

MemSQL عبارة عن قاعدة بيانات تعمل مُباشرة من الذاكرة in-memory تستطيع أن تُخدِّم القراءة والكتابة بشكل أسرع من قواعد البيانات التقليديّة، وبالرغم من أنّها تقنية حديثة إلّا أنّها تتعامل بميفاق protocol قاعدة بيانات MySQL لذلك يكون التعامل معها مألوفًا.

تضم MemSQL أحدث قدرات MySQL مع ميّزات حديثة مثل دعم JSON والقدرة على عمل upsert للبيانات (تعني كلمة upsert إدراج صف جديد إن لم يكن موجودًا أي insert، أو تحديث هذا الصف إن كان موجودًا أي update). إنّ أحد أهم نقاط تفوّق MemSQL على MySQL هي قدرتها على فصل الاستعلام query عبر عدّة عقد nodes، والمعروفة أيضًا باسم المعالجة المتوازية على نطاق واسع massively parallel processing، ممّا يؤدي إلى سرعة أكبر في قراءة الاستعلامات.
سنقوم في هذا الدّرس بتثبيت MemSQL على خادوم Ubuntu، تنفيذ تجارب قياس الأداء benchmarks، والتعامل مع إدراج بيانات JSON عبر عميل سطر الأوامر في MySQL.
المتطلبات الأساسية
سنحتاج لمتابعة هذا الدّرس إلى:
- Ubuntu 14.04 x64 Droplet مع ذاكرة RAM 8 غيغابايت على الأقل (أو خادوم محلّي بنفس المواصفات)
- مستخدم غير جذري non-root مع صلاحيّات sudo، والذي يُمكِن إعداده عن طريق درس الإعداد الأولي للخادوم مع Ubuntu.
الخطوة الأولى – تثبيت MemSQL
سنقوم في هذا القسم بتحضير بيئة العمل من أجل تثبيت MemSQL.
يتم عرض آخر إصدار من MemSQL على صفحة تحميله، سنقوم بتحميل وتثبيت MemSQL Ops، والذي هو برنامج يدير تحميل وتحضير خادومنا لتشغيل MemSQL بشكل صحيح، الإصدار الأحدث من MemSQL Ops لدى كتابة هذا الدّرس هو 4.0.35.
نقوم في البداية بتنزيل ملف حزمة تثبيت MemSQL من موقعها على الإنترنت:
wget http://download.memsql.com/memsql-ops-4.0.35/memsql-ops-4.0.35.tar.gz
نستخرج extract بعدها الحزمة:
tar -xzf memsql-ops-4.0.35.tar.gz
أنشأ استخراج الحزمة مجلّدًا يُدعى memsql-ops-4.0.35، نلاحظ أنّ اسم المجلّد يحتوي على رقم الإصدار، لذلك إن قمت بتنزيل إصدار أحدث من الإصدار المحدّد في هذا الدّرس فستملك مجلّدًا مع رقم الإصدار الذي نزّلته.
نغير الدليل إلى هذا المجلّد:
cd memsql-ops-4.0.35
ثم نقوم بتنفيذ script التثبيت والذي هو جزء من حزمة التثبيت التي استخرجناها للتو:
sudo ./install.sh
سنرى بعض الخَرْج output من الـ script، وسيسألنا بعد لحظات إذا ما كنّا نرغب بتثبيت MemSQL على هذا المُضيف host فقط، سنتعلّم تثبيت MemSQL على عدّة أجهزة في درس لاحق، لذا من أجل غرض هذا الدّرس فلنقل نعم yes عن طريق إدخال الحرف y:
Installation script prompt and output . . . Do you want to install MemSQL on this host only? [y/N] y 2015-09-04 14:30:38: Jd0af3b [INFO] Deploying MemSQL to 45.55.146.81:3306 2015-09-04 14:30:38: J4e047f [INFO] Deploying MemSQL to 45.55.146.81:3307 2015-09-04 14:30:48: J4e047f [INFO] Downloading MemSQL: 100.00% 2015-09-04 14:30:48: J4e047f [INFO] Installing MemSQL 2015-09-04 14:30:49: Jd0af3b [INFO] Downloading MemSQL: 100.00% 2015-09-04 14:30:49: Jd0af3b [INFO] Installing MemSQL 2015-09-04 14:31:01: J4e047f [INFO] Finishing MemSQL Install 2015-09-04 14:31:03: Jd0af3b [INFO] Finishing MemSQL Install Waiting for MemSQL to start...
نمتلك الآن مجموعة MemSQL مُثبَّتة على خادوم أوبونتو لدينا، ولكن نلاحظ من السجلّات السّابقة أنّه تم تثبيت MemSQL مرتين.
تستطيع MemSQL أن تعمل بدورين مختلفين: عقدة مُجمِّع aggregator node وعقدة ورقة leaf node، إنّ سبب تثبيت MemSQL مرتين هو أنّها تحتاج على الأقل إلى عقدة مُجمِّع واحدة وعقدة ورقة واحدة لكي يعمل العنقود cluster.
إنّ عقدة المُجمِّع aggregator node هي واجهتنا إلى MemSQL، وهي تبدو بالنسبة للعالم الخارجي مشابهة كثيرًا لـ MySQL، فهي تستمع إلى نفس المنفذ port، وبإمكاننا أن نربط إليها أدوات تتوقّع أن تتعامل مع MySQL ومكتبات MySQL المعياريّة، وظيفة المُجمِّع هي أن يعرف عن كافّة عُقَد الورقة leaf nodes لـ MemSQL، يتعامل مع عُملاء MySQL، ويترجم استعلاماتهم إلى MemSQL.
تُخزِّن عقدة الورقة leaf node البيانات فعليًّا، فعندما تستقبل عقدة الورقة طلبًا من عقدة المُجمِّع لقراءة أو كتابة البيانات تقوم بتنفيذ هذا الاستعلام وتُعيد النتائج إلى عقدة المُجمِّع، تسمح MemSQL لنا بمشاركة بياناتنا عبر عدّة مضيفين، وتمتلك كل عقدة ورقة قسمًا من تلك البيانات (حتى مع وجود عقدة ورقة واحدة تكون البيانات تكون البيانات مُقسَّمة ضمن تلك العقدة).
عندما نملك عدة عقد ورقة يكون المُجمِّع مسؤولًا عن ترجمة استعلامات MySQL لجميع عقد الورقة التي ينبغي أن تشارك في هذا الاستعلام، ومن ثمّ يتلقى الردود من جميع عقد الورقة ويُجمِّع النتيجة في استعلام واحد يعود إلى عميل MySQL لدينا، وهكذا تتم إدارة الاستعلامات المتوازية.
يمتلك إعداد المضيف الوحيد لدينا عقدة مُجمِّع وورقة تعملان على نفس الجهاز، ولكن نستطيع إضافة المزيد من عقد الورقة عبر العديد من الأجهزة الأخرى.
الخطوة الثانية – تنفيذ تجربة قياس أداء
فلنرى مدى السّرعة التي تستطيع أن تعمل بها MemSQL باستخدام الأداة MemSQL Ops والتي تم تثبيتها كجزء من script تثبيت MemSQL.
نذهب إلى http://you_server_ip:9000 في متصفحنا:

تعطينا الأداة MemSQL Ops لمحة عامّة عن العنقود cluster لدينا، نمتلك عقدتي MemSQL: المُجمِّع الرئيسي وعقدة الورقة.
فلنقم بإجراء اختبار السّرعة Speed Test على عقدة MemSQL في جهازنا المفرد، نضغط على Speed Test من القائمة الموجودة على اليسار، وبعدها نضغط على START TEST، وهذا مثال عن النتائج التي قد نراها:

لن نشرح في هذا الدّرس كيفيّة تثبيت MemSQL على خواديم متعددة، ولكن من أجل المقارنة أدرجنا هنا قياس أداء من عنقود MemSQL على نظام Ubuntu يملك 8 جيجابايت من الذّاكرة Ram وعدّة عقد (عقدة مُجمِّع وعقدتا leaf):
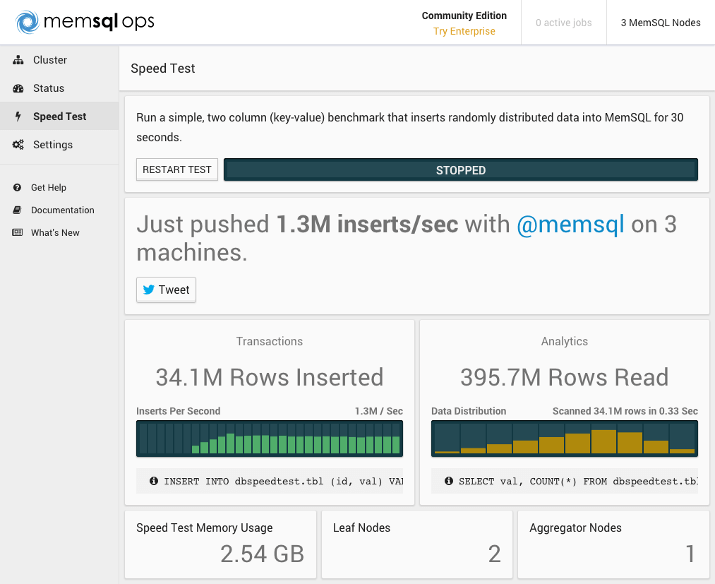
نكون قادرين بزيادة عدد عقد leaf أن نُضاعِف مُعدَّل الإدراج insert، وبالنظر إلى أقسام قراءة الصفوف Rows Read نستطيع أن نرى أنّ عنقود العقد الثلاثة لدينا قادر على قراءة الصفوف بشكل متزامن أكثر بمقدار 12 مليون صف من عنقود العقدة الواحدة وفي نفس المدة الزمنية.
الخطوة الثالثة – التعامل مع MemSQL من خلال mysql-client
تبدو MemSQL بالنسبة للعملاء مثل MySQL، فكلاهما تتعامل بنفس الميفاق protocol، ولبدء التخاطب مع عنقود MemSQL لدينا نقوم بتثبيت mysql-client.
في البداية نقوم بتحديث apt لكي نُثبِّت الإصدار الأخير من العميل client في الخطوة التالية:
sudo apt-get update
نُثبِّت الآن عميل MySQL والذي سيُمكّننا من تنفيذ الأمر mysql:
sudo apt-get install mysql-client-core-5.6
نحن الآن على استعداد للاتصال بـ MemSQL باستخدام عميل MySQL، سنتصل باستخدام المستخدم الجذري root إلى المضيف 127.0.0.1 (والذي هو عنوان IP للمضيف المحلّي localhost لدينا) على المنفذ 3306، سنقوم بتخصيص رسالة المُحث prompt لتكون <memsql:
mysql -u root -h 127.0.0.1 -P 3306 --prompt="memsql> "
سنشاهد بعض أسطر الخَرْج متبوعة بالمُحث <memsql.
فلنقم بسرد list قواعد البيانات:
memsql> show databases;
سنشاهد هذا الخَرْج:
+--------------------+ | Database | +--------------------+ | information_schema | | memsql | | sharding | +--------------------+ 3 rows in set (0.01 sec)
نُنشِئ قاعدة بيانات جديدة تُدعى tutorial:
memsql> create database tutorial;
ثم نتحوّل لاستخدام قاعدة البيانات الجديدة باستخدام الأمر use:
memsql> use tutorial;
نقوم بعدها بإنشاء جدول users والذي يملك الحقلين id و email، يجب علينا تحديد نوع لكلا هذين الحقلين، فلنجعل id من نوع bigint و email من نوع varchar بطول 255، سنخبر أيضًا قاعدة البيانات أنّ الحقل id هو مفتاح أساسي primary key والحقل email لا يُمكن أن يكون عَدم Null.
memsql> create table users (id bigint auto_increment primary key, email varchar(255) not null);
ربّما تلاحظ زمن تنفيذ بطيء للأمر الأخير (15-20 ثانية)، هناك سبب رئيسي يجعل من MemSQL بطيئة في إنشاء هذا الجدول الجديد وهو: توليد الشيفرة code generation.
تستخدم MemSQL توليد الشيفرة لتنفيذ الاستعلامات، وهذا يعني أنّه في كل مرة تتم فيها مصادفة نوع جديد من الاستعلامات تحتاج MemSQL توليد وتصريف compile الشيفرة التي تُمثِّل الاستعلام، يتم بعدها نقل الشيفرة إلى العنقود لتنفيذها، وهذا يُسرِّع عمليّة معالجة البيانات الفعليّة ولكن هناك تكلفة من أجل التحضير، تبذل MemSQL جهدها لإعادة استخدام الاستعلامات المُولَّدة مُسبقًا pre-generated queries، ولكن تبقى الاستعلامات الجديدة ذات البُنية التي لم تشاهدها MemSQL من قبل بطيئة.
وبالعودة إلى جدول users نقوم بإلقاء نظرة على تعريفه:
memsql> describe users;
+-------+--------------+------+------+---------+----------------+ | Field | Type | Null | Key | Default | Extra | +-------+--------------+------+------+---------+----------------+ | id | bigint(20) | NO | PRI | NULL | auto_increment | | email | varchar(255) | NO | | NULL | | +-------+--------------+------+------+---------+----------------+ 2 rows in set (0.00 sec)
فلنقم الآن بإدراج بعض أمثلة عناوين البريد الإلكتروني في الجدول users، وهي نفس الصياغة syntax التي نستخدمها لقاعدة بيانات MySQL:
memsql> insert into users (email) values ('one@example.com'), ('two@example.com'), ('three@example.com');Inserting emails output Query OK, 3 rows affected (1.57 sec) Records: 3 Duplicates: 0 Warnings: 0
نستعلم الآن عن الجدول users:
memsql> select * from users;
بإمكاننا رؤية البيانات التي أدخلناها للتو:
+----+-------------------+ | id | email | +----+-------------------+ | 2 | two@example.com | | 1 | one@example.com | | 3 | three@example.com | +----+-------------------+ 3 rows in set (0.07 sec)
الخطوة الرابعة – إدراج واستعلام JSON
توفِّر MemSQL نوع JSON، لذا سنقوم في هذه الخطوة بإنشاء جدول أحداث events لاستخدام الأحداث الواردة، يمتلك هذا الجدول حقل id (كما فعلنا مع جدول users) وحقل event والذي سيكون من النوع JSON:
memsql> create table events (id bigint auto_increment primary key, event json not null);
فلنقم بإدراج حدثين، سنقوم في JSON بإرجاع حقل email والذي بدوره يقوم بإعادة الإرجاع إلى مُعرِّفات IDs المستخدمين الذين أدخلناهم في الخطوة الثالثة:
memsql> insert into events (event) values ('{"name": "sent email", "email": "one@example.com"}'), ('{"name": "received email", "email": "two@example.com"}');نقوم الآن بإلقاء نظرة على الأحداث events التي أدرجناها للتو:
memsql> select * from events;
+----+-----------------------------------------------------+
| id | event |
+----+-----------------------------------------------------+
| 2 | {"email":"two@example.com","name":"received email"} |
| 1 | {"email":"one@example.com","name":"sent email"} |
+----+-----------------------------------------------------+
2 rows in set (3.46 sec)نستطيع بعدها الاستعلام عن كل الأحداث events التي تكون خاصّية JSON لها التي تُدعى name هي النّص “received email”:
memsql> select * from events where event::$name = 'received email';
+----+-----------------------------------------------------+
| id | event |
+----+-----------------------------------------------------+
| 2 | {"email":"two@example.com","name":"received email"} |
+----+-----------------------------------------------------+
1 row in set (5.84 sec)نحاول تغيير هذا الاستعلام لإيجاد تلك الأحداث التي خاصيّة name لها هي النّص “sent email”:
memsql> select * from events where event::$name = 'sent email';
+----+-------------------------------------------------+
| id | event |
+----+-------------------------------------------------+
| 1 | {"email":"one@example.com","name":"sent email"} |
+----+-------------------------------------------------+
1 row in set (0.00 sec)تم تنفيذ هذا الاستعلام الأخير بشكل أسرع من الاستعلام الذي سبقه لأنّنا غيّرنا فقط مُعامِل في الاستعلام، لذا كانت MemSQL قادرة على تخطّي توليد الشيفرة.
فلنقم بعمل شيء أكثر تقدّمًا بالنسبة لقاعدة بيانات SQL مُوزَّعة، وهو ضم جدولين على أساس مفاتيح غير أساسيّة non-primary حيث يتم تداخل قيمة ما من الانضمام join بداخل قيمة JSON ولكن يكون الترشيح filter على أساس قيمة JSON مختلفة.
نسأل في البداية عن كافّة حقول جدول المستخدمين users مع ضم جدول الأحداث events بمطابقة حقل البريد الإلكتروني email حيث يكون اسم الحدث هو “received email”.
memsql> select * from users left join events on users.email = events.event::$email where events.event::$name = 'received email';
+----+-----------------+------+-----------------------------------------------------+
| id | email | id | event |
+----+-----------------+------+-----------------------------------------------------+
| 2 | two@example.com | 2 | {"email":"two@example.com","name":"received email"} |
+----+-----------------+------+-----------------------------------------------------+
1 row in set (14.19 sec)نجرب بعد ذلك نفس الاستعلام ولكن مع ترشيح الأحداث “sent email” فقط:
memsql> select * from users left join events on users.email = events.event::$email where events.event::$name = 'sent email';
+----+-----------------+------+-------------------------------------------------+
| id | email | id | event |
+----+-----------------+------+-------------------------------------------------+
| 1 | one@example.com | 1 | {"email":"one@example.com","name":"sent email"} |
+----+-----------------+------+-------------------------------------------------+
1 row in set (0.01 sec)وكما وجدنا سابقًا فإنّ الاستعلام الثاني أسرع بكثير من الأول، تظهر فائدة توليد الشيفرة عند تنفيذ أكثر من مليون صف، كما رأينا في قياس الأداء، إنّ مرونة استخدام قواعد بيانات SQL تفهم JSON وكيفيّة الانضمام بين الجداول هي ميزة قوية للمستخدمين.
الخاتمة
لقد قمنا بتثبيت MemSQL، تنفيذ تجربة قياس أداء العقد لدينا، التعامل مع العقدة من خلال عميل MySQL المعياري، وتعاملنا مع بعض الميّزات المتقدمة غير الموجودة في MySQL، ينبغي أن يعطينا هذا فكرة واضحة عمّا يمكن أن تفعله قاعدة بيانات SQL داخل الذاكرة لنا.
لا يزال هناك الكثير لتعلّمه حول كيفيّة توزيع MemSQL لبياناتنا فعليًّا، كيفية بناء الجداول من أجل أفضل أداء، كيفيّة توسيع MemSQL عبر عدّة عقد، كيفيّة تكرار بياناتنا من أجل توافريّة عالية للبيانات، وكيفيّة تأمين MemSQL.
ترجمة -وبتصرّف- لـ How to Install MemSQL on Ubuntu 14.04 لصاحبه Ian Hansen.







أفضل التعليقات
لا توجد أية تعليقات بعد
انضم إلى النقاش
يمكنك أن تنشر الآن وتسجل لاحقًا. إذا كان لديك حساب، فسجل الدخول الآن لتنشر باسم حسابك.