاب ونسخة الكتاب ونوع الكتاب والمؤلف) مكان الكائن object، والكائنات objects هي جمع كائن، والمعرّف id هو نسخة فريدة من الحقل (_id) تُعطَى لكل نسخة من نموذج Mongoose افتراضيًا. catalog/: الصفحة الرئيسية أو صفحة الفهرس. catalog/<objects>/: قائمة بجميع الكتب أو نسخها أو أنواعها أو المؤلفين، مثل /catalog/books/ و /catalog/genres/ وغير ذلك. catalog/<object>/<id>: صفحة التفاصيل لكتاب أو نسخة أو نوع أو مؤلف معين مع قيمة الحقل _id المُحدَّدة، مثل /catalog/book/584493c1f4887f06c0e67d37. catalog/<object>/create: استمارة إنشاء كتاب أو نسخة أو نوع أو مؤلف جديد، مثل /catalog/book/create. catalog/<object>/<id>/update: استمارة لتحديث كتاب أو نسخة أو نوع أو مؤلف معين مع قيمة الحقل _id المُحدَّدة، مثل /catalog/book/584493c1f4887f06c0e67d37/update. catalog/<object>/<id>/delete: استمارة لحذف كتاب أو نسخة أو نوع أو مؤلف معين مع قيمة الحقل _id المُحدَّدة، مثل /catalog/book/584493c1f4887f06c0e67d37/delete. لا تشفِّر الصفحة الرئيسية الأولى وصفحات القائمة أيّ معلومات إضافية، فبينما تعتمد النتائج المُعادة على نوع النموذج والمحتوى في قاعدة البيانات، ستبقى الاستعلامات المُنفَّذة للحصول على المعلومات نفسها دائمًا، وبالمثل، ستكون الشيفرة البرمجية المُنفَّذة لإنشاء الكائن نفسها دائمًا. تُستخدَم عناوين URL الأخرى للعمل على نسخةٍ من مستند أو نموذج معين، وتشفّر هوية العنصر في عنوان URL (كما هو موضّح في العنصر <id> سابقًا). سنستخدم معاملات المسار لاستخراج المعلومات المشفرة وتمريرها إلى معالج الوجهة، وسنستخدمها في مقال لاحق لتحديد المعلومات التي نحصل عليها من قاعدة البيانات ديناميكيًا. نحتاج فقط إلى وجهة واحدة لكل مورد من نوع معين من خلال تشفير المعلومات في عنوان URL، مثل استخدام وجهة واحدة للتعامل مع عرض عنصر كتاب واحد. ملاحظة: يسمح إطار عمل Express بإنشاء عناوين URL الخاصة بك بالطريقة التي تريدها، إذ يمكنك تشفير المعلومات في متن عنوان URL أو استخدام معاملات URL من النوع GET (مثل /book/?id=6). يجب أن تظل عناوين URL نظيفة ومنطقية وقابلة للقراءة بغض النظر عن الطريقة التي تستخدمها. سننشئ فيما يلي دوال رد نداء معالجة الوجهة وشيفرة الوجهة البرمجية لجميع عناوين URL السابقة. إنشاء دوال رد النداء لمعالجة الوجهة سننشئ أولًا جميع دوال رد النداء الوهمية أو الهيكلية التي ستُستدعَى لاحقًا قبل أن نعرّف الوجهات، وستُخزَّن دوال رد النداء في وحدات متحكمات منفصلة لكل من Book و BookInstance و Genre و Author، إذ يمكنك استخدام أي بنية ملفات أو وحدات، ولكن تبدو الطريقة التي سنستخدمها مناسبة ودقيقة لهذا المشروع. ابدأ بإنشاء مجلدٍ للمتحكمات في جذر المشروع /controllers، ثم أنشئ ملفات أو وحدات منفصلة للمتحكمات للتعامل مع كل نموذج كما يلي: /express-locallibrary-tutorial //the project root /controllers authorController.js bookController.js bookinstanceController.js genreController.js ستستخدم المتحكمات الوحدة express-async-handler، لذا ثبّتها في المكتبة باستخدام npm قبل المتابعة كما يلي: npm install --save express-async-handler متحكم المؤلف Author افتح الملف "/controllers/authorController.js" واكتب فيه الشيفرة البرمجية التالية: const Author = require("../models/author"); const asyncHandler = require("express-async-handler"); // عرض قائمة بجميع المؤلفين exports.author_list = asyncHandler(async (req, res, next) => { res.send("NOT IMPLEMENTED: Author list"); }); // عرض صفحة التفاصيل لمؤلف معين exports.author_detail = asyncHandler(async (req, res, next) => { res.send(`NOT IMPLEMENTED: Author detail: ${req.params.id}`); }); // عرض استمارة إنشاء مؤلف باستخدام GET exports.author_create_get = asyncHandler(async (req, res, next) => { res.send("NOT IMPLEMENTED: Author create GET"); }); // معالجة إنشاء مؤلف باستخدام POST exports.author_create_post = asyncHandler(async (req, res, next) => { res.send("NOT IMPLEMENTED: Author create POST"); }); // عرض استمارة حذف المؤلف باستخدام GET exports.author_delete_get = asyncHandler(async (req, res, next) => { res.send("NOT IMPLEMENTED: Author delete GET"); }); // معالجة حذف المؤلف باستخدام POST exports.author_delete_post = asyncHandler(async (req, res, next) => { res.send("NOT IMPLEMENTED: Author delete POST"); }); // عرض استمارة تحديث المؤلف باستخدام GET exports.author_update_get = asyncHandler(async (req, res, next) => { res.send("NOT IMPLEMENTED: Author update GET"); }); // معالجة تحديث المؤلف باستخدام POST exports.author_update_post = asyncHandler(async (req, res, next) => { res.send("NOT IMPLEMENTED: Author update POST"); }); تطلب الوحدة أولًا نموذج المؤلف Author الذي سنستخدمه لاحقًا للوصول إلى بياناتنا وتحديثها، والمغلِّف asyncHandler الذي سنستخدمه لالتقاط الاستثناءات من دوال معالج الوجهة، ثم تصدِّر دوالًا لكل عنوان من عناوين URL التي نرغب في معالجتها. لاحظ أن عمليات الإنشاء والتحديث والحذف تستخدم الاستمارات Forms، وبالتالي تملك توابعًا إضافية لمعالجة طلبات الاستمارة من النوع Post، وسنناقش هذه التوابع في مقال لاحق. تستخدم جميع الدوال الدالة المُغلِّفة Wrapper السابقة في معالجة الاستثناءات في دوال الوجهة مع وسائط للطلب والاستجابة والدالة التالية next، وتستجيب الدوال بسلسلة نصية تشير إلى أن الصفحة المرتبطة لم تُنشَأ بعد. إذا كان من المتوقع أن تتلقى دالة المتحكم معاملات المسار، فستكون هذه المعاملات هي الخرج الموجود في سلسلة الرسالة النصية (لاحظ req.params.id). لاحظ أنه يمكن ألّا تحتوي بعض دوال الوجهة بعد تقديمها على أي شيفرة برمجية يمكنها أن ترمي استثناءات، ولكن يمكننا تغيير تلك الدوال إلى دوال معالجة وجهة عادية عند الوصول إليها. متحكم نسخة الكتاب BookInstance افتح الملف /controllers/bookinstanceController.js وانسخ الشيفرة البرمجية التالية التي تتبع نمطًا مطابقًا لوحدة المتحكم Author: const BookInstance = require("../models/bookinstance"); const asyncHandler = require("express-async-handler"); // عرض قائمة بجميع نسخ الكتب BookInstance exports.bookinstance_list = asyncHandler(async (req, res, next) => { res.send("NOT IMPLEMENTED: BookInstance list"); }); // عرض صفحة تفاصيل نسخة كتاب BookInstance معينة exports.bookinstance_detail = asyncHandler(async (req, res, next) => { res.send(`NOT IMPLEMENTED: BookInstance detail: ${req.params.id}`); }); // عرض استمارة إنشاء نسخة الكتاب BookInstance باستخدام GET exports.bookinstance_create_get = asyncHandler(async (req, res, next) => { res.send("NOT IMPLEMENTED: BookInstance create GET"); }); // معالجة إنشاء نسخة كتاب BookInstance باستخدام POST exports.bookinstance_create_post = asyncHandler(async (req, res, next) => { res.send("NOT IMPLEMENTED: BookInstance create POST"); }); // عرض استمارة حذف نسخة كتاب BookInstance باستخدام GET exports.bookinstance_delete_get = asyncHandler(async (req, res, next) => { res.send("NOT IMPLEMENTED: BookInstance delete GET"); }); // معالجة حذف نسخة كتاب BookInstance باستخدام POST exports.bookinstance_delete_post = asyncHandler(async (req, res, next) => { res.send("NOT IMPLEMENTED: BookInstance delete POST"); }); // عرض استمارة تحديث نسخة كتاب BookInstance باستخدام GET exports.bookinstance_update_get = asyncHandler(async (req, res, next) => { res.send("NOT IMPLEMENTED: BookInstance update GET"); }); // معالجة تحديث نسخة الكتاب باستخدام POST exports.bookinstance_update_post = asyncHandler(async (req, res, next) => { res.send("NOT IMPLEMENTED: BookInstance update POST"); }); متحكم نوع الكتاب Genre افتح الملف /controllers/genreController.js والصق فيه النص التالي الذي يتبع نمطًا مطابقًا لملفات Author و BookInstance: const Genre = require("../models/genre"); const asyncHandler = require("express-async-handler"); // عرض قائمة بجميع أنواع الكتب Genre exports.genre_list = asyncHandler(async (req, res, next) => { res.send("NOT IMPLEMENTED: Genre list"); }); // عرض صفحة تفاصيل نوع كتاب Genre معين exports.genre_detail = asyncHandler(async (req, res, next) => { res.send(`NOT IMPLEMENTED: Genre detail: ${req.params.id}`); }); // عرض استمارة إنشاء نوع الكتاب Genre باستخدام GET exports.genre_create_get = asyncHandler(async (req, res, next) => { res.send("NOT IMPLEMENTED: Genre create GET"); }); // معالجة إنشاء نوع كتاب Genre باستخدام POST exports.genre_create_post = asyncHandler(async (req, res, next) => { res.send("NOT IMPLEMENTED: Genre create POST"); }); // عرض استمارة حذف نوع كتاب Genre باستخدام GET exports.genre_delete_get = asyncHandler(async (req, res, next) => { res.send("NOT IMPLEMENTED: Genre delete GET"); }); // معالجة حذف نوع كتاب Genre باستخدام POST exports.genre_delete_post = asyncHandler(async (req, res, next) => { res.send("NOT IMPLEMENTED: Genre delete POST"); }); // عرض استمارة تحديث نوع كتاب Genre باستخدام GET exports.genre_update_get = asyncHandler(async (req, res, next) => { res.send("NOT IMPLEMENTED: Genre update GET"); }); // معالجة تحديث نوع كتاب Genre باستخدام POST exports.genre_update_post = asyncHandler(async (req, res, next) => { res.send("NOT IMPLEMENTED: Genre update POST"); }); متحكم الكتاب Book افتح الملف /controllers/bookController.js وانسخ الشيفرة البرمجية التالية، إذ يتبع هذا الملف النمط المتبع نفسه في وحدات المتحكمات الأخرى، ولكنه يحتوي أيضًا على الدالة index() لعرض صفحة الترحيب بالموقع: const Book = require("../models/book"); const asyncHandler = require("express-async-handler"); exports.index = asyncHandler(async (req, res, next) => { res.send("NOT IMPLEMENTED: Site Home Page"); }); // عرض قائمة بجميع الكتب exports.book_list = asyncHandler(async (req, res, next) => { res.send("NOT IMPLEMENTED: Book list"); }); // عرض صفحة تفاصيل كتاب معين exports.book_detail = asyncHandler(async (req, res, next) => { res.send(`NOT IMPLEMENTED: Book detail: ${req.params.id}`); }); // عرض استمارة إنشاء كتاب باستخدام GET exports.book_create_get = asyncHandler(async (req, res, next) => { res.send("NOT IMPLEMENTED: Book create GET"); }); // معالجة إنشاء كتاب باستخدام POST exports.book_create_post = asyncHandler(async (req, res, next) => { res.send("NOT IMPLEMENTED: Book create POST"); }); // عرض استمارة حذف كتاب باستخدام GET exports.book_delete_get = asyncHandler(async (req, res, next) => { res.send("NOT IMPLEMENTED: Book delete GET"); }); // معالجة حذف كتاب باستخدام POST exports.book_delete_post = asyncHandler(async (req, res, next) => { res.send("NOT IMPLEMENTED: Book delete POST"); }); // عرض استمارة تحديث كتاب باستخدام GET exports.book_update_get = asyncHandler(async (req, res, next) => { res.send("NOT IMPLEMENTED: Book update GET"); }); // معالجة تحديث كتاب باستخدام POST exports.book_update_post = asyncHandler(async (req, res, next) => { res.send("NOT IMPLEMENTED: Book update POST"); }); إنشاء دليل وحدات الوجهة سننشئ الآن وجهات لجميع عناوين URL التي يحتاجها موقع المكتبة المحلية LocalLibrary، والتي ستستدعي دوال المتحكمات التي عرّفناها في الأقسام السابقة. تحتوي البنية الهيكلية للموقع مسبقًا على المجلد "./routes" الذي يحتوي على وجهات لصفحة الفهرس index والمستخدمين users. أنشئ ملف وجهة آخر هو catalog.js ضمن هذا المجلد كما يلي: /express-locallibrary-tutorial //the project root /routes index.js users.js catalog.js افتح الملف /routes/catalog.js وانسخ الشيفرة البرمجية التالية: const express = require("express"); const router = express.Router(); // طلب وحدات المتحكمات const book_controller = require("../controllers/bookController"); const author_controller = require("../controllers/authorController"); const genre_controller = require("../controllers/genreController"); const book_instance_controller = require("../controllers/bookinstanceController"); /// وجهات الكتاب /// // الحصول على صفحة الدليل الرئيسية router.get("/", book_controller.index); // طلب GET لإنشاء كتاب. يجب أن يأتي هذا الطلب قبل الوجهات Routes التي تعرض الكتاب (يستخدم المعرّف id) router.get("/book/create", book_controller.book_create_get); // طلب POST لإنشاء كتاب router.post("/book/create", book_controller.book_create_post); // طلب GET لحذف كتاب router.get("/book/:id/delete", book_controller.book_delete_get); // طلب POST لحذف كتاب router.post("/book/:id/delete", book_controller.book_delete_post); // طلب GET لتحديث كتاب router.get("/book/:id/update", book_controller.book_update_get); // طلب POST لتحديث كتاب router.post("/book/:id/update", book_controller.book_update_post); // طلب GET لكتاب واحد router.get("/book/:id", book_controller.book_detail); // طلب GET لقائمة جميع عناصر الكتب router.get("/books", book_controller.book_list); /// وجهات المؤلف /// // طلب GET لإنشاء مؤلف Author. يجب أن يأتي هذا الطلب قبل وجهة المعرّف (مثل عرض مؤلف) router.get("/author/create", author_controller.author_create_get); // طلب POST لإنشاء مؤلف router.post("/author/create", author_controller.author_create_post); // طلب GET لحذف مؤلف router.get("/author/:id/delete", author_controller.author_delete_get); // طلب POST لحذف مؤلف router.post("/author/:id/delete", author_controller.author_delete_post); // طلب GET لتحديث مؤلف router.get("/author/:id/update", author_controller.author_update_get); // طلب POST لتحديث مؤلف router.post("/author/:id/update", author_controller.author_update_post); // طلب GET لمؤلف واحد router.get("/author/:id", author_controller.author_detail); // طلب GET لقائمة جميع المؤلفين router.get("/authors", author_controller.author_list); /// وجهات نوع الكتاب GENRE /// // طلب GET لإنشاء نوع كتاب. يجب أن يأتي هذا الطلب قبل الوجهة التي تعرض نوع الكتاب (يستخدم المعرّف) router.get("/genre/create", genre_controller.genre_create_get); // طلب POST لإنشاء نوع كتاب router.post("/genre/create", genre_controller.genre_create_post); // طلب GET لحذف نوع كتاب router.get("/genre/:id/delete", genre_controller.genre_delete_get); // طلب POST لحذف نوع كتاب router.post("/genre/:id/delete", genre_controller.genre_delete_post); // طلب GET لتحديث نوع كتاب router.get("/genre/:id/update", genre_controller.genre_update_get); // طلب POST لتحديث نوع كتاب router.post("/genre/:id/update", genre_controller.genre_update_post); // طلب GET لنوع كتاب واحد router.get("/genre/:id", genre_controller.genre_detail); // طلب GET لقائمة جميع أنواع الكتب router.get("/genres", genre_controller.genre_list); /// طرق نسخ الكتب BOOKINSTANCE /// // طلب GET لإنشاء نسخة كتاب BookInstance. يجب أن يأتي هذا الطلب قبل الوجهة التي تعرض نسخة الكتاب (يستخدم المعرّف) router.get( "/bookinstance/create", book_instance_controller.bookinstance_create_get, ); // طلب POST لإنشاء نسخة كتاب router.post( "/bookinstance/create", book_instance_controller.bookinstance_create_post, ); // طلب GET لحذف نسخة كتاب router.get( "/bookinstance/:id/delete", book_instance_controller.bookinstance_delete_get, ); // طلب POST لحذف نسخة كتاب router.post( "/bookinstance/:id/delete", book_instance_controller.bookinstance_delete_post, ); // طلب GET لتحديث نسخة الكتاب router.get( "/bookinstance/:id/update", book_instance_controller.bookinstance_update_get, ); // طلب POST لتحديث نسخة كتاب router.post( "/bookinstance/:id/update", book_instance_controller.bookinstance_update_post, ); // طلب GET لنسخة كتاب واحدة router.get("/bookinstance/:id", book_instance_controller.bookinstance_detail); // طلب GET لقائمة جميع نسخ الكتاب router.get("/bookinstances", book_instance_controller.bookinstance_list); module.exports = router; تطلب الوحدة كائن Express ثم تستخدمه لإنشاء كائن Router، إذ تُضبَط جميع الوجهات في هذا الكائن الذي يُصدَّر لاحقًا. تُعرّف الوجهات إما باستخدام تابع .get() أو تابع .post() للكائن Router، وتُعرّف جميع المسارات باستخدام سلاسل نصية، إذ لا نستخدم أنماط سلاسل نصية أو تعابيرًا نمطية. تستخدم الوجهات التي تعمل على بعض الموارد المحددة (مثل الكتاب) معاملاتِ المسار للحصول على معرّف الكائن من عنوان URL، وتُستورَد جميع دوال المعالجة من وحدات المتحكمات التي أنشأناها في القسم السابق. تحديث وحدة وجهة صفحة الفهرس ضبطنا جميع وجهاتنا الجديدة، ولكن لا يزال لدينا الوجهة إلى الصفحة الأصلية، ولكن لنعيد التوجيه إلى صفحة الفهرس الجديدة التي أنشأناها في المسار '/catalog' بدلًا من ذلك. افتح الملف /routes/index.js وضع الدالة التالية بدلًا من الوجهة الحالية: // الحصول على الصفحة الرئيسية router.get("/", function (req, res) { res.redirect("/catalog"); }); ملاحظة: استخدمنا تابع الاستجابة redirect() الذي يؤدي إلى إعادة التوجيه إلى الصفحة المحددة، مع إرسال رمز حالة HTTP الذي هو "302 Found" افتراضيًا، ويمكنك تغيير رمز الحالة المُعاد إن لزم الأمر وتوفير مسارات مطلقة أو نسبية. يمكنك الاطلاع على مقال رموز الإجابة في HTTP والمقال كيفية استكشاف وإصلاح رموز أخطاء HTTP الشائعةعلى أكاديمية حسوب لمزيدٍ من المعلومات حول رموز حالة HTTP. تحديث الملف app.js تتمثل الخطوة الأخيرة في إضافة الوجهات إلى سلسلة البرمجيات الوسيطة في الملف app.js، لذا افتح هذا الملف، واطلب وجهة الدليل بعد الوجهات الأخرى من خلال إضافة السطر الثالث التالي بعد السطرين الآخرين الموجودين مسبقًا في الملف: var indexRouter = require("./routes/index"); var usersRouter = require("./routes/users"); const catalogRouter = require("./routes/catalog"); // استيراد الوجهات لمنطقة "الدليل" في الموقع ضِف بعد ذلك وجهة الدليل catalog إلى مكدس البرمجيات الوسيطة بعد الوجهات الأخرى من خلال إضافة السطر الثالث التالي بعد السطرين الآخرين الموجودين مسبقًا في الملف: app.use("/", indexRouter); app.use("/users", usersRouter); app.use("/catalog", catalogRouter); // إضافة وجهات الدليل إلى سلسلة البرمجيات الوسيطة ملاحظة: أضفنا وحدة دليلنا في المسار '/catalog' الذي سيكون البادئة لجميع المسارات المحدَّدة في وحدة الدليل، فمثلًا سيكون عنوان URL هو /catalog/books/ للوصول إلى قائمة الكتب. يجب أن يكون لدينا الآن مسارات ودوال هيكلية مُفعَّلة لجميع عناوين URL التي سندعمها في موقع المكتبة المحلية LocalLibrary. اختبار الوجهات أولًا، ابدأ تشغيل موقع الويب بالطريقة المعتادة، فالطريقة الافتراضية في أنظمة التشغيل هي: // نظام ويندوز SET DEBUG=express-locallibrary-tutorial:* & npm start // ماك أو لينكس DEBUG=express-locallibrary-tutorial:* npm start ولكن إذا سبق لك إعداد nodemon، فيمكنك بدلًا من ذلك استخدام ما يلي: npm run serverstart انتقل بعد ذلك إلى عدد من عناوين URL الخاصة بموقع المكتبة المحلية LocalLibrary وتحقق من عدم ظهور صفحة خطأ (HTTP 404). إليك مجموعة صغيرة من عناوين URL: http://localhost:3000/ http://localhost:3000/catalog http://localhost:3000/catalog/books http://localhost:3000/catalog/bookinstances/ http://localhost:3000/catalog/authors/ http://localhost:3000/catalog/genres/ http://localhost:3000/catalog/book/5846437593935e2f8c2aa226 http://localhost:3000/catalog/book/create الخلاصة أنشأنا جميع الوجهات الخاصة بموقعنا، مع دوال المتحكمات الوهمية التي يمكننا ملؤها بتقديم كامل في مقالات لاحقة، وتعلمنا الكثير من المعلومات الأساسية حول وجهات Express والتعامل مع الاستثناءات وبعض الأساليب لبناء الوجهات والمتحكمات. سننشئ في المقال التالي صفحة ترحيب مناسبة للموقع باستخدام العروض (القوالب) والمعلومات المخزنة في نماذجنا، وسننشئ استمارات HTML وشيفرة معالجة الاستمارات لبدء تعديل البيانات التي يخزنها الموقع. ترجمة -وبتصرُّف- للمقال Express Tutorial Part 4: Routes and controllers. اقرأ أيضًا المقال السابق تطبيق عملي لتعلم Express - الجزء الثاني: استخدام قاعدة البيانات باستخدام مكتبة Mongoose. إنشاء خادم ويب في Node.js باستخدام الوحدة HTTP. المتحكّمات Controllers والعروض Views في إطار العمل Rails. -
.png.927a970da3619cf5a4afa1af55ebf253.png) يقدّم هذا المقال مقدمة موجزة عن قواعد البيانات وكيفية استخدامها مع تطبيقات Node/Express، ثم يوضّح كيفية استخدام مكتبة Mongoose لتوفير الوصول إلى قاعدة بيانات موقع المكتبة المحلية LocalLibrary، ويشرح كيفية التصريح عن مخطط الكائنات object schema والنماذج Models، وأنواع الحقول الرئيسية والتحقق الأساسي من صحة البيانات. يعرض أيضًا بإيجاز بعض الطرق الرئيسية التي يمكنك من خلالها الوصول إلى بيانات النموذج. المتطلبات الأساسية: الاطلاع على مقال إنشاء موقع ويب هيكلي لمكتبة محلية. الهدف: أن تكون قادرًا على تصميم وإنشاء نماذجك باستخدام مكتبة Mongoose. يستخدم موظفو المكتبة موقع المكتبة المحلية لتخزين المعلومات حول الكتب والمستعيرين، بينما يستخدمه أعضاء المكتبة لتصفح الكتب والبحث عنها ولمعرفة ما إذا كان هناك أيّ نسخ متاحة ثم حجزها أو استعارتها. لذا سنخزّن المعلومات في قاعدة بيانات لتخزينها واسترجاعها بكفاءة. يمكن لتطبيقات Express استخدام العديد من قواعد البيانات المختلفة، وهناك العديد من الأساليب التي يمكنك استخدامها لإجراء عمليات الإنشاء والقراءة والتحديث والحذف -أو CRUD اختصارًا. يقدم هذا المقال نظرةً عامةً موجزة عن بعض الخيارات المتاحة ثم ينتقل ليشرح الآليات المختارة بالتفصيل. قواعد البيانات الممكن استخدامها يمكن لتطبيقات Express استخدام أيّ قاعدة بيانات تدعمها بيئة Node، إذ لا يحدد إطارعمل Express أيّ سلوك أو متطلبات إضافية محددة لإدارة قاعدة البيانات، وهناك العديد من الخيارات الشائعة بما في ذلك قواعد بيانات PostgreSQL و MySQL و Redis و SQLite و MongoDB وغير ذلك. يجب أن تأخذ في حساباتك عند اختيار قاعدة بيانات أشياءً مثل منحنى الوقت لتعلمها أو للحصول على نتائج والأداء وسهولة التكرار أو النسخ الاحتياطي والتكلفة ودعم المجتمع وغير ذلك. لا توجد قاعدة بيانات أفضل من الأخرى، ولكن تُعَد أيّ قاعدة بيانات شائعة تقريبًا مقبولة بصورة جيدة لموقع صغير إلى متوسط الحجم مثل موقع مكتبتنا المحلية. اطلع على تكامل قاعدة البيانات في توثيق Express لمزيد من المعلومات حول هذه الخيارات. أفضل طريقة للتفاعل مع قاعدة البيانات هناك طريقتان شائعتان للتفاعل مع قاعدة البيانات، هما: استخدام لغة الاستعلام الأصيلة لقواعد البيانات مثل لغة SQL. استخدام نموذج بيانات الكائن Object Data Model -أو اختصارًا ODM- أو نموذج الكائنات العلاقي Object Relational Model -أو ORM اختصارًا. يمثل نموذج ODM/ORM بيانات موقع الويب بوصفها كائنات جافا سكريبت، والتي تُربَط بعد ذلك بقاعدة البيانات الأساسية، إذ ترتبط بعض نماذج ORM بقاعدة بيانات معينة، بينما يوفر بعضها الآخر واجهة خلفية لا تعتمد على قاعدة البيانات. يمكن الحصول على أفضل أداء باستخدام لغة SQL أو أيّ لغة استعلام تدعمها قاعدة البيانات، إذ يُعَد نموذج ODM أبطأ لأنه يستخدم شيفرة ترجمة للربط بين الكائنات وتنسيق قاعدة البيانات، إذ يمكن ألّا يستخدم هذا النموذج استعلامات قاعدة البيانات الأكثر كفاءة، وهذا صحيح بصورة خاصة إذا كان نموذج ODM يدعم واجهات خلفية لقواعد بيانات مختلفة، وبالتالي يجب تقديم تنازلات أكبر فيما يتعلق بميزات قاعدة البيانات المدعومة. تتمثل فائدة استخدام نموذج ORM في أنه يمكن للمبرمجين الاستمرار في التفكير وفق مصطلحات كائنات جافاسكربت بدلًا من دلالات قواعد البيانات، وهذا صحيح بصورة خاصة إذا كنت بحاجة إلى العمل مع قواعد بيانات مختلفة على موقع الويب نفسه أو مواقع ويب مختلفة، ويوفر هذا النموذج أيضًا مكانًا واضحًا لإجراء التحقق من صحة البيانات. ملاحظة: يؤدي استخدام نماذج ODM/ORM إلى انخفاض تكاليف التطوير والصيانة، إذ يجب أن تفكر كثيرًا في استخدام نموذج ODM إلّا إذا كنت على دراية بلغة الاستعلام الأصيلة أو إذا كان الأداء أمرًا بالغ الأهمية. نموذج ORM/ODM الذي يجب أن استخدامه هناك العديد من حلول ODM/ORM المتاحة على موقع مدير الحزم npm (اطلع على odm و orm للتعرف على بعض من هذه الحلول). إليك بعضًا من هذه الحلول الشائعة: Mongoose: هي أداة نمذجة كائنات قاعدة بيانات MongoDB المُصمَّمة للعمل في بيئة غير متزامنة. Waterline: هو نموذج ORM المُستخرَج من إطار عمل الويب Sails القائم على إطار عمل Express. يوفر واجهة برمجة تطبيقات مُوحَّدة للوصول إلى العديد من قواعد البيانات المختلفة، بما في ذلك Redis و MySQL و LDAP و MongoDB و Postgres. Bookshelf: يتميز بواجهات رد النداء Callback التقليدية القائمة على الوعود Promise، مما يوفر دعمًا لمعامَلات قاعدة البيانات وتحميل العلاقات النشط أو النشط المتداخل والارتباطات متعددة الأشكال ودعم علاقات واحد إلى واحد one-to-one وواحد إلى متعدد one-to-many ومتعدد إلى متعدد many-to-many، ويعمل مع قواعد بيانات PostgreSQL و MySQL و SQLite3. يمكنك الاطلاع على مقال العلاقات بين الجداول في SQL على أكاديمية حسوب لمزيدٍ من المعلومات حول العلاقات بين الجداول. Objection: يسهّل قدر الإمكان استخدام قوة لغة SQL الكاملة ومحرك قاعدة البيانات الأساسي، ويدعم SQLite3 و Postgres و MySQL. Sequelize: هو نموذج ORM مبني على الوعود لكلٍّ من Node.js و io.js، ويدعم الأنواع المختلفة من لغات PostgreSQL و MySQL و MariaDB و SQLite و MSSQL ويتميز بدعمٍ قوي للمعامَلات transaction والعلاقات وتكرار عمليات القراءة وغير ذلك. Node ORM2: هو مدير علاقات الكائنات الخاص ببيئة NodeJS، ويدعم MySQL و SQLite و Progress، مما يساعد على العمل مع قاعدة البيانات باستخدام أسلوب موجَّه بالكائنات. GraphQL: لغة استعلام أساسية لواجهات برمجة التطبيقات restful API، وتحظى لغة GraphQL بشعبية كبيرة ولديها ميزات متاحة لقراءة البيانات من قواعد البيانات. يجب مراعاة كل من الميزات المتوفرة ونشاط المجتمع (التنزيلات والمساهمات وتقارير الأخطاء وجودة التوثيق وغير ذلك) عند اختيار الحل المناسب، وتُعَد مكتبة Mongoose أكثر نماذج ODM شيوعًا، وهو خيار جيد عند استخدام MongoDB لقاعدة بياناتك. استخدام مكتبة Mongoose وقاعدة بيانات MongoDB لموقع المكتبة المحلية سنستخدم في مثالنا مكتبة Mongoose بوصفها نموذج ODM للوصول إلى بيانات مكتبتنا، إذ تتصرف هذه المكتبة بمثابة واجهة أمامية لقاعدة بيانات MongoDB، وهي قاعدة بيانات NoSQL مفتوحة المصدر تستخدم نموذج بيانات موجَّهًا بالمستندات، إذ تشبه مجموعة المستندات في قاعدة بيانات MongoDB جدولًا من الصفوف في قاعدة بيانات علاقية. تحظى هذه المجموعة من نموذج ODM وقاعدة البيانات بشعبية كبيرة في مجتمع Node، ويرجع ذلك جزئيًا إلى أن تخزين المستندات ونظام الاستعلام يشبه إلى حد كبير JSON، وبالتالي فهو مألوف لمطوري جافا سكريبت. ملاحظة: لست بحاجة إلى معرفة قاعدة بيانات MongoDB لاستخدام مكتبة Mongoose، بالرغم من أن أجزاءً من توثيق Mongoose أسهل في الاستخدام والفهم إذا كنت على دراية بقاعدة بيانات MongoDB. سنوضح فيما يلي كيفية تعريف والوصول إلى مخطط ونماذج Mongoose لمثال موقع ويب المكتبة المحلية LocalLibrary. تصميم نماذج موقع المكتبة المحلية يفضَّل أخذ بضع دقائق للتفكير في البيانات التي يجب تخزينها والعلاقات بين الكائنات قبل البدء في كتابة شيفرة النماذج، إذ نعلم أننا بحاجةٍ إلى تخزين معلومات حول الكتب (العنوان والملخص والمؤلف ونوع الكتاب ورقم ISBN)، وقد يكون لدينا نسخٌ متعددة متاحة (مع معرّفات فريدة عامة وحالات توفرها وغير ذلك)، ويمكن أن نحتاج إلى تخزين مزيدٍ من المعلومات حول المؤلف أكثر من مجرد اسمه، ويمكن أن يكون هناك عدة مؤلفين لهم الاسم نفسه أو أسماء متشابهة. نريد أن نكون قادرين على فرز المعلومات بناءً على عنوان الكتاب والمؤلف ونوع الكتاب Genre وفئته Category. من المنطقي أن يكون لديك نماذج منفصلة لكل كائن (مجموعة من المعلومات المتعلقة ببعضها) عند تصميم نماذجك، وبالتالي فإن بعض المرشّحين الواضحين لهذه النماذج هم الكتب ونسخ الكتب والمؤلفون. يمكن أن ترغب في استخدام النماذج لتمثيل خيارات قائمة الاختيار (مثل قائمة اختيارات منسدلة) بدلًا من كتابة شيفرة ثابتة للخيارات في موقع الويب نفسه، إذ يوصَى بذلك عندما لا تكون جميع الخيارات معروفة مسبقًا أو أنها ستتغير، ومن الأمثلة الجيدة لذلك هو نوع الكتاب، مثل النوع الخيالي والخيال العلمي وغير ذلك. يجب الآن التفكير في العلاقات بين النماذج والحقول بعد تحديدها، إذ يوضح مخطط ارتباط باستخدام لغة UML الآتي النماذج التي سنعرّفها في حالتنا (على شكل صناديق)، إذ أنشأنا نماذجًا للكتاب (تفاصيل الكتاب العامة)، ونسخة الكتاب (حالة نسخ الكتاب الحقيقية المحدَّدة المتاحة في النظام)، والمؤلف، وقررنا أيضًا أن يكون لدينا نموذج لنوع الكتاب بحيث يمكن إنشاء القيم ديناميكيًا. لم ننشئ نموذجًا لحالة نسخة الكتاب BookInstance:status، إذ سنجعل القيم المقبولة ثابتة لأننا لا نتوقع تغييرها. يمكنك رؤية اسم النموذج وأسماء الحقول وأنواعها والتوابع وأنواع الإعادة الخاصة بها في كل صندوق. يوضح المخطط البياني الآتي أيضًا العلاقات بين النماذج، بما في ذلك درجة تعدّدها Multiplicities، وهي الأعداد الموجودة على المخطط والتي توضح عدد أو الحد الأقصى والحد الأدنى لكل نموذج الذي يمكن أن يكون موجودًا في العلاقة، فمثلًا يوضّح الخط المتصل بين الصناديق أن الكتاب Book والنوع Genre مرتبطان، وتوضح الأعداد القريبة من نموذج الكتاب Book أنه يجب يكون للنوع Genre صفر أو أكثر من الكتب Book (بقدر ما تريد)، بينما توضح الأعداد الموجودة على الطرف الآخر من الخط بجوار نموذج النوع Genre أن الكتاب يمكن أن يكون له صفر أو أكثر من الأنواع Genre المتعلقة به. ملاحظة: يُفضَّل غالبًا أن يكون لديك الحقل الذي يعرّف العلاقة بين المستندات/النماذج في نموذج واحد فقط كما سنوضّح لاحقًا، ولا يزال بإمكانك العثور على العلاقة العكسية من خلال البحث عن _id المرتبط بها في النموذج الآخر. اخترنا فيما يلي تعريف العلاقة بينBook/Genre و Book/Author في مخطط Schema الكتاب Book، والعلاقة بين Book/BookInstance في مخطط نسخة الكتاب BookInstance، إذ كان هذا الاختيار عشوائيًا إلى حدٍ ما، وكان من الممكن أيضًا أن يكون أحد الحقول موجودًا في المخطط الآخر. ملاحظة: يوفر القسم التالي شرحًا بسيطًا عن كيفية تعريف النماذج واستخدامها، لذلك ضع في بالك أثناء القراءة كيف سنبني كل نموذج من النماذج الموجودة في المخطط البياني السابق. واجهات برمجة تطبيقات قاعدة البيانات غير المتزامنة تُعَد توابع قاعدة البيانات لإنشاء السجلات أو العثور عليها أو تحديثها أو حذفها غير متزامنة، وهذا يعني أن التوابع تعيد القيم مباشرةً ويكون تشغيل الشيفرة البرمجية الخاصة بمعالجة نجاح أو فشل التابع في وقت لاحق عند اكتمال العملية. يمكن تنفيذ شيفرة برمجية أخرى أثناء انتظار الخادم لاكتمال عملية قاعدة البيانات، لذلك يمكن أن يظل الخادم مستجيبًا للطلبات الأخرى. تحتوي لغة جافا سكريبت Javascript على عدد من الآليات لدعم السلوك غير المتزامن، إذ اعتمدت كثيرًا سابقًا على تمرير دوال رد النداء إلى توابع غير متزامنة لمعالجة حالات النجاح والخطأ، وحلّت الوعود Promises محل دوال رد النداء إلى حد كبير في لغة جافا سكربت الحديثة. الوعود هي كائنات يعيدها (مباشرةً) تابع غير متزامن يمثل حالتها المستقبلية، ويستقر كائن الوعد عند اكتمال العملية، ويحقق كائنًا يمثل نتيجة العملية أو الخطأ. هناك طريقتان رئيسيتان يمكنك من خلالهما استخدام الوعود لتشغيل الشيفرة البرمجية عند استقرار الوعد، إذ نوصي بقراءة كيفية استخدام الوعود للحصول على نظرة عامة عالية المستوى على كلا الأسلوبين. سنستخدم في هذا المقال await لانتظار اكتمال الوعد في async function، لأن هذا الأسلوب يؤدي إلى الحصول على شيفرة برمجية غير متزامنة مفهومة وأكثر قابلية للقراءة. تتمثل الطريقة التي يعمل بها هذا الأسلوب في أنك تستخدم الكلمة الأساسية async function لتمييز الدالة بوصفها غير متزامنة، ثم تطبّق ضمن هذه الدالة تابع await على أيّ تابع يعيد وعدًا، وتتوقف عملية الدالة غير المتزامنة عند تنفيذها مؤقتًا عند أول تابع await حتى استقرار الوعد، ثم تعيد الدالة غير المتزامنة ويمكنك تشغيل الشيفرة البرمجية الموجودة بعد تلك الدالة من منظور الشيفرة البرمجية المحيطة. يعيد التابع await ضمن الدالة غير المتزامنة النتيجة لاحقًا عند استقرار الوعد، أو يعطي خطأً عند رفض الوعد، ثم تُنفَّذ الشيفرة البرمجية الموجودة في الدالة غير المتزامنة حتى يظهر تابع await آخر، إذ ستتوقف مؤقتًا مرةً أخرى، أو حتى تشغيل الشيفرة البرمجية بأكملها الموجودة في الدالة. يمكنك أن ترى كيفية عمل هذه الطريقة في المثال الآتي، إذ تُعَد myFunction() دالة غير متزامنة تُستدعَى ضمن كتلة try...catch. يُوقََف تنفيذ الشيفرة البرمجية مؤقتًا في التابع methodThatReturnsPromise() عند تشغيل الدالة myFunction() حتى تحقيق الوعد، وعندها يستمر تنفيذ الشيفرة البرمجية حتى الوصول إلى التابع aFunctionThatReturnsPromise() وينتظر مرةً أخرى. تُشغَّل الشيفرة البرمجية الموجودة في كتلة catch عند رمي خطأ في الدالة غير المتزامنة، إذ سيحدث ذلك عند رفض الوعد الذي يعيده أيّ من هذين التابعين. async function myFunction { // ... await someObject.methodThatReturnsPromise(); // ... await aFunctionThatReturnsPromise(); // ... } try { // ... myFunction(); // ... } catch (e) { // شيفرة معالجة الخطأ } تُشغَّل التوابع غير المتزامنة السابقة تسلسليًا، وإذا لم تعتمد التوابع على بعضها بعضًا، فيمكنك تشغيلها على التوازي وإنهاء العملية بأكملها بسرعة أكبر، ويمكن تحقيق ذلك باستخدام التابع Promise.all() الذي يأخذ تكرارًا من الوعود بوصفها دخلًا ويعيد وعدًا Promise واحدًا. يمكن الوفاء بهذا الوعد المُعاد عند الوفاء بجميع وعود الدخل مع مجموعة من قيم الوفاء، ويرفَض عند رفض أيٍّ من وعود الدخل مع سبب الرفض الأول. توضح الشيفرة البرمجية التالية كيفية عمل ذلك، إذ لدينا أولًا دالتان تعيدان وعودًا، إذ ننتظرهما await حتى يكتملا باستخدام الوعد الذي يعيده التابع Promise.all(). يعيد await بمجرد أن تكتمل كلتا الدالتين وتُملَأ مصفوفة النتائج، ثم يستمر تنفيذ الدالة حتى الوصول إلى تابع await التالي، وتنتظر حتى استقرار الوعد الذي تعيده الدالة anotherFunctionThatReturnsPromise(). يمكنك استدعاء الدالة myFunction() في كتلة try...catch لالتقاط الأخطاء. async function myFunction { // ... const [resultFunction1, resultFunction2] = await Promise.all([ functionThatReturnsPromise1(), functionThatReturnsPromise2() ]); // ... await anotherFunctionThatReturnsPromise(resultFunction1); } تسمح الوعود مع await/async بالتحكم المرن والمنطقي بالتنفيذ غير المتزامن. مقدمة إلى مكتبة Mongoose يقدم هذا القسم نظرةً عامة حول كيفية توصيل مكتبة Mongoose بقاعدة بيانات MongoDB، وكيفية تعريف المخططات والنماذج، وكيفية تطبيق الاستعلامات الأساسية. تثبيت Mongoose و MongoDB تُثبَّت مكتبة Mongoose في مشروعك (في الملف package.json) مثل أي اعتمادية أخرى باستخدام مدير حزم npm، إذ يمكن تثبيتها باستخدم الأمر التالي في مجلد مشروعك: npm install mongoose يضيف تثبيت مكتبة Mongoose جميع اعتمادياتها بما في ذلك مشغِّل قاعدة بيانات MongoDB، لكنه لا يؤدي إلى تثبيت MongoDB. إذا أدرتَ تثبيت خادم MongoDB، فيمكنك تنزيل المثبِّتات لأنظمة تشغيل مختلفة وتثبيتها محليًا، ويمكنك استخدام نسخ من MongoDB المستندة إلى السحابة. ملاحظة: سنستخدم في هذا المقال قاعدة البيانات المستندة إلى السحابة MongoDB Atlas بوصفها طبقة خدمة مجانية لتوفير قاعدة البيانات، وهي مناسبة لبيئة التطوير والتعلم لأنها تجعل نظام تشغيل التثبيت مستقلًا، وتُعَد قاعدة البيانات التي تمثل خدمة Database-as-a-service أيضًا إحدى الطرق التي يمكن أن تستخدمها لقاعدة بيانات بيئة الإنتاج. الاتصال بقاعدة بيانات MongoDB تتطلب مكتبة Mongoose اتصالًا بقاعدة بيانات MongoDB، وذلك باستخدام الدالة require() والاتصال بقاعدة بيانات مستضافة محليًا باستخدام mongoose.connect() كما يلي، ولكن سنتّصل بدلًا من ذلك في هذا المقال بقاعدة بيانات مستضافة عبر الإنترنت: // استيراد وحدة mongoose const mongoose = require("mongoose"); // اضبط `strictQuery: false` للاشتراك العام في الترشيح وفق الخاصيات غير المُدرَجة في المخطط // لأن هذا الخيار يزيل تحذيرات Mongoose 7 الأولية. // اطّلع على https://mongoosejs.com/docs/migrating_to_6.html#strictquery-is-removed-and-replaced-by-strict mongoose.set("strictQuery", false); // حدّد عنوان URL لقاعدة البيانات للاتصال به const mongoDB = "mongodb://127.0.0.1/my_database"; // انتظر حتى الاتصال بقاعدة البيانات، مع تسجيل خطأ إذا كانت هناك مشكلة main().catch((err) => console.log(err)); async function main() { await mongoose.connect(mongoDB); } ملاحظة: ننتظر await الوعد الذي يعيده التابع connect() ضمن دالة مُصرَّح عنها باستخدام async function كما ناقشنا سابقًا في قسم واجهات برمجة التطبيقات لقاعدة البيانات غير المتزامنة من هذا المقال. نستخدم المعالج catch() الخاص بالوعد لمعالجة الأخطاء عند محاولة الاتصال، ولكن يمكن أيضًا استدعاء main() ضمن كتلة try...catch. يمكنك الحصول على كائن Connection الافتراضي باستخدام mongoose.connection، وإذا كنت بحاجة إلى إنشاء اتصالات إضافية، فيمكنك استخدام التابع mongoose.createConnection() الذي يأخذ صيغة معرّف URI نفسه الخاص بقاعدة البيانات (مع المضيف وقاعدة البيانات والمنفذ والخيارات وإلخ) الذي يستخدمه التابع connect() ويعيد كائن Connection. لاحظ أن createConnection() يعيد مباشرةً، وبالتالي إذا كنت بحاجة إلى الانتظار حتى إنشاء الاتصال، فيمكنك استدعاؤه مع asPromise() لإعادة وعد (mongoose.createConnection(mongoDB).asPromise()). تعريف وإنشاء النماذج تُعرَّف النماذج باستخدام الواجهة Schema التي تتيح تعريف الحقول المُخزَّنة في المستندات مع متطلبات التحقق من صحة البيانات والقيم الافتراضية. يمكنك أيضًا تعريف التوابع المساعدة الثابتة ونُسَخ منها لتسهيل العمل مع أنواع بياناتك، والخاصيات الافتراضية التي يمكنك استخدامها مثل الحقول الأخرى، ولكنها غير مخزنة في قاعدة البيانات فعليًا (سنناقش ذلك لاحقًا). تُصرَّف بعد ذلك واجهات Schema إلى نماذج باستخدام التابع mongoose.model()، ثم يمكنك استخدام النموذج للعثور على كائنات من نوعٍ محدَّد وإنشائها وتحديثها وحذفها. ملاحظة: يُربَط كل نموذج بمجموعة من المستندات في قاعدة بيانات MongoDB، إذ ستحتوي المستندات على أنواع الحقول/المخططات Schema المحددة في نموذج Schema. تعريف المخططات يوضّح جزء الشيفرة البرمجية التالي كيفية تعريف مخطط بسيط، إذ يجب أولًا طلب مكتبة mongoose باستخدام الدالة require()، ثم استخدم باني Schema لإنشاء نسخة من المخطط الجديد، مع تعريف الحقول المختلفة ضمنه في معامل باني الكائن. // طلب مكتبة Mongoose const mongoose = require("mongoose"); // تعريف مخطط const Schema = mongoose.Schema; const SomeModelSchema = new Schema({ a_string: String, a_date: Date, }); لدينا في المثال السابق حقلين فقط نوعاهما: سلسلة نصية String وتاريخ Date، وسنعرض في الأقسام التالية بعض أنواع الحقول الأخرى والتحقق من صحتها والتوابع الأخرى. إنشاء نموذج تُنشَأ النماذج من المخططات باستخدام التابع mongoose.model() كما يلي: // تعريف مخطط const Schema = mongoose.Schema; const SomeModelSchema = new Schema({ a_string: String, a_date: Date, }); // تصريف النموذج من المخطط const SomeModel = mongoose.model("SomeModel", SomeModelSchema); الوسيط الأول هو الاسم المفرد للمجموعة التي ستُنشَأ لنموذجك، إذ ستنشِئ مكتبة Mongoose مجموعة قاعدة البيانات للنموذج SomeModel السابق، والوسيط الثاني هو المخطط الذي تريد استخدامه في إنشاء النموذج. ملاحظة: يمكنك استخدام أصناف Classes نموذجك بعد تعريفها لإنشاء سجلات أو تحديثها أو حذفها، ويمكنك تشغيل الاستعلامات للحصول على جميع السجلات أو مجموعات فرعية معينة من السجلات. سنوضح كيفية تحقيق ذلك لاحقًا في قسم استخدام النماذج وعندما ننشئ العروض Views. أنواع المخططات والحقول يمكن أن يحتوي المخطط على عدد عشوائي من الحقول، إذ يمثل كلٌّ منها حقلًا في المستندات المخزنة في قاعدة بيانات MongoDB. يوضّح المثال التالي مخططًا يحتوي على العديد من أنواع الحقول وكيفية التصريح عنها: const schema = new Schema({ name: String, binary: Buffer, living: Boolean, updated: { type: Date, default: Date.now() }, age: { type: Number, min: 18, max: 65, required: true }, mixed: Schema.Types.Mixed, _someId: Schema.Types.ObjectId, array: [], ofString: [String], // يمكنك أيضًا الحصول على مصفوفة لكل نوع من الأنواع الأخرى nested: { stuff: { type: String, lowercase: true, trim: true } }, }); لا تحتاج معظم أنواع المخططات SchemaTypes (الواصفات الموجودة بعد "type:" أو بعد أسماء الحقول) شرحًا، ولكن هناك بعض الاستثناءات وهي: ObjectId: يمثل نسخًا محدّدة لنموذجٍ في قاعدة البيانات، فمثلًا يمكن أن يستخدم الكتاب هذا النوع لتمثيل كائن مؤلفه، وسيحتوي هذا النوع على معرّف فريد (_id) للكائن، ويمكننا استخدام التابع populate() لسحب المعلومات عند الحاجة. Mixed: نوع مخطط عشوائي. []: مصفوفة من العناصر، إذ يمكنك إجراء عمليات مصفوفات جافاسكربت على هذه النماذج (الدفع والسحب إلغاء الإزاحة وإلخ). توضح الأمثلة السابقة مصفوفةً من الكائنات بدون نوع محدد ومصفوفة من كائنات String، ولكن يمكن أن يكون لديك مصفوفة من أيّ نوع من الكائنات. توضّح الشيفرة البرمجية أيضًا طريقتين للتصريح عن الحقل هما: اسم الحقل ونوعه مثل زوج قيمة-مفتاح (كما هو الحال مع اسم الحقول name و binary و living مثلًا). اسم الحقل متبوعًا بكائن يحدد النوع type وأيّ خيارات أخرى للحقل، إذ تتضمن هذه الخيارات ما يلي: قيم افتراضية. أدوات التحقق المبنية مسبقًا، مثل القيم العليا أو الدنيا، ودوال التحقق من صحة البيانات المُخصَّصة. ما إذا كان الحقل مطلوبًا. ما إذا كان يجب ضبط حقول String تلقائيًا بأحرف صغيرة أو كبيرة أو حذف المسافات في بداية ونهاية السلسلة النصية، مثل: { type: String, lowercase: true, trim: true } اطّلع على أنواع المخططات في توثيق Mongoose لمزيد من المعلومات حول الخيارات. التحقق من صحة البيانات توفر مكتبة Mongoose أدوات تحقق من صحة البيانات مبنية مسبقًا ومخصصة، وأدوات تحقق متزامنة وغير متزامنة، وتسمح بتحديد كلٍّ من مجال القيم المقبول ورسالة الخطأ التي تمثل فشل التحقق من صحة البيانات في جميع الحالات. تتضمن أدوات التحقق من صحة البيانات المبنية مسبقًا ما يلي: تحتوي جميع أنواع المخططات على أداة التحقق required المبنية مسبقًا التي تُستخدم لتحديد ما إذا كان يجب توفير الحقل لحفظ مستندٍ ما. تحتوي الأعداد Numbers على أدوات تحقق من صحة الحد الأدنى min والحد الأعلى max. تحتوي السلاسل النصية Strings على أدوات التحقق التالية: enum: تحدد مجموعة القيم المسموح بها للحقل. match: تحدد التعبير النمطي Regular Expression الذي يجب أن تتطابق معه السلسلة النصية. الطول الأقصى maxLength والطول الأدنى minLength للسلسلة النصية. يوضح المثال التالي -المأخوذ من توثيق Mongoose- كيفية تحديد بعض أنواع أدوات التحقق من صحة البيانات ورسائل الخطأ: const breakfastSchema = new Schema({ eggs: { type: Number, min: [6, "Too few eggs"], max: 12, required: [true, "Why no eggs?"], }, drink: { type: String, enum: ["Coffee", "Tea", "Water"], }, }); اطّلع على التحقق من صحة البيانات في توثيق Mongoose للحصول على معلومات كاملة حول التحقق من صحة الحقول. الخاصيات الافتراضية الخاصيات الافتراضية هي خاصيات المستند التي يمكنك جلبها وضبطها دون استمرار وجودها في قاعدة بيانات MongoDB، إذ تُعَد الجوالب Getters مفيدة لتنسيق الحقول أو دمجها، وتكون الضوابط Setters مفيدة في تفكيك قيمة واحدة إلى قيم متعددة لتخزينها. يبني المثال الموجود في توثيق Mongoose (ويهدم) خاصية افتراضية للاسم الكامل من حقل الاسم الأول والأخير، ويُعَد ذلك أسهل وأنظف من بناء اسم كامل في كل مرة يُستخدَم أحدها في قالب. ملاحظة: سنستخدم خاصية افتراضية في موقع المكتبة المحلية لتعريف عنوان URL فريد لكل سجل نموذج باستخدام مسار وقيمة _id الخاصة بالسجل. اطلع على الخاصيات الافتراضية في توثيق Mongoose لمزيد من المعلومات. التوابع والاستعلامات المساعدة يمكن أن يحتوي المخطط أيضًا على نسخ من التوابع Instance methods وتوابع ثابتة static methods واستعلامات مساعدة query helpers، إذ تتشابه نسخ التوابع والتوابع الثابتة، ولكن مع وجود اختلاف واضح في أن نسخ التوابع مرتبطة بسجل معين ويمكنها الوصول إلى الكائن الحالي. تسمح الاستعلامات المساعدة بتوسيع واجهة برمجة تطبيقات باني الاستعلامات القابلة للتسلسل الخاصة بمكتبة mongoose، مثل السماح بإضافة استعلام وفق الاسم "byName"، إضافةً إلى توابع find() و findOne() و findById(). استخدام النماذج يمكنك بعد إنشاء مخطط استخدامه لإنشاء النماذج، إذ يمثل النموذج مجموعة من المستندات الموجودة في قاعدة البيانات التي يمكنك البحث عنها، بينما تمثل نسخ النموذج المستندات الفردية التي يمكنك حفظها واسترجاعها. سنقدم فيما يلي نظرة عامة موجزة، لذا يمكنك الاطلاع على النماذج في توثيق Mongoose لمزيد من المعلومات. ملاحظة: يُعَد إنشاء السجلات وتحديثها وحذفها والاستعلام عنها عمليات غير متزامنة تعيد وعدًا. سنوضح في الأمثلة التالية استخدام التوابع المتعلقة بهذا الموضوع والتابع await، أي سنوضح الشيفرة البرمجية الأساسي لاستخدام التوابع، إذ سنحذف دالة async function المحيطة وكتلة try...catch لالتقاط الأخطاء للتوضيح. إنشاء وتعديل المستندات يمكنك إنشاء سجل من خلال تعريف نسخة من النموذج ثم استدعاء save(). تفترض الأمثلة التالية أن SomeModel هو نموذج (له حقل واحد هو name) أنشأناه من المخطط. // أنشئ نسخة من النموذج SomeModel const awesome_instance = new SomeModel({ name: "awesome" }); // احفظ نسخة النموذج الجديدة بطريقة غير متزامنة await awesome_instance.save(); يمكنك أيضًا استخدام create() لتعريف نسخة من النموذج في الوقت الذي تحفظها فيه. سننشئ فيما يلي نسخة واحدة فقط، ولكن يمكنك إنشاء نسخ متعددة من خلال تمرير مصفوفة من الكائنات. await SomeModel.create({ name: "also_awesome" }); لكل نموذج اتصاله المرتبط به، والذي سيكون الاتصال الافتراضي عند استخدام mongoose.model()، ويمكنك إنشاء اتصال جديد واستدعاء .model() لإنشاء المستندات في قاعدة بيانات مختلفة. يمكنك الوصول إلى الحقول في هذا السجل الجديد باستخدام الصيغة النقطية وتغيير القيم، ويجب استدعاء save() أو update() لتخزين القيم المُعدَّلة في قاعدة البيانات. // الوصول إلى قيم حقول النموذج باستخدام الصيغة النقطية console.log(awesome_instance.name); // يجب تسجيل 'also_awesome' أيضًا // تغيير السجل من خلال تعديل الحقول ثم استدعاء save() awesome_instance.name = "New cool name"; await awesome_instance.save(); البحث عن السجلات يمكنك البحث عن السجلات باستخدام توابع الاستعلام من خلال تحديد شروط الاستعلام بوصفها مستند JSON. يوضح جزء الشيفرة التالي كيفية العثور على جميع الرياضيين Athlete الذين يلعبون كرة المضرب في قاعدة بيانات، ويعيد فقط حقول اسم name وعُمر age الرياضي، إذ نحدد فقط حقلًا واحدًا مطابقًا (الرياضة sport)، ولكن يمكنك إضافة مزيدٍ من المعايير أو تحديد معايير التعبير النمطي أو إزالة جميع الشروط لإعادة جميع الرياضيين. const Athlete = mongoose.model("Athlete", yourSchema); // العثور على جميع الرياضيين الذين يلعبون كرة المضرب مع تحديد حقول 'name' و 'age' const tennisPlayers = await Athlete.find( { sport: "Tennis" }, "name age" ).exec(); ملاحظة: من المهم أن تتذكر أن عدم العثور على أي نتائج ليس خطأً في البحث، ولكنه يمكن أن يكون حالة فشل في سياق تطبيقك. إذا توقّع تطبيقك بحثًا ما للعثور على قيمة، فيمكنك التحقق من عدد المدخلات المُعَادة في النتيجة. تعيد واجهات برمجة تطبيقات الاستعلام مثل find() متغيرًا من النوع Query، ويمكنك استخدام كائن استعلام لبناء استعلام ضمن أجزاء قبل تنفيذه باستخدام التابع exec() الذي ينفّذ الاستعلام ويعيد وعدًا يمكنك انتظاره باستخدام await للحصول على النتيجة. // العثور على جميع الرياضيين الذين يلعبون كرة المضرب const query = Athlete.find({ sport: "Tennis" }); // اختيار حقول 'name' و 'age' query.select("name age"); // قصر نتائجنا على 5 عناصر query.limit(5); // الفرز وفق العمر query.sort({ age: -1 }); // تنفيذ الاستعلام في وقت لاحق query.exec(); عرّفنا شروط الاستعلام في التابع find()، ويمكننا تطبيق ذلك أيضًا باستخدام الدالة where()، ويمكننا سَلسَلة جميع أجزاء الاستعلام مع بعضها باستخدام المعامل النقطي (.) بدلًا من إضافتها بصورة منفصلة. جزء الشيفرة البرمجية التالي هو الاستعلام السابق نفسه مع شرط إضافي للعُمر: Athlete.find() .where("sport") .equals("Tennis") .where("age") .gt(17) .lt(50) // استعلام where إضافي .limit(5) .sort({ age: -1 }) .select("name age") .exec(); يحصل التابع find() على جميع السجلات المطابقة، ولكنك تريد الحصول على تطابق واحد فقط في أغلب الأحيان، لذا يمكنك استخدام توابع الاستعلام التالية لسجل واحد: findById(): يبحث عن المستند باستخدام المعرّف id، فلكل مستندٍ معرّفٌ فريد. findOne(): يبحث عن مستند واحد يطابق معاييرًا محدَّدة. findByIdAndRemove() و findByIdAndUpdate() و findOneAndRemove() و findOneAndUpdate(): تبحث عن مستند واحد باستخدام المعرّف id أو المعايير، فإما أن تحدّثه أو تزيله، إذ تُعَد هذه الدوال ملائمة ومفيدة لتحديث السجلات وإزالتها. ملاحظة: هناك أيضًا التابع countDocuments() الذي يمكنك استخدامه للحصول على عدد العناصر التي تطابق الشروط، ويُعَد مفيدًا إذا أردتَ إجراء تعداد دون جلب السجلات فعليًا. هناك الكثير من الأمور التي يمكنك تطبيقها على الاستعلامات، لذا اطّلع على الاستعلامات في توثيق Mongoose لمزيد من المعلومات. العمل مع المستندات- الملء Population يمكنك إنشاء مراجعٍ من نسخة مستند أو نموذج إلى آخر باستخدام حقل المخطط ObjectId، أو من مستند إلى عدة مستندات باستخدام مصفوفة من ObjectId. يخزّن هذا الحقل معرّف النموذج المرتبط به، وإذا كنت بحاجة إلى محتوى المستند الفعلي، فيمكنك استخدام التابع populate() في استعلام لاستبدال المعرّف بالبيانات الفعلية. يعرّف المخطط التالي مثلًا المؤلفين والقصص، إذ يمكن أن يكون لكل مؤلف قصص متعددة، والتي نمثلها بوصفها مصفوفة من ObjectId، ويمكن أن يكون لكل قصة مؤلف واحد. تخبر الخاصية ref المخطط بالنموذج الذي يمكن إسناده إلى هذا الحقل. const mongoose = require("mongoose"); const Schema = mongoose.Schema; const authorSchema = Schema({ name: String, stories: [{ type: Schema.Types.ObjectId, ref: "Story" }], }); const storySchema = Schema({ author: { type: Schema.Types.ObjectId, ref: "Author" }, title: String, }); const Story = mongoose.model("Story", storySchema); const Author = mongoose.model("Author", authorSchema); يمكننا حفظ المراجع التي تشير إلى المستند من خلال إسناد قيمة _id إليها، إذ سننشئ فيما يلي مؤلفًا ثم ننشئ قصة ونسند معرّف المؤلف إلى حقل مؤلف القصة: const bob = new Author({ name: "Bob Smith" }); await bob.save(); // Bob موجود الآن، لذا لننشئ قصة const story = new Story({ title: "Bob goes sledding", author: bob._id, // إسناد _id للمؤلف Bob، إذ يُنشَأ هذا المعرّف افتراضيًا }); await story.save(); ملاحظة: إحدى الفوائد الرائعة لهذا النمط من البرمجة هي أنه لا يتعين علينا تعقيد المسار الرئيسي لشيفرتنا البرمجية من خلال التحقق من الأخطاء، فإذا فشلت أيّ عملية حفظ save()، سيُرفَض الوعد وسيُرمَى خطأ. تتعامل شيفرة معالجة الأخطاء مع ذلك بصورة منفصلة (في كتلة catch() عادةً)، لذا يُعَد الهدف من شيفرتنا البرمجية واضحًا جدًا. يحتوي مستند القصة الآن على مؤلف يُشار إليه باستخدام معرّف مستند المؤلف، ونستخدم التابع populate() كما هو موضح فيما يلي للحصول على معلومات المؤلف في نتائج القصة: Story.findOne({ title: "Bob goes sledding" }) .populate("author") // استبدال معرّف المؤلف بمعلومات المؤلف الفعلية في النتائج .exec(); ملاحظة: سيلاحظ القراء المتمرسون أننا أضفنا مؤلفًا إلى القصة، لكننا لم نفعل أي شيء لإضافة القصة إلى مصفوفة stories الخاصة بالمؤلف. تتمثل إحدى الطرق للحصول على جميع القصص لمؤلف معين في إضافة القصة إلى مصفوفة القصص، ولكن ذلك يمكن أن يؤدي إلى وجود مكانين للاحتفاظ بالمعلومات المتعلقة بالمؤلفين والقصص. توجد طريقة أفضل، وهي الحصول على معرّف _id المؤلف، ثم استخدام find() للبحث عنه في حقل المؤلف عبر جميع القصص. Story.find({ author: bob._id }).exec(); اطلّع على Population في توثيق Mongoose لمزيد من المعلومات التفصيلية. مخطط أو نموذج واحد لكل ملف يمكنك إنشاء مخططات ونماذج باستخدام أي بنية ملفات تريدها، ولكننا نوصي بتعريف كل مخطط نموذج في وحدته أو ملفه الخاص، ثم تصدير التابع لإنشاء النموذج كما يلي: // الملف: ./models/somemodel.js // طلب Mongoose const mongoose = require("mongoose"); // تعريف مخطط const Schema = mongoose.Schema; const SomeModelSchema = new Schema({ a_string: String, a_date: Date, }); // تصدير دالة لإنشاء صنف النموذج "SomeModel" module.exports = mongoose.model("SomeModel", SomeModelSchema); يمكنك بعد ذلك طلب النموذج واستخدامه مباشرةً في ملفات أخرى، وسنوضح فيما يلي كيفية استخدامه للحصول على جميع نسخ النموذج: // إنشاء نموذج SomeModel من خلال طلب الوحدة const SomeModel = require("../models/somemodel"); // استخدام كائن (نموذج) SomeModel للعثور على كافة سجلات SomeModel const modelInstances = await SomeModel.find().exec(); إعداد قاعدة بيانات MongoDB تعرّفنا على ما يمكن أن تفعله مكتبة Mongoose وكيفية تصميم نماذجنا، وحان الوقت الآن لبدء العمل على موقع المكتبة المحلية LocalLibrary، وأول شيء يجب فعله هو إعداد قاعدة بيانات MongoDB التي يمكننا استخدامها لتخزين بيانات مكتبتنا. سنستخدم في هذا المقال قاعدة البيانات التجريبية المُستضافَة على السحابة MongoDB Atlas، إذ لا تُعَد طبقة قاعدة البيانات هذه مناسبة لمواقع الويب في بيئة الإنتاج لأنها لا تحتوي على تكرار Redundancy، ولكنها رائعة لعملية التطوير والنماذج الأولية، وسنستخدمها لأنها مجانية وسهلة الإعداد، ولأنها بائع شائع لقاعدة البيانات التي تمثل خدمة، والتي يمكن أن تختارها لقاعدة بيانات الإنتاج الخاصة بك، وتشمل الخيارات الشائعة الأخرى Compose و ScaleGrid و ObjectRocket. ملاحظة: يمكنك أيضًا إعداد قاعدة بيانات MongoDb محليًا من خلال تنزيل وتثبيت الملفات الثنائية المناسبة لنظامك، إذ ستكون بقية الإرشادات الواردة في هذا المقال متشابهة باستثناء عنوان URL لقاعدة البيانات الذي يمكن أن تحدده عند الاتصال. نستضيف لاحقًا في مقال نشر تطبيق Express في بيئة الإنتاج كلًا من التطبيق وقاعدة البيانات على منصة Railway، ولكن يمكن أيضًا استخدام قاعدة بيانات على MongoDB Atlas. يجب أولًا إنشاء حساب على MongoDB Atlas، وهو مجاني ويتطلب فقط إدخال تفاصيل الاتصال الأساسية والإقرار بشروط الخدمة. ستنتقل بعد تسجيل الدخول إلى الشاشة الرئيسية، لذا اتبع الخطوات التالية: أولًا، انقر على زر "إنشاء Create" في قسم نظرة عامة Overview. ثانيًا، سيؤدي ذلك إلى فتح شاشة نشر قاعدة بيانات سحابية Deploy a cloud database. انقر على زر MO FREE. ثالثًا، سيؤدي ذلك إلى سرد خيارات مختلفة للاختيار بينها: حدد أي مزوّد من قسم المزوّد والمنطقة Provider & Region، إذ تقدّم المناطق المختلفة مزوّدين مختلفين. يمكنك تغيير اسم العنقود ضمن قسم اسم العنقود Cluster Name، إذ سنسميه Cluster0. انقر بعد ذلك على زر "إنشاء عنقود Create Cluster"، وسيستغرق إنشاء العنقود بضع دقائق. رابعًا، سيؤدي ذلك إلى فتح قسم بداية سريعة للأمان Security Quickstart. أدخِل اسم المستخدم وكلمة المرور، وتذكّر نسخ الاعتماديات وتخزينها بأمان إذ سنحتاج إليها لاحقًا. انقر على زر "إنشاء مستخدم Create User". ملاحظة: تجنب استخدام محارف خاصة في كلمة مرور مستخدم MongoDB لأن مكتبة Mongoose يمكن ألّا يحلّل سلسلة الاتصال بصورة صحيحة. أدخل 0.0.0.0/0 في حقل عنوان IP الذي يخبر قاعدة بيانات MongoDB أننا نريد السماح بالوصول من أيّ مكان، ثم انقر على زر "إضافة إدخال Add Entry". ملاحظة: يُعَد قصر عناوين IP التي يمكنها الاتصال على قاعدة بياناتك ومواردك الأخرى من أفضل الممارسات، ولكن سنسمح في مثالنا بالاتصال من أيّ مكان لأننا لا نعرف من أين سيأتي الطلب بعد النشر. انقر بعد ذلك على زر "إنهاء وإغلاق Finish and Close". خامسًا، سيؤدي ذلك إلى فتح الشاشة التالية، لذا انقر على زر "الانتقال إلى قواعد البيانات Go to Databases". سادسًا، ستعود بعد ذلك إلى شاشة نظرة عامة Overview. انقر على قسم قاعدة البيانات Database تحت قائمة "Deployment" الموجودة على اليسار وانقر على زر استعراض التجميعات Browse Collections. سابعًا، سيؤدي ذلك إلى فتح قسم التجميعات Collections. انقر على زر "إضافة بياناتي الخاصة Add My Own Data". ثامنًا، ستظهر الآن شاشة إنشاء قاعدة بيانات Create Database. أدخِل الاسم local_library لاسم قاعدة البيانات الجديدة، ثم أدخِل اسم المجموعة Collection0، ثم انقر على زر "إنشاء Create" لإنشاء قاعدة البيانات. تاسعًا، ستعود إلى شاشة المجموعات Collections مع وجود قاعدة بياناتك التي أنشأتها. انقر على نافذة "نظرة عامة Overview" للعودة إلى شاشة نظرة عامة على العنقود. عاشرًا، انقر على زر "اتصال Connect" من شاشة نظرة عامة Overview للعنقود Cluster0. سيؤدي ذلك إلى فتح شاشة الاتصال بالعنقود Connect to Cluster. انقر على خيار Drivers الموجود تحت خيار الاتصال بتطبيقك Connect your application. أخيرًا، ستظهر لك شاشة الاتصال Connect. اتبع بعد ذلك الخطوات التالية: حدد مشغّل driver ونسخة Node كما هو موضح في الشكل السابق. انقر على أيقونة النسخ Copy لنسخ سلسلة الاتصال. الصقها في محرر نصوصك المحلي. حدّث اسم المستخدم وكلمة المرور بكلمة مرور مستخدمك. أدخِل اسم قاعدة البيانات "local_library" في المسار قبل الخيارات (...mongodb.net/local_library?retryWrites...). احفظ الملف الذي يحتوي على هذه السلسلة في مكان آمن. أنشأتَ قاعدة البيانات، ولديك عنوان URL (مع اسم مستخدم وكلمة مرور) الذي يمكن استخدامه للوصول إليها، إذ سيبدو كما يلي: mongodb+srv://your_user_name:your_password@cluster0.lz91hw2.mongodb.net/local_library?retryWrites=true&w=majority تثبيت Mongoose افتح موجّه الأوامر وانتقل إلى المجلد الذي أنشأتَ فيه موقعك الهيكلي الخاص بالمكتبة المحلية، ثم أدخِل الأمر التالي لتثبيت مكتبة Mongoose (واعتمادياتها) وضِفها إلى ملف package.json، إن لم تكن قد فعلتَ ذلك مسبقًا عند قراءة فقرة مقدمة إلى مكتبة Mongoose. npm install mongoose الاتصال بقاعدة بيانات MongoDB افتح الملف "/app.js" في جذر مشروعك وانسخ النص التالي في مكان التصريح عن كائن تطبيق Express (بعد سطر const app = express();). ضع عنوان URL الخاص بالموقع الذي يمثل قاعدة بياناتك (أي باستخدام المعلومات الواردة من mongoDB Atlas) مكان سلسلة عنوان URL لقاعدة البيانات ('insert_your_database_url_here'). // إعداد اتصال mongoose const mongoose = require("mongoose"); mongoose.set("strictQuery", false); const mongoDB = "insert_your_database_url_here"; main().catch((err) => console.log(err)); async function main() { await mongoose.connect(mongoDB); } تنشئ هذه الشيفرة البرمجية الاتصال الافتراضي بقاعدة البيانات ويبلّغ عن وجود أيّ أخطاء في الطرفية. تعريف مخطط المكتبة المحلية سنعرّف وحدة منفصلة لكل نموذج كما وضّحنا سابقًا. ابدأ بإنشاء مجلد للنماذج في جذر المشروع (/models) ثم أنشئ ملفات منفصلة لكل نموذج كما يلي: /express-locallibrary-tutorial // the project root /models author.js book.js bookinstance.js genre.js نموذج المؤلف Author انسخ شيفرة مخطط المؤلف Author التالية والصقها في ملف "./models/author.js"، إذ يعرّف هذا المخطط مؤلفًا يحتوي على حقول من نوع المخطط String للاسم الأول واسم العائلة (مطلوبة بحد أقصى 100 محرف) وحقول من النوع Date لتواريخ الميلاد والوفاة. const mongoose = require("mongoose"); const Schema = mongoose.Schema; const AuthorSchema = new Schema({ first_name: { type: String, required: true, maxLength: 100 }, family_name: { type: String, required: true, maxLength: 100 }, date_of_birth: { type: Date }, date_of_death: { type: Date }, }); // الخاصية الافتراضية لاسم المؤلف الكامل AuthorSchema.virtual("name").get(function () { // يمكن تجنب الأخطاء في الحالات التي لا يحمل فيها المؤلف اسم عائلة أو اسمًا أولًا // من خلال التأكد من معالجة الاستثناء عبر إعادة سلسلة فارغة لهذه الحالة let fullname = ""; if (this.first_name && this.family_name) { fullname = `${this.family_name}, ${this.first_name}`; } return fullname; }); // الخاصية الافتراضية لعنوان URL الخاص بالمؤلف AuthorSchema.virtual("url").get(function () { // لا نستخدم دالة سهمية لأننا نحتاج إلى هذا الكائن return `/catalog/author/${this._id}`; }); // تصدير النموذج module.exports = mongoose.model("Author", AuthorSchema); صرّحنا عن الخاصية الافتراضية لمخطط المؤلف AuthorSchema بالاسم "url"، والتي تعرض عنوان URL المطلق المطلوب للحصول على نسخة معينة من النموذج، إذ سنستخدم هذه الخاصية في قوالبنا كلما احتجنا إلى الحصول على ارتباط إلى مؤلف معين. ملاحظة: يُعَد التصريح عن عناوين URL بوصفها خاصيات افتراضية في المخطط فكرةً جيدة لأن عنوان URL لعنصرٍ ما يجب تغييره في مكانٍ واحد فقط. لن يعمل الرابط الذي يستخدم عنوان URL هذا حاليًا، لأنه ليس لدينا أيّ شيفرة لمعالجة الوجهات Routes لنسخ النماذج الفردية، إذ سنضبطها في مقالٍ لاحق. نصدّر بعد ذلك النموذج في نهاية الوحدة. نموذج الكتاب Book انسخ شيفرة مخطط الكتاب Book التالية والصقها في الملف "./models/book.js"، والتي تشبه في معظمها نموذج المؤلف، إذ صرّحنا عن مخطط يحتوي على عدد من الحقول من النوع String وخاصية افتراضية للحصول على عنوان URL لسجلات كتاب معينة، ثم صدّرنا النموذج. const mongoose = require("mongoose"); const Schema = mongoose.Schema; const BookSchema = new Schema({ title: { type: String, required: true }, author: { type: Schema.Types.ObjectId, ref: "Author", required: true }, summary: { type: String, required: true }, isbn: { type: String, required: true }, genre: [{ type: Schema.Types.ObjectId, ref: "Genre" }], }); // الخاصية الافتراضية لعنوان URL الخاص بالكتاب BookSchema.virtual("url").get(function () { // لا نستخدم دالة سهمية لأننا نحتاج إلى هذا الكائن return `/catalog/book/${this._id}`; }); // تصدير النموذج module.exports = mongoose.model("Book", BookSchema); الاختلاف الرئيسي هنا هو أننا أنشأنا مرجعين إلى نماذج أخرى هما: المؤلف author هو مرجع إلى كائن نموذج Author واحد، وهو مطلوب. النوع genre هو مرجع إلى مصفوفة من كائنات نموذج Genre، ولكننا لم نصرّح عن هذا الكائن بعد. نموذج نسخة الكتاب BookInstance انسخ شيفرة مخطط BookInstance التالية والصقها في الملف "./models/bookinstance.js"، إذ يمثل BookInstance نسخةً محددةً من الكتاب الذي يمكن أن يستعيره شخص ما ويتضمن معلومات حول ما إذا كانت النسخة متوفرة، والتاريخ المتوقع لاسترجاعها، وتفاصيل "الطبعة" أو النسخة. const mongoose = require("mongoose"); const Schema = mongoose.Schema; const BookInstanceSchema = new Schema({ book: { type: Schema.Types.ObjectId, ref: "Book", required: true }, // reference to the associated book imprint: { type: String, required: true }, status: { type: String, required: true, enum: ["Available", "Maintenance", "Loaned", "Reserved"], default: "Maintenance", }, due_back: { type: Date, default: Date.now }, }); // الخاصية الافتراضية لعنوان URL الخاص بالكتاب BookInstanceSchema.virtual("url").get(function () { // لا نستخدم دالة سهمية لأننا نحتاج إلى هذا الكائن return `/catalog/bookinstance/${this._id}`; }); // تصدير النموذج module.exports = mongoose.model("BookInstance", BookInstanceSchema); الأشياء الجديدة هي خيارات الحقول التالية: enum: يسمح بضبط القيم المسموح بها من نوع السلسلة النصية String، إذ نستخدمه في هذه الحالة لتحديد حالة توفر الكتب. يعني استخدام enum أنه يمكننا منع الأخطاء الإملائية والقيم العشوائية للحالة. default: نستخدمه لضبط الحالة الافتراضية لنسخ الكتاب التي أنشأناها على القيمة "في الصيانة Maintenance" وتاريخ due_back الافتراضي على القيمة now. لاحظ كيفية استدعاء دالة التاريخ Date عند ضبط التاريخ. يجب أن يكون كل شيء آخر مألوفًا من المخطط السابق. نموذج نوع الكتاب Genre- التحدي افتح الملف "./models/genre.js" وأنشئ مخططًا لتخزين أنواع الكتب (فئة الكتاب مثل ما إذا كان كتابًا خياليًا أو غير خيالي أو عاطفيًا أو تاريخيًا عسكريًا وغير ذلك). سيكون التعريف مشابهًا جدًا للنماذج الأخرى: يجب أن يحتوي النموذج على نوع المخطط String بالاسم name لوصف نوع الكتاب. يجب أن يكون هذا الاسم مطلوبًا ويتكون من 3 إلى 100 محرف. التصريح عن الخاصية الافتراضية لعنوان URL الخاص بنوع الكتاب بالاسم url. تصدير النموذج. إنشاء بعض العناصر للاختبار لدينا الآن جميع النماذج المُعدَّة للموقع، ويمكننا اختبار النماذج وإنشاء بعض أمثلة الكتب والعناصر الأخرى التي يمكننا استخدامها في المقالات اللاحقة من خلال تشغيل سكربت مستقل لإنشاء عناصر لكل نوع. أولًا، نزّل أو أنشئ الملف populatedb.js ضمن المجلد express-locallibrary-tutorial (في مستوى الملف package.json نفسه). ملاحظة: لست بحاجة إلى معرفة كيفية عمل الملف "populatedb.js"، فهو يضيف فقط عينة بيانات إلى قاعدة البيانات. ثانيًا، شغّل السكريبت باستخدام أمر node في موجه أوامرك مع تمرير عنوان URL لقاعدة بيانات MongoDB (عنوان URL نفسه الذي وضعته مكان العنصر البديل insert_your_database_url_here في الملف app.js سابقًا): node populatedb <your mongodb url> ملاحظة: يجب تغليف عنوان URL لقاعدة البيانات ضمن علامات اقتباس (") مزدوجة في نظام ويندوز، ويمكن أن تحتاج إلى علامات اقتباس مفردة (') في أنظمة التشغيل الأخرى. ثالثًا، يجب تشغيل السكريبت حتى اكتماله، إذ يعرض العناصر أثناء إنشائها في الطرفية. ملاحظة: انتقل إلى قاعدة بياناتك على MongoDB Atlas في نافذة التجميعات Collections، إذ يجب أن تكون الآن قادرًا على التنقل في مجموعات الكتب والمؤلفين والأنواع ونسخ الكتب والتحقق من المستندات الفردية. الخلاصة تعلمنا في هذا المقال بعض الأشياء عن قواعد البيانات ونماذج ORM على Node/Express، وتعرّفنا على كيفية تعريف مخطط ونماذج Mongoose، ثم استخدمنا هذه المعلومات لتصميم وتقديم نماذج Book و BookInstance و Author و Genre لموقع المكتبة المحلية LocalLibrary، واختبرنا نماذجنا من خلال إنشاء عدد من نسخ باستخدام سكريبت مستقل. سنتعرّف في المقال التالي على إنشاء بعض الصفحات لعرض هذه الكائنات. ترجمة -وبتصرُّف- للمقال Express Tutorial Part 3: Using a Database with Mongoose. اقرأ أيضًا المقال السابق تطبيق عملي لتعلم Express - الجزء الأول: إنشاء موقع ويب هيكلي لمكتبة محلية مقارنة بين MySQL و MongoDB تجهيز قاعدة البيانات PostgreSQL والتّعريف بمفهومي ORM وإضافات Flask دمج قاعدة البيانات MongoDB في تطبيقك Node
يقدّم هذا المقال مقدمة موجزة عن قواعد البيانات وكيفية استخدامها مع تطبيقات Node/Express، ثم يوضّح كيفية استخدام مكتبة Mongoose لتوفير الوصول إلى قاعدة بيانات موقع المكتبة المحلية LocalLibrary، ويشرح كيفية التصريح عن مخطط الكائنات object schema والنماذج Models، وأنواع الحقول الرئيسية والتحقق الأساسي من صحة البيانات. يعرض أيضًا بإيجاز بعض الطرق الرئيسية التي يمكنك من خلالها الوصول إلى بيانات النموذج. المتطلبات الأساسية: الاطلاع على مقال إنشاء موقع ويب هيكلي لمكتبة محلية. الهدف: أن تكون قادرًا على تصميم وإنشاء نماذجك باستخدام مكتبة Mongoose. يستخدم موظفو المكتبة موقع المكتبة المحلية لتخزين المعلومات حول الكتب والمستعيرين، بينما يستخدمه أعضاء المكتبة لتصفح الكتب والبحث عنها ولمعرفة ما إذا كان هناك أيّ نسخ متاحة ثم حجزها أو استعارتها. لذا سنخزّن المعلومات في قاعدة بيانات لتخزينها واسترجاعها بكفاءة. يمكن لتطبيقات Express استخدام العديد من قواعد البيانات المختلفة، وهناك العديد من الأساليب التي يمكنك استخدامها لإجراء عمليات الإنشاء والقراءة والتحديث والحذف -أو CRUD اختصارًا. يقدم هذا المقال نظرةً عامةً موجزة عن بعض الخيارات المتاحة ثم ينتقل ليشرح الآليات المختارة بالتفصيل. قواعد البيانات الممكن استخدامها يمكن لتطبيقات Express استخدام أيّ قاعدة بيانات تدعمها بيئة Node، إذ لا يحدد إطارعمل Express أيّ سلوك أو متطلبات إضافية محددة لإدارة قاعدة البيانات، وهناك العديد من الخيارات الشائعة بما في ذلك قواعد بيانات PostgreSQL و MySQL و Redis و SQLite و MongoDB وغير ذلك. يجب أن تأخذ في حساباتك عند اختيار قاعدة بيانات أشياءً مثل منحنى الوقت لتعلمها أو للحصول على نتائج والأداء وسهولة التكرار أو النسخ الاحتياطي والتكلفة ودعم المجتمع وغير ذلك. لا توجد قاعدة بيانات أفضل من الأخرى، ولكن تُعَد أيّ قاعدة بيانات شائعة تقريبًا مقبولة بصورة جيدة لموقع صغير إلى متوسط الحجم مثل موقع مكتبتنا المحلية. اطلع على تكامل قاعدة البيانات في توثيق Express لمزيد من المعلومات حول هذه الخيارات. أفضل طريقة للتفاعل مع قاعدة البيانات هناك طريقتان شائعتان للتفاعل مع قاعدة البيانات، هما: استخدام لغة الاستعلام الأصيلة لقواعد البيانات مثل لغة SQL. استخدام نموذج بيانات الكائن Object Data Model -أو اختصارًا ODM- أو نموذج الكائنات العلاقي Object Relational Model -أو ORM اختصارًا. يمثل نموذج ODM/ORM بيانات موقع الويب بوصفها كائنات جافا سكريبت، والتي تُربَط بعد ذلك بقاعدة البيانات الأساسية، إذ ترتبط بعض نماذج ORM بقاعدة بيانات معينة، بينما يوفر بعضها الآخر واجهة خلفية لا تعتمد على قاعدة البيانات. يمكن الحصول على أفضل أداء باستخدام لغة SQL أو أيّ لغة استعلام تدعمها قاعدة البيانات، إذ يُعَد نموذج ODM أبطأ لأنه يستخدم شيفرة ترجمة للربط بين الكائنات وتنسيق قاعدة البيانات، إذ يمكن ألّا يستخدم هذا النموذج استعلامات قاعدة البيانات الأكثر كفاءة، وهذا صحيح بصورة خاصة إذا كان نموذج ODM يدعم واجهات خلفية لقواعد بيانات مختلفة، وبالتالي يجب تقديم تنازلات أكبر فيما يتعلق بميزات قاعدة البيانات المدعومة. تتمثل فائدة استخدام نموذج ORM في أنه يمكن للمبرمجين الاستمرار في التفكير وفق مصطلحات كائنات جافاسكربت بدلًا من دلالات قواعد البيانات، وهذا صحيح بصورة خاصة إذا كنت بحاجة إلى العمل مع قواعد بيانات مختلفة على موقع الويب نفسه أو مواقع ويب مختلفة، ويوفر هذا النموذج أيضًا مكانًا واضحًا لإجراء التحقق من صحة البيانات. ملاحظة: يؤدي استخدام نماذج ODM/ORM إلى انخفاض تكاليف التطوير والصيانة، إذ يجب أن تفكر كثيرًا في استخدام نموذج ODM إلّا إذا كنت على دراية بلغة الاستعلام الأصيلة أو إذا كان الأداء أمرًا بالغ الأهمية. نموذج ORM/ODM الذي يجب أن استخدامه هناك العديد من حلول ODM/ORM المتاحة على موقع مدير الحزم npm (اطلع على odm و orm للتعرف على بعض من هذه الحلول). إليك بعضًا من هذه الحلول الشائعة: Mongoose: هي أداة نمذجة كائنات قاعدة بيانات MongoDB المُصمَّمة للعمل في بيئة غير متزامنة. Waterline: هو نموذج ORM المُستخرَج من إطار عمل الويب Sails القائم على إطار عمل Express. يوفر واجهة برمجة تطبيقات مُوحَّدة للوصول إلى العديد من قواعد البيانات المختلفة، بما في ذلك Redis و MySQL و LDAP و MongoDB و Postgres. Bookshelf: يتميز بواجهات رد النداء Callback التقليدية القائمة على الوعود Promise، مما يوفر دعمًا لمعامَلات قاعدة البيانات وتحميل العلاقات النشط أو النشط المتداخل والارتباطات متعددة الأشكال ودعم علاقات واحد إلى واحد one-to-one وواحد إلى متعدد one-to-many ومتعدد إلى متعدد many-to-many، ويعمل مع قواعد بيانات PostgreSQL و MySQL و SQLite3. يمكنك الاطلاع على مقال العلاقات بين الجداول في SQL على أكاديمية حسوب لمزيدٍ من المعلومات حول العلاقات بين الجداول. Objection: يسهّل قدر الإمكان استخدام قوة لغة SQL الكاملة ومحرك قاعدة البيانات الأساسي، ويدعم SQLite3 و Postgres و MySQL. Sequelize: هو نموذج ORM مبني على الوعود لكلٍّ من Node.js و io.js، ويدعم الأنواع المختلفة من لغات PostgreSQL و MySQL و MariaDB و SQLite و MSSQL ويتميز بدعمٍ قوي للمعامَلات transaction والعلاقات وتكرار عمليات القراءة وغير ذلك. Node ORM2: هو مدير علاقات الكائنات الخاص ببيئة NodeJS، ويدعم MySQL و SQLite و Progress، مما يساعد على العمل مع قاعدة البيانات باستخدام أسلوب موجَّه بالكائنات. GraphQL: لغة استعلام أساسية لواجهات برمجة التطبيقات restful API، وتحظى لغة GraphQL بشعبية كبيرة ولديها ميزات متاحة لقراءة البيانات من قواعد البيانات. يجب مراعاة كل من الميزات المتوفرة ونشاط المجتمع (التنزيلات والمساهمات وتقارير الأخطاء وجودة التوثيق وغير ذلك) عند اختيار الحل المناسب، وتُعَد مكتبة Mongoose أكثر نماذج ODM شيوعًا، وهو خيار جيد عند استخدام MongoDB لقاعدة بياناتك. استخدام مكتبة Mongoose وقاعدة بيانات MongoDB لموقع المكتبة المحلية سنستخدم في مثالنا مكتبة Mongoose بوصفها نموذج ODM للوصول إلى بيانات مكتبتنا، إذ تتصرف هذه المكتبة بمثابة واجهة أمامية لقاعدة بيانات MongoDB، وهي قاعدة بيانات NoSQL مفتوحة المصدر تستخدم نموذج بيانات موجَّهًا بالمستندات، إذ تشبه مجموعة المستندات في قاعدة بيانات MongoDB جدولًا من الصفوف في قاعدة بيانات علاقية. تحظى هذه المجموعة من نموذج ODM وقاعدة البيانات بشعبية كبيرة في مجتمع Node، ويرجع ذلك جزئيًا إلى أن تخزين المستندات ونظام الاستعلام يشبه إلى حد كبير JSON، وبالتالي فهو مألوف لمطوري جافا سكريبت. ملاحظة: لست بحاجة إلى معرفة قاعدة بيانات MongoDB لاستخدام مكتبة Mongoose، بالرغم من أن أجزاءً من توثيق Mongoose أسهل في الاستخدام والفهم إذا كنت على دراية بقاعدة بيانات MongoDB. سنوضح فيما يلي كيفية تعريف والوصول إلى مخطط ونماذج Mongoose لمثال موقع ويب المكتبة المحلية LocalLibrary. تصميم نماذج موقع المكتبة المحلية يفضَّل أخذ بضع دقائق للتفكير في البيانات التي يجب تخزينها والعلاقات بين الكائنات قبل البدء في كتابة شيفرة النماذج، إذ نعلم أننا بحاجةٍ إلى تخزين معلومات حول الكتب (العنوان والملخص والمؤلف ونوع الكتاب ورقم ISBN)، وقد يكون لدينا نسخٌ متعددة متاحة (مع معرّفات فريدة عامة وحالات توفرها وغير ذلك)، ويمكن أن نحتاج إلى تخزين مزيدٍ من المعلومات حول المؤلف أكثر من مجرد اسمه، ويمكن أن يكون هناك عدة مؤلفين لهم الاسم نفسه أو أسماء متشابهة. نريد أن نكون قادرين على فرز المعلومات بناءً على عنوان الكتاب والمؤلف ونوع الكتاب Genre وفئته Category. من المنطقي أن يكون لديك نماذج منفصلة لكل كائن (مجموعة من المعلومات المتعلقة ببعضها) عند تصميم نماذجك، وبالتالي فإن بعض المرشّحين الواضحين لهذه النماذج هم الكتب ونسخ الكتب والمؤلفون. يمكن أن ترغب في استخدام النماذج لتمثيل خيارات قائمة الاختيار (مثل قائمة اختيارات منسدلة) بدلًا من كتابة شيفرة ثابتة للخيارات في موقع الويب نفسه، إذ يوصَى بذلك عندما لا تكون جميع الخيارات معروفة مسبقًا أو أنها ستتغير، ومن الأمثلة الجيدة لذلك هو نوع الكتاب، مثل النوع الخيالي والخيال العلمي وغير ذلك. يجب الآن التفكير في العلاقات بين النماذج والحقول بعد تحديدها، إذ يوضح مخطط ارتباط باستخدام لغة UML الآتي النماذج التي سنعرّفها في حالتنا (على شكل صناديق)، إذ أنشأنا نماذجًا للكتاب (تفاصيل الكتاب العامة)، ونسخة الكتاب (حالة نسخ الكتاب الحقيقية المحدَّدة المتاحة في النظام)، والمؤلف، وقررنا أيضًا أن يكون لدينا نموذج لنوع الكتاب بحيث يمكن إنشاء القيم ديناميكيًا. لم ننشئ نموذجًا لحالة نسخة الكتاب BookInstance:status، إذ سنجعل القيم المقبولة ثابتة لأننا لا نتوقع تغييرها. يمكنك رؤية اسم النموذج وأسماء الحقول وأنواعها والتوابع وأنواع الإعادة الخاصة بها في كل صندوق. يوضح المخطط البياني الآتي أيضًا العلاقات بين النماذج، بما في ذلك درجة تعدّدها Multiplicities، وهي الأعداد الموجودة على المخطط والتي توضح عدد أو الحد الأقصى والحد الأدنى لكل نموذج الذي يمكن أن يكون موجودًا في العلاقة، فمثلًا يوضّح الخط المتصل بين الصناديق أن الكتاب Book والنوع Genre مرتبطان، وتوضح الأعداد القريبة من نموذج الكتاب Book أنه يجب يكون للنوع Genre صفر أو أكثر من الكتب Book (بقدر ما تريد)، بينما توضح الأعداد الموجودة على الطرف الآخر من الخط بجوار نموذج النوع Genre أن الكتاب يمكن أن يكون له صفر أو أكثر من الأنواع Genre المتعلقة به. ملاحظة: يُفضَّل غالبًا أن يكون لديك الحقل الذي يعرّف العلاقة بين المستندات/النماذج في نموذج واحد فقط كما سنوضّح لاحقًا، ولا يزال بإمكانك العثور على العلاقة العكسية من خلال البحث عن _id المرتبط بها في النموذج الآخر. اخترنا فيما يلي تعريف العلاقة بينBook/Genre و Book/Author في مخطط Schema الكتاب Book، والعلاقة بين Book/BookInstance في مخطط نسخة الكتاب BookInstance، إذ كان هذا الاختيار عشوائيًا إلى حدٍ ما، وكان من الممكن أيضًا أن يكون أحد الحقول موجودًا في المخطط الآخر. ملاحظة: يوفر القسم التالي شرحًا بسيطًا عن كيفية تعريف النماذج واستخدامها، لذلك ضع في بالك أثناء القراءة كيف سنبني كل نموذج من النماذج الموجودة في المخطط البياني السابق. واجهات برمجة تطبيقات قاعدة البيانات غير المتزامنة تُعَد توابع قاعدة البيانات لإنشاء السجلات أو العثور عليها أو تحديثها أو حذفها غير متزامنة، وهذا يعني أن التوابع تعيد القيم مباشرةً ويكون تشغيل الشيفرة البرمجية الخاصة بمعالجة نجاح أو فشل التابع في وقت لاحق عند اكتمال العملية. يمكن تنفيذ شيفرة برمجية أخرى أثناء انتظار الخادم لاكتمال عملية قاعدة البيانات، لذلك يمكن أن يظل الخادم مستجيبًا للطلبات الأخرى. تحتوي لغة جافا سكريبت Javascript على عدد من الآليات لدعم السلوك غير المتزامن، إذ اعتمدت كثيرًا سابقًا على تمرير دوال رد النداء إلى توابع غير متزامنة لمعالجة حالات النجاح والخطأ، وحلّت الوعود Promises محل دوال رد النداء إلى حد كبير في لغة جافا سكربت الحديثة. الوعود هي كائنات يعيدها (مباشرةً) تابع غير متزامن يمثل حالتها المستقبلية، ويستقر كائن الوعد عند اكتمال العملية، ويحقق كائنًا يمثل نتيجة العملية أو الخطأ. هناك طريقتان رئيسيتان يمكنك من خلالهما استخدام الوعود لتشغيل الشيفرة البرمجية عند استقرار الوعد، إذ نوصي بقراءة كيفية استخدام الوعود للحصول على نظرة عامة عالية المستوى على كلا الأسلوبين. سنستخدم في هذا المقال await لانتظار اكتمال الوعد في async function، لأن هذا الأسلوب يؤدي إلى الحصول على شيفرة برمجية غير متزامنة مفهومة وأكثر قابلية للقراءة. تتمثل الطريقة التي يعمل بها هذا الأسلوب في أنك تستخدم الكلمة الأساسية async function لتمييز الدالة بوصفها غير متزامنة، ثم تطبّق ضمن هذه الدالة تابع await على أيّ تابع يعيد وعدًا، وتتوقف عملية الدالة غير المتزامنة عند تنفيذها مؤقتًا عند أول تابع await حتى استقرار الوعد، ثم تعيد الدالة غير المتزامنة ويمكنك تشغيل الشيفرة البرمجية الموجودة بعد تلك الدالة من منظور الشيفرة البرمجية المحيطة. يعيد التابع await ضمن الدالة غير المتزامنة النتيجة لاحقًا عند استقرار الوعد، أو يعطي خطأً عند رفض الوعد، ثم تُنفَّذ الشيفرة البرمجية الموجودة في الدالة غير المتزامنة حتى يظهر تابع await آخر، إذ ستتوقف مؤقتًا مرةً أخرى، أو حتى تشغيل الشيفرة البرمجية بأكملها الموجودة في الدالة. يمكنك أن ترى كيفية عمل هذه الطريقة في المثال الآتي، إذ تُعَد myFunction() دالة غير متزامنة تُستدعَى ضمن كتلة try...catch. يُوقََف تنفيذ الشيفرة البرمجية مؤقتًا في التابع methodThatReturnsPromise() عند تشغيل الدالة myFunction() حتى تحقيق الوعد، وعندها يستمر تنفيذ الشيفرة البرمجية حتى الوصول إلى التابع aFunctionThatReturnsPromise() وينتظر مرةً أخرى. تُشغَّل الشيفرة البرمجية الموجودة في كتلة catch عند رمي خطأ في الدالة غير المتزامنة، إذ سيحدث ذلك عند رفض الوعد الذي يعيده أيّ من هذين التابعين. async function myFunction { // ... await someObject.methodThatReturnsPromise(); // ... await aFunctionThatReturnsPromise(); // ... } try { // ... myFunction(); // ... } catch (e) { // شيفرة معالجة الخطأ } تُشغَّل التوابع غير المتزامنة السابقة تسلسليًا، وإذا لم تعتمد التوابع على بعضها بعضًا، فيمكنك تشغيلها على التوازي وإنهاء العملية بأكملها بسرعة أكبر، ويمكن تحقيق ذلك باستخدام التابع Promise.all() الذي يأخذ تكرارًا من الوعود بوصفها دخلًا ويعيد وعدًا Promise واحدًا. يمكن الوفاء بهذا الوعد المُعاد عند الوفاء بجميع وعود الدخل مع مجموعة من قيم الوفاء، ويرفَض عند رفض أيٍّ من وعود الدخل مع سبب الرفض الأول. توضح الشيفرة البرمجية التالية كيفية عمل ذلك، إذ لدينا أولًا دالتان تعيدان وعودًا، إذ ننتظرهما await حتى يكتملا باستخدام الوعد الذي يعيده التابع Promise.all(). يعيد await بمجرد أن تكتمل كلتا الدالتين وتُملَأ مصفوفة النتائج، ثم يستمر تنفيذ الدالة حتى الوصول إلى تابع await التالي، وتنتظر حتى استقرار الوعد الذي تعيده الدالة anotherFunctionThatReturnsPromise(). يمكنك استدعاء الدالة myFunction() في كتلة try...catch لالتقاط الأخطاء. async function myFunction { // ... const [resultFunction1, resultFunction2] = await Promise.all([ functionThatReturnsPromise1(), functionThatReturnsPromise2() ]); // ... await anotherFunctionThatReturnsPromise(resultFunction1); } تسمح الوعود مع await/async بالتحكم المرن والمنطقي بالتنفيذ غير المتزامن. مقدمة إلى مكتبة Mongoose يقدم هذا القسم نظرةً عامة حول كيفية توصيل مكتبة Mongoose بقاعدة بيانات MongoDB، وكيفية تعريف المخططات والنماذج، وكيفية تطبيق الاستعلامات الأساسية. تثبيت Mongoose و MongoDB تُثبَّت مكتبة Mongoose في مشروعك (في الملف package.json) مثل أي اعتمادية أخرى باستخدام مدير حزم npm، إذ يمكن تثبيتها باستخدم الأمر التالي في مجلد مشروعك: npm install mongoose يضيف تثبيت مكتبة Mongoose جميع اعتمادياتها بما في ذلك مشغِّل قاعدة بيانات MongoDB، لكنه لا يؤدي إلى تثبيت MongoDB. إذا أدرتَ تثبيت خادم MongoDB، فيمكنك تنزيل المثبِّتات لأنظمة تشغيل مختلفة وتثبيتها محليًا، ويمكنك استخدام نسخ من MongoDB المستندة إلى السحابة. ملاحظة: سنستخدم في هذا المقال قاعدة البيانات المستندة إلى السحابة MongoDB Atlas بوصفها طبقة خدمة مجانية لتوفير قاعدة البيانات، وهي مناسبة لبيئة التطوير والتعلم لأنها تجعل نظام تشغيل التثبيت مستقلًا، وتُعَد قاعدة البيانات التي تمثل خدمة Database-as-a-service أيضًا إحدى الطرق التي يمكن أن تستخدمها لقاعدة بيانات بيئة الإنتاج. الاتصال بقاعدة بيانات MongoDB تتطلب مكتبة Mongoose اتصالًا بقاعدة بيانات MongoDB، وذلك باستخدام الدالة require() والاتصال بقاعدة بيانات مستضافة محليًا باستخدام mongoose.connect() كما يلي، ولكن سنتّصل بدلًا من ذلك في هذا المقال بقاعدة بيانات مستضافة عبر الإنترنت: // استيراد وحدة mongoose const mongoose = require("mongoose"); // اضبط `strictQuery: false` للاشتراك العام في الترشيح وفق الخاصيات غير المُدرَجة في المخطط // لأن هذا الخيار يزيل تحذيرات Mongoose 7 الأولية. // اطّلع على https://mongoosejs.com/docs/migrating_to_6.html#strictquery-is-removed-and-replaced-by-strict mongoose.set("strictQuery", false); // حدّد عنوان URL لقاعدة البيانات للاتصال به const mongoDB = "mongodb://127.0.0.1/my_database"; // انتظر حتى الاتصال بقاعدة البيانات، مع تسجيل خطأ إذا كانت هناك مشكلة main().catch((err) => console.log(err)); async function main() { await mongoose.connect(mongoDB); } ملاحظة: ننتظر await الوعد الذي يعيده التابع connect() ضمن دالة مُصرَّح عنها باستخدام async function كما ناقشنا سابقًا في قسم واجهات برمجة التطبيقات لقاعدة البيانات غير المتزامنة من هذا المقال. نستخدم المعالج catch() الخاص بالوعد لمعالجة الأخطاء عند محاولة الاتصال، ولكن يمكن أيضًا استدعاء main() ضمن كتلة try...catch. يمكنك الحصول على كائن Connection الافتراضي باستخدام mongoose.connection، وإذا كنت بحاجة إلى إنشاء اتصالات إضافية، فيمكنك استخدام التابع mongoose.createConnection() الذي يأخذ صيغة معرّف URI نفسه الخاص بقاعدة البيانات (مع المضيف وقاعدة البيانات والمنفذ والخيارات وإلخ) الذي يستخدمه التابع connect() ويعيد كائن Connection. لاحظ أن createConnection() يعيد مباشرةً، وبالتالي إذا كنت بحاجة إلى الانتظار حتى إنشاء الاتصال، فيمكنك استدعاؤه مع asPromise() لإعادة وعد (mongoose.createConnection(mongoDB).asPromise()). تعريف وإنشاء النماذج تُعرَّف النماذج باستخدام الواجهة Schema التي تتيح تعريف الحقول المُخزَّنة في المستندات مع متطلبات التحقق من صحة البيانات والقيم الافتراضية. يمكنك أيضًا تعريف التوابع المساعدة الثابتة ونُسَخ منها لتسهيل العمل مع أنواع بياناتك، والخاصيات الافتراضية التي يمكنك استخدامها مثل الحقول الأخرى، ولكنها غير مخزنة في قاعدة البيانات فعليًا (سنناقش ذلك لاحقًا). تُصرَّف بعد ذلك واجهات Schema إلى نماذج باستخدام التابع mongoose.model()، ثم يمكنك استخدام النموذج للعثور على كائنات من نوعٍ محدَّد وإنشائها وتحديثها وحذفها. ملاحظة: يُربَط كل نموذج بمجموعة من المستندات في قاعدة بيانات MongoDB، إذ ستحتوي المستندات على أنواع الحقول/المخططات Schema المحددة في نموذج Schema. تعريف المخططات يوضّح جزء الشيفرة البرمجية التالي كيفية تعريف مخطط بسيط، إذ يجب أولًا طلب مكتبة mongoose باستخدام الدالة require()، ثم استخدم باني Schema لإنشاء نسخة من المخطط الجديد، مع تعريف الحقول المختلفة ضمنه في معامل باني الكائن. // طلب مكتبة Mongoose const mongoose = require("mongoose"); // تعريف مخطط const Schema = mongoose.Schema; const SomeModelSchema = new Schema({ a_string: String, a_date: Date, }); لدينا في المثال السابق حقلين فقط نوعاهما: سلسلة نصية String وتاريخ Date، وسنعرض في الأقسام التالية بعض أنواع الحقول الأخرى والتحقق من صحتها والتوابع الأخرى. إنشاء نموذج تُنشَأ النماذج من المخططات باستخدام التابع mongoose.model() كما يلي: // تعريف مخطط const Schema = mongoose.Schema; const SomeModelSchema = new Schema({ a_string: String, a_date: Date, }); // تصريف النموذج من المخطط const SomeModel = mongoose.model("SomeModel", SomeModelSchema); الوسيط الأول هو الاسم المفرد للمجموعة التي ستُنشَأ لنموذجك، إذ ستنشِئ مكتبة Mongoose مجموعة قاعدة البيانات للنموذج SomeModel السابق، والوسيط الثاني هو المخطط الذي تريد استخدامه في إنشاء النموذج. ملاحظة: يمكنك استخدام أصناف Classes نموذجك بعد تعريفها لإنشاء سجلات أو تحديثها أو حذفها، ويمكنك تشغيل الاستعلامات للحصول على جميع السجلات أو مجموعات فرعية معينة من السجلات. سنوضح كيفية تحقيق ذلك لاحقًا في قسم استخدام النماذج وعندما ننشئ العروض Views. أنواع المخططات والحقول يمكن أن يحتوي المخطط على عدد عشوائي من الحقول، إذ يمثل كلٌّ منها حقلًا في المستندات المخزنة في قاعدة بيانات MongoDB. يوضّح المثال التالي مخططًا يحتوي على العديد من أنواع الحقول وكيفية التصريح عنها: const schema = new Schema({ name: String, binary: Buffer, living: Boolean, updated: { type: Date, default: Date.now() }, age: { type: Number, min: 18, max: 65, required: true }, mixed: Schema.Types.Mixed, _someId: Schema.Types.ObjectId, array: [], ofString: [String], // يمكنك أيضًا الحصول على مصفوفة لكل نوع من الأنواع الأخرى nested: { stuff: { type: String, lowercase: true, trim: true } }, }); لا تحتاج معظم أنواع المخططات SchemaTypes (الواصفات الموجودة بعد "type:" أو بعد أسماء الحقول) شرحًا، ولكن هناك بعض الاستثناءات وهي: ObjectId: يمثل نسخًا محدّدة لنموذجٍ في قاعدة البيانات، فمثلًا يمكن أن يستخدم الكتاب هذا النوع لتمثيل كائن مؤلفه، وسيحتوي هذا النوع على معرّف فريد (_id) للكائن، ويمكننا استخدام التابع populate() لسحب المعلومات عند الحاجة. Mixed: نوع مخطط عشوائي. []: مصفوفة من العناصر، إذ يمكنك إجراء عمليات مصفوفات جافاسكربت على هذه النماذج (الدفع والسحب إلغاء الإزاحة وإلخ). توضح الأمثلة السابقة مصفوفةً من الكائنات بدون نوع محدد ومصفوفة من كائنات String، ولكن يمكن أن يكون لديك مصفوفة من أيّ نوع من الكائنات. توضّح الشيفرة البرمجية أيضًا طريقتين للتصريح عن الحقل هما: اسم الحقل ونوعه مثل زوج قيمة-مفتاح (كما هو الحال مع اسم الحقول name و binary و living مثلًا). اسم الحقل متبوعًا بكائن يحدد النوع type وأيّ خيارات أخرى للحقل، إذ تتضمن هذه الخيارات ما يلي: قيم افتراضية. أدوات التحقق المبنية مسبقًا، مثل القيم العليا أو الدنيا، ودوال التحقق من صحة البيانات المُخصَّصة. ما إذا كان الحقل مطلوبًا. ما إذا كان يجب ضبط حقول String تلقائيًا بأحرف صغيرة أو كبيرة أو حذف المسافات في بداية ونهاية السلسلة النصية، مثل: { type: String, lowercase: true, trim: true } اطّلع على أنواع المخططات في توثيق Mongoose لمزيد من المعلومات حول الخيارات. التحقق من صحة البيانات توفر مكتبة Mongoose أدوات تحقق من صحة البيانات مبنية مسبقًا ومخصصة، وأدوات تحقق متزامنة وغير متزامنة، وتسمح بتحديد كلٍّ من مجال القيم المقبول ورسالة الخطأ التي تمثل فشل التحقق من صحة البيانات في جميع الحالات. تتضمن أدوات التحقق من صحة البيانات المبنية مسبقًا ما يلي: تحتوي جميع أنواع المخططات على أداة التحقق required المبنية مسبقًا التي تُستخدم لتحديد ما إذا كان يجب توفير الحقل لحفظ مستندٍ ما. تحتوي الأعداد Numbers على أدوات تحقق من صحة الحد الأدنى min والحد الأعلى max. تحتوي السلاسل النصية Strings على أدوات التحقق التالية: enum: تحدد مجموعة القيم المسموح بها للحقل. match: تحدد التعبير النمطي Regular Expression الذي يجب أن تتطابق معه السلسلة النصية. الطول الأقصى maxLength والطول الأدنى minLength للسلسلة النصية. يوضح المثال التالي -المأخوذ من توثيق Mongoose- كيفية تحديد بعض أنواع أدوات التحقق من صحة البيانات ورسائل الخطأ: const breakfastSchema = new Schema({ eggs: { type: Number, min: [6, "Too few eggs"], max: 12, required: [true, "Why no eggs?"], }, drink: { type: String, enum: ["Coffee", "Tea", "Water"], }, }); اطّلع على التحقق من صحة البيانات في توثيق Mongoose للحصول على معلومات كاملة حول التحقق من صحة الحقول. الخاصيات الافتراضية الخاصيات الافتراضية هي خاصيات المستند التي يمكنك جلبها وضبطها دون استمرار وجودها في قاعدة بيانات MongoDB، إذ تُعَد الجوالب Getters مفيدة لتنسيق الحقول أو دمجها، وتكون الضوابط Setters مفيدة في تفكيك قيمة واحدة إلى قيم متعددة لتخزينها. يبني المثال الموجود في توثيق Mongoose (ويهدم) خاصية افتراضية للاسم الكامل من حقل الاسم الأول والأخير، ويُعَد ذلك أسهل وأنظف من بناء اسم كامل في كل مرة يُستخدَم أحدها في قالب. ملاحظة: سنستخدم خاصية افتراضية في موقع المكتبة المحلية لتعريف عنوان URL فريد لكل سجل نموذج باستخدام مسار وقيمة _id الخاصة بالسجل. اطلع على الخاصيات الافتراضية في توثيق Mongoose لمزيد من المعلومات. التوابع والاستعلامات المساعدة يمكن أن يحتوي المخطط أيضًا على نسخ من التوابع Instance methods وتوابع ثابتة static methods واستعلامات مساعدة query helpers، إذ تتشابه نسخ التوابع والتوابع الثابتة، ولكن مع وجود اختلاف واضح في أن نسخ التوابع مرتبطة بسجل معين ويمكنها الوصول إلى الكائن الحالي. تسمح الاستعلامات المساعدة بتوسيع واجهة برمجة تطبيقات باني الاستعلامات القابلة للتسلسل الخاصة بمكتبة mongoose، مثل السماح بإضافة استعلام وفق الاسم "byName"، إضافةً إلى توابع find() و findOne() و findById(). استخدام النماذج يمكنك بعد إنشاء مخطط استخدامه لإنشاء النماذج، إذ يمثل النموذج مجموعة من المستندات الموجودة في قاعدة البيانات التي يمكنك البحث عنها، بينما تمثل نسخ النموذج المستندات الفردية التي يمكنك حفظها واسترجاعها. سنقدم فيما يلي نظرة عامة موجزة، لذا يمكنك الاطلاع على النماذج في توثيق Mongoose لمزيد من المعلومات. ملاحظة: يُعَد إنشاء السجلات وتحديثها وحذفها والاستعلام عنها عمليات غير متزامنة تعيد وعدًا. سنوضح في الأمثلة التالية استخدام التوابع المتعلقة بهذا الموضوع والتابع await، أي سنوضح الشيفرة البرمجية الأساسي لاستخدام التوابع، إذ سنحذف دالة async function المحيطة وكتلة try...catch لالتقاط الأخطاء للتوضيح. إنشاء وتعديل المستندات يمكنك إنشاء سجل من خلال تعريف نسخة من النموذج ثم استدعاء save(). تفترض الأمثلة التالية أن SomeModel هو نموذج (له حقل واحد هو name) أنشأناه من المخطط. // أنشئ نسخة من النموذج SomeModel const awesome_instance = new SomeModel({ name: "awesome" }); // احفظ نسخة النموذج الجديدة بطريقة غير متزامنة await awesome_instance.save(); يمكنك أيضًا استخدام create() لتعريف نسخة من النموذج في الوقت الذي تحفظها فيه. سننشئ فيما يلي نسخة واحدة فقط، ولكن يمكنك إنشاء نسخ متعددة من خلال تمرير مصفوفة من الكائنات. await SomeModel.create({ name: "also_awesome" }); لكل نموذج اتصاله المرتبط به، والذي سيكون الاتصال الافتراضي عند استخدام mongoose.model()، ويمكنك إنشاء اتصال جديد واستدعاء .model() لإنشاء المستندات في قاعدة بيانات مختلفة. يمكنك الوصول إلى الحقول في هذا السجل الجديد باستخدام الصيغة النقطية وتغيير القيم، ويجب استدعاء save() أو update() لتخزين القيم المُعدَّلة في قاعدة البيانات. // الوصول إلى قيم حقول النموذج باستخدام الصيغة النقطية console.log(awesome_instance.name); // يجب تسجيل 'also_awesome' أيضًا // تغيير السجل من خلال تعديل الحقول ثم استدعاء save() awesome_instance.name = "New cool name"; await awesome_instance.save(); البحث عن السجلات يمكنك البحث عن السجلات باستخدام توابع الاستعلام من خلال تحديد شروط الاستعلام بوصفها مستند JSON. يوضح جزء الشيفرة التالي كيفية العثور على جميع الرياضيين Athlete الذين يلعبون كرة المضرب في قاعدة بيانات، ويعيد فقط حقول اسم name وعُمر age الرياضي، إذ نحدد فقط حقلًا واحدًا مطابقًا (الرياضة sport)، ولكن يمكنك إضافة مزيدٍ من المعايير أو تحديد معايير التعبير النمطي أو إزالة جميع الشروط لإعادة جميع الرياضيين. const Athlete = mongoose.model("Athlete", yourSchema); // العثور على جميع الرياضيين الذين يلعبون كرة المضرب مع تحديد حقول 'name' و 'age' const tennisPlayers = await Athlete.find( { sport: "Tennis" }, "name age" ).exec(); ملاحظة: من المهم أن تتذكر أن عدم العثور على أي نتائج ليس خطأً في البحث، ولكنه يمكن أن يكون حالة فشل في سياق تطبيقك. إذا توقّع تطبيقك بحثًا ما للعثور على قيمة، فيمكنك التحقق من عدد المدخلات المُعَادة في النتيجة. تعيد واجهات برمجة تطبيقات الاستعلام مثل find() متغيرًا من النوع Query، ويمكنك استخدام كائن استعلام لبناء استعلام ضمن أجزاء قبل تنفيذه باستخدام التابع exec() الذي ينفّذ الاستعلام ويعيد وعدًا يمكنك انتظاره باستخدام await للحصول على النتيجة. // العثور على جميع الرياضيين الذين يلعبون كرة المضرب const query = Athlete.find({ sport: "Tennis" }); // اختيار حقول 'name' و 'age' query.select("name age"); // قصر نتائجنا على 5 عناصر query.limit(5); // الفرز وفق العمر query.sort({ age: -1 }); // تنفيذ الاستعلام في وقت لاحق query.exec(); عرّفنا شروط الاستعلام في التابع find()، ويمكننا تطبيق ذلك أيضًا باستخدام الدالة where()، ويمكننا سَلسَلة جميع أجزاء الاستعلام مع بعضها باستخدام المعامل النقطي (.) بدلًا من إضافتها بصورة منفصلة. جزء الشيفرة البرمجية التالي هو الاستعلام السابق نفسه مع شرط إضافي للعُمر: Athlete.find() .where("sport") .equals("Tennis") .where("age") .gt(17) .lt(50) // استعلام where إضافي .limit(5) .sort({ age: -1 }) .select("name age") .exec(); يحصل التابع find() على جميع السجلات المطابقة، ولكنك تريد الحصول على تطابق واحد فقط في أغلب الأحيان، لذا يمكنك استخدام توابع الاستعلام التالية لسجل واحد: findById(): يبحث عن المستند باستخدام المعرّف id، فلكل مستندٍ معرّفٌ فريد. findOne(): يبحث عن مستند واحد يطابق معاييرًا محدَّدة. findByIdAndRemove() و findByIdAndUpdate() و findOneAndRemove() و findOneAndUpdate(): تبحث عن مستند واحد باستخدام المعرّف id أو المعايير، فإما أن تحدّثه أو تزيله، إذ تُعَد هذه الدوال ملائمة ومفيدة لتحديث السجلات وإزالتها. ملاحظة: هناك أيضًا التابع countDocuments() الذي يمكنك استخدامه للحصول على عدد العناصر التي تطابق الشروط، ويُعَد مفيدًا إذا أردتَ إجراء تعداد دون جلب السجلات فعليًا. هناك الكثير من الأمور التي يمكنك تطبيقها على الاستعلامات، لذا اطّلع على الاستعلامات في توثيق Mongoose لمزيد من المعلومات. العمل مع المستندات- الملء Population يمكنك إنشاء مراجعٍ من نسخة مستند أو نموذج إلى آخر باستخدام حقل المخطط ObjectId، أو من مستند إلى عدة مستندات باستخدام مصفوفة من ObjectId. يخزّن هذا الحقل معرّف النموذج المرتبط به، وإذا كنت بحاجة إلى محتوى المستند الفعلي، فيمكنك استخدام التابع populate() في استعلام لاستبدال المعرّف بالبيانات الفعلية. يعرّف المخطط التالي مثلًا المؤلفين والقصص، إذ يمكن أن يكون لكل مؤلف قصص متعددة، والتي نمثلها بوصفها مصفوفة من ObjectId، ويمكن أن يكون لكل قصة مؤلف واحد. تخبر الخاصية ref المخطط بالنموذج الذي يمكن إسناده إلى هذا الحقل. const mongoose = require("mongoose"); const Schema = mongoose.Schema; const authorSchema = Schema({ name: String, stories: [{ type: Schema.Types.ObjectId, ref: "Story" }], }); const storySchema = Schema({ author: { type: Schema.Types.ObjectId, ref: "Author" }, title: String, }); const Story = mongoose.model("Story", storySchema); const Author = mongoose.model("Author", authorSchema); يمكننا حفظ المراجع التي تشير إلى المستند من خلال إسناد قيمة _id إليها، إذ سننشئ فيما يلي مؤلفًا ثم ننشئ قصة ونسند معرّف المؤلف إلى حقل مؤلف القصة: const bob = new Author({ name: "Bob Smith" }); await bob.save(); // Bob موجود الآن، لذا لننشئ قصة const story = new Story({ title: "Bob goes sledding", author: bob._id, // إسناد _id للمؤلف Bob، إذ يُنشَأ هذا المعرّف افتراضيًا }); await story.save(); ملاحظة: إحدى الفوائد الرائعة لهذا النمط من البرمجة هي أنه لا يتعين علينا تعقيد المسار الرئيسي لشيفرتنا البرمجية من خلال التحقق من الأخطاء، فإذا فشلت أيّ عملية حفظ save()، سيُرفَض الوعد وسيُرمَى خطأ. تتعامل شيفرة معالجة الأخطاء مع ذلك بصورة منفصلة (في كتلة catch() عادةً)، لذا يُعَد الهدف من شيفرتنا البرمجية واضحًا جدًا. يحتوي مستند القصة الآن على مؤلف يُشار إليه باستخدام معرّف مستند المؤلف، ونستخدم التابع populate() كما هو موضح فيما يلي للحصول على معلومات المؤلف في نتائج القصة: Story.findOne({ title: "Bob goes sledding" }) .populate("author") // استبدال معرّف المؤلف بمعلومات المؤلف الفعلية في النتائج .exec(); ملاحظة: سيلاحظ القراء المتمرسون أننا أضفنا مؤلفًا إلى القصة، لكننا لم نفعل أي شيء لإضافة القصة إلى مصفوفة stories الخاصة بالمؤلف. تتمثل إحدى الطرق للحصول على جميع القصص لمؤلف معين في إضافة القصة إلى مصفوفة القصص، ولكن ذلك يمكن أن يؤدي إلى وجود مكانين للاحتفاظ بالمعلومات المتعلقة بالمؤلفين والقصص. توجد طريقة أفضل، وهي الحصول على معرّف _id المؤلف، ثم استخدام find() للبحث عنه في حقل المؤلف عبر جميع القصص. Story.find({ author: bob._id }).exec(); اطلّع على Population في توثيق Mongoose لمزيد من المعلومات التفصيلية. مخطط أو نموذج واحد لكل ملف يمكنك إنشاء مخططات ونماذج باستخدام أي بنية ملفات تريدها، ولكننا نوصي بتعريف كل مخطط نموذج في وحدته أو ملفه الخاص، ثم تصدير التابع لإنشاء النموذج كما يلي: // الملف: ./models/somemodel.js // طلب Mongoose const mongoose = require("mongoose"); // تعريف مخطط const Schema = mongoose.Schema; const SomeModelSchema = new Schema({ a_string: String, a_date: Date, }); // تصدير دالة لإنشاء صنف النموذج "SomeModel" module.exports = mongoose.model("SomeModel", SomeModelSchema); يمكنك بعد ذلك طلب النموذج واستخدامه مباشرةً في ملفات أخرى، وسنوضح فيما يلي كيفية استخدامه للحصول على جميع نسخ النموذج: // إنشاء نموذج SomeModel من خلال طلب الوحدة const SomeModel = require("../models/somemodel"); // استخدام كائن (نموذج) SomeModel للعثور على كافة سجلات SomeModel const modelInstances = await SomeModel.find().exec(); إعداد قاعدة بيانات MongoDB تعرّفنا على ما يمكن أن تفعله مكتبة Mongoose وكيفية تصميم نماذجنا، وحان الوقت الآن لبدء العمل على موقع المكتبة المحلية LocalLibrary، وأول شيء يجب فعله هو إعداد قاعدة بيانات MongoDB التي يمكننا استخدامها لتخزين بيانات مكتبتنا. سنستخدم في هذا المقال قاعدة البيانات التجريبية المُستضافَة على السحابة MongoDB Atlas، إذ لا تُعَد طبقة قاعدة البيانات هذه مناسبة لمواقع الويب في بيئة الإنتاج لأنها لا تحتوي على تكرار Redundancy، ولكنها رائعة لعملية التطوير والنماذج الأولية، وسنستخدمها لأنها مجانية وسهلة الإعداد، ولأنها بائع شائع لقاعدة البيانات التي تمثل خدمة، والتي يمكن أن تختارها لقاعدة بيانات الإنتاج الخاصة بك، وتشمل الخيارات الشائعة الأخرى Compose و ScaleGrid و ObjectRocket. ملاحظة: يمكنك أيضًا إعداد قاعدة بيانات MongoDb محليًا من خلال تنزيل وتثبيت الملفات الثنائية المناسبة لنظامك، إذ ستكون بقية الإرشادات الواردة في هذا المقال متشابهة باستثناء عنوان URL لقاعدة البيانات الذي يمكن أن تحدده عند الاتصال. نستضيف لاحقًا في مقال نشر تطبيق Express في بيئة الإنتاج كلًا من التطبيق وقاعدة البيانات على منصة Railway، ولكن يمكن أيضًا استخدام قاعدة بيانات على MongoDB Atlas. يجب أولًا إنشاء حساب على MongoDB Atlas، وهو مجاني ويتطلب فقط إدخال تفاصيل الاتصال الأساسية والإقرار بشروط الخدمة. ستنتقل بعد تسجيل الدخول إلى الشاشة الرئيسية، لذا اتبع الخطوات التالية: أولًا، انقر على زر "إنشاء Create" في قسم نظرة عامة Overview. ثانيًا، سيؤدي ذلك إلى فتح شاشة نشر قاعدة بيانات سحابية Deploy a cloud database. انقر على زر MO FREE. ثالثًا، سيؤدي ذلك إلى سرد خيارات مختلفة للاختيار بينها: حدد أي مزوّد من قسم المزوّد والمنطقة Provider & Region، إذ تقدّم المناطق المختلفة مزوّدين مختلفين. يمكنك تغيير اسم العنقود ضمن قسم اسم العنقود Cluster Name، إذ سنسميه Cluster0. انقر بعد ذلك على زر "إنشاء عنقود Create Cluster"، وسيستغرق إنشاء العنقود بضع دقائق. رابعًا، سيؤدي ذلك إلى فتح قسم بداية سريعة للأمان Security Quickstart. أدخِل اسم المستخدم وكلمة المرور، وتذكّر نسخ الاعتماديات وتخزينها بأمان إذ سنحتاج إليها لاحقًا. انقر على زر "إنشاء مستخدم Create User". ملاحظة: تجنب استخدام محارف خاصة في كلمة مرور مستخدم MongoDB لأن مكتبة Mongoose يمكن ألّا يحلّل سلسلة الاتصال بصورة صحيحة. أدخل 0.0.0.0/0 في حقل عنوان IP الذي يخبر قاعدة بيانات MongoDB أننا نريد السماح بالوصول من أيّ مكان، ثم انقر على زر "إضافة إدخال Add Entry". ملاحظة: يُعَد قصر عناوين IP التي يمكنها الاتصال على قاعدة بياناتك ومواردك الأخرى من أفضل الممارسات، ولكن سنسمح في مثالنا بالاتصال من أيّ مكان لأننا لا نعرف من أين سيأتي الطلب بعد النشر. انقر بعد ذلك على زر "إنهاء وإغلاق Finish and Close". خامسًا، سيؤدي ذلك إلى فتح الشاشة التالية، لذا انقر على زر "الانتقال إلى قواعد البيانات Go to Databases". سادسًا، ستعود بعد ذلك إلى شاشة نظرة عامة Overview. انقر على قسم قاعدة البيانات Database تحت قائمة "Deployment" الموجودة على اليسار وانقر على زر استعراض التجميعات Browse Collections. سابعًا، سيؤدي ذلك إلى فتح قسم التجميعات Collections. انقر على زر "إضافة بياناتي الخاصة Add My Own Data". ثامنًا، ستظهر الآن شاشة إنشاء قاعدة بيانات Create Database. أدخِل الاسم local_library لاسم قاعدة البيانات الجديدة، ثم أدخِل اسم المجموعة Collection0، ثم انقر على زر "إنشاء Create" لإنشاء قاعدة البيانات. تاسعًا، ستعود إلى شاشة المجموعات Collections مع وجود قاعدة بياناتك التي أنشأتها. انقر على نافذة "نظرة عامة Overview" للعودة إلى شاشة نظرة عامة على العنقود. عاشرًا، انقر على زر "اتصال Connect" من شاشة نظرة عامة Overview للعنقود Cluster0. سيؤدي ذلك إلى فتح شاشة الاتصال بالعنقود Connect to Cluster. انقر على خيار Drivers الموجود تحت خيار الاتصال بتطبيقك Connect your application. أخيرًا، ستظهر لك شاشة الاتصال Connect. اتبع بعد ذلك الخطوات التالية: حدد مشغّل driver ونسخة Node كما هو موضح في الشكل السابق. انقر على أيقونة النسخ Copy لنسخ سلسلة الاتصال. الصقها في محرر نصوصك المحلي. حدّث اسم المستخدم وكلمة المرور بكلمة مرور مستخدمك. أدخِل اسم قاعدة البيانات "local_library" في المسار قبل الخيارات (...mongodb.net/local_library?retryWrites...). احفظ الملف الذي يحتوي على هذه السلسلة في مكان آمن. أنشأتَ قاعدة البيانات، ولديك عنوان URL (مع اسم مستخدم وكلمة مرور) الذي يمكن استخدامه للوصول إليها، إذ سيبدو كما يلي: mongodb+srv://your_user_name:your_password@cluster0.lz91hw2.mongodb.net/local_library?retryWrites=true&w=majority تثبيت Mongoose افتح موجّه الأوامر وانتقل إلى المجلد الذي أنشأتَ فيه موقعك الهيكلي الخاص بالمكتبة المحلية، ثم أدخِل الأمر التالي لتثبيت مكتبة Mongoose (واعتمادياتها) وضِفها إلى ملف package.json، إن لم تكن قد فعلتَ ذلك مسبقًا عند قراءة فقرة مقدمة إلى مكتبة Mongoose. npm install mongoose الاتصال بقاعدة بيانات MongoDB افتح الملف "/app.js" في جذر مشروعك وانسخ النص التالي في مكان التصريح عن كائن تطبيق Express (بعد سطر const app = express();). ضع عنوان URL الخاص بالموقع الذي يمثل قاعدة بياناتك (أي باستخدام المعلومات الواردة من mongoDB Atlas) مكان سلسلة عنوان URL لقاعدة البيانات ('insert_your_database_url_here'). // إعداد اتصال mongoose const mongoose = require("mongoose"); mongoose.set("strictQuery", false); const mongoDB = "insert_your_database_url_here"; main().catch((err) => console.log(err)); async function main() { await mongoose.connect(mongoDB); } تنشئ هذه الشيفرة البرمجية الاتصال الافتراضي بقاعدة البيانات ويبلّغ عن وجود أيّ أخطاء في الطرفية. تعريف مخطط المكتبة المحلية سنعرّف وحدة منفصلة لكل نموذج كما وضّحنا سابقًا. ابدأ بإنشاء مجلد للنماذج في جذر المشروع (/models) ثم أنشئ ملفات منفصلة لكل نموذج كما يلي: /express-locallibrary-tutorial // the project root /models author.js book.js bookinstance.js genre.js نموذج المؤلف Author انسخ شيفرة مخطط المؤلف Author التالية والصقها في ملف "./models/author.js"، إذ يعرّف هذا المخطط مؤلفًا يحتوي على حقول من نوع المخطط String للاسم الأول واسم العائلة (مطلوبة بحد أقصى 100 محرف) وحقول من النوع Date لتواريخ الميلاد والوفاة. const mongoose = require("mongoose"); const Schema = mongoose.Schema; const AuthorSchema = new Schema({ first_name: { type: String, required: true, maxLength: 100 }, family_name: { type: String, required: true, maxLength: 100 }, date_of_birth: { type: Date }, date_of_death: { type: Date }, }); // الخاصية الافتراضية لاسم المؤلف الكامل AuthorSchema.virtual("name").get(function () { // يمكن تجنب الأخطاء في الحالات التي لا يحمل فيها المؤلف اسم عائلة أو اسمًا أولًا // من خلال التأكد من معالجة الاستثناء عبر إعادة سلسلة فارغة لهذه الحالة let fullname = ""; if (this.first_name && this.family_name) { fullname = `${this.family_name}, ${this.first_name}`; } return fullname; }); // الخاصية الافتراضية لعنوان URL الخاص بالمؤلف AuthorSchema.virtual("url").get(function () { // لا نستخدم دالة سهمية لأننا نحتاج إلى هذا الكائن return `/catalog/author/${this._id}`; }); // تصدير النموذج module.exports = mongoose.model("Author", AuthorSchema); صرّحنا عن الخاصية الافتراضية لمخطط المؤلف AuthorSchema بالاسم "url"، والتي تعرض عنوان URL المطلق المطلوب للحصول على نسخة معينة من النموذج، إذ سنستخدم هذه الخاصية في قوالبنا كلما احتجنا إلى الحصول على ارتباط إلى مؤلف معين. ملاحظة: يُعَد التصريح عن عناوين URL بوصفها خاصيات افتراضية في المخطط فكرةً جيدة لأن عنوان URL لعنصرٍ ما يجب تغييره في مكانٍ واحد فقط. لن يعمل الرابط الذي يستخدم عنوان URL هذا حاليًا، لأنه ليس لدينا أيّ شيفرة لمعالجة الوجهات Routes لنسخ النماذج الفردية، إذ سنضبطها في مقالٍ لاحق. نصدّر بعد ذلك النموذج في نهاية الوحدة. نموذج الكتاب Book انسخ شيفرة مخطط الكتاب Book التالية والصقها في الملف "./models/book.js"، والتي تشبه في معظمها نموذج المؤلف، إذ صرّحنا عن مخطط يحتوي على عدد من الحقول من النوع String وخاصية افتراضية للحصول على عنوان URL لسجلات كتاب معينة، ثم صدّرنا النموذج. const mongoose = require("mongoose"); const Schema = mongoose.Schema; const BookSchema = new Schema({ title: { type: String, required: true }, author: { type: Schema.Types.ObjectId, ref: "Author", required: true }, summary: { type: String, required: true }, isbn: { type: String, required: true }, genre: [{ type: Schema.Types.ObjectId, ref: "Genre" }], }); // الخاصية الافتراضية لعنوان URL الخاص بالكتاب BookSchema.virtual("url").get(function () { // لا نستخدم دالة سهمية لأننا نحتاج إلى هذا الكائن return `/catalog/book/${this._id}`; }); // تصدير النموذج module.exports = mongoose.model("Book", BookSchema); الاختلاف الرئيسي هنا هو أننا أنشأنا مرجعين إلى نماذج أخرى هما: المؤلف author هو مرجع إلى كائن نموذج Author واحد، وهو مطلوب. النوع genre هو مرجع إلى مصفوفة من كائنات نموذج Genre، ولكننا لم نصرّح عن هذا الكائن بعد. نموذج نسخة الكتاب BookInstance انسخ شيفرة مخطط BookInstance التالية والصقها في الملف "./models/bookinstance.js"، إذ يمثل BookInstance نسخةً محددةً من الكتاب الذي يمكن أن يستعيره شخص ما ويتضمن معلومات حول ما إذا كانت النسخة متوفرة، والتاريخ المتوقع لاسترجاعها، وتفاصيل "الطبعة" أو النسخة. const mongoose = require("mongoose"); const Schema = mongoose.Schema; const BookInstanceSchema = new Schema({ book: { type: Schema.Types.ObjectId, ref: "Book", required: true }, // reference to the associated book imprint: { type: String, required: true }, status: { type: String, required: true, enum: ["Available", "Maintenance", "Loaned", "Reserved"], default: "Maintenance", }, due_back: { type: Date, default: Date.now }, }); // الخاصية الافتراضية لعنوان URL الخاص بالكتاب BookInstanceSchema.virtual("url").get(function () { // لا نستخدم دالة سهمية لأننا نحتاج إلى هذا الكائن return `/catalog/bookinstance/${this._id}`; }); // تصدير النموذج module.exports = mongoose.model("BookInstance", BookInstanceSchema); الأشياء الجديدة هي خيارات الحقول التالية: enum: يسمح بضبط القيم المسموح بها من نوع السلسلة النصية String، إذ نستخدمه في هذه الحالة لتحديد حالة توفر الكتب. يعني استخدام enum أنه يمكننا منع الأخطاء الإملائية والقيم العشوائية للحالة. default: نستخدمه لضبط الحالة الافتراضية لنسخ الكتاب التي أنشأناها على القيمة "في الصيانة Maintenance" وتاريخ due_back الافتراضي على القيمة now. لاحظ كيفية استدعاء دالة التاريخ Date عند ضبط التاريخ. يجب أن يكون كل شيء آخر مألوفًا من المخطط السابق. نموذج نوع الكتاب Genre- التحدي افتح الملف "./models/genre.js" وأنشئ مخططًا لتخزين أنواع الكتب (فئة الكتاب مثل ما إذا كان كتابًا خياليًا أو غير خيالي أو عاطفيًا أو تاريخيًا عسكريًا وغير ذلك). سيكون التعريف مشابهًا جدًا للنماذج الأخرى: يجب أن يحتوي النموذج على نوع المخطط String بالاسم name لوصف نوع الكتاب. يجب أن يكون هذا الاسم مطلوبًا ويتكون من 3 إلى 100 محرف. التصريح عن الخاصية الافتراضية لعنوان URL الخاص بنوع الكتاب بالاسم url. تصدير النموذج. إنشاء بعض العناصر للاختبار لدينا الآن جميع النماذج المُعدَّة للموقع، ويمكننا اختبار النماذج وإنشاء بعض أمثلة الكتب والعناصر الأخرى التي يمكننا استخدامها في المقالات اللاحقة من خلال تشغيل سكربت مستقل لإنشاء عناصر لكل نوع. أولًا، نزّل أو أنشئ الملف populatedb.js ضمن المجلد express-locallibrary-tutorial (في مستوى الملف package.json نفسه). ملاحظة: لست بحاجة إلى معرفة كيفية عمل الملف "populatedb.js"، فهو يضيف فقط عينة بيانات إلى قاعدة البيانات. ثانيًا، شغّل السكريبت باستخدام أمر node في موجه أوامرك مع تمرير عنوان URL لقاعدة بيانات MongoDB (عنوان URL نفسه الذي وضعته مكان العنصر البديل insert_your_database_url_here في الملف app.js سابقًا): node populatedb <your mongodb url> ملاحظة: يجب تغليف عنوان URL لقاعدة البيانات ضمن علامات اقتباس (") مزدوجة في نظام ويندوز، ويمكن أن تحتاج إلى علامات اقتباس مفردة (') في أنظمة التشغيل الأخرى. ثالثًا، يجب تشغيل السكريبت حتى اكتماله، إذ يعرض العناصر أثناء إنشائها في الطرفية. ملاحظة: انتقل إلى قاعدة بياناتك على MongoDB Atlas في نافذة التجميعات Collections، إذ يجب أن تكون الآن قادرًا على التنقل في مجموعات الكتب والمؤلفين والأنواع ونسخ الكتب والتحقق من المستندات الفردية. الخلاصة تعلمنا في هذا المقال بعض الأشياء عن قواعد البيانات ونماذج ORM على Node/Express، وتعرّفنا على كيفية تعريف مخطط ونماذج Mongoose، ثم استخدمنا هذه المعلومات لتصميم وتقديم نماذج Book و BookInstance و Author و Genre لموقع المكتبة المحلية LocalLibrary، واختبرنا نماذجنا من خلال إنشاء عدد من نسخ باستخدام سكريبت مستقل. سنتعرّف في المقال التالي على إنشاء بعض الصفحات لعرض هذه الكائنات. ترجمة -وبتصرُّف- للمقال Express Tutorial Part 3: Using a Database with Mongoose. اقرأ أيضًا المقال السابق تطبيق عملي لتعلم Express - الجزء الأول: إنشاء موقع ويب هيكلي لمكتبة محلية مقارنة بين MySQL و MongoDB تجهيز قاعدة البيانات PostgreSQL والتّعريف بمفهومي ORM وإضافات Flask دمج قاعدة البيانات MongoDB في تطبيقك Node