


Arabic Language
-
المساهمات
32 -
تاريخ الانضمام
-
تاريخ آخر زيارة
نوع المحتوى
ريادة الأعمال
البرمجة
التصميم
DevOps
التسويق والمبيعات
العمل الحر
البرامج والتطبيقات
آخر التحديثات
قصص نجاح
أسئلة وأجوبة
كتب
دورات
أجوبة بواسطة Arabic Language
-
-
بتاريخ 7 دقائق مضت قال Talaat Magdy:
تعتبر أشهر مكتبة في python هي matplotlib . هي مكتبة تساعدك علي تمثيل داتا بأشكال محتلفه منتوعه .
مثلا نريد تمثيل two list
x = [2, 4, 6] y = [1, 3, 5] plt.plot(x, y) plt.show()
سوف يظهر بهذا الشكل
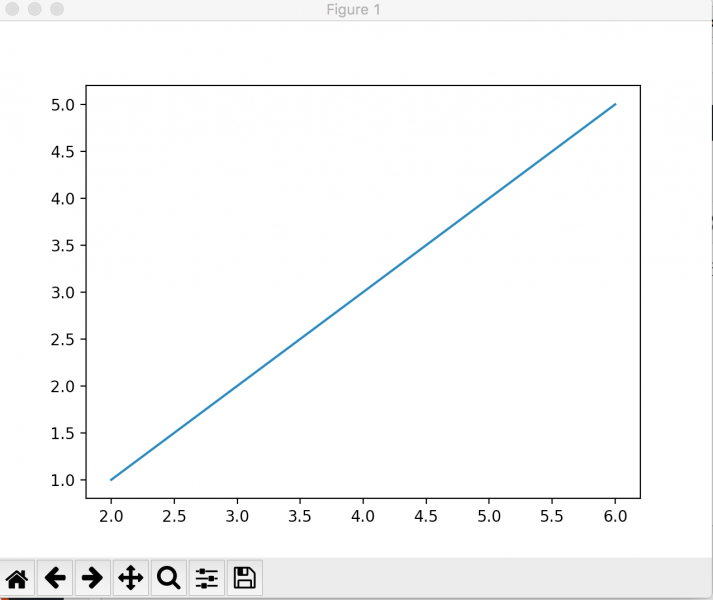
تدعم مكتبة الكثير من أشكال فمثلا

شكرا جزيلا ولكن هل لا بد من تحويل النصوص لأرقام ؟ لأن البيانات عندي نصية
-
مرحبا
عندي نصين كل نص في عمود والعمودين متساويين في الطول
العمودين متشابهين في بعض الكلمات
نسبة التشابه طلعتها بالبايثون
أرغب في تمثيل هذا التشابه بأي رسم بياني ممكن
مع الشكر
-
جهازي يعمل على ويندوز 10 الرام فيه 16 قيقا والمستهلكة 15,8
ولا أعرف السبب حقيقة كل شي سويته ودي اعرف وش اللي مستهلك الرام !!
كيف أعرف هذا التطبيق؟
-
 1
1
-
-
انحلت المشكلة عندي باستعمال سبايدر الحمد لله
-
استعملي cosine similarity
-
أنا قمت بهذه الخطوات كما ذكرت في السؤال ولم تحل المشكلة للأسف
-
تظهر لي هذه الرسالة عند تنفيذ أحد الأوامر
IOPub data rate exceeded. The notebook server will temporarily stop sending output to the client in order to avoid crashing it. To change this limit, set the config variable `--NotebookApp.iopub_data_rate_limit`. Current values: NotebookApp.iopub_data_rate_limit=1000000.0 (bytes/sec) NotebookApp.rate_limit_window=3.0 (secs)
بحثت عن المشكلة في المواقع ووجدتها في تعديل ملف التعريف إلى أقصى حد ممكن
عدلته وما زالت المشكلة بل إن إن اللميت يظهر لي limit=1000000.0 (bytes/sec) وكأني ما عدلته !
أرجو المساعدة أو إعطائي طريقة بديلة لحفظ النتائج في الجهاز دون شرط عرضها وشكرا لكم
-
تمام التمام أخي يعني سواء أسميتها خوارزمية أو مقياس فالأمر سيان خصوصا أني سأستعمل البايثون في إجراء العملية.
شكرا مليون
-
مرحبا
أعمل على مجموعتي بيانات لأجل استخراج الكلمات المتطابقة وأستعمل جاكارد JACCARD
في الجانب النظري أود أن أعرف بجاكارد ولكني وجدته يعرف مرة بوصفه مقياس رياضي ومرة أخرى بوصفه خوارزمية
فهل هو خوارزمية أو مقياس ؟ ولماذا تختلف تسميته ؟
شكرا لكم
-
نعم أخي الكريم ولكن لو جربت تطبيقها على نص لم تدرب عليه سيحدث هناك أخطاء في بعض أقسام الكلام بسبب وجود كلمات غير معروفة لم يدرب عليها النموذج، ومن ثم التشابه التوزيعي سيساعد في التخلص من وقوع النموذج في هذه الأخطاء ولكن السؤال كيف؟
-
مرحبا للجميع
يستعمل التشابه التوزيعي لحل مشكلات تصنيف الكلام إلى اسم وفعل وحرف إذا كانت البيانات قليلة وتكرارات الحرف مثلا صفرية أو منخفضة
هل أحد لديه فكرة عن آلية ذلك فقط الآلية دون الكود ؟
-
أخي الكريم المودل قيمته وانتهيت وكان على اللغة العربية خليط فصحى تراث ومعاصرة
الآن أريد أن أجرب هذا المودل على بيانات تراث فقط وليس عندي نسخة test
لذلك ما زال سؤال هل الأكيورسي والمراجعة اليدوية هي الحل الوحيد؟
المشروع عبارة عن part of speech tagger بالبايثون
-
طيب أستاذي إذا كانت البياناتضخمة فهل يعقل أن أقوم بمراجعتها يدويا حتى أظهر قيمة الاكيورسي ؟ ألا تستعمل منهجية أخرى هنا؟ عندي آلاف الكلمات لا بد أن أمر عليها
-
الحقيقة بعد شكري لك
أن الهدف ليس قياس المودل وإنما تطبيقه على نصوص أخرى وتقديمها للمهتم
لكني أود تصحيحها وأود أيضا حساب نسبة الخطأ
فهل حساب الخطأ يكون بالاكيورسي فقط؟
-
السلام عليكم
وشكرا للقائمين على الموقع ونفع الله بهم دائما
قمت ببناء مودل دريته على قاعدة بيانات 80% ثم اختبرته على 20% قمت بفصلها مسبقا من الأول unseen وحقق نسبة جيدة باستعمال مصفوفة الارتباك confusion
الآن أريد تجربته على بيانات جديدة مهيأة بنفس حالة البيانات التي درب عليها المودل
وأود أن أرى عمل المودل عليها
السؤال: لأتحقق من عمله هل علي المراجعة اليدوية؟ أم أن هناك مقاييس أداء جاهزة؟ هل هناك غير مقياس الصحة؟ باختصار كيف أقيس أدائه وأن لم أقم بعمل tagging للبيانات مسبقا؟
وشكرا مقدما
-
ليس عندي كلمات تفي شكرك حقيقة
شكرا بحجم الكون أفدتني كثير
عفوا فقط لأتأكد من فهمي
تحديدي يعني للمعاملين كلما صغر كان ذلك أفضل، أليس كذلك؟
الأول يجب أن يكون أكبر من صفر الثاني يجب أن يكون أصغر من 1 حتى يتعلم المودل بدون الوقوع في الاوفر فتينق
يعني التحديد للتوزيع الإحصائي كيف ؟ أعتمد على ماذا؟ هل أضعه اعتباطيا؟
-
1
-
-
وجدت هذا الكلام ولكني ما زلت أجهل كيف أحدد search space هل أضعها عشوائيا؟
Definition: A scalar field is a broad term for functions who take in points in a two or three dimensional space (R2 or R3) and outputs real numbers. The scalar field is a concept spawn from the natural and physical sciences since they often deal with a region of physical space with a function attached to it. For example, the function that gives the temperature of any point in the room you are sitting is a scalar field.You should note that a function doesn't need to expressed and defined as a mathematical formulat for it to be an explicit function. (Good luck figuring out the function for the temperature of every spot in your room!) Just the input-output correspondence. So particular scalara field may be specified by a mathematical expression, or it may be a function whose value at any point could be obtained by physical measurement.
-
اقتباس
%%time # define fixed parameters and parameters to search crf = sklearn_crfsuite.CRF( algorithm='lbfgs', max_iterations=1000, all_possible_transitions=True ) params_space = { 'c1': scipy.stats.expon(scale=0), 'c2': scipy.stats.expon(scale=500), } # use the same metric for evaluation f1_scorer = make_scorer(metrics.flat_f1_score, average='weighted', labels=labels) # search rs = RandomizedSearchCV(crf, params_space, cv=3, verbose=20, n_jobs=-1, n_iter=4, return_train_score=True, scoring=f1_scorer) rs.fit(X_train, y_train) print(rs.best_score_) print(rs.best_estimator_.get_params())
مرحبا
في هذا الكود يوجد params_space وهي مجال القيم التي سينتج عنها تحديد أفضل قيمتين c1 وc2 لخوارزمية crf
crf = sklearn_crfsuite.CRF(algorithm= 'lbfgs', c1=0, #القيمة الافتراضية c2=1,#القيمة الافتراضية max_iterations=1000, all_possible_transitions=True) crf.fit(X_train, y_train)
مجال القيم هذا توجد فيه أرقام لا أفهمها ولا أفهم إلام ترمز ولماذا كلما صغرت كانت النتيجة أدق ؟ وهل لها مقابل بالنسبة المئوية ؟ يعني لو وضعت 0.5 ماذا تعني وليكن ذلك موضحا على محورين x y أود أن أفهمها حقيقة كما فهمت أن n_iter=4 كلما زادت كلما كان فرص الحصول على قيم أدق أفضل.
شكرا لكم
-
1
-
-
مرحبا
إذاعندي قاعدة بيانات قمت بتدريب نموذج واختباره بالاعتماد عليها ثم قمت بتطبيقه على بيانات unseen
ثم صححتها يدويا وأضفتها لقاعدة البيانات الأساسية وكررت هذه العملية من أجل زيادة حجم البيانات
هل لهذه التقنية مصطلح علمي نحو: augmentation
شكرا مقدما
-
سؤال نظري: متى لا يصلح عمل cross validation مع البيانات؟
هل هناك اشتراطات لعمله مع البيانات أم أن أي حجم بيانات لا يتعارض معه؟
مع الشكر مقدما
-
بتاريخ 18 ساعات قال مصطفى القباني:
تمام البيانات موجودة في شكل متسلسل وهذا صحيح، بالتالي تكون الدقة العالية التي حققها المودل هي دليل على حدوث الoverfitting.
يمكنك معالجة هذا بتصغير حجم المودل فمثلا يمكنك تقليل حجم الembedding layer أو حجم الLSTM layer.
يمكنك القراءة أكثر عن ظاهرة الoverfitting من هنا.
أخي الكريم
عفوا عندي مشكلة أخرى في البيانات وهو أني عند التنبؤ وإدخال نص خارجي لتحديد أنواع الكلمة فيه يقوم بتحديد كل الكلمات التي وردت في قاعدة البيانات التي تدرب عليها وإذا كان هناك كلمة لم يرها يعطيني keyError فكيف تحل هذه المشكلة؟
-
يعطيك العافية شكرا لك الشكر الجزيل
-
لما D
توفى V
والد A
السعدى N
عطفت V
عليه RP
زوجة N
والده Aهكذا في ملف txt ويفصل بين الكلفة ونوعها tab
طبعا عندي أكواد أستعملها لفصل كل عمود عن الآخر
فتصبح على هذه الصورة
['ف' 'قد' 'عاش' 'الى' 'سنة' '1388' 'ه' 'ست' 'و' 'تسعين' 'سنة']
['RP' 'RP' 'V' 'RP' 'N' 'DIGIT' 'ABBREV' 'N' 'N' 'N' 'N']
بتاريخ 21 دقائق مضت قال مصطفى القباني:هل يمكنك أن ترفق بعض البيانات المستخدمة للتدريب؟
أنا أعتقد أن المشكلة هي في شكل البيانات، لأن قوة LSTM تظهر عند إستخدامها على الsequences أو البيانات المتتابعة أو المتسلسلة، وإستخدامها لعمل تصنيف للكلمة بدون مدخلات متسلسلة سيحدث overfitting.
لما D
توفى V
والد A
السعدى N
عطفت V
عليه RP
زوجة N
والده Aهكذا في ملف txt ويفصل بين الكلفة ونوعها tab
طبعا عندي أكواد أستعملها لفصل كل عمود عن الآخر
فتصبح على هذه الصورة
['ف' 'قد' 'عاش' 'الى' 'سنة' '1388' 'ه' 'ست' 'و' 'تسعين' 'سنة']
['RP' 'RP' 'V' 'RP' 'N' 'DIGIT' 'ABBREV' 'N' 'N' 'N' 'N']
-
شكرا لردك وسأبدأ من الأخير.
المخرج المقصود به أني أقدم نصا لم يتدرب عليه النموذج وليس من عينة الاختبار ليقوم بتحديد نوع كل كلمة فيه فعل اسم حرف ..الخ
ومليء بالأخطاء.
البيانات واحدة وتقسيمها عشوائي
وجربت أيضا فصلها يدويا ونفس المشكلة
أقوم به على مستوى الكلمة وليس على مستوى الحرف
from keras.models import Sequential
from keras.layers import Dense, LSTM, InputLayer, Bidirectional, TimeDistributed, Embedding, Activation
from keras.optimizers import Adam
model = Sequential()
model.add(InputLayer(input_shape=(MAX_LENGTH, )))
model.add(Embedding(len(word2index), 256))
model.add(Bidirectional(LSTM(128, return_sequences=True)))
model.add(TimeDistributed(Dense(len(tag2index))))
model.add(Activation('softmax'))
model.compile(loss='categorical_crossentropy',
optimizer=Adam(0.001),
metrics=['accuracy', ignore_class_accuracy(0)])
model.summary()بالنسبة للتشكيل أنا أريد بناء هذا النظام للنصوص غير المشكولة لأننا في الغالب نكتب بدونها.
كيف نقوم بعمل Scaling على ال Dataset - بايثون
في بايثون
نشر
هل هذه العمليات تنفذ على X او y ؟